องค์กรต่างๆ ใช้ข้อมูลของตนเพื่อแก้ปัญหาที่ซับซ้อนโดยเริ่มต้นเล็กๆ ทำการทดลองซ้ำๆ และปรับปรุงโซลูชัน แม้ว่าจะมองข้ามพลังของการทดสอบไม่ได้ แต่องค์กรต่างๆ ก็ต้องระมัดระวังเกี่ยวกับความคุ้มค่าของการทดลองดังกล่าว หากใช้เวลาไปกับการสร้างโครงสร้างพื้นฐานสำหรับการเปิดใช้งานการทดสอบ ก็ยิ่งเพิ่มต้นทุนเข้าไปอีก
นักพัฒนาต้องการสภาพแวดล้อมการพัฒนาแบบบูรณาการ (IDE) สำหรับการสำรวจข้อมูลและการดีบักเวิร์กโฟลว์ และโปรไฟล์การคำนวณที่แตกต่างกันสำหรับการเรียกใช้เวิร์กโฟลว์เหล่านี้ ถ้าคุณเลือก อเมซอน EMR สำหรับกรณีการใช้งานดังกล่าว คุณสามารถใช้ IDE ที่เรียกว่า อเมซอน EMR สตูดิโอ สำหรับการสำรวจข้อมูล การแปลง การควบคุมเวอร์ชัน และการดีบัก และเรียกใช้งาน Spark เพื่อประมวลผลข้อมูลจำนวนมาก กำลังปรับใช้ Amazon EMR บน Amazon EKS ลดความซับซ้อนในการจัดการ ลดต้นทุน และปรับปรุงประสิทธิภาพ อย่างไรก็ตาม วิศวกรข้อมูลหรือผู้ดูแลระบบไอทีต้องใช้เวลาในการสร้างโครงสร้างพื้นฐาน กำหนดค่าความปลอดภัย และสร้างปลายทางที่มีการจัดการเพื่อให้ผู้ใช้เชื่อมต่อ ซึ่งหมายความว่าโครงการดังกล่าวต้องรอจนกว่าผู้เชี่ยวชาญเหล่านี้จะสร้างโครงสร้างพื้นฐาน
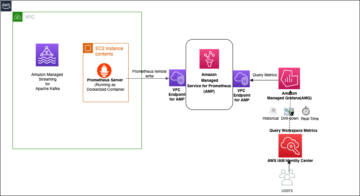
ในโพสต์นี้ เราจะแสดงวิธีที่วิศวกรข้อมูลหรือผู้ดูแลระบบไอทีสามารถใช้ สถาปัตยกรรมอ้างอิง AWS Analytics (ARA) เพื่อเร่งการปรับใช้โครงสร้างพื้นฐาน ช่วยให้องค์กรของคุณประหยัดทั้งเวลาและเงินที่ใช้ในการทดลองวิเคราะห์ข้อมูลเหล่านี้ เราใช้ห้องสมุดเพื่อปรับใช้ Amazon Elastic Kubernetes คลัสเตอร์ (Amazon EKS) กำหนดค่าให้ใช้ Amazon EMR บน EKS และปรับใช้ คลัสเตอร์เสมือน และปลายทางที่มีการจัดการและ EMR Studio จากนั้น คุณสามารถเรียกใช้งานบนคลัสเตอร์เสมือนหรือเรียกใช้การวิเคราะห์ข้อมูลเชิงสำรวจด้วย โน๊ตบุ๊ค Jupyter บน Amazon EMR Studio และ Amazon EMR บน EKS สถาปัตยกรรมด้านล่างแสดงถึงโครงสร้างพื้นฐานที่คุณจะปรับใช้กับสถาปัตยกรรมอ้างอิง AWS Analytics

เบื้องต้น
ในการปฏิบัติตาม คุณต้องมีบัญชี AWS ที่บู๊ตด้วย ชุดพัฒนา AWS Cloud (AWS CDK) สำหรับคำแนะนำ โปรดดูที่ ร่วมมือ. บทช่วยสอนต่อไปนี้ใช้ TypeScript และต้องใช้ AWS CDK เวอร์ชัน 2 หรือใหม่กว่า หากคุณไม่ได้ติดตั้ง AWS CDK โปรดดูที่ ติดตั้ง AWS CDK.
ตั้งค่าโครงการ AWS CDK
ในการปรับใช้ทรัพยากรโดยใช้ ARA คุณต้องตั้งค่าโครงการ AWS CDK และติดตั้งไลบรารี ARA ก่อน ทำตามขั้นตอนต่อไปนี้:
- สร้างโฟลเดอร์ชื่อ emr-eks-app:
- เริ่มต้นโครงการ AWS CDK ในไดเร็กทอรีว่างและเรียกใช้คำสั่งต่อไปนี้:
- ติดตั้งไลบรารี ARA:
- ใน lib/emr-eks-app.ts ให้อิมพอร์ตไลบรารี ARA ดังนี้ บรรทัดแรกเรียกไลบรารี ARA บรรทัดที่สองกำหนดนโยบาย AWS Identity and Access Management (IAM):
สร้างและกำหนดคลัสเตอร์ EKS และความสามารถในการคำนวณ
เพื่อสร้าง EMR บน EKS คลัสเตอร์เสมือนคุณต้องปรับใช้คลัสเตอร์ EKS ก่อน ไลบรารี ARA กำหนดโครงสร้างที่เรียกว่า EmrEksCluster. โครงสร้างจัดเตรียมคลัสเตอร์ EKS เปิดใช้งาน บทบาท IAM สำหรับบัญชีบริการและปรับใช้ชุดของตัวควบคุมที่รองรับ เช่น ตัวควบคุมตัวจัดการใบรับรอง (จำเป็นสำหรับตำแหน่งข้อมูลที่มีการจัดการซึ่งใช้โดย Amazon EMR Studio) รวมถึงตัวปรับขนาดอัตโนมัติของคลัสเตอร์เพื่อให้มีคลัสเตอร์ที่ยืดหยุ่นและประหยัดค่าใช้จ่ายเมื่อไม่มีงานถูกส่งไปยังคลัสเตอร์ .
