Det här är ett gästinlägg skrivet av Ahmed Saef Zamzam och Geetha Anne från Confluent.
Företag använder dataströmmar i realtid för att få insikter om företagets prestanda och fatta välgrundade, datadrivna beslut snabbare. Eftersom realtidsdata har blivit avgörande för företag, anpassar ett växande antal företag sin datastrategi för att fokusera på data i rörelse. Händelseströmning är det centrala nervsystemet i en data i rörelse-strategi och i många organisationer, Apache Kafka är verktyget som driver den.
Idag är Kafka välkänt och flitigt använt för att streama data. Men att hantera och driva Kafka i stor skala kan fortfarande vara utmanande. Konfluenta erbjuder en lösning genom sin fullt hanterade, molnbaserade tjänst som förenklar drift och drift av dataströmmar i stor skala. Confluent utökar Kafka med öppen källkod genom en uppsättning relaterade tjänster och funktioner utformade för att förbättra upplevelsen av data i rörelse för operatörer, utvecklare och arkitekter i produktionen.
I det här inlägget visar vi hur Amazonas Athena, Amazon QuickSight, och Confluent arbetar tillsammans för att möjliggöra visualisering av dataströmmar i nästan realtid. Vi använder Kafka-kontakten i Athena för att göra följande:
- Sammanfoga data inuti Confluent med data som lagras i en av de många datakällor som stöds av Athena, som t.ex. Amazon enkel lagringstjänst (Amazon S3)
- Visualisera Confluent-data med QuickSight
Utmaningar
Specialbyggda strömbearbetningsmotorer, som Sammanflytande ksqlDB, tillhandahåller ofta SQL-liknande semantik för realtidstransformationer, kopplingar, aggregationer och filter på strömmande data. Med ksqlDB kan du skapa ihållande frågor, som kontinuerligt bearbetar strömmar av händelser enligt specifik logik, och materialiserar strömmande data i vyer som kan frågas vid en tidpunkt (dra frågor) eller prenumererade på av kunder (push-frågor).
ksqlDB är en lösning som gjorde strömbehandling tillgänglig för ett större antal användare. Men pull-frågor, som de som stöds av ksqlDB, kanske inte är lämpliga för alla användningsfall för strömbearbetning, och det kan finnas komplexitet eller unika krav som pull-frågor inte är designade för.
Datavisualisering för Confluent data
Ett vanligt användningsfall för företag är datavisualisering. För att visualisera data lagrad i Confluent kan du använda en av över 120 förbyggda kontakter, som tillhandahålls av Confluent, för att skriva strömmande data till en destinationsdatalager som du väljer. Därefter ansluter du ditt Business Intelligence-verktyg (BI) till datalagret för att börja visualisera data.
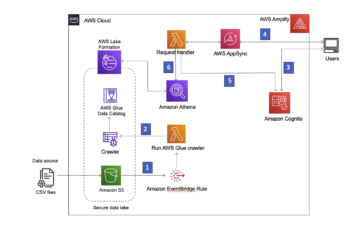
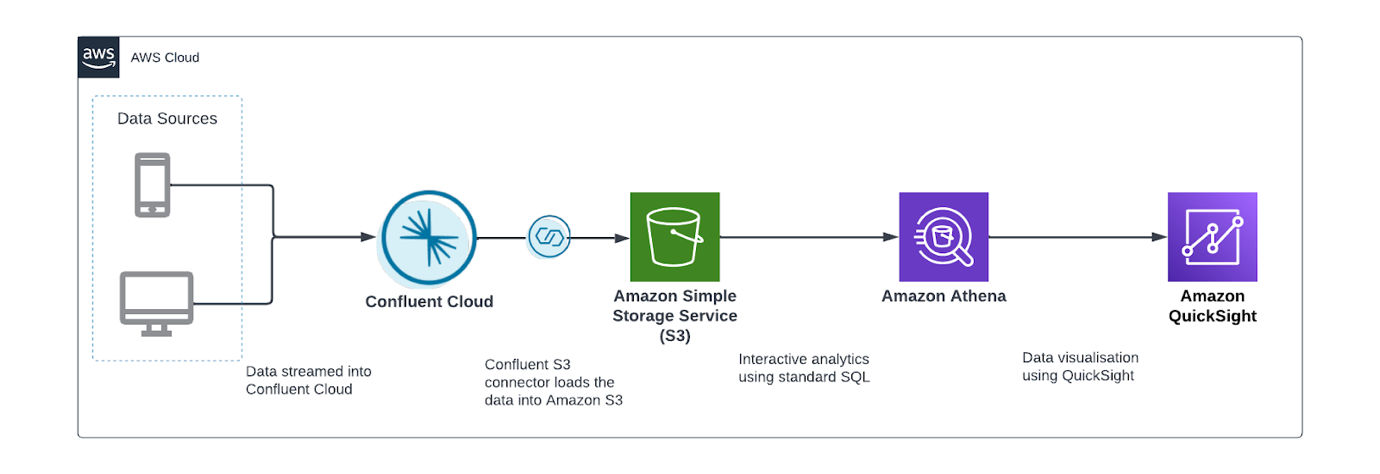
Följande diagram visar en typisk arkitektur som används av många Confluent-kunder. I detta arbetsflöde skrivs data till Amazon S3 genom Confluent S3 diskbänkskontakt och analyseras sedan med Athena, en serverlös interaktiv analystjänst som gör att du kan analysera och söka efter data lagrad i Amazon S3 och olika andra datakällor med standard SQL. Du kan sedan använda Athena som en indatakälla till QuickSight, en mycket skalbar molnbaserad BI-tjänst, för vidare analys.
