Amazon EMR ไร้เซิร์ฟเวอร์ ช่วยให้คุณสามารถเรียกใช้เฟรมเวิร์กข้อมูลขนาดใหญ่แบบโอเพ่นซอร์ส เช่น Apache Spark และ Apache Hive โดยไม่ต้องจัดการคลัสเตอร์และเซิร์ฟเวอร์ ด้วย EMR Serverless คุณสามารถเรียกใช้ปริมาณงานการวิเคราะห์ได้ทุกขนาดด้วยการปรับขนาดอัตโนมัติที่ปรับขนาดทรัพยากรในไม่กี่วินาทีเพื่อตอบสนองความต้องการปริมาณข้อมูลที่เปลี่ยนแปลงและการประมวลผล EMR Serverless ปรับขนาดทรัพยากรขึ้นและลงโดยอัตโนมัติเพื่อให้ความจุในปริมาณที่เหมาะสมสำหรับแอปพลิเคชันของคุณ
เรารู้สึกตื่นเต้นที่จะประกาศว่าขณะนี้ EMR Serverless มีการกำหนดค่าของผู้ปฏิบัติงาน 8 vCPU พร้อมหน่วยความจำสูงสุด 60 GB และ 16 vCPU พร้อมหน่วยความจำสูงสุด 120 GB ช่วยให้คุณสามารถเรียกใช้ปริมาณงานที่ใช้การประมวลผลและหน่วยความจำมากบน EMR Serverless แอปพลิเคชัน EMR Serverless ใช้พนักงานภายในเพื่อดำเนินการปริมาณงาน และคุณสามารถกำหนดคอนฟิกผู้ปฏิบัติงานที่แตกต่างกันตามข้อกำหนดปริมาณงานของคุณ ก่อนหน้านี้ การกำหนดค่าของผู้ปฏิบัติงานที่ใหญ่ที่สุดที่มีอยู่บน EMR Serverless คือ 4 vCPU ที่มีหน่วยความจำสูงสุด 30 GB ความสามารถนี้เป็นประโยชน์อย่างยิ่งสำหรับสถานการณ์ทั่วไปต่อไปนี้:
- สับเปลี่ยนภาระงานหนัก
- เวิร์กโหลดที่ใช้หน่วยความจำมาก
มาดูกรณีการใช้งานแต่ละกรณีและประโยชน์ของการมีขนาดผู้ปฏิบัติงานที่ใหญ่ขึ้น
ประโยชน์ของการใช้คนงานจำนวนมากสำหรับการสับเปลี่ยนปริมาณงานมาก
ใน Spark และ Hive การสับเปลี่ยนจะเกิดขึ้นเมื่อข้อมูลจำเป็นต้องแจกจ่ายซ้ำทั่วทั้งคลัสเตอร์ระหว่างการคำนวณ เมื่อแอปพลิเคชันของคุณดำเนินการแปลงแบบกว้างหรือลดการดำเนินการ เช่น join, groupBy, sortBy,หรือ repartition, Spark และ Hive ทริกเกอร์การสับเปลี่ยน นอกจากนี้ ทุกๆ สเตจของ Spark และจุดยอดของ Tez จะถูกจำกัดด้วยการดำเนินการสับเปลี่ยน ยกตัวอย่าง Spark ตามค่าเริ่มต้น มีพาร์ติชัน 200 พาร์ติชันสำหรับทุกงาน Spark ที่กำหนดโดย spark.sql.shuffle.partitions. อย่างไรก็ตาม Spark จะคำนวณจำนวนงานในทันทีตามขนาดข้อมูลและการดำเนินการที่กำลังดำเนินการ เมื่อทำการแปลงแบบกว้างบนชุดข้อมูลขนาดใหญ่ อาจมีข้อมูล GB หรือกระทั่ง TB ที่งานทั้งหมดจำเป็นต้องดึงข้อมูล
การสับเปลี่ยนมักจะมีราคาแพงในแง่ของเวลาและทรัพยากร และอาจนำไปสู่ปัญหาคอขวดของประสิทธิภาพ ดังนั้น การปรับสับเปลี่ยนให้เหมาะสมอาจมีผลกระทบอย่างมากต่อประสิทธิภาพและต้นทุนของงาน Spark ด้วยพนักงานจำนวนมาก จึงสามารถจัดสรรข้อมูลได้มากขึ้นไปยังหน่วยความจำของโปรแกรมประมวลผลแต่ละตัว ซึ่งช่วยลดการสับเปลี่ยนข้อมูลระหว่างโปรแกรมประมวลผล สิ่งนี้จะนำไปสู่การเพิ่มประสิทธิภาพการอ่านแบบสุ่ม เนื่องจากจะมีการดึงข้อมูลมากขึ้นจากพนักงานคนเดียวกันในเครื่อง และจะมีการดึงข้อมูลจากระยะไกลจากพนักงานคนอื่นๆ น้อยลง
การทดลอง
