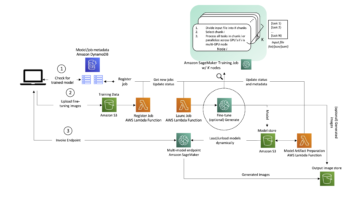
โมเดลหม้อแปลงที่เน้นความสนใจจำนวนมากได้รับผลประโยชน์มหาศาลจากการประมวลผลภาษาธรรมชาติ (NLP) อย่างไรก็ตาม การฝึกอบรมเครือข่ายขนาดยักษ์เหล่านี้ตั้งแต่ต้นต้องใช้ข้อมูลและการคำนวณจำนวนมหาศาล สำหรับชุดข้อมูล NLP ที่มีขนาดเล็กลง กลยุทธ์ที่เรียบง่ายแต่มีประสิทธิภาพคือการใช้หม้อแปลงไฟฟ้าที่ผ่านการฝึกอบรมมาแล้ว ซึ่งมักจะได้รับการฝึกฝนในรูปแบบที่ไม่มีผู้ดูแลบนชุดข้อมูลขนาดใหญ่มาก และปรับแต่งชุดข้อมูลที่สนใจ กอดหน้า มีสวนสัตว์จำลองขนาดใหญ่ของหม้อแปลงไฟฟ้าที่ผ่านการฝึกอบรมมาแล้ว และทำให้เข้าถึงได้ง่ายแม้สำหรับผู้ใช้มือใหม่
อย่างไรก็ตาม การปรับแต่งโมเดลเหล่านี้อย่างละเอียดยังคงต้องการความรู้จากผู้เชี่ยวชาญ เนื่องจากโมเดลเหล่านี้ค่อนข้างอ่อนไหวต่อไฮเปอร์พารามิเตอร์ เช่น อัตราการเรียนรู้หรือขนาดแบทช์ ในโพสต์นี้ เราแสดงวิธีเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์เหล่านี้ด้วยเฟรมเวิร์กโอเพนซอร์ส ไซน์ทูน สำหรับการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์แบบกระจาย (HPO) Syne Tune ช่วยให้เราสามารถค้นหาการกำหนดค่าไฮเปอร์พารามิเตอร์ที่ดีกว่าซึ่งได้รับการปรับปรุงสัมพัทธ์ระหว่าง 1-4% เมื่อเทียบกับไฮเปอร์พารามิเตอร์เริ่มต้นในความนิยม กาว ชุดข้อมูลมาตรฐาน ทางเลือกของรุ่นก่อนการฝึกอบรมนั้นยังถือเป็นไฮเปอร์พารามิเตอร์ ดังนั้น Syne Tune จะเลือกโดยอัตโนมัติ สำหรับปัญหาการจัดประเภทข้อความ สิ่งนี้นำไปสู่การเพิ่มความแม่นยำเพิ่มเติมประมาณ 5% เมื่อเทียบกับแบบจำลองเริ่มต้น อย่างไรก็ตาม เราสามารถทำการตัดสินใจที่ผู้ใช้ต้องทำได้มากขึ้นโดยอัตโนมัติ เราสาธิตสิ่งนี้โดยเปิดเผยประเภทของอินสแตนซ์เป็นไฮเปอร์พารามิเตอร์ที่เราใช้ในการปรับใช้โมเดลในภายหลัง ด้วยการเลือกประเภทอินสแตนซ์ที่เหมาะสม เราจะพบการกำหนดค่าที่ลดต้นทุนและเวลาแฝงได้อย่างเหมาะสม
สำหรับการแนะนำ Syne Tune โปรดดูที่ เรียกใช้งานปรับแต่งไฮเปอร์พารามิเตอร์และสถาปัตยกรรมประสาทด้วย Syne Tune.
การเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์ด้วย Syne Tune
เราจะใช้ กาว ชุดมาตรฐานซึ่งประกอบด้วยชุดข้อมูลเก้าชุดสำหรับงานทำความเข้าใจภาษาธรรมชาติ เช่น การรับรู้ข้อความหรือการวิเคราะห์ความรู้สึก เพื่อการนั้น เราจึงปรับ Hugging Face's run_glue.py สคริปต์การฝึกอบรม ชุดข้อมูล GLUE มาพร้อมกับชุดฝึกอบรมและประเมินผลที่กำหนดไว้ล่วงหน้าพร้อมป้ายกำกับ รวมถึงชุดทดสอบการพักสายที่ไม่มีป้ายกำกับ ดังนั้นเราจึงแบ่งชุดการฝึกออกเป็นชุดการฝึกและการตรวจสอบ (แบ่ง 70%/30%) และใช้ชุดการประเมินเป็นชุดข้อมูลการทดสอบการพัก นอกจากนี้เรายังเพิ่มฟังก์ชันเรียกกลับอื่นให้กับ Trainer API ของ Hugging Face ซึ่งจะรายงานประสิทธิภาพการตรวจสอบหลังจากแต่ละยุคกลับไปยัง Syne Tune ดูรหัสต่อไปนี้:
เราเริ่มต้นด้วยการปรับพารามิเตอร์ไฮเปอร์พารามิเตอร์การฝึกอบรมทั่วไปให้เหมาะสม: อัตราการเรียนรู้ อัตราส่วนการวอร์มอัพเพื่อเพิ่มอัตราการเรียนรู้ และขนาดแบทช์สำหรับการปรับแต่ง BERT ที่ฝึกไว้ล่วงหน้า (bert-เบส-เคส) ซึ่งเป็นโมเดลเริ่มต้นในตัวอย่าง Hugging Face ดูรหัสต่อไปนี้:
เป็นวิธีการ HPO ของเรา เราใช้ อาชาซึ่งสุ่มตัวอย่างการกำหนดค่าไฮเปอร์พารามิเตอร์อย่างสม่ำเสมอโดยสุ่มและหยุดการประเมินการกำหนดค่าที่มีประสิทธิภาพต่ำซ้ำๆ แม้ว่าวิธีการที่ซับซ้อนกว่านั้นจะใช้แบบจำลองความน่าจะเป็นของฟังก์ชันวัตถุประสงค์ เช่น BO หรือ MoBster มีอยู่ แต่เราใช้ ASHA สำหรับโพสต์นี้ เพราะมันมาโดยไม่มีข้อสันนิษฐานใดๆ ในพื้นที่การค้นหา
ในรูปต่อไปนี้ เราเปรียบเทียบการปรับปรุงสัมพัทธ์ในข้อผิดพลาดในการทดสอบกับการกำหนดค่าไฮเปอร์พารามิเตอร์เริ่มต้นของ Hugging Faces
![]()
เพื่อความง่าย เราจำกัดการเปรียบเทียบกับ MRPC, COLA และ STSB แต่เรายังสังเกตเห็นการปรับปรุงที่คล้ายกันสำหรับชุดข้อมูล GLUE อื่นๆ ด้วย สำหรับแต่ละชุดข้อมูล เราเรียกใช้ ASHA บน ml.g4dn.xlarge . เดียว อเมซอน SageMaker อินสแตนซ์ที่มีงบประมาณรันไทม์ 1,800 วินาที ซึ่งสอดคล้องกับการประเมินฟังก์ชันเต็มรูปแบบประมาณ 13, 7 และ 9 รายการในชุดข้อมูลเหล่านี้ตามลำดับ เพื่อพิจารณาการสุ่มที่แท้จริงของกระบวนการฝึกอบรม ตัวอย่างเช่น เกิดจากการสุ่มตัวอย่างแบบกลุ่มย่อย เราเรียกใช้ทั้ง ASHA และการกำหนดค่าเริ่มต้นสำหรับการทำซ้ำห้าครั้งด้วยเมล็ดพันธุ์อิสระสำหรับเครื่องกำเนิดตัวเลขสุ่ม และรายงานค่าเบี่ยงเบนมาตรฐานและค่าเฉลี่ยของ การปรับปรุงสัมพัทธ์ในการทำซ้ำ เราเห็นได้ว่าในชุดข้อมูลทั้งหมด เราสามารถปรับปรุงประสิทธิภาพการคาดการณ์ได้ 1-3% เมื่อเทียบกับประสิทธิภาพของการกำหนดค่าเริ่มต้นที่เลือกมาอย่างดี