Även om detta tillvägagångssätt fungerar bra för många användningsfall, kräver det att data flyttas, och därför dupliceras, innan det kan visualiseras. Denna dubblering lägger inte bara till tid och ansträngning för dataingenjörer som kan behöva utveckla och testa nya skript, utan skapar också dataredundans, vilket gör det mer utmanande att hantera och säkra data, och ökar lagringskostnaderna.
Berika data med referensdata i ett annat datalager
Med ksqlDB-frågor är källan och destinationen alltid Kafka-ämnen. Därför, om du har en dataström som du behöver berika med extern referensdata, har du två alternativ. Ett alternativ är att importera referensdata till Confluent, modellera det som en tabell och använda ksqlDB:s strömtabellsanslutning för att berika strömmen. Det andra alternativet är att mata in dataströmmen i ett separat datalager och utföra kopplingsoperationer där. Båda kräver dataflyttning och resulterar i dubblettdatalagring.
Lösningsöversikt
Hittills har vi diskuterat två utmaningar som inte hanteras av konventionella strömbearbetningsverktyg. Finns det en lösning som löser båda utmaningarna samtidigt?
När du vill analysera data utan separata pipelines och jobb är Athena ett populärt val. Med Athena kan du köra SQL-frågor på en brett utbud av datakällor— förutom Amazon S3 — utan att lära sig ett nytt språk, utveckla skript för att extrahera (och duplicera) data eller hantera infrastruktur.
Nyligen meddelade Athena en kontakt för Kafka. Precis som Athenas andra kopplingar, bearbetas frågor om Kafka inom Kafka och returnerar resultat till Athena. Anslutningen stöder predikat-pushdown, vilket innebär att om du lägger till filter i dina frågor kan du minska mängden data som skannas, förbättra frågeprestanda och minska kostnaderna.
Till exempel, när du använder denna anslutning, mängden data som skannas av frågan SELECT * FROM CONFLUENT_TABLE kan vara betydligt högre än mängden data som skannas av frågan SELECT * FROM CONFLUENT_TABLE WHERE COUNTRY = 'UK'. Anledningen är att AWS Lambda funktion som tillhandahåller runtime-miljön för Athena-anslutningen, filtrerar data vid källan innan den returneras till Athena.
Låt oss anta att vi har en ström av onlinetransaktioner som flödar in i Confluent och kundreferensdata lagrade i Amazon S3. Vi vill använda Athena för att sammanfoga båda datakällorna och producera en ny datauppsättning för QuickSight. Istället för att använda S3 sink-kontakten för att ladda data till Amazon S3, använder vi Athena för att fråga Confluent och sammanfoga den med S3-data – allt utan att flytta data. Följande diagram illustrerar denna arkitektur.

Vi utför följande steg:
- Registrera schemat för dina Confluent-data.
- Konfigurera Athena-kontakten för Kafka.
- Alternativt kan du interaktivt analysera Confluent-data.
- Skapa en QuickSight-datauppsättning med Athena som källa.
Registrera schemat
För att ansluta Athena till Confluent måste kopplingen schemat för ämnet registreras i AWS Glue Schema Registry, som Athena använder för frågeplanering.
Följande är en exempelpost i Confluent:
Följande är schemat för denna post:
Dataproducenten som skriver data kan registrera detta schema med AWS Glue Schema Registry. Alternativt kan du använda AWS Management Console or AWS-kommandoradsgränssnitt (AWS CLI) till skapa ett schema manuellt.
Vi skapar schemat manuellt genom att köra följande CLI-kommando. Byta ut med ditt registernamn och se till att texten i beskrivningsfältet innehåller den obligatoriska strängen {AthenaFederationKafka}:
Därefter kör vi följande kommando för att skapa ett schema i det nyskapade schemaregistret:
Innan du kör kommandot, se till att ange följande information:
- ersätta med vårt AWS Glue Schema Registry-namn
- ersätta med namnet på vårt Confluent Cloud-ämne, till exempel transaktioner
- ersätta <Kompatibilitetsläge> med en av de som stöds kompatibilitetslägent.ex. "Bakåt"
- ersätta med vårt schema
Konfigurera och distribuera Athena Connector
Med vårt schema skapat är vi redo att distribuera Athena-anslutningen. Slutför följande steg:
- Välj på Athena-konsolen Datakällor i navigeringsfönstret.