เพื่อแสดงให้เห็นถึงประโยชน์ของการใช้ผู้ปฏิบัติงานจำนวนมากสำหรับการสืบค้นที่มีการสับเปลี่ยนมาก ลองใช้กัน q78 จาก TPC-DS ซึ่งเป็นการสืบค้นแบบ Spark ที่มีการสับเปลี่ยนจำนวนมากซึ่งสับเปลี่ยนข้อมูล 167 GB ใน 12 ขั้นของ Spark ลองทำแบบสอบถามเดียวกันซ้ำสองครั้งด้วยการกำหนดค่าที่แตกต่างกัน
การกำหนดค่าสำหรับการทดสอบ 1 มีดังนี้:
- ขนาดของตัวดำเนินการที่ร้องขอขณะสร้างแอปพลิเคชัน EMR Serverless = 4 vCPU, หน่วยความจำ 8 GB, ดิสก์ 200 GB
- การกำหนดค่างาน Spark:
spark.executor.cores= 4spark.executor.memory= 8spark.executor.instances= 48- ความขนาน = 192 (
spark.executor.instances*spark.executor.cores)
การกำหนดค่าสำหรับการทดสอบ 2 มีดังนี้:
- ขนาดของตัวดำเนินการที่ร้องขอขณะสร้างแอปพลิเคชัน EMR Serverless = 8 vCPU, หน่วยความจำ 16 GB, ดิสก์ 200 GB
- การกำหนดค่างาน Spark:
spark.executor.cores= 8spark.executor.memory= 16spark.executor.instances= 24- ความขนาน = 192 (
spark.executor.instances*spark.executor.cores)
เรามาปิดใช้งานการจัดสรรแบบไดนามิกด้วยการตั้งค่า spark.dynamicAllocation.enabled ไปยัง false สำหรับการทดสอบทั้งสองเพื่อหลีกเลี่ยงสัญญาณรบกวนที่อาจเกิดขึ้นเนื่องจากเวลาเปิดใช้ตัวดำเนินการที่ผันแปร และรักษาการใช้ทรัพยากรให้สอดคล้องกันสำหรับการทดสอบทั้งสอง เราใช้ วัดประกายไฟซึ่งเป็นเครื่องมือโอเพ่นซอร์สที่ทำให้การรวบรวมและวิเคราะห์เมตริกประสิทธิภาพของ Spark ง่ายขึ้น เนื่องจากเราใช้ตัวดำเนินการในจำนวนที่แน่นอน จำนวน vCPU และหน่วยความจำทั้งหมดที่ร้องขอจึงเท่ากันสำหรับการทดสอบทั้งสองครั้ง ตารางต่อไปนี้สรุปการสังเกตจากเมตริกที่รวบรวมด้วยการวัดประกายไฟ
| . | เวลาทั้งหมดที่ใช้ในการค้นหาเป็นมิลลิวินาที | สับเปลี่ยน LocalBlocksFetched | สับเปลี่ยน RemoteBlocksFetched | สับเปลี่ยน LocalBytesRead | สุ่มRemoteBytesRead | สุ่มFetchWaitTime | สุ่มเวลาเขียน |
| 1 ทดสอบ | 153244 | 114175 | 5291825 | 3.5 GB | 163.1 GB | ชั่วโมง 1.9 | 4.7 นาที |
| 2 ทดสอบ | 108136 | 225448 | 5185552 | 6.9 GB | 159.7 GB | 3.2 นาที | 5.2 นาที |
ดังที่เห็นจากตาราง มีความแตกต่างอย่างมีนัยสำคัญในด้านประสิทธิภาพเนื่องจากการปรับปรุงการสับเปลี่ยน การทดสอบ 2 ด้วยจำนวนตัวดำเนินการครึ่งหนึ่งซึ่งมีขนาดใหญ่เป็นสองเท่าของการทดสอบ 1 รันเร็วขึ้น 29.44% พร้อมดึงข้อมูลแบบสับเปลี่ยนในเครื่องมากกว่า 1.97 เท่าเมื่อเทียบกับการทดสอบ 1 สำหรับการสืบค้นเดียวกัน การขนานเท่าเดิม และทรัพยากร vCPU และหน่วยความจำรวมที่เท่ากัน . ดังนั้น คุณจะได้รับประโยชน์จากประสิทธิภาพที่ดีขึ้นโดยไม่กระทบต่อต้นทุนหรือการทำงานแบบคู่ขนานด้วยความช่วยเหลือจากผู้บริหารระดับสูง เราสังเกตเห็นประโยชน์ด้านประสิทธิภาพที่คล้ายคลึงกันสำหรับข้อความค้นหา TPC-DS ที่เน้นการสุ่มอื่นๆ เช่น q23a และ 23b.
