ในบทความนี้ คุณจะได้พบกับวิธีการต่างๆ ในการแปลง PDF เป็น Google ชีต
คุณจะได้เรียนรู้ว่า Nanonets สามารถทำได้อย่างไร ทำให้เวิร์กโฟลว์ทั้งหมดในการแปลง PDF เป็น Google ชีตเป็นไปโดยอัตโนมัติ ออนไลน์
ก่อนที่เราจะดูวิธีการแปลง PDF เป็น Google ชีต มาดูว่าทำไมการทำสิ่งนี้จึงสำคัญ
ทำไมต้องแปลง PDF เป็น Google ชีต
ตามนี้ Google บล็อก โพสต์จากหน้าบล็อกอย่างเป็นทางการของ Google ธุรกิจมากกว่า 5 ล้านแห่งกำลังใช้โซลูชัน G Suite ของตน ในเวลาเดียวกัน บริษัทจำนวนมากได้เริ่มใช้การผสานรวม Google ชีตเพื่อทำงานอัตโนมัติ
ลองพิจารณากรณีการใช้งานทั่วไป ทีมบัญชีเจ้าหนี้ของคุณจะได้รับใบแจ้งหนี้ในรูปแบบ PDF มาตรฐาน มีคนผ่านใบแจ้งหนี้และคีย์ข้อมูลที่จำเป็นลงในเอกสาร Google ชีตด้วยตนเองก่อนที่จะส่งต่อไปยังส่วนการเงิน ส่วนการเงินจะจ่ายเงินให้กับซัพพลายเออร์ของคุณและทำการเข้าสู่บัญชีแยกประเภทของบริษัท
นอกเหนือจากกระบวนการที่ยืดเยื้อมาเป็นเวลานานแล้ว นี่ยังมีโอกาสเกิดข้อผิดพลาดและจะทำให้ระบบอัตโนมัติเป็นไปโดยอัตโนมัติ
ตอนนี้ความจำเป็นในการแปลง PDF เป็นแบบฟอร์ม Google ชีตนั้นชัดเจนแล้ว มาดูกันว่าเอกสาร PDF มีโครงสร้างอย่างไร และความท้าทายในการแยกวิเคราะห์เอกสารเหล่านี้คืออะไร
ต้องการแปลง รูปแบบไฟล์ PDF ไฟล์ไปที่ Google เอกสาร ? เช็คเอาท์ นาโนเน็ต ฟรี ตัวแปลง PDF เป็น CSV. หรือค้นหาวิธีการ ทำให้เวิร์กโฟลว์ PDF เป็น Google ชีตทั้งหมดเป็นอัตโนมัติด้วย Nanonets.
ความท้าทายในการแยกวิเคราะห์เอกสาร PDF
