บทนำ
โลกของข้อมูลการตรวจสอบอาจซับซ้อน โดยมีความท้าทายมากมายที่ต้องเอาชนะ หนึ่งในความท้าทายที่ใหญ่ที่สุดคือการจัดการแอตทริบิวต์ที่เป็นหมวดหมู่ในขณะที่จัดการกับชุดข้อมูล ในบทความนี้ เราจะเจาะลึกโลกของข้อมูลการตรวจสอบ การตรวจจับความผิดปกติ และผลกระทบของการเข้ารหัสแอตทริบิวต์หมวดหมู่ในโมเดล
หนึ่งในความท้าทายหลักที่เกี่ยวข้องกับการตรวจจับความผิดปกติสำหรับข้อมูลการตรวจสอบคือการจัดการแอตทริบิวต์ที่เป็นหมวดหมู่ การเข้ารหัสแอตทริบิวต์หมวดหมู่เป็นสิ่งจำเป็นเนื่องจากแบบจำลองไม่สามารถตีความการป้อนข้อความได้ โดยทั่วไป ทำได้โดยใช้การเข้ารหัสฉลากหรือการเข้ารหัสแบบร้อนครั้งเดียว อย่างไรก็ตาม ในชุดข้อมูลขนาดใหญ่ การเข้ารหัสแบบ One-hot อาจทำให้โมเดลมีประสิทธิภาพต่ำเนื่องจากมิติที่สาปแช่ง
วัตถุประสงค์การเรียนรู้
-
เพื่อให้เข้าใจแนวคิดของการตรวจสอบข้อมูลและความท้าทาย
- เพื่อประเมินวิธีการต่างๆ ของการตรวจจับความผิดปกติเชิงลึกที่ไม่มีผู้ดูแล
- เพื่อทำความเข้าใจผลกระทบของการเข้ารหัสแอตทริบิวต์ตามหมวดหมู่บนแบบจำลองที่ใช้สำหรับการตรวจจับความผิดปกติในข้อมูลการตรวจสอบ
บทความนี้เผยแพร่โดยเป็นส่วนหนึ่งของไฟล์ Blogathon วิทยาศาสตร์ข้อมูล.
สารบัญ
- อัตตาคืออะไร?
- การตรวจจับความผิดปกติคืออะไร?
- ความท้าทายสำคัญที่เผชิญขณะตรวจสอบข้อมูล
- การตรวจสอบชุดข้อมูลสำหรับการตรวจจับความผิดปกติ
- การเข้ารหัสแอตทริบิวต์หมวดหมู่
- การเข้ารหัสตามหมวดหมู่
- แบบจำลองการตรวจจับความผิดปกติที่ไม่ได้รับการดูแล
- การเข้ารหัสแอตทริบิวต์ตามหมวดหมู่ส่งผลกระทบต่อโมเดลอย่างไร
8.1 การแสดง t-SNE ของชุดข้อมูลประกันภัยรถยนต์
8.2 การแสดง t-SNE ของชุดข้อมูลประกันภัยรถยนต์
8.3 การแสดง t-SNE ของชุดข้อมูลการเรียกร้องยานพาหนะ - สรุป
ที่การตรวจสอบข้อมูล?
