โครงข่ายประสาทเทียมเรียนรู้ผ่านตัวเลข ดังนั้นแต่ละคำจะถูกจับคู่กับเวกเตอร์เพื่อแสดงคำเฉพาะ เลเยอร์การฝังอาจเปรียบได้กับตารางการค้นหาที่เก็บการฝังคำและดึงข้อมูลเหล่านั้นโดยใช้ดัชนี
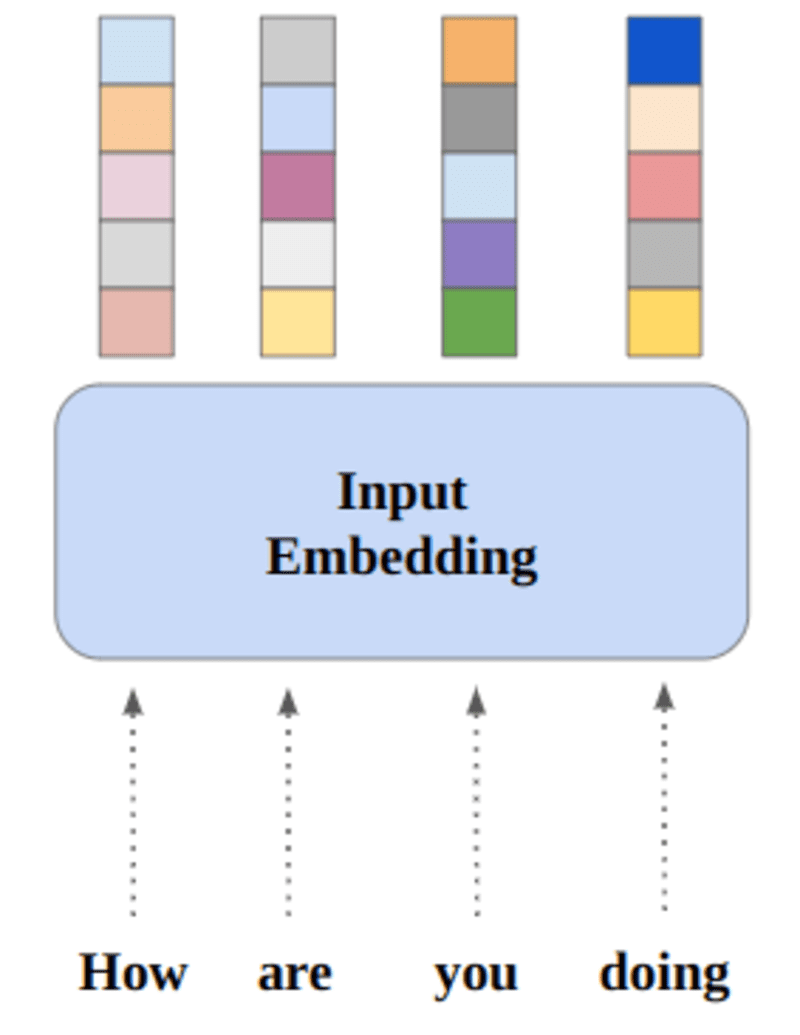
คำที่มีความหมายเหมือนกันจะใกล้เคียงในรูปของระยะทางแบบยุคลิด/ความคล้ายคลึงกันของโคไซน์ ตัวอย่างเช่น ในการแสดงคำด้านล่าง "วันเสาร์" "วันอาทิตย์" และ "วันจันทร์" มีความเกี่ยวข้องกับแนวคิดเดียวกัน ดังนั้นเราจะเห็นว่าคำเหล่านั้นมีความคล้ายคลึงกัน

การกำหนดตำแหน่งของคำ ทำไมต้องกำหนดตำแหน่งของคำ? เนื่องจากตัวเข้ารหัสของหม้อแปลงไม่มีการเกิดซ้ำเหมือนโครงข่ายประสาทเทียมที่เกิดซ้ำ เราต้องเพิ่มข้อมูลบางอย่างเกี่ยวกับตำแหน่งในการฝังอินพุต สิ่งนี้ทำได้โดยใช้การเข้ารหัสตำแหน่ง ผู้เขียนบทความใช้ฟังก์ชันต่อไปนี้เพื่อจำลองตำแหน่งของคำ
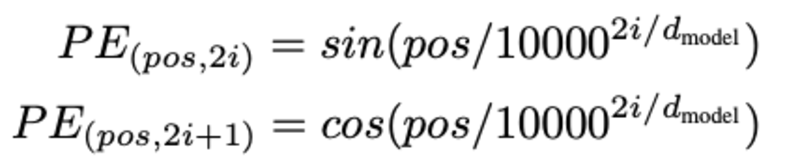
เราจะพยายามอธิบายการเข้ารหัสตำแหน่ง
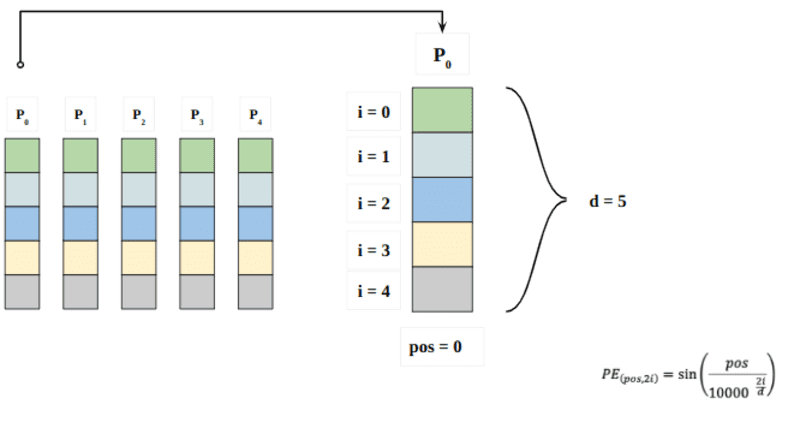