แนะนำ
หากต้องการพิจารณาว่าพนักงานจำนวนมากจะได้รับประโยชน์จากแอปพลิเคชัน Spark ที่เน้นการสับเปลี่ยนหรือไม่ ให้พิจารณาสิ่งต่อไปนี้:
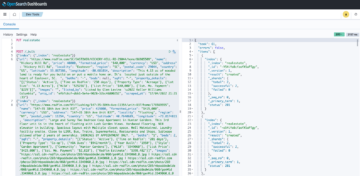
- ตรวจสอบ การฝึกงาน แท็บจาก Spark History Server UI ของแอปพลิเคชัน EMR Serverless ของคุณ ตัวอย่างเช่น จากภาพหน้าจอต่อไปนี้ของ Spark History Server เราสามารถระบุได้ว่างาน Spark นี้เขียนและอ่านข้อมูลสับเปลี่ยน 167 GB ที่รวบรวมจาก 12 สเตจ โดยดูที่ สุ่มอ่าน และ สุ่มเขียน คอลัมน์ หากงานของคุณสับเปลี่ยนข้อมูลมากกว่า 50 GB คุณอาจได้รับประโยชน์จากการใช้ผู้ปฏิบัติงานขนาดใหญ่ที่มี 8 หรือ 16 vCPU หรือ
spark.executor.cores.

- ตรวจสอบ SQL/ดาต้าเฟรม จาก Spark History Server UI ของแอปพลิเคชัน EMR Serverless ของคุณ (สำหรับ Dataframe และ Dataset API เท่านั้น) เมื่อคุณเลือกการดำเนินการ Spark ที่ดำเนินการ เช่น รวบรวม รับ แสดงสตริง หรือบันทึก คุณจะเห็น DAG แบบรวมสำหรับทุกขั้นตอนโดยคั่นด้วยการแลกเปลี่ยน ทุกการแลกเปลี่ยนใน DAG สอดคล้องกับการดำเนินการสับเปลี่ยน และจะประกอบด้วยไบต์และบล็อกในเครื่องและระยะไกลดังที่เห็นในภาพหน้าจอต่อไปนี้ หากการสุ่มบล็อกหรือไบต์ในเครื่องที่ดึงมานั้นน้อยกว่ามากเมื่อเทียบกับบล็อกหรือไบต์ระยะไกลที่ดึงมา คุณสามารถรันแอปพลิเคชันของคุณอีกครั้งด้วยคนงานจำนวนมากขึ้น (ด้วย 8 หรือ 16 vCPU หรือ spark.executor.cores) และตรวจสอบเมตริกการแลกเปลี่ยนเหล่านี้ใน DAG เพื่อ ดูว่ามีการปรับปรุงหรือไม่

- ใช้ วัดประกายไฟ เครื่องมือด้วยแบบสอบถาม Spark ของคุณเพื่อรับเมตริกการสับเปลี่ยนในไดรเวอร์ Spark
stdoutดังที่แสดงในบันทึกต่อไปนี้สำหรับงาน Spark ตรวจสอบเวลาที่ใช้ในการอ่านแบบสุ่ม (shuffleFetchWaitTime) และการเขียนแบบสุ่ม (shuffleWriteTime) และอัตราส่วนของไบต์ในเครื่องที่ดึงข้อมูลกับไบต์ระยะไกลที่ดึงมา หากการดำเนินการสับเปลี่ยนใช้เวลานานกว่า 2 นาที ให้รันแอปพลิเคชันของคุณใหม่ด้วยผู้ปฏิบัติงานที่มีขนาดใหญ่กว่า (ที่มี 8 หรือ 16 vCPU หรือspark.executor.cores) ด้วย Spark Measure เพื่อติดตามการปรับปรุงประสิทธิภาพการสุ่มและรันไทม์งานโดยรวม
ประโยชน์ของการใช้คนงานจำนวนมากสำหรับเวิร์กโหลดที่ใช้หน่วยความจำมาก
ปริมาณงานบางประเภทใช้หน่วยความจำมาก และอาจได้รับประโยชน์จากการกำหนดค่าหน่วยความจำที่มากขึ้นต่อผู้ปฏิบัติงาน ในส่วนนี้ เราจะหารือเกี่ยวกับสถานการณ์ทั่วไปที่คนทำงานจำนวนมากอาจเป็นประโยชน์สำหรับการรันเวิร์กโหลดที่ใช้หน่วยความจำมาก
ข้อมูลเบ้