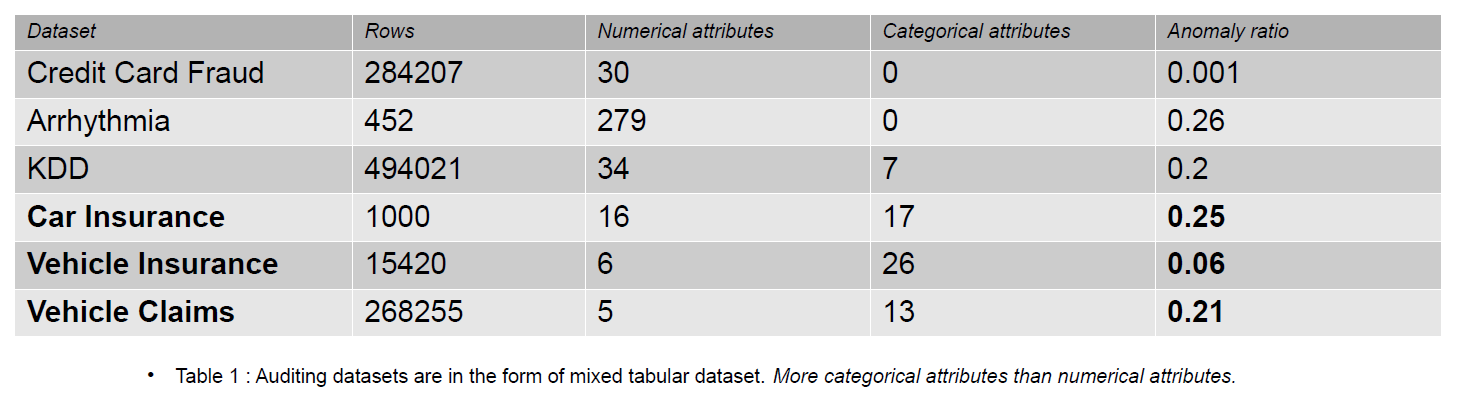
ข้อมูลการตรวจสอบอาจรวมถึงวารสาร การเรียกร้องค่าสินไหมทดแทน และข้อมูลการบุกรุกสำหรับระบบสารสนเทศ ในบทความนี้จะยกตัวอย่างการเคลมประกันภัยรถยนต์ การเรียกร้องค่าสินไหมทดแทนแตกต่างจากชุดข้อมูลการตรวจจับความผิดปกติ เช่น KDD ด้วยคุณลักษณะตามหมวดหมู่จำนวนมากขึ้น
คุณสมบัติตามหมวดหมู่เป็นข้อโต้แย้งในข้อมูลของเราที่สามารถเป็นได้ทั้งประเภทจำนวนเต็มหรืออักขระ คุณลักษณะที่เป็นตัวเลขคือแอตทริบิวต์ที่ต่อเนื่องในข้อมูลของเราซึ่งมีค่าตามจริงเสมอ ชุดข้อมูลที่มีคุณสมบัติเป็นตัวเลขเป็นที่นิยมในชุมชนการตรวจจับความผิดปกติ เช่น ข้อมูลการฉ้อโกงบัตรเครดิต ชุดข้อมูลที่เผยแพร่ต่อสาธารณะส่วนใหญ่มีคุณลักษณะการจัดหมวดหมู่น้อยกว่าข้อมูลการเรียกร้องค่าสินไหมทดแทน คุณลักษณะตามหมวดหมู่มีจำนวนมากกว่าคุณลักษณะที่เป็นตัวเลขในชุดข้อมูลการเรียกร้องค่าสินไหมทดแทน
การเคลมประกันประกอบด้วยคุณสมบัติต่างๆ เช่น รุ่น ยี่ห้อ รายได้ ต้นทุน ปัญหา สี เป็นต้น จำนวนของคุณสมบัติตามหมวดหมู่ในข้อมูลการตรวจสอบมีมากกว่าในชุดข้อมูลบัตรเครดิตและ KDD ชุดข้อมูลเหล่านี้เป็นเกณฑ์มาตรฐานในวิธีการตรวจจับสิ่งผิดปกติที่ไม่มีผู้ดูแล ดังที่เห็นในตารางด้านล่าง ชุดข้อมูลการเคลมประกันมีคุณลักษณะที่เป็นหมวดหมู่มากขึ้น ซึ่งมีความสำคัญต่อการทำความเข้าใจพฤติกรรมของข้อมูลที่ฉ้อฉล
ชุดข้อมูลการตรวจสอบที่ใช้ในการประเมินผลกระทบของการเข้ารหัสตามหมวดหมู่ ได้แก่ การประกันภัยรถยนต์ การประกันภัยรถยนต์ และการเคลมรถยนต์
การตรวจจับความผิดปกติคืออะไร?
