โพสต์นี้เขียนร่วมกับ Mahima Agarwal วิศวกรการเรียนรู้ของเครื่อง และ Deepak Mettem ผู้จัดการฝ่ายวิศวกรรมอาวุโสของ VMware Carbon Black
วีเอ็มแวร์ คาร์บอนแบล็ค เป็นโซลูชันการรักษาความปลอดภัยที่มีชื่อเสียงซึ่งให้การป้องกันการโจมตีทางไซเบอร์สมัยใหม่อย่างเต็มรูปแบบ ด้วยข้อมูลหลายเทราไบต์ที่สร้างโดยผลิตภัณฑ์ ทีมวิเคราะห์ความปลอดภัยจึงมุ่งเน้นไปที่การสร้างโซลูชันแมชชีนเลิร์นนิง (ML) เพื่อแสดงการโจมตีที่สำคัญและเน้นย้ำถึงภัยคุกคามที่เกิดขึ้นใหม่จากสัญญาณรบกวน
เป็นสิ่งสำคัญสำหรับทีม VMware Carbon Black ในการออกแบบและสร้างไปป์ไลน์ MLOps แบบ end-to-end แบบกำหนดเอง ซึ่งจะประสานและทำให้เวิร์กโฟลว์เป็นแบบอัตโนมัติในวงจรชีวิตของ ML และเปิดใช้การฝึกอบรมแบบจำลอง การประเมิน และการปรับใช้
มีวัตถุประสงค์หลักสองประการในการสร้างไปป์ไลน์นี้: สนับสนุนนักวิทยาศาสตร์ข้อมูลสำหรับการพัฒนาแบบจำลองขั้นสุดท้าย และการคาดคะเนแบบจำลองพื้นผิวในผลิตภัณฑ์โดยให้บริการแบบจำลองในปริมาณมากและในการจราจรการผลิตแบบเรียลไทม์ ดังนั้น VMware Carbon Black และ AWS จึงเลือกที่จะสร้างไปป์ไลน์ MLOps แบบกำหนดเองโดยใช้ อเมซอน SageMaker เพื่อความสะดวกในการใช้งาน ความอเนกประสงค์ และโครงสร้างพื้นฐานที่มีการจัดการเต็มรูปแบบ เราจัดเตรียมการฝึกอบรม ML และไปป์ไลน์การปรับใช้โดยใช้ เวิร์กโฟลว์ที่มีการจัดการของ Amazon สำหรับ Apache Airflow (Amazon MWAA) ซึ่งทำให้เราสามารถมุ่งเน้นไปที่การเขียนเวิร์กโฟลว์และไปป์ไลน์โดยใช้โปรแกรมมากขึ้นโดยไม่ต้องกังวลเกี่ยวกับการปรับขนาดอัตโนมัติหรือการบำรุงรักษาโครงสร้างพื้นฐาน
ด้วยไปป์ไลน์นี้ สิ่งที่ครั้งหนึ่งเคยเป็นการวิจัย ML ที่ขับเคลื่อนด้วยโน้ตบุ๊กของ Jupyter ได้กลายเป็นกระบวนการอัตโนมัติในการนำโมเดลไปใช้ในการผลิตโดยมีการแทรกแซงเพียงเล็กน้อยจากนักวิทยาศาสตร์ข้อมูล ก่อนหน้านี้ กระบวนการฝึกอบรม การประเมิน และการปรับใช้โมเดลอาจใช้เวลามากกว่าหนึ่งวัน ด้วยการติดตั้งใช้งานนี้ ทุกสิ่งจะถูกเรียกใช้ทันที และลดเวลาโดยรวมลงเหลือไม่กี่นาที
ในโพสต์นี้ สถาปนิก VMware Carbon Black และ AWS จะหารือเกี่ยวกับวิธีที่เราสร้างและจัดการเวิร์กโฟลว์ ML แบบกำหนดเองโดยใช้ Gitlab, Amazon MWAA และ SageMaker เราหารือถึงสิ่งที่เราประสบความสำเร็จจนถึงตอนนี้ การปรับปรุงเพิ่มเติมในไปป์ไลน์ และบทเรียนที่ได้รับระหว่างทาง
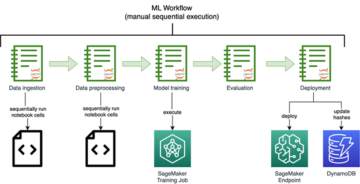
ภาพรวมโซลูชัน
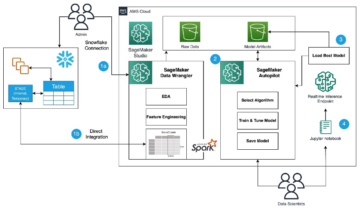
ไดอะแกรมต่อไปนี้แสดงสถาปัตยกรรมแพลตฟอร์ม ML

การออกแบบโซลูชันระดับสูง
แพลตฟอร์ม ML นี้ได้รับการจินตนาการและออกแบบให้ใช้งานโดยรุ่นต่างๆ ในที่เก็บรหัสต่างๆ ทีมของเราใช้ GitLab เป็นเครื่องมือจัดการซอร์สโค้ดเพื่อดูแลที่เก็บโค้ดทั้งหมด การเปลี่ยนแปลงใด ๆ ในซอร์สโค้ดที่เก็บแบบจำลองจะถูกรวมเข้าด้วยกันอย่างต่อเนื่องโดยใช้ Gitlab CIซึ่งเรียกใช้เวิร์กโฟลว์ที่ตามมาในไปป์ไลน์ (การฝึกโมเดล การประเมิน และการปรับใช้)
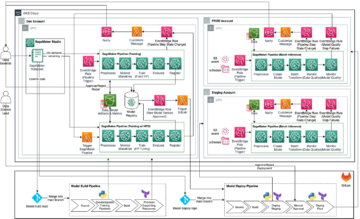
