ในโลกของวิศวกรรมซอฟต์แวร์และการพัฒนา องค์กรต่าง ๆ ใช้เครื่องมือการจัดการโครงการเช่น แอตลาสเซียน จิรา คลาวด์- การจัดการโครงการกับ Jira นำไปสู่ชุดข้อมูลที่หลากหลาย ซึ่งสามารถให้ข้อมูลเชิงลึกในอดีตและเชิงคาดการณ์เกี่ยวกับความพยายามของโครงการและการพัฒนา
แม้ว่า Jira Cloud จะให้ความสามารถในการรายงาน แต่การโหลดข้อมูลนี้ลงใน Data Lake จะช่วยเสริมประสิทธิภาพด้วยข้อมูลทางธุรกิจอื่นๆ ตลอดจนสนับสนุนการใช้เครื่องมือระบบธุรกิจอัจฉริยะ (BI) และแอปพลิเคชันปัญญาประดิษฐ์ (AI) และการเรียนรู้ของเครื่อง (ML) บริษัทต่างๆ มักจะใช้แนวทาง Data Lake ในการวิเคราะห์ โดยนำข้อมูลจากระบบต่างๆ มากมายมาไว้ในที่เดียว เพื่อลดความซับซ้อนของวิธีการวิเคราะห์
โพสต์นี้แสดงวิธีการใช้งาน Amazon App Flow และ AWS กาว เพื่อสร้างไปป์ไลน์การนำเข้าข้อมูลอัตโนมัติเต็มรูปแบบที่จะซิงโครไนซ์ข้อมูล Jira ของคุณเข้ากับ Data Lake ของคุณ Amazon AppFlow มีการผสานรวมซอฟต์แวร์เป็นบริการ (SaaS) เข้ากับ Jira Cloud เพื่อโหลดข้อมูลลงในบัญชี AWS ของคุณ AWS Glue เป็นบริการค้นหา โหลด และแปลงข้อมูลแบบไร้เซิร์ฟเวอร์ ซึ่งจะเตรียมข้อมูลสำหรับการใช้งานในกิจกรรม BI และ AI/ML นอกจากนี้ โพสต์นี้มุ่งมั่นที่จะบรรลุโซลูชันที่ใช้โค้ดน้อยและไร้เซิร์ฟเวอร์เพื่อประสิทธิภาพการดำเนินงานและการเพิ่มประสิทธิภาพต้นทุน และโซลูชันยังรองรับการโหลดส่วนเพิ่มเพื่อเพิ่มประสิทธิภาพต้นทุน
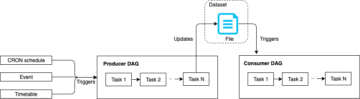
ภาพรวมโซลูชัน
โซลูชันนี้ใช้ Amazon AppFlow เพื่อดึงข้อมูลจาก Jira Cloud ข้อมูลจะถูกซิงโครไนซ์กับ บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) ที่ใช้การดาวน์โหลดแบบเต็มครั้งแรกและการดาวน์โหลดการเปลี่ยนแปลงที่เพิ่มขึ้นในภายหลัง เมื่อมีข้อมูลใหม่มาถึงบัคเก็ต S3 ฟังก์ชันขั้นตอนของ AWS เวิร์กโฟลว์จะถูกทริกเกอร์ที่จัดเตรียมกิจกรรมแยก แปลง และโหลด (ETL) โดยใช้ AWS กาว โปรแกรมรวบรวมข้อมูลและ AWS กาว DataBrew- จากนั้นข้อมูลจะพร้อมใช้งานใน AWS Glue Data Catalog และสามารถสอบถามผ่านบริการต่างๆ เช่น อเมซอน อาเธน่า, อเมซอน QuickSightและ อเมซอน Redshift Spectrum- โซลูชันนี้เป็นแบบอัตโนมัติโดยสมบูรณ์และไร้เซิร์ฟเวอร์ ส่งผลให้ค่าใช้จ่ายในการดำเนินงานต่ำ เมื่อการตั้งค่านี้เสร็จสมบูรณ์ ข้อมูล Jira ของคุณจะถูกนำเข้าโดยอัตโนมัติและอัปเดตอยู่เสมอใน Data Lake ของคุณ!
ไดอะแกรมต่อไปนี้แสดงสถาปัตยกรรมโซลูชัน
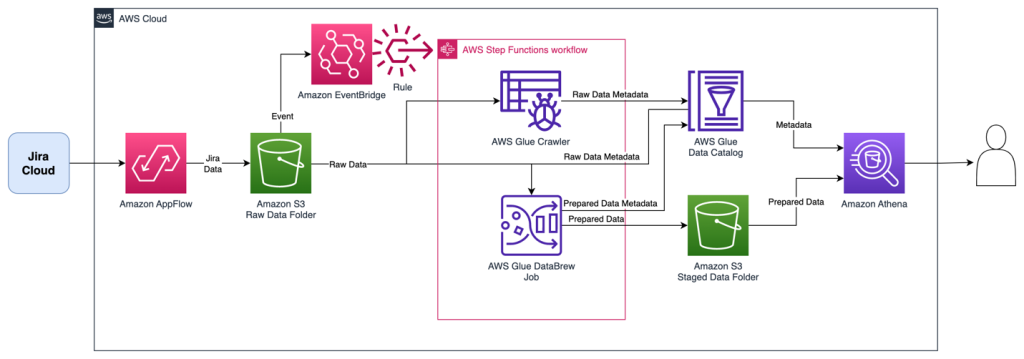
เวิร์กโฟลว์ Step Functions จัดกิจกรรม ETL ต่อไปนี้ ซึ่งส่งผลให้มี 2 ตาราง:
- โปรแกรมรวบรวมข้อมูล AWS Glue รวบรวมการดาวน์โหลดทั้งหมดไว้ในตาราง AWS Glue ตารางเดียวที่มีชื่อว่า
jira_raw- ตารางนี้ประกอบด้วยการดาวน์โหลดแบบเต็มและการดาวน์โหลดที่เพิ่มขึ้นจาก Jira โดยมีบันทึกเดียวกันหลายเวอร์ชันที่แสดงถึงการเปลี่ยนแปลงเมื่อเวลาผ่านไป - งาน DataBrew จะเตรียมข้อมูลสำหรับการรายงานโดยการคลายแพ็กคู่คีย์-ค่าในช่องต่างๆ ตลอดจนลบบันทึกที่เสื่อมค่าออกเมื่อมีการอัปเดตในการเก็บข้อมูลการเปลี่ยนแปลงที่ตามมา ข้อมูลที่พร้อมสำหรับการรายงานนี้จะพร้อมใช้งานในตาราง AWS Glue ที่ชื่อว่า
jira_data.