ที่นี่ "pos" หมายถึงตำแหน่งของ "คำ" ในลำดับ P0 หมายถึงตำแหน่งที่ฝังของคำแรก “d” หมายถึงขนาดของคำ/โทเค็นที่ฝัง ในตัวอย่างนี้ d=5 สุดท้าย “i” หมายถึงแต่ละมิติจาก 5 มิติของการฝัง (เช่น 0, 1,2,3,4)
ถ้า “i” แปรผันตามสมการข้างต้น คุณจะได้เส้นโค้งจำนวนมากที่มีความถี่ต่างกัน การอ่านค่าการฝังตำแหน่งเทียบกับความถี่ที่แตกต่างกัน โดยให้ค่าที่แตกต่างกันในมิติการฝังที่แตกต่างกันสำหรับ P0 และ P4
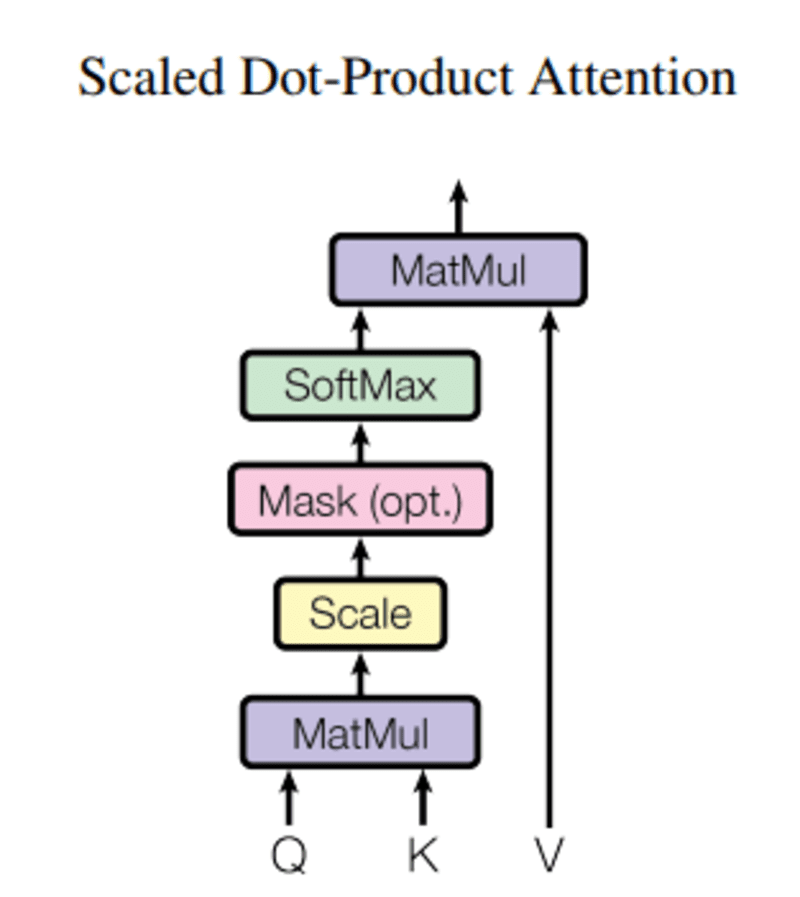
ในการนี้ สอบถาม, Q แทนคำเวกเตอร์, the คีย์เค เป็นคำอื่นทั้งหมดในประโยค และ ค่า V แสดงถึงเวกเตอร์ของคำ
จุดประสงค์ของการให้ความสนใจคือการคำนวณความสำคัญของคำหลักเมื่อเทียบกับคำค้นหาที่เกี่ยวข้องกับบุคคล/สิ่งของหรือแนวคิดเดียวกัน
ในกรณีของเรา V เท่ากับ Q
กลไกความสนใจทำให้เราเห็นความสำคัญของคำในประโยค
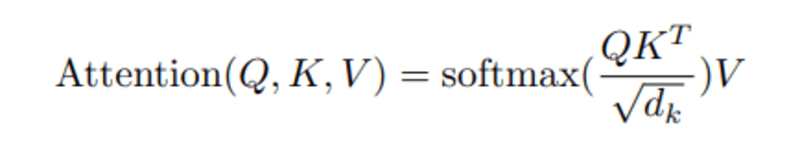
เมื่อเราคำนวณดอทโปรดักต์ที่ทำให้เป็นมาตรฐานระหว่างเคียวรีและคีย์ เราจะได้เทนเซอร์ที่แสดงถึงความสำคัญสัมพัทธ์ของคำแต่ละคำสำหรับเคียวรี
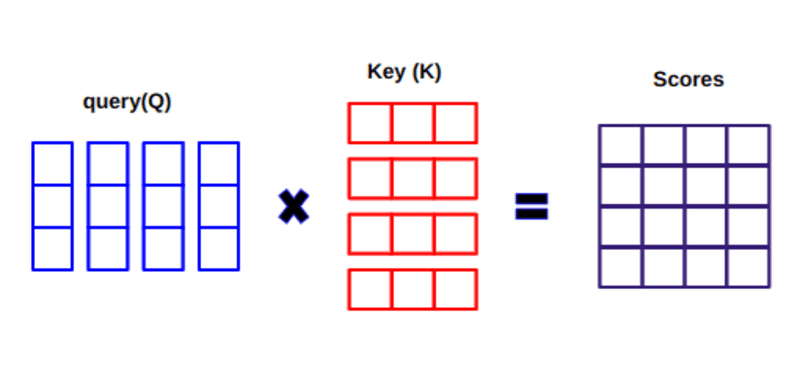
เมื่อคำนวณดอทโปรดักต์ระหว่าง Q และ KT เราจะพยายามประเมินว่าเวกเตอร์ (เช่น คำที่อยู่ระหว่างเคียวรีกับคีย์) เรียงตัวกันอย่างไร และส่งคืนค่าน้ำหนักสำหรับแต่ละคำในประโยค