- Välja Skapa datakälla.
- Sök efter och välj Apache Kafka.
- För Datakällans namnanger du namnet på datakällan.

Det här datakällans namn kommer att refereras till i dina frågor. Till exempel:
Om vi tillämpar detta på vårt användningsfall och tidigare definierade schema, skulle vår fråga vara som följer:
- I Anslutningsdetaljer avsnitt väljer Skapa Lambda-funktion.
Du omdirigeras till Applikationer sida på lambdakonsolen. Vissa av applikationsinställningarna är redan ifyllda.
Följande är de viktiga inställningar som krävs för att integrera med Confluent Cloud. För mer information om dessa inställningar, se parametrar.
- För LambdaFunktionsnamn, ange namnet på den lambdafunktion som kontakten ska använda. Till exempel,
athena_confluent_connector.
Vi använder denna parameter i nästa steg.
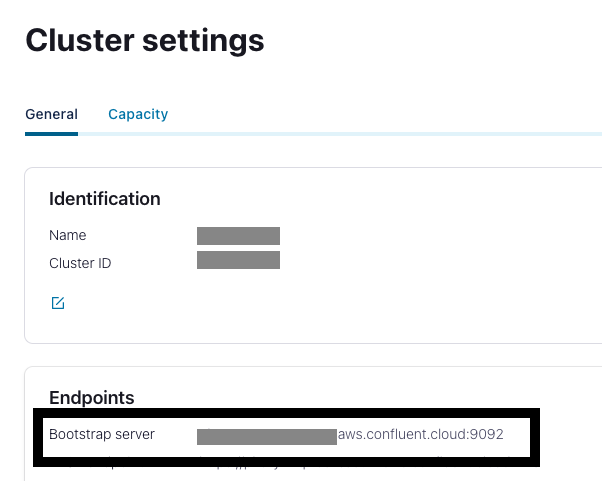
- För Kafka Endpoint, ange Confluent Cloud bootstrap URL.
Du hittar detta på Klusterinställningar sida i Confluent Cloud UI.
Confluent Cloud stöder två autentiseringsmekanismer: OAuth och SASL/PLAIN (API-nycklar). Anslutningen stöder inte OAuth; detta lämnar oss med SASL/PLAIN. SASL/PLAIN använder SSL som säkerhetsprotokoll och PLAIN som SASL-mekanism.
- För AuthType, stiga på
SASL_SSL_PLAIN.
API-nyckeln och hemligheten som används av anslutaren för att komma åt Confluent måste lagras i AWS Secrets Manager.
- Skaffa din Confluent API-nyckel eller skapa en ny.
- Kör följande AWS CLI-kommando för att skapa hemligheten i Secrets Manager:
Den hemliga strängen ska ha två nyckel-värdepar, varav ett namnges username och den andra password.
- För SecretNamePrefix, ange det hemliga namnprefixet som skapades i föregående steg.
- Om Confluent-molnklustret är tillgängligt över internet, lämna SecurityGroupIds och SubnetIds tom. Annars måste din Lambda-funktion köras i en VPC som har anslutning till ditt Confluent Cloud-nätverk. Ange därför ett säkerhetsgrupp-ID och tre privata subnät-ID:n i denna VPC.
- För SpillBucket, ange namnet på en S3-hink där kontakten kan spilla data.
Athena-kontakter lagrar tillfälligt (Spill) data till Amazon S3 för vidare bearbetning av Athena.
- Välja Jag är medveten om att den här appen skapar anpassade IAM-roller och resurspolicyer.
- Välja Distribuera.
- Återgå till Anslutningsdetaljer avsnitt om Athena-konsolen och för Lambda, ange namnet på Lambda-funktionen du skapade.
- Välja Nästa.
- Välja Skapa datakälla.
Utför interaktiv analys av konfluenta data
Med Athena-anslutningen konfigurerad är vår streamingdata nu sökbar från samma tjänst som vi använder för att analysera S3-datasjöar. Därefter använder vi Athena för att utföra punkt-i-tidsanalys av transaktioner som flödar genom Confluent Cloud.
