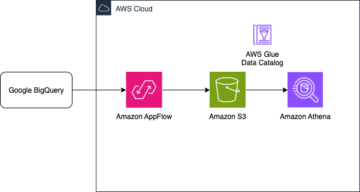
องค์กรต่างๆ ได้เลือกที่จะสร้าง Data Lake ไว้ด้านบน บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) มาหลายปีแล้ว Data Lake เป็นตัวเลือกยอดนิยมสำหรับองค์กรในการจัดเก็บข้อมูลองค์กรทั้งหมดที่สร้างขึ้นโดยทีมต่างๆ ทั่วทั้งโดเมนธุรกิจ จากรูปแบบที่แตกต่างกันทั้งหมด และแม้แต่ประวัติ ตาม เรียนบริษัทโดยเฉลี่ยจะเห็นปริมาณข้อมูลที่เพิ่มขึ้นในอัตราที่เกิน 50% ต่อปี โดยปกติแล้วจะจัดการแหล่งข้อมูลที่ไม่ซ้ำกันเฉลี่ย 33 แห่งเพื่อการวิเคราะห์
ทีมมักจะพยายามจำลองงานนับพันงานจากฐานข้อมูลเชิงสัมพันธ์ด้วยรูปแบบการแยก การแปลง และโหลด (ETL) เดียวกัน มีความพยายามอย่างมากในการรักษาสถานะงานและกำหนดเวลางานแต่ละงานเหล่านี้ แนวทางนี้ช่วยให้ทีมเพิ่มตารางโดยมีการเปลี่ยนแปลงเล็กน้อย และยังรักษาสถานะของงานโดยใช้ความพยายามเพียงเล็กน้อย สิ่งนี้สามารถนำไปสู่การปรับปรุงอย่างมากในไทม์ไลน์การพัฒนาและการติดตามงานได้อย่างง่ายดาย
ในโพสต์นี้ เราจะแสดงวิธีจำลองที่เก็บข้อมูลเชิงสัมพันธ์ทั้งหมดของคุณลงใน Data Lake ของธุรกรรมในรูปแบบอัตโนมัติด้วยงาน ETL เดียวโดยใช้ Apache Iceberg และ AWS กาว.
สถาปัตยกรรมโซลูชัน
Data Lake คือ มักจะจัด การใช้บัคเก็ต S3 แยกต่างหากสำหรับข้อมูลสามชั้น ได้แก่ เลเยอร์ดิบที่มีข้อมูลในรูปแบบดั้งเดิม เลเยอร์สเตจที่มีข้อมูลที่ประมวลผลระดับกลางที่ปรับให้เหมาะสมสำหรับการใช้งาน และเลเยอร์การวิเคราะห์ที่มีข้อมูลที่รวบรวมไว้สำหรับกรณีการใช้งานเฉพาะ ในเลเยอร์ Raw ตารางมักจะได้รับการจัดระเบียบตามแหล่งข้อมูล ในขณะที่ตารางในเลเยอร์ Stage จะถูกจัดระเบียบตามโดเมนธุรกิจที่ตารางนั้นอยู่
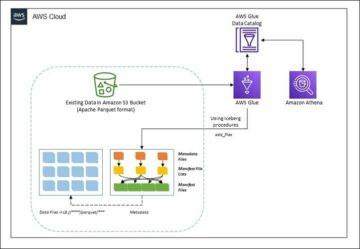
โพสต์นี้ให้ การก่อตัวของ AWS Cloud เทมเพลตที่ปรับใช้งาน AWS Glue ที่อ่านเส้นทาง Amazon S3 สำหรับแหล่งข้อมูลเดียวของเลเยอร์ดิบ Data Lake และนำเข้าข้อมูลลงในตาราง Apache Iceberg บนเลเยอร์สเตจโดยใช้ รองรับ AWS Glue สำหรับเฟรมเวิร์ก Data Lake. งานคาดหวังว่าตารางในเลเยอร์ดิบจะต้องมีโครงสร้างในลักษณะเดียวกัน บริการย้ายฐานข้อมูล AWS (AWS DMS) นำเข้าข้อมูลเหล่านี้: สคีมา ตาราง และไฟล์ข้อมูล
วิธีนี้ใช้ ที่เก็บพารามิเตอร์ AWS Systems Manager สำหรับการกำหนดค่าตาราง คุณควรแก้ไขพารามิเตอร์นี้โดยระบุตารางที่คุณต้องการประมวลผลและวิธีการ รวมถึงข้อมูล เช่น คีย์หลัก พาร์ติชัน และโดเมนธุรกิจที่เกี่ยวข้อง งานจะใช้ข้อมูลนี้เพื่อสร้างฐานข้อมูลโดยอัตโนมัติ (หากยังไม่มี) สำหรับทุกโดเมนธุรกิจ สร้างตาราง Iceberg และดำเนินการโหลดข้อมูล
สุดท้ายเราก็ใช้ อเมซอน อาเธน่า เพื่อสืบค้นข้อมูลในตารางภูเขาน้ำแข็ง
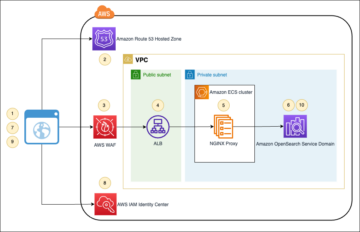
ไดอะแกรมต่อไปนี้แสดงสถาปัตยกรรมนี้

การใช้งานนี้มีข้อควรพิจารณาดังต่อไปนี้:
- ตารางทั้งหมดจากแหล่งข้อมูลต้องมีคีย์หลักที่จะจำลองแบบโดยใช้โซลูชันนี้ คีย์หลักอาจเป็นคอลัมน์เดียวหรือคีย์ผสมที่มีมากกว่าหนึ่งคอลัมน์ก็ได้
- หาก Data Lake มีตารางที่ไม่จำเป็นต้องเพิ่มหรือไม่มีคีย์หลัก คุณสามารถแยกตารางเหล่านั้นออกจากการกำหนดค่าพารามิเตอร์ และใช้กระบวนการ ETL แบบดั้งเดิมเพื่อนำเข้าข้อมูลเหล่านั้นลงใน Data Lake นั่นอยู่นอกขอบเขตของโพสต์นี้
- หากมีแหล่งข้อมูลเพิ่มเติมที่จำเป็นต้องนำเข้า คุณสามารถปรับใช้สแต็ก CloudFormation หลายสแต็ก โดยหนึ่งสแต็กเพื่อจัดการแหล่งข้อมูลแต่ละแห่ง
- งาน AWS Glue ได้รับการออกแบบมาเพื่อประมวลผลข้อมูลในสองเฟส ได้แก่ โหลดเริ่มต้นที่ทำงานหลังจาก AWS DMS เสร็จสิ้นงานโหลดทั้งหมด และโหลดส่วนเพิ่มที่ทำงานตามกำหนดเวลาที่ใช้ไฟล์ Change Data Capture (CDC) ที่ AWS DMS จับ การประมวลผลส่วนเพิ่มจะดำเนินการโดยใช้ บุ๊กมาร์กงาน AWS Glue.