อัตโนมัติเลือกรุ่นก่อนการฝึกอบรม
เราสามารถใช้ HPO เพื่อไม่เพียงแต่ค้นหาไฮเปอร์พารามิเตอร์เท่านั้น แต่ยังเลือกแบบจำลองก่อนการฝึกอบรมที่เหมาะสมโดยอัตโนมัติอีกด้วย ทำไมเราต้องการทำเช่นนี้? เนื่องจากไม่มีแบบจำลองใดที่มีประสิทธิภาพเหนือกว่าชุดข้อมูลทั้งหมด เราจึงต้องเลือกแบบจำลองที่เหมาะสมสำหรับชุดข้อมูลเฉพาะ เพื่อแสดงให้เห็นสิ่งนี้ เราประเมินรุ่นหม้อแปลงยอดนิยมหลายรุ่นจาก Hugging Face สำหรับแต่ละชุดข้อมูล เราจัดอันดับแต่ละรุ่นตามประสิทธิภาพการทดสอบ การจัดอันดับในชุดข้อมูล (ดูรูปต่อไปนี้) เปลี่ยนแปลงและไม่ใช่รูปแบบเดียวที่ทำคะแนนสูงสุดในทุกชุดข้อมูล ตามข้อมูลอ้างอิง เรายังแสดงประสิทธิภาพการทดสอบสัมบูรณ์ของแต่ละรุ่นและชุดข้อมูลในรูปต่อไปนี้
ในการเลือกแบบจำลองที่เหมาะสมโดยอัตโนมัติ เราสามารถกำหนดตัวเลือกของแบบจำลองเป็นพารามิเตอร์ตามหมวดหมู่ และเพิ่มสิ่งนี้ลงในพื้นที่การค้นหาไฮเปอร์พารามิเตอร์ของเรา:
แม้ว่าตอนนี้พื้นที่การค้นหาจะใหญ่ขึ้น แต่ก็ไม่ได้หมายความว่าจะเพิ่มประสิทธิภาพได้ยากขึ้นเสมอไป รูปต่อไปนี้แสดงข้อผิดพลาดในการทดสอบของการกำหนดค่าที่สังเกตได้ดีที่สุด (อิงจากข้อผิดพลาดในการตรวจสอบความถูกต้อง) บนชุดข้อมูล MRPC ของ ASHA เมื่อเวลาผ่านไปเมื่อเราค้นหาในพื้นที่เดิม (เส้นสีน้ำเงิน) (ด้วยโมเดล pre-trained ของ BERT-base-cased ) หรือในช่องค้นหาที่เพิ่มใหม่ (เส้นสีส้ม) ด้วยงบประมาณเท่ากัน ASHA สามารถค้นหาการกำหนดค่าไฮเปอร์พารามิเตอร์ที่มีประสิทธิภาพดีกว่ามากในพื้นที่การค้นหาที่ขยายมากกว่าในพื้นที่ที่เล็กกว่า
![]()
เลือกประเภทอินสแตนซ์โดยอัตโนมัติ
ในทางปฏิบัติ เราอาจไม่ได้สนใจแค่การเพิ่มประสิทธิภาพการคาดการณ์เท่านั้น เรายังอาจสนใจเกี่ยวกับวัตถุประสงค์อื่นๆ เช่น เวลาฝึกอบรม ค่าใช้จ่าย (ดอลลาร์) เวลาแฝง หรือตัวชี้วัดความเป็นธรรม เรายังต้องสร้างตัวเลือกอื่นๆ นอกเหนือจากไฮเปอร์พารามิเตอร์ของโมเดล เช่น การเลือกประเภทอินสแตนซ์
แม้ว่าประเภทอินสแตนซ์จะไม่ส่งผลต่อประสิทธิภาพการคาดการณ์ แต่จะมีผลกระทบอย่างมากต่อค่าใช้จ่าย (ดอลลาร์) รันไทม์การฝึกอบรม และเวลาแฝง หลังมีความสำคัญอย่างยิ่งเมื่อมีการปรับใช้โมเดล เราสามารถระบุ HPO ว่าเป็นปัญหาการปรับให้เหมาะสมแบบหลายวัตถุประสงค์ ซึ่งเราตั้งเป้าที่จะเพิ่มประสิทธิภาพหลายวัตถุประสงค์พร้อมกัน อย่างไรก็ตาม ไม่มีโซลูชันเดียวที่ปรับเมตริกทั้งหมดให้เหมาะสมในเวลาเดียวกัน แต่เราตั้งเป้าที่จะค้นหาชุดการกำหนดค่าที่แลกเปลี่ยนวัตถุประสงค์หนึ่งกับอีกวัตถุประสงค์หนึ่งได้อย่างเหมาะสมที่สุด นี้เรียกว่า ชุดพาเรโต้.