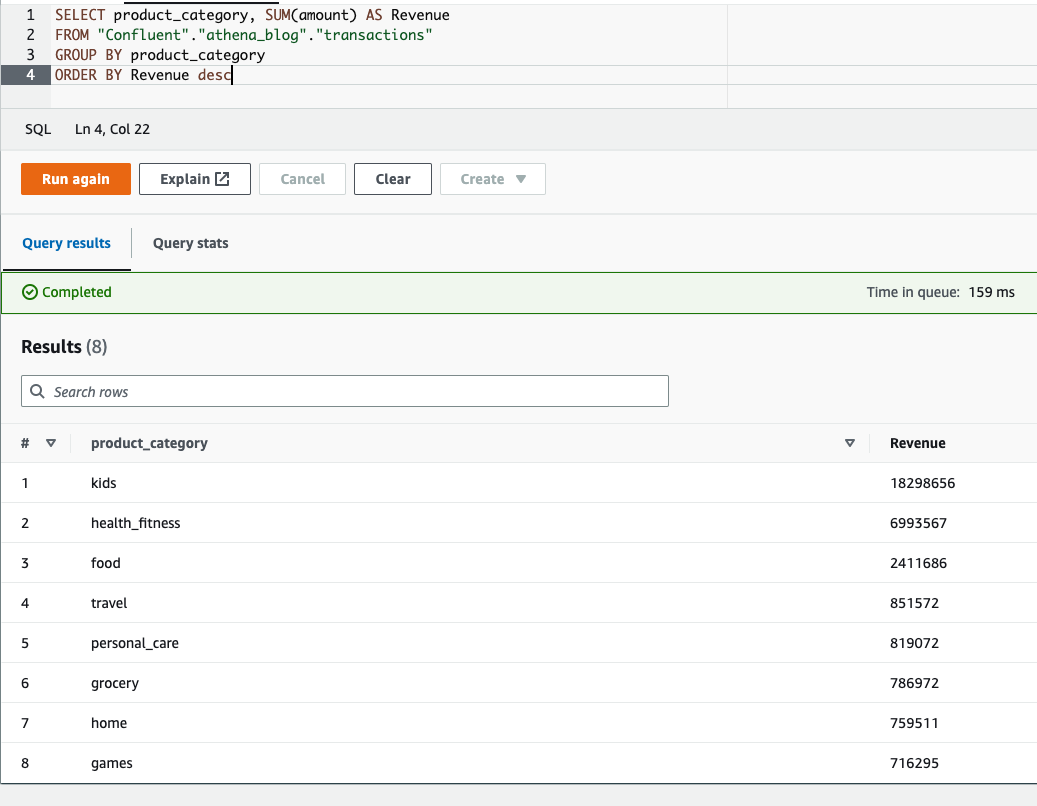
aggregation
Vi kan använda standard SQL-funktioner för att aggregera data. Till exempel kan vi få intäkterna per produktkategori:
Berika transaktionsdata med kunddata
Aggregeringsexemplet är också tillgängligt med ksqlDB pull-frågor. Men Athenas anslutning tillåter oss att sammanfoga data med andra datakällor som Amazon S3.
I vårt användningsfall saknar transaktionerna som streamas till Confluent Cloud detaljerad information om kunder, förutom en customer_id. Däremot har vi en referensdatauppsättning i Amazon S3 som har mer information om kunderna. Med Athena kan vi sammanfoga båda dataseten för att få insikter om våra kunder. Se följande kod:
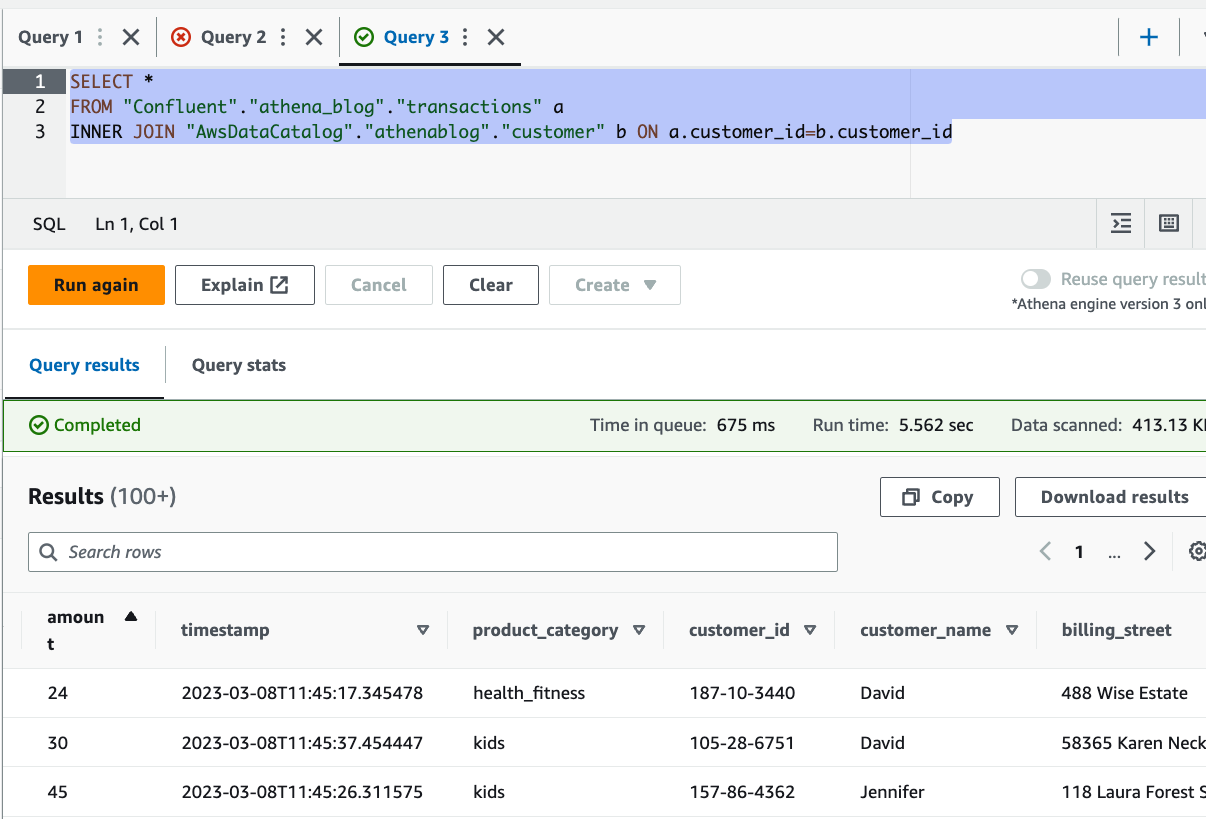
Du kan se från resultaten att vi kunde berika streamingdata med kunddetaljer, lagrade i Amazon S3, inklusive namn och adress.