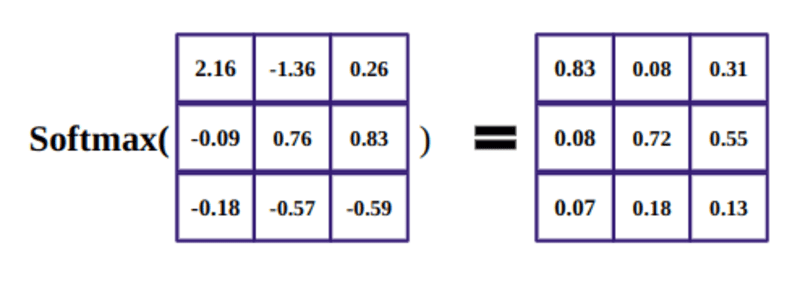
จากนั้น เราทำให้ผลลัพธ์กำลังสองของ d_k เป็นมาตรฐาน และฟังก์ชัน softmax จะทำให้เงื่อนไขเป็นปกติและปรับขนาดใหม่ระหว่าง 0 ถึง 1
สุดท้าย เราคูณผลลัพธ์ (เช่น น้ำหนัก) ด้วยค่า (เช่น ทุกคำ) เพื่อลดความสำคัญของคำที่ไม่เกี่ยวข้องและเน้นเฉพาะคำที่สำคัญที่สุด
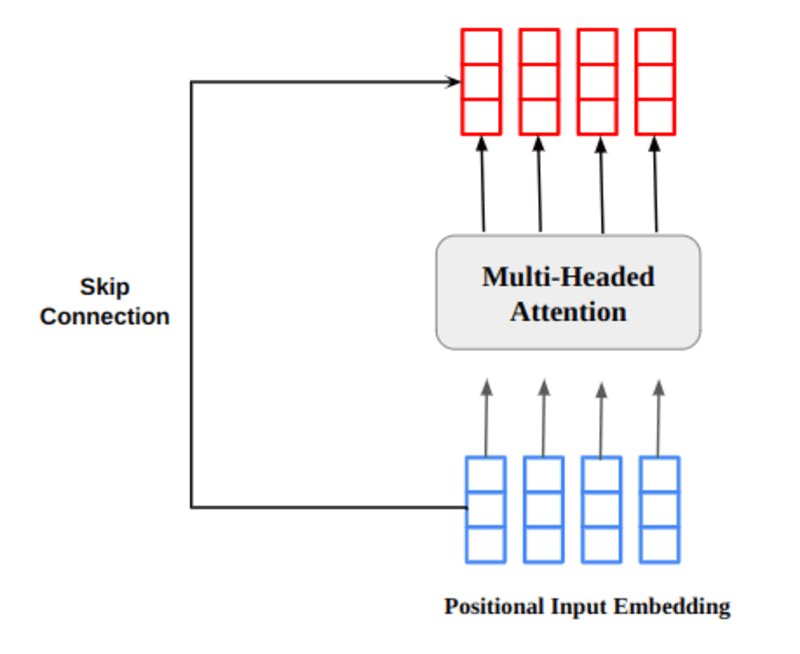
เวกเตอร์เอาต์พุตความสนใจแบบหลายหัวถูกเพิ่มในการฝังอินพุตตำแหน่งเดิม สิ่งนี้เรียกว่าการเชื่อมต่อที่เหลือ/ข้ามการเชื่อมต่อ เอาต์พุตของการเชื่อมต่อที่เหลือจะผ่านการทำให้เป็นมาตรฐานของเลเยอร์ เอาต์พุตที่เหลือที่ทำให้เป็นมาตรฐานจะถูกส่งผ่านเครือข่ายการส่งต่อแบบจุดสำหรับการประมวลผลเพิ่มเติม
มาสก์เป็นเมทริกซ์ที่มีขนาดเท่ากับคะแนนความสนใจซึ่งเต็มไปด้วยค่า 0 และค่าอนันต์ติดลบ
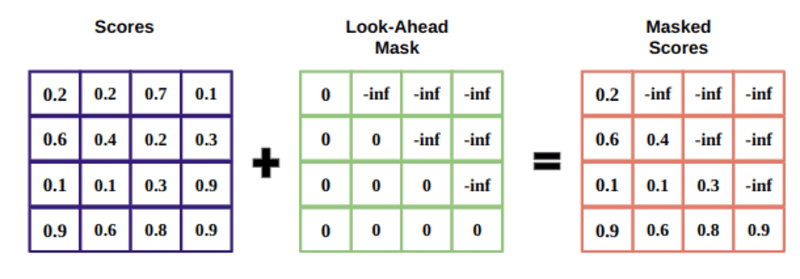
เหตุผลของการมาสก์คือเมื่อคุณหาค่าซอฟต์แม็กซ์ของคะแนนที่ถูกมาสก์ ค่าอินฟินิตีเชิงลบจะเป็นศูนย์ ทำให้คะแนนความสนใจเป็นศูนย์สำหรับโทเค็นในอนาคต