มีเก้าขั้นตอนในการทำบทช่วยสอนนี้ให้เสร็จสิ้น:
- ตั้งค่าตำแหน่งข้อมูลต้นทางสำหรับ AWS DMS
- ปรับใช้โซลูชันโดยใช้ AWS CloudFormation
- ตรวจสอบงานการจำลอง AWS DMS
- คุณสามารถเลือกเพิ่มสิทธิ์สำหรับการเข้ารหัสและถอดรหัสหรือ การก่อตัวของทะเลสาบ AWS.
- ตรวจสอบการกำหนดค่าตารางในที่เก็บพารามิเตอร์
- ทำการโหลดข้อมูลเบื้องต้น
- ทำการโหลดข้อมูลส่วนเพิ่ม
- ตรวจสอบการนำเข้าตาราง
- กำหนดเวลาการโหลดข้อมูลแบทช์ที่เพิ่มขึ้น
เบื้องต้น
ก่อนที่จะเริ่มบทช่วยสอนนี้ คุณควรจะคุ้นเคยกับ Iceberg เสียก่อน หากคุณไม่ใช่ คุณสามารถเริ่มต้นด้วยการจำลองตารางเดียวโดยทำตามคำแนะนำใน นำ UPSERT ที่ใช้ CDC ไปใช้ใน Data Lake โดยใช้ Apache Iceberg และ AWS Glue. นอกจากนี้ ให้ตั้งค่าต่อไปนี้:
ตั้งค่าตำแหน่งข้อมูลต้นทางสำหรับ AWS DMS
ก่อนที่เราจะสร้างงาน AWS DMS เราจำเป็นต้องตั้งค่าตำแหน่งข้อมูลต้นทางเพื่อเชื่อมต่อกับฐานข้อมูลต้นทาง:
- บนคอนโซล AWS DMS ให้เลือก ปลายทาง ในบานหน้าต่างนำทาง
- Choose สร้างปลายทาง.
- หากฐานข้อมูลของคุณทำงานบน Amazon RDS ให้เลือก เลือกอินสแตนซ์ DB RDSจากนั้นเลือกอินสแตนซ์จากรายการ มิฉะนั้น ให้เลือกเอ็นจิ้นต้นทางและระบุข้อมูลการเชื่อมต่อผ่าน ผู้จัดการความลับของ AWS หรือด้วยตนเอง
- สำหรับ ตัวระบุปลายทางป้อนชื่อปลายทาง ตัวอย่างเช่น source-postgresql.
- Choose สร้างปลายทาง.
ปรับใช้โซลูชันโดยใช้ AWS CloudFormation
สร้างสแต็ก CloudFormation โดยใช้เทมเพลตที่ให้มา ทำตามขั้นตอนต่อไปนี้:
- Choose เปิดตัวกอง:

- Choose ถัดไป.
- ระบุชื่อสแต็ก เช่น
transactionaldl-postgresql. - ป้อนพารามิเตอร์ที่จำเป็น:
- DMSS3จุดสิ้นสุดIAMRoleARN – บทบาท IAM ARN สำหรับ AWS DMS เพื่อเขียนข้อมูลลงใน Amazon S3
- ReplicationInstanceArn – อินสแตนซ์การจำลอง AWS DMS ARN
- S3BucketStage – ชื่อของบัคเก็ตที่มีอยู่ซึ่งใช้สำหรับเลเยอร์สเตจของ Data Lake
- S3Bucketกาว – ชื่อของบัคเก็ต S3 ที่มีอยู่สำหรับจัดเก็บสคริปต์ AWS Glue
- S3BucketRaw – ชื่อของบัคเก็ตที่มีอยู่ซึ่งใช้สำหรับเลเยอร์ดิบของ Data Lake
- แหล่งที่มาEndpointArn – ARN ตำแหน่งข้อมูล AWS DMS ที่คุณสร้างไว้ก่อนหน้านี้
- SourceName – ตัวระบุที่กำหนดเองของแหล่งข้อมูลที่จะทำซ้ำ (เช่น
postgres). ใช้เพื่อกำหนดเส้นทาง S3 ของ Data Lake (เลเยอร์ดิบ) ที่จะจัดเก็บข้อมูล
- ห้ามแก้ไขพารามิเตอร์ต่อไปนี้:
- ที่มา S3BucketBlog – ชื่อบัคเก็ตที่เก็บสคริปต์ AWS Glue ที่ให้ไว้
- SourceS3BucketPrefix – ชื่อคำนำหน้าบัคเก็ตที่เก็บสคริปต์ AWS Glue ที่ให้ไว้
- Choose ถัดไป สองครั้ง
- เลือก ฉันรับทราบว่า AWS CloudFormation อาจสร้างทรัพยากร IAM ด้วยชื่อที่กำหนดเอง
- Choose สร้าง stack.
หลังจากผ่านไปประมาณ 5 นาที สแต็ก CloudFormation ก็จะถูกปรับใช้
ตรวจสอบงานการจำลอง AWS DMS
การปรับใช้ AWS CloudFormation ได้สร้างตำแหน่งข้อมูลเป้าหมาย AWS DMS ให้กับคุณ เนื่องจากการตั้งค่าตำแหน่งข้อมูลเฉพาะสองรายการ ข้อมูลจะถูกนำเข้าตามที่เราต้องการบน Amazon S3
- บนคอนโซล AWS DMS ให้เลือก ปลายทาง ในบานหน้าต่างนำทาง
- ค้นหาและเลือกปลายทางที่ขึ้นต้นด้วย
dmsIcebergs3endpoint. - ตรวจสอบการตั้งค่าปลายทาง:
DataFormatถูกกำหนดเป็นparquet.TimestampColumnNameจะเพิ่มคอลัมน์last_update_timeพร้อมวันที่สร้างบันทึกบน Amazon S3

การปรับใช้ยังสร้างงานการจำลองแบบ AWS DMS ที่เริ่มต้นด้วย dmsicebergtask.