Visualisera data med QuickSight
En annan kraftfull funktion som denna anslutning ger är möjligheten att visualisera data lagrad i Confluent med hjälp av vilket BI-verktyg som helst som stöder Athena som datakälla. I det här inlägget använder vi QuickSight. QuickSight är en maskininlärning (ML)-driven BI-tjänst byggd för molnet. Du kan använda den för att leverera lättförståeliga insikter till personerna du arbetar med, var de än befinner sig.
För mer information om hur du registrerar dig för QuickSight, se Registrera dig för en Amazon QuickSight-prenumeration.
Slutför följande steg för att visualisera din strömmande data med QuickSight:
- Välj på QuickSight-konsolen dataset i navigeringsfönstret.
- Välja Nytt datasätt.
- Välj Athena som datakälla.
- För Datakällans namn, ange ett namn.
- Välja Skapa datakälla.
- I Välj ditt bord avsnitt väljer Använd anpassad SQL.
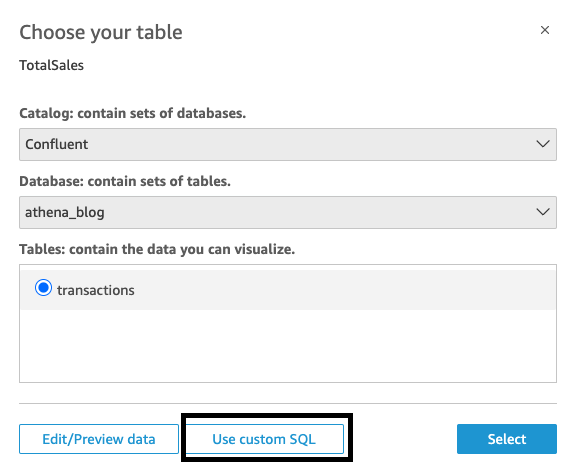
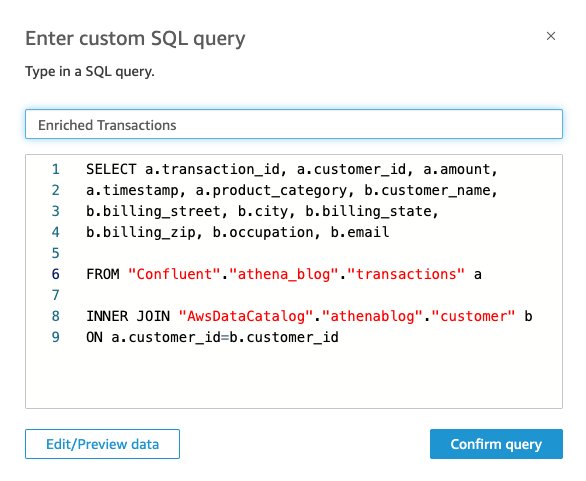
- Ange kopplingsfrågan som den som gavs tidigare och välj sedan Bekräfta frågan.
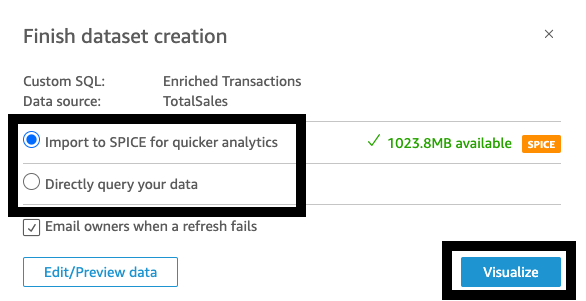
- Välj sedan att importera data till KRYDDA (Supersnabb, Parallell, In-Memory Calculation Engine), en fullständigt hanterad minnescache som ökar prestandan, eller fråga direkt efter data.