สิ่งนี้บอกให้นางแบบไม่ให้ความสำคัญกับคำเหล่านั้น
จุดประสงค์ของฟังก์ชัน softmax คือการจับจำนวนจริง (บวกและลบ) และเปลี่ยนให้เป็นจำนวนบวกซึ่งรวมเป็น 1
ราวิคูมาร์ นาดูวิน ยุ่งอยู่กับการสร้างและทำความเข้าใจงาน NLP โดยใช้ PyTorch
Original. โพสต์ใหม่โดยได้รับอนุญาต
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html?utm_source=rss&utm_medium=rss&utm_campaign=concepts-you-should-know-before-getting-into-transformer
- 1
- a
- เกี่ยวกับเรา
- ข้างบน
- ที่เพิ่ม
- กับ
- ชิด
- ทั้งหมด
- และ
- ที่เกี่ยวข้อง
- ความสนใจ
- ผู้เขียน
- เพราะ
- ก่อน
- ด้านล่าง
- ระหว่าง
- การก่อสร้าง
- พวง
- ที่เรียกว่า
- กรณี
- ปิดหน้านี้
- เมื่อเทียบกับ
- คำนวณ
- การคำนวณ
- แนวคิด
- แนวความคิด
- การเชื่อมต่อ
- กำหนด
- การกำหนด
- ต่าง
- มิติ
- DOT
- แต่ละ
- ประมาณการ
- ตัวอย่าง
- อธิบาย
- ที่เต็มไป
- ในที่สุด
- ชื่อจริง
- โฟกัส
- ดังต่อไปนี้
- ฟังก์ชัน
- ฟังก์ชั่น
- ต่อไป
- อนาคต
- ได้รับ
- ได้รับ
- GitHub
- จะช่วยให้
- ให้
- ไป
- คว้า