แผนภาพสถาปัตยกรรมต่อไปนี้แสดงเวิร์กโฟลว์แบบ end-to-end และส่วนประกอบที่เกี่ยวข้องในไปป์ไลน์ MLOps ของเรา

เวิร์กโฟลว์แบบครบวงจร
ไปป์ไลน์การฝึกอบรม การประเมิน และการปรับใช้โมเดล ML ได้รับการจัดการโดยใช้ Amazon MWAA ซึ่งเรียกว่า กราฟ Acyclic กำกับ (แดก). DAG คือการรวบรวมงานต่างๆ เข้าด้วยกัน โดยจัดระเบียบด้วยการขึ้นต่อกันและความสัมพันธ์เพื่อบอกว่าควรทำงานอย่างไร
ในระดับสูง สถาปัตยกรรมของโซลูชันประกอบด้วยองค์ประกอบหลักสามส่วน:
- ที่เก็บรหัสไปป์ไลน์ ML
- การฝึกอบรมแบบจำลอง ML และไปป์ไลน์การประเมิน
- ไปป์ไลน์การปรับใช้โมเดล ML
เรามาคุยกันถึงวิธีการจัดการส่วนประกอบต่างๆ เหล่านี้และวิธีที่พวกมันโต้ตอบกัน
ที่เก็บรหัสไปป์ไลน์ ML
หลังจากที่ Repo โมเดลผสานรวม Repo MLOps เป็นไปป์ไลน์ดาวน์สตรีม และนักวิทยาศาสตร์ด้านข้อมูลคอมมิตโค้ดใน Repo โมเดลของตน นักวิ่ง GitLab จะทำการตรวจสอบและทดสอบโค้ดมาตรฐานที่กำหนดไว้ใน repo นั้น และทริกเกอร์ไปป์ไลน์ MLOps ตามการเปลี่ยนแปลงโค้ด เราใช้ไปป์ไลน์หลายโครงการของ Gitlab เพื่อเปิดใช้งานทริกเกอร์นี้ใน repos ต่างๆ
ไปป์ไลน์ MLOps GitLab รันสเตจชุดหนึ่ง ดำเนินการตรวจสอบรหัสพื้นฐานโดยใช้ pylint จัดทำแพ็คเกจการฝึกอบรมและรหัสอนุมานของโมเดลภายในอิมเมจ Docker และเผยแพร่อิมเมจคอนเทนเนอร์ไปยัง การลงทะเบียน Amazon Elastic Container (อีซีอาร์ของอเมซอน) Amazon ECR เป็นรีจีสทรีคอนเทนเนอร์ที่มีการจัดการเต็มรูปแบบซึ่งให้บริการโฮสติ้งประสิทธิภาพสูง คุณจึงปรับใช้อิมเมจและอาร์ติแฟกต์ของแอปพลิเคชันได้อย่างวางใจได้จากทุกที่
การฝึกอบรมแบบจำลอง ML และไปป์ไลน์การประเมิน
หลังจากเผยแพร่ภาพแล้ว จะทำให้เกิดการฝึกอบรมและการประเมินผล อาปาเช่แอร์โฟลว์ ท่อส่งผ่านทาง AWS แลมบ์ดา การทำงาน. Lambda เป็นบริการประมวลผลแบบไร้เซิร์ฟเวอร์ที่ขับเคลื่อนด้วยเหตุการณ์ ซึ่งช่วยให้คุณเรียกใช้โค้ดสำหรับแอปพลิเคชันหรือบริการแบ็คเอนด์ทุกประเภทโดยไม่ต้องจัดเตรียมหรือจัดการเซิร์ฟเวอร์
หลังจากทริกเกอร์ไปป์ไลน์สำเร็จแล้ว จะดำเนินการฝึกอบรมและประเมินผล DAG ซึ่งจะเริ่มต้นการฝึกอบรมแบบจำลองใน SageMaker ในตอนท้ายของไปป์ไลน์การฝึกอบรมนี้ กลุ่มผู้ใช้ที่ระบุจะได้รับการแจ้งเตือนพร้อมผลการประเมินการฝึกอบรมและแบบจำลองทางอีเมล บริการแจ้งเตือนแบบง่ายของ Amazon (Amazon SNS) และ Slack Amazon SNS เป็นบริการ Pub/Sub ที่มีการจัดการเต็มรูปแบบสำหรับการส่งข้อความ A2A และ A2P
หลังจากการวิเคราะห์ผลการประเมินอย่างพิถีพิถัน นักวิทยาศาสตร์ข้อมูลหรือวิศวกร ML สามารถปรับใช้โมเดลใหม่ได้หากประสิทธิภาพของโมเดลที่ผ่านการฝึกอบรมใหม่ดีกว่าเมื่อเทียบกับเวอร์ชันก่อนหน้า ประสิทธิภาพของโมเดลได้รับการประเมินตามเมตริกเฉพาะโมเดล (เช่น คะแนน F1, MSE หรือเมทริกซ์ความสับสน)
ไปป์ไลน์การปรับใช้โมเดล ML
ในการเริ่มการปรับใช้ ผู้ใช้จะเริ่มงาน GitLab ที่ทริกเกอร์ Deployment DAG ผ่านฟังก์ชัน Lambda เดียวกัน หลังจากที่ไพพ์ไลน์ทำงานสำเร็จ จะสร้างหรืออัปเดตจุดสิ้นสุดของ SageMaker ด้วยโมเดลใหม่ นอกจากนี้ยังส่งการแจ้งเตือนพร้อมรายละเอียดปลายทางทางอีเมลโดยใช้ Amazon SNS และ Slack