รูปแบบเอกสารแบบพกพาเป็นรูปแบบไฟล์ที่พัฒนาโดย Adobe และต่อมาได้เปิดตัวเป็นมาตรฐานเปิด นับตั้งแต่นั้นมาก็ได้รับการยอมรับอย่างกว้างขวางเนื่องจากไม่เชื่อเรื่องพระเจ้ากับระบบปฏิบัติการพื้นฐาน
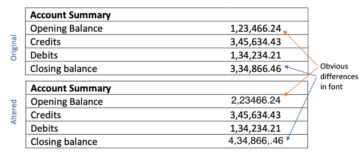
เหตุใดจึงเป็นเรื่องยากที่จะแยกวิเคราะห์ PDF และแปลงเนื้อหาเป็นรูปแบบอื่น รูปภาพต่อไปนี้พูดได้นับพันคำและจะผลักดันให้กลับบ้าน
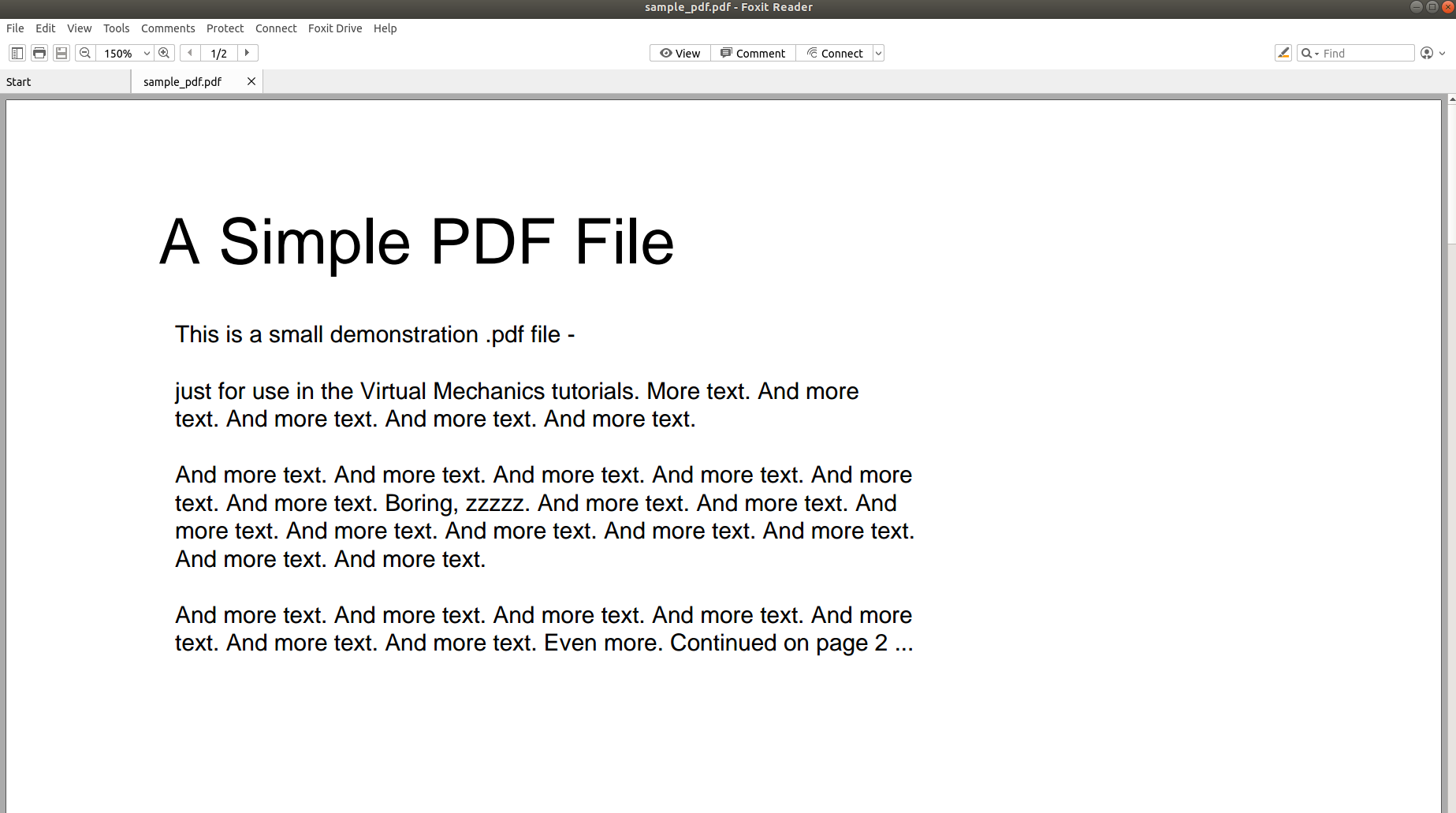
รูปภาพด้านบนแสดงภาพหน้าจอของเอกสาร PDF ที่เปิดขึ้นโดยใช้โปรแกรมอ่าน PDF มาลองเปิดเอกสาร PDF เดียวกันโดยใช้โปรแกรมแก้ไขข้อความกัน
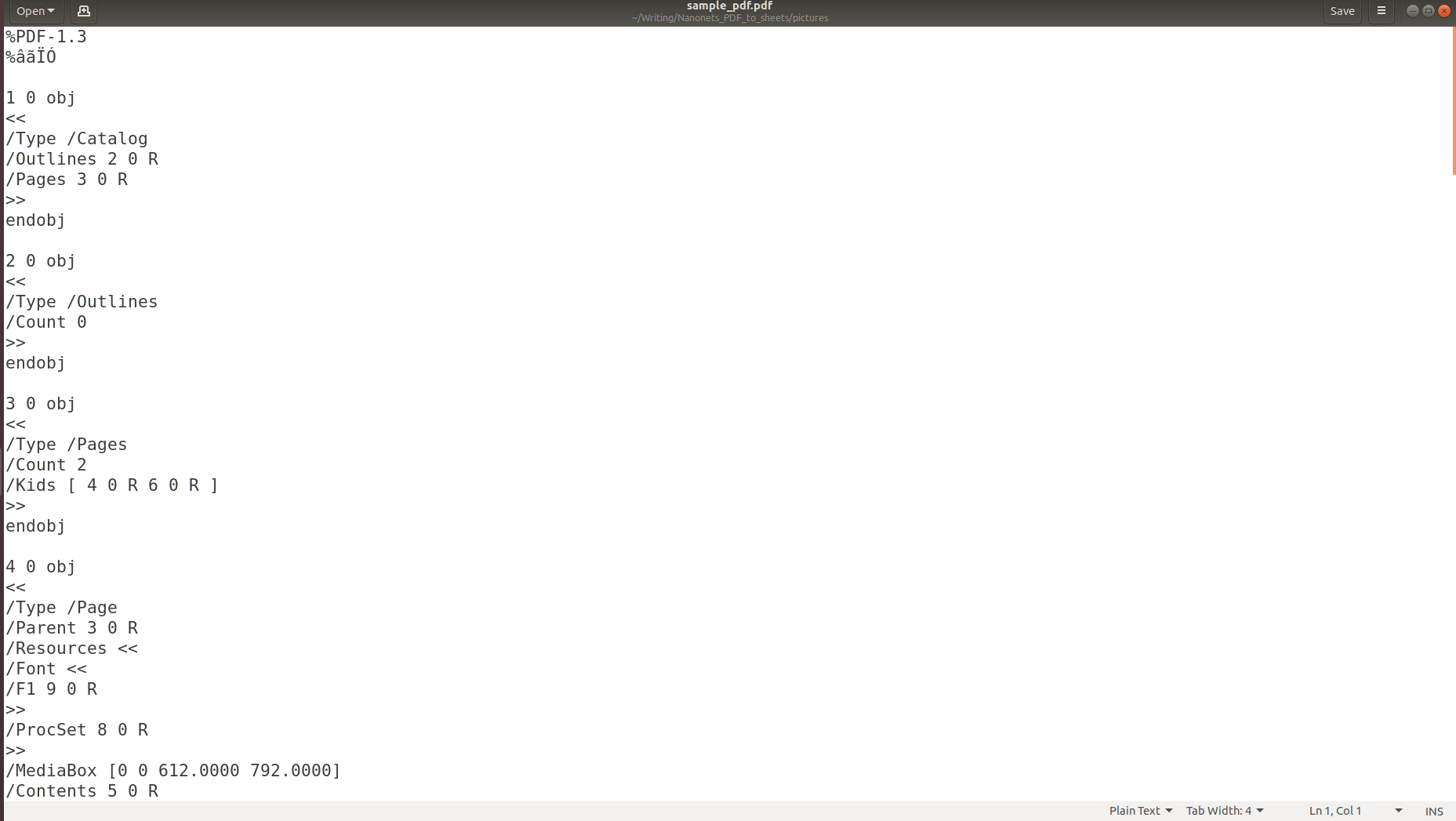
รูปภาพด้านบนแสดงให้เห็นชัดเจนว่าเมื่อข้อมูลถูกจัดเก็บในรูปแบบ PDF โครงสร้างดั้งเดิมของข้อมูลจะสูญหายไปโดยสิ้นเชิง เนื่องจากรูปแบบ PDF ประกอบด้วยคำแนะนำในการพิมพ์/วาดลำดับอักขระบนหน้า
ถ้าคุณคิดว่าการแยกข้อความทำได้ยาก การดึงข้อมูลที่มีอยู่ในตารางจะยิ่งท้าทายมากขึ้นไปอีก เนื่องจากมีรูปแบบตารางที่ใช้กันอย่างแพร่หลาย
หวังว่าคุณจะมั่นใจว่าการแปลงเอกสาร PDF เป็นแบบฟอร์ม Google ชีตนั้นไม่ใช่เรื่องง่าย ส่วนถัดไปจะพูดถึงวิธีการที่โปรแกรมแยกวิเคราะห์ PDF สมัยใหม่ส่วนใหญ่ใช้ในการจดจำ/แยกวิเคราะห์ข้อมูลจากเอกสาร PDF
แนวทางสมัยใหม่ในการแยกวิเคราะห์เอกสาร PDF
ตัวแยกวิเคราะห์ PDF ที่ทันสมัยส่วนใหญ่ใช้ประโยชน์จากโฟลว์ที่อธิบายไว้ด้านล่างเพื่อแยกวิเคราะห์ข้อมูลที่ไม่มีโครงสร้างจากเอกสาร PDF
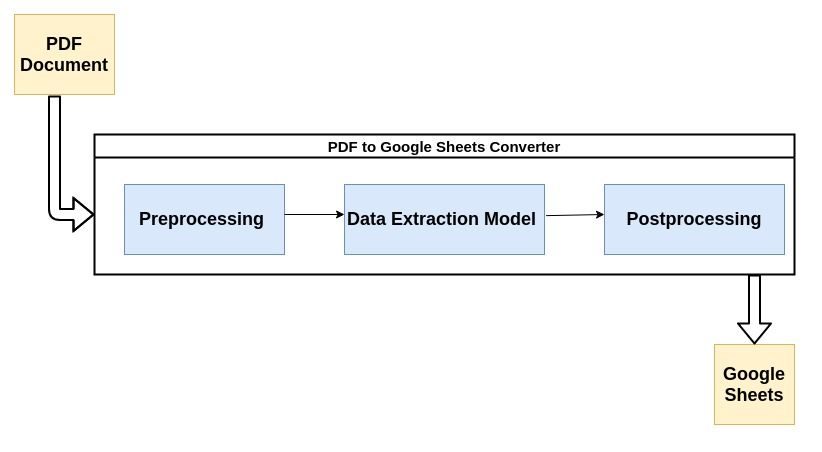
มาดูแต่ละขั้นตอนของกระบวนการกัน:
1. การประมวลผลล่วงหน้าหรือการล้างข้อมูล:
ยิ่ง PDF ของคุณดูดีขึ้นเท่าไหร่ แบบจำลองแมชชีนเลิร์นนิงของคุณจะแยกหรือ . ได้ง่ายขึ้น เก็บข้อมูล จากมัน. ตัวอย่างเช่น ถ้าเอกสาร PDF ถูกสแกน เอกสารนั้นจะต้องมีวัตถุสแกนที่อาจส่งผลต่อประสิทธิภาพของตัวแปลง
การกำจัดสัญญาณรบกวนโดยใช้ตัวกรองที่เหมาะสม, ไบนารี, การแก้ไขความเอียง ฯลฯ เป็นขั้นตอนก่อนการประมวลผลทั่วไปบางส่วน โพสต์ต่อไปนี้ของ Nanonets โพสต์ของ Nanonets Tesseract มีตัวอย่างที่ดีเกี่ยวกับวิธีการประมวลผลเอกสารล่วงหน้าก่อน Optical Character ยอมรับ(OCR) ทำงานบนพวกเขา
นี่คือที่ที่เวทมนตร์ส่วนใหญ่เกิดขึ้น การดึงข้อมูลมักจะดำเนินการโดยโมเดล Machine Learning (ML) โมเดล ML ส่วนใหญ่ที่ใช้สำหรับการดึงข้อมูลจาก PDF ประกอบด้วยเครื่องมือการรู้จำอักขระด้วยแสง เครื่องมือการรู้จำข้อความและรูปแบบ ฯลฯ
สำหรับจุดประสงค์ของโพสต์นี้ เราสามารถถือว่าโมเดลนั้นเป็นกล่องดำที่รับเอกสาร PDF ของคุณเป็นอินพุตและแยกข้อมูลที่แยกวิเคราะห์ออกมา นอกจากนี้ เนื่องจากใช้ ML เป็นแกนหลัก จึงสามารถฝึกอบรมใหม่ด้วยข้อมูลที่กำหนดเองเพื่อให้เหมาะสมกับกรณีการใช้งานของบริษัทของคุณ
3. หลังการประมวลผล:
ในขั้นตอนนี้ ข้อมูลที่แยกออกมาจะถูกแปลงเป็นรูปแบบที่ต้องการ เช่น CSV, XML, JSON เป็นต้น นอกจากนี้ ยังมีการเพิ่มกฎที่ผู้ใช้กำหนดเพิ่มเติมนอกเหนือจากการคาดการณ์ของ AI ซึ่งอาจรวมถึงกฎสำหรับการจัดรูปแบบผลลัพธ์ ข้อจำกัดเพิ่มเติมเกี่ยวกับข้อมูลที่ดึงออกมา เป็นต้น
ส่วนต่อไปนี้จะกล่าวถึงตัวชี้วัดบางอย่างที่เราสามารถใช้วัดประสิทธิภาพของโปรแกรมแยกวิเคราะห์ PDF
ต้องการแปลง รูปแบบไฟล์ PDF ไฟล์ไปที่ Google เอกสาร ? เช็คเอาท์ นาโนเน็ต ฟรี ตัวแปลง PDF เป็น CSV. ดูวิธีทำให้เวิร์กโฟลว์ PDF เป็น Google ชีตของคุณทำงานโดยอัตโนมัติด้วย Nanonets