- Choose งานจำลองแบบ ในบานหน้าต่างนำทางและค้นหางาน
คุณจะเห็นว่า ประเภทงาน ถูกทำเครื่องหมายเป็น โหลดเต็ม การจำลองแบบต่อเนื่อง. AWS DMS จะดำเนินการโหลดข้อมูลที่มีอยู่เต็มครั้งแรก จากนั้นสร้างไฟล์ส่วนเพิ่มโดยมีการเปลี่ยนแปลงกับฐานข้อมูลต้นทาง
เกี่ยวกับ กฎการทำแผนที่ แท็บ มีกฎสองประเภท:
- กฎการเลือกที่มีชื่อของสคีมาต้นทางและตารางที่จะถูกนำเข้าจากฐานข้อมูลต้นทาง โดยค่าเริ่มต้น จะใช้ฐานข้อมูลตัวอย่างที่ให้ไว้ในข้อกำหนดเบื้องต้น
dms_sampleและตารางทั้งหมดที่มีคีย์เวิร์ด % - กฎการแปลงสองกฎที่รวมชื่อสคีมาและชื่อตารางไว้ในไฟล์เป้าหมายบน Amazon S3 เป็นคอลัมน์ งาน AWS Glue ของเราใช้สิ่งนี้เพื่อให้ทราบว่าไฟล์ใน Data Lake สอดคล้องกับตารางใด
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับวิธีการปรับแต่งสิ่งนี้สำหรับแหล่งข้อมูลของคุณเอง โปรดดูที่ กฎการคัดเลือกและการดำเนินการ.

มาเปลี่ยนการกำหนดค่าบางอย่างเพื่อเตรียมงานให้เสร็จ
- เกี่ยวกับ สถานะ เมนูให้เลือก แก้ไข.
- ตัว Vortex Indicator ได้ถูกนำเสนอลงในนิตยสาร การตั้งค่างาน ส่วนใต้ หยุดงานหลังจากโหลดเต็มเลือก หยุดหลังจากใช้การเปลี่ยนแปลงที่แคชไว้.
ด้วยวิธีนี้ เราสามารถควบคุมการโหลดครั้งแรกและการสร้างไฟล์ส่วนเพิ่มเป็นสองขั้นตอนที่แตกต่างกัน เราใช้วิธีการสองขั้นตอนนี้เพื่อรันงาน AWS Glue หนึ่งครั้งต่อแต่ละขั้นตอน
- ภายใต้ บันทึกงานเลือก เปิดบันทึก CloudWatch.
- Choose ลด.
- รอประมาณ 1 นาทีเพื่อให้สถานะงานการย้ายฐานข้อมูลแสดงเป็น พร้อม.
เพิ่มสิทธิ์สำหรับการเข้ารหัสและถอดรหัสหรือ Lake Formation
คุณสามารถเลือกเพิ่มสิทธิ์สำหรับการเข้ารหัสและถอดรหัสหรือ Lake Formation ได้
เพิ่มสิทธิ์การเข้ารหัสและถอดรหัส
หากบัคเก็ต S3 ของคุณที่ใช้สำหรับเลเยอร์ Raw และ Stage ได้รับการเข้ารหัสโดยใช้ บริการจัดการคีย์ AWS คีย์ที่จัดการโดยลูกค้า (AWS KMS) คุณต้องเพิ่มสิทธิ์เพื่ออนุญาตให้งาน AWS Glue เข้าถึงข้อมูลได้:
เพิ่มสิทธิ์การสร้างทะเลสาบ
หากคุณกำลังจัดการสิทธิ์โดยใช้ Lake Formation คุณจะต้องอนุญาตให้งาน AWS Glue ของคุณสร้างฐานข้อมูลและตารางของโดเมนของคุณผ่านบทบาท IAM GlueJobRole.
- ให้สิทธิ์ในการสร้างฐานข้อมูล (สำหรับคำแนะนำ โปรดดูที่ การสร้างฐานข้อมูล).
- ให้สิทธิ์ SUPER แก่
defaultฐานข้อมูล - ให้สิทธิ์เข้าถึงตำแหน่งข้อมูล.
- หากคุณสร้างฐานข้อมูลด้วยตนเอง ให้ให้สิทธิ์กับฐานข้อมูลทั้งหมดเพื่อสร้างตาราง อ้างถึง การให้สิทธิ์ตารางโดยใช้คอนโซล Lake Formation และวิธีการทรัพยากรที่ระบุชื่อ or การให้สิทธิ์ Data Catalog โดยใช้วิธี LF-TBAC ตามกรณีการใช้งานของคุณ
หลังจากที่คุณเสร็จสิ้นขั้นตอนภายหลังของการดำเนินการโหลดข้อมูลเริ่มต้นแล้ว ตรวจสอบให้แน่ใจว่าได้เพิ่มสิทธิ์สำหรับผู้ใช้บริการในการสืบค้นตารางด้วย บทบาทของงานจะกลายเป็นเจ้าของตารางทั้งหมดที่สร้างขึ้น และผู้ดูแลระบบ Data Lake จะสามารถดำเนินการมอบสิทธิ์ให้กับผู้ใช้เพิ่มเติมได้
ตรวจสอบการกำหนดค่าตารางในที่เก็บพารามิเตอร์
งาน AWS Glue ที่ดำเนินการนำเข้าข้อมูลลงในตาราง Iceberg จะใช้ข้อกำหนดของตารางที่ให้ไว้ในที่เก็บพารามิเตอร์ ทำตามขั้นตอนต่อไปนี้เพื่อตรวจสอบที่เก็บพารามิเตอร์ที่กำหนดค่าไว้โดยอัตโนมัติสำหรับคุณ หากจำเป็นให้ปรับเปลี่ยนตามความต้องการของคุณเอง
- บนคอนโซลที่เก็บพารามิเตอร์ ให้เลือก พารามิเตอร์ของฉัน ในบานหน้าต่างนำทาง
สแต็ก CloudFormation สร้างพารามิเตอร์ XNUMX ตัว:
iceberg-configสำหรับการกำหนดค่างานiceberg-tablesสำหรับการกำหนดค่าตาราง
- เลือกพารามิเตอร์ ภูเขาน้ำแข็ง-ตาราง.
โครงสร้าง JSON ประกอบด้วยข้อมูลที่ AWS Glue ใช้เพื่ออ่านข้อมูลและเขียนตาราง Iceberg บนโดเมนเป้าหมาย:
- หนึ่งวัตถุต่อตาราง – ชื่อของออบเจ็กต์ถูกสร้างขึ้นโดยใช้ชื่อสคีมา จุด และชื่อตาราง ตัวอย่างเช่น,
schema.table. - คีย์หลัก – ควรระบุสิ่งนี้ให้กับทุกตารางต้นฉบับ คุณสามารถระบุคอลัมน์เดียวหรือรายการคอลัมน์ที่คั่นด้วยเครื่องหมายจุลภาค (โดยไม่ต้องเว้นวรรค)
- พาร์ทิชัน Cols – ตัวเลือกนี้จะแบ่งพาร์ติชันคอลัมน์สำหรับตารางเป้าหมาย หากคุณไม่ต้องการสร้างตารางที่แบ่งพาร์ติชัน ให้ระบุสตริงว่าง มิฉะนั้น ให้ระบุคอลัมน์เดียวหรือรายการคอลัมน์ที่คั่นด้วยเครื่องหมายจุลภาคที่จะใช้ (โดยไม่ต้องเว้นวรรค)
- หากคุณต้องการใช้แหล่งข้อมูลของคุณเอง ให้ใช้โค้ด JSON ต่อไปนี้และแทนที่ข้อความเป็นตัวพิมพ์ใหญ่จากเทมเพลตที่ให้ไว้ หากคุณใช้แหล่งข้อมูลตัวอย่างที่ให้ไว้ ให้คงการตั้งค่าเริ่มต้นไว้:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Choose บันทึกการเปลี่ยนแปลง.