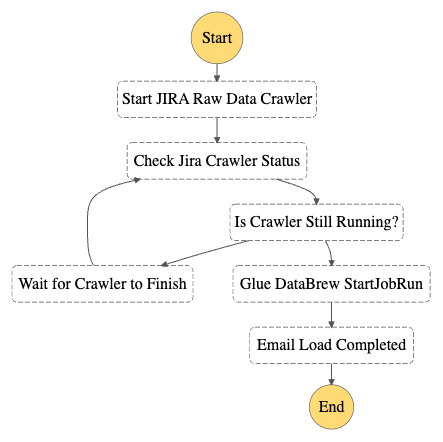
รูปภาพต่อไปนี้แสดงเวิร์กโฟลว์ Step Functions
เบื้องต้น
โซลูชันนี้ต้องการสิ่งต่อไปนี้:
- สิทธิ์การเข้าถึงระดับผู้ดูแลระบบสำหรับอินสแตนซ์ Jira Cloud ของคุณและบัญชีนักพัฒนา Jira Cloud ที่เกี่ยวข้อง
- An บัญชี AWS และการเข้าสู่ระบบด้วยการเข้าถึง คอนโซลการจัดการ AWS- คุณจะต้องเข้าสู่ระบบ AWS Identity และการจัดการการเข้าถึง สิทธิ์ (IAM) ในการสร้างและเข้าถึงทรัพยากรในบัญชี AWS ของคุณ
- ความรู้พื้นฐานเกี่ยวกับ AWS และความรู้ในการทำงานของการบริหาร Jira
กำหนดค่าอินสแตนซ์ Jira
หลังจากเข้าสู่ระบบอินสแตนซ์ Jira Cloud คุณจะสร้างโปรเจ็กต์ Jira ที่มี Epic ที่เกี่ยวข้องและปัญหาเพื่อดาวน์โหลดลงใน Data Lake หากคุณเริ่มต้นด้วยอินสแตนซ์ Jira ใหม่ ควรมีอย่างน้อยหนึ่งโปรเจ็กต์ที่มีการสุ่มตัวอย่าง Epic และปัญหาสำหรับการดาวน์โหลดข้อมูลเริ่มต้น เนื่องจากช่วยให้คุณสร้างชุดข้อมูลเริ่มต้นได้โดยไม่มีข้อผิดพลาดหรือช่องขาดหายไป โปรดทราบว่าคุณอาจมีหลายโครงการเช่นกัน
หลังจากที่คุณสร้างโปรเจ็กต์ Jira ของคุณและเติมมหากาพย์และประเด็นต่างๆ ลงในโปรเจ็กต์แล้ว ตรวจสอบให้แน่ใจว่าคุณยังสามารถเข้าถึง พอร์ทัลนักพัฒนา Jira- ในขั้นตอนต่อๆ ไป คุณจะใช้พอร์ทัลนักพัฒนานี้เพื่อสร้างการตรวจสอบสิทธิ์และการอนุญาตสำหรับการเชื่อมต่อ Amazon AppFlow
จัดเตรียมทรัพยากรด้วย AWS CloudFormation
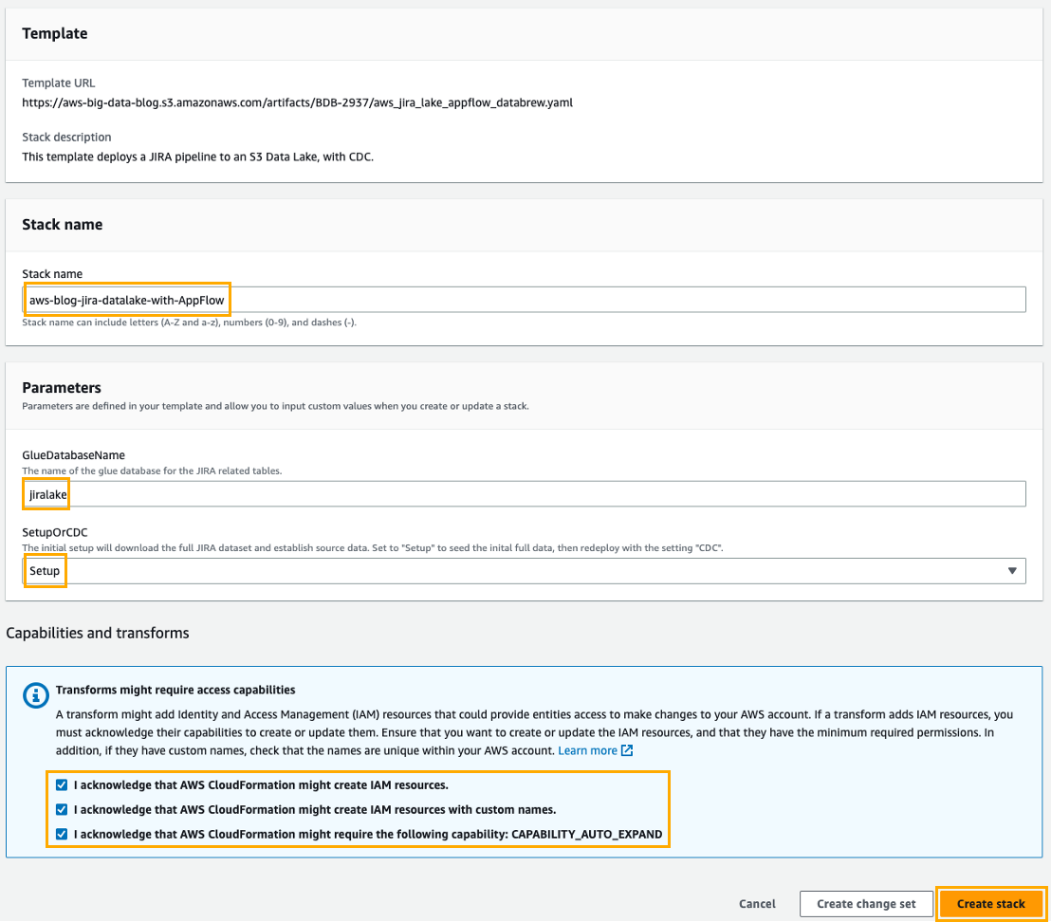
สำหรับการตั้งค่าเริ่มต้น คุณจะต้องเปิดไฟล์ การก่อตัวของ AWS Cloud stack เพื่อสร้างบัคเก็ต S3 เพื่อจัดเก็บข้อมูล บทบาท IAM สำหรับการเข้าถึงข้อมูล และส่วนประกอบ AWS Glue crawler และ Data Catalog ทำตามขั้นตอนต่อไปนี้:
- ลงชื่อเข้าใช้บัญชี AWS ของคุณ
- คลิก เรียกใช้ Stack:

- สำหรับ ชื่อกองให้ป้อนชื่อสำหรับสแต็ก (ค่าเริ่มต้นคือ
aws-blog-jira-datalake-with-AppFlow). - สำหรับ ชื่อฐานข้อมูลกาวให้ป้อนชื่อเฉพาะสำหรับฐานข้อมูล Data Catalog เพื่อเก็บข้อมูลเมตาของตารางข้อมูล Jira (ค่าเริ่มต้นคือ
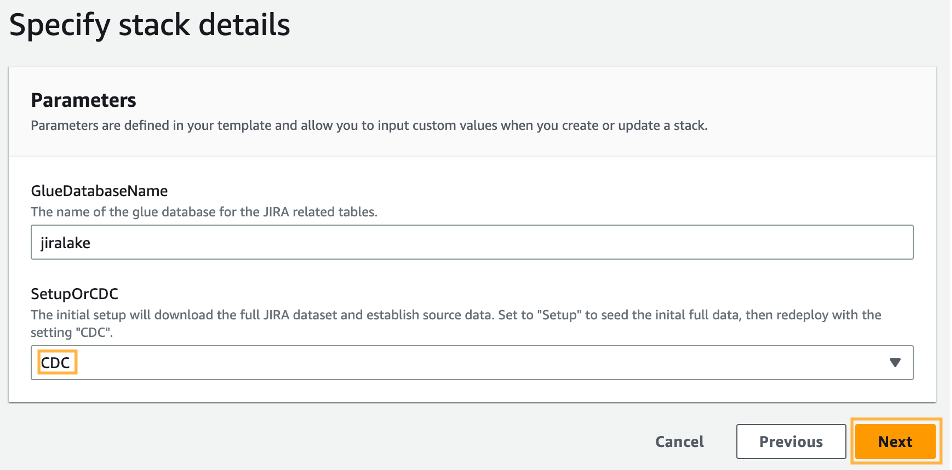
jiralake). - สำหรับ InitialRunFlagเลือก การติดตั้ง- โหมดนี้จะสแกนข้อมูลทั้งหมดและปิดใช้งานคุณสมบัติการเปลี่ยนแปลงข้อมูลการจับ (CDC) ของสแต็ก (เนื่องจากนี่คือการโหลดครั้งแรก สแต็กจึงต้องมีการโหลดข้อมูลเริ่มต้นก่อนที่คุณจะกำหนดค่า CDC ในขั้นตอนต่อๆ ไป)
- ภายใต้ ความสามารถและการเปลี่ยนแปลงเลือกกล่องกาเครื่องหมายการรับทราบเพื่ออนุญาตให้สร้างทรัพยากร IAM ภายในบัญชี AWS ของคุณ
- ตรวจสอบพารามิเตอร์และเลือก สร้าง stack เพื่อปรับใช้สแต็ก CloudFormation กระบวนการนี้จะใช้เวลาประมาณ 5-10 นาทีจึงจะเสร็จสมบูรณ์
- หลังจากปรับใช้สแต็กแล้ว ให้ตรวจสอบ Outputs แท็บสำหรับสแต็กและรวบรวมค่าต่อไปนี้เพื่อใช้เมื่อคุณตั้งค่า Amazon AppFlow:
- บัคเก็ตปลายทางของ Amazon AppFlow (
o01AppFlowBucket) - เส้นทางบัคเก็ตปลายทางของ Amazon AppFlow (
o02AppFlowPath) - บทบาทสำหรับตัวเชื่อมต่อ Amazon AppFlow Jira (
o03AppFlowRole)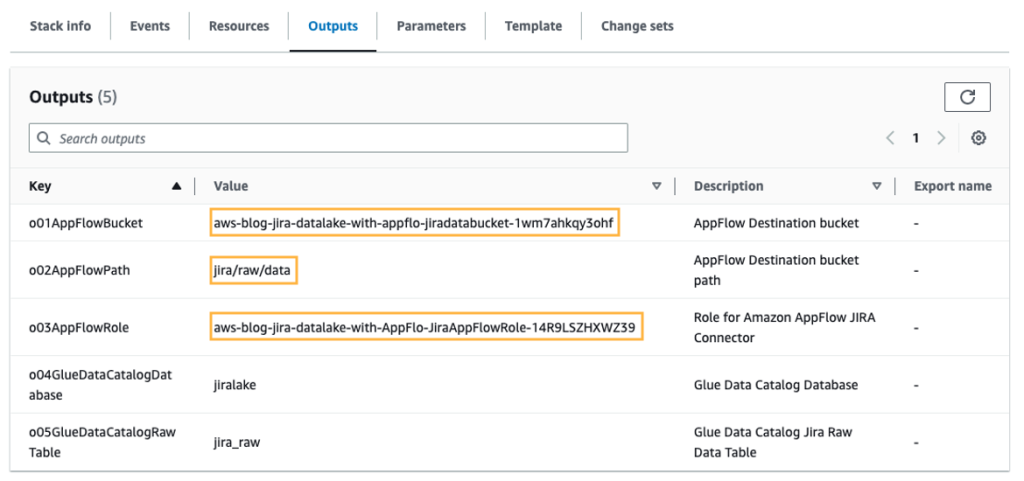
- บัคเก็ตปลายทางของ Amazon AppFlow (
กำหนดค่า Jira Cloud
จากนั้น ให้คุณกำหนดค่าอินสแตนซ์ Jira Cloud สำหรับการเข้าถึงโดย Amazon AppFlow สำหรับคำแนะนำแบบเต็ม โปรดดูที่ ตัวเชื่อมต่อ Jira Cloud สำหรับ Amazon AppFlow- ขั้นตอนต่อไปนี้จะสรุปคำแนะนำเหล่านี้และหารือเกี่ยวกับการกำหนดค่าเฉพาะเพื่อเปิดใช้ OAuth ใน Jira Cloud:
- เปิด พอร์ทัลนักพัฒนา Jira.