ในกรณีที่เกิดความล้มเหลวในไปป์ไลน์ตัวใดตัวหนึ่ง ผู้ใช้จะได้รับแจ้งผ่านช่องทางการสื่อสารเดียวกัน
SageMaker นำเสนอการอนุมานตามเวลาจริงซึ่งเหมาะอย่างยิ่งสำหรับการอนุมานปริมาณงานที่ต้องการเวลาแฝงต่ำและปริมาณงานสูง ตำแหน่งข้อมูลเหล่านี้ได้รับการจัดการอย่างเต็มรูปแบบ โหลดบาลานซ์ และปรับขนาดอัตโนมัติ และสามารถนำไปใช้ใน Availability Zone หลายแห่งเพื่อความพร้อมใช้งานสูง ไปป์ไลน์ของเราสร้างจุดสิ้นสุดสำหรับโมเดลหลังจากทำงานสำเร็จ
ในส่วนต่อไปนี้ เราจะขยายส่วนประกอบต่างๆ และลงลึกในรายละเอียด
GitLab: โมเดลแพ็คเกจและไปป์ไลน์ทริกเกอร์
เราใช้ GitLab เป็นที่เก็บโค้ดของเราและสำหรับไปป์ไลน์ในการจัดแพ็คเกจโค้ดโมเดลและทริกเกอร์ Airflow DAG ที่ดาวน์สตรีม
ไปป์ไลน์หลายโครงการ
คุณลักษณะไปป์ไลน์ GitLab แบบหลายโปรเจ็กต์ถูกใช้โดยไปป์ไลน์หลัก (อัปสตรีม) เป็นที่เก็บโมเดลและไปป์ไลน์ย่อย (ดาวน์สตรีม) เป็นที่เก็บ MLOps แต่ละ repo จะรักษา .gitlab-ci.yml และบล็อกโค้ดต่อไปนี้ที่เปิดใช้งานในไปป์ไลน์อัปสตรีมจะทริกเกอร์ไปป์ไลน์ MLOps ดาวน์สตรีม
ไปป์ไลน์อัปสตรีมส่งรหัสโมเดลไปยังไปป์ไลน์ดาวน์สตรีมที่งานบรรจุภัณฑ์และการเผยแพร่ CI ถูกทริกเกอร์ โค้ดเพื่อบรรจุโค้ดโมเดลและเผยแพร่ไปยัง Amazon ECR ได้รับการดูแลและจัดการโดยไปป์ไลน์ MLOps มันส่งตัวแปรเช่น ACCESS_TOKEN (สามารถสร้างภายใต้ การตั้งค่า, ทางเข้า), JOB_ID (เพื่อเข้าถึงสิ่งประดิษฐ์อัปสตรีม) และตัวแปร $CI_PROJECT_ID (รหัสโครงการของ repo โมเดล) เพื่อให้ไปป์ไลน์ MLOps สามารถเข้าถึงไฟล์โค้ดโมเดลได้ กับ สิ่งประดิษฐ์งาน คุณสมบัติจาก Gitlab repo ดาวน์สตรีมเข้าถึงสิ่งประดิษฐ์ระยะไกลโดยใช้คำสั่งต่อไปนี้:
repo โมเดลสามารถใช้ downstream ไปป์ไลน์สำหรับหลายโมเดลจาก repo เดียวกันโดยขยายระยะที่ทริกเกอร์โดยใช้ ขยาย คำหลักจาก GitLab ซึ่งช่วยให้คุณใช้การกำหนดค่าเดียวกันซ้ำได้ในขั้นตอนต่างๆ
หลังจากเผยแพร่อิมเมจโมเดลไปยัง Amazon ECR ไปป์ไลน์ MLOps จะทริกเกอร์ไปป์ไลน์การฝึกอบรม Amazon MWAA โดยใช้ Lambda หลังจากการอนุมัติของผู้ใช้ จะทริกเกอร์การปรับใช้โมเดลไปป์ไลน์ Amazon MWAA โดยใช้ฟังก์ชัน Lambda เดียวกัน
การกำหนดเวอร์ชันความหมายและผ่านเวอร์ชันดาวน์สตรีม
เราพัฒนาโค้ดแบบกำหนดเองสำหรับอิมเมจ ECR เวอร์ชันและโมเดล SageMaker ไปป์ไลน์ MLOps จัดการตรรกะการกำหนดเวอร์ชันเชิงความหมายสำหรับอิมเมจและโมเดลโดยเป็นส่วนหนึ่งของสเตจที่โค้ดโมเดลได้รับการคอนเทนเนอร์ และส่งต่อเวอร์ชันไปยังสเตจภายหลังในฐานะอาร์ติแฟกต์
การอบรมขึ้นใหม่
เนื่องจากการฝึกซ้ำเป็นส่วนสำคัญของวงจรชีวิต ML เราจึงนำความสามารถในการฝึกซ้ำมาใช้เป็นส่วนหนึ่งของไปป์ไลน์ของเรา เราใช้ SageMaker list-models API เพื่อระบุว่ากำลังฝึกใหม่หรือไม่โดยอิงจากหมายเลขเวอร์ชันการฝึกซ้ำของโมเดลและการประทับเวลา
เราจัดการกำหนดการรายวันของขั้นตอนการฝึกอบรมใหม่โดยใช้ ไปป์ไลน์กำหนดการของ GitLab.