ตัวชี้วัดเพื่อวัดประสิทธิภาพของโปรแกรมแปลงไฟล์ PDF
เนื่องจากตัวแปลง PDF ส่วนใหญ่จะใช้สำหรับการประมวลผลใบแจ้งหนี้หรืองานที่เกี่ยวข้อง ความถูกต้องและความเร็วของการแยกตารางจากเอกสาร PDF จึงเป็นปัจจัยสำคัญในการตัดสินประสิทธิภาพของตัวแปลง PDF
2. ความสามารถหลายภาษา:
บริษัทขนาดใหญ่ส่วนใหญ่ต้องรับใบแจ้งหนี้ในหลายภาษา ตัวแยกวิเคราะห์ PDF ควรสนับสนุนการแยกวิเคราะห์แบบหลายภาษาหรือควรให้ตัวเลือกที่ผู้ใช้สามารถฝึกโมเดลโดยใช้ข้อมูลที่กำหนดเอง
3. บูรณาการกับซอฟต์แวร์บัญชี:
ตัวแปลง PDF ที่เหมาะควรเป็นโมดูลแบบพลักแอนด์เพลย์ที่สามารถเพิ่มลงในไฟล์ที่มีอยู่ของคุณได้อย่างง่ายดาย เวิร์กโฟลว์เอกสาร. ควรสนับสนุนการรวมเข้ากับซอฟต์แวร์บัญชียอดนิยมเช่น QuickBooks, Xero, Wave เป็นต้น
4. ง่ายและใช้งานง่าย:
เครื่องมือนี้มักจะดำเนินการโดยผู้ใช้ที่ไม่ใช่ด้านเทคนิค มันจะเป็นประโยชน์หากสามารถใช้งานได้โดยมีความรู้ด้านเทคนิคน้อยที่สุด
วิธีการต่างๆ ในการแปลง PDF เป็น Google ชีต
1. การใช้ Google Docs เพื่อแปลง PDF เป็น Google ชีต
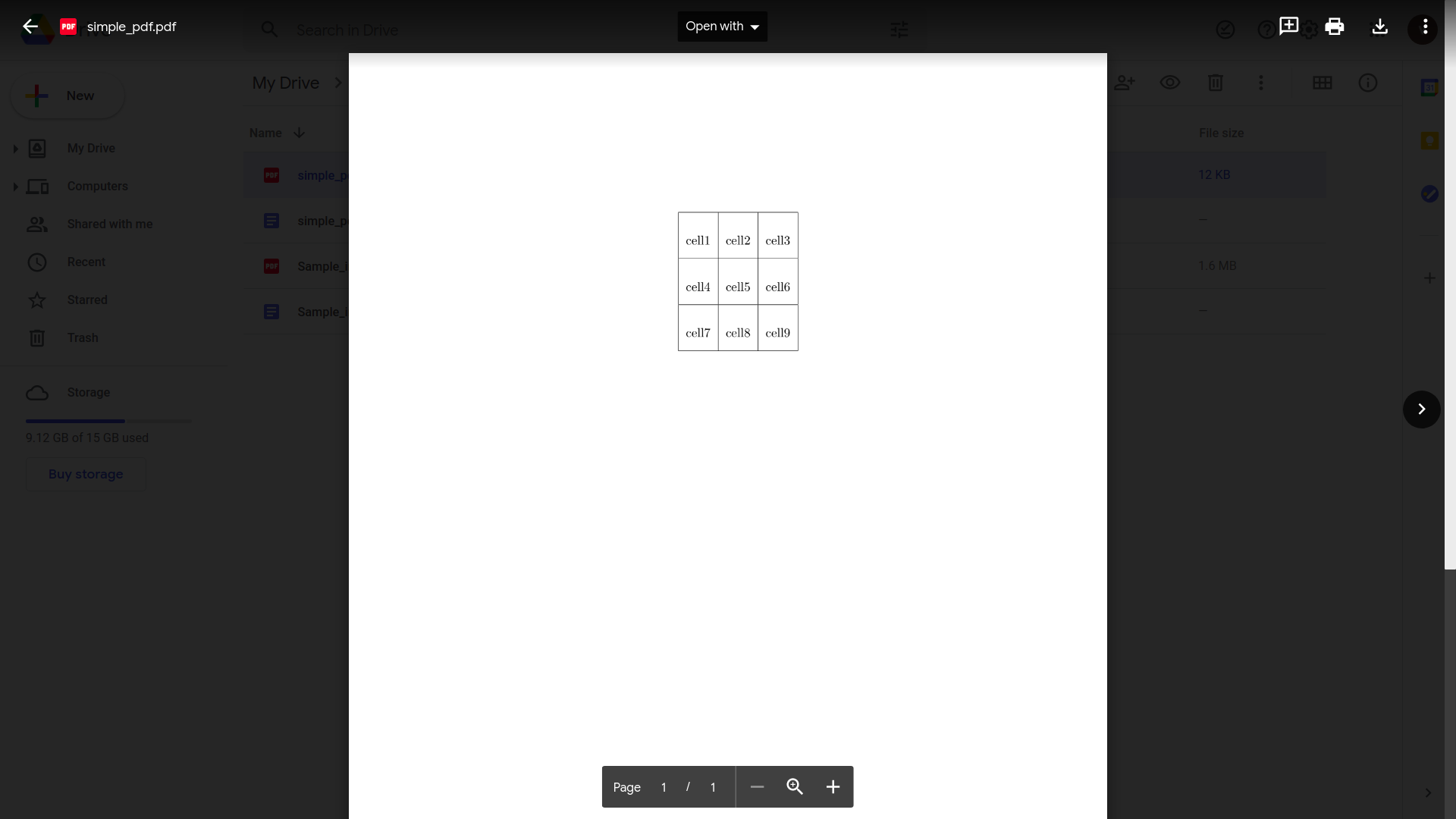
Google ไดรฟ์มีความสามารถในการจดจำตารางและข้อความภายในเอกสาร PDF อย่างง่าย คุณเพียงแค่ต้อง:
-
อัปโหลดไฟล์ PDF ของคุณไปยัง Google Drive
-
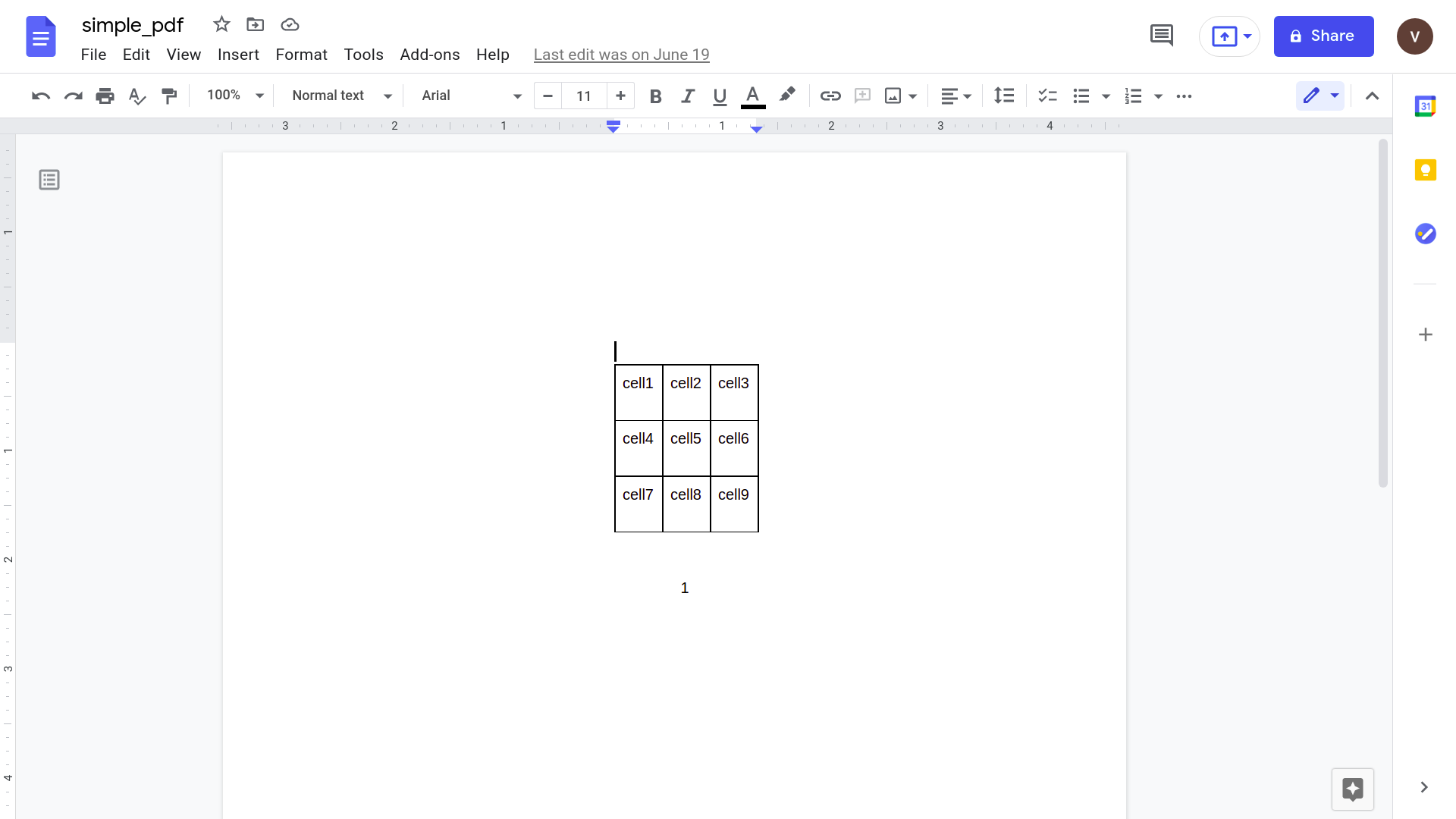
คลิก “เปิดด้วย Google เอกสาร”
-
คัดลอกข้อมูลที่คุณต้องการและวางลงใน Google ชีต
แม้ว่าจะดูเหมือนว่าจะใช้ได้ผลดี แต่มาลองทำอะไรที่เป็นประโยชน์มากกว่านี้หน่อย พิจารณาใบแจ้งหนี้ง่ายๆ นี้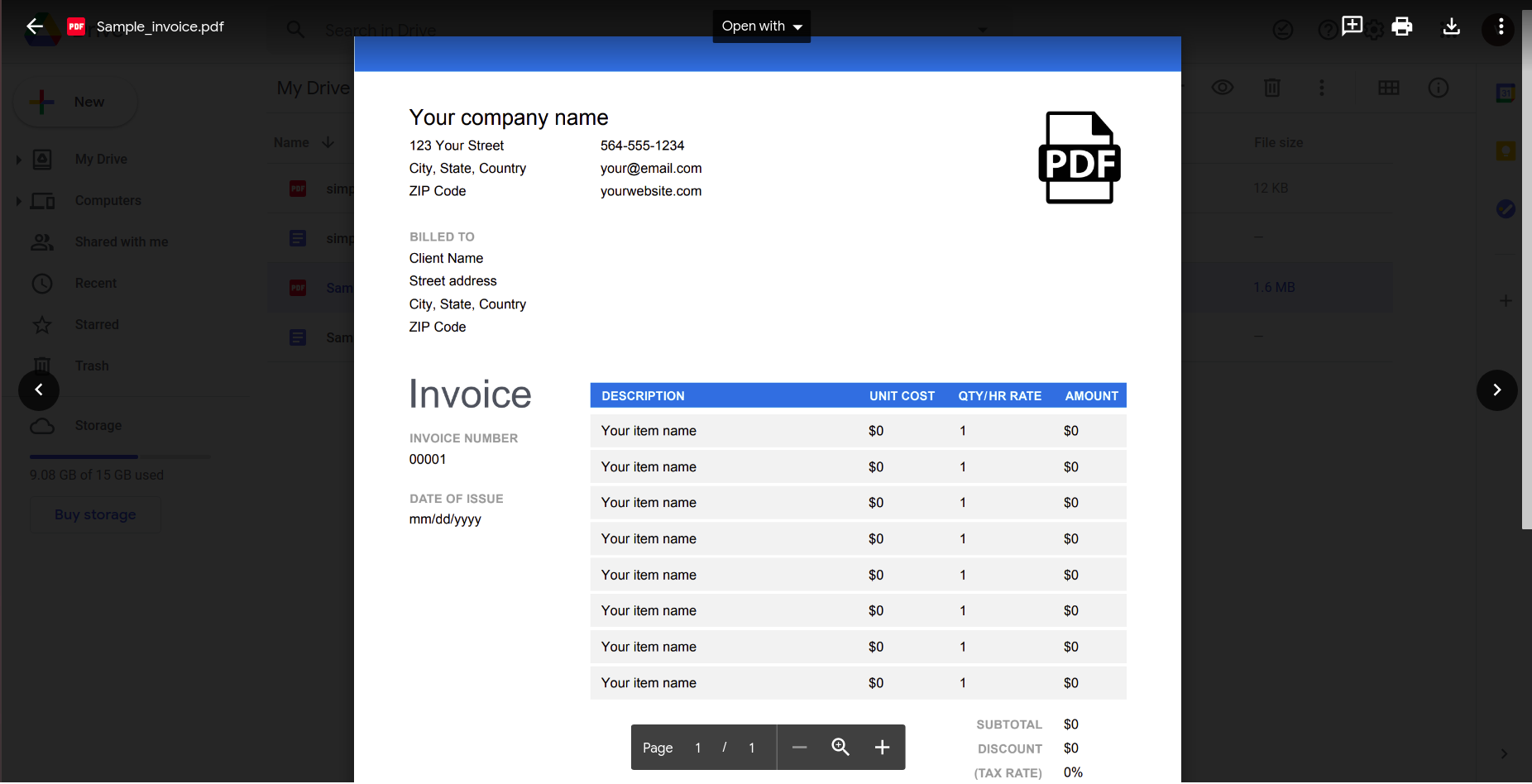