- สร้างการผสานรวม OAuth 2 จากคอนโซลแอปพลิเคชันสำหรับนักพัฒนาโดยเลือก สร้างบัญชีตัวแทน an บูรณาการ OAuth 2.0- นี่จะเป็นกลไกการเข้าสู่ระบบสำหรับ AppFlow
- เปิดใช้งานการอนุญาตแบบละเอียด ดู ขอบเขตที่แนะนำ สำหรับการตั้งค่าสิทธิ์เพื่อให้ AppFlow เข้าถึงอินสแตนซ์ Jira ของคุณได้อย่างเหมาะสม
- เพิ่มขอบเขตสิทธิ์ต่อไปนี้ลงในแอป OAuth ของคุณ:
manage:jira-configurationread:field-configuration:jira
- ภายใต้ การอนุญาต, ตั้งค่า URL โทรกลับ เพื่อกลับไปยัง Amazon AppFlow ด้วย URL
https://us-east-1.console.aws.amazon.com/AppFlow/oauth. - ภายใต้ การตั้งค่าให้จดรหัสไคลเอ็นต์และข้อมูลลับเพื่อใช้ในขั้นตอนต่อๆ ไปเพื่อตั้งค่าการตรวจสอบสิทธิ์จาก Amazon AppFlow
สร้างการเชื่อมต่อ Amazon AppFlow Jira Cloud
ในขั้นตอนนี้ คุณจะกำหนดค่า Amazon AppFlow ให้เรียกใช้ข้อมูลทั้งหมดของคุณแบบเต็มเพียงครั้งเดียว โดยสร้าง Data Lake เริ่มต้น:
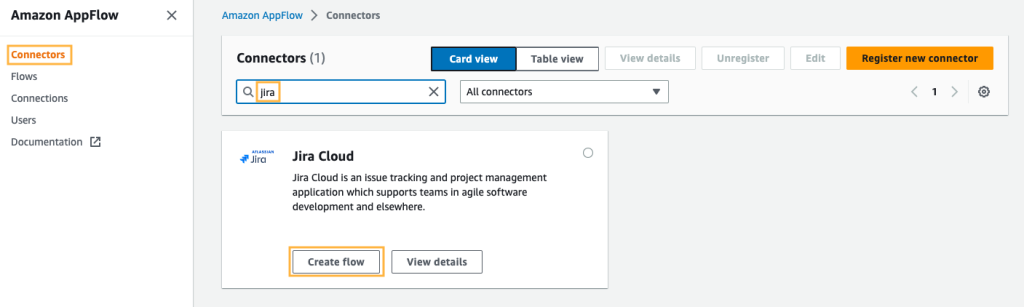
- บนคอนโซล Amazon AppFlow ให้เลือก เชื่อมต่อ ในบานหน้าต่างนำทาง
- ค้นหาตัวเชื่อมต่อ Jira Cloud
- Choose สร้างกระแส บนไทล์ตัวเชื่อมต่อเพื่อสร้างการเชื่อมต่อกับอินสแตนซ์ Jira ของคุณ
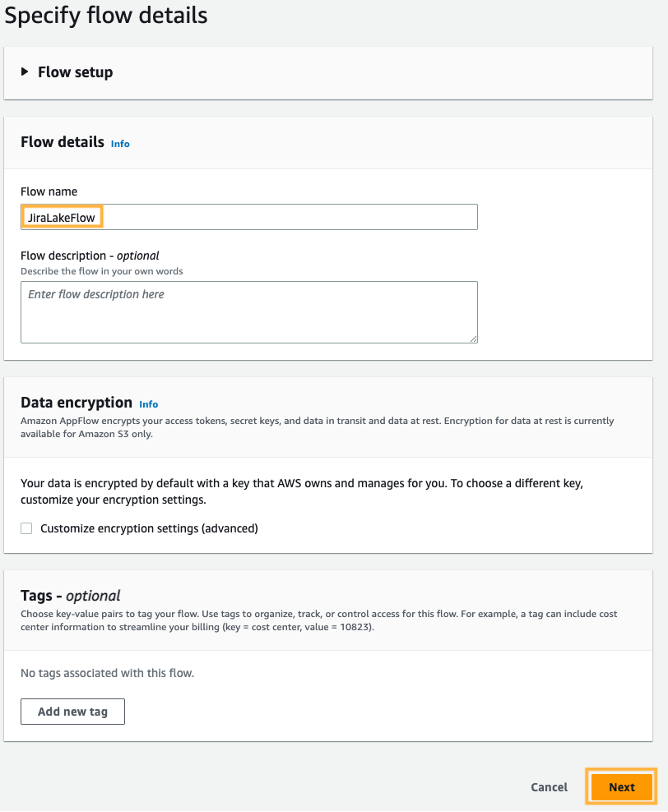
- สำหรับ ชื่อโฟลว์ ป้อนชื่อสำหรับโฟลว์ (เช่น
JiraLakeFlow). - ออกจาก การเข้ารหัสข้อมูล การตั้งค่าเป็นค่าเริ่มต้น
- Choose ถัดไป.
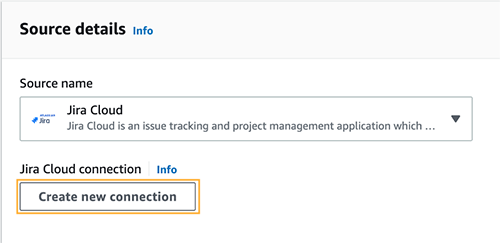
- สำหรับ ชื่อแหล่งที่มา, ใช้ค่าเริ่มต้นของ จิรา คลาวด์.
- Choose สร้างการเชื่อมต่อใหม่ ภายใต้ การเชื่อมต่อจิราคลาวด์.