ทำการโหลดข้อมูลเบื้องต้น
เมื่อการกำหนดค่าที่จำเป็นเสร็จสิ้นแล้ว เราจะนำเข้าข้อมูลเริ่มต้น ขั้นตอนนี้ประกอบด้วยสามส่วน: การนำเข้าข้อมูลจากฐานข้อมูลเชิงสัมพันธ์ต้นทางไปยังเลเยอร์ดิบของ Data Lake การสร้างตารางภูเขาน้ำแข็งบนเลเยอร์สเตจของ Data Lake และการตรวจสอบผลลัพธ์โดยใช้ Athena
นำเข้าข้อมูลเข้าสู่เลเยอร์ดิบของ Data Lake
หากต้องการนำเข้าข้อมูลจากแหล่งข้อมูลเชิงสัมพันธ์ (PostgreSQL หากคุณใช้ตัวอย่างที่ให้มา) ไปยัง Data Lake ธุรกรรมของเราโดยใช้ Iceberg ให้ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล AWS DMS ให้เลือก งานการย้ายฐานข้อมูล ในบานหน้าต่างนำทาง
- เลือกงานการจำลองแบบที่คุณสร้างขึ้นและบน สถานะ เมนูให้เลือก เริ่มต้นใหม่/ดำเนินการต่อ.
- รอประมาณ 5 นาทีสำหรับงานการจำลองแบบให้เสร็จสมบูรณ์ คุณสามารถตรวจสอบตารางที่นำเข้ามาได้ สถิติ แท็บของงานการจำลองแบบ

หลังจากผ่านไปสักครู่ งานก็เสร็จสิ้นพร้อมกับข้อความ โหลดเต็มที่แล้ว.
- บนคอนโซล Amazon S3 ให้เลือกบัคเก็ตที่คุณกำหนดเป็นเลเยอร์ดิบ
ภายใต้คำนำหน้า S3 ที่กำหนดบน AWS DMS (ตัวอย่างเช่น postgres) คุณควรเห็นลำดับชั้นของโฟลเดอร์ที่มีโครงสร้างดังต่อไปนี้:
- schema
- ชื่อตาราง
LOAD00000001.parquetLOAD0000000N.parquet
- ชื่อตาราง

หากบัคเก็ต S3 ของคุณว่างเปล่า ให้ตรวจสอบ การแก้ไขปัญหางานการย้ายใน AWS Database Migration Service ก่อนที่จะรันงาน AWS Glue
สร้างและนำเข้าข้อมูลลงในตาราง Iceberg
ก่อนที่จะรันงาน เรามาสำรวจสคริปต์ของงาน AWS Glue ที่ให้ไว้โดยเป็นส่วนหนึ่งของสแต็ก CloudFormation เพื่อทำความเข้าใจลักษณะการทำงานของงานกันก่อน
- บนคอนโซล AWS Glue Studio ให้เลือก งาน ในบานหน้าต่างนำทาง
- ค้นหางานที่เริ่มต้นด้วย
IcebergJob-และคำต่อท้ายชื่อสแต็ก CloudFormation ของคุณ (เช่นIcebergJob-transactionaldl-postgresql). - เลือกงาน.

สคริปต์งานได้รับการกำหนดค่าที่ต้องการจากที่เก็บพารามิเตอร์ ฟังก์ชั่น getConfigFromSSM() ส่งคืนการกำหนดค่าที่เกี่ยวข้องกับงาน เช่น บัคเก็ตต้นทางและปลายทางที่ต้องการอ่านและเขียนข้อมูล ตัวแปร ssmparam_table_values มีข้อมูลที่เกี่ยวข้องกับตาราง เช่น โดเมนข้อมูล ชื่อตาราง คอลัมน์พาร์ติชัน และคีย์หลักของตารางที่จำเป็นต้องนำเข้า ดูรหัส Python ต่อไปนี้:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']สคริปต์ใช้ชื่อแค็ตตาล็อกที่กำหนดเองสำหรับ Iceberg ที่กำหนดเป็น my_catalog สิ่งนี้ถูกนำไปใช้ใน AWS Glue Data Catalog โดยใช้การกำหนดค่า Spark ดังนั้นการดำเนินการ SQL ที่ชี้ไปที่ my_catalog จะถูกนำไปใช้กับ Data Catalog ดูรหัสต่อไปนี้:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
สคริปต์จะวนซ้ำตารางที่กำหนดไว้ในที่เก็บพารามิเตอร์ และดำเนินการตรรกะในการตรวจสอบว่ามีตารางอยู่หรือไม่ และข้อมูลที่เข้ามาเป็นการโหลดครั้งแรกหรือมีการอัปโหลดหรือไม่:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')พื้นที่ initialLoadRecordsSparkSQL() ฟังก์ชั่นโหลดข้อมูลเริ่มต้นเมื่อไม่มีคอลัมน์การดำเนินการในไฟล์ S3 AWS DMS เพิ่มคอลัมน์นี้ลงในไฟล์ข้อมูล Parquet ที่สร้างโดยการจำลองแบบต่อเนื่อง (CDC) เท่านั้น การโหลดข้อมูลดำเนินการโดยใช้คำสั่ง INSERT INTO กับ SparkSQL ดูรหัสต่อไปนี้:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
ตอนนี้เรารันงาน AWS Glue เพื่อนำเข้าข้อมูลเริ่มต้นลงในตาราง Iceberg สแต็ก CloudFormation เพิ่ม --datalake-formats พารามิเตอร์ โดยเพิ่มไลบรารี Iceberg ที่จำเป็นให้กับงาน
- Choose เรียกใช้งาน.
- Choose งานวิ่ง เพื่อติดตามสถานะ รอจนกระทั่งสถานะเป็น วิ่งสำเร็จ.
ตรวจสอบข้อมูลที่โหลด
เพื่อยืนยันว่างานประมวลผลข้อมูลที่คาดไว้ ให้ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล Athena ให้เลือก ตัวแก้ไขข้อความค้นหา ในบานหน้าต่างนำทาง
- ตรวจสอบ
AwsDataCatalogถูกเลือกเป็นแหล่งข้อมูล - ภายใต้ ฐานข้อมูลให้เลือกโดเมนข้อมูลที่คุณต้องการสำรวจ ตามการกำหนดค่าที่คุณกำหนดไว้ในที่เก็บพารามิเตอร์ หากใช้ฐานข้อมูลตัวอย่างที่ให้มา ให้ใช้
sports.
ภายใต้ ตารางและมุมมองเราจะสามารถดูรายการตารางที่สร้างขึ้นโดยงาน AWS Glue ได้
- เลือกเมนูตัวเลือก (สามจุด) ถัดจากชื่อตารางแรก จากนั้นเลือก แสดงตัวอย่างข้อมูล.
