ในเดือนพฤศจิกายน 2022 เรา ประกาศ ที่ลูกค้า AWS สามารถสร้างรูปภาพจากข้อความได้ การแพร่กระจายที่เสถียร แบบจำลองใน Amazon SageMaker JumpStart. Stable Diffusion เป็นโมเดลการเรียนรู้เชิงลึกที่ช่วยให้คุณสร้างภาพคุณภาพสูงสมจริงและงานศิลปะที่น่าทึ่งได้ในเวลาเพียงไม่กี่วินาที แม้ว่าการสร้างภาพที่น่าประทับใจสามารถใช้ประโยชน์ได้ในอุตสาหกรรมต่างๆ ตั้งแต่งานศิลปะไปจนถึง NFT และอื่นๆ แต่วันนี้เรายังคาดหวังว่า AI จะสามารถปรับแต่งได้ วันนี้เราขอประกาศว่าคุณสามารถปรับแต่งโมเดลการสร้างภาพให้เหมาะกับกรณีการใช้งานของคุณโดยการปรับแต่งอย่างละเอียดบนชุดข้อมูลที่คุณกำหนดเองใน Amazon SageMaker JumpStart. สิ่งนี้มีประโยชน์เมื่อสร้างงานศิลปะ โลโก้ การออกแบบที่กำหนดเอง NFT และอื่นๆ หรือเรื่องสนุกๆ เช่น การสร้างภาพ AI แบบกำหนดเองของสัตว์เลี้ยงหรืออวาตาร์ของคุณเอง
ในโพสต์นี้ เราจะให้ภาพรวมของวิธีการปรับแต่งโมเดล Stable Diffusion แบบละเอียดในสองวิธี: โดยทางโปรแกรมผ่าน JumpStart API มีอยู่ในไฟล์ SageMaker Python SDKและส่วนติดต่อผู้ใช้ (UI) ของ JumpStart ใน สตูดิโอ Amazon SageMaker. นอกจากนี้ เรายังหารือเกี่ยวกับวิธีเลือกการออกแบบ รวมถึงคุณภาพของชุดข้อมูล ขนาดของชุดข้อมูลการฝึก การเลือกค่าไฮเปอร์พารามิเตอร์ และการบังคับใช้กับชุดข้อมูลหลายชุด สุดท้าย เราจะหารือเกี่ยวกับโมเดลที่ปรับแต่งอย่างละเอียดกว่า 80 รายการที่เผยแพร่ต่อสาธารณะด้วยภาษาและสไตล์อินพุตที่แตกต่างกันที่เพิ่งเพิ่มเข้ามาใน JumpStart
การแพร่กระจายที่เสถียรและการถ่ายโอนการเรียนรู้
Stable Diffusion เป็นโมเดลแปลงข้อความเป็นรูปภาพที่ช่วยให้คุณสร้างรูปภาพเหมือนจริงได้จากข้อความแจ้ง แบบจำลองการแพร่กระจายฝึกฝนโดยการเรียนรู้ที่จะลบจุดรบกวนที่เพิ่มเข้าไปในภาพจริง กระบวนการลดสัญญาณรบกวนนี้สร้างภาพที่สมจริง แบบจำลองเหล่านี้ยังสามารถสร้างรูปภาพจากข้อความเพียงอย่างเดียวโดยกำหนดเงื่อนไขของกระบวนการสร้างบนข้อความ ตัวอย่างเช่น Stable Diffusion คือการแพร่กระจายแฝงที่โมเดลเรียนรู้ที่จะจดจำรูปร่างในภาพที่มีสัญญาณรบกวนบริสุทธิ์ และค่อยๆ นำรูปร่างเหล่านี้มาโฟกัส หากรูปร่างตรงกับคำในข้อความอินพุต ข้อความจะต้องถูกฝังลงในพื้นที่แฝงโดยใช้แบบจำลองภาษา จากนั้น ชุดของการเพิ่มสัญญาณรบกวนและการดำเนินการกำจัดสัญญาณรบกวนจะดำเนินการในพื้นที่แฝงด้วยสถาปัตยกรรม U-Net สุดท้าย เอาต์พุตที่ไม่มีสัญญาณรบกวนจะถูกถอดรหัสลงในพื้นที่พิกเซล
ในแมชชีนเลิร์นนิง (ML) ความสามารถในการถ่ายโอนความรู้ที่เรียนรู้ในโดเมนหนึ่งไปยังอีกโดเมนหนึ่งเรียกว่า ถ่ายทอดการเรียนรู้. คุณสามารถใช้การเรียนรู้การถ่ายโอนเพื่อสร้างแบบจำลองที่แม่นยำในชุดข้อมูลขนาดเล็กของคุณ โดยมีค่าใช้จ่ายในการฝึกอบรมที่ต่ำกว่าค่าใช้จ่ายในการฝึกอบรมแบบจำลองดั้งเดิมมาก ด้วยการเรียนรู้การถ่ายโอน คุณสามารถปรับแต่งแบบจำลองการแพร่กระจายที่เสถียรในชุดข้อมูลของคุณเองด้วยภาพเพียงห้าภาพ ตัวอย่างเช่น ทางด้านซ้ายเป็นภาพการฝึกของสุนัขชื่อ Doppler ที่ใช้ในการปรับแต่งโมเดล ตรงกลางและขวาเป็นภาพที่สร้างโดยโมเดลที่ปรับแต่งอย่างละเอียดเมื่อถูกขอให้ทำนายภาพของ Doppler บนชายหาดและภาพร่างดินสอ

ทางด้านซ้ายคือภาพของเก้าอี้สีขาวที่ใช้ในการปรับแต่งโมเดลและภาพของเก้าอี้สีแดงที่สร้างโดยโมเดลที่ปรับแต่งอย่างละเอียด ด้านขวาเป็นภาพออตโตมันที่ใช้ในการปรับแต่งโมเดลและภาพแมวนั่งบนออตโตมัน