- ตัว Vortex Indicator ได้ถูกนำเสนอลงในนิตยสาร เชื่อมต่อกับจิราคลาวด์ ส่วน ให้ป้อนค่าสำหรับ รหัสลูกค้า, ความลับของลูกค้าและ จิราคลาวด์ไซต์ ที่คุณรวบรวมไว้ก่อนหน้านี้ นี่เป็นการรับรองความถูกต้องจาก AppFlow ถึง Jira Cloud
- สำหรับ ชื่อการเชื่อมต่อป้อนชื่อการเชื่อมต่อ (เช่น
JiraLakeCloudConnection). - Choose เชื่อมต่อ- คุณจะได้รับแจ้งให้อนุญาตให้แอป OAuth เข้าถึงบัญชี Atlassian ของคุณเพื่อตรวจสอบการตรวจสอบสิทธิ์
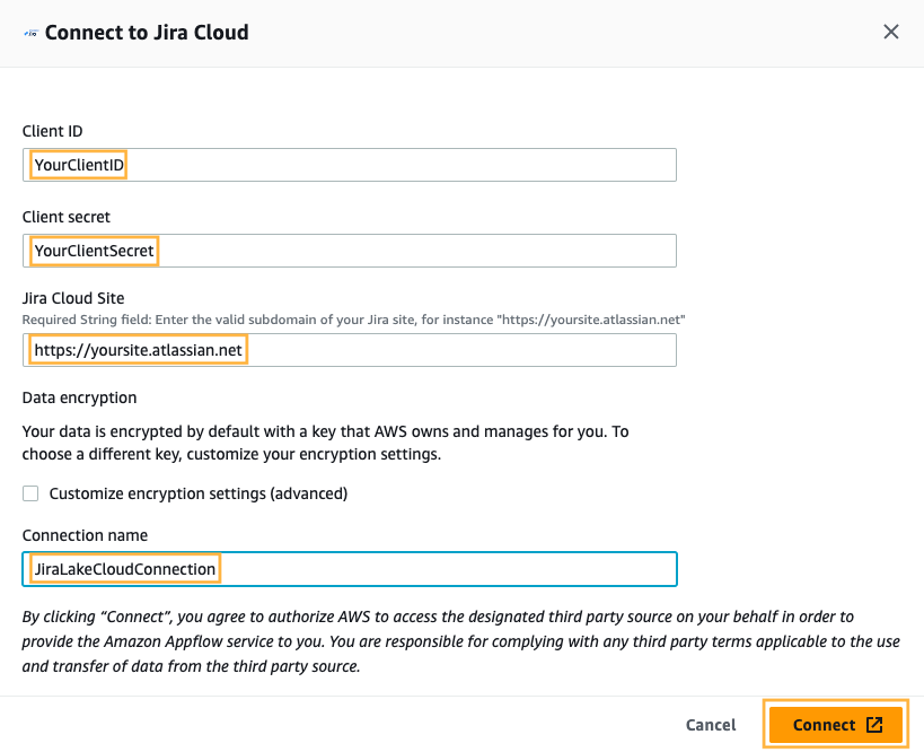
- ตัว Vortex Indicator ได้ถูกนำเสนอลงในนิตยสาร อนุญาตแอป หน้าต่างที่ปรากฏขึ้น ให้เลือก ยอมรับ.
- เมื่อสร้างการเชื่อมต่อแล้ว ให้กลับไปที่ กำหนดค่าโฟลว์ ส่วนบนคอนโซล Amazon AppFlow
- สำหรับ เวอร์ชันเอพีไอเลือก V2 เพื่อใช้ API การค้นหา Jira ล่าสุด
- สำหรับ วัตถุจิราคลาวด์เลือก »ÑËÒ เพื่อค้นหาและดาวน์โหลดประเด็นทั้งหมดและรายละเอียดที่เกี่ยวข้อง
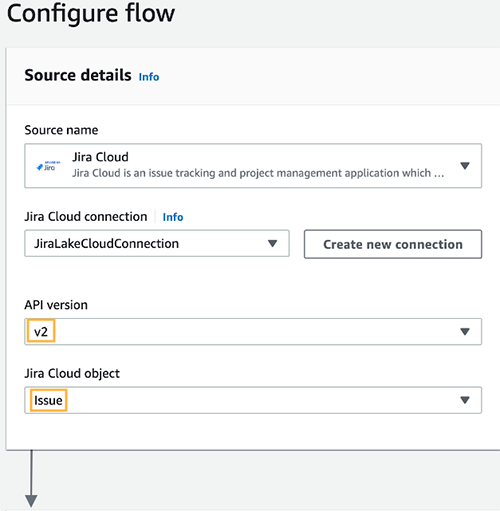
- สำหรับ ชื่อปลายทาง ใน รายละเอียดจุดหมายปลายทาง ส่วนเลือก Amazon S3.
- สำหรับ รายละเอียดถังให้เลือกชื่อบัคเก็ต S3 ที่ตรงกับค่าบัคเก็ตปลายทางของ Amazon AppFlow ที่คุณรวบรวมจากเอาต์พุตของสแต็ก CloudFormation
- ป้อนเส้นทางบัคเก็ตปลายทางของ Amazon AppFlow เพื่อดำเนินการเส้นทาง S3 แบบเต็ม การดำเนินการนี้จะส่งข้อมูล Jira ไปยังบัคเก็ต S3 ที่สร้างโดยสคริปต์ CloudFormation
- ทิ้ง จัดทำรายการข้อมูลของคุณใน AWS Glue Data Catalog ไม่ได้เลือก สคริปต์ CloudFormation ใช้โปรแกรมรวบรวมข้อมูล AWS Glue เพื่ออัปเดต Data Catalog ในลักษณะอื่น โดยจัดกลุ่มการดาวน์โหลดทั้งหมดไว้ในตารางทั่วไป ดังนั้นเราจึงปิดใช้งานการอัปเดตที่นี่
- สำหรับ การตั้งค่ารูปแบบไฟล์ให้เลือก รูปแบบปาร์เก้ และเลือก รักษาชนิดข้อมูลต้นฉบับในเอาต์พุต Parquet- ไม้ปาร์เก้เป็นรูปแบบเสาเพื่อเพิ่มประสิทธิภาพการสืบค้นในภายหลัง
- เลือก เพิ่มการประทับเวลาให้กับชื่อไฟล์ for
การตั้งค่าชื่อไฟล์- ซึ่งจะทำให้คุณสามารถค้นหาไฟล์ข้อมูลที่ดาวน์โหลดตามวันและเวลาที่ระบุได้อย่างง่ายดาย

- ในตอนนี้ ให้เลือก รันออนดีมานด์ สำหรับ ทริกเกอร์การไหล เพื่อรันโฟลว์โหลดแบบเต็มด้วยตนเอง คุณจะกำหนดเวลาการดาวน์โหลดในขั้นตอนต่อมาเมื่อใช้ CDC
- Choose ถัดไป.

- เกี่ยวกับ แมปเขตข้อมูล ใหเลือก แมปฟิลด์ด้วยตนเอง.
- สำหรับ การทำแผนที่ฟิลด์ต้นทางไปยังปลายทางให้เลือกช่องแบบเลื่อนลงด้านล่าง ชื่อช่องต้นทาง และเลือก แมปฟิลด์ทั้งหมดโดยตรง- การดำเนินการนี้จะดึงฟิลด์ทั้งหมดลงตามที่ได้รับ เนื่องจากเราจะใช้การเตรียมข้อมูลในขั้นตอนต่อๆ ไปแทน
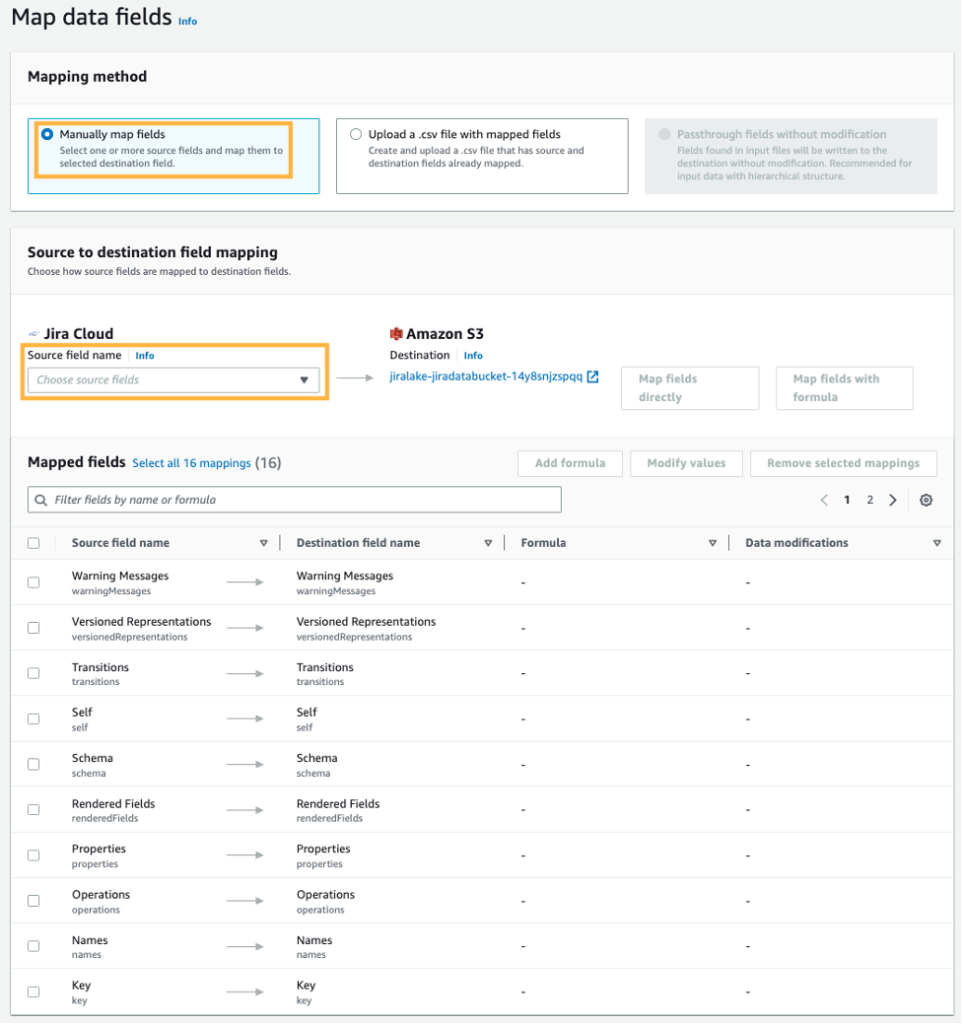
- ภายใต้ การตั้งค่าพาร์ติชันและการรวมกลุ่มคุณสามารถตั้งค่าพาร์ติชันในลักษณะที่เหมาะกับกรณีการใช้งานของคุณได้ สำหรับตัวอย่างนี้ เราใช้พาร์ติชันรายวัน ดังนั้นให้เลือก วันและเวลา และเลือก ทุกวัน.