คุณสามารถดูข้อมูลที่โหลดลงในตาราง Iceberg ได้ 
ทำการโหลดข้อมูลส่วนเพิ่ม
ตอนนี้เราเริ่มบันทึกการเปลี่ยนแปลงจากฐานข้อมูลเชิงสัมพันธ์ของเราและนำไปใช้กับ Data Lake ของธุรกรรม ขั้นตอนนี้ยังแบ่งออกเป็นสามส่วน: การจับการเปลี่ยนแปลง การนำไปใช้กับตารางภูเขาน้ำแข็ง และการตรวจสอบผลลัพธ์
บันทึกการเปลี่ยนแปลงจากฐานข้อมูลเชิงสัมพันธ์
เนื่องจากการกำหนดค่าที่เราระบุไว้ งานการจำลองแบบจึงหยุดลงหลังจากรันเฟสการโหลดแบบเต็ม ตอนนี้เราเริ่มงานใหม่เพื่อเพิ่มไฟล์ส่วนเพิ่มที่มีการเปลี่ยนแปลงในเลเยอร์ดิบของ Data Lake
- บนคอนโซล AWS DMS ให้เลือกงานที่เราสร้างและดำเนินการก่อนหน้านี้
- เกี่ยวกับ สถานะ เมนูให้เลือก เรซูเม่.
- Choose เริ่มงาน เพื่อเริ่มบันทึกการเปลี่ยนแปลง
- หากต้องการทริกเกอร์การสร้างไฟล์ใหม่บน Data Lake ให้แทรก อัปเดต หรือลบตารางของฐานข้อมูลต้นทางโดยใช้เครื่องมือการจัดการฐานข้อมูลที่คุณต้องการ หากใช้ฐานข้อมูลตัวอย่างที่ให้มา คุณสามารถรันคำสั่ง SQL ต่อไปนี้:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- ในหน้ารายละเอียดงาน AWS DMS ให้เลือก สถิติตาราง แท็บเพื่อดูการเปลี่ยนแปลงที่บันทึกไว้

- เปิดเลเยอร์ดิบของ Data Lake เพื่อค้นหาไฟล์ใหม่ที่เก็บการเปลี่ยนแปลงส่วนเพิ่มไว้ภายในคำนำหน้าของทุกตาราง เช่น ภายใต้
sporting_eventคำนำหน้า
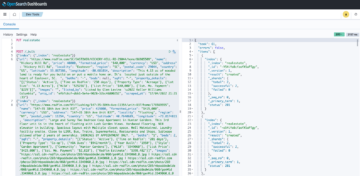
บันทึกที่มีการเปลี่ยนแปลงสำหรับ sporting_event ตารางดูเหมือนภาพหน้าจอต่อไปนี้

สังเกตเห็น Op คอลัมน์ในตอนต้นระบุด้วยการอัปเดต (U). นอกจากนี้ ค่าวันที่/เวลาที่สองคือคอลัมน์ควบคุมที่เพิ่มโดย AWS DMS พร้อมเวลาที่บันทึกการเปลี่ยนแปลง

ใช้การเปลี่ยนแปลงกับตาราง Iceberg โดยใช้ AWS Glue
ตอนนี้เรารันงาน AWS Glue อีกครั้ง และจะประมวลผลเฉพาะไฟล์ที่เพิ่มขึ้นใหม่โดยอัตโนมัติเนื่องจากเปิดใช้งานบุ๊กมาร์กงาน เรามาทบทวนวิธีการทำงานกัน
พื้นที่ dedupCDCRecords() ฟังก์ชันทำการขจัดข้อมูลซ้ำซ้อนเนื่องจากการเปลี่ยนแปลงหลายครั้งในรหัสบันทึกเดียวสามารถบันทึกได้ภายในไฟล์ข้อมูลเดียวกันบน Amazon S3 การขจัดข้อมูลซ้ำซ้อนจะดำเนินการตาม last_update_time คอลัมน์ที่เพิ่มโดย AWS DMS ซึ่งระบุการประทับเวลาเมื่อบันทึกการเปลี่ยนแปลง ดูรหัส Python ต่อไปนี้:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFบนบรรทัด 99 the upsertRecordsSparkSQL() ฟังก์ชันดำเนินการ upsert ในลักษณะเดียวกันกับโหลดเริ่มต้น แต่คราวนี้ใช้คำสั่ง SQL MERGE
ตรวจสอบการเปลี่ยนแปลงที่ใช้
เปิดคอนโซล Athena และเรียกใช้แบบสอบถามที่เลือกบันทึกที่เปลี่ยนแปลงในฐานข้อมูลต้นทาง หากใช้ฐานข้อมูลตัวอย่างที่ให้มา ให้ใช้แบบสอบถาม SQL ต่อไปนี้:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

ตรวจสอบการนำเข้าตาราง
สคริปต์งาน AWS Glue ได้รับการเข้ารหัสอย่างง่าย การจัดการข้อยกเว้นของ Python เพื่อตรวจจับข้อผิดพลาดระหว่างการประมวลผลตารางเฉพาะ บุ๊กมาร์กงานจะถูกบันทึกหลังจากที่แต่ละตารางเสร็จสิ้นการประมวลผลเรียบร้อยแล้ว เพื่อหลีกเลี่ยงการประมวลผลตารางใหม่ หากลองเรียกใช้งานอีกครั้งสำหรับตารางที่มีข้อผิดพลาด
พื้นที่ อินเทอร์เฟซบรรทัดคำสั่ง AWS AWS (AWS CLI) ให้ get-job-bookmark คำสั่งสำหรับ AWS Glue ที่ให้ข้อมูลเชิงลึกเกี่ยวกับสถานะของบุ๊กมาร์กสำหรับแต่ละตารางที่ประมวลผล
- บนคอนโซล AWS Glue Studio ให้เลือกงาน ETL
- เลือก งานวิ่ง แท็บและคัดลอก ID การรันงาน
- เรียกใช้คำสั่งต่อไปนี้บนเทอร์มินัลที่ได้รับการตรวจสอบสิทธิ์สำหรับ AWS CLI โดยแทนที่
<GLUE_JOB_RUN_ID>ในบรรทัด 1 ด้วยค่าที่คุณคัดลอก หากไม่ได้ตั้งชื่อสแต็ก CloudFormation ของคุณtransactionaldl-postgresqlระบุชื่องานของคุณในบรรทัดที่ 2 ของสคริปต์:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunในโซลูชันนี้ เมื่อการประมวลผลตารางทำให้เกิดข้อยกเว้น งาน AWS Glue จะไม่ล้มเหลวตามตรรกะนี้ แต่ตารางจะถูกเพิ่มลงในอาร์เรย์ที่พิมพ์หลังจากงานเสร็จสมบูรณ์แทน ในสถานการณ์ดังกล่าว งานจะถูกทำเครื่องหมายว่าล้มเหลวหลังจากที่พยายามประมวลผลตารางที่เหลือที่ตรวจพบในแหล่งข้อมูลดิบ ด้วยวิธีนี้ ตารางที่ไม่มีข้อผิดพลาดไม่จำเป็นต้องรอจนกว่าผู้ใช้จะระบุและแก้ไขปัญหาในตารางที่ขัดแย้งกัน ผู้ใช้สามารถตรวจจับการรันงานที่มีปัญหาได้อย่างรวดเร็วโดยใช้สถานะการรันงาน AWS Glue และระบุตารางใดที่เป็นสาเหตุของปัญหาโดยใช้บันทึก CloudWatch สำหรับการรันงาน