Användning av SPICE kommer att förbättra prestandan, men data kan behöva uppdateras med jämna mellanrum. Du kan välja att uppdatera din datauppsättning stegvis or schemalägg regelbundna uppdateringar med SPICE. Om du vill att data i nästan realtid ska återspeglas i dina instrumentpaneler väljer du Fråga din data direkt. Observera att med alternativet för direktfrågningar kan användaråtgärder i QuickSight, som att tillämpa ett detaljerat filter, anropa en ny Athena-fråga.
- Välja visualisera.
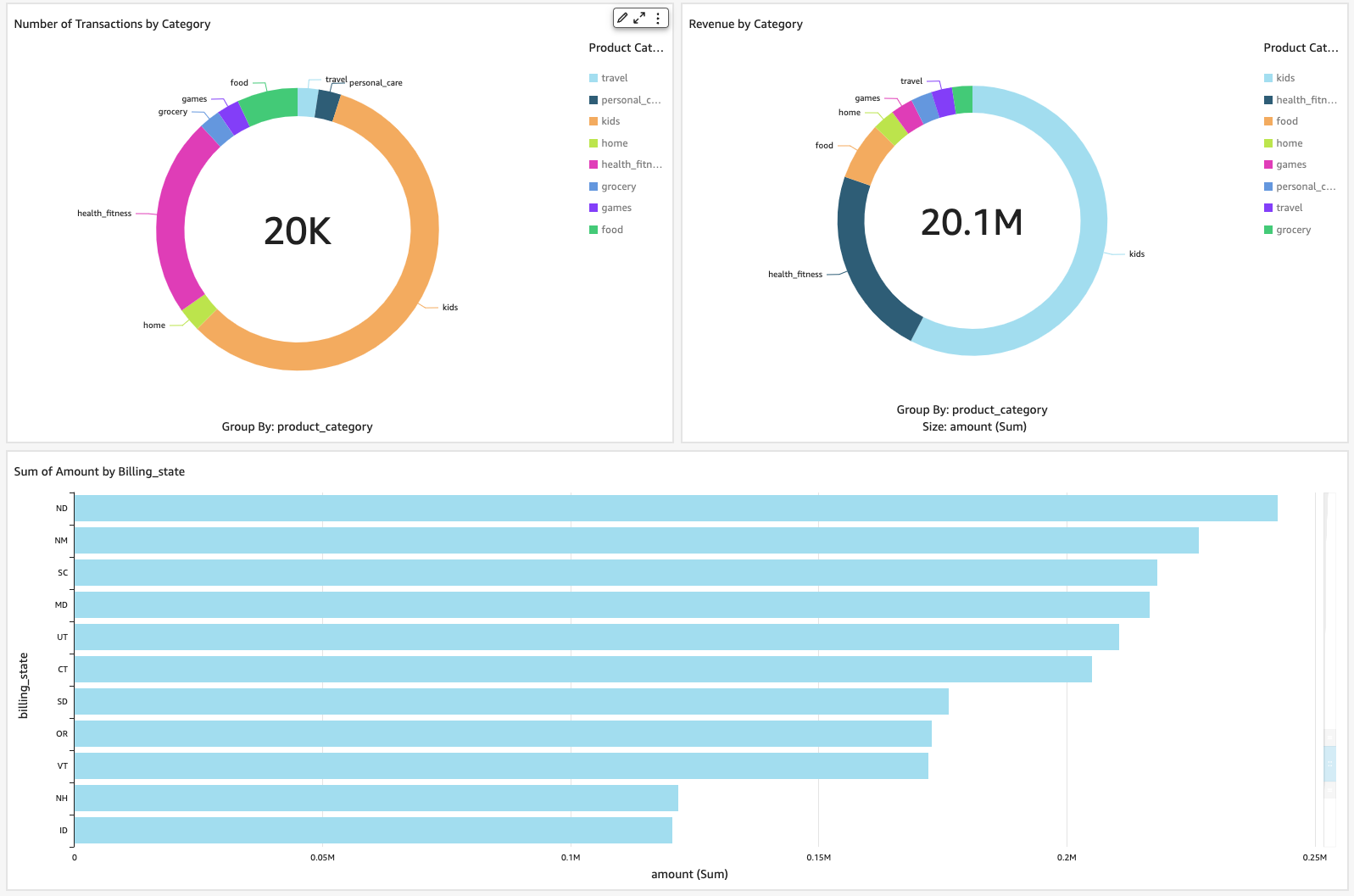
Det var allt, vi har framgångsrikt kopplat QuickSight till Confluent genom Athena. Med bara några klick kan du skapa några bilder som visar data från Confluent.
Städa upp
För att undvika att ådra sig pågående avgifter, radera de resurser du tillhandahållit genom att utföra följande steg:
- Ta bort AWS Glue-schemat och registret.
- Ta bort Athena Kafka-kontakten.
- Ta bort QuickSight-datauppsättningen.