Terraform: การตั้งค่าโครงสร้างพื้นฐาน
นอกจากคลัสเตอร์ Amazon MWAA, ที่เก็บ ECR, ฟังก์ชัน Lambda และหัวข้อ SNS แล้ว โซลูชันนี้ยังใช้ AWS Identity และการจัดการการเข้าถึง (IAM) บทบาท ผู้ใช้ และนโยบาย บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon ที่ฝากข้อมูล (Amazon S3) และ อเมซอน คลาวด์วอตช์ ผู้ส่งบันทึก
เราใช้ terraform เพื่อใช้โครงสร้างพื้นฐานเป็นรหัส เมื่อใดก็ตามที่จำเป็นต้องมีการอัปเดต infra การเปลี่ยนแปลงโค้ดจะทริกเกอร์ไปป์ไลน์ GitLab CI ที่เราตั้งค่าไว้ ซึ่งจะตรวจสอบความถูกต้องและนำการเปลี่ยนแปลงไปใช้ในสภาพแวดล้อมต่างๆ (เช่น การเพิ่มสิทธิ์ให้กับนโยบาย IAM ในบัญชี dev, stage และ prod)
Amazon ECR, Amazon S3 และ Lambda: การอำนวยความสะดวกไปป์ไลน์
เราใช้บริการหลักดังต่อไปนี้เพื่ออำนวยความสะดวกในไปป์ไลน์ของเรา:
- อเมซอน ECR – เพื่อรักษาและอนุญาตให้เรียกใช้อิมเมจคอนเทนเนอร์โมเดลได้อย่างสะดวก เราติดแท็กด้วยเวอร์ชันความหมายและอัปโหลดไปยังที่เก็บ ECR ที่ตั้งค่าตาม
${project_name}/${model_name}ผ่าน Terraform สิ่งนี้ทำให้ชั้นของการแยกระหว่างโมเดลต่างๆ ดีขึ้น และช่วยให้เราสามารถใช้อัลกอริทึมที่กำหนดเองและจัดรูปแบบคำขอการอนุมานและการตอบสนองเพื่อรวมข้อมูลรายการโมเดลที่ต้องการ (ชื่อโมเดล เวอร์ชัน เส้นทางข้อมูลการฝึกอบรม และอื่นๆ) - Amazon S3 – เราใช้บัคเก็ต S3 เพื่อคงข้อมูลการฝึกโมเดล สิ่งประดิษฐ์โมเดลที่ผ่านการฝึกอบรมต่อโมเดล Airflow DAG และข้อมูลเพิ่มเติมอื่นๆ ที่ท่อส่งต้องการ
- แลมบ์ดา – เนื่องจากคลัสเตอร์ Airflow ของเราถูกปรับใช้ใน VPC แยกต่างหากเพื่อความปลอดภัย จึงไม่สามารถเข้าถึง DAG ได้โดยตรง ดังนั้นเราจึงใช้ฟังก์ชัน Lambda ซึ่งดูแลด้วย Terraform เพื่อทริกเกอร์ DAG ใดๆ ที่ระบุโดยชื่อ DAG ด้วยการตั้งค่า IAM ที่เหมาะสม งาน GitLab CI จะทริกเกอร์ฟังก์ชัน Lambda ซึ่งส่งผ่านการกำหนดค่าลงไปจนถึงการฝึกอบรมที่ขอหรือ DAG การปรับใช้
Amazon MWAA: การฝึกอบรมและไปป์ไลน์การปรับใช้
ดังที่ได้กล่าวไว้ก่อนหน้านี้ เราใช้ Amazon MWAA เพื่อจัดเตรียมการฝึกอบรมและไปป์ไลน์การปรับใช้ เราใช้ตัวดำเนินการ SageMaker ที่มีอยู่ใน แพ็คเกจผู้ให้บริการ Amazon สำหรับ Airflow เพื่อรวมเข้ากับ SageMaker (เพื่อหลีกเลี่ยงการสร้างเทมเพลต jinja)
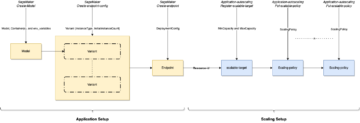
เราใช้ตัวดำเนินการต่อไปนี้ในขั้นตอนการฝึกอบรมนี้ (แสดงในแผนภาพเวิร์กโฟลว์ต่อไปนี้):

ท่อส่งฝึกอบรม กปน
เราใช้ตัวดำเนินการต่อไปนี้ในขั้นตอนการปรับใช้ (แสดงในไดอะแกรมเวิร์กโฟลว์ต่อไปนี้):

ไปป์ไลน์การปรับใช้โมเดล
เราใช้ Slack และ Amazon SNS เพื่อเผยแพร่ข้อความแสดงข้อผิดพลาด/ข้อความสำเร็จและผลการประเมินในทั้งสองไปป์ไลน์ Slack มีตัวเลือกมากมายในการปรับแต่งข้อความ รวมถึงสิ่งต่อไปนี้:
- SnsPublishOperator - เราใช้ SnsPublishOperator เพื่อส่งการแจ้งเตือนสำเร็จ/ล้มเหลวไปยังอีเมลของผู้ใช้
- API หย่อน - เราได้สร้าง URL ของเว็บฮุคที่เข้ามา เพื่อรับการแจ้งเตือนไปป์ไลน์ไปยังช่องที่ต้องการ
CloudWatch และ VMware Wavefront: การตรวจสอบและการบันทึก