- สคริปต์งานใช้คุณลักษณะนี้กับโค้ด Python ต่อไปนี้:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')ภาพหน้าจอต่อไปนี้แสดงวิธีที่บันทึกของ CloudWatch ค้นหาตารางที่ทำให้เกิดข้อผิดพลาดในการประมวลผล

สอดคล้องกับ เลนส์วิเคราะห์ข้อมูลกรอบงาน AWS Well-Architected แนวทางปฏิบัติ คุณสามารถปรับกลไกการควบคุมที่ซับซ้อนมากขึ้นเพื่อระบุและแจ้งให้ผู้มีส่วนได้ส่วนเสียทราบเมื่อเกิดข้อผิดพลาดบนไปป์ไลน์ข้อมูล ตัวอย่างเช่น คุณสามารถใช้ อเมซอน ไดนาโมดีบี ตารางควบคุมเพื่อจัดเก็บตารางและงานทั้งหมดที่มีข้อผิดพลาดหรือใช้ บริการแจ้งเตือนแบบง่ายของ Amazon (อเมซอน SNS) ถึง ส่งการแจ้งเตือนไปยังผู้ปฏิบัติงาน เมื่อเป็นไปตามเกณฑ์ที่กำหนด
กำหนดเวลาการโหลดข้อมูลแบทช์ที่เพิ่มขึ้น
สแต็ก CloudFormation ปรับใช้ไฟล์ อเมซอน EventBridge กฎ (ปิดใช้งานโดยค่าเริ่มต้น) ที่สามารถทริกเกอร์งาน AWS Glue ให้ทำงานตามกำหนดเวลาได้ หากต้องการจัดเตรียมกำหนดการของคุณเองและเปิดใช้งานกฎ ให้ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล EventBridge เลือก กฎระเบียบ ในบานหน้าต่างนำทาง
- ค้นหากฎที่นำหน้าด้วยชื่อสแต็ก CloudFormation ของคุณตามด้วย
JobTrigger(ตัวอย่างเช่น,transactionaldl-postgresql-JobTrigger-randomvalue). - เลือกกฎ
- ภายใต้ กำหนดการ การแข่งขันเลือก Edit.
กำหนดการเริ่มต้นได้รับการกำหนดค่าให้ทริกเกอร์ทุกชั่วโมง
- ระบุกำหนดการที่คุณต้องการรันงาน
- นอกจากนี้ คุณสามารถใช้ไฟล์ นิพจน์ cron ของ EventBridge โดยการเลือก กำหนดการที่ละเอียด.

- เมื่อคุณตั้งค่านิพจน์ cron เสร็จแล้ว ให้เลือก ถัดไป สามครั้งแล้วจึงเลือกในที่สุด อัปเดตกฎ เพื่อบันทึกการเปลี่ยนแปลง
กฎถูกสร้างขึ้นโดยปิดใช้งานตามค่าเริ่มต้นเพื่อให้คุณเรียกใช้การโหลดข้อมูลเริ่มต้นก่อน
- เปิดใช้งานกฎโดยเลือก ทำให้สามารถ.
คุณสามารถใช้ การตรวจสอบ เพื่อดูการเรียกใช้กฎหรือบน AWS Glue โดยตรง วิ่งงาน รายละเอียด
สรุป
หลังจากปรับใช้โซลูชันนี้ คุณจะนำเข้าตารางของคุณบนแหล่งข้อมูลเชิงสัมพันธ์แหล่งเดียวได้โดยอัตโนมัติ องค์กรที่ใช้ Data Lake เป็นแพลตฟอร์มข้อมูลส่วนกลางมักจะต้องจัดการแหล่งข้อมูลหลายแหล่ง หรือบางครั้งก็ถึงสิบแหล่งด้วยซ้ำ นอกจากนี้ กรณีการใช้งานเพิ่มมากขึ้นเรื่อยๆ ต้องการให้องค์กรนำความสามารถด้านธุรกรรมไปใช้กับ Data Lake คุณสามารถใช้โซลูชันนี้เพื่อเร่งการนำความสามารถดังกล่าวไปใช้ในแหล่งข้อมูลเชิงสัมพันธ์ทั้งหมดของคุณ เพื่อเปิดใช้งานกรณีการใช้งานทางธุรกิจใหม่ๆ ทำให้กระบวนการนำไปใช้งานเป็นไปโดยอัตโนมัติเพื่อให้ได้คุณค่าจากข้อมูลของคุณมากขึ้น
เกี่ยวกับผู้เขียน
 หลุยส์ เกราร์โด้ บาเอซ่า เป็น Big Data Architect ใน Amazon Web Services (AWS) Data Lab เขามีประสบการณ์ 12 ปีในการช่วยเหลือองค์กรต่างๆ ในภาคการดูแลสุขภาพ การเงิน และการศึกษาให้นำโปรแกรมสถาปัตยกรรมองค์กร การประมวลผลแบบคลาวด์ และความสามารถในการวิเคราะห์ข้อมูลมาใช้ ปัจจุบัน Luis ช่วยองค์กรต่างๆ ทั่วละตินอเมริกาในการเร่งริเริ่มข้อมูลเชิงกลยุทธ์
หลุยส์ เกราร์โด้ บาเอซ่า เป็น Big Data Architect ใน Amazon Web Services (AWS) Data Lab เขามีประสบการณ์ 12 ปีในการช่วยเหลือองค์กรต่างๆ ในภาคการดูแลสุขภาพ การเงิน และการศึกษาให้นำโปรแกรมสถาปัตยกรรมองค์กร การประมวลผลแบบคลาวด์ และความสามารถในการวิเคราะห์ข้อมูลมาใช้ ปัจจุบัน Luis ช่วยองค์กรต่างๆ ทั่วละตินอเมริกาในการเร่งริเริ่มข้อมูลเชิงกลยุทธ์