In lib/emr-eks-app.tsให้เพิ่มบรรทัดต่อไปนี้:
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับคุณสมบัติที่คุณสามารถปรับแต่งได้ โปรดดูที่ EmrEksClusterProps. มีสองพารามิเตอร์บังคับใน EmrEksCluster สร้าง: อย่างแรกคือ eksAdminRoleArn บทบาทเป็นข้อบังคับและเป็นบทบาทที่คุณใช้เพื่อโต้ตอบกับ Kubernetes controlplane บทบาทนี้ต้องมีสิทธิ์ระดับผู้ดูแล สร้างหรืออัปเดตคลัสเตอร์. พารามิเตอร์ที่สองคือ autoscalingพารามิเตอร์นี้ให้คุณเลือกกลไกการปรับขนาดอัตโนมัติได้เช่นกัน คาร์เพนเตอร์ or Kubernetes Cluster Autoscaler ดั้งเดิม. ในบล็อกนี้ เราจะใช้ Karpenter และเราแนะนำให้ใช้เนื่องจากการปรับขนาดอัตโนมัติที่เร็วขึ้น การจัดการโหนดและการจัดเตรียมที่ง่ายขึ้น ตอนนี้คุณพร้อมที่จะกำหนดความสามารถในการคำนวณแล้ว
วิธีหนึ่งในการกำหนดโหนดของผู้ปฏิบัติงานใน Amazon EKS คือการใช้กลุ่มโหนดที่ได้รับการจัดการ เราใช้กลุ่มโหนดหนึ่งที่เรียกว่า toolingซึ่งเป็นเจ้าภาพ แกนกลาง, ตัวควบคุมทางเข้า, ผู้จัดการใบรับรอง, คาร์เพนเตอร์ และพ็อดอื่นๆ ที่จำเป็นสำหรับการรัน EMR ในงาน EKS หรือ ManagedEndpoint เรายังกำหนดค่าเริ่มต้น Karpenter ผู้จัดเตรียม ที่กำหนดความสามารถที่จะใช้สำหรับงานที่ส่งโดย EMR บน EKS ผู้จัดเตรียมเหล่านี้ได้รับการปรับให้เหมาะสมสำหรับกรณีการใช้งาน Spark ที่แตกต่างกัน (งานสำคัญ งานไม่สำคัญ งานทดลอง และงานโต้ตอบ). โครงสร้างยังช่วยให้คุณส่งตัวจัดสรรของคุณเองที่กำหนดโดยรายการ Kubernetes ผ่านวิธีการที่เรียกว่า addKarpenterProvisioner. เรามาหารือเกี่ยวกับผู้จัดเตรียมที่กำหนดไว้ล่วงหน้า
การกำหนดค่า Default Provisioners
ตัวจัดเตรียมเริ่มต้นถูกตั้งค่าไว้สำหรับการทดสอบอย่างรวดเร็วและเป็น สร้างขึ้นโดยค่าเริ่มต้นเสมอ. อย่างไรก็ตาม หากคุณไม่ต้องการใช้ คุณสามารถตั้งค่า defaultNodeGroups พารามิเตอร์ false ใน EmrEksCluster คุณสมบัติในขณะที่สร้าง ผู้จัดเตรียมได้รับการกำหนดดังต่อไปนี้และสร้างขึ้นในแต่ละซับเน็ตที่ Amazon EKS ใช้:
- ผู้จัดเตรียมที่สำคัญ – ทุ่มเทให้กับการสนับสนุนงานที่มี SLA เชิงรุกและมีความละเอียดอ่อนด้านเวลา ผู้จัดเตรียมใช้อินสแตนซ์ตามความต้องการซึ่งไม่ได้หยุดทำงาน ซึ่งแตกต่างจากอินสแตนซ์ Spot และวงจรชีวิตของอินสแตนซ์จะดำเนินต่อไปตามงานใดงานหนึ่ง โหนดใช้ที่จัดเก็บอินสแตนซ์ซึ่งเป็นดิสก์ NVMe ที่ต่อกับโฮสต์ ซึ่งให้ปริมาณงาน I/O สูงที่ช่วยให้ประสิทธิภาพของ Spark ดีขึ้น เนื่องจากใช้เป็นที่เก็บข้อมูลชั่วคราวสำหรับการรั่วไหลของดิสก์และการสับเปลี่ยน ประเภทอินสแตนซ์ที่ใช้ในโหนดเป็นตระกูล m6gd อินสแตนซ์ใช้ AWS กราวิตอน โปรเซสเซอร์ซึ่งนำเสนอ ราคา/ประสิทธิภาพที่ดีกว่าโปรเซสเซอร์ x86. หากต้องการใช้ตัวจัดเตรียมนี้ในงานของคุณ คุณสามารถใช้สิ่งต่อไปนี้ การกำหนดค่าตัวอย่างซึ่งอ้างถึงใน การแทนที่การกำหนดค่า ของ EMR ในการส่งงาน EKS
- ผู้จัดเตรียมที่ไม่สำคัญ – ผู้จัดเตรียมนี้ใช้ประโยชน์จากอินสแตนซ์ Spot เพื่อประหยัดค่าใช้จ่ายสำหรับงานที่ไม่คำนึงถึงเวลาหรืองานที่ใช้สำหรับการทดลอง โหนดนี้ใช้อินสแตนซ์ Spot เนื่องจากงานไม่สำคัญและสามารถขัดจังหวะได้ อินสแตนซ์เหล่านี้สามารถหยุดได้หากเรียกคืนอินสแตนซ์ ประเภทอินสแตนซ์ที่ใช้ในโหนดเป็นตระกูล m6gd ไดรเวอร์เป็นแบบ On-Demand และตัวดำเนินการอยู่ในอินสแตนซ์สปอต
- ตัวจัดเตรียมโน้ตบุ๊ก – ตัวจัดเตรียมมีไว้สำหรับการเรียกใช้ตำแหน่งข้อมูลที่มีการจัดการซึ่งใช้โดย Amazon EMR Studio สำหรับการสำรวจข้อมูลโดยใช้ Amazon EMR บน EKS อินสแตนซ์เป็นของตระกูล t3 และเป็นอินสแตนซ์ตามความต้องการสำหรับไดรเวอร์และอินสแตนซ์ Spot สำหรับตัวดำเนินการเพื่อให้ต้นทุนต่ำ หากอินสแตนซ์ตัวดำเนินการหยุดทำงาน Karpenter จะเริ่มต้นใหม่ หากอินสแตนซ์ตัวดำเนินการหยุดทำงานบ่อยเกินไป คุณสามารถกำหนดอินสแตนซ์ของคุณเองได้โดยใช้อินสแตนซ์แบบออนดีมานด์