การเปิดสิ่งนี้โดยใช้แอปพลิเคชัน Google docs ให้ผลลัพธ์ดังต่อไปนี้
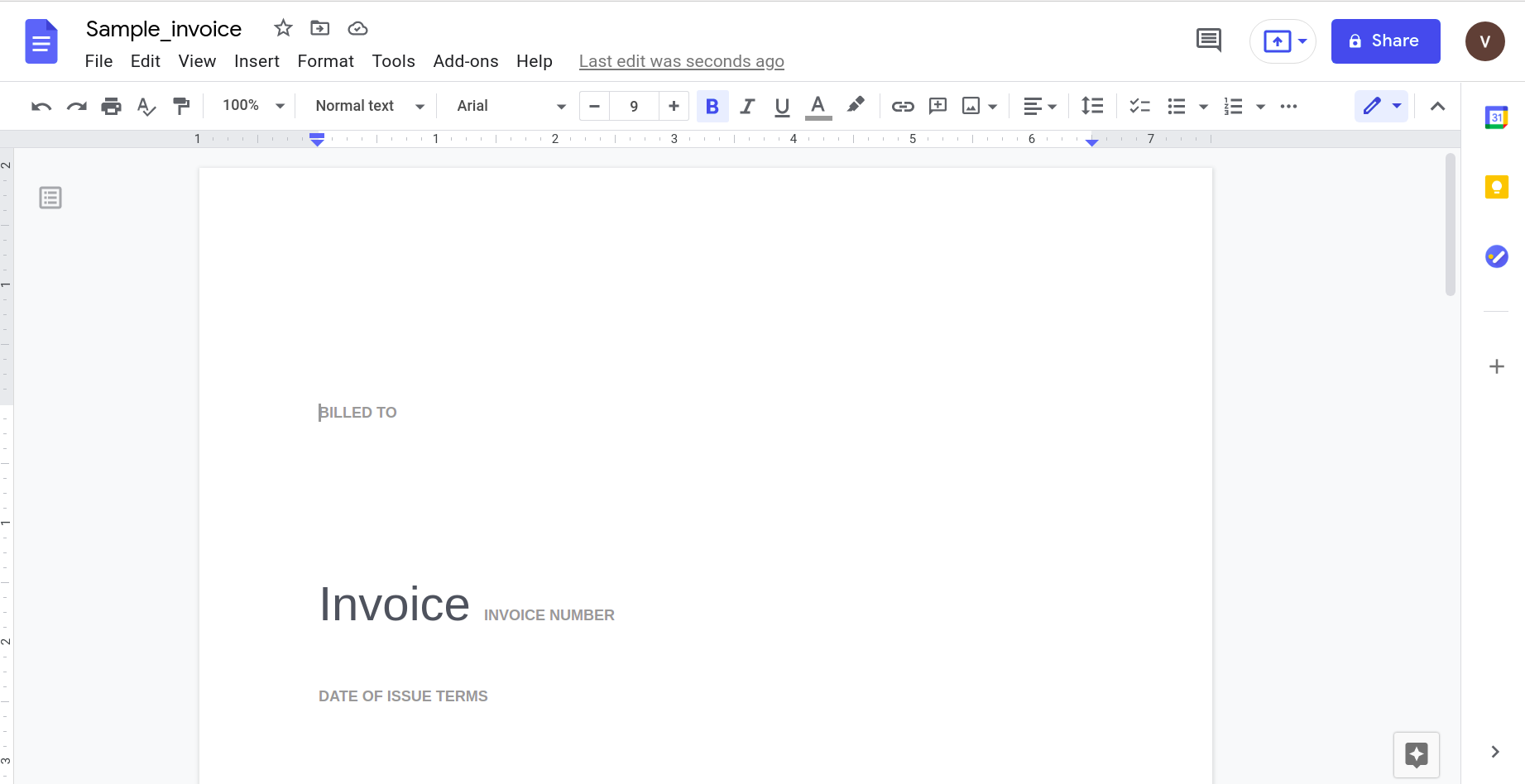
เห็นได้ชัดว่าเมื่อความซับซ้อนของเอกสารเพิ่มขึ้น เราจำเป็นต้องพึ่งพาเครื่องมือที่ซับซ้อนมากขึ้นในการจดจำข้อมูล
2. การใช้เครื่องมือออนไลน์:
เครื่องมือออนไลน์หลายอย่าง เช่น โปรแกรมแยกตาราง PDF, Online2PDF ฯลฯ ผสานรวมกับ Google ไดรฟ์โดยตรง และให้ความสามารถในการแปลงเอกสาร PDF เป็น Google ชีตได้ทันที
อย่างไรก็ตาม เมื่อเครื่องมือเหล่านี้ได้รับการทดสอบโดยใช้ตัวอย่างใบแจ้งหนี้ PDF ที่แสดงด้านบน ส่วนใหญ่กรณีจะไม่พบตาราง
ต้องการแปลง รูปแบบไฟล์ PDF ไฟล์ไปที่ Google เอกสาร ? เช็คเอาท์ นาโนเน็ต ฟรี ตัวแปลง PDF เป็น CSV. ดูวิธีทำให้เวิร์กโฟลว์ PDF เป็น Google ชีตของคุณทำงานโดยอัตโนมัติด้วย Nanonets ดังที่แสดงด้านล่าง
กระบวนการแปลง PDF เป็น Google ชีตอัตโนมัติ
เราสามารถทำให้กระบวนการแยกวิเคราะห์ PDF และดึงข้อมูลลงในแบบฟอร์ม Google ชีตได้อย่างสมบูรณ์โดยอัตโนมัติโดยใช้เครื่องมือต่อไปนี้
1. การใช้เว็บฮุค:
Webhooks คือคำขอ HTTP ที่กำหนดขึ้นเอง โดยปกติแล้วจะถูกทริกเกอร์ในเหตุการณ์ เช่น เมื่อเกิดเหตุการณ์ แอปพลิเคชันจะส่งข้อมูลไปยัง URL ที่กำหนดไว้ล่วงหน้า
คุณจะใช้สิ่งนี้เพื่อทำให้เวิร์กโฟลว์ของคุณทำงานอัตโนมัติได้อย่างไร ลองพิจารณากรณีการใช้งานทั่วไปของการประมวลผลใบแจ้งหนี้ คุณได้รับใบแจ้งหนี้จำนวนหนึ่งจากซัพพลายเออร์ของคุณและป้อนลงในตัวแปลง PDF เป็น Google ชีตซึ่งอยู่บนคลาวด์ คุณรู้ได้อย่างไรว่าตัวแบบประมวลผลเอกสารเสร็จแล้ว?