Slutsats
I det här inlägget diskuterade vi användningsfall för Athena och Confluent. Vi gav exempel på hur du kan använda både för nästan realtidsdatavisualisering med QuickSight och interaktiv analys som involverar kopplingar mellan strömmande data i Confluent och data lagrad i Amazon S3.
Athena-kontakten för Kafka förenklar processen med att söka och analysera strömmande data från Confluent Cloud. Det tar bort behovet av att först flytta strömmande data till beständig lagring innan den kan användas i nedströms användningsfall som business intelligence. Detta kompletterar den befintliga integrationen mellan Confluent och Athena, med hjälp av S3 sink-kontakten, som möjliggör laddning av strömmande data i en datasjö, och är ett ytterligare alternativ för kunder som vill möjliggöra interaktiv analys av Confluent-data.
Om författarna
 Ahmed Zamzam är Senior Partner Solutions Architect på Confluent, med fokus på AWS-partnerskapet. I sin roll arbetar han med kunder i EMEA-regionen i olika branscher för att hjälpa dem att bygga applikationer som utnyttjar deras data med Confluent och AWS. Före Confluent var Ahmed en Specialist Solutions Architect för Analytics AWS specialiserad på dataströmning och sökning. På fritiden tycker Ahmed om att resa, spela tennis och cykla.
Ahmed Zamzam är Senior Partner Solutions Architect på Confluent, med fokus på AWS-partnerskapet. I sin roll arbetar han med kunder i EMEA-regionen i olika branscher för att hjälpa dem att bygga applikationer som utnyttjar deras data med Confluent och AWS. Före Confluent var Ahmed en Specialist Solutions Architect för Analytics AWS specialiserad på dataströmning och sökning. På fritiden tycker Ahmed om att resa, spela tennis och cykla.
 Geetha Anne är en Partner Solutions Engineer på Confluent med tidigare erfarenhet av att implementera lösningar för datadrivna affärsproblem i molnet, som involverar datalagring och realtidsströmningsanalys. Hon blev förälskad i distribuerad datoranvändning under sin grundutbildning och har följt hennes intresse sedan dess. Geetha tillhandahåller teknisk vägledning, designrådgivning och tankeledarskap till viktiga Confluent-kunder och partners. Hon tycker också om att lära ut komplexa tekniska koncept för både teknikkunniga och allmänna publiker.
Geetha Anne är en Partner Solutions Engineer på Confluent med tidigare erfarenhet av att implementera lösningar för datadrivna affärsproblem i molnet, som involverar datalagring och realtidsströmningsanalys. Hon blev förälskad i distribuerad datoranvändning under sin grundutbildning och har följt hennes intresse sedan dess. Geetha tillhandahåller teknisk vägledning, designrådgivning och tankeledarskap till viktiga Confluent-kunder och partners. Hon tycker också om att lära ut komplexa tekniska koncept för både teknikkunniga och allmänna publiker.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/visualize-confluent-data-in-amazon-quicksight-using-amazon-athena/
- :är
- $UPP
- 100
- 11
- 7
- 8
- 9
- a
- förmåga
- Able
- Om oss
- tillgång
- tillgänglig
- Enligt
- bekräfta
- tvärs
- åtgärder
- Dessutom
- Annat
- adress
- adresser
- Lägger
- rådgivning
- aggregation
- Alla
- tillåter
- redan
- alltid
- amason
- Amazonas Athena
- Amazon QuickSight
- mängd
- analys
- analytics
- analysera
- analys
- och
- meddelade
- Annan
- Apache
- Apache Kafka
- isär
- api
- app
- Ansökan
- tillämpningar
- Tillämpa
- tillvägagångssätt
- arkitektur
- ÄR
- AS
- bistå
- At
- målgrupper
- Autentisering
- tillgänglig
- undvika
- AWS
- AWS-lim
- BE
- blir
- innan
- börja
- mellan
- Bootstrap
- Bringar
- Byggnad
- byggt
- företag
- business intelligence
- företag
- by
- cache
- KAN
- Kan få
- Vid
- fall
- Kategori
- centrala
- utmaningar
- utmanande
- avgifter
- val
- Välja
- klienter
- cloud
- moln infödd
- kluster
- koda
- Företag
- Företagets
- fullborda
- fullborda
- komplex
- komplexiteter
- databehandling
- Begreppen
- Genomför
- Bekräfta
- Konfluenta
- Kontakta
- anslutna
- anslutning
- Anslutningar
- Konsol
- kontinuerligt
- konventionell
- Pris