ดังต่อไปนี้ ลิงค์ ให้รายละเอียดเพิ่มเติมเกี่ยวกับวิธีกำหนดผู้จัดเตรียมแต่ละราย คุณสมบัตินำเข้าหนึ่งรายการที่กำหนดไว้ใน Provisioners เริ่มต้นคือมีหนึ่งรายการสำหรับแต่ละ AZ สิ่งนี้มีความสำคัญเนื่องจากช่วยให้คุณลดต้นทุนการถ่ายโอนเครือข่ายระหว่าง AZ เมื่อ Spark เรียกใช้การสับเปลี่ยน
สำหรับโพสต์นี้ เราใช้ Provisioners เริ่มต้น ดังนั้นคุณไม่จำเป็นต้องเพิ่มบรรทัดโค้ดใดๆ สำหรับส่วนนี้ หากคุณต้องการเพิ่ม Provisioners ของคุณเอง คุณสามารถใช้วิธีนี้ได้ addKarpenterProvisioner เพื่อใช้รายการของคุณเอง คุณสามารถใช้วิธีตัวช่วยใน Utils ชั้นชอบ readYamlDocument เพื่ออ่านเอกสาร YAML และ loadYaml โหลดไฟล์ YAML และส่งต่อเป็นอาร์กิวเมนต์ addKarpenterProvisioner วิธี
ปรับใช้คลัสเตอร์เสมือนและบทบาทการดำเนินการ
คลัสเตอร์เสมือนคือเนมสเปซ Kubernetes ที่ Amazon EMR ลงทะเบียนด้วย เมื่อคุณส่งงาน พ็อดไดรเวอร์และตัวเรียกใช้งานจะทำงานอยู่ในเนมสเปซที่เกี่ยวข้อง เดอะ EmrEksCluster สร้างเสนอวิธีการที่เรียกว่า addEmrVirtualClusterซึ่งสร้างคลัสเตอร์เสมือนให้กับคุณ วิธีการใช้เวลา EmrVirtualClusterOptions เป็นพารามิเตอร์ซึ่งมีแอตทริบิวต์ดังต่อไปนี้:
- ชื่อ – ชื่อคลัสเตอร์เสมือนของคุณ
- สร้างเนมสเปซ – ฟิลด์ทางเลือกที่สร้างเนมสเปซ EKS นี่เป็นประเภทบูลีนและโดยค่าเริ่มต้นจะไม่สร้างเนมสเปซ EKS แยกต่างหาก ดังนั้นคลัสเตอร์เสมือนของคุณจึงถูกสร้างขึ้นในเนมสเปซเริ่มต้น
- eksNamespace – ชื่อของเนมสเปซ EKS ที่จะเชื่อมโยงกับคลัสเตอร์ EMR เสมือน หากไม่มีการกำหนดเนมสเปซ โครงสร้างจะใช้เนมสเปซเริ่มต้น
- In
lib/emr-eks-app.tsเพิ่มบรรทัดต่อไปนี้เพื่อสร้างคลัสเตอร์เสมือนของคุณ:ตอนนี้เราสร้างบทบาทการดำเนินการ ซึ่งเป็นบทบาท IAM ที่ไดรเวอร์และผู้ดำเนินการใช้เพื่อโต้ตอบกับบริการของ AWS ก่อนที่เราจะสร้างบทบาทการดำเนินการสำหรับ Amazon EMR ได้ เราต้องสร้างก่อน
ManagedPolicy. โปรดทราบว่าในโค้ดต่อไปนี้ เราสร้างนโยบายเพื่ออนุญาตให้เข้าถึงบัคเก็ต Amazon Simple Storage Service (Amazon S3) และบันทึกของ Amazon CloudWatch - In
lib/emr-eks-app.tsเพิ่มบรรทัดต่อไปนี้เพื่อสร้างนโยบาย:หากคุณต้องการใช้ AWS Glue Data Catalog ให้เพิ่มสิทธิ์ในนโยบายก่อนหน้านี้
ตอนนี้ เราสร้างบทบาทการดำเนินการสำหรับ Amazon EMR บน EKS โดยใช้นโยบายที่กำหนดไว้ในขั้นตอนที่แล้วโดยใช้
createExecutionRoleวิธีการเช่น พ็อดไดรเวอร์และเอ็กซีคิวเตอร์สามารถรับบทบาทนี้เพื่อเข้าถึงและประมวลผลข้อมูล บทบาทถูกกำหนดขอบเขตในลักษณะที่เฉพาะพ็อดในเนมสเปซคลัสเตอร์เสมือนเท่านั้นที่สามารถรับได้ หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับเงื่อนไขที่ใช้โดยวิธีนี้เพื่อจำกัดการเข้าถึงบทบาทเฉพาะพ็อดที่สร้างโดย Amazon EMR บน EKS ในเนมสเปซของคลัสเตอร์เสมือน โปรดดูที่การใช้บทบาทการดำเนินการกับ Amazon EMR บน EKS - In
lib/emr-eks-app.tsเพิ่มบรรทัดต่อไปนี้เพื่อสร้างบทบาทการดำเนินการ:รหัสก่อนหน้าสร้างบทบาท IAM ที่เรียกว่า
execRoleJobด้วยนโยบาย IAM ที่กำหนดไว้ในemrekspolicyและกำหนดขอบเขตไปที่เนมสเปซdataanalysis. - สุดท้าย เราส่งออกพารามิเตอร์ที่สำคัญสำหรับการรันงาน:
ปรับใช้ Amazon EMR Studio และจัดเตรียมผู้ใช้
ในการปรับใช้ EMR Studio สำหรับการสำรวจข้อมูลและการเขียนงาน ไลบรารี ARA จะมีโครงสร้างที่เรียกว่า NotebookPlatform. โครงสร้างนี้ทำให้คุณสามารถปรับใช้ EMR Studios ได้มากเท่าที่คุณต้องการ (ภายในขีดจำกัดของบัญชี) และตั้งค่าด้วยโหมดการรับรองความถูกต้องที่เหมาะกับคุณและกำหนดผู้ใช้ให้กับพวกเขา หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับโหมดการรับรองความถูกต้องที่มีใน Amazon EMR Studio โปรดดูที่ เลือกโหมดการรับรองความถูกต้องสำหรับ Amazon EMR Studio.