การปรับแต่งโมเดลขนาดใหญ่อย่าง Stable Diffusion มักจะต้องการให้คุณจัดทำสคริปต์การฝึกอบรม มีปัญหามากมาย รวมถึงปัญหาหน่วยความจำไม่เพียงพอ ปัญหาขนาดเพย์โหลด และอื่นๆ นอกจากนี้ คุณต้องเรียกใช้การทดสอบแบบ end-to-end เพื่อให้แน่ใจว่าสคริปต์ โมเดล และอินสแตนซ์ที่ต้องการทำงานร่วมกันได้อย่างมีประสิทธิภาพ JumpStart ทำให้กระบวนการนี้ง่ายขึ้นด้วยการจัดเตรียมสคริปต์ที่พร้อมใช้งานซึ่งได้รับการทดสอบอย่างเข้มงวด สคริปต์การปรับแต่ง JumpStart สำหรับโมเดล Stable Diffusion สร้างขึ้นจากสคริปต์การปรับแต่งอย่างละเอียดจาก ดรีมบูธ. คุณสามารถเข้าถึงสคริปต์เหล่านี้ได้ด้วยการคลิกเพียงครั้งเดียวผ่าน UI ของ Studio หรือใช้โค้ดเพียงไม่กี่บรรทัดผ่านทาง JumpStart API.
โปรดทราบว่าการใช้แบบจำลองการแพร่กระจายที่เสถียรแสดงว่าคุณยอมรับ ใบอนุญาต CreativeML Open RAIL++-M.
ใช้ JumpStart โดยทางโปรแกรมกับ SageMaker SDK
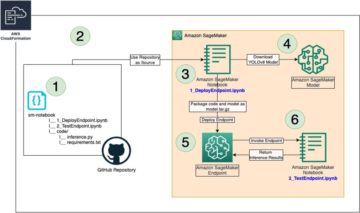
ส่วนนี้อธิบายวิธีฝึกและปรับใช้โมเดลด้วย SageMaker Python SDK. เราเลือกโมเดลที่ผ่านการฝึกอบรมล่วงหน้าที่เหมาะสมใน JumpStart ฝึกโมเดลนี้ด้วยงานฝึกอบรม SageMaker และปรับใช้โมเดลที่ผ่านการฝึกอบรมไปยังตำแหน่งข้อมูล SageMaker นอกจากนี้ เราเรียกใช้การอนุมานบนจุดสิ้นสุดที่ปรับใช้ ทั้งหมดนี้ใช้ SageMaker Python SDK ตัวอย่างต่อไปนี้มีข้อมูลโค้ด สำหรับโค้ดฉบับสมบูรณ์พร้อมขั้นตอนทั้งหมดในการสาธิตนี้ โปรดดูที่ ข้อมูลเบื้องต้นเกี่ยวกับ JumpStart - ข้อความเป็นรูปภาพ ตัวอย่างโน๊ตบุ๊ค
ฝึกฝนและปรับแต่งโมเดลการแพร่กระจายที่เสถียรอย่างละเอียด
แต่ละรุ่นมีเอกลักษณ์เฉพาะตัว model_id. รหัสต่อไปนี้แสดงวิธีการปรับแต่งโมเดลพื้นฐาน Stable Diffusion 2.1 ที่ระบุโดย model_id model-txt2img-stabilityai-stable-diffusion-v2-1-base ในชุดข้อมูลการฝึกอบรมที่กำหนดเอง สำหรับรายการทั้งหมดของ model_id ค่าและรุ่นที่สามารถปรับแต่งได้ โปรดดูที่ อัลกอริธึมในตัวพร้อมตารางโมเดลที่ผ่านการฝึกอบรมมาแล้ว. แต่ละ model_idเพื่อเปิดงานฝึกอบรม SageMaker ผ่าน ประมาณการ คลาสของ SageMaker Python SDK คุณต้องดึง URI อิมเมจ Docker, URI ของสคริปต์การฝึก และ URI ของโมเดลที่ผ่านการฝึกอบรมล่วงหน้าผ่านฟังก์ชันยูทิลิตี้ที่มีให้ใน SageMaker URI ของสคริปต์การฝึกอบรมประกอบด้วยโค้ดที่จำเป็นทั้งหมดสำหรับการประมวลผลข้อมูล การโหลดโมเดลที่ฝึกไว้ล่วงหน้า การฝึกโมเดล และการบันทึกโมเดลที่ฝึกแล้วสำหรับการอนุมาน URI ของโมเดลที่ฝึกไว้ล่วงหน้าประกอบด้วยข้อกำหนดของสถาปัตยกรรมโมเดลที่ฝึกไว้ล่วงหน้าและพารามิเตอร์ของโมเดล URI ของโมเดลที่ฝึกไว้ล่วงหน้ามีความเฉพาะเจาะจงสำหรับโมเดลนั้นๆ โมเดลทาร์บอลที่ฝึกไว้ล่วงหน้าได้รับการดาวน์โหลดล่วงหน้าจาก Hugging Face และบันทึกด้วยลายเซ็นโมเดลที่เหมาะสมใน บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon บัคเก็ต (Amazon S3) เพื่อให้งานการฝึกอบรมทำงานในการแยกเครือข่าย ดูรหัสต่อไปนี้:
ด้วยสิ่งประดิษฐ์การฝึกอบรมเฉพาะรุ่นเหล่านี้ คุณสามารถสร้างวัตถุของ ประมาณการ ระดับ:
ชุดข้อมูลการฝึกอบรม
ต่อไปนี้เป็นคำแนะนำสำหรับการจัดรูปแบบข้อมูลการฝึกอบรม:
- อินพุต – ไดเร็กทอรีที่มีอิมเมจอินสแตนซ์
dataset_info.jsonด้วยการกำหนดค่าต่อไปนี้:- รูปภาพอาจเป็นรูปแบบ .png, .jpg หรือ .jpeg
- พื้นที่
dataset_info.jsonไฟล์ต้องเป็นรูปแบบ{'instance_prompt':<<instance_prompt>>}
- เอาท์พุต – โมเดลที่ผ่านการฝึกอบรมแล้วซึ่งสามารถนำไปใช้เพื่อการอนุมานได้
เส้นทาง S3 ควรมีลักษณะดังนี้ s3://bucket_name/input_directory/. หมายเหตุต่อท้าย / จำเป็นต้องมี
ต่อไปนี้คือตัวอย่างรูปแบบข้อมูลการฝึกอบรม:
สำหรับคำแนะนำเกี่ยวกับวิธีการจัดรูปแบบข้อมูลในขณะที่ใช้การเก็บรักษาไว้ก่อน โปรดดูที่ส่วน การเก็บรักษาก่อน ในโพสต์นี้
เรามีชุดข้อมูลเริ่มต้นของภาพแมว ประกอบด้วยแปดภาพ (ภาพตัวอย่างที่สอดคล้องกับอินสแตนซ์พรอมต์) ของแมวตัวเดียวที่ไม่มีภาพระดับ สามารถดาวน์โหลดได้จาก GitHub. หากใช้ชุดข้อมูลเริ่มต้น ให้ลองใช้ข้อความแจ้ง "รูปแมว riobugger" ขณะทำการอนุมานในสมุดบันทึกสาธิต
ใบอนุญาต: เอ็มไอที.
ไฮเปอร์พารามิเตอร์
ถัดไป สำหรับการถ่ายโอนการเรียนรู้ในชุดข้อมูลที่คุณกำหนดเอง คุณอาจต้องเปลี่ยนค่าเริ่มต้นของไฮเปอร์พารามิเตอร์การฝึก คุณสามารถเรียกค้นพจนานุกรม Python ของไฮเปอร์พารามิเตอร์เหล่านี้ได้ด้วยค่าดีฟอลต์โดยการโทร hyperparameters.retrieve_defaultให้อัปเดตตามต้องการ แล้วส่งต่อไปยังคลาส Estimator ดูรหัสต่อไปนี้:
ไฮเปอร์พารามิเตอร์ต่อไปนี้ได้รับการสนับสนุนโดยอัลกอริทึมการปรับละเอียด:
- with_prior_preservation – ตั้งค่าสถานะเพื่อเพิ่มการสูญเสียการเก็บรักษาก่อนหน้า การเก็บรักษาไว้ก่อนเป็นการทำให้เป็นมาตรฐานเพื่อหลีกเลี่ยงการใส่มากเกินไป (ตัวเลือก:
[“True”,“False”], ค่าเริ่มต้น:“False”.) - num_class_images – ภาพระดับต่ำสุดสำหรับการสูญเสียการเก็บรักษาครั้งก่อน ถ้า
with_prior_preservation = Trueและมีรูปภาพที่มีอยู่ไม่เพียงพอclass_data_dirรูปภาพเพิ่มเติมจะถูกสุ่มตัวอย่างด้วยclass_prompt. (ค่า: จำนวนเต็มบวก ค่าเริ่มต้น: 100) - ยุค – จำนวนรอบที่อัลกอริทึมการปรับแต่งอย่างละเอียดใช้ผ่านชุดข้อมูลการฝึก (ค่า: จำนวนเต็มบวก ค่าเริ่มต้น: 20)
- Max_steps – จำนวนขั้นตอนการฝึกอบรมทั้งหมดที่ต้องดำเนินการ ถ้าไม่
Noneแทนที่ยุค (ค่า:“None”หรือสตริงจำนวนเต็ม ค่าเริ่มต้น:“None”.) - ขนาดแบทช์ –: จำนวนตัวอย่างการฝึกที่ดำเนินการก่อนที่จะอัปเดตตุ้มน้ำหนักแบบจำลอง เหมือนกับขนาดแบทช์ระหว่างการสร้างคลาสอิมเมจ if
with_prior_preservation = True. (ค่า: จำนวนเต็มบวก ค่าเริ่มต้น: 1) - อัตราการเรียนรู้ – อัตราที่น้ำหนักแบบจำลองได้รับการปรับปรุงหลังจากทำงานผ่านตัวอย่างการฝึกอบรมแต่ละชุด (ค่า: ทศนิยมที่เป็นบวก ค่าเริ่มต้น: 2e-06)
- before_loss_weight – น้ำหนักของการสูญเสียการเก็บรักษาครั้งก่อน (ค่า: ทศนิยมที่เป็นบวก ค่าเริ่มต้น: 1.0)
- center_crop – เลือกว่าจะครอบตัดภาพก่อนที่จะปรับขนาดเป็นความละเอียดที่ต้องการหรือไม่ (ตัวเลือก:
[“True”/“False”], ค่าเริ่มต้น:“False”.) - lr_scheduler – ประเภทของตัวกำหนดอัตราการเรียนรู้ (ตัวเลือก:
["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"], ค่าเริ่มต้น:"constant".) ดูข้อมูลเพิ่มเติมได้ที่ เครื่องมือกำหนดอัตราการเรียนรู้. - อดัม_น้ำหนัก_สลาย – น้ำหนักที่ลดลงจะใช้ (ถ้าไม่ใช่ศูนย์) กับทุกเลเยอร์ยกเว้นอคติทั้งหมดและ
LayerNormน้ำหนักในAdamWเครื่องมือเพิ่มประสิทธิภาพ (ค่า: ลอย ค่าเริ่มต้น: 1e-2) - adam_beta1 – ไฮเปอร์พารามิเตอร์เบต้า 1 (อัตราการสลายตัวแบบเอกซ์โปเนนเชียลสำหรับช่วงเวลาแรกโดยประมาณ) สำหรับ
AdamWเครื่องมือเพิ่มประสิทธิภาพ (ค่า: ลอย ค่าเริ่มต้น: 0.9) - adam_beta2 – ไฮเปอร์พารามิเตอร์เบต้า 2 (อัตราการสลายตัวแบบเอกซ์โปเนนเชียลสำหรับช่วงเวลาแรกโดยประมาณ) สำหรับ
AdamWเครื่องมือเพิ่มประสิทธิภาพ (ค่า: ลอย ค่าเริ่มต้น: 0.999) - อดัม_เอปไซลอน -
epsilonไฮเปอร์พารามิเตอร์สำหรับAdamWเครื่องมือเพิ่มประสิทธิภาพ โดยปกติจะตั้งค่าเป็นค่าเล็กน้อยเพื่อหลีกเลี่ยงการหารด้วย 0 (ค่า: float, ค่าเริ่มต้น: 1e-8) - การไล่ระดับสี_การสะสม_ขั้นตอน – จำนวนขั้นตอนการอัปเดตที่จะสะสมก่อนดำเนินการย้อนหลัง/อัปเดตผ่าน (ค่า: จำนวนเต็ม ค่าเริ่มต้น: 1)
- max_grad_norm – บรรทัดฐานการไล่ระดับสีสูงสุด (สำหรับการไล่ระดับสี) (ค่า: ลอย, ค่าเริ่มต้น: 1.0.)
- เมล็ดพันธุ์ – แก้ไขสถานะสุ่มเพื่อให้ได้ผลลัพธ์ที่ทำซ้ำได้ในการฝึกอบรม (ค่า: จำนวนเต็ม ค่าเริ่มต้น: 0)
นำโมเดลที่ได้รับการฝึกฝนมาปรับใช้
หลังจากการฝึกโมเดลเสร็จสิ้น คุณสามารถปรับใช้โมเดลโดยตรงกับตำแหน่งข้อมูลแบบถาวรตามเวลาจริงได้ เราดึง URI อิมเมจ Docker และ URI ของสคริปต์ที่จำเป็นและปรับใช้โมเดล ดูรหัสต่อไปนี้:
ทางด้านซ้ายเป็นภาพการฝึกของแมวชื่อ riobugger ที่ใช้ในการปรับแต่งโมเดลอย่างละเอียด (พารามิเตอร์เริ่มต้นยกเว้น max_steps = 400). ตรงกลางและด้านขวาเป็นภาพที่สร้างโดยโมเดลที่ปรับแต่งอย่างละเอียดเมื่อถูกขอให้ทำนายภาพของ riobugger บนชายหาดและภาพร่างดินสอ

สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับการอนุมาน รวมถึงพารามิเตอร์ที่รองรับ รูปแบบการตอบสนอง และอื่นๆ โปรดดูที่ สร้างรูปภาพจากข้อความด้วยโมเดลการแพร่กระจายที่เสถียรบน Amazon SageMaker JumpStart.
เข้าถึง JumpStart ผ่าน Studio UI
ในส่วนนี้ เราจะสาธิตวิธีฝึกและปรับใช้โมเดล JumpStart ผ่าน Studio UI วิดีโอต่อไปนี้แสดงวิธีค้นหาโมเดล Stable Diffusion ที่ฝึกไว้ล่วงหน้าบน JumpStart ฝึกและปรับใช้ หน้าโมเดลมีข้อมูลที่มีค่าเกี่ยวกับโมเดลและวิธีใช้งาน หลังจากกำหนดค่าอินสแตนซ์การฝึกอบรม SageMaker ให้เลือก รถไฟ. หลังจากโมเดลได้รับการฝึกอบรมแล้ว คุณสามารถปรับใช้โมเดลที่ผ่านการฝึกอบรมได้โดยเลือก ปรับใช้. หลังจากที่จุดสิ้นสุดอยู่ในขั้นตอน "ในการให้บริการ" ก็พร้อมที่จะตอบสนองต่อคำขอการอนุมาน
เพื่อเร่งเวลาในการอนุมาน JumpStart จัดทำสมุดบันทึกตัวอย่างที่แสดงวิธีการเรียกใช้การอนุมานบนจุดสิ้นสุดที่สร้างขึ้นใหม่ หากต้องการเข้าถึงสมุดบันทึกใน Studio ให้เลือก เปิดสมุดบันทึก ใน ใช้ปลายทางจากสตูดิโอ ส่วนของหน้าจุดสิ้นสุดของโมเดล
JumpStart ยังมีสมุดบันทึกที่เรียบง่ายซึ่งคุณสามารถใช้เพื่อปรับแต่งโมเดลการแพร่กระจายที่เสถียรอย่างละเอียดและนำโมเดลที่ปรับแต่งแล้วไปปรับใช้ คุณสามารถใช้เพื่อสร้างภาพความสนุกสนานของสุนัขของคุณ หากต้องการเข้าถึงสมุดบันทึก ให้ค้นหา "สร้างภาพหมาแสนสนุกของคุณ" ในแถบค้นหาของ JumpStart ในการรันโน้ตบุ๊ก คุณสามารถใช้ภาพการฝึกเพียงห้าภาพและอัปโหลดไปยังโฟลเดอร์สตูดิโอในเครื่อง หากคุณมีภาพมากกว่าห้าภาพ คุณสามารถอัปโหลดได้เช่นกัน Notebook อัปโหลดอิมเมจการฝึกไปยัง S3 ฝึกโมเดลในชุดข้อมูลของคุณ และปรับใช้โมเดลผลลัพธ์ การฝึกอบรมอาจใช้เวลา 20 นาทีจึงจะเสร็จสิ้น คุณสามารถเปลี่ยนจำนวนก้าวเพื่อเร่งการฝึกได้ Notebook มีพร้อมต์ตัวอย่างให้ลองกับโมเดลที่ปรับใช้ แต่คุณสามารถลองพร้อมท์ใดก็ได้ที่คุณต้องการ คุณยังสามารถดัดแปลงสมุดบันทึกเพื่อสร้างภาพแทนตัวของคุณเองหรือสัตว์เลี้ยงของคุณ ตัวอย่างเช่น คุณสามารถอัปโหลดภาพแมวของคุณในขั้นตอนแรก แทนที่จะใช้สุนัขของคุณ จากนั้นเปลี่ยนข้อความแจ้งจากสุนัขเป็นแมว แล้วโมเดลจะสร้างภาพแมวของคุณ
การพิจารณาปรับจูน
แบบจำลองการแพร่กระจายที่เสถียรมีแนวโน้มที่จะมากเกินไปอย่างรวดเร็ว เพื่อให้ได้ภาพที่มีคุณภาพดี เราต้องหาสมดุลที่ดีระหว่างไฮเปอร์พารามิเตอร์การฝึกที่มีอยู่ เช่น จำนวนขั้นตอนการฝึกและอัตราการเรียนรู้ ในส่วนนี้ เราจะแสดงผลการทดลองบางส่วนและให้คำแนะนำเกี่ยวกับวิธีตั้งค่าพารามิเตอร์เหล่านี้
แนะนำ
พิจารณาคำแนะนำต่อไปนี้:
- เริ่มต้นด้วยภาพการฝึกที่มีคุณภาพดี (4–20) หากฝึกใบหน้ามนุษย์ คุณอาจต้องการภาพมากกว่านี้
- ฝึก 200–400 ก้าวเมื่อฝึกสุนัขหรือแมวและวิชาอื่นๆ ที่ไม่ใช่มนุษย์ หากฝึกใบหน้ามนุษย์ คุณอาจต้องมีขั้นตอนมากกว่านี้ หากเกินพอดี ให้ลดจำนวนขั้นลง ถ้าเกิดความไม่พอดี (ตัวแบบที่ปรับละเอียดไม่สามารถสร้างภาพของวัตถุเป้าหมายได้) ให้เพิ่มจำนวนขั้นตอน
- หากฝึกใบหน้าที่ไม่ใช่มนุษย์ คุณอาจตั้งค่า
with_prior_preservation = Falseเพราะไม่ส่งผลกระทบต่อประสิทธิภาพการทำงานมากนัก บนใบหน้าของมนุษย์ คุณอาจต้องตั้งค่าwith_prior_preservation=True. - ถ้าตั้งค่า
with_prior_preservation=Trueให้ใช้ประเภทอินสแตนซ์ ml.g5.2xlarge - เมื่อฝึกหลายวิชาตามลำดับ หากวิชาคล้ายกันมาก (เช่น สุนัขทุกตัว) โมเดลจะเก็บวิชาสุดท้ายไว้และลืมวิชาก่อนหน้า หากตัวแบบแตกต่างกัน (เช่น อันดับแรกเป็นแมวแล้วเป็นสุนัข) ตัวแบบจะเก็บทั้งสองแบบไว้
- ขอแนะนำให้ใช้อัตราการเรียนรู้ที่ต่ำและเพิ่มจำนวนขั้นตอนไปเรื่อย ๆ จนกว่าจะได้ผลลัพธ์ที่น่าพอใจ
ชุดข้อมูลการฝึกอบรม
คุณภาพของโมเดลที่ได้รับการปรับแต่งจะได้รับผลกระทบโดยตรงจากคุณภาพของรูปภาพการฝึก ดังนั้นคุณต้องรวบรวมรูปภาพคุณภาพสูงเพื่อให้ได้ผลลัพธ์ที่ดี ภาพเบลอหรือความละเอียดต่ำจะส่งผลต่อคุณภาพของโมเดลที่ปรับแต่งอย่างละเอียด โปรดทราบพารามิเตอร์เพิ่มเติมต่อไปนี้:
- จำนวนภาพการฝึก – คุณสามารถปรับแต่งโมเดลอย่างละเอียดบนภาพการฝึกเพียงสี่ภาพ เราทดลองกับชุดข้อมูลการฝึกอบรมที่มีขนาดเพียง 4 ภาพและมากถึง 16 ภาพ ในทั้งสองกรณี การปรับแต่งแบบละเอียดสามารถปรับโมเดลให้เข้ากับตัวแบบได้
- รูปแบบชุดข้อมูล – เราทดสอบอัลกอริทึมการปรับแต่งรูปภาพในรูปแบบ .png, .jpg และ .jpeg รูปแบบอื่นอาจใช้งานได้เช่นกัน
- ความละเอียดของภาพ – ภาพการฝึกอาจมีความละเอียดเท่าใดก็ได้ อัลกอริธึมการปรับละเอียดจะปรับขนาดรูปภาพการฝึกทั้งหมดก่อนที่จะเริ่มการปรับละเอียด อย่างไรก็ตาม หากคุณต้องการควบคุมการครอบตัดและปรับขนาดรูปภาพฝึกหัดได้มากขึ้น เราขอแนะนำให้ปรับขนาดรูปภาพด้วยตัวคุณเองเป็นความละเอียดพื้นฐานของโมเดล (ในตัวอย่างนี้ 512×512 พิกเซล)
การตั้งค่าการทดสอบ
ในการทดสอบในโพสต์นี้ ในขณะที่การปรับแต่งอย่างละเอียด เราใช้ค่าเริ่มต้นของไฮเปอร์พารามิเตอร์ เว้นแต่จะระบุไว้ นอกจากนี้ เราใช้หนึ่งในสี่ชุดข้อมูล:
- สุนัข1-8 – สุนัข 1 มี 8 ภาพ
- สุนัข1-16 – สุนัข 1 มี 16 ภาพ
- สุนัข2-4 – สุนัข 2 มีสี่ภาพ
- แมว -8 – แมวที่มี 8 ภาพ
เพื่อลดความยุ่งเหยิง เราจะแสดงเพียงรูปภาพตัวแทนของชุดข้อมูลในแต่ละส่วนพร้อมกับชื่อชุดข้อมูล คุณสามารถค้นหาชุดการฝึกอบรมทั้งหมดได้ในส่วน ชุดข้อมูลการทดสอบ ในโพสต์นี้
ฟิตติ้งมากเกินไป
โมเดลการแพร่กระจายที่เสถียรมักจะเกินพอดีเมื่อปรับแต่งภาพบางภาพอย่างละเอียด ดังนั้นคุณต้องเลือกพารามิเตอร์เช่น epochs, max_epochsและอัตราการเรียนรู้อย่างรอบคอบ ในส่วนนี้ เราใช้ชุดข้อมูล Dog1-16