เราใช้แดชบอร์ด CloudWatch เพื่อกำหนดค่าการตรวจสอบและการบันทึกปลายทาง ช่วยให้เห็นภาพและติดตามเมตริกการดำเนินงานและประสิทธิภาพของแบบจำลองต่างๆ ที่เฉพาะเจาะจงสำหรับแต่ละโครงการ นอกเหนือไปจากนโยบายการปรับขนาดอัตโนมัติที่ตั้งค่าไว้เพื่อติดตามนโยบายบางส่วนแล้ว เรายังตรวจสอบการเปลี่ยนแปลงในการใช้งาน CPU และหน่วยความจำ คำขอต่อวินาที เวลาตอบสนอง และเมตริกโมเดลอย่างต่อเนื่อง
CloudWatch ยังรวมเข้ากับแดชบอร์ด VMware Tanzu Wavefront เพื่อให้สามารถแสดงภาพเมตริกสำหรับจุดสิ้นสุดของแบบจำลอง ตลอดจนบริการอื่นๆ ในระดับโครงการ
ผลประโยชน์ทางธุรกิจและสิ่งต่อไป
ไปป์ไลน์ ML มีความสำคัญอย่างยิ่งต่อบริการและคุณสมบัติ ML ในโพสต์นี้ เราได้กล่าวถึงกรณีการใช้งาน ML แบบ end-to-end โดยใช้ความสามารถจาก AWS เราสร้างไปป์ไลน์แบบกำหนดเองโดยใช้ SageMaker และ Amazon MWAA ซึ่งเราสามารถนำมาใช้ซ้ำได้ในโครงการและแบบจำลองต่างๆ และทำให้วงจรชีวิตของ ML เป็นอัตโนมัติ ซึ่งลดเวลาจากการฝึกแบบจำลองไปจนถึงการปรับใช้จริงให้เหลือเพียง 10 นาที
ด้วยการเปลี่ยนภาระของวงจรชีวิต ML ไปเป็น SageMaker ทำให้มีโครงสร้างพื้นฐานที่ปรับให้เหมาะสมและปรับขนาดได้สำหรับการฝึกโมเดลและการปรับใช้ การแสดงแบบจำลองด้วย SageMaker ช่วยให้เราทำการคาดการณ์แบบเรียลไทม์ด้วยเวลาแฝงระดับมิลลิวินาทีและความสามารถในการตรวจสอบ เราใช้ Terraform เพื่อความสะดวกในการติดตั้งและจัดการโครงสร้างพื้นฐาน
ขั้นตอนต่อไปสำหรับไปป์ไลน์นี้คือการปรับปรุงไปป์ไลน์การฝึกโมเดลด้วยความสามารถในการฝึกซ้ำ ไม่ว่าจะเป็นตามกำหนดเวลาหรือตามการตรวจจับการเลื่อนของโมเดล สนับสนุนการปรับใช้เงาหรือการทดสอบ A/B เพื่อการปรับใช้โมเดลที่รวดเร็วและผ่านเกณฑ์ และการติดตามสายเลือด ML เรายังวางแผนที่จะประเมิน ท่อส่ง Amazon SageMaker เนื่องจากตอนนี้รองรับการรวม GitLab แล้ว
บทเรียนที่ได้รับ
ในการสร้างโซลูชันนี้ เราได้เรียนรู้ว่าคุณควรสรุปแต่เนิ่นๆ แต่อย่าสรุปมากเกินไป เมื่อเราออกแบบสถาปัตยกรรมเสร็จในขั้นแรก เราพยายามสร้างและบังคับใช้โค้ดเทมเพลทสำหรับโค้ดโมเดลเพื่อเป็นแนวทางปฏิบัติที่ดีที่สุด อย่างไรก็ตาม ในช่วงเริ่มต้นของกระบวนการพัฒนานั้น เทมเพลตนั้นกว้างเกินไปหรือมีรายละเอียดมากเกินไปที่จะใช้ซ้ำได้สำหรับโมเดลในอนาคต
หลังจากส่งมอบโมเดลแรกผ่านไปป์ไลน์ เทมเพลตก็ออกมาเป็นธรรมชาติตามข้อมูลเชิงลึกจากงานก่อนหน้าของเรา ไปป์ไลน์ไม่สามารถทำทุกอย่างได้ตั้งแต่วันแรก
การทดลองแบบจำลองและการผลิตมักมีข้อกำหนดที่แตกต่างกันมาก (หรือบางครั้งก็ขัดแย้งกัน) สิ่งสำคัญคือต้องสร้างความสมดุลให้กับข้อกำหนดเหล่านี้ตั้งแต่เริ่มต้นในฐานะทีมและจัดลำดับความสำคัญตามลำดับ
นอกจากนี้ คุณอาจไม่ต้องการทุกฟีเจอร์ของบริการ การใช้คุณสมบัติที่จำเป็นจากบริการและการออกแบบโมดูลเป็นกุญแจสำคัญในการพัฒนาที่มีประสิทธิภาพมากขึ้นและไปป์ไลน์ที่ยืดหยุ่น
สรุป
ในโพสต์นี้ เราแสดงวิธีที่เราสร้างโซลูชัน MLOps โดยใช้ SageMaker และ Amazon MWAA ที่ทำให้กระบวนการปรับใช้โมเดลกับการผลิตเป็นไปโดยอัตโนมัติโดยมีการแทรกแซงเพียงเล็กน้อยจากนักวิทยาศาสตร์ข้อมูล เราสนับสนุนให้คุณประเมินบริการต่างๆ ของ AWS เช่น SageMaker, Amazon MWAA, Amazon S3 และ Amazon ECR เพื่อสร้างโซลูชัน MLOps ที่สมบูรณ์
*Apache, Apache Airflow และ Airflow เป็นเครื่องหมายการค้าจดทะเบียนหรือเครื่องหมายการค้าของ มูลนิธิซอฟต์แวร์ Apache ในสหรัฐอเมริกาและ/หรือประเทศอื่นๆ