โครงสร้างสร้างบทบาทและนโยบาย IAM ที่จำเป็นทั้งหมดที่ Amazon EMR Studio ต้องการ นอกจากนี้ยังสร้างบัคเก็ต S3 ที่ Amazon EMR Studio จัดเก็บโน้ตบุ๊กทั้งหมด ที่เก็บข้อมูลถูกเข้ารหัสด้วย คีย์ที่จัดการโดยลูกค้า (CMK) ที่สร้างโดย AWS CDK stack ขั้นตอนต่อไปนี้แสดงวิธีสร้าง EMR Studio ของคุณเองด้วยโครงสร้าง
ต้องใช้โครงสร้างแพลตฟอร์มโน้ตบุ๊ก NotebookPlatformProps เป็นคุณสมบัติ ซึ่งอนุญาตให้คุณกำหนด EMR Studio, เนมสเปซ, ชื่อของ EMR Studio และโหมดการรับรองความถูกต้อง
- In
lib/emr-eks-app.tsให้เพิ่มบรรทัดต่อไปนี้:สำหรับโพสต์นี้ เราใช้ผู้ใช้ IAM เพื่อให้คุณทำซ้ำได้อย่างง่ายดายในบัญชีของคุณเอง อย่างไรก็ตาม หากคุณมี IAM federation หรือ single sign-on (SSO) อยู่แล้ว คุณสามารถใช้แทนผู้ใช้ IAM หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับพารามิเตอร์ของ
NotebookPlatformProps, เอ่ยถึง อุปกรณ์ประกอบฉากแพลตฟอร์มโน้ตบุ๊ก.ต่อไป เราต้องสร้างและกำหนดผู้ใช้ให้กับ Amazon EMR Studio สำหรับสิ่งนี้ โครงสร้างมีเมธอดที่เรียกว่า
addUserที่รับรายชื่อผู้ใช้และกำหนดให้กับ Amazon EMR Studio ในกรณีของ SSO หรืออัปเดตนโยบาย IAM เพื่ออนุญาตการเข้าถึง Amazon EMR Studio สำหรับผู้ใช้ IAM ที่ให้มา ผู้ใช้ยังสามารถมีปลายทางที่มีการจัดการได้หลายจุด และผู้ใช้แต่ละคนสามารถกำหนดเวอร์ชัน Amazon EMR ของตนได้ พวกเขาสามารถใช้ชุดอินสแตนซ์ Amazon Elastic Compute Cloud (Amazon EC2) ที่แตกต่างกันและสิทธิ์ที่แตกต่างกันโดยใช้บทบาทการปฏิบัติงาน - In
lib/emr-eks-app.tsให้เพิ่มบรรทัดต่อไปนี้:ในโค้ดก่อนหน้านี้ เพื่อความกระชับ เราใช้นโยบาย IAM เดิมที่เราสร้างขึ้นในบทบาทการดำเนินการอีกครั้ง
โปรดทราบว่าโครงสร้างจะปรับจำนวนจุดสิ้นสุดที่มีการจัดการที่สร้างขึ้นอย่างเหมาะสม หากปลายทางสองรายการมีชื่อเหมือนกัน ระบบจะสร้างเพียงรายการเดียว
- ตอนนี้เราได้กำหนดการปรับใช้ของเราแล้ว เราสามารถปรับใช้ได้:
คุณสามารถค้นหาโครงการตัวอย่างที่มีขั้นตอนทั้งหมดของการดำเนินการใน GitHub ต่อไปนี้ กรุ.