ในการประเมินประสิทธิภาพของโมเดล เราจะประเมินโมเดลที่ปรับแต่งอย่างละเอียดสำหรับสี่งาน:
- โมเดลที่ปรับแต่งอย่างละเอียดสามารถสร้างภาพของตัวแบบ (Doppler dog) ในการตั้งค่าเดียวกับที่ได้รับการฝึกฝนได้หรือไม่?
- การสังเกต – ใช่ มันสามารถ เป็นที่น่าสังเกตว่าประสิทธิภาพของโมเดลเพิ่มขึ้นตามจำนวนขั้นตอนการฝึกอบรม
- โมเดลที่ปรับแต่งอย่างละเอียดสามารถสร้างภาพของวัตถุในการตั้งค่าที่แตกต่างจากที่ได้รับการฝึกฝนได้หรือไม่? ตัวอย่างเช่น มันสามารถสร้างภาพ Doppler บนชายหาดได้หรือไม่?
- การสังเกต – ใช่ มันสามารถ เป็นที่น่าสังเกตว่าประสิทธิภาพของโมเดลจะเพิ่มขึ้นตามจำนวนขั้นตอนการฝึกจนถึงจุดหนึ่ง อย่างไรก็ตาม หากโมเดลได้รับการฝึกอบรมนานเกินไป ประสิทธิภาพของโมเดลจะลดลงเนื่องจากโมเดลมีแนวโน้มที่จะเกินพอดี
- แบบจำลองที่ปรับละเอียดสามารถสร้างภาพของชั้นเรียนที่เข้าร่วมการฝึกอบรมได้หรือไม่? ตัวอย่างเช่น สามารถสร้างภาพลักษณ์ของสุนัขทั่วไปได้หรือไม่
- การสังเกต – เมื่อเราเพิ่มจำนวนขั้นตอนการฝึก หุ่นจำลองก็เริ่มเกินพอดี เป็นผลให้ลืมคลาสทั่วไปของสุนัขและจะสร้างภาพที่เกี่ยวข้องกับตัวแบบเท่านั้น
- โมเดลที่ปรับแต่งแล้วสามารถสร้างรูปภาพของชั้นเรียนหรือวิชาที่ไม่อยู่ในชุดข้อมูลการฝึกอบรมได้หรือไม่ ตัวอย่างเช่น สามารถสร้างภาพแมวได้หรือไม่
- การสังเกต – เมื่อเราเพิ่มจำนวนขั้นตอนการฝึก หุ่นจำลองก็เริ่มเกินพอดี ผลที่ได้คือจะสร้างเฉพาะภาพที่เกี่ยวข้องกับเรื่องโดยไม่คำนึงถึงชั้นเรียนที่ระบุ
เราปรับแต่งโมเดลอย่างละเอียดตามจำนวนขั้นตอนต่างๆ (โดยการตั้งค่า max_steps hyperparameters) และสำหรับแต่ละโมเดลที่ปรับแต่งอย่างละเอียด เราสร้างอิมเมจในแต่ละพรอมต์ทั้งสี่ต่อไปนี้ (แสดงในตัวอย่างต่อไปนี้จากซ้ายไปขวา:
- “รูปถ่ายของสุนัข Doppler”
- “ภาพถ่ายสุนัข Doppler บนชายหาด”
- “รูปถ่ายของสุนัข”
- “รูปถ่ายของแมว”
รูปภาพต่อไปนี้มาจากโมเดลที่ได้รับการฝึกฝนด้วย 50 ขั้นตอน