การบิดเบือนข้อมูลมักเกิดขึ้นในชุดข้อมูลหลายประเภท ตัวอย่างทั่วไปบางส่วน ได้แก่ การตรวจจับการฉ้อโกง การวิเคราะห์ประชากร และการกระจายรายได้ ตัวอย่างเช่น เมื่อคุณต้องการตรวจจับความผิดปกติในข้อมูลของคุณ คาดว่าจะมีข้อมูลเพียงน้อยกว่า 1% เท่านั้นที่ผิดปกติ หากคุณต้องการทำการรวมข้อมูลนอกเหนือจากเรกคอร์ดปกติเทียบกับเรกคอร์ดที่ผิดปกติ 99% ของข้อมูลจะถูกประมวลผลโดยผู้ปฏิบัติงานคนเดียว ซึ่งอาจทำให้ผู้ปฏิบัติงานคนนั้นมีหน่วยความจำไม่เพียงพอ อาจสังเกตเห็นการบิดเบือนข้อมูลสำหรับการแปลงที่ใช้หน่วยความจำมาก เช่น groupBy, orderBy, join, ฟังก์ชั่นหน้าต่าง, collect_list, collect_setและอื่น ๆ ประเภทการเข้าร่วมเช่น BroadcastNestedLoopJoin และผลิตภัณฑ์ Cartesan นั้นใช้หน่วยความจำมากโดยเนื้อแท้และไวต่อการบิดเบือนข้อมูล ในทำนองเดียวกัน หากข้อมูลอินพุตของคุณถูกบีบอัด Gzip ไฟล์ Gzip ไฟล์เดียวจะไม่สามารถอ่านได้มากกว่าหนึ่งงาน เนื่องจากประเภทการบีบอัด Gzip นั้นแยกไม่ได้ เมื่อมีไฟล์ Gzip ขนาดใหญ่มากสองสามไฟล์ในอินพุต งานของคุณอาจใช้หน่วยความจำไม่เพียงพอ เนื่องจากงานเดียวอาจต้องอ่านไฟล์ Gzip ขนาดใหญ่ที่ไม่พอดีกับหน่วยความจำตัวดำเนินการ
ความล้มเหลวเนื่องจากการบิดเบือนข้อมูลสามารถบรรเทาได้โดยใช้กลยุทธ์ เช่น การเติมเกลือ อย่างไรก็ตาม การดำเนินการนี้มักต้องการการเปลี่ยนแปลงโค้ดจำนวนมาก ซึ่งอาจเป็นไปไม่ได้สำหรับปริมาณงานการผลิตที่ล้มเหลวเนื่องจากการบิดเบือนข้อมูลอย่างไม่เคยปรากฏมาก่อน ซึ่งเกิดจากปริมาณข้อมูลขาเข้าที่เพิ่มขึ้นอย่างกะทันหัน สำหรับวิธีแก้ปัญหาที่ง่ายกว่า คุณอาจต้องการเพิ่มหน่วยความจำของผู้ปฏิบัติงาน ใช้คนงานจำนวนมากขึ้นด้วย spark.executor.memory ช่วยให้คุณสามารถจัดการกับข้อมูลที่บิดเบือนได้โดยไม่ต้องทำการเปลี่ยนแปลงใด ๆ กับรหัสแอปพลิเคชันของคุณ
แคช
เพื่อปรับปรุงประสิทธิภาพ Spark อนุญาตให้คุณแคชเฟรมข้อมูล ชุดข้อมูล และ RDD ในหน่วยความจำ สิ่งนี้ทำให้คุณสามารถใช้ data frame ซ้ำได้หลายครั้งในแอปพลิเคชันของคุณโดยไม่ต้องคำนวณใหม่ ตามค่าเริ่มต้น JVM ของโปรแกรมดำเนินการมากถึง 50% จะถูกใช้เพื่อแคชเฟรมข้อมูลตาม property spark.memory.storageFraction. ตัวอย่างเช่นหากไฟล์ spark.executor.memory ตั้งค่าเป็น 30 GB จากนั้น 15 GB ใช้สำหรับพื้นที่เก็บข้อมูลแคชที่ไม่ถูกไล่ออก
ระดับการจัดเก็บเริ่มต้นของการดำเนินการแคชคือ DISK_AND_MEMORY. หากขนาดของ data frame ที่คุณพยายามแคชไม่พอดีกับหน่วยความจำของ executor แคชส่วนหนึ่งจะกระจายไปยังดิสก์ หากมีพื้นที่ไม่เพียงพอในการเขียนข้อมูลที่แคชไว้ในดิสก์ บล็อกจะถูกขับออกและคุณจะไม่ได้รับประโยชน์จากการแคช การใช้ผู้ปฏิบัติงานที่ใหญ่ขึ้นทำให้คุณสามารถแคชข้อมูลในหน่วยความจำได้มากขึ้น เพิ่มประสิทธิภาพงานโดยการดึงบล็อกที่แคชไว้จากหน่วยความจำแทนที่จะเป็นที่เก็บข้อมูลพื้นฐาน