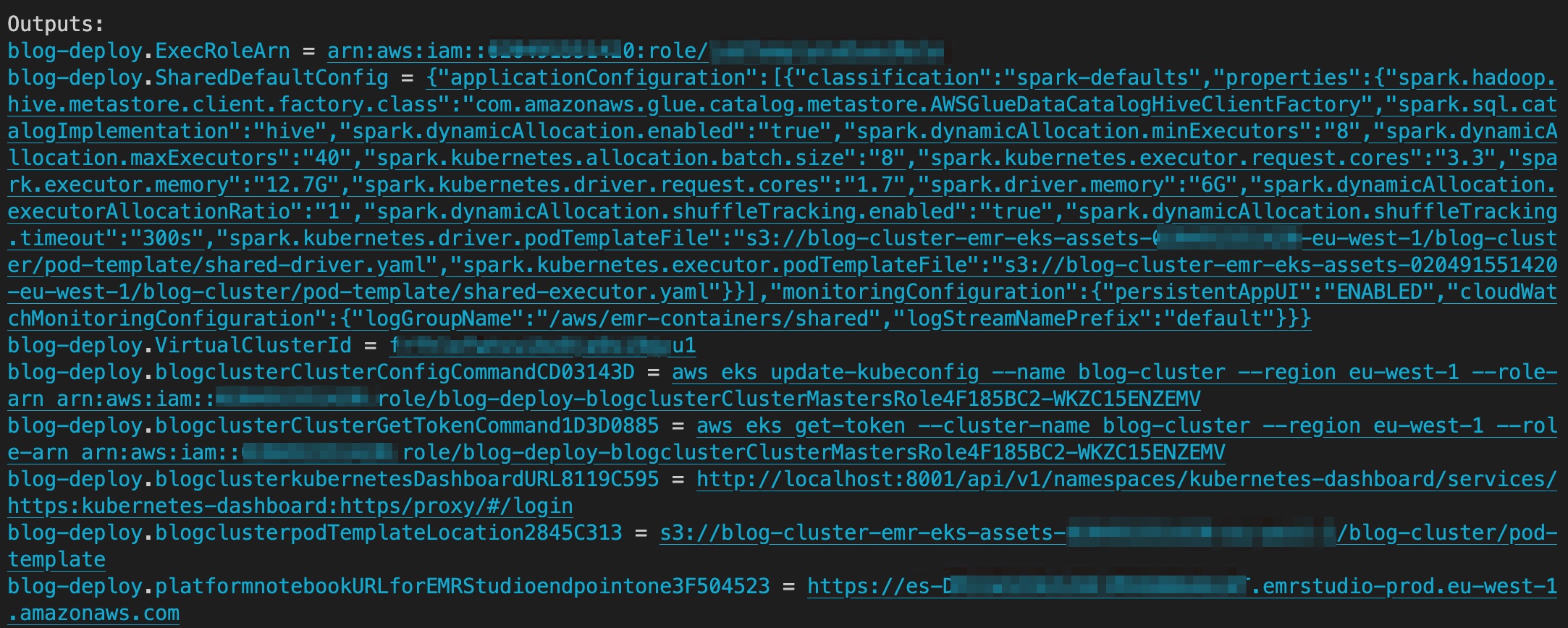
เมื่อการปรับใช้เสร็จสิ้น เอาต์พุตจะมีบัคเก็ต S3 ที่มีเนื้อหาสำหรับ podTemplateลิงก์สำหรับ EMR Studio และรหัสคลัสเตอร์เสมือน EMR Studio ภาพหน้าจอต่อไปนี้แสดงเอาต์พุตของ AWS CDK หลังจากการปรับใช้เสร็จสมบูรณ์
ส่งงาน

เนื่องจากเรากำลังใช้ Provisioners เริ่มต้น เราจะใช้ podTemplate ที่กำหนดโดยโครงสร้างที่มีอยู่ใน ที่เก็บ ARA GitHub. สิ่งเหล่านี้ถูกอัปโหลดให้คุณโดยโครงสร้างไปยังบัคเก็ต S3 ที่เรียก <clustername>-emr-eks-assets; คุณต้องอ้างถึงพวกเขาในงาน Spark ของคุณเท่านั้น ในงานนี้ คุณยังใช้พารามิเตอร์งานในเอาต์พุตเมื่อสิ้นสุดการปรับใช้ AWS CDK พารามิเตอร์เหล่านี้อนุญาตให้คุณใช้ AWS Glue Data Catalog และนำแนวทางปฏิบัติที่ดีที่สุดของ Spark ไปใช้งานบน Kubernetes เช่น dynamicAllocation และการจัดวางฝัก ในตอนท้ายของ cdk deploy ARA จะแสดงการกำหนดค่าตัวอย่างงานพร้อมแนวปฏิบัติที่ดีที่สุดที่แสดงไว้ก่อนที่คุณจะสามารถใช้เพื่อส่งงานได้ สามารถส่งงานได้ดังนี้
การรันงานคือหน่วยของงาน เช่น ไฟล์ Spark JAR ที่ส่งไปยัง EMR บนคลัสเตอร์ EKS เราเริ่มงานโดยใช้ start-job-run สั่งการ. หมายเหตุ คุณสามารถใช้ SparkSubmitParameters เพื่อระบุเส้นทาง Amazon S3 ไปยังเทมเพลตพ็อด ดังที่แสดงในคำสั่งต่อไปนี้:
รหัสใช้ค่าต่อไปนี้:
- – รหัสคลัสเตอร์เสมือน EMR
- – ชื่องาน Spark ของคุณ
- – บทบาทการดำเนินการที่คุณสร้างขึ้น
- – Amazon S3 URI ของงาน Spark ของคุณ
- – URI ของ Amazon S3 ของเทมเพลตพ็อดไดรเวอร์ ซึ่งคุณได้รับจากเอาต์พุต AWS CDK
- – Amazon S3 URI ของเทมเพลตพ็อดตัวดำเนินการ
- – ชื่อกลุ่มบันทึก CloudWatch ของคุณ
- – คำนำหน้าสตรีมบันทึก CloudWatch ของคุณ
คุณสามารถไปที่คอนโซล Amazon EMR เพื่อตรวจสอบสถานะงานของคุณและดูบันทึก คุณยังสามารถตรวจสอบสถานะได้โดยเรียกใช้ describe-job-run คำสั่ง:
สำรวจข้อมูลโดยใช้ Amazon EMR Studio
ในส่วนนี้ เราจะแสดงวิธีที่คุณสามารถสร้างพื้นที่ทำงานใน Amazon EMR Studio และเชื่อมต่อกับตำแหน่งข้อมูลที่มีการจัดการของ Amazon EKS จากพื้นที่ทำงาน จากเอาต์พุต ให้ใช้ลิงก์ไปยัง Amazon EMR Studio เพื่อนำทางไปยังการปรับใช้ EMR Studio คุณต้องลงชื่อเข้าใช้ด้วย IAM ชื่อผู้ใช้ ที่คุณระบุไว้ใน addUser วิธี
สร้างพื้นที่ทำงาน
หากต้องการสร้างพื้นที่ทำงาน ให้ทำตามขั้นตอนต่อไปนี้:
- เข้าสู่ระบบ EMR Studio ที่สร้างโดย AWS CDK
- Choose สร้างพื้นที่ทำงาน.
- ป้อนชื่อพื้นที่ทำงานและคำอธิบายเพิ่มเติม
- เลือก อนุญาต การทำงานร่วมกันในพื้นที่ทำงาน หากคุณต้องการทำงานกับผู้ใช้ Studio รายอื่นใน Workspace นี้แบบเรียลไทม์
- Choose สร้างพื้นที่ทำงาน.