 ไซคิราน เรดดี้ เอนูกู เป็น Data Architect ใน Amazon Web Services (AWS) Data Lab เขามีประสบการณ์ 10 ปีในการปรับใช้กระบวนการโหลดข้อมูล การแปลง และการแสดงภาพ ปัจจุบัน SaiKiran ช่วยให้องค์กรต่างๆ ในอเมริกาเหนือนำสถาปัตยกรรมข้อมูลสมัยใหม่มาใช้ เช่น Data Lake และ Data Mesh เขามีประสบการณ์ในภาคการค้าปลีก สายการบิน และการเงิน
ไซคิราน เรดดี้ เอนูกู เป็น Data Architect ใน Amazon Web Services (AWS) Data Lab เขามีประสบการณ์ 10 ปีในการปรับใช้กระบวนการโหลดข้อมูล การแปลง และการแสดงภาพ ปัจจุบัน SaiKiran ช่วยให้องค์กรต่างๆ ในอเมริกาเหนือนำสถาปัตยกรรมข้อมูลสมัยใหม่มาใช้ เช่น Data Lake และ Data Mesh เขามีประสบการณ์ในภาคการค้าปลีก สายการบิน และการเงิน
 นเรนทรา เมอร์ลา เป็น Data Architect ใน Amazon Web Services (AWS) Data Lab เขามีประสบการณ์ 12 ปีในการออกแบบและการผลิตทั้งไปป์ไลน์ข้อมูลแบบเรียลไทม์และแบบแบตช์ รวมถึงการสร้าง Data Lake บนสภาพแวดล้อมคลาวด์และในองค์กร ปัจจุบัน Narendra ช่วยองค์กรต่างๆ ในอเมริกาเหนือในการสร้างและออกแบบสถาปัตยกรรมข้อมูลที่แข็งแกร่ง และมีประสบการณ์ในภาคโทรคมนาคมและการเงิน
นเรนทรา เมอร์ลา เป็น Data Architect ใน Amazon Web Services (AWS) Data Lab เขามีประสบการณ์ 12 ปีในการออกแบบและการผลิตทั้งไปป์ไลน์ข้อมูลแบบเรียลไทม์และแบบแบตช์ รวมถึงการสร้าง Data Lake บนสภาพแวดล้อมคลาวด์และในองค์กร ปัจจุบัน Narendra ช่วยองค์กรต่างๆ ในอเมริกาเหนือในการสร้างและออกแบบสถาปัตยกรรมข้อมูลที่แข็งแกร่ง และมีประสบการณ์ในภาคโทรคมนาคมและการเงิน
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- เกี่ยวกับเรา
- เร่งความเร็ว
- เข้า
- ตาม
- รับทราบ
- ข้าม
- ปรับ
- ที่เพิ่ม
- เพิ่มเติม
- นอกจากนี้
- เพิ่ม
- ผู้ดูแลระบบ
- การบริหาร
- นำมาใช้
- การนำมาใช้
- หลังจาก
- สายการบิน
- ทั้งหมด
- แล้ว
- อเมซอน
- อเมซอน อาเธน่า
- อเมซอน RDS
- Amazon Web Services
- Amazon Web Services (AWS)
- สหรัฐอเมริกา
- การวิเคราะห์
- การวิเคราะห์
- และ
- Angeles
- อาปาเช่
- ปรากฏ
- การใช้งาน
- ประยุกต์
- การประยุกต์ใช้
- เข้าใกล้
- ประมาณ
- สถาปัตยกรรม
- แถว
- ที่เกี่ยวข้อง
- รับรองความถูกต้อง
- โดยอัตโนมัติ
- อัตโนมัติ
- อัตโนมัติ
- โดยอัตโนมัติ
- เฉลี่ย
- หลีกเลี่ยง
- AWS
- การก่อตัวของ AWS Cloud
- AWS กาว
- ตาม
- ค้างคาว
- เพราะ
- กลายเป็น
- ก่อน
- การเริ่มต้น
- ใหญ่
- ข้อมูลขนาดใหญ่
- สร้าง
- สร้าง
- การก่อสร้าง
- ธุรกิจ
- สามารถรับ
- ความสามารถในการ
- หมวก
- จับ
- จับ
- กรณี
- กรณี
- แค็ตตาล็อก
- จับ
- ก่อให้เกิด
- สาเหตุที่
- การก่อให้เกิด
- CDC
- ส่วนกลาง
- บาง
- เปลี่ยนแปลง
- การเปลี่ยนแปลง
- ทางเลือก
- Choose
- เลือก
- เลือก
- เมฆ
- คอมพิวเตอร์เมฆ
- รหัส
- คอลัมน์
- คอลัมน์
- บริษัท
- สมบูรณ์
- การคำนวณ
- องค์ประกอบ
- การกำหนดค่า
- ยืนยัน
- ขัดแย้ง
- เชื่อมต่อ
- การเชื่อมต่อ
- การพิจารณา
- ปลอบใจ
- ผู้บริโภค
- การบริโภค
- มี
- ต่อ
- ต่อเนื่องกัน
- ควบคุม
- ได้
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- การสร้าง
- การสร้าง
- เกณฑ์
- ขณะนี้
- ประเพณี
- ลูกค้า
- ปรับแต่ง
- ข้อมูล
- วิเคราะห์ข้อมูล
- ดาต้าเลค
- แพลตฟอร์มข้อมูล
- ฐานข้อมูล
- ฐานข้อมูล
- วันที่
- ค่าเริ่มต้น
- กำหนด
- ปรับใช้
- นำไปใช้
- ปรับใช้
- การใช้งาน
- Deploys
- ออกแบบ
- ได้รับการออกแบบ
- การออกแบบ
- รายละเอียด
- ตรวจพบ
- พัฒนาการ
- ต่าง
- โดยตรง
- พิการ
- แบ่งออก
- ไม่
- โดเมน
- โดเมน
- Dont
- ในระหว่าง
- แต่ละ
- ก่อน
- อย่างง่ายดาย
- การศึกษา
- ความพยายาม
- ทั้ง
- ทำให้สามารถ
- เปิดการใช้งาน
- ที่มีการเข้ารหัส
- การเข้ารหัสลับ
- ปลายทาง
- เครื่องยนต์
- เข้าสู่
- Enterprise
- สภาพแวดล้อม
- ข้อผิดพลาด
- อีเธอร์ (ETH)
- แม้
- ทุกๆ
- ตัวอย่าง
- เกินกว่า
- ยกเว้น
- ข้อยกเว้น
- ที่มีอยู่
- ที่มีอยู่
- ที่คาดหวัง
- คาดว่า
- ประสบการณ์
- สำรวจ
- ส่วนขยาย
- สารสกัด
- ล้มเหลว
- คุ้นเคย
- ร้านแฟชั่นเกาหลี
- ลักษณะ
- สองสาม
- เนื้อไม่มีมัน
- ไฟล์
- ในที่สุด
- เงินทุน
- ทางการเงิน
- หา
- เสร็จสิ้น
- ชื่อจริง
- ตาม
- ดังต่อไปนี้
