Kära läsare,
I den här bloggen kommer jag att diskutera chunking både teoretiskt och praktiskt i Python.
Så, låt oss börja...
OBS: För implementeringen är det bättre att använda Python IDLE eftersom utgången är en ritning av ett träd som dyker upp i ett separat fönster.
agenda
- Vad är chunking?
- Var används chunking?
- Typer av chunking
- Implementering av chunking i Python
- Resultat
Vad är chunking?
Chunking definieras som den process av naturligt språkbehandling som används för att identifiera delar av tal och korta fraser som finns i en given mening.
När vi minns våra gamla goda engelska grammatikklasser i skolan, notera att det finns åtta orddelar, nämligen substantivet, verbet, adjektivet, adverbet, prepositionen, konjunktionen, pronomenet och interjektionen. I ovanstående definition av chunking hänvisar korta fraser också till de fraser som bildas genom att inkludera någon av dessa delar av tal.
Till exempel kan chunking göras för att identifiera och därmed gruppera substantivfraser eller enbart substantiv, adjektiv eller adjektivfraser och så vidare. Tänk på meningen nedan:
“Jag hade hamburgare och bakverk till frukost.”
I det här fallet, om vi vill gruppera eller dela substantivfraser, får vi "burgare", "bakelser" och "lunch" som är substantiven eller substantivgrupperna i meningen.
Var används chunking?
Varför skulle vi vilja lära oss något utan att veta var det används allmänt?! Att titta på applikationerna som diskuteras i det här avsnittet av bloggen hjälper dig att hålla dig nyfiken till slutet!
Chunking används för att få de nödvändiga fraserna från en given mening. Däremot kan POS-taggning endast användas för att upptäcka de delar av tal som varje ord i meningen tillhör.
När vi har massor av beskrivningar eller modifieringar kring ett visst ord eller frasen av vårt intresse, använder vi chunking för att ta tag i den önskade frasen ensam, och ignorerar resten runt den. Därför banar chunking ett sätt att gruppera de nödvändiga fraserna och utesluta alla modifierare runt dem som inte är nödvändiga för vår analys. Sammanfattningsvis hjälper chunking oss att extrahera de viktiga orden ensamma från långa beskrivningar. Således är chunking ett steg i informationsutvinning.
Intressant nog utvidgas denna process av chunking i NLP till olika andra applikationer; till exempel att gruppera frukter av en specifik kategori, säg, frukter rika på proteiner som en grupp, frukter rika på vitaminer som en annan grupp, och så vidare. Dessutom kan chunking också användas för att gruppera liknande bilar, säg, bilar som stöder automatisk växel i en grupp och de andra som stöder manuell växel i en annan del och så vidare.
Typer av chunking
Det finns i stort sett två typer av chunking:
- Klumpar ihop
- Klumpar ner
Klumpar ihop:
Här dyker vi inte djupt; istället är vi nöjda med bara en översikt över informationen. Det hjälper oss bara att få en kort uppfattning om de givna uppgifterna.
Klipp ner:
Till skillnad från den tidigare typen av chunking hjälper chunking oss att få detaljerad information.
Så om du bara vill ha en insikt, överväg att "chunka upp" annars föredrar "chunking down".
Implementering av chunking i Python
Föreställ dig en situation där du vill extrahera alla verb från den givna texten för din analys. Så i det här fallet måste vi överväga delning av verbfraser. Detta beror på att vårt mål är att extrahera alla verbfraser från den givna texten. Chunking görs med hjälp av reguljära uttryck.
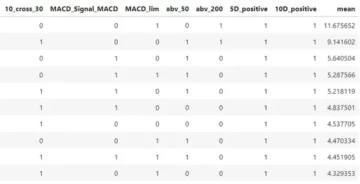
Oroa dig inte om det är första gången du stöter på termen "vanliga uttryck". Tabellen nedan är här, till din räddning:
|
|
|
|
|
|
|
|
|
|
|
|
Tabellen ovan innehåller de vanligaste reguljära uttrycken som används. Reguljära uttryck är mycket användbara på kommandoraden, särskilt när du tar bort, lokaliserar, byter namn på eller flyttar filer.
Hur som helst, för den här implementeringen kommer vi bara att använda *. Titta gärna på tabellen ovan för att bekanta dig med symbolen!
Vi kommer att utföra chunking med nltk, det mest populära NLP-biblioteket. Så låt oss först importera det.
importera nltk
Låt oss överväga exempeltexten nedan som jag skapade på egen hand. Ersätt gärna nedanstående med valfri exempeltext du vill implementera chunking!
sample_text=""" Rama dödade Ravana för att rädda Sita från Lanka. Legenden om Ramayan är det mest populära indiska eposet. Många filmer och serier har redan spelats in på flera språk här i Indien baserat på Ramayana. """
Uppenbarligen måste uppgifterna satssymboliseras och sedan ordsymboliseras innan vi fortsätter. Tokenisering är inget annat än processen att bryta ner den givna textbiten i mindre enheter såsom meningar, vid meningstokenisering och ord, vid ordtokenisering.