หลังจากที่คุณสร้างพื้นที่ทำงานแล้ว ให้เลือกจากรายการพื้นที่ทำงานเพื่อเปิดสภาพแวดล้อม JupyterLab
ภาพหน้าจอต่อไปนี้แสดงให้เห็นว่าเทอร์มินัลมีลักษณะอย่างไร สำหรับข้อมูลเพิ่มเติมเกี่ยวกับอินเทอร์เฟซผู้ใช้ โปรดดูที่ ทำความเข้าใจกับอินเทอร์เฟซผู้ใช้ของ Workspace.
เชื่อมต่อกับ EMR บนตำแหน่งข้อมูลที่มีการจัดการ EKS
คุณสามารถเชื่อมต่อกับ EMR บนปลายทางที่มีการจัดการ EKS ได้อย่างง่ายดายจากพื้นที่ทำงาน
- ในบานหน้าต่างนำทาง บน เครือข่ายวิสาหกิจ ให้เลือก คลัสเตอร์ EMR บน EKS for
ประเภทคลัสเตอร์.
คลัสเตอร์เสมือนจะปรากฏบนเมนูดร็อปดาวน์ EMR Cluster บน EKS และจุดสิ้นสุดจะปรากฏบนเมนูแบบเลื่อนลง Endpoint หากมีปลายทางหลายจุด จุดเหล่านี้จะปรากฏที่นี่ และคุณสามารถสลับไปมาระหว่างจุดสิ้นสุดได้อย่างง่ายดายจากพื้นที่ทำงาน - เลือกปลายทางที่เหมาะสมแล้วเลือกแนบ

ทำงานกับโน๊ตบุ๊ค
ตอนนี้คุณสามารถเปิดสมุดบันทึกและเชื่อมต่อกับเคอร์เนลที่ต้องการเพื่อทำงานของคุณ ตัวอย่างเช่น คุณสามารถเลือกเคอร์เนล PySpark ดังที่แสดงในภาพหน้าจอต่อไปนี้
สำรวจข้อมูลของคุณ
ขั้นตอนแรกของแบบฝึกหัดการสำรวจข้อมูลของเราคือการสร้างเซสชัน Spark จากนั้นโหลดชุดข้อมูลแท็กซี่นิวยอร์กจากบัคเก็ต S3 ลงใน กรอบข้อมูล. ใช้บล็อคโค้ดต่อไปนี้เพื่อโหลดข้อมูลลงใน data frame คัดลอก URI ของ Amazon S3 สำหรับตำแหน่งที่ชุดข้อมูลอยู่ใน Amazon S3
หลังจากที่เราโหลดข้อมูลลงใน data frame แล้ว เราจะแทนที่ข้อมูลของ current_date คอลัมน์ที่มีวันที่ปัจจุบันจริง นับจำนวนแถว และบันทึกข้อมูลลงในไฟล์ Parquet:
ภาพหน้าจอต่อไปนี้แสดงผลของโน้ตบุ๊กของเราที่ทำงานบน Amazon EMR Studio และเมื่อ PySpark ทำงานบน Amazon EMR บน EKS
ทำความสะอาด
หากต้องการล้างข้อมูลหลังจากโพสต์นี้ ให้เรียกใช้ cdk destroy.
สรุป
ในโพสต์นี้ เราได้แสดงวิธีที่คุณสามารถใช้ ARA เพื่อปรับใช้โครงสร้างพื้นฐานการวิเคราะห์ข้อมูลอย่างรวดเร็วและเริ่มทำการทดลองกับข้อมูลของคุณ คุณสามารถดูตัวอย่างฉบับสมบูรณ์ที่อ้างอิงได้ในโพสต์นี้ใน พื้นที่เก็บข้อมูล GitHub. สถาปัตยกรรมอ้างอิง AWS Analytics ใช้รูปแบบ Analytics ทั่วไปและแนวทางปฏิบัติที่ดีที่สุดของ AWS เพื่อให้คุณพร้อมใช้งานโครงสร้างสำหรับการทดสอบของคุณ รูปแบบหนึ่งคือ data mesh ซึ่งคุณสามารถปรึกษาวิธีใช้ได้ในนี้ โพสต์บล็อก.