เกี่ยวกับผู้เขียน
 ดีพัค เม็ทเทม เป็นผู้จัดการฝ่ายวิศวกรรมอาวุโสใน VMware, Carbon Black Unit เขาและทีมของเขาทำงานเกี่ยวกับการสร้างแอปพลิเคชันและบริการแบบสตรีมมิ่งที่มีความพร้อมใช้งานสูง ปรับขนาดได้ และยืดหยุ่น เพื่อนำโซลูชันที่ใช้การเรียนรู้ด้วยเครื่องของลูกค้ามาใช้ในแบบเรียลไทม์ เขาและทีมของเขายังรับผิดชอบในการสร้างเครื่องมือที่จำเป็นสำหรับนักวิทยาศาสตร์ข้อมูลในการสร้าง ฝึกฝน ปรับใช้ และตรวจสอบความถูกต้องของโมเดล ML ในการผลิต
ดีพัค เม็ทเทม เป็นผู้จัดการฝ่ายวิศวกรรมอาวุโสใน VMware, Carbon Black Unit เขาและทีมของเขาทำงานเกี่ยวกับการสร้างแอปพลิเคชันและบริการแบบสตรีมมิ่งที่มีความพร้อมใช้งานสูง ปรับขนาดได้ และยืดหยุ่น เพื่อนำโซลูชันที่ใช้การเรียนรู้ด้วยเครื่องของลูกค้ามาใช้ในแบบเรียลไทม์ เขาและทีมของเขายังรับผิดชอบในการสร้างเครื่องมือที่จำเป็นสำหรับนักวิทยาศาสตร์ข้อมูลในการสร้าง ฝึกฝน ปรับใช้ และตรวจสอบความถูกต้องของโมเดล ML ในการผลิต
 มหิมา อัควาล เป็นวิศวกรแมชชีนเลิร์นนิงใน VMware หน่วยคาร์บอนแบล็ค
มหิมา อัควาล เป็นวิศวกรแมชชีนเลิร์นนิงใน VMware หน่วยคาร์บอนแบล็ค
เธอทำงานเกี่ยวกับการออกแบบ สร้าง และพัฒนาส่วนประกอบหลักและสถาปัตยกรรมของแพลตฟอร์มแมชชีนเลิร์นนิงสำหรับ VMware CB SBU
 วัมชี กฤษณะ เอนาโบธาลา เป็น Sr. Applied AI Specialist Architect ที่ AWS เขาทำงานร่วมกับลูกค้าจากภาคส่วนต่างๆ เพื่อเร่งความเร็วของข้อมูลที่มีผลกระทบสูง การวิเคราะห์ และการเรียนรู้ของเครื่อง เขาหลงใหลเกี่ยวกับระบบคำแนะนำ, NLP และด้านคอมพิวเตอร์วิทัศน์ใน AI และ ML นอกเวลางาน Vamshi เป็นผู้ที่ชื่นชอบ RC สร้างอุปกรณ์ RC (เครื่องบิน รถยนต์ และโดรน) และยังชอบทำสวนอีกด้วย
วัมชี กฤษณะ เอนาโบธาลา เป็น Sr. Applied AI Specialist Architect ที่ AWS เขาทำงานร่วมกับลูกค้าจากภาคส่วนต่างๆ เพื่อเร่งความเร็วของข้อมูลที่มีผลกระทบสูง การวิเคราะห์ และการเรียนรู้ของเครื่อง เขาหลงใหลเกี่ยวกับระบบคำแนะนำ, NLP และด้านคอมพิวเตอร์วิทัศน์ใน AI และ ML นอกเวลางาน Vamshi เป็นผู้ที่ชื่นชอบ RC สร้างอุปกรณ์ RC (เครื่องบิน รถยนต์ และโดรน) และยังชอบทำสวนอีกด้วย
 ซาฮิล ธาปาร์ เป็นสถาปนิก Enterprise Solutions เขาทำงานร่วมกับลูกค้าเพื่อช่วยสร้างแอปพลิเคชันที่พร้อมใช้งานสูง ปรับขนาดได้ และยืดหยุ่นบน AWS Cloud ปัจจุบันเขามุ่งเน้นไปที่โซลูชันคอนเทนเนอร์และแมชชีนเลิร์นนิง
ซาฮิล ธาปาร์ เป็นสถาปนิก Enterprise Solutions เขาทำงานร่วมกับลูกค้าเพื่อช่วยสร้างแอปพลิเคชันที่พร้อมใช้งานสูง ปรับขนาดได้ และยืดหยุ่นบน AWS Cloud ปัจจุบันเขามุ่งเน้นไปที่โซลูชันคอนเทนเนอร์และแมชชีนเลิร์นนิง
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :เป็น
- $ ขึ้น
- 1
- 10
- 100
- 7
- 8
- a
- เกี่ยวกับเรา
- เร่งความเร็ว
- เข้า
- Accessed
- ตาม
- บัญชี
- ประสบความสำเร็จ
- ข้าม
- วัฏจักร
- นอกจากนี้
- เพิ่มเติม
- ข้อมูลเพิ่มเติม
- หลังจาก
- กับ
- AI
- อัลกอริทึม
- ทั้งหมด
- ช่วยให้
- อเมซอน
- อเมซอน SageMaker
- การวิเคราะห์
- การวิเคราะห์
- และ
- ทุกแห่ง
- อาปาเช่
- API
- การใช้งาน
- การใช้งาน