- สำหรับ การตั้งค่าการรวมกลุ่มปล่อยให้มันเป็นค่าเริ่มต้นของ อย่ารวมกัน.
- Choose ถัดไป.

- เกี่ยวกับ เพิ่มตัวกรอง คุณสามารถสร้างตัวกรองเพื่อดาวน์โหลดเฉพาะข้อมูลที่ต้องการได้ สำหรับตัวอย่างนี้ คุณดาวน์โหลดข้อมูลทั้งหมด ดังนั้นให้เลือก ถัดไป.
- ตรวจสอบและเลือก สร้างกระแส.
- เมื่อสร้างโฟลว์แล้ว ให้เลือก วิ่งไหล เพื่อเริ่มต้นการเพาะข้อมูลเบื้องต้น หลังจากนั้นสักครู่ คุณจะได้รับแบนเนอร์แจ้งว่าการวิ่งเสร็จสิ้นเรียบร้อยแล้ว

ตรวจสอบข้อมูลเมล็ดพันธุ์
ในขั้นตอนนี้ของกระบวนการ ขณะนี้คุณมีข้อมูลในสภาพแวดล้อม S3 ของคุณแล้ว เมื่อมีการสร้างไฟล์ข้อมูลใหม่ในบัคเก็ต S3 ระบบจะเรียกใช้โปรแกรมรวบรวมข้อมูล AWS Glue โดยอัตโนมัติเพื่อจัดทำแคตตาล็อกข้อมูลใหม่ คุณสามารถดูได้ว่าเสร็จสมบูรณ์หรือไม่โดยการตรวจสอบเครื่องสถานะ Step Functions สำหรับ ประสบความสำเร็จ สถานะการทำงาน มีลิงก์ไปยังเครื่องสถานะบนสแต็ก CloudFormation แหล่งข้อมูล ซึ่งจะนำคุณไปยังเครื่องสถานะ Step Functions
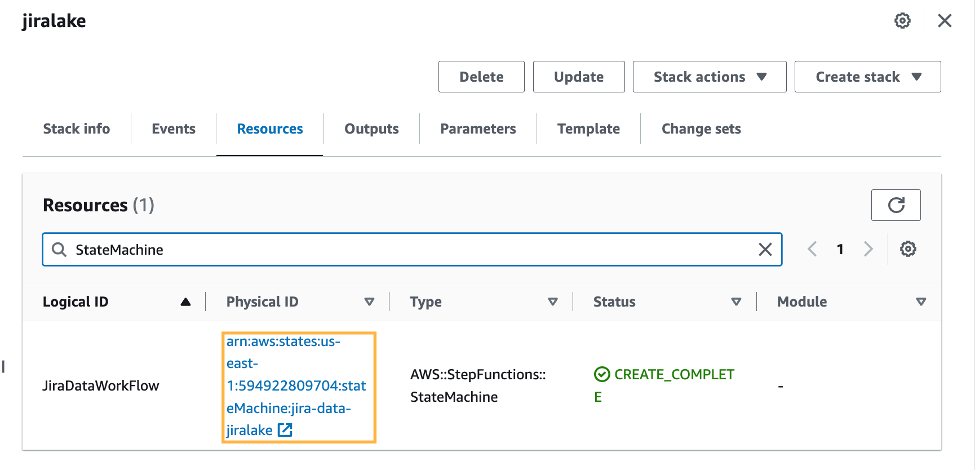
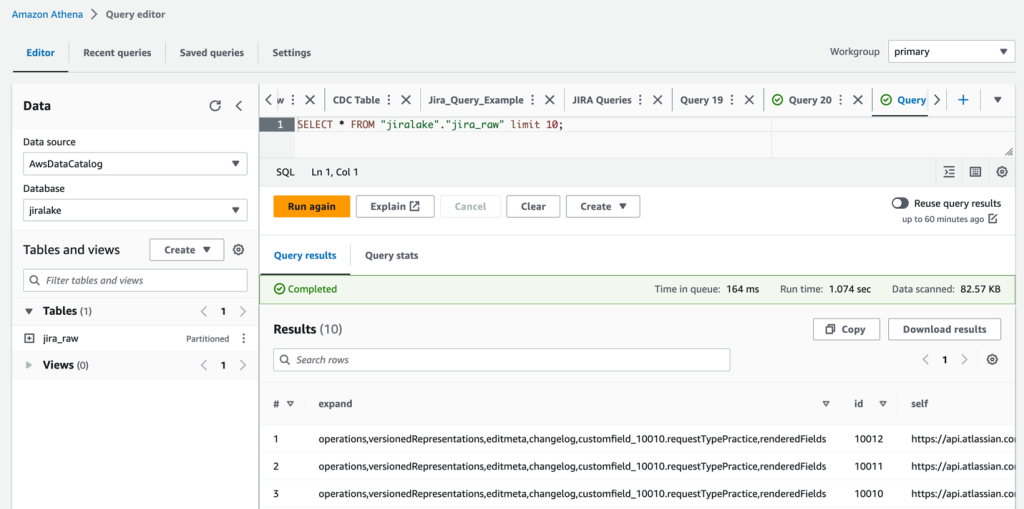
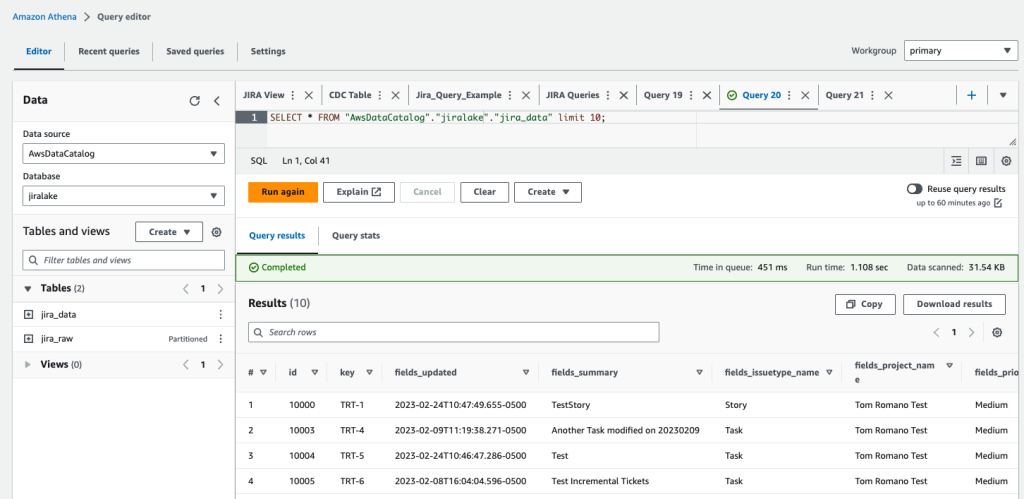
เมื่อเครื่องสถานะเสร็จสมบูรณ์ ก็ถึงเวลาตรวจสอบข้อมูลดิบของ Jira กับ Athena ฐานข้อมูลเป็นไปตามที่คุณระบุใน CloudFormation stack (jiralake โดยค่าเริ่มต้น) และชื่อตารางคือ jira_raw- หากคุณเก็บชื่อฐานข้อมูล AWS Glue เริ่มต้นไว้ jiralakeAthena SQL เป็นดังนี้:
หากคุณสำรวจข้อมูล คุณจะสังเกตเห็นว่าข้อมูลส่วนใหญ่ที่คุณต้องการใช้งานนั้นจริงๆ แล้วบรรจุอยู่ในคอลัมน์ที่เรียกว่า fields- ซึ่งหมายความว่าข้อมูลจะไม่พร้อมใช้งานเป็นคอลัมน์ในการสืบค้น Athena ของคุณ ทำให้ยากต่อการเลือก กรอง และจัดเรียงแต่ละฟิลด์ภายในการสืบค้น Athena SQL สิ่งนี้จะได้รับการแก้ไขในขั้นตอนถัดไป
ตั้งค่า CDC และคลายคอลัมน์ฟิลด์
ในการเพิ่ม CDC ที่กำลังดำเนินอยู่และฟอร์แมตข้อมูลใหม่สำหรับการวิเคราะห์ เราขอแนะนำงาน DataBrew เพื่อแปลงข้อมูลและกรองเป็นเวอร์ชันล่าสุดของแต่ละบันทึกเมื่อมีการเปลี่ยนแปลงเข้ามา คุณสามารถทำได้โดยอัปเดตสแตก CloudFormation ด้วยแฟล็กที่มี CDC และขั้นตอนการแปลงข้อมูล
- บนคอนโซล AWS CloudFormation ให้กลับไปที่สแต็ก
- Choose บันทึก.