แทนที่จะตรวจสอบด้วยตนเองว่าการแปลงเสร็จสมบูรณ์หรือไม่ คุณสามารถใช้เว็บฮุคที่แจ้งให้คุณทราบเมื่อข้อมูลใน PDF ถูกแยกไปยังเอกสาร Google ชีต
2. การใช้ APIs
API ย่อมาจาก Application Programming Interface การใช้การเรียก API ที่เหมาะสม การแปลงเอกสาร PDF เป็น Google ชีตอาจเป็นเรื่องง่ายเหมือนการเขียนโค้ดบรรทัดต่อไปนี้
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
หากบริษัทของคุณตั้งค่าการผสานรวมกับ Webhooks แล้ว คุณจะได้รับการแจ้งเตือนเมื่อแปลงเอกสาร PDF ของคุณสำเร็จ จากนั้น คุณสามารถดาวน์โหลดแบบฟอร์ม Google ชีตได้โดยใช้ API ที่แสดงด้านล่าง
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF เป็น Google ชีตด้วย Nanonets
ตัวแยกวิเคราะห์ PDF ของ Nanonets ทำให้การแยกวิเคราะห์และการแปลงทำได้ง่ายและแม่นยำ ตัวแยกวิเคราะห์ PDF ใช้เพื่อแยกวิเคราะห์ใบแจ้งหนี้ตัวอย่าง ส่วนนี้แสดงให้เห็นถึงการใช้งานง่ายและความแม่นยำของเครื่องมือ แทนที่จะพูดถึงความยอดเยี่ยม รูปภาพต่อไปนี้แสดงให้เห็นอย่างชัดเจนถึงประเด็นนี้
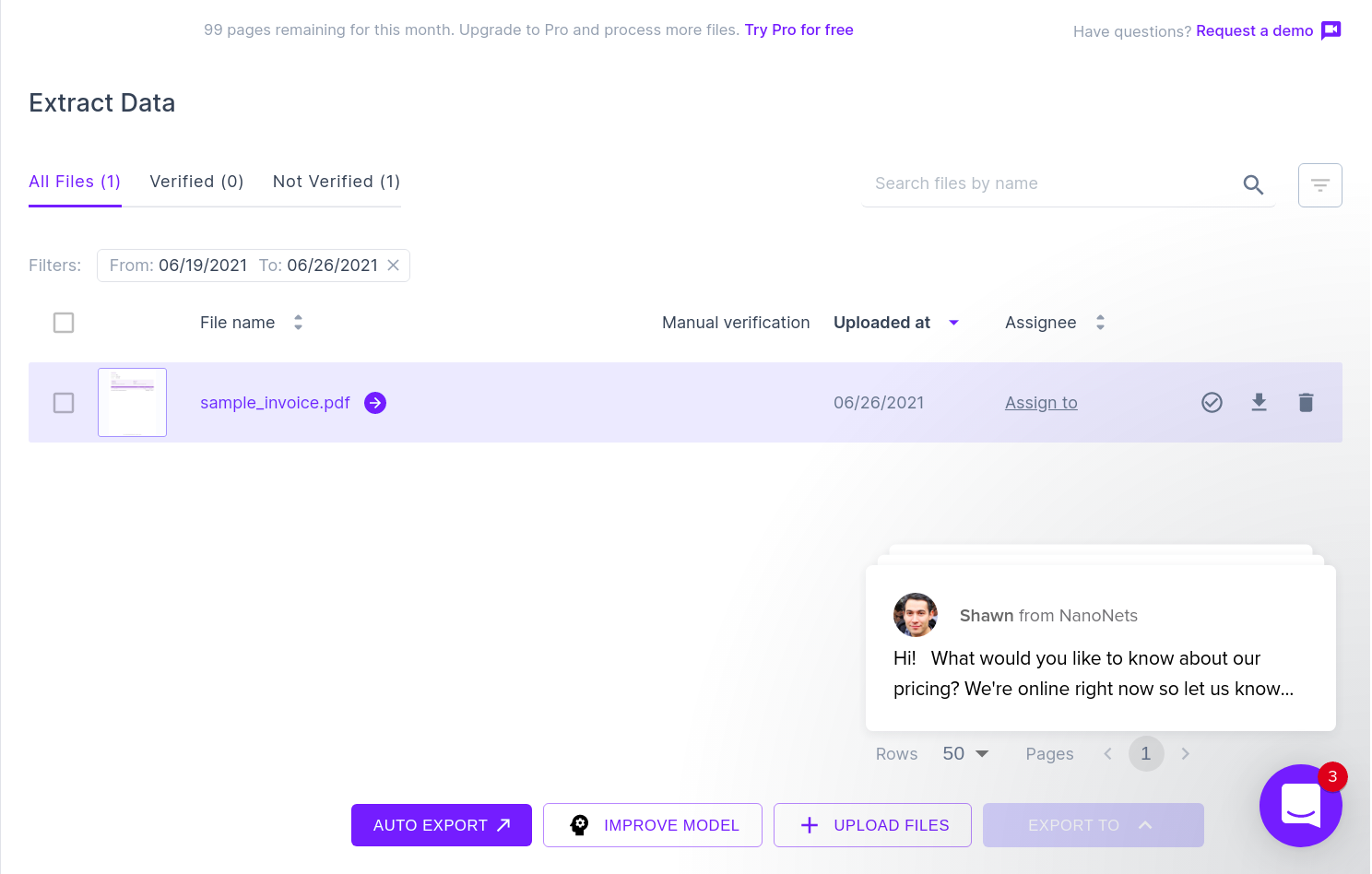
รูปภาพที่แสดงด้านล่างเป็นภาพหน้าจอของใบแจ้งหนี้ตัวอย่างที่ป้อนไปยังโปรแกรมแยกวิเคราะห์ PDF ของ Nanonets
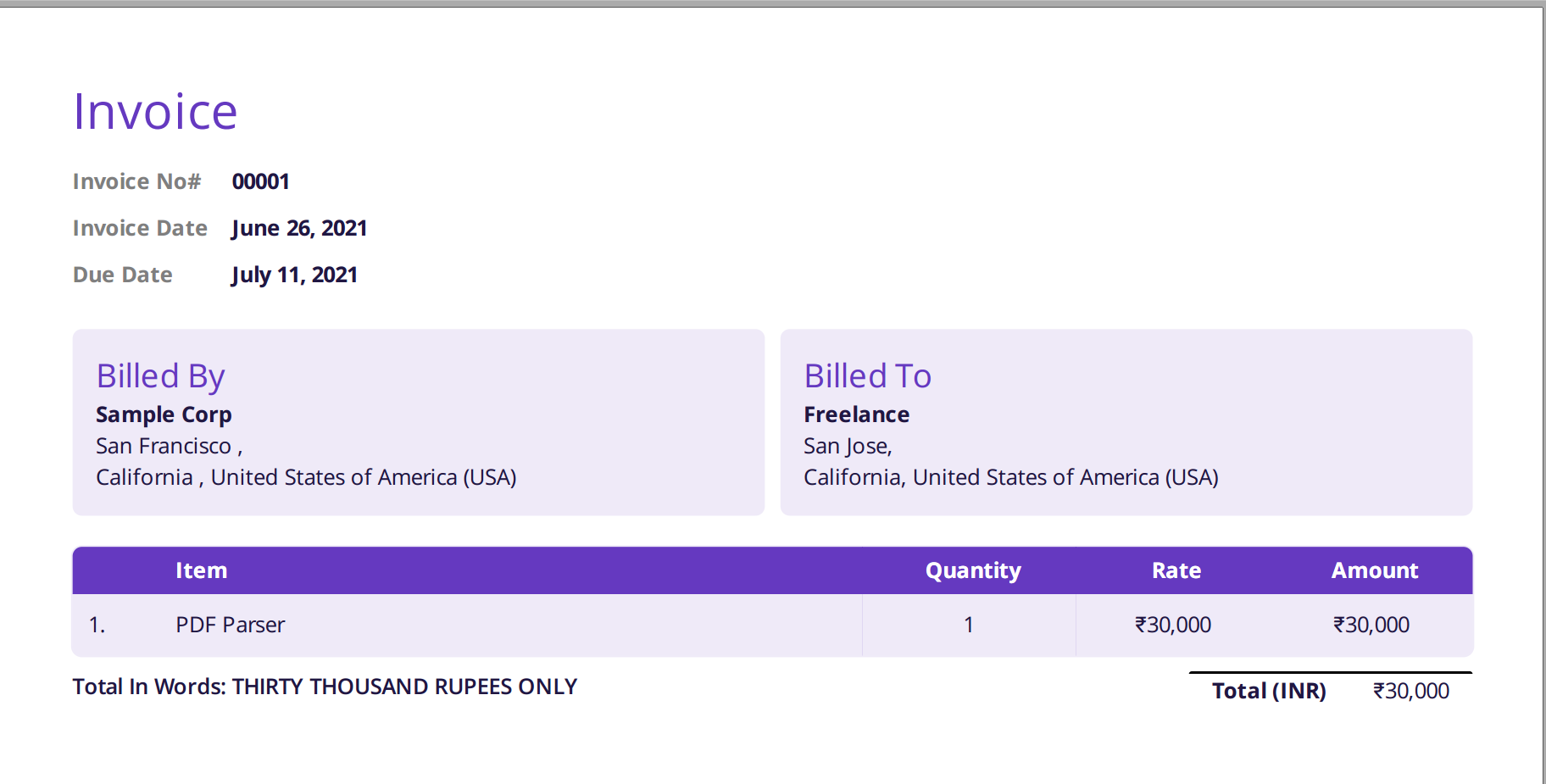
เพียงไปที่เว็บไซต์ Nanonets และอัปโหลดใบแจ้งหนี้ การแปลงใช้เวลาเพียงไม่กี่วินาทีหลังจากนั้น ข้อมูลที่แยกวิเคราะห์แล้วสามารถดาวน์โหลดในรูปแบบต่างๆ เช่น CSV, XLSX เป็นต้น (ดู Nanonets' ตัวแปลง PDF เป็น CSV)
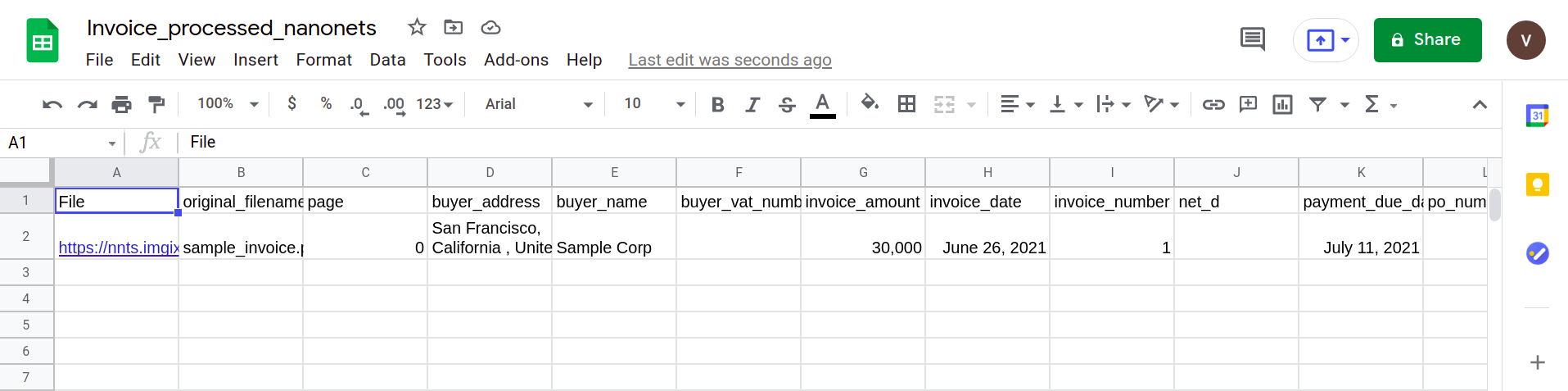
รูปภาพถัดไปแสดงภาพหน้าจอของไฟล์ CSV ที่มีข้อมูลที่แยกวิเคราะห์จากเอกสาร PDF

สุดท้าย ในการแปลงไฟล์ CSV เป็นรูปแบบ Google ชีต ก็แค่อัปโหลดไฟล์ XLSX/CSV ลงใน Google Drive ของคุณ ขั้นตอนนี้สามารถดำเนินการโดยอัตโนมัติโดยใช้ API ของไดรฟ์ของ Google
ส่วนต่อไปนี้แสดงวิธีการสร้างไปป์ไลน์อย่างง่ายโดยใช้ตัวแยกวิเคราะห์ PDF ของ Nanonets