โมเดลต่อไปนี้ได้รับการฝึกฝนด้วย 100 ขั้นตอน

เราฝึกโมเดลต่อไปนี้ด้วย 200 ขั้นตอน

รูปภาพต่อไปนี้มาจากแบบจำลองที่ฝึกด้วย 400 ขั้นตอน

สุดท้าย ภาพต่อไปนี้เป็นผลจาก 800 ก้าว

ฝึกฝนชุดข้อมูลหลายชุด
ขณะปรับละเอียด คุณอาจต้องการปรับแต่งหลายวัตถุอย่างละเอียด และให้โมเดลที่ปรับแต่งแล้วสามารถสร้างภาพของวัตถุทั้งหมดได้ ขออภัย ขณะนี้ JumpStart จำกัดการฝึกอบรมในหัวข้อเดียว คุณไม่สามารถปรับแต่งโมเดลแบบละเอียดในหลายวัตถุพร้อมกันได้ นอกจากนี้ การปรับโมเดลอย่างละเอียดสำหรับวัตถุต่างๆ ตามลำดับจะส่งผลให้โมเดลลืมวัตถุแรกหากวัตถุคล้ายกัน
เราพิจารณาการทดลองต่อไปนี้ในส่วนนี้:
- ปรับโมเดลอย่างละเอียดสำหรับหัวเรื่อง A
- ปรับแต่งโมเดลผลลัพธ์จากขั้นตอนที่ 1 สำหรับหัวเรื่อง B
- สร้างรูปภาพของหัวเรื่อง A และหัวเรื่อง B โดยใช้โมเดลเอาต์พุตจากขั้นตอนที่ 2
ในการทดลองต่อไปนี้ เราสังเกตว่า:
- ถ้า A เป็นสุนัข 1 และ B เป็นสุนัข 2 รูปภาพทั้งหมดที่สร้างขึ้นในขั้นตอนที่ 3 จะคล้ายกับสุนัข 2
- ถ้า A เป็นสุนัข 2 และ B เป็นสุนัข 1 รูปภาพทั้งหมดที่สร้างขึ้นในขั้นตอนที่ 3 จะคล้ายกับสุนัข 1
- ถ้า A เป็น dog 1 และ B เป็น cat รูปภาพที่สร้างด้วย dog prompt จะคล้ายกับ dog 1 และรูปภาพที่สร้างจาก cat prompt จะคล้ายกับ cat
ฝึกสุนัขตัวที่ 1 แล้วฝึกสุนัขตัวที่ 2
ในขั้นตอนที่ 1 เราปรับแต่งโมเดลอย่างละเอียดถึง 200 ขั้นตอนสำหรับรูปภาพสุนัข 1 แปดภาพ ในขั้นตอนที่ 2 เราปรับแต่งโมเดลเพิ่มเติมอีก 200 ขั้นตอนสำหรับรูปภาพสุนัข 2 สี่ภาพ

ต่อไปนี้คือรูปภาพที่สร้างโดยโมเดลที่ปรับแต่งแล้วในตอนท้ายของขั้นตอนที่ 2 สำหรับข้อความแจ้งต่างๆ

ฝึกสุนัขตัวที่ 2 แล้วฝึกสุนัขตัวที่ 1
ในขั้นตอนที่ 1 เราปรับแต่งโมเดลอย่างละเอียดถึง 200 ขั้นตอนสำหรับรูปภาพสุนัข 2 สี่ภาพ ในขั้นตอนที่ 2 เราปรับแต่งโมเดลเพิ่มเติมอีก 200 ขั้นตอนสำหรับรูปภาพสุนัข 1 แปดภาพ

ต่อไปนี้คือรูปภาพที่สร้างโดยโมเดลที่ปรับละเอียดเมื่อสิ้นสุดขั้นตอนที่ 2 พร้อมข้อความแจ้งต่างๆ

ฝึกสุนัขและแมว
ในขั้นตอนที่ 1 เราปรับแต่งโมเดลอย่างละเอียดถึง 200 ขั้นสำหรับภาพแมวแปดภาพ จากนั้นเราปรับแต่งโมเดลเพิ่มเติมอีก 200 ขั้นในแปดภาพของสุนัข 1

ต่อไปนี้คือรูปภาพที่สร้างโดยโมเดลที่ปรับละเอียดเมื่อสิ้นสุดขั้นตอนที่ 2 รูปภาพที่มีข้อความเกี่ยวกับแมวจะดูเหมือนแมวในขั้นตอนที่ 1 ของการปรับละเอียด และรูปภาพที่มีข้อความเกี่ยวกับสุนัขจะดูเหมือนสุนัขใน ขั้นตอนที่ 2 ของการปรับละเอียด