- เลือก ใช้เทมเพลตปัจจุบัน และเลือก ถัดไป.
- สำหรับ โปรแกรมติดตั้งOrCDCเลือก CDCแล้วเลือก ถัดไป- ซึ่งจะเปิดใช้งานทั้งขั้นตอน CDC และขั้นตอนการแปลงข้อมูลสำหรับข้อมูล Jira
- เลือกต่อไป ถัดไป จนกระทั่งถึง รีวิว มาตรา.
- เลือก ฉันรับทราบว่า AWS CloudFormation อาจสร้างทรัพยากร IAMแล้วเลือก ส่ง.

- กลับไปที่คอนโซล Amazon AppFlow แล้วเปิดโฟลว์ของคุณ
- เกี่ยวกับ สถานะ เมนูให้เลือก แก้ไขโฟลว์- ตอนนี้เราจะแก้ไขทริกเกอร์โฟลว์เพื่อเรียกใช้การโหลดที่เพิ่มขึ้นเป็นระยะๆ
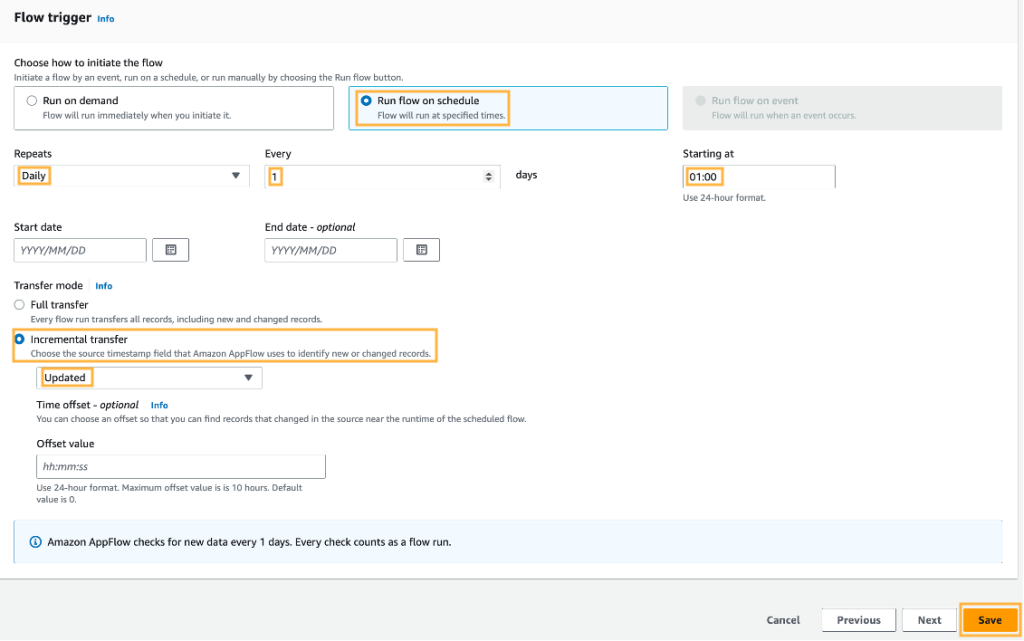
- เลือก เรียกใช้โฟลว์ตามกำหนดเวลา.
- กำหนดค่าการทำซ้ำที่ต้องการ รวมถึงเวลาและวันที่เริ่มต้น สำหรับตัวอย่างนี้ เราเลือก ทุกวัน for ซ้ำ และป้อน 1 สำหรับจำนวนวันที่คุณจะมีทริกเกอร์โฟลว์ สำหรับ เริ่มต้นที่, เข้า 01:00 น.
- เลือก การถ่ายโอนที่เพิ่มขึ้น for โหมดถ่ายโอน.
- Choose วันที่อัพเดท บนเมนูแบบเลื่อนลงเพื่อให้บันทึกการเปลี่ยนแปลงตามเวลาที่อัปเดตบันทึก
- Choose ลด- ด้วยการตั้งค่าเหล่านี้ในตัวอย่างของเรา การวิ่งจะเกิดขึ้นทุกคืนเวลา 1:00 น.
ตรวจสอบข้อมูลการวิเคราะห์
เมื่อโหลดส่วนเพิ่มครั้งถัดไปเกิดขึ้นซึ่งส่งผลให้เกิดข้อมูลใหม่ เวิร์กโฟลว์ Step Functions จะเริ่มงาน DataBrew และเติมตารางข้อมูลเชิงวิเคราะห์แบบเป็นขั้นใหม่ชื่อ jira_data ในฐานข้อมูล Data Catalog ของคุณ หากคุณไม่ต้องการรอ คุณสามารถทริกเกอร์เวิร์กโฟลว์ Step Functions ได้ด้วยตนเอง
งาน DataBrew ดำเนินการแปลงข้อมูลและงานกรอง งานจะแยกคีย์-ค่าออกจากข้อมูล Jira JSON และข้อมูลดิบของ Jira ส่งผลให้เกิดสคีมาข้อมูลแบบตารางที่อำนวยความสะดวกในการใช้งานกับเครื่องมือ BI และ AI/ML เมื่อรายการ Jira มีการเปลี่ยนแปลง ข้อมูลของรายการที่เปลี่ยนแปลงจะถูกส่งอีกครั้ง ส่งผลให้รายการมีหลายเวอร์ชันในฟีดข้อมูลดิบ งาน DataBrew กรองฟีดข้อมูลดิบเพื่อให้ตารางข้อมูลผลลัพธ์มีเฉพาะเวอร์ชันล่าสุดของแต่ละรายการเท่านั้น คุณสามารถปรับปรุงงาน DataBrew นี้เพื่อปรับแต่งข้อมูลตามความต้องการของคุณเพิ่มเติมได้ เช่น การเปลี่ยนชื่อฟิลด์ที่กำหนดเองของ Jira ทั่วไปเพื่อให้สะท้อนถึงความหมายทางธุรกิจ
เมื่อเวิร์กโฟลว์ Step Functions เสร็จสมบูรณ์ เราสามารถสืบค้นข้อมูลใน Athena ได้อีกครั้งโดยใช้แบบสอบถามต่อไปนี้:
คุณจะเห็นได้ว่าในการเปลี่ยนแปลงของเรา jira_data ตาราง ฟิลด์ JSON ที่ซ้อนกันจะแบ่งออกเป็นคอลัมน์ของตัวเองสำหรับแต่ละฟิลด์ นอกจากนี้ คุณจะสังเกตเห็นว่าเราได้กรองบันทึกที่ล้าสมัยซึ่งถูกแทนที่ด้วยการอัปเดตบันทึกล่าสุดในการโหลดข้อมูลในภายหลัง เพื่อให้ข้อมูลมีความสดใหม่ หากคุณต้องการเปลี่ยนชื่อช่องที่กำหนดเอง ลบคอลัมน์ หรือปรับโครงสร้างสิ่งที่ออกมาจาก JSON ที่ซ้อนกัน คุณสามารถแก้ไขสูตร DataBrew เพื่อให้บรรลุเป้าหมายนี้ได้ ณ จุดนี้ ข้อมูลก็พร้อมที่จะใช้งานโดยเครื่องมือวิเคราะห์ของคุณ เช่น อเมซอน QuickSight.
ทำความสะอาด
หากคุณต้องการยุติโซลูชันนี้ คุณสามารถลบออกได้โดยทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล Amazon AppFlow ให้ปิดใช้งานโฟลว์สำหรับ Jira และเลือกลบออกได้
- บนคอนโซล Amazon S3 ให้เลือกบัคเก็ต S3 สำหรับสแต็ก และล้างบัคเก็ตเพื่อลบข้อมูลที่มีอยู่
- บนคอนโซล AWS CloudFormation ให้ลบสแต็ก CloudFormation ที่คุณปรับใช้
สรุป
ในโพสต์นี้ เราได้สร้างกระบวนการโหลดข้อมูลส่วนเพิ่มแบบไร้เซิร์ฟเวอร์สำหรับ Jira ที่จะซิงโครไนซ์ข้อมูลในขณะที่จัดการฟิลด์ที่กำหนดเองโดยใช้ Amazon AppFlow, AWS Glue และ Step Functions วิธีการนี้ใช้ Amazon AppFlow เพื่อโหลดข้อมูลลงใน Amazon S3 เพิ่มขึ้น จากนั้นเราใช้ AWS Glue และ Step Functions เพื่อจัดการการแยกฟิลด์ที่กำหนดเองของ Jira และโหลดฟิลด์เหล่านั้นในรูปแบบที่จะสอบถามโดยบริการการวิเคราะห์ เช่น Athena, QuickSight หรือ Redshift Spectrum หรือบริการ AI/ML เช่น อเมซอน SageMaker.