ความผิดปกติคือการสังเกตที่อยู่ห่างไกลจากข้อมูลปกติในชุดข้อมูลตามระยะทางที่กำหนด (Threshold) ในแง่ของการตรวจสอบข้อมูล เราต้องการคำว่าข้อมูลที่เป็นการฉ้อฉล การตรวจจับความผิดปกติจะแยกแยะระหว่างข้อมูลปกติและข้อมูลปลอมโดยใช้แมชชีนเลิร์นนิงหรือโมเดลการเรียนรู้เชิงลึก วิธีการต่างๆ สามารถใช้สำหรับการตรวจจับความผิดปกติ เช่น การประมาณค่าความหนาแน่น ข้อผิดพลาดในการสร้างใหม่ และวิธีการจำแนกประเภท
- การประมาณค่าความหนาแน่น – วิธีการเหล่านี้ประมาณการแจกแจงข้อมูลปกติและจัดประเภทข้อมูลที่ผิดปกติหากไม่ได้สุ่มตัวอย่างจากการแจกแจงที่เรียนรู้
- ข้อผิดพลาดในการสร้างใหม่ – วิธีการตามข้อผิดพลาดของการสร้างใหม่ขึ้นอยู่กับหลักการที่ว่าข้อมูลปกติสามารถสร้างขึ้นใหม่โดยมีความสูญเสียน้อยกว่าข้อมูลที่ผิดปกติ ยิ่งการสูญเสียการสร้างใหม่สูงเท่าใด โอกาสที่ข้อมูลจะผิดปกติก็จะยิ่งเพิ่มสูงขึ้นเท่านั้น
- วิธีการจำแนกประเภท - วิธีการจำแนกเช่น ป่าสุ่ม, Isolation Forest, One Class – Support Vector Machines และ Local Outlier Factors สามารถใช้สำหรับการตรวจจับความผิดปกติได้ การจำแนกประเภทในการตรวจจับความผิดปกติเกี่ยวข้องกับการระบุคลาสใดคลาสหนึ่งว่าเป็นความผิดปกติ ถึงกระนั้น คลาสจะถูกแบ่งออกเป็นสองกลุ่ม (0 และ 1) ในสถานการณ์หลายคลาส และคลาสที่มีข้อมูลน้อยกว่าคือคลาสที่ผิดปกติ
ผลลัพธ์ของวิธีการข้างต้นคือคะแนนความผิดปกติหรือข้อผิดพลาดในการสร้างใหม่ จากนั้นเราต้องตัดสินใจเลือกเกณฑ์ตามที่เราจัดประเภทข้อมูลที่ผิดปกติ
ความท้าทายสำคัญที่เผชิญขณะตรวจสอบข้อมูล
- การจัดการแอตทริบิวต์หมวดหมู่: การเข้ารหัสแอตทริบิวต์หมวดหมู่เป็นสิ่งจำเป็นเนื่องจากแบบจำลองไม่สามารถตีความการป้อนข้อความได้ ดังนั้น ค่าต่างๆ จะถูกเข้ารหัสด้วยการเข้ารหัส Label หรือการเข้ารหัส One Hot แต่ในชุดข้อมูลขนาดใหญ่ One hot encoding จะแปลงข้อมูลเป็นพื้นที่มิติสูงโดยเพิ่มจำนวนแอตทริบิวต์ โมเดลทำงานได้ไม่ดีเนื่องจาก คำสาปแห่งมิติ.