เพื่อวิเคราะห์การตั้งค่านี้เพิ่มเติม เราได้เพิ่มตัวเลือกประเภทอินสแตนซ์เป็นไฮเปอร์พารามิเตอร์ตามหมวดหมู่เพิ่มเติมในพื้นที่การค้นหาของเรา:
เราใช้ MO-อาชาซึ่งปรับ ASHA ให้เข้ากับสถานการณ์สมมติหลายวัตถุประสงค์โดยใช้การเรียงลำดับที่ไม่ครอบงำ ในการวนซ้ำแต่ละครั้ง MO-ASHA ยังเลือกการกำหนดค่าแต่ละรายการด้วย รวมถึงประเภทของอินสแตนซ์ที่เราต้องการประเมินด้วย ในการรัน HPO บนชุดอินสแตนซ์ที่ต่างกัน Syne Tune จัดเตรียมแบ็กเอนด์ SageMaker ด้วยแบ็กเอนด์นี้ การทดลองแต่ละครั้งจะได้รับการประเมินว่าเป็นงานฝึกอบรม SageMaker อิสระในอินสแตนซ์ของตัวเอง จำนวนผู้ปฏิบัติงานกำหนดจำนวนงาน SageMaker ที่เราเรียกใช้พร้อมกันในเวลาที่กำหนด ตัวเพิ่มประสิทธิภาพเอง MO-ASHA ในกรณีของเรา ทำงานบนเครื่องในพื้นที่ โน้ตบุ๊ก Sagemaker หรืองานฝึกอบรม SageMaker ที่แยกต่างหาก ดูรหัสต่อไปนี้:
ตัวเลขต่อไปนี้แสดงข้อผิดพลาดเวลาแฝงเทียบกับการทดสอบทางด้านซ้ายและเวลาแฝงเทียบกับต้นทุนทางด้านขวาสำหรับการกำหนดค่าแบบสุ่มที่สุ่มตัวอย่างโดย MO-ASHA (เราจำกัดแกนสำหรับการมองเห็น) บนชุดข้อมูล MRPC หลังจากรันเป็นเวลา 10,800 วินาทีกับคนทำงานสี่คน สีระบุประเภทอินสแตนซ์ เส้นประสีดำแสดงถึงชุด Pareto ซึ่งหมายถึงชุดของจุดที่ครอบงำจุดอื่นๆ ทั้งหมดในวัตถุประสงค์อย่างน้อยหนึ่งรายการ
เราสามารถสังเกตการประนีประนอมระหว่างเวลาแฝงและข้อผิดพลาดในการทดสอบ ซึ่งหมายความว่าการกำหนดค่าที่ดีที่สุดที่มีข้อผิดพลาดในการทดสอบต่ำสุดจะไม่ได้รับเวลาแฝงที่ต่ำที่สุด คุณสามารถเลือกการกำหนดค่าไฮเปอร์พารามิเตอร์ที่ลดประสิทธิภาพการทดสอบลงได้ตามความต้องการของคุณ แต่มาพร้อมกับเวลาแฝงที่น้อยกว่า นอกจากนี้เรายังเห็นการแลกเปลี่ยนระหว่างเวลาแฝงและต้นทุน ตัวอย่างเช่น การใช้อินสแตนซ์ ml.g4dn.xlarge ที่เล็กกว่านั้น เราเพิ่มเวลาแฝงเพียงเล็กน้อยเท่านั้น แต่จ่ายหนึ่งในสี่ของต้นทุนของอินสแตนซ์ ml.g4dn.8xlarge
สรุป
ในโพสต์นี้ เราได้พูดถึงการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์สำหรับการปรับโมเดลหม้อแปลงไฟฟ้าที่ผ่านการฝึกอบรมล่วงหน้าอย่างละเอียดจาก Hugging Face โดยอิงจาก Syne Tune เราเห็นว่าการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์ เช่น อัตราการเรียนรู้ ขนาดแบทช์ และอัตราส่วนการวอร์มอัพ ทำให้เราปรับปรุงการกำหนดค่าเริ่มต้นที่เลือกมาอย่างดีได้ นอกจากนี้เรายังสามารถขยายสิ่งนี้ได้ด้วยการเลือกโมเดลที่ได้รับการฝึกอบรมล่วงหน้าโดยอัตโนมัติผ่านการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์