- ประยุกต์
- AI ประยุกต์
- การอนุมัติ
- สถาปัตยกรรม
- เป็น
- พื้นที่
- AS
- แง่มุม
- At
- การโจมตี
- การเขียน
- รถยนต์
- อัตโนมัติ
- โดยอัตโนมัติ
- ความพร้อมใช้งาน
- ใช้ได้
- หลีกเลี่ยง
- AWS
- แบ็กเอนด์
- ยอดคงเหลือ
- ตาม
- ขั้นพื้นฐาน
- BE
- เพราะ
- การเริ่มต้น
- ประโยชน์ที่ได้รับ
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- Black
- ปิดกั้น
- สาขา
- นำมาซึ่ง
- สร้าง
- การก่อสร้าง
- สร้าง
- ภาระ
- by
- CAN
- ไม่ได้
- ความสามารถในการ
- คาร์บอน
- รถยนต์
- กรณี
- CB
- บาง
- การเปลี่ยนแปลง
- ช่อง
- เด็ก
- เลือก
- เมฆ
- Cluster
- รหัส
- ชุด
- การสื่อสาร
- เมื่อเทียบกับ
- สมบูรณ์
- ส่วนประกอบ
- คำนวณ
- คอมพิวเตอร์
- วิสัยทัศน์คอมพิวเตอร์
- ปฏิบัติ
- องค์ประกอบ
- การกำหนดค่า
- ขัดแย้ง
- ความสับสน
- การพิจารณา
- บริโภค
- ถูกใช้
- ภาชนะ
- ภาชนะบรรจุ
- อย่างต่อเนื่อง
- สะดวกสบาย
- แกน
- ได้
- ประเทศ
- ซีพียู
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- การสร้าง
- วิกฤติ
- สำคัญมาก
- ขณะนี้
- ประเพณี
- ลูกค้า
- ปรับแต่ง
- cyberattacks
- DAG
- ประจำวัน
- หน้าปัด
- ข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- วัน
- กำหนด
- การส่งมอบ
- ปรับใช้
- นำไปใช้
- ปรับใช้
- การใช้งาน
- การใช้งาน
- Deploys
- ออกแบบ
- ได้รับการออกแบบ
- การออกแบบ
- รายละเอียด
- รายละเอียด
- การตรวจพบ
- dev
- พัฒนา
- ที่กำลังพัฒนา
- พัฒนาการ
- ต่าง
- โดยตรง
- สนทนา
- กล่าวถึง
- นักเทียบท่า
- Dont
- ลง
- โดรน
- แต่ละ
- ก่อน
- ก่อน
- สะดวกในการใช้
- ที่มีประสิทธิภาพ
- ทั้ง
- อีเมล
- กากกะรุน
- ทำให้สามารถ
- เปิดการใช้งาน
- ช่วยให้
- ส่งเสริม
- จบสิ้น
- ปลายทาง
- วิศวกร
- ชั้นเยี่ยม
- Enterprise
- โซลูชั่นองค์กร
- คนที่กระตือรือร้น
- สภาพแวดล้อม
- อุปกรณ์
- จำเป็น
- อีเธอร์ (ETH)
- ประเมินค่า
- ประเมิน
- การประเมินการ
- การประเมินผล
- การประเมินผล
- แม้
- เหตุการณ์
- ทุกๆ
- ทุกอย่าง
- ตัวอย่าง
- แสดง
- การขยาย
- f1
- อำนวยความสะดวก
- ความล้มเหลว
- ไกล
- เร็วขึ้น
- ลักษณะ
- คุณสมบัติ
- สองสาม
- ไฟล์
- ชื่อจริง
- มีความยืดหยุ่น
- โฟกัส
- มุ่งเน้น
- มุ่งเน้นไปที่
- ดังต่อไปนี้
- สำหรับ
- รูป
- ราคาเริ่มต้นที่
- เต็ม
- เต็มสเปกตรัม
- อย่างเต็มที่
- ฟังก์ชัน
- ฟังก์ชั่น
- ต่อไป
- อนาคต
- สร้าง
- ได้รับ
- ดี
- บัญชีกลุ่ม
- มี
- มี
- ช่วย
- ช่วย
- จะช่วยให้
- จุดสูง
- ประสิทธิภาพสูง
- อย่างสูง
- โฮสติ้ง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- อย่างไรก็ตาม
- HTML
- ที่ http
- HTTPS
- AMI
- ID
- ในอุดมคติ
- ระบุ
- แยกแยะ
- เอกลักษณ์
- ภาพ
- ภาพ
- การดำเนินการ
- การดำเนินงาน
- การดำเนินการ
- in
- ประกอบด้วย
- รวมถึง
- รวมทั้ง
- ข้อมูล
- โครงสร้างพื้นฐาน
- ความคิดริเริ่ม
- ข้อมูลเชิงลึก
- รวบรวม
- แบบบูรณาการ
- รวม
- บูรณาการ
- โต้ตอบ
- การแทรกแซง
- จะเรียก
- ร่วมมือ
- ความเหงา
- IT
- ITS
- การสัมภาษณ์
- งาน
- jpg
- เก็บ
- คีย์
- กุญแจ
- ความแอบแฝง
- ชั้น
- ได้เรียนรู้
- การเรียนรู้
- บทเรียน
- บทเรียนที่ได้รับ
- ช่วยให้
- ชั้น
- วงจรชีวิต
- กดไลก์
- น้อย
- โหลด
- ต่ำ
- เครื่อง