- สำหรับผู้บริโภค
- ฟอร์ม
- การสร้าง
- กรอบ
- ราคาเริ่มต้นที่
- เต็ม
- ฟังก์ชัน
- สร้าง
- รุ่น
- ได้รับ
- ให้
- ทุน
- การเจริญเติบโต
- จัดการ
- การดูแลสุขภาพ
- การช่วยเหลือ
- จะช่วยให้
- ลำดับชั้น
- ประวัติ
- โฮลดิ้ง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTML
- HTTPS
- ใหญ่
- AMI
- ระบุ
- ระบุ
- ระบุ
- แยกแยะ
- การดำเนินการ
- การดำเนินงาน
- การดำเนินการ
- การดำเนินการ
- การดำเนินการ
- การปรับปรุง
- in
- ประกอบด้วย
- รวมถึง
- รวมทั้ง
- ขาเข้า
- บ่งชี้ว่า
- เป็นรายบุคคล
- ข้อมูล
- แรกเริ่ม
- ความคิดริเริ่ม
- แทรก
- ความเข้าใจ
- ตัวอย่าง
- แทน
- คำแนะนำการใช้
- Intermediate
- ปัญหา
- ปัญหา
- IT
- การย้ำ
- การสัมภาษณ์
- งาน
- JSON
- เก็บ
- คีย์
- กุญแจ
- ทราบ
- ห้องปฏิบัติการ
- ทะเลสาบ
- ละติน
- ละตินอเมริกา
- ชั้น
- ชั้น
- นำ
- เรียนรู้
- ห้องสมุด
- LIMIT
- Line
- รายการ
- โหลด
- โหลด
- โหลด
- ที่ตั้ง
- ดู
- LOOKS
- ลอส
- Los Angeles
- Lot
- หลัก
- รักษา
- ทำ
- การจัดการ
- การจัดการ
- ผู้จัดการ
- การจัดการ
- ด้วยมือ
- หลาย
- การทำแผนที่
- โดดเด่น
- เมนู
- ผสาน
- ข่าวสาร
- อาจ
- การโยกย้าย
- ขั้นต่ำ
- นาที
- นาที
- ทันสมัย
- แก้ไข
- การตรวจสอบ
- การตรวจสอบ
- ข้อมูลเพิ่มเติม
- มากที่สุด
- เป็นที่นิยม
- หลาย
- ชื่อ
- ที่มีชื่อ
- ชื่อ
- นำทาง
- การเดินเรือ
- จำเป็นต้อง
- จำเป็น
- ความต้องการ
- ใหม่
- ถัดไป
- ทางทิศเหนือ
- อเมริกาเหนือ
- การประกาศ
- จำนวน
- วัตถุ
- วัตถุ
- ONE
- ต่อเนื่อง
- OP
- การดำเนินการ
- การปรับให้เหมาะสม
- Options
- องค์กร
- องค์กร
- Organized
- เป็นต้นฉบับ
- มิฉะนั้น
- ด้านนอก
- ของตนเอง
- เจ้าของ
- บานหน้าต่าง
- พารามิเตอร์
- พารามิเตอร์
- ส่วนหนึ่ง
- ส่วน
- เส้นทาง
- แบบแผน
- รูปแบบไฟล์ PDF
- ดำเนินการ
- ที่มีประสิทธิภาพ
- ดำเนินการ
- ระยะเวลา
- สิทธิ์
- ระยะ
- เวที
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- ยอดนิยม
- โพสต์
- postgresql
- การปฏิบัติ
- ที่ต้องการ
- ข้อกำหนดเบื้องต้น
- นำเสนอ
- ประถม
- ปัญหา
- กระบวนการ
- กระบวนการ
- การประมวลผล
- ผลิต
- โปรแกรม
- ให้
- ให้
- ให้
- หลาม
- อย่างรวดเร็ว
- ยก
- คะแนน
- ดิบ
- ข้อมูลดิบ
- อ่าน
- เรียลไทม์
- ระเบียน
- บันทึก
- แทนที่
- การจำลองแบบ
- การทำซ้ำ
- ต้องการ
- จำเป็นต้องใช้
- ทรัพยากร
- แหล่งข้อมูล
- REST
- ผลสอบ
- ค้าปลีก
- กลับ
- รับคืน
- ทบทวน
- แข็งแรง
- บทบาท
- กฎ
- กฎระเบียบ
- วิ่ง
- วิ่ง
- เดียวกัน
- ลด
- สถานการณ์
- กำหนด
- ขอบเขต
- สคริปต์
- ค้นหา
- ที่สอง
- ภาค
- เห็น
- เลือก
- การเลือก
- การเลือก
- แยก
- บริการ
- ชุด
- การตั้งค่า
- การตั้งค่า
- น่า
- โชว์
- แสดงให้เห็นว่า
- คล้ายคลึงกัน
- ง่าย
- ตั้งแต่
- เดียว
- So
- ทางออก
- แก้ปัญหา
- บาง
- ซับซ้อน
- แหล่ง
- แหล่งที่มา
- ช่องว่าง
- จุดประกาย
- โดยเฉพาะ
- สเปค
- ที่ระบุไว้
- กีฬา
- SQL
- กอง
- สแต็ค
- ระยะ
- ผู้มีส่วนได้เสีย
- เริ่มต้น
- ข้อความที่เริ่ม
- ที่เริ่มต้น
- เริ่มต้น
- สหรัฐอเมริกา
- สถิติ
- Status
- ขั้นตอน
- ขั้นตอน
- หยุด
- การเก็บรักษา
- จัดเก็บ
- เก็บไว้
- ร้านค้า
- ยุทธศาสตร์
- โครงสร้าง
- โครงสร้าง
- สตูดิโอ
- ประสบความสำเร็จ
- อย่างเช่น
- ยิ่งใหญ่
- สนับสนุน
- ระบบ
- ตาราง
- เป้า
- งาน
- งาน
- ทีม
- ทีม
- โทรคมนาคม
- เทมเพลต
- สถานีปลายทาง
- พื้นที่
- ที่มา
- ของพวกเขา
- พัน
- สาม
- ตลอด
- เวลา
- ไทม์ไลน์
- ครั้ง
- การประทับเวลา
- ไปยัง
- เครื่องมือ
- ด้านบน
- รวม
- การติดตาม
- แบบดั้งเดิม
- ธุรกรรม
- แปลง
- การแปลง
- เรียก
- เกี่ยวกับการสอน
- ชนิด
- ภายใต้
- เข้าใจ
- เป็นเอกลักษณ์
- บันทึก
- การปรับปรุง
- ใช้
- ใช้กรณี
- ผู้ใช้งาน
- ผู้ใช้
- มักจะ
- ความคุ้มค่า
- การตรวจสอบ
- รายละเอียด
- การสร้างภาพ
- ปริมาณ
- รอ
- คลังสินค้า
- เว็บ
- บริการเว็บ
- ที่
- จะ
- ภายใน
- ไม่มี
- โรงงาน
- เขียน
- เขียน
- มันแกว
- ปี
- ปี
- ของคุณ
- ลมทะเล