- การเลือกเกณฑ์สำหรับการจำแนกประเภท: หากข้อมูลไม่มีป้ายกำกับ เป็นการยากที่จะประเมินประสิทธิภาพของโมเดล เนื่องจากเราไม่ทราบจำนวนความผิดปกติที่มีอยู่ในชุดข้อมูล ความรู้เดิมเกี่ยวกับชุดข้อมูลทำให้กำหนดเกณฑ์ได้ง่ายขึ้น สมมติว่าเรามีตัวอย่างที่ผิดปกติ 5 ใน 10 ตัวอย่างในข้อมูลของเรา เราจึงสามารถเลือกเกณฑ์ได้ที่คะแนนเปอร์เซ็นไทล์ 50
- ชุดข้อมูลสาธารณะ: ชุดข้อมูลการตรวจสอบส่วนใหญ่เป็นความลับเนื่องจากเป็นของบริษัทองค์กรและมีข้อมูลส่วนตัวที่ละเอียดอ่อน วิธีหนึ่งที่เป็นไปได้ในการลดปัญหาการรักษาความลับคือการฝึกอบรมโดยใช้ชุดข้อมูลสังเคราะห์ (การอ้างสิทธิ์ในรถยนต์)
การตรวจสอบชุดข้อมูลสำหรับการตรวจจับความผิดปกติ
การเคลมประกันภัยสำหรับรถยนต์ประกอบด้วยข้อมูลเกี่ยวกับคุณสมบัติของรถยนต์ เช่น รุ่น ยี่ห้อ ราคา ปี และประเภทเชื้อเพลิง ประกอบด้วยข้อมูลเกี่ยวกับคนขับ วันเกิด เพศ และอาชีพ นอกจากนี้ การเรียกร้องอาจรวมถึงข้อมูลเกี่ยวกับต้นทุนรวมของการซ่อม ชุดข้อมูลที่ใช้ในบทความนี้ทั้งหมดมาจากโดเมนเดียว แต่จะแตกต่างกันไปตามจำนวนแอตทริบิวต์และจำนวนอินสแตนซ์
-
ชุดข้อมูลการอ้างสิทธิ์ยานพาหนะมีขนาดใหญ่ ประกอบด้วยแถวมากกว่า 250,000 แถว และแอตทริบิวต์ตามหมวดหมู่มีจำนวนสมาชิก 1171 รายการ ชุดข้อมูลนี้ได้รับผลกระทบจากคำสาปของมิติเนื่องจากขนาดที่ใหญ่
- ชุดข้อมูลประกันภัยรถยนต์เป็นขนาดกลาง โดยมี 15,420 แถวและ 151 ค่าตามหมวดหมู่ที่ไม่ซ้ำกัน สิ่งนี้ทำให้มีแนวโน้มที่จะทนทุกข์ทรมานจากคำสาปแห่งมิติน้อยลง
- ชุดข้อมูลการประกันภัยรถยนต์มีขนาดเล็ก มีป้ายกำกับและตัวอย่างที่ผิดปกติ 25% และมีคุณลักษณะเชิงตัวเลขและการจัดหมวดหมู่ในจำนวนที่ใกล้เคียงกัน ด้วยหมวดหมู่ที่ไม่ซ้ำกัน 169 หมวดหมู่ จึงไม่ได้รับผลกระทบจากคำสาปแห่งมิติ
การเข้ารหัสแอตทริบิวต์ตามหมวดหมู่
การเข้ารหัสค่าหมวดหมู่ที่แตกต่างกัน
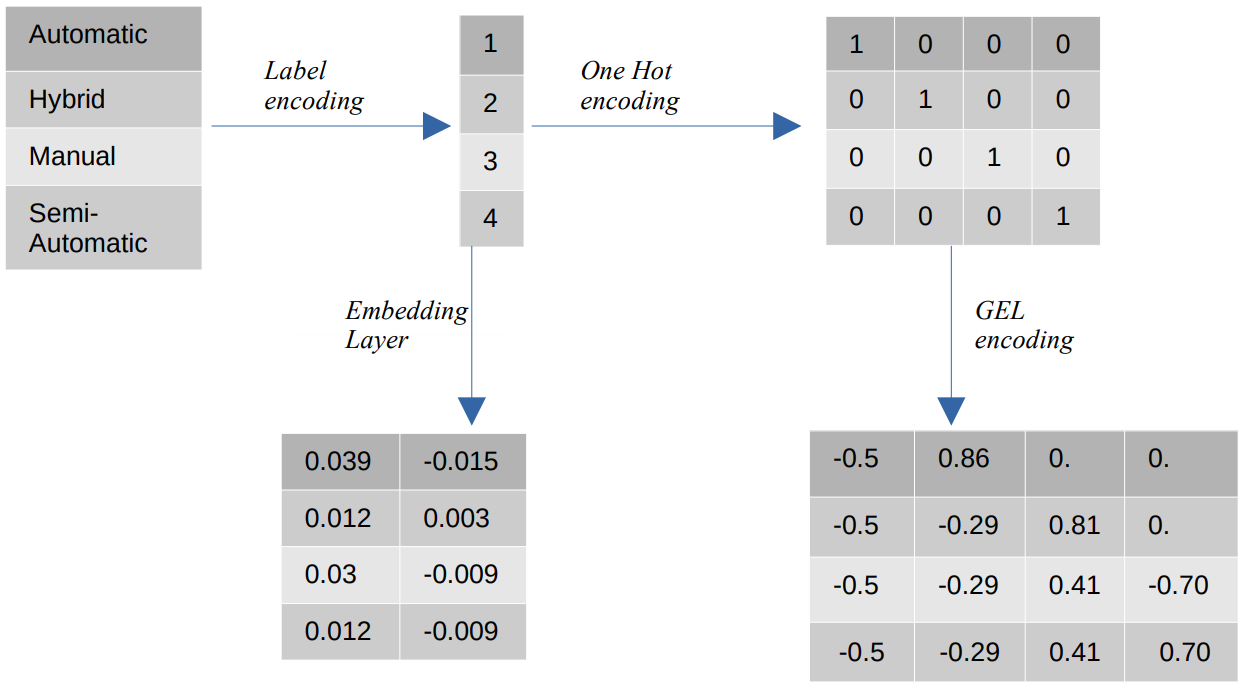