การทดลอง
ตัวอย่างเช่นต่อไปนี้ งาน PySpark นำไปสู่การเบ้ โดยตัวดำเนินการหนึ่งตัวประมวลผล 99.95% ของข้อมูลที่มีการรวมหน่วยความจำมากเช่น collect_list. งานยังแคชเฟรมข้อมูลขนาดใหญ่มาก (2.2 TB) มารันงานเดียวกันซ้ำสองรอบบน EMR Serverless ด้วยการกำหนดค่า vCPU และหน่วยความจำต่อไปนี้
มาเรียกใช้การทดสอบ 3 ด้วยการกำหนดค่าผู้ปฏิบัติงานที่ใหญ่ที่สุดเท่าที่จะเป็นไปได้ก่อนหน้านี้:
- ขนาดชุดตัวดำเนินการขณะสร้างแอปพลิเคชัน EMR Serverless = 4 vCPU, หน่วยความจำ 30 GB, ดิสก์ 200 GB
- การกำหนดค่างาน Spark:
spark.executor.cores= 4spark.executor.memory= 27 ก
เรียกใช้การทดสอบ 4 ด้วยการกำหนดค่าผู้ปฏิบัติงานขนาดใหญ่ที่เพิ่งเปิดตัว:
- ขนาดของตัวดำเนินการที่ตั้งค่าไว้ขณะสร้างแอปพลิเคชัน EMR Serverless = 8 vCPU, หน่วยความจำ 60 GB, ดิสก์ 200 GB
- การกำหนดค่างาน Spark:
spark.executor.cores= 8spark.executor.memory= 54 ก
การทดสอบ 3 ล้มเหลวด้วย FetchFailedExceptionซึ่งเป็นผลมาจากหน่วยความจำตัวดำเนินการไม่เพียงพอสำหรับงาน

นอกจากนี้ จาก Spark UI ของการทดสอบ 3 เราเห็นว่าหน่วยความจำสำรองของโปรแกรมดำเนินการนั้นถูกใช้อย่างเต็มที่สำหรับการแคชเฟรมข้อมูล

บล็อกที่เหลือสำหรับแคชถูกกระจายไปยังดิสก์ ดังที่เห็นในโปรแกรมดำเนินการ stderr บันทึก:
ประมาณ 33% ของเฟรมข้อมูลที่คงอยู่ถูกแคชไว้บนดิสก์ ดังที่เห็นใน พื้นที่จัดเก็บ แท็บของ Spark UI

ทดสอบ 4 ด้วยตัวประมวลผลที่ใหญ่ขึ้นและ vCores ทำงานได้สำเร็จโดยไม่เกิดข้อผิดพลาดเกี่ยวกับหน่วยความจำ นอกจากนี้ มีเพียงประมาณ 2.2% ของ data frame เท่านั้นที่ถูกแคชไปยังดิสก์ ดังนั้น บล็อกแคชของเฟรมข้อมูลจะถูกดึงมาจากหน่วยความจำแทนที่จะดึงจากดิสก์ ซึ่งให้ประสิทธิภาพที่ดีกว่า

แนะนำ
หากต้องการพิจารณาว่าพนักงานจำนวนมากจะได้รับประโยชน์จากแอปพลิเคชัน Spark ที่ใช้หน่วยความจำมากหรือไม่ ให้พิจารณาสิ่งต่อไปนี้:
- ตรวจสอบว่าแอปพลิเคชัน Spark ของคุณมีข้อมูลเอียงหรือไม่โดยดูที่ Spark UI สกรีนช็อตต่อไปนี้ของ Spark UI แสดงตัวอย่างสถานการณ์ข้อมูลเอียงที่งานหนึ่งประมวลผลข้อมูลส่วนใหญ่ (145.2 GB) โดยดูที่ สุ่มอ่าน ขนาด. หากงานหนึ่งหรือน้อยกว่านั้นประมวลผลข้อมูลมากกว่างานอื่นๆ อย่างมีนัยสำคัญ ให้รันแอปพลิเคชันของคุณใหม่ด้วยผู้ปฏิบัติงานขนาดใหญ่ที่มีหน่วยความจำ 60–120 G (
spark.executor.memoryตั้งค่าที่ใดก็ได้ตั้งแต่ 54–109 GB การแยกตัวประกอบใน 10% ของspark.executor.memoryOverhead).