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ AWS Glue และ DataBrew โปรดดูที่ เริ่มต้นใช้งาน AWS Glue DataBrew- ด้วย DataBrew คุณสามารถนำตัวอย่างการแปลงข้อมูลในโปรเจ็กต์นี้และปรับแต่งเอาต์พุตให้ตรงกับความต้องการเฉพาะของคุณได้ ซึ่งอาจรวมถึงการเปลี่ยนชื่อคอลัมน์ การสร้างฟิลด์เพิ่มเติม และอื่นๆ
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ Amazon AppFlow โปรดดูที่ เริ่มต้นใช้งาน Amazon AppFlow- โปรดทราบว่า Amazon AppFlow รองรับการผสานรวมกับแอปพลิเคชัน SaaS จำนวนมาก นอกเหนือจาก Jira Cloud
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการจัดเตรียมโฟลว์ด้วย Step Functions โปรดดู สร้างเวิร์กโฟลว์แบบไร้เซิร์ฟเวอร์ด้วย AWS Step Functions และ AWS Lambda- เวิร์กโฟลว์สามารถปรับปรุงเพื่อโหลดข้อมูลลงในคลังข้อมูลได้ เช่น อเมซอน Redshiftหรือทริกเกอร์การรีเฟรชชุดข้อมูล QuickSight สำหรับการวิเคราะห์และการรายงาน
ในโพสต์ต่อๆ ไป เราจะกล่าวถึงวิธีการแยกความสัมพันธ์ระหว่างพ่อแม่และลูกภายในข้อมูล Jira โดยใช้ Athena และวิธีการแสดงภาพข้อมูลโดยใช้ QuickSight
เกี่ยวกับผู้เขียน
 ทอม โรมาโน เป็นสถาปนิกโซลูชันอาวุโสสำหรับ AWS World Wide Public Sector จากแทมปา รัฐฟลอริดา และช่วยเหลือลูกค้า GovTech และ EdTech ในขณะที่พวกเขาสร้างโซลูชันใหม่ที่เป็นระบบคลาวด์เนทิฟ ขับเคลื่อนด้วยเหตุการณ์ และไม่มีเซิร์ฟเวอร์ เขาเป็นโปรแกรมเมอร์ Python ที่กระตือรือร้นทั้งในด้านการพัฒนาแอปพลิเคชันและการวิเคราะห์ข้อมูล และเป็นผู้เชี่ยวชาญด้านการวิเคราะห์ ในเวลาว่าง ทอมบินเครื่องบินจำลองควบคุมระยะไกลและสนุกกับการพักผ่อนกับครอบครัวทั่วฟลอริดาและแคริบเบียน
ทอม โรมาโน เป็นสถาปนิกโซลูชันอาวุโสสำหรับ AWS World Wide Public Sector จากแทมปา รัฐฟลอริดา และช่วยเหลือลูกค้า GovTech และ EdTech ในขณะที่พวกเขาสร้างโซลูชันใหม่ที่เป็นระบบคลาวด์เนทิฟ ขับเคลื่อนด้วยเหตุการณ์ และไม่มีเซิร์ฟเวอร์ เขาเป็นโปรแกรมเมอร์ Python ที่กระตือรือร้นทั้งในด้านการพัฒนาแอปพลิเคชันและการวิเคราะห์ข้อมูล และเป็นผู้เชี่ยวชาญด้านการวิเคราะห์ ในเวลาว่าง ทอมบินเครื่องบินจำลองควบคุมระยะไกลและสนุกกับการพักผ่อนกับครอบครัวทั่วฟลอริดาและแคริบเบียน
 เชน ทอมป์สัน เป็น Sr. Solutions Architect ในเมืองซานหลุยส์โอบิสโป รัฐแคลิฟอร์เนีย โดยทำงานร่วมกับ AWS Startups เขาทำงานร่วมกับลูกค้าที่ใช้ AI/ML ในรูปแบบธุรกิจของตน และมีความหลงใหลในการทำให้ AI/ML เป็นประชาธิปไตย เพื่อให้ลูกค้าทุกคนได้รับประโยชน์จากสิ่งนี้ ในเวลาว่าง Shane ชอบที่จะใช้เวลากับครอบครัวและท่องเที่ยวรอบโลก
เชน ทอมป์สัน เป็น Sr. Solutions Architect ในเมืองซานหลุยส์โอบิสโป รัฐแคลิฟอร์เนีย โดยทำงานร่วมกับ AWS Startups เขาทำงานร่วมกับลูกค้าที่ใช้ AI/ML ในรูปแบบธุรกิจของตน และมีความหลงใหลในการทำให้ AI/ML เป็นประชาธิปไตย เพื่อให้ลูกค้าทุกคนได้รับประโยชน์จากสิ่งนี้ ในเวลาว่าง Shane ชอบที่จะใช้เวลากับครอบครัวและท่องเที่ยวรอบโลก
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. ยานยนต์ / EVs, คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- BlockOffsets การปรับปรุงการเป็นเจ้าของออฟเซ็ตด้านสิ่งแวดล้อมให้ทันสมัย เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/empower-your-jira-data-in-a-data-lake-with-amazon-appflow-and-aws-glue/
- :เป็น
- :ไม่
- $ ขึ้น
- 1
- 10
- 100
- 24
- 25
- 27
- 31
- 500
- 7
- 700
- a
- เกี่ยวกับเรา
- เข้า
- บรรลุผล
- ลงชื่อเข้าใช้
- บรรลุ
- รับทราบ
- กิจกรรม
- จริง
- เพิ่ม
- นอกจากนี้
- เพิ่มเติม
- นอกจากนี้
- การบริหาร
- หลังจาก
- อีกครั้ง
- การรวมตัว
- AI
- AI / ML
- เครื่องบิน
- ทั้งหมด
- อนุญาต
- ช่วยให้
- ด้วย
- am
- อเมซอน
- อเมซอน อาเธน่า
- Amazon Web Services
- an
- วิเคราะห์
- การวิเคราะห์
- และ
- API
- app
- การใช้งาน
- การพัฒนาโปรแกรมประยุกต์
- การใช้งาน
- เข้าใกล้
- เหมาะสม
- สถาปัตยกรรม
- เป็น
- รอบ
- จัด
- มาถึง
- เทียม
- ปัญญาประดิษฐ์
- ปัญญาประดิษฐ์ (AI)
- AS
- ช่วย
- ที่เกี่ยวข้อง
- At
- Atlassian
- การยืนยันตัวตน
- อัตโนมัติ
- อัตโนมัติ
- ใช้ได้
- AWS
- การก่อตัวของ AWS Cloud
- AWS กาว
- ฟังก์ชันขั้นตอนของ AWS
- กลับ
- แบนเนอร์
- ตาม
- รากฐาน
- BE
- เพราะ
- รับ
- ก่อน
- ประโยชน์
- คณะกรรมการ
- ทั้งสอง
- กล่อง
- ในกล่องสี่เหลี่ยม
- นำมาซึ่ง
- การนำ
- แตก
- ธุรกิจ
- ระบบธุรกิจอัจฉริยะ
- รูปแบบธุรกิจ
- ปุ่ม
- by
- แคลิฟอร์เนีย
- ที่เรียกว่า
- CAN
- ความสามารถในการ
- ความสามารถ
- จับ
- ถูกจับกุม
- จับ
- แคริบเบียน
- กรณี
- แค็ตตาล็อก
- CDC
- เปลี่ยนแปลง
- การเปลี่ยนแปลง
- การเปลี่ยนแปลง
- ตรวจสอบ
- การตรวจสอบ
- Choose
- เลือก
- ไคลเอนต์
- เมฆ
- เมฆพื้นเมือง
- รวบรวม
- เก็บรวบรวม
- คอลัมน์
- คอลัมน์
- อย่างไร
- มา
- ร่วมกัน
- บริษัท
- สมบูรณ์
- อย่างสมบูรณ์
- เสร็จสิ้น
- ส่วนประกอบ
- ประกอบด้วย
- องค์ประกอบ
- การเชื่อมต่อ
- ปลอบใจ
- การบริโภค
- มี
- ควบคุม
- ราคา
- ได้
- หน้าปก
- ไม้เลื้อย
- สร้าง
- ที่สร้างขึ้น
- การสร้าง
- ปัจจุบัน
- ประเพณี
- ลูกค้า
- ปรับแต่ง
- ประจำวัน