คุณยังสามารถสำรวจอื่นๆ โครงสร้างที่นำเสนอในห้องสมุดนี้ เพื่อทดลองกับบริการ AWS Analytics ก่อนที่จะเปลี่ยนปริมาณงานของคุณสำหรับการผลิต
เกี่ยวกับผู้เขียน
 ลอตฟี มูฮิบ เป็นสถาปนิกโซลูชันอาวุโสที่ทำงานให้กับทีมภาครัฐกับ Amazon Web Services เขาช่วยให้ลูกค้าภาครัฐทั่วทั้ง EMEA ตระหนักถึงความคิดของพวกเขา สร้างบริการใหม่ และสร้างสรรค์สิ่งใหม่สำหรับพลเมือง ในเวลาว่าง Lotfi สนุกกับการปั่นจักรยานและวิ่ง
ลอตฟี มูฮิบ เป็นสถาปนิกโซลูชันอาวุโสที่ทำงานให้กับทีมภาครัฐกับ Amazon Web Services เขาช่วยให้ลูกค้าภาครัฐทั่วทั้ง EMEA ตระหนักถึงความคิดของพวกเขา สร้างบริการใหม่ และสร้างสรรค์สิ่งใหม่สำหรับพลเมือง ในเวลาว่าง Lotfi สนุกกับการปั่นจักรยานและวิ่ง
 สันดิพันธ์ ภูมิิก เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญด้านการวิเคราะห์อาวุโสในลอนดอน เขาได้ทำงานร่วมกับลูกค้าในอุตสาหกรรมต่างๆ เช่น การธนาคารและบริการทางการเงิน การดูแลสุขภาพ พลังงานและสาธารณูปโภค การผลิตและการค้าปลีก ซึ่งช่วยให้พวกเขาแก้ปัญหาความท้าทายที่ซับซ้อนด้วยแพลตฟอร์มข้อมูลขนาดใหญ่ ที่ AWS เขามุ่งเน้นไปที่บัญชีเชิงกลยุทธ์ในสหราชอาณาจักรและไอร์แลนด์ และช่วยลูกค้าเร่งการเดินทางสู่ระบบคลาวด์และสร้างสรรค์สิ่งใหม่ๆ โดยใช้บริการการวิเคราะห์ของ AWS และแมชชีนเลิร์นนิง เขาชอบเล่นแบดมินตันและอ่านหนังสือ
สันดิพันธ์ ภูมิิก เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญด้านการวิเคราะห์อาวุโสในลอนดอน เขาได้ทำงานร่วมกับลูกค้าในอุตสาหกรรมต่างๆ เช่น การธนาคารและบริการทางการเงิน การดูแลสุขภาพ พลังงานและสาธารณูปโภค การผลิตและการค้าปลีก ซึ่งช่วยให้พวกเขาแก้ปัญหาความท้าทายที่ซับซ้อนด้วยแพลตฟอร์มข้อมูลขนาดใหญ่ ที่ AWS เขามุ่งเน้นไปที่บัญชีเชิงกลยุทธ์ในสหราชอาณาจักรและไอร์แลนด์ และช่วยลูกค้าเร่งการเดินทางสู่ระบบคลาวด์และสร้างสรรค์สิ่งใหม่ๆ โดยใช้บริการการวิเคราะห์ของ AWS และแมชชีนเลิร์นนิง เขาชอบเล่นแบดมินตันและอ่านหนังสือ
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/accelerate-your-data-exploration-and-experimentation-with-the-aws-analytics-reference-architecture-library/
- 1
- 10
- 100
- 11
- 6G
- 7
- 9
- a
- เกี่ยวกับเรา
- เร่งความเร็ว
- เข้า
- การจัดการการเข้าถึง
- ลงชื่อเข้าใช้
- บัญชี
- ข้าม
- การปฏิบัติ
- เพิ่ม
- การบริหาร
- หลังจาก
- ก้าวร้าว
- ทั้งหมด
- การจัดสรร
- ช่วยให้
- แล้ว
- แม้ว่า
- อเมซอน
- Amazon EC2
- อเมซอน EMR
- Amazon Web Services
- การวิเคราะห์
- การวิเคราะห์
- และ
- อาปาเช่
- app
- ปรากฏ
- ใช้
- เหมาะสม
- สถาปัตยกรรม
- ข้อโต้แย้ง
- สินทรัพย์
- ที่เกี่ยวข้อง
- แนบ
- แอตทริบิวต์
- การยืนยันตัวตน
- การเขียน
- รถยนต์
- ใช้ได้
- AWS
- AWS กาว
- AWS Identity และการจัดการการเข้าถึง (IAM)
- การธนาคาร
- ตาม
- เพราะ
- ก่อน
- ด้านล่าง
- ที่ดีที่สุด
- ปฏิบัติที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- ปิดกั้น
- บล็อก
- ร้านหนังสือเกาหลี
- สร้าง
- สร้าง
- ที่เรียกว่า
- โทร
- ความจุ
- กรณี
- กรณี
- แค็ตตาล็อก
- ระมัดระวัง
- CD
- ใบรับรอง
- ความท้าทาย
- ตรวจสอบ
- Choose
- ประชา
- ชั้น
- การจัดหมวดหมู่
- ไคลเอนต์
- เมฆ
- Cluster
- รหัส
- คอลัมน์
- COM
- ร่วมกัน
- สมบูรณ์
- ซับซ้อน
- คำนวณ
- สภาพ
- เชื่อมต่อ
- ปลอบใจ
- สร้าง
- มี
- ควบคุม
- ตัวควบคุม
- ราคา
- ค่าใช้จ่าย
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- การสร้าง
- การสร้าง
- วิกฤติ
- ปัจจุบัน
- ลูกค้า
- ปรับแต่ง
- ข้อมูล
- การวิเคราะห์ข้อมูล
- วิเคราะห์ข้อมูล
- วิศวกรข้อมูล
- วันที่
- วันเวลา
- ทุ่มเท
- ค่าเริ่มต้น
- กำหนด
- ปรับใช้
- ปรับใช้
- การใช้งาน
- Deploys
- ลักษณะ
- รายละเอียด
- พัฒนาการ
- ต่าง
- สนทนา
- เอกสาร
- ไม่
- Dont
- คนขับรถ
- แต่ละ
- อย่างง่ายดาย
- ผล
- ทั้ง
- EMEA
- เปิดการใช้งาน
- ช่วยให้
- การเปิดใช้งาน
- ที่มีการเข้ารหัส
- ปลายทาง
- วิศวกร
- สิ่งแวดล้อม
- อีเธอร์ (ETH)
- ตัวอย่าง
- การปฏิบัติ