Följt av tokenisering görs POS-taggning (part-of-speech) för varje ord, där orddelen för varje ord kommer att identifieras. Nu är vi bara intresserade av verbet del av tal och vill extrahera detsamma.
Ange därför den del av ordet som vi är intresserade av med det obligatoriska reguljära uttrycket enligt följande:
VB: {}
tokenized=nltk.sent_tokenize(sample_text) för mig i tokenized: words=nltk.word_tokenize(i) # print(words) tagged_words=nltk.pos_tag(words) # print(tagged_words) chunkGram=r"""VB: {}" "" chunkParser=nltk.RegexpParser(chunkGram) chunked=chunkParser.parse(tagged_words) chunked.draw()
Det reguljära uttrycket(RE) omges av vinkelparenteser() som i sin tur är inneslutna inom parenteser({ och }).
OBS: Ange RE enligt önskad POS
VB står för verbet POS. Punkten som efterföljer VB betyder att matcha vilket tecken som helst efter VB. Frågetecknet efter punkten anger att ett tecken efter B endast får förekomma en gång eller inte får förekomma alls. Men från tabellen som vi såg tidigare är denna karaktär valfri. Vi har ramat in det reguljära uttrycket på detta sätt eftersom verbfraser i NLTK inkluderar följande POS-taggar:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Således kan verbfraser tillhöra någon av ovanstående POS. Det är därför det reguljära uttrycket ramas in som VB.? som inkluderar alla ovanstående kategorier. RegexpParser-paketet används för att kontrollera om en POS uppfyller vårt erforderliga mönster som vi har nämnt med RE tidigare.
Hela koden kan ses på följande sätt:
import nltk nltk.download('averaged_perceptron_tagger') sample_text=""" Rama dödade Ravana för att rädda Sita från Lanka. Legenden om Ramayan är det mest populära indiska eposet. Många filmer och serier har redan spelats in på flera språk här i Indien baserat på Ramayana. """ tokenized=nltk.sent_tokenize(sample_text) för i i tokenized: words=nltk.word_tokenize(i) # print(words) tagged_words=nltk.pos_tag(words) # print(tagged_words) chunkGram =r"""VB: {}""" chunkParser=nltk.RegexpParser(chunkGram) chunked=chunkParser.parse(tagged_words) chunked.draw()
Resultat


Slutligen får vi en trädform av ordens POS tillsammans med orden vars POS matchar den givna RE. Ögonblicksbilden av utdata som erhållits för exempeltexten som vi skickat kan ses i ovanstående figurer.
Observera att de ord som uppfyller vår RE endast för verbfraser är tydligt markerade i utmatningen. Därför har chunking av verbfraser utförts framgångsrikt.
Hoppas du tyckte att min artikel var användbar.
Tack!
Referensprojekt
1. Implementering av chunking i Python
3. Fullständig lista över POS tillgängliga i NLP
om mig
Jag är Nithyashree V, en sista året BTech Data Science and Engineering-student. Jag älskar att lära mig så coola tekniker och omsätta dem i praktiken, särskilt att observera hur de hjälper oss att lösa samhällets utmanande problem. Mina intresseområden inkluderar artificiell intelligens, datavetenskap och naturlig språkbehandling.
Här är min LinkedIn-profil: Min LinkedIn
Du kan läsa mina andra artiklar om Analytics Vidhya från här..
Källa: https://www.analyticsvidhya.com/blog/2021/10/what-is-chunking-in-natural-language-processing/
- "
- 7
- Alla
- analys
- analytics
- tillämpningar
- runt
- Artikeln
- artiklar
- artificiell intelligens
- Blogg
- Frukost
- bilar
- koda
- kommande
- Gemensam
- Datavetenskap
- datum
- datavetenskap
- Teknik
- Engelska
- extraktion
- Förnamn
- första gången
- formen
- Fri
- Gear
- god
- ta
- Grammatik
- Grupp
- här.
- Markerad
- Hur ser din drömresa ut
- HTTPS
- Tanken
- identifiera
- Inklusive
- indien
- informationen
- information utvinning
- Intelligens
- intresse
- IT
- språk
- Språk
- LÄRA SIG
- inlärning
- Bibliotek
- linje
- Lista
- älskar
- markera
- Match
- Media
- Mest populär
- Filmer
- nämligen
- Naturligt språk
- Naturlig språkbehandling
- nlp
- Övriga
- Övrigt
- Mönster
- fraser
- Populära
- PoS
- presentera
- Profil
- Python
- RE
- läsare
- REST
- Skola
- Vetenskap
- Kort
- Snapshot
- So
- LÖSA
- Spot
- bo
- student
- stödja
- Tekniken
- tid
- tokenization
- us
- Vad är
- inom
- ord
- år
- noll-