ต้องการดึงข้อมูลจากเอกสาร PDF และแปลง/เพิ่มลงในเอกสาร Google ชีตหรือไม่ ดู นาโนเน็ต™ เพื่อส่งออกข้อมูลใด ๆ จากเอกสาร PDF ไปยัง Google ชีตโดยอัตโนมัติ!
การสร้างไปป์ไลน์อย่างง่าย
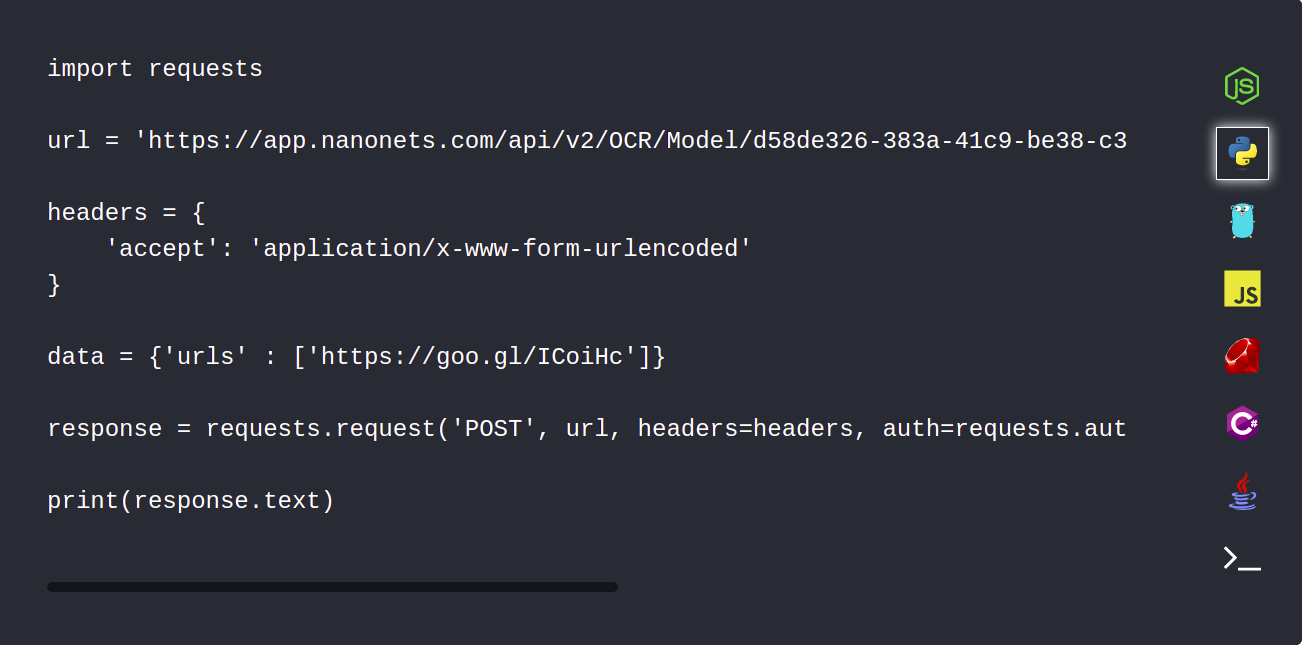
1. อัปโหลดเอกสาร PDF ของคุณโดยอัตโนมัติโดยใช้ Nanonets API
Nanonets API ให้คุณอัปโหลดเอกสารที่ต้องแยกวิเคราะห์โดยอัตโนมัติ ข้อมูลโค้ดต่อไปนี้แสดงให้เห็นว่าสามารถทำได้โดยใช้ python
2. ใช้การรวมเว็บฮุคเพื่อรับการแจ้งเตือนเมื่อการแยกวิเคราะห์เสร็จสิ้น
เว็บฮุคสามารถกำหนดค่าให้แจ้งเตือนคุณโดยอัตโนมัติเมื่อแยกวิเคราะห์เอกสารแล้ว
3. ตรวจสอบและอัปโหลดไปยัง Google ชีต
ดาวน์โหลดและตรวจสอบไฟล์ CSV เพื่อให้แน่ใจว่าทุกอย่างเป็นไปตามลำดับ และอัปโหลดข้อมูลไปยัง Google ชีตโดยใช้ Google Drive API
ขอบนาโนเน็ต
นี่คือคุณสมบัติบางอย่างของ Nanonets PDF Parser ที่ทำให้เป็นเครื่องมือในอุดมคติสำหรับธุรกิจของคุณ
1. การบูรณาการภายนอก:
โมเดล nanonets สามารถรวมเข้ากับ MySql, Quickbooks, Salesforce และอื่นๆ ได้อย่างง่ายดาย ซึ่งหมายความว่าเวิร์กโฟลว์ปัจจุบันของคุณจะไม่ถูกรบกวน และสามารถเสียบตัวแปลงนาโนเน็ตเป็นโมดูลเพิ่มเติมได้
2. ความแม่นยำสูงและเวลาในการประมวลผลต่ำ:
เครื่องมือแยกวิเคราะห์ PDF ของ Nanonets มีความแม่นยำมากกว่า 95%+ ซึ่งสูงกว่าคู่แข่งมาก
3. คุณสมบัติหลังการประมวลผลที่ยอดเยี่ยม:
สมมติว่าฐานข้อมูลของคุณถูกรวมเข้ากับโมเดลนาโนเน็ต โมเดลจะเติมข้อมูลในช่องบางช่องโดยอัตโนมัติ (ด้วยข้อมูลจากฐานข้อมูลของคุณ) ตามข้อมูลที่ดึงมาจากเอกสาร ตัวอย่างเช่น:
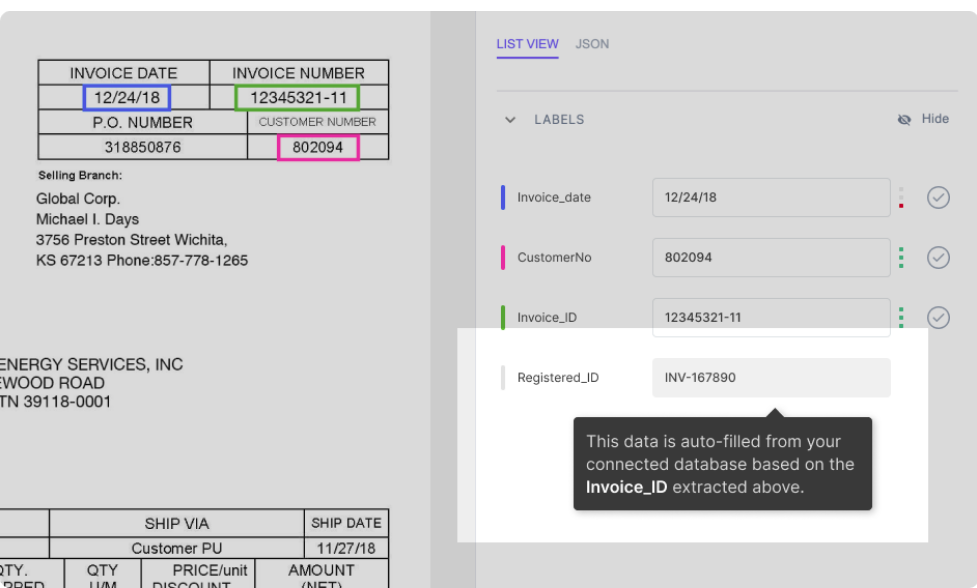
ดังที่แสดงในรูป ฟิลด์ Registered_ID จะถูกกรอกโดยอัตโนมัติ (โดยการค้นหาฐานข้อมูล) ตาม Invoice_ID ที่ดึงมาจาก PDF
4. อินเทอร์เฟซที่เรียบง่ายและใช้งานง่าย
แม้ว่าฟีเจอร์นี้จะถูกประเมินต่ำเกินไป แต่ฉันพบว่า UI และ UX นั้นตรงจุด ขั้นตอนการลงทะเบียน อัปโหลดเอกสาร และแยกวิเคราะห์ข้อมูลทั้งหมดใช้เวลาไม่ถึง 5 นาที เกือบเท่ากับเวลาที่แล็ปท็อปของฉันใช้ในการบู๊ต!