- ตรวจสอบ พื้นที่จัดเก็บ แท็บของ Spark History Server เพื่อตรวจสอบอัตราส่วนของข้อมูลที่แคชในหน่วยความจำต่อดิสก์จาก ขนาดในหน่วยความจำ และ ขนาดในดิสก์ คอลัมน์ ถ้าข้อมูลของคุณมากกว่า 10% ถูกแคชไว้ที่ดิสก์ ให้รันแอปพลิเคชันของคุณใหม่ด้วยคนงานที่ใหญ่ขึ้นเพื่อเพิ่มจำนวนข้อมูลที่แคชในหน่วยความจำ
- อีกวิธีหนึ่งในการตัดสินล่วงหน้าว่างานของคุณต้องการหน่วยความจำเพิ่มหรือไม่คือการตรวจสอบ หน่วยความจำ JVM สูงสุด บน Spark UI รัฟ แท็บ หากหน่วยความจำ JVM สูงสุดที่ใช้อยู่ใกล้กับหน่วยความจำตัวประมวลผลหรือไดรเวอร์ คุณสามารถสร้างแอปพลิเคชันที่มีผู้ปฏิบัติงานขนาดใหญ่ขึ้นและกำหนดค่าที่สูงขึ้นสำหรับ
spark.executor.memoryorspark.driver.memory. ตัวอย่างเช่น ในภาพหน้าจอต่อไปนี้ ค่าสูงสุดของการใช้หน่วยความจำ JVM สูงสุดคือ 26 GB และspark.executor.memoryตั้งค่าเป็น 27 G ในกรณีนี้ อาจเป็นประโยชน์หากใช้คนงานขนาดใหญ่ที่มีหน่วยความจำ 60 GB และspark.executor.memoryตั้งเป็น 54 G.

สิ่งที่ควรพิจารณา
แม้ว่า vCPU ขนาดใหญ่จะช่วยเพิ่มพื้นที่ของบล็อกการสับเปลี่ยน แต่ก็มีปัจจัยอื่นๆ ที่เกี่ยวข้อง เช่น ปริมาณงานของดิสก์, IOPS ของดิสก์ (การดำเนินการอินพุต/เอาต์พุตต่อวินาที) และแบนด์วิดท์เครือข่าย ในบางกรณี ผู้ปฏิบัติงานขนาดเล็กที่มีดิสก์มากขึ้นสามารถให้ดิสก์ IOPS, ทรูพุต และแบนด์วิธเครือข่ายโดยรวมสูงกว่าเมื่อเทียบกับผู้ปฏิบัติงานขนาดใหญ่จำนวนน้อยกว่า เราขอแนะนำให้คุณเปรียบเทียบปริมาณงานของคุณกับการกำหนดค่า vCPU ที่เหมาะสม เพื่อเลือกการกำหนดค่าที่ดีที่สุดสำหรับปริมาณงานของคุณ
สำหรับงานที่มีการสับเปลี่ยนจำนวนมาก ขอแนะนำให้ใช้ดิสก์ขนาดใหญ่ คุณสามารถแนบดิสก์ได้สูงสุด 200 GB กับผู้ปฏิบัติงานแต่ละคนเมื่อคุณสร้างแอปพลิเคชันของคุณ การใช้ vCPU ขนาดใหญ่ (spark.executor.cores) ต่อตัวดำเนินการอาจเพิ่มการใช้งานดิสก์ของผู้ปฏิบัติงานแต่ละคน หากแอปพลิเคชันของคุณล้มเหลวด้วย “ไม่มีพื้นที่เหลือในอุปกรณ์” เนื่องจากไม่สามารถใส่ข้อมูลแบบสุ่มในดิสก์ได้ ให้ใช้พนักงานขนาดเล็กที่มีดิสก์ 200 GB
สรุป
ในโพสต์นี้ คุณได้เรียนรู้เกี่ยวกับประโยชน์ของการใช้ตัวดำเนินการขนาดใหญ่สำหรับงาน EMR Serverless ของคุณ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการกำหนดค่าผู้ปฏิบัติงานที่แตกต่างกัน โปรดดูที่ การกำหนดค่าผู้ปฏิบัติงาน. การกำหนดค่าผู้ปฏิบัติงานขนาดใหญ่มีให้บริการในทุกภูมิภาคที่มี EMR Serverless ใช้ได้.