ด้วยความช่วยเหลือจากแบ็กเอนด์ SageMaker ของ Syne Tune เราสามารถถือว่าประเภทอินสแตนซ์เป็นไฮเปอร์พารามิเตอร์ได้ แม้ว่าประเภทอินสแตนซ์จะไม่ส่งผลต่อประสิทธิภาพ แต่ก็มีผลกระทบอย่างมากต่อเวลาในการตอบสนองและค่าใช้จ่าย ดังนั้น โดยการกำหนดให้ HPO เป็นปัญหาการปรับให้เหมาะสมแบบหลายวัตถุประสงค์ เราจึงสามารถค้นหาชุดการกำหนดค่าที่แลกเปลี่ยนวัตถุประสงค์หนึ่งกับอีกวัตถุประสงค์หนึ่งได้อย่างเหมาะสมที่สุด หากคุณต้องการลองด้วยตัวเองลองดูที่ .ของเรา ตัวอย่างโน๊ตบุ๊ค.
เกี่ยวกับผู้เขียน
![]() แอรอนไคลน์ เป็นนักวิทยาศาสตร์ประยุกต์ที่ AWS
แอรอนไคลน์ เป็นนักวิทยาศาสตร์ประยุกต์ที่ AWS
![]() มาเธียส ซีเกอร์ เป็นหัวหน้านักวิทยาศาสตร์ประยุกต์ที่ AWS
มาเธียส ซีเกอร์ เป็นหัวหน้านักวิทยาศาสตร์ประยุกต์ที่ AWS
![]() เดวิด ซาลินาส เป็น Sr Applied Scientist ที่ AWS
เดวิด ซาลินาส เป็น Sr Applied Scientist ที่ AWS
![]() เอมิลี่ เว็บเบอร์ เข้าร่วม AWS หลังจากเปิดตัว SageMaker และพยายามบอกให้โลกรู้ตั้งแต่นั้นมา! นอกเหนือจากการสร้างประสบการณ์ ML ใหม่ให้กับลูกค้าแล้ว เอมิลี่ชอบนั่งสมาธิและศึกษาพุทธศาสนาในทิเบต
เอมิลี่ เว็บเบอร์ เข้าร่วม AWS หลังจากเปิดตัว SageMaker และพยายามบอกให้โลกรู้ตั้งแต่นั้นมา! นอกเหนือจากการสร้างประสบการณ์ ML ใหม่ให้กับลูกค้าแล้ว เอมิลี่ชอบนั่งสมาธิและศึกษาพุทธศาสนาในทิเบต
![]() เซดริก อาร์แชมโบ เป็นนักวิทยาศาสตร์ประยุกต์หลักที่ AWS และ Fellow of the European Lab for Learning and Intelligent Systems
เซดริก อาร์แชมโบ เป็นนักวิทยาศาสตร์ประยุกต์หลักที่ AWS และ Fellow of the European Lab for Learning and Intelligent Systems
- คอยน์สมาร์ท การแลกเปลี่ยน Bitcoin และ Crypto ที่ดีที่สุดในยุโรป
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าฟรี
- คริปโตฮอว์ก เรดาร์ Altcoin ทดลองฟรี.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/hyperparameter-optimization-for-fine-tuning-pre-trained-transformer-models-from-hugging-face/
- "
- 10
- 100
- 7
- 9
- a
- เกี่ยวกับเรา
- แน่นอน
- สามารถเข้าถึงได้
- ลงชื่อเข้าใช้
- บรรลุ
- ข้าม
- เพิ่มเติม
- มีผลต่อ
- ทั้งหมด
- ช่วยให้
- แม้ว่า
- อเมซอน
- จำนวน
- การวิเคราะห์
- วิเคราะห์
- อื่น
- API