การเก็บรักษาก่อน
การเก็บรักษาไว้ก่อนเป็นเทคนิคที่ใช้รูปภาพเพิ่มเติมของคลาสเดียวกันที่เรากำลังพยายามฝึกฝน ตัวอย่างเช่น หากข้อมูลการฝึกประกอบด้วยรูปภาพของสุนัขเฉพาะที่มีการเก็บรักษาไว้ล่วงหน้า เราจะรวมรูปภาพของสุนัขทั่วไปในชั้นเรียน มันพยายามหลีกเลี่ยงการโอเวอร์ฟิตโดยแสดงภาพสุนัขที่แตกต่างกันในขณะที่กำลังฝึกสุนัขตัวใดตัวหนึ่ง แท็กที่ระบุสุนัขเฉพาะที่มีอยู่ในพรอมต์ของอินสแตนซ์หายไปในพรอมต์ของคลาส ตัวอย่างเช่น พรอมต์ของอินสแตนซ์อาจเป็น "รูปภาพของแมว riobugger" และพรอมต์ของชั้นเรียนอาจเป็น "รูปภาพของแมว" คุณสามารถเปิดใช้งานการเก็บรักษาล่วงหน้าได้โดยการตั้งค่าไฮเปอร์พารามิเตอร์ with_prior_preservation = True. ถ้าตั้งค่า with_prior_preservation = Trueคุณต้องรวม class_prompt in dataset_info.json และอาจรวมถึงภาพชั้นเรียนที่มีให้คุณ ต่อไปนี้คือรูปแบบชุดข้อมูลการฝึกอบรมเมื่อตั้งค่า with_prior_preservation = True:
- อินพุต – ไดเร็กทอรีที่มีอิมเมจอินสแตนซ์
dataset_info.jsonและไดเร็กทอรี (ไม่บังคับ)class_data_dir. หมายเหตุต่อไปนี้:- รูปภาพอาจเป็นรูปแบบ .png, .jpg, .jpeg
- พื้นที่
dataset_info.jsonไฟล์ต้องเป็นรูปแบบ{'instance_prompt':<<instance_prompt>>,'class_prompt':<<class_prompt>>}. - พื้นที่
class_data_dirไดเร็กทอรีต้องมีอิมเมจคลาส ถ้าclass_data_dirไม่มีอยู่หรือมีรูปภาพที่มีอยู่ไม่เพียงพอclass_data_dirรูปภาพเพิ่มเติมจะถูกสุ่มตัวอย่างด้วยclass_prompt.
สำหรับชุดข้อมูล เช่น แมวและสุนัข การเก็บรักษาไว้ก่อนจะไม่ส่งผลกระทบต่อประสิทธิภาพของโมเดลที่ปรับแต่งอย่างละเอียด ดังนั้นจึงสามารถหลีกเลี่ยงได้ อย่างไรก็ตาม เมื่อฝึกฝนบนใบหน้า สิ่งนี้เป็นสิ่งที่จำเป็น สำหรับข้อมูลเพิ่มเติม โปรดดูที่ การฝึกการแพร่กระจายที่เสถียรด้วย Dreambooth โดยใช้เครื่องกระจายสัญญาณ.
ประเภทอินสแตนซ์
การปรับโมเดล Stable Diffusion อย่างละเอียดนั้นต้องการการคำนวณแบบเร่งโดยอินสแตนซ์ที่รองรับ GPU เราทดลองการปรับแต่งของเราด้วยอินสแตนซ์ ml.g4dn.2xlarge (หน่วยความจำ CUDA 16 GB, 1 GPU) และอินสแตนซ์ ml.g5.2xlarge (หน่วยความจำ CUDA 24 GB, 1 GPU) ความต้องการหน่วยความจำจะสูงขึ้นเมื่อสร้างคลาสอิมเมจ ดังนั้นหากตั้งค่า with_prior_preservation=Trueให้ใช้ประเภทอินสแตนซ์ ml.g5.2xlarge เนื่องจากการฝึกทำงานใน CUDA ปัญหาหน่วยความจำไม่เพียงพอในอินสแตนซ์ ml.g4dn.2xlarge สคริปต์การปรับแต่ง JumpStart ในปัจจุบันใช้ GPU เดี่ยว ดังนั้นการปรับแต่งอย่างละเอียดบนอินสแตนซ์หลาย GPU จะไม่ทำให้ประสิทธิภาพเพิ่มขึ้น สำหรับข้อมูลเพิ่มเติมเกี่ยวกับอินสแตนซ์ประเภทต่างๆ โปรดดูที่ ประเภทอินสแตนซ์ Amazon EC2.
ข้อจำกัดและความลำเอียง
แม้ว่า Stable Diffusion จะมีประสิทธิภาพที่น่าประทับใจในการสร้างภาพ แต่ก็มีข้อจำกัดและอคติหลายประการ ซึ่งรวมถึงแต่ไม่จำกัดเพียง:
- โมเดลอาจสร้างใบหน้าหรือแขนขาได้ไม่แม่นยำ เนื่องจากข้อมูลการฝึกมีรูปภาพที่มีคุณสมบัติเหล่านี้ไม่เพียงพอ
- แบบจำลองได้รับการฝึกอบรมเกี่ยวกับ ชุดข้อมูล LAION-5Bซึ่งมีเนื้อหาสำหรับผู้ใหญ่และอาจไม่เหมาะสำหรับการใช้ผลิตภัณฑ์โดยไม่ต้องพิจารณาเพิ่มเติม
- โมเดลอาจทำงานได้ไม่ดีกับภาษาที่ไม่ใช่ภาษาอังกฤษ เนื่องจากโมเดลได้รับการฝึกอบรมเกี่ยวกับข้อความภาษาอังกฤษ
- โมเดลไม่สามารถสร้างข้อความที่ดีภายในรูปภาพได้
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับข้อจำกัดและอคติ โปรดดูที่ การ์ดโมเดลฐานการแพร่กระจาย v2-1 ที่เสถียร. ข้อจำกัดเหล่านี้สำหรับโมเดลที่ได้รับการฝึกอบรมล่วงหน้ายังสามารถส่งผลต่อโมเดลที่ได้รับการปรับแต่งอย่างละเอียดอีกด้วย
ทำความสะอาด
หลังจากที่คุณเรียกใช้สมุดบันทึกเสร็จแล้ว ตรวจสอบให้แน่ใจว่าได้ลบทรัพยากรทั้งหมดที่สร้างขึ้นในกระบวนการเพื่อให้แน่ใจว่าการเรียกเก็บเงินจะหยุดลง รหัสสำหรับล้างข้อมูลปลายทางมีให้ในที่เกี่ยวข้อง ข้อมูลเบื้องต้นเกี่ยวกับ JumpStart - ข้อความเป็นรูปภาพ ตัวอย่างโน๊ตบุ๊ค
โมเดลที่ปรับแต่งอย่างละเอียดที่เผยแพร่สู่สาธารณะใน JumpStart
แม้ว่าโมเดล Stable Diffusion ที่ออกโดย ความเสถียรAI มีประสิทธิภาพที่น่าประทับใจ พวกเขามีข้อจำกัดในแง่ของภาษาหรือโดเมนที่ได้รับการฝึกฝน ตัวอย่างเช่น แบบจำลอง Stable Diffusion ได้รับการฝึกโดยใช้ข้อความภาษาอังกฤษ แต่คุณอาจต้องสร้างรูปภาพจากข้อความที่ไม่ใช่ภาษาอังกฤษ อีกทางเลือกหนึ่ง แบบจำลองการแพร่กระจายที่เสถียรได้รับการฝึกฝนเพื่อสร้างภาพที่เหมือนจริง แต่คุณอาจต้องสร้างภาพเคลื่อนไหวหรือภาพศิลปะ
JumpStart มีโมเดลกว่า 80 โมเดลที่เผยแพร่สู่สาธารณะพร้อมภาษาและธีมต่างๆ โมเดลเหล่านี้มักเป็นเวอร์ชันที่ปรับแต่งอย่างละเอียดจากโมเดล Stable Diffusion ที่ออกโดย StabilityAI หากกรณีการใช้งานของคุณตรงกับโมเดลที่ปรับแต่งแล้วรุ่นใดรุ่นหนึ่ง คุณไม่จำเป็นต้องรวบรวมชุดข้อมูลของคุณเองและปรับแต่ง คุณสามารถปรับใช้หนึ่งในโมเดลเหล่านี้ผ่าน Studio UI หรือใช้ JumpStart API ที่ใช้งานง่าย ในการปรับใช้โมเดล Stable Diffusion ที่ฝึกไว้ล่วงหน้าใน JumpStart โปรดดูที่ สร้างรูปภาพจากข้อความด้วยโมเดลการแพร่กระจายที่เสถียรบน Amazon SageMaker JumpStart.
ต่อไปนี้เป็นตัวอย่างบางส่วนของรูปภาพที่สร้างโดยรุ่นต่างๆ ที่มีอยู่ใน JumpStart