เกี่ยวกับผู้เขียน
 วีณา วสุเทวัญ เป็นสถาปนิกโซลูชันคู่ค้าอาวุโสและผู้เชี่ยวชาญ Amazon EMR ที่ AWS โดยมุ่งเน้นที่ข้อมูลขนาดใหญ่และการวิเคราะห์ เธอช่วยลูกค้าและพันธมิตรสร้างโซลูชันที่เพิ่มประสิทธิภาพ ปรับขนาดได้ และปลอดภัย; ปรับปรุงสถาปัตยกรรมให้ทันสมัย และย้ายปริมาณงานข้อมูลขนาดใหญ่ไปยัง AWS
วีณา วสุเทวัญ เป็นสถาปนิกโซลูชันคู่ค้าอาวุโสและผู้เชี่ยวชาญ Amazon EMR ที่ AWS โดยมุ่งเน้นที่ข้อมูลขนาดใหญ่และการวิเคราะห์ เธอช่วยลูกค้าและพันธมิตรสร้างโซลูชันที่เพิ่มประสิทธิภาพ ปรับขนาดได้ และปลอดภัย; ปรับปรุงสถาปัตยกรรมให้ทันสมัย และย้ายปริมาณงานข้อมูลขนาดใหญ่ไปยัง AWS
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/amazon-emr-serverless-supports-larger-worker-sizes-to-run-more-compute-and-memory-intensive-workloads/
- 1
- 10
- 100
- 11
- 2%
- 7
- 70
- 9
- ลด 95%
- a
- เกี่ยวกับเรา
- ข้าม
- การกระทำ
- กับ
- การรวมตัว
- ทั้งหมด
- จัดสรร
- การจัดสรร
- การอนุญาต
- ช่วยให้
- อเมซอน
- อเมซอน EMR
- จำนวน
- การวิเคราะห์
- การวิเคราะห์
- และ
- ประกาศ
- ทุกแห่ง
- อาปาเช่
- Apache Spark
- APIs
- การใช้งาน
- การใช้งาน
- การประยุกต์ใช้
- แนบ
- อัตโนมัติ
- อัตโนมัติ
- ใช้ได้
- หลีกเลี่ยง
- AWS
- แบนด์วิดธ์
- ตาม
- เพราะ
- กำลัง
- มาตรฐาน
- เป็นประโยชน์
- ประโยชน์
- ประโยชน์ที่ได้รับ
- ที่ดีที่สุด
- ดีกว่า
- ใหญ่
- ข้อมูลขนาดใหญ่
- ปิดกั้น
- Blocks
- การส่งเสริม
- คอขวด
- สร้าง
- แคช
- ความจุ
- กรณี
- กรณี
- ที่เกิดจาก
- การเปลี่ยนแปลง
- เปลี่ยนแปลง
- Choose
- ปิดหน้านี้
- Cluster
- รหัส
- รวบรวม
- ชุด
- คอลัมน์
- ร่วมกัน
- อย่างธรรมดา
- เมื่อเทียบกับ
- ประนีประนอม
- การคำนวณ
- คำนวณ
- องค์ประกอบ
- การกำหนดค่า
- พิจารณา
- คงเส้นคงวา
- สิ่งแวดล้อม
- สอดคล้อง
- ราคา
- ได้
- สร้าง
- การสร้าง
- ลูกค้า
- DAG
- ข้อมูล
- ชุดข้อมูล
- ค่าเริ่มต้น
- กำหนด
- องศา
- สาธิต
- การตรวจพบ
- กำหนด
- ความแตกต่าง
- ต่าง
- สนทนา
- การกระจาย
- ไม่
- Dont
- ลง
- คนขับรถ
- ในระหว่าง
- พลวัต
- แต่ละ
- ช่วยให้
- ส่งเสริม
- พอ
- ข้อผิดพลาด
- โดยเฉพาะอย่างยิ่ง
- อีเธอร์ (ETH)
- แม้
- ทุกๆ
- ตัวอย่าง
- ตัวอย่าง
- ตลาดแลกเปลี่ยน
- แลกเปลี่ยน
- ตื่นเต้น
- ดำเนินการ
- ที่คาดหวัง
- แพง
- กว้างขวาง
- ปัจจัย
- ล้มเหลว
- ล้มเหลว
- ไกล
- เร็วขึ้น
- เป็นไปได้
- ดึงข้อมูลแล้ว
- สองสาม
- เนื้อไม่มีมัน
- ไฟล์
- พอดี
- การแก้ไข
- โดยมุ่งเน้น
- ดังต่อไปนี้
- ดังต่อไปนี้
- FRAME
- กรอบ
- การหลอกลวง
- การตรวจจับการฉ้อโกง
- ราคาเริ่มต้นที่
- อย่างเต็มที่
- ฟังก์ชั่น
- ได้รับ