- เรียนรู้เครื่อง
- หลัก
- เก็บรักษา
- รักษา
- การบำรุงรักษา
- ทำ
- จัดการ
- การจัดการ
- การจัดการ
- ผู้จัดการ
- จัดการ
- การจัดการ
- คู่มือ
- มดลูก
- หน่วยความจำ
- กล่าวถึง
- ข้อความ
- ส่งข้อความ
- ตัวชี้วัด
- อาจ
- มิลลิวินาที
- นาที
- ML
- ม.ป.ป
- แบบ
- โมเดล
- ทันสมัย
- การตรวจสอบ
- การตรวจสอบ
- ข้อมูลเพิ่มเติม
- มีประสิทธิภาพมากขึ้น
- หลาย
- ชื่อ
- เป็นธรรมชาติ
- จำเป็น
- จำเป็นต้อง
- ใหม่
- ถัดไป
- NLP
- สัญญาณรบกวน
- การประกาศ
- การแจ้งเตือน
- จำนวน
- of
- การเสนอ
- เสนอ
- on
- ONE
- การดำเนินงาน
- ผู้ประกอบการ
- การปรับให้เหมาะสม
- Options
- บงการ
- Organized
- อื่นๆ
- ด้านนอก
- ทั้งหมด
- แพ็คเกจ
- แพคเกจ
- บรรจุภัณฑ์
- ส่วนหนึ่ง
- ผ่าน
- ที่ผ่านไป
- หลงใหล
- เส้นทาง
- การปฏิบัติ
- การอนุญาต
- ท่อ
- แผนการ
- Planes
- เวที
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- นโยบาย
- นโยบาย
- โพสต์
- การปฏิบัติ
- การคาดการณ์
- ก่อน
- จัดลำดับความสำคัญ
- กระบวนการ
- ผลิตภัณฑ์
- การผลิต
- โครงการ
- โครงการ
- เหมาะสม
- การป้องกัน
- ให้
- ผู้จัดหา
- ให้
- ประกาศ
- การตีพิมพ์
- เผยแพร่
- การประกาศ
- วัตถุประสงค์
- มีคุณสมบัติ
- พิสัย
- เรียลไทม์
- แนะนำ
- ลดลง
- เรียกว่า
- ลงทะเบียน
- รีจิสทรี
- ความสัมพันธ์
- รีโมท
- มีชื่อเสียง
- กรุ
- ร้องขอ
- การร้องขอ
- จำเป็นต้องใช้
- ความต้องการ
- การวิจัย
- ยืดหยุ่น
- คำตอบ
- รับผิดชอบ
- ผลสอบ
- การอบรมขึ้นใหม่
- นำมาใช้ใหม่
- บทบาท
- วิ่ง
- ทางวิ่ง
- sagemaker
- เดียวกัน
- ที่ปรับขนาดได้
- ปรับ
- กำหนด
- ที่กำหนดไว้
- นักวิทยาศาสตร์
- นักวิทยาศาสตร์
- ที่สอง
- ส่วน
- ภาค
- ความปลอดภัย
- ระดับอาวุโส
- แยก
- serverless
- เซิร์ฟเวอร์
- บริการ
- บริการ
- การให้บริการ
- ชุด
- การติดตั้ง
- เงา
- ขยับ
- น่า
- แสดง
- ง่าย
- หย่อน
- So
- จนถึงตอนนี้
- ซอฟต์แวร์
- ทางออก
- โซลูชัน
- บาง
- แหล่ง
- รหัสแหล่งที่มา
- ผู้เชี่ยวชาญ
- โดยเฉพาะ
- ที่ระบุไว้
- สเปกตรัม
- ไฟฉายสว่างจ้า
- ระยะ
- ขั้นตอน
- มาตรฐาน
- เริ่มต้น
- เริ่มต้น
- สหรัฐอเมริกา
- ขั้นตอน
- การเก็บรักษา
- กลยุทธ์
- ที่พริ้ว
- เพรียวลม
- ภายหลัง
- ประสบความสำเร็จ
- อย่างเช่น
- สนับสนุน
- ที่สนับสนุน
- พื้นผิว
- ระบบ
- TAG
- เอา
- งาน
- ทีม
- แม่แบบ
- terraform
- การทดสอบ
- ที่
- พื้นที่
- ของพวกเขา
- พวกเขา
- ดังนั้น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- ภัยคุกคาม
- สาม
- ตลอด
- ตลอด
- ปริมาณงาน
- เวลา
- การประทับเวลา
- ไปยัง
- ร่วมกัน
- เกินไป
- เครื่องมือ
- เครื่องมือ
- ด้านบน
- หัวข้อ
- ลู่
- การติดตาม
- เครื่องหมายการค้า
- การจราจร
- รถไฟ
- ผ่านการฝึกอบรม
- การฝึกอบรม
- เรียก
- ทริกเกอร์
- กลับ
- ภายใต้
- หน่วย
- พร้อมใจกัน
- ประเทศสหรัฐอเมริกา
- การปรับปรุง
- us
- การใช้
- ใช้
- ใช้กรณี
- ผู้ใช้งาน
- ผู้ใช้
- ตรวจสอบความถูกต้อง
- การตรวจสอบ
- ตัวแปร
- ต่างๆ
- รุ่น
- จวน
- วิสัยทัศน์
- เห็นภาพ
- VMware
- ปริมาณ
- ทาง..
- ดี
- อะไร
- ว่า
- ที่
- กว้าง
- ช่วงกว้าง
- กับ
- ภายใน
- ไม่มี
- งาน
- เวิร์กโฟลว์
- ขั้นตอนการทำงาน
- โรงงาน
- จะ
- ลมทะเล
- รหัสไปรษณีย์
- โซน