- ข้อมูล
- การเข้าถึงข้อมูล
- วิเคราะห์ข้อมูล
- ดาต้าเลค
- การเตรียมข้อมูล
- คลังข้อมูล
- ฐานข้อมูล
- ชุดข้อมูล
- วันที่
- วัน
- ค่าเริ่มต้น
- democratizing
- แสดงให้เห็นถึง
- ปรับใช้
- นำไปใช้
- ที่ต้องการ
- ปลายทาง
- รายละเอียด
- ผู้พัฒนา
- พัฒนาการ
- ต่าง
- การค้นพบ
- สนทนา
- do
- ทำ
- Dont
- ลง
- ดาวน์โหลด
- ดาวน์โหลด
- ขับเคลื่อน
- แต่ละ
- ก่อน
- อย่างง่ายดาย
- EdTech
- อย่างมีประสิทธิภาพ
- ความพยายาม
- ให้อำนาจ
- ทำให้สามารถ
- ชั้นเยี่ยม
- เสริม
- ที่เพิ่มขึ้น
- ทำให้มั่นใจ
- เข้าสู่
- กระตือรือร้น
- สิ่งแวดล้อม
- มหากาพย์
- ข้อผิดพลาด
- สร้าง
- ที่จัดตั้งขึ้น
- การสร้าง
- อีเธอร์ (ETH)
- เหตุการณ์
- ตัวอย่าง
- ที่มีอยู่
- สำรวจ
- สารสกัด
- การสกัด
- อำนวยความสะดวก
- อำนวยความสะดวก
- ครอบครัว
- คุณสมบัติ
- สนาม
- สาขา
- รูป
- เนื้อไม่มีมัน
- ไฟล์
- กรอง
- กรอง
- ฟิลเตอร์
- หา
- ฟลอริด้า
- ไหล
- กระแส
- ดังต่อไปนี้
- ดังต่อไปนี้
- สำหรับ
- รูป
- ฟรี
- สด
- ราคาเริ่มต้นที่
- เต็ม
- อย่างเต็มที่
- ฟังก์ชั่น
- ต่อไป
- อนาคต
- โกฟเทค
- ให้
- การจัดการ
- เกิดขึ้น
- ยาก
- มี
- he
- จะช่วยให้
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- ไฮไลต์
- ของเขา
- ทางประวัติศาสตร์
- ถือ
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTML
- ที่ http
- HTTPS
- AMI
- ID
- เอกลักษณ์
- if
- แสดงให้เห็นถึง
- ภาพ
- การดำเนินการ
- การดำเนินการ
- in
- ประกอบด้วย
- รวมถึง
- รวมทั้ง
- การแสดง
- เป็นรายบุคคล
- แรกเริ่ม
- ข้อมูลเชิงลึก
- ตัวอย่าง
- แทน
- คำแนะนำการใช้
- บูรณาการ
- การผสานรวม
- Intelligence
- เข้าไป
- แนะนำ
- ปัญหา
- IT
- รายการ
- การสัมภาษณ์
- jpg
- JSON
- เก็บ
- เก็บไว้
- ความรู้
- ทะเลสาบ
- ต่อมา
- ล่าสุด
- เปิดตัว
- นำไปสู่
- เรียนรู้
- การเรียนรู้
- น้อยที่สุด
- ทิ้ง
- กดไลก์
- LIMIT
- LINK
- โหลด
- โหลด
- โหลด
- การเข้าสู่ระบบ
- เข้าสู่ระบบ
- รัก
- ต่ำ
- เครื่อง
- เรียนรู้เครื่อง
- การทำ
- จัดการ
- การจัดการ
- เครื่องมือการจัดการ
- การจัดการ
- ลักษณะ
- ด้วยมือ
- หลาย
- แผนที่
- อาจ..
- ความหมาย
- วิธี
- กลไก
- พบ
- เมนู
- เมตาดาต้า
- อาจ
- นาที
- หายไป
- ผสม
- ML
- โหมด
- แบบ
- แก้ไข
- ข้อมูลเพิ่มเติม
- มากที่สุด
- หลาย
- ชื่อ
- ที่มีชื่อ
- ชื่อ
- พื้นเมือง
- การเดินเรือ
- จำเป็นต้อง
- ความต้องการ
- ใหม่
- โซลูชั่นใหม่
- ถัดไป
- หมายเหตุ
- สังเกต..
- ตอนนี้
- จำนวน
- รับรอง
- ล้าสมัย
- of
- มักจะ
- on
- ONE
- ต่อเนื่อง
- เพียง
- เปิด
- การดำเนินงาน
- การเพิ่มประสิทธิภาพ
- เพิ่มประสิทธิภาพ
- or
- องค์กร
- อื่นๆ
- ของเรา
- ออก
- เอาท์พุต
- เกิน
- ของตนเอง
- แน่น
- หน้า
- คู่
- บานหน้าต่าง
- พารามิเตอร์
- หลงใหล
- เส้นทาง
- ดำเนินการ
- เป็นระยะ
- การอนุญาต
- สิทธิ์
- ท่อ
- สถานที่
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- จุด
- Pops
- ประชากร
- พอร์ทัล
- โพสต์
- โพสต์
- การจัดเตรียม
- เตรียมการ
- เตรียมความพร้อม
- ก่อน
- กระบวนการ
- โปรแกรมเมอร์
- โครงการ
- การบริหารจัดการโครงการ
- โครงการ
- ให้
- ให้
- สาธารณะ
- หลาม
- คำสั่ง
- ดิบ
- ข้อมูลดิบ
- มาถึง
- พร้อม
- รับ
- ที่ได้รับ
- เมื่อเร็ว ๆ นี้
- สูตร
- ระเบียน
- บันทึก
- เปลี่ยนเส้นทาง
- สะท้อน
- ความสัมพันธ์
- รีโมท
- เอาออก
- ลบ
- การรายงาน
- เป็นตัวแทนของ
- แสดงให้เห็นถึง
- ร้องขอ
- ต้อง
- แหล่งข้อมูล
- ปรับโครงสร้าง
- ส่งผลให้
- ผลสอบ
- กลับ
- ทบทวน
- การตรวจสอบ
- รวย
- บทบาท
- วิ่ง
- ทำงาน
- s
- SaaS
- เดียวกัน
- ซาน
- การสแกน
- กำหนด
- ค้นหา
- ลับ
- Section
- ภาค
- เห็น
- เมล็ดพันธุ์
- เลือก
- ส่ง
- serverless
- บริการ
- บริการ
- ชุด
- การตั้งค่า
- การตั้งค่า
- การติดตั้ง
- หลาย
- น่า
- โชว์
- การแสดง
- แสดง
- แสดงให้เห็นว่า
- ง่าย
- ลดความซับซ้อน
- เดียว
- So
- ซอฟต์แวร์
- ซอฟต์แวร์เป็นบริการ
- วิศวกรรมซอฟต์แวร์
- ทางออก
- โซลูชัน
- บาง
- แหล่ง
- ผู้เชี่ยวชาญ
- โดยเฉพาะ
- ที่ระบุไว้
- สเปกตรัม
- ใช้จ่าย
- SQL
- กอง
- ระยะ
- เริ่มต้น
- ข้อความที่เริ่ม
- ที่เริ่มต้น
- startups
- สถานะ
- Status
- ขั้นตอน
- ขั้นตอน
- การเก็บรักษา
- จัดเก็บ
- เก็บไว้
- มุ่งมั่น
- ภายหลัง
- ประสบความสำเร็จ
- อย่างเช่น
- สรุป
- สนับสนุน
- รองรับ
- ระบบ
- ตาราง
- เอา
- งาน
- ที่
- พื้นที่
- รัฐ
- โลก
- ของพวกเขา
- พวกเขา
- แล้วก็
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- เวลา
- การประทับเวลา
- ไปยัง
- ทอม
- เครื่องมือ
- โอน
- แปลง
- การแปลง
- เปลี่ยน
- การเดินทาง
- เรียก
- ทริกเกอร์
- สอง
- ชนิด
- ภายใต้
- เป็นเอกลักษณ์
- แกะกล่อง
- จนกระทั่ง
- บันทึก
- ให้กับคุณ
- การปรับปรุง
- การปรับปรุง
- URL
- ใช้
- ใช้กรณี
- มือสอง
- ใช้
- การใช้
- ความคุ้มค่า
- ความคุ้มค่า
- ตรวจสอบ
- รุ่น
- รุ่น
- เห็นภาพ
- รอ
- ต้องการ
- คลังสินค้า
- ทาง..
- we
- เว็บ
- บริการเว็บ
- ดี
- คือ
- อะไร
- เมื่อ
- ที่
- ในขณะที่
- WHO
- กว้าง
- จะ
- หน้าต่าง
- กับ
- ภายใน
- ไม่มี
- งาน
- เวิร์กโฟลว์
- การทำงาน
- โรงงาน
- โลก
- จะ
- เธอ
- ของคุณ
- ลมทะเล