- kunde
- land
- skapa
- skapas
- skapar
- beställnings
- kund
- Kunder
- datum
- datasjö
- datalagring
- datstrategi
- datavisualisering
- data driven
- datauppsättningar
- Dagar
- beslut
- definierade
- leverera
- demonstrera
- distribuera
- beskrivning
- Designa
- utformade
- destination
- detaljerad
- detaljer
- utveckla
- utvecklare
- utveckla
- rikta
- direkt
- diskuteras
- visning
- distribueras
- distribuerad databehandling
- inte
- under
- ansträngning
- EMEA
- möjliggöra
- möjliggör
- Motor
- ingenjör
- Ingenjörer
- Motorer
- berika
- ange
- företag
- Miljö
- väsentlig
- Eter (ETH)
- händelse
- händelser
- NÅGONSIN
- exempel
- exempel
- befintliga
- erfarenhet
- extern
- extrahera
- långt
- snabbare
- Leverans
- Funktioner
- få
- fält
- Fält
- fyllda
- filtrera
- filter
- hitta
- Förnamn
- Strömmande
- Fokus
- följt
- efter
- följer
- För
- Fri
- frekvent
- från
- fullständigt
- fungera
- funktioner
- ytterligare
- Få
- Allmänt
- skaffa sig
- ges
- Grupp
- Odling
- Gäst
- gäst inlägg
- vägleda
- Har
- högre
- höggradigt
- Hur ser din drömresa ut
- Men
- html
- http
- HTTPS
- IAM
- ID
- genomföra
- importera
- med Esport
- förbättra
- in
- innefattar
- Inklusive
- Ökar
- industrier
- informationen
- informeras
- Infrastruktur
- ingång
- insikter
- istället
- Integrera
- integrering
- Intelligens
- interaktiva
- intresse
- Internet
- IT
- DESS
- Lediga jobb
- delta
- Fogar
- jpg
- json
- kafka
- Nyckel
- nycklar
- barn
- känd
- Brist
- sjö
- språk
- Ledarskap
- inlärning
- Lämna
- Hävstång
- tycka om
- linje
- läsa in
- läser in
- älskar
- Maskinen
- maskininlärning
- gjord
- göra
- Framställning
- hantera
- förvaltade
- ledning
- chef
- hantera
- manuellt
- många
- kartläggning
- betyder
- mekanism
- meddelande
- ML
- modell
- mer
- rörelse
- flytta
- rörelse
- rörliga
- namn
- Som heter
- nativ
- Navigering
- Behöver
- behov
- nät
- Nya
- Nästa
- antal
- oauth
- of
- Erbjudanden
- on
- ONE
- pågående
- nätet
- online-transaktioner
- öppen källkod
- drift
- Verksamhet
- operatörer
- Alternativet
- Tillbehör
- beställa
- organisationer
- Övriga
- annat
- sida
- par
- panelen
- Parallell
- parameter
- partnern
- partner
- Partnerskap
- Lösenord
- Personer
- utföra
- prestanda
- Enkel
- planering
- plato
- Platon Data Intelligence
- PlatonData
- i
- Punkt
- Populära
- Inlägg
- den mäktigaste
- befogenheter
- föregående
- tidigare
- Innan
- privat
- problem
- process
- bearbetning
- producera
- producent
- Produkt
- Produktion
- protokoll
- ge
- förutsatt
- ger
- område
- redo
- realtid
- data i realtid
- Anledningen
- post
- minska
- reflekterad
- region
- registrera
- registrerat
- register
- regelbunden
- relaterad
- ersätta
- kräver
- Obligatorisk
- Krav
- Kräver
- resurs
- Resurser
- resultera
- Resultat
- avkastning
- tillbaka
- intäkter
- Roll
- roller
- Körning
- rinnande
- Samma
- skalbar
- Skala
- skript
- Sök
- Secret
- §
- säkra
- säkerhet
- semantik
- senior
- separat
- Server
- service
- Tjänster
- in
- inställningar
- skall
- signifikant
- signering
- Enkelt
- samtidigt
- eftersom
- lösning
- Lösningar
- några
- något
- Källa
- Källor
- specialist
- specialiserad
- specifik
- krydda
- SQL
- SSL
- standard
- Steg
- Steg
- Fortfarande
- förvaring
- lagra
- lagras
- Strategi
- ström
- strömmas
- streaming
- strömmar
- Sträng
- undernät
- Framgångsrikt
- sådana
- lämplig
- svit
- stödja
- Som stöds
- Stöder
- system
- bord
- Undervisning
- Teknisk
- tennis
- testa
- den där
- Smakämnen
- källan
- deras
- Dem
- Där.
- därför
- Dessa
- trodde
- tanke ledarskap
- tre
- Genom
- tid
- tidsstämpel
- till
- tillsammans
- verktyg
- verktyg
- ämne
- ämnen
- transaktion
- Transaktioner
- transformationer
- Traveling
- typisk
- ui
- Uk
- unika
- uppdaterad
- URL
- us
- användning
- användningsfall
- Användare
- användare
- utnyttjas
- olika
- visningar
- visualisering
- visualisera
- Lagring
- VÄL
- som
- VEM
- brett
- bredare
- kommer
- med
- inom
- utan
- Arbete
- jobba tillsammans
- arbetsflöde
- fungerar
- skulle
- skriva
- skrivning
- skriven
- Din
- zephyrnet