5. ฐานลูกค้าขนาดใหญ่
ในกรณีที่คุณยังมีการจองเกี่ยวกับการใช้ Nanonets เพื่อทำให้เวิร์กโฟลว์ของคุณเป็นแบบอัตโนมัติ ลองดูบริษัทบางแห่งที่ใช้บริการของพวกเขา
- Deloitte
- เชอร์วินวิลเลียมส์
- DoorDash
- พีแอนด์จี
ต้องการดึงข้อมูลจากเอกสาร PDF และแปลง/เพิ่มลงในเอกสาร Google ชีตหรือไม่ ดู นาโนเน็ต™ เพื่อส่งออกข้อมูลใด ๆ จากเอกสาร PDF ไปยัง Google ชีตโดยอัตโนมัติ!
สรุป
ในโพสต์นี้ เรามาดูกันว่าคุณจะทำให้เวิร์กโฟลว์ของคุณทำงานอัตโนมัติโดยใช้ตัวแปลง PDF เป็น Google ชีตได้อย่างไร ในขั้นต้น เราได้เรียนรู้เกี่ยวกับความจำเป็นในการแปลงเอกสาร PDF เป็น Google ชีต ตามด้วยความท้าทายที่ต้องเผชิญในระหว่างกระบวนการนี้ จากนั้นเราก็เจาะลึกถึงแนวทางที่ parsers สมัยใหม่ใช้ในการแยกวิเคราะห์เอกสาร PDF และนำแนวทางทั่วไปบางส่วนไปใช้ เรายังได้เรียนรู้วิธีที่เราสามารถทำให้การแปลงเป็นอัตโนมัติโดยใช้การผสานรวมภายนอก เช่น เว็บฮุคและ API สุดท้าย เราใช้เครื่องมือ Nanonets เพื่อแยกวิเคราะห์ตัวอย่างใบแจ้งหนี้ ดึงข้อมูลลงในแบบฟอร์ม Google ชีต และสำรวจฟีเจอร์หลังการประมวลผลที่ยอดเยี่ยม
คุณได้ลองยิงโมเดลนาโนเน็ตส์ไหม? หากเป็นเช่นนั้น โปรดแสดงความคิดเห็นด้านล่างเกี่ยวกับประสบการณ์ของคุณกับเครื่องมือนี้ ถ้าไม่ไปข้างหน้าและลองใช้ มันอาจทำให้วันของคุณ!
- AI
- AI และการเรียนรู้ของเครื่อง
- ไอ อาร์ต
- เครื่องกำเนิดไออาร์ท
- หุ่นยนต์ไอ
- ปัญญาประดิษฐ์
- ใบรับรองปัญญาประดิษฐ์
- ปัญญาประดิษฐ์ในการธนาคาร
- หุ่นยนต์ปัญญาประดิษฐ์
- หุ่นยนต์ปัญญาประดิษฐ์
- ซอฟต์แวร์ปัญญาประดิษฐ์
- blockchain
- การประชุม blockchain ai
- เหรียญอัจฉริยะ
- ปัญญาประดิษฐ์สนทนา
- การประชุม crypto ai
- ดัล-อี
- การเรียนรู้ลึก ๆ
- google ai
- เรียนรู้เครื่อง
- pdf เป็น google ชีต
- เพลโต
- เพลโตไอ
- เพลโตดาต้าอินเทลลิเจนซ์
- เกมเพลโต
- เพลโตดาต้า
- เพลโตเกม
- ขนาดไอ
- วากยสัมพันธ์
- ลมทะเล