โปรดทราบว่าโมเดลเหล่านี้ไม่ได้รับการปรับแต่งอย่างละเอียดโดยใช้สคริปต์ JumpStart หรือสคริปต์ DreamBooth คุณสามารถดาวน์โหลดรายการรุ่นปรับแต่งทั้งหมดที่มีจำหน่ายทั่วไปพร้อมตัวอย่างการแจ้งเตือนได้จาก โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม.
สำหรับตัวอย่างเพิ่มเติมที่สร้างรูปภาพจากโมเดลเหล่านี้ โปรดดูหัวข้อ โมเดลที่ได้รับการปรับแต่งแบบโอเพ่นซอร์ส ในภาคผนวก
สรุป
ในโพสต์นี้ เราได้แสดงวิธีปรับแต่งโมเดล Stable Diffusion สำหรับข้อความเป็นรูปภาพ จากนั้นปรับใช้โดยใช้ JumpStart นอกจากนี้ เรายังกล่าวถึงข้อควรพิจารณาบางประการที่คุณควรทำขณะปรับแต่งโมเดลโดยละเอียด และผลกระทบต่อประสิทธิภาพของโมเดลที่ปรับแต่งอย่างละเอียดอย่างไร เรายังกล่าวถึงโมเดลที่ปรับแต่งแบบละเอียดพร้อมใช้งานกว่า 80 รายการที่มีอยู่ใน JumpStart เราได้แสดงข้อมูลโค้ดในโพสต์นี้—สำหรับโค้ดฉบับสมบูรณ์พร้อมขั้นตอนทั้งหมดในการสาธิตนี้ โปรดดูที่ ข้อมูลเบื้องต้นเกี่ยวกับ JumpStart - ข้อความเป็นรูปภาพ ตัวอย่างโน๊ตบุ๊ค. ลองใช้วิธีแก้ปัญหาด้วยตัวคุณเองและส่งความคิดเห็นของคุณถึงเรา
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับรุ่นและการปรับแต่ง DreamBooth โปรดดูแหล่งข้อมูลต่อไปนี้:
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ JumpStart โปรดดูบล็อกโพสต์ต่อไปนี้:
เกี่ยวกับผู้เขียน
 ดร.วิเวก มะดัน เป็นนักวิทยาศาสตร์ประยุกต์กับทีม Amazon SageMaker JumpStart เขาสำเร็จการศึกษาระดับปริญญาเอกจากมหาวิทยาลัยอิลลินอยส์ Urbana-Champaign และเป็นนักวิจัยหลังปริญญาเอกที่ Georgia Tech เขาเป็นนักวิจัยเชิงรุกด้านการเรียนรู้ของเครื่องและการออกแบบอัลกอริธึม และได้ตีพิมพ์เอกสารในการประชุม EMNLP, ICLR, COLT, FOCS และ SODA
ดร.วิเวก มะดัน เป็นนักวิทยาศาสตร์ประยุกต์กับทีม Amazon SageMaker JumpStart เขาสำเร็จการศึกษาระดับปริญญาเอกจากมหาวิทยาลัยอิลลินอยส์ Urbana-Champaign และเป็นนักวิจัยหลังปริญญาเอกที่ Georgia Tech เขาเป็นนักวิจัยเชิงรุกด้านการเรียนรู้ของเครื่องและการออกแบบอัลกอริธึม และได้ตีพิมพ์เอกสารในการประชุม EMNLP, ICLR, COLT, FOCS และ SODA
 ไฮโกะ ฮ็อตซ์ เป็นสถาปนิกโซลูชันอาวุโสสำหรับ AI และการเรียนรู้ของเครื่องโดยเน้นเป็นพิเศษเกี่ยวกับการประมวลผลภาษาธรรมชาติ (NLP) โมเดลภาษาขนาดใหญ่ (LLM) และ AI เชิงกำเนิด ก่อนหน้านี้เขาเคยเป็นหัวหน้าฝ่ายวิทยาศาสตร์ข้อมูลสำหรับฝ่ายบริการลูกค้าในสหภาพยุโรปของ Amazon Heiko ช่วยให้ลูกค้าของเราประสบความสำเร็จในการเดินทางด้วย AI/ML บน AWS และได้ทำงานร่วมกับองค์กรในหลายอุตสาหกรรม ซึ่งรวมถึงการประกันภัย บริการทางการเงิน สื่อและความบันเทิง การดูแลสุขภาพ สาธารณูปโภค และการผลิต ในเวลาว่าง Heiko จะเดินทางให้มากที่สุด
ไฮโกะ ฮ็อตซ์ เป็นสถาปนิกโซลูชันอาวุโสสำหรับ AI และการเรียนรู้ของเครื่องโดยเน้นเป็นพิเศษเกี่ยวกับการประมวลผลภาษาธรรมชาติ (NLP) โมเดลภาษาขนาดใหญ่ (LLM) และ AI เชิงกำเนิด ก่อนหน้านี้เขาเคยเป็นหัวหน้าฝ่ายวิทยาศาสตร์ข้อมูลสำหรับฝ่ายบริการลูกค้าในสหภาพยุโรปของ Amazon Heiko ช่วยให้ลูกค้าของเราประสบความสำเร็จในการเดินทางด้วย AI/ML บน AWS และได้ทำงานร่วมกับองค์กรในหลายอุตสาหกรรม ซึ่งรวมถึงการประกันภัย บริการทางการเงิน สื่อและความบันเทิง การดูแลสุขภาพ สาธารณูปโภค และการผลิต ในเวลาว่าง Heiko จะเดินทางให้มากที่สุด
ภาคผนวก: ชุดข้อมูลการทดสอบ
ส่วนนี้มีชุดข้อมูลที่ใช้ในการทดลองในโพสต์นี้
สุนัข1-8

สุนัข1-16

สุนัข2-4

สุนัข3-8

ภาคผนวก: โมเดลที่ได้รับการปรับแต่งแบบโอเพ่นซอร์ส
ต่อไปนี้เป็นตัวอย่างบางส่วนของรูปภาพที่สร้างโดยรุ่นต่างๆ ที่มีอยู่ใน JumpStart แต่ละภาพมีคำบรรยายด้วย model_id เริ่มต้นด้วยคำนำหน้า huggingface-txt2img- ตามด้วยพรอมต์ที่ใช้สร้างภาพในบรรทัดถัดไป

























- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/fine-tune-text-to-image-stable-diffusion-models-with-amazon-sagemaker-jumpstart/
- 1
- 100
- 11
- 2022
- 9
- a
- ความสามารถ
- สามารถ
- เกี่ยวกับเรา
- เร่งความเร็ว
- เร่ง
- เข้า
- ซื้อสะสม
- ถูกต้อง
- บรรลุ
- คล่องแคล่ว
- ปรับ
- ที่เพิ่ม
- นอกจากนี้
- เพิ่มเติม
- ผู้ใหญ่
- หลังจาก
- AI
- AI และการเรียนรู้ของเครื่อง
- AI / ML
- ขั้นตอนวิธี
- อัลกอริทึม
- ทั้งหมด
- ช่วยให้
- คนเดียว
- แล้ว
- แม้ว่า
- อเมซอน
- อเมซอน SageMaker
- Amazon SageMaker JumpStart
- และ
- ประกาศ
- อื่น
- APIs
- ประยุกต์
- ใช้
- เหมาะสม
- สถาปัตยกรรม
- ศิลปะ
- ศิลปะ
- ที่เกี่ยวข้อง
- อัตโนมัติ
- ใช้ได้
- อวตาร
- หลีกเลี่ยง
- หลีกเลี่ยง
- AWS
- ยอดคงเหลือ
- บาร์
- ฐาน
- ชายหาด
- เพราะ
- ก่อน
- กำลัง
- ระหว่าง
- เกิน
- อคติ
- การเรียกเก็บเงิน
- บล็อก
- บล็อกโพสต์
- นำ
- สร้าง
- ที่เรียกว่า
- โทร
- รอบคอบ
- พกพา
- กรณี
- กรณี
- แมว
- แมว
- บาง
- เก้าอี้
- เปลี่ยนแปลง
- ตรวจสอบ
- ทางเลือก
- ทางเลือก
- Choose
- เลือก
- ชั้น
- รกรุงรัง
- รหัส
- รวบรวม
- ความคิดเห็น
- การคำนวณ
- การประชุม
- องค์ประกอบ
- พิจารณา
- การพิจารณา
- คงที่
- สร้าง
- ภาชนะ
- มี
- เนื้อหา
- ควบคุม
- ตรงกัน
- ค่าใช้จ่าย
- สร้าง
- ที่สร้างขึ้น
- การสร้าง
- พืชผล
- ขณะนี้
- ประเพณี
- ลูกค้า
- บริการลูกค้า
- ลูกค้า
- ข้อมูล
- การประมวลผล
- วิทยาศาสตร์ข้อมูล
- ชุดข้อมูล
- ลึก
- การเรียนรู้ลึก ๆ
- ค่าเริ่มต้น
- ทดลอง
- สาธิต
- ปรับใช้
- นำไปใช้
- ออกแบบ
- การออกแบบ
- รายละเอียด
- ต่าง
- การจัดจำหน่าย
- โดยตรง
- สนทนา
- กล่าวถึง
- การแบ่ง
- นักเทียบท่า
- ตู้คอนเทนเนอร์ Dock
- ไม่
- สุนัข
- สุนัข
- การทำ
- โดเมน
- Dont
- ดาวน์โหลด
- ในระหว่าง
- แต่ละ
- ง่ายต่อการใช้งาน
- ที่มีประสิทธิภาพ
- ที่ฝัง
- ทำให้สามารถ
- ช่วยให้
- จบสิ้น
- ปลายทาง
- ภาษาอังกฤษ
- พอ
- ทำให้มั่นใจ
- ความบันเทิง
- การเข้า
- ยุค
- ประมาณการ
- ฯลฯ
- อีเธอร์ (ETH)
- EU
- ประเมินค่า
- ตัวอย่าง
- ตัวอย่าง
- ยกเว้น
- ดำเนินการ
- คาดหวัง
- การทดลอง
- ที่ชี้แจง
- ใบหน้า
- ใบหน้า
- สองสาม
- เนื้อไม่มีมัน
- ไฟล์
- ในที่สุด
- ทางการเงิน
- บริการทางการเงิน
- หา
- เสร็จสิ้น
- ชื่อจริง
- พอดี
- แก้ไขปัญหา
- ลอย
- โฟกัส
- ตาม
- ดังต่อไปนี้
- รูป
- ราคาเริ่มต้นที่
- เต็ม
- สนุก
- ฟังก์ชั่น
- ต่อไป
- นอกจากนี้
- ได้รับ
- สร้าง
- สร้าง
- สร้าง
- การสร้าง
- รุ่น
- กำเนิด
- กำเนิด AI
- จอร์เจีย
- ได้รับ
- GitHub
- ดี
- GPU
- ค่อยๆ
- การจัดการ
- ที่เกิดขึ้น
- หัว
- การดูแลสุขภาพ
- จะช่วยให้
- ที่มีคุณภาพสูง
- สูงกว่า
- เจ้าภาพ
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- HTTPS
- เป็นมนุษย์
- ไอซีแอลอาร์
- ระบุ
- อิลลินอยส์
- ภาพ
- การสร้างภาพ
- ภาพ
- ส่งผลกระทบ
- ที่กระทบ
- นำเข้า
- ประทับใจ
- in
- ประกอบด้วย
- รวมถึง
- รวมทั้ง
- รวมเข้าด้วยกัน
- เพิ่ม
- เพิ่มขึ้น
- ที่เพิ่มขึ้น
- อุตสาหกรรม
- ข้อมูล
- อินพุต
- ตัวอย่าง
- แทน
- คำแนะนำการใช้
- ประกัน
- อินเตอร์เฟซ
- ร่วมมือ
- ความเหงา
- ปัญหา
- ปัญหา
- IT
- การสัมภาษณ์
- การเดินทาง
- JSON
- เก็บ
- ความรู้
- ภาษา
- ภาษา
- ใหญ่
- ชื่อสกุล
- เปิดตัว
- ชั้น
- เรียนรู้
- ได้เรียนรู้
- การเรียนรู้
- ข้อ จำกัด
- ถูก จำกัด
- Line
- เส้น
- รายการ
- น้อย
- โหลด
- ในประเทศ
- นาน
- ดู
- ดูเหมือน
- ปิด
- ต่ำ
- เครื่อง
- เรียนรู้เครื่อง
- ทำ
- ลักษณะ
- ด้วยมือ
- การผลิต
- หลาย
- การจับคู่
- สูงสุด
- ภาพบรรยากาศ
- หน่วยความจำ
- กลาง
- อาจ
- ใจ
- ขั้นต่ำ
- หายไป
- ML
- แบบ
- โมเดล
- ขณะ
- ข้อมูลเพิ่มเติม
- หลาย
- ชื่อ
- ที่มีชื่อ
- โดยธรรมชาติ
- ภาษาธรรมชาติ
- ประมวลผลภาษาธรรมชาติ
- จำเป็น
- จำเป็นต้อง
- จำเป็น
- เครือข่าย
- ถัดไป
- NFTS
- NLP
- สัญญาณรบกวน
- สมุดบันทึก
- พฤศจิกายน
- จำนวน
- วัตถุ
- สังเกต
- ONE
- เปิด
- การดำเนินการ
- ใบสั่ง
- องค์กร
- เป็นต้นฉบับ
- อื่นๆ
- ภาพรวม
- ของตนเอง
- เอกสาร
- พารามิเตอร์
- ในสิ่งที่สนใจ
- ผ่าน
- ที่ผ่านไป
- เส้นทาง
- ดำเนินการ
- การปฏิบัติ
- ที่มีประสิทธิภาพ
- ปรับแต่ง
- สัตว์เลี้ยง
- ภาพเสมือนจริง
- พิกเซล
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- กรุณา
- จุด
- บวก
- เป็นไปได้
- โพสต์
- โพสต์
- คาดการณ์
- นำเสนอ
- ก่อน
- ก่อน
- กระบวนการ
- การประมวลผล
- ก่อ
- ผลิตภัณฑ์
- ก้าวหน้า
- ให้
- ให้
- ให้
- การให้
- สาธารณชน
- การตีพิมพ์
- หลาม
- คุณภาพ
- อย่างรวดเร็ว
- สุ่ม
- ตั้งแต่
- คะแนน
- พร้อม
- จริง
- เรียลไทม์
- เหมือนจริง
- เมื่อเร็ว ๆ นี้
- รับรู้
- แนะนำ
- แนะนำ
- สีแดง
- ลด
- ไม่คำนึงถึง
- ที่เกี่ยวข้อง
- การเผยแพร่
- การกำจัด
- เอาออก
- ตัวแทน
- การร้องขอ
- ต้องการ
- จำเป็นต้องใช้
- ความต้องการ
- ต้อง
- นักวิจัย
- ความละเอียด
- แหล่งข้อมูล
- ตอบสนอง
- คำตอบ
- ผล
- ส่งผลให้
- ผลสอบ
- บทบาท
- วิ่ง
- วิ่ง
- sagemaker
- กล่าวว่า
- เดียวกัน
- ประหยัด
- วิทยาศาสตร์
- นักวิทยาศาสตร์
- สคริปต์
- SDK
- ค้นหา
- วินาที
- Section
- ระดับอาวุโส
- ชุด
- บริการ
- บริการ
- ชุด
- การตั้งค่า
- หลาย
- รูปร่าง
- น่า
- โชว์
- แสดง
- แสดงให้เห็นว่า
- อย่างมีความหมาย
- คล้ายคลึงกัน
- ง่าย
- ง่ายดาย
- เดียว
- นั่ง
- ขนาด
- เล็ก
- มีขนาดเล็กกว่า
- So
- ทางออก
- โซลูชัน
- บาง
- ช่องว่าง
- พิเศษ
- โดยเฉพาะ
- ที่ระบุไว้
- ความเร็ว
- มั่นคง
- ระยะ
- ที่เริ่มต้น
- เริ่มต้น
- สถานะ
- ขั้นตอน
- ขั้นตอน
- หยุด
- การเก็บรักษา
- สตูดิโอ
- หรือ
- ที่ประสบความสำเร็จ
- อย่างเช่น
- ทนทุกข์ทรมาน
- เพียงพอ
- สนับสนุน
- ที่สนับสนุน
- รองรับ
- TAG
- เอา
- ใช้เวลา
- เป้า
- งาน
- ทีม
- เทคโนโลยี
- เงื่อนไขการใช้บริการ
- การทดสอบ
- พื้นที่
- ของพวกเขา
- ดังนั้น
- ตลอด
- เวลา
- ไปยัง
- ในวันนี้
- ร่วมกัน
- เกินไป
- รวม
- รถไฟ
- ผ่านการฝึกอบรม
- การฝึกอบรม
- รถไฟ
- โอน
- เดินทาง
- ชนิด
- ui
- เป็นเอกลักษณ์
- มหาวิทยาลัย
- บันทึก
- ให้กับคุณ
- การปรับปรุง
- URI
- us
- ใช้
- ใช้กรณี
- ผู้ใช้งาน
- ส่วนติดต่อผู้ใช้
- มักจะ
- ยูทิลิตี้
- ประโยชน์
- ใช้ประโยชน์
- มีคุณค่า
- ข้อมูลที่มีค่า
- ความคุ้มค่า
- ความคุ้มค่า
- ต่างๆ
- วีดีโอ
- วิธี
- น้ำหนัก
- ว่า
- ที่
- ในขณะที่
- ขาว
- จะ
- ภายใน
- ไม่มี
- คำ
- งาน
- ทำงานด้วยกัน
- ทำงาน
- การทำงาน
- คุ้มค่า
- ผล
- ของคุณ
- ด้วยตัวคุณเอง
- ลมทะเล
- เป็นศูนย์