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- HTTPS
- ความสำคัญ
- สำคัญ
- in
- ดัชนี
- เป็นรายบุคคล
- ข้อมูล
- อินพุต
- KD นักเก็ต
- คีย์
- กุญแจ
- ทราบ
- ชั้น
- เรียนรู้
- การออกจาก
- ค้นหา
- หน้ากาก
- มดลูก
- ความหมาย
- วิธี
- กลไก
- แบบ
- มากที่สุด
- จำเป็นต้อง
- เชิงลบ
- เครือข่าย
- เครือข่าย
- ประสาท
- เครือข่ายประสาทเทียม
- NLP
- ตัวเลข
- เป็นต้นฉบับ
- อื่นๆ
- กระดาษ
- ในสิ่งที่สนใจ
- ผ่าน
- การอนุญาต
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- ตำแหน่ง
- ตำแหน่ง
- บวก
- การประมวลผล
- ผลิตภัณฑ์
- วัตถุประสงค์
- ใส่
- ไฟฉาย
- การอ่าน
- จริง
- เหตุผล
- การเกิดขึ้นอีก
- ลด
- หมายถึง
- ที่เกี่ยวข้อง
- แสดง
- การแสดง
- แสดงให้เห็นถึง
- ผล
- ส่งผลให้
- กลับ
- เดียวกัน
- ประโยค
- ลำดับ
- น่า
- คล้ายคลึงกัน
- ขนาด
- So
- บาง
- squared
- ร้านค้า
- ตาราง
- เอา
- งาน
- บอก
- เงื่อนไขการใช้บริการ
- พื้นที่
- คิดว่า
- ตลอด
- ไปยัง
- ราชสกุล
- หม้อแปลง
- กลับ
- ความเข้าใจ
- us
- ความคุ้มค่า
- ความคุ้มค่า
- น้ำหนัก
- ที่
- จะ
- คำ
- คำ
- ลมทะเล
- เป็นศูนย์