- ประยุกต์
- ประมาณ
- สถาปัตยกรรม
- เติม
- โดยอัตโนมัติ
- อัตโนมัติ
- เฉลี่ย
- AWS
- แกน
- เพราะ
- มาตรฐาน
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- เกิน
- Black
- กล้า
- เพิ่ม
- งบ
- การก่อสร้าง
- ซึ่ง
- กรณี
- ที่เกิดจาก
- ทางเลือก
- ทางเลือก
- เลือก
- ชั้น
- การจัดหมวดหมู่
- รหัส
- อย่างไร
- เมื่อเทียบกับ
- คำนวณ
- องค์ประกอบ
- ควบคุม
- ลูกค้า
- ข้อมูล
- การตัดสินใจ
- สาธิต
- ปรับใช้
- นำไปใช้
- กระจาย
- ไม่
- ดอลลาร์
- แต่ละ
- อย่างง่ายดาย
- มีประสิทธิภาพ
- ในทวีปยุโรป
- ประเมินค่า
- การประเมินผล
- ตัวอย่าง
- ประสบการณ์
- ชำนาญ
- ขยายออก
- ใบหน้า
- ร้านแฟชั่นเกาหลี
- รูป
- ดังต่อไปนี้
- กรอบ
- ราคาเริ่มต้นที่
- เต็ม
- ฟังก์ชัน
- ต่อไป
- นอกจากนี้
- เครื่องกำเนิดไฟฟ้า
- ช่วย
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTTPS
- ส่งผลกระทบ
- สำคัญ
- ปรับปรุง
- การปรับปรุง
- เพิ่ม
- อิสระ
- มีอิทธิพล
- ตัวอย่าง
- ฉลาด
- อยากเรียนรู้
- IT
- ตัวเอง
- การสัมภาษณ์
- งาน
- เข้าร่วม
- ความรู้
- ห้องปฏิบัติการ
- ป้ายกำกับ
- ภาษา
- ใหญ่
- ที่มีขนาดใหญ่
- เปิดตัว
- นำไปสู่
- การเรียนรู้
- LIMIT
- Line
- ในประเทศ
- เครื่อง
- ทำ
- ทำให้
- มาก
- ความหมาย
- วิธีการ
- ตัวชี้วัด
- อาจ
- ML
- แบบ
- โมเดล
- ข้อมูลเพิ่มเติม
- หลาย
- โดยธรรมชาติ
- จำเป็นต้อง
- ความต้องการ
- เครือข่าย
- สมุดบันทึก
- จำนวน
- วัตถุประสงค์
- ที่ได้รับ
- การเพิ่มประสิทธิภาพ
- เพิ่มประสิทธิภาพ
- การเพิ่มประสิทธิภาพ
- เป็นต้นฉบับ
- อื่นๆ
- ของตนเอง
- โดยเฉพาะ
- ชำระ
- การปฏิบัติ
- ที่มีประสิทธิภาพ
- กรุณา
- จุด
- ยอดนิยม
- การปฏิบัติ
- หลัก
- ปัญหา
- กระบวนการ
- การประมวลผล
- ให้
- พิสัย
- อันดับ
- รายงาน
- ผู้รายงานข่าว
- รายงาน
- แสดงให้เห็นถึง
- ต้อง
- ผลสอบ
- วิ่ง
- วิ่ง
- เดียวกัน
- นักวิทยาศาสตร์
- ค้นหา
- วินาที
- เมล็ดพันธุ์
- เลือก
- ความรู้สึก
- ชุด
- การตั้งค่า
- โชว์
- สำคัญ
- คล้ายคลึงกัน
- ง่าย
- เดียว
- ขนาด
- ทางออก
- ซับซ้อน
- ช่องว่าง
- โดยเฉพาะ
- แยก
- มาตรฐาน
- เริ่มต้น
- สถานะ
- ยังคง
- กลยุทธ์
- ระบบ
- งาน
- ทดสอบ
- พื้นที่
- โลก
- ดังนั้น
- เวลา
- การค้า
- การฝึกอบรม
- รักษา
- มหึมา
- การทดลอง
- ความเข้าใจ
- us
- ใช้
- ผู้ใช้
- มักจะ
- นำไปใช้
- การตรวจสอบ
- ความชัดเจน
- วิกิพีเดีย
- ไม่มี
- แรงงาน
- โลก
- ของคุณ