- การออกกำลังกาย
- การทดลอง
- ผู้เชี่ยวชาญ
- การสำรวจ
- การวิเคราะห์ข้อมูลเชิงสำรวจ
- สำรวจ
- โรงงาน
- ครอบครัว
- เร็วขึ้น
- สหพันธ์
- สนาม
- เนื้อไม่มีมัน
- ไฟล์
- ทางการเงิน
- บริการทางการเงิน
- หา
- ชื่อจริง
- มุ่งเน้นไปที่
- ปฏิบัติตาม
- ดังต่อไปนี้
- ดังต่อไปนี้
- FRAME
- ราคาเริ่มต้นที่
- เต็ม
- ฟังก์ชั่น
- ต่อไป
- สร้าง
- ได้รับ
- GitHub
- Go
- บัญชีกลุ่ม
- กลุ่ม
- Hadoop
- การดูแลสุขภาพ
- การช่วยเหลือ
- จะช่วยให้
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- จุดสูง
- รัง
- เจ้าภาพ
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- HTTPS
- AMI
- ความคิด
- เอกลักษณ์
- การระบุตัวตนและการจัดการการเข้าถึง
- การจัดการข้อมูลประจำตัวและการเข้าถึง (IAM)
- การดำเนินการ
- การดำเนินการ
- การดำเนินการ
- นำเข้า
- สำคัญ
- ช่วยเพิ่ม
- in
- อุตสาหกรรม
- ข้อมูล
- โครงสร้างพื้นฐาน
- เราสร้างสรรค์สิ่งใหม่ ๆ
- ติดตั้ง
- ตัวอย่าง
- แทน
- คำแนะนำการใช้
- แบบบูรณาการ
- โต้ตอบ
- การโต้ตอบ
- อินเตอร์เฟซ
- ขัดจังหวะ
- ไอร์แลนด์
- IT
- การสัมภาษณ์
- งาน
- การเดินทาง
- JSON
- เก็บ
- Kubernetes
- ใหญ่
- ขนาดใหญ่
- เรียนรู้
- การเรียนรู้
- เลฟเวอเรจ
- ห้องสมุด
- LIMIT
- Line
- เส้น
- LINK
- ที่เชื่อมโยง
- รายการ
- จดทะเบียน
- โหลด
- ที่ตั้ง
- ลอนดอน
- LOOKS
- ต่ำ
- เครื่อง
- เรียนรู้เครื่อง
- การจัดการ
- การจัดการ
- ผู้จัดการ
- จำเป็น
- การผลิต
- หลาย
- วิธี
- กลไก
- หน่วยความจำ
- เมนู
- วิธี
- วิธีการ
- โหมด
- เงิน
- ข้อมูลเพิ่มเติม
- หลาย
- ชื่อ
- ที่มีชื่อ
- นำทาง
- การเดินเรือ
- จำเป็น
- จำเป็นต้อง
- จำเป็น
- ความต้องการ
- เครือข่าย
- ใหม่
- นิวยอร์ก
- ปม
- โหนด
- สมุดบันทึก
- โน๊ตบุ๊ค
- จำนวน
- เสนอ
- เสนอ
- เสนอ
- ONE
- เปิด
- การปรับให้เหมาะสม
- เพิ่มประสิทธิภาพ
- organizacja
- องค์กร
- อื่นๆ
- ของตนเอง
- บานหน้าต่าง
- พารามิเตอร์
- พารามิเตอร์
- เส้นทาง
- แบบแผน
- รูปแบบ
- การปฏิบัติ
- การอนุญาต
- สิทธิ์
- ทางร่างกาย
- สถานที่
- เวที
- แพลตฟอร์ม
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- ฝัก
- นโยบาย
- นโยบาย
- โพสต์
- อำนาจ
- การปฏิบัติ
- ที่ต้องการ
- ก่อน
- ปัญหาที่เกิดขึ้น
- กระบวนการ
- หน่วยประมวลผล
- การผลิต
- ดูรายละเอียด
- โครงการ
- โครงการ
- คุณสมบัติ
- คุณสมบัติ
- ให้
- ให้
- บทบัญญัติ
- สาธารณะ
- อย่างรวดเร็ว
- รวดเร็ว
- อ่าน
- การอ่าน
- พร้อม
- จริง
- เรียลไทม์
- ตระหนักถึง
- แนะนำ
- บันทึก
- ลด
- ลด
- ลงทะเบียน
- แทนที่
- แสดง
- ขอ
- ต้อง
- แหล่งข้อมูล
- จำกัด
- ผล
- ค้าปลีก
- บทบาท
- บทบาท
- วิ่ง
- วิ่ง
- ประโยชน์
- เดียวกัน
- ลด
- ประหยัด
- ที่สอง
- Section
- ภาค
- ความปลอดภัย
- ระดับอาวุโส
- มีความละเอียดอ่อน
- บริการ
- บริการ
- เซสชั่น
- ชุด
- โชว์
- แสดง
- แสดงให้เห็นว่า
- สับเปลี่ยน
- ลงชื่อ
- ง่าย
- ที่เรียบง่าย
- เดียว
- ขนาด
- เล็ก
- So
- ทางออก
- โซลูชัน
- แก้
- จุดประกาย
- ผู้เชี่ยวชาญ
- ใช้จ่าย
- การใช้จ่าย
- จุด
- SQL
- กอง
- เริ่มต้น
- ข้อความที่เริ่ม
- ที่เริ่มต้น
- งบ
- Status
- ขั้นตอน
- ขั้นตอน
- หยุด
- การเก็บรักษา
- เก็บไว้
- ร้านค้า
- ยุทธศาสตร์
- กระแส
- สตูดิโอ
- สตูดิโอ
- ส่ง
- ส่ง
- ส่ง
- ซับเน็ต
- อย่างเช่น
- เหมาะสม
- ที่จัดมา
- ที่สนับสนุน
- สวิตซ์
- ใช้เวลา
- งาน
- ทีม
- เทมเพลต
- ชั่วคราว
- สถานีปลายทาง
- พื้นที่
- สหราชอาณาจักร
- ของพวกเขา
- ตลอด
- ปริมาณงาน
- เวลา
- ไปยัง
- เกินไป
- รวม
- โอน
- การแปลง
- เปลี่ยน
- จริง
- เกี่ยวกับการสอน
- ชนิด
- ประเภท
- Uk
- พื้นฐาน
- หน่วย
- บันทึก
- การปรับปรุง
- อัปโหลด
- URI
- ใช้
- ผู้ใช้งาน
- ส่วนติดต่อผู้ใช้
- ผู้ใช้
- ยูทิลิตี้
- ความคุ้มค่า
- ความคุ้มค่า
- รุ่น
- การควบคุมเวอร์ชัน
- รายละเอียด
- เสมือน
- ปริมาณ
- รอ
- เว็บ
- บริการเว็บ
- อะไร
- ที่
- จะ
- ภายใน
- งาน
- ทำงาน
- ผู้ปฏิบัติงาน
- ขั้นตอนการทำงาน
- การทำงาน
- เขียน
- มันแกว
- ของคุณ
- ลมทะเล