- ครึ่ง
- จัดการ
- มี
- ช่วย
- จะช่วยให้
- สูงกว่า
- อย่างสูง
- ประวัติ
- รัง
- อย่างไรก็ตาม
- HTML
- HTTPS
- ใหญ่
- ส่งผลกระทบ
- ปรับปรุง
- การปรับปรุง
- การปรับปรุง
- การปรับปรุง
- in
- การไร้ความสามารถ
- เงินได้
- ขาเข้า
- เพิ่ม
- เพิ่มขึ้น
- ข้อมูล
- ข้อมูล
- อินพุต
- แทน
- ร่วมมือ
- IT
- ซ้ำ
- การสัมภาษณ์
- งาน
- ร่วม
- เก็บ
- ใหญ่
- ที่มีขนาดใหญ่
- ใหญ่ที่สุด
- เปิดตัว
- นำ
- นำไปสู่
- ได้เรียนรู้
- ชั้น
- LIMIT
- ในประเทศ
- ในท้องถิ่น
- ดู
- ที่ต้องการหา
- การทำ
- การจัดการ
- สูงสุด
- วัด
- พบ
- หน่วยความจำ
- ตัวชี้วัด
- อพยพ
- นาที
- โหมด
- ทันสมัย
- การตรวจสอบ
- ข้อมูลเพิ่มเติม
- มากที่สุด
- MS
- หลาย
- จำเป็นต้อง
- ความต้องการ
- เครือข่าย
- สัญญาณรบกวน
- ปกติ
- จำนวน
- ได้รับ
- เสนอ
- การเสนอ
- เสนอ
- ONE
- โอเพนซอร์ส
- การดำเนินการ
- การดำเนินการ
- การปรับให้เหมาะสม
- การเพิ่มประสิทธิภาพ
- ใบสั่ง
- อื่นๆ
- ทั้งหมด
- หุ้นส่วน
- พาร์ทเนอร์
- จุดสูงสุด
- ดำเนินการ
- การปฏิบัติ
- ดำเนินการ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- ประชากร
- เป็นไปได้
- โพสต์
- ที่มีศักยภาพ
- ที่อาจเกิดขึ้น
- ก่อนหน้านี้
- กระบวนการ
- กระบวนการ
- การประมวลผล
- ผลิตภัณฑ์
- การผลิต
- ให้
- อัตราส่วน
- อ่าน
- แนะนำ
- บันทึก
- ลด
- ภูมิภาค
- การเผยแพร่
- ที่เหลืออยู่
- รีโมท
- ร้องขอ
- ความต้องการ
- ต้อง
- ลิขสิทธิ์
- ทรัพยากร
- แหล่งข้อมูล
- ทบทวน
- วิ่ง
- วิ่ง
- เดียวกัน
- ลด
- ที่ปรับขนาดได้
- ขนาด
- ตาชั่ง
- ปรับ
- สถานการณ์
- สถานการณ์
- ที่สอง
- วินาที
- Section
- ปลอดภัย
- ระดับอาวุโส
- serverless
- เซิร์ฟเวอร์
- ชุด
- การตั้งค่า
- หลาย
- ที่ใช้ร่วมกัน
- แสดง
- แสดงให้เห็นว่า
- สับเปลี่ยน
- สำคัญ
- อย่างมีความหมาย
- คล้ายคลึงกัน
- เหมือนกับ
- เดียว
- ขนาด
- ขนาด
- เอียง
- เล็ก
- มีขนาดเล็กกว่า
- So
- จนถึงตอนนี้
- โซลูชัน
- บาง
- ช่องว่าง
- จุดประกาย
- ผู้เชี่ยวชาญ
- SQL
- ระยะ
- ขั้นตอน
- การเก็บรักษา
- จัดเก็บ
- กลยุทธ์
- ประสบความสำเร็จ
- อย่างเช่น
- ฉับพลัน
- เพียงพอ
- เหมาะสม
- รองรับ
- พรั่ง
- ฉลาด
- ตาราง
- เอา
- ใช้เวลา
- การ
- งาน
- งาน
- เงื่อนไขการใช้บริการ
- ทดสอบ
- การทดสอบ
- พื้นที่
- ของพวกเขา
- ดังนั้น
- ปริมาณงาน
- การขว้างปา
- เวลา
- ครั้ง
- ไปยัง
- เครื่องมือ
- ด้านบน
- รวม
- ลู่
- การแปลง
- การแปลง
- กลับ
- ชนิด
- เป็นปกติ
- ui
- พื้นฐาน
- เป็นประวัติการณ์
- การใช้
- ใช้
- ใช้
- ความคุ้มค่า
- ปริมาณ
- ไดรฟ์
- ที่
- ในขณะที่
- กว้าง
- จะ
- ไม่มี
- ผู้ปฏิบัติงาน
- แรงงาน
- เขียน
- ของคุณ
- ลมทะเล