- การเข้ารหัสฉลาก – ในการเข้ารหัสฉลาก ค่าหมวดหมู่จะถูกแทนที่ด้วยค่าเลขจำนวนเต็มระหว่าง 1 ถึงจำนวนหมวดหมู่ การเข้ารหัสฉลากแสดงถึงหมวดหมู่ในลักษณะที่ต้องการสำหรับค่าลำดับ ถึงกระนั้น เมื่อคุณลักษณะเป็นแบบระบุชื่อ การแสดงจะไม่ถูกต้องเนื่องจากค่าหมวดหมู่ไม่สอดคล้องกับคำสั่งเฉพาะ
ตัวอย่างเช่น หากเรามีหมวดหมู่ เช่น อัตโนมัติ ไฮบริด แมนนวล และกึ่งอัตโนมัติในคุณลักษณะ การเข้ารหัสป้ายกำกับจะแปลงค่าเหล่านี้เป็น {1: อัตโนมัติ 2: ไฮบริด 3: กำหนดเอง 4:กึ่งอัตโนมัติ} การแสดงนี้ไม่ได้ให้ข้อมูลเกี่ยวกับค่าตามหมวดหมู่ แต่การแสดงเช่น {0: ต่ำ, 1: ปานกลาง, 2: สูง} ให้การแสดงที่ชัดเจนเนื่องจากตัวแปรคุณลักษณะต่ำได้รับการกำหนดค่าตัวเลขที่ต่ำกว่า ดังนั้น การเข้ารหัสฉลากจึงดีกว่าสำหรับค่าลำดับ แต่เสียเปรียบสำหรับค่าเล็กน้อย - หนึ่งการเข้ารหัสร้อน – One Hot encoding ใช้เพื่อแก้ไขปัญหาของค่าการเข้ารหัสเล็กน้อย ซึ่งจะแปลงค่าตามหมวดหมู่แต่ละค่าเป็นคุณสมบัติที่แตกต่างกันในชุดข้อมูลที่ประกอบด้วยค่าไบนารี ตัวอย่างเช่น ในกรณีของสี่หมวดหมู่ที่แตกต่างกันซึ่งเข้ารหัสเป็น {1, 2, 3, 4} การเข้ารหัสแบบ Hot เดียวจะสร้างคุณสมบัติใหม่ เช่น {อัตโนมัติ: [1,0,0,0], ไฮบริด: [0,1,0,0 ,0,0,1,0], แมนนวล: [0,0,0,1], กึ่งอัตโนมัติ: [XNUMX]}
ขนาดของชุดข้อมูลนั้นขึ้นอยู่กับจำนวนหมวดหมู่ที่มีอยู่ในชุดข้อมูลโดยตรง ด้วยเหตุนี้ การเข้ารหัสแบบ One Hot อาจนำไปสู่การสาปแช่งของมิติ ซึ่งเป็นข้อเสียเปรียบของวิธีการเข้ารหัสนี้ - การเข้ารหัสเจล – การเข้ารหัส GEL เป็นเทคนิคการฝังที่สามารถใช้ในวิธีการเรียนรู้แบบมีผู้สอนและไม่มีผู้ดูแล มันขึ้นอยู่กับหลักการของการเข้ารหัสแบบ One Hot และสามารถใช้เพื่อลดมิติของคุณสมบัติตามหมวดหมู่ที่ได้รับการเข้ารหัสโดยใช้การเข้ารหัสแบบ One Hot
- การฝังเลเยอร์ - การฝังคำเป็นวิธีการใช้การแสดงที่กะทัดรัดและหนาแน่น ซึ่งคำที่คล้ายกันมีการเข้ารหัสที่คล้ายคลึงกัน การฝังเป็นเวกเตอร์หนาแน่นของค่าทศนิยมที่เป็นพารามิเตอร์ที่ฝึกได้ การฝัง Word มีตั้งแต่ 8 มิติ (สำหรับชุดข้อมูลขนาดเล็ก) ไปจนถึง 1024 มิติ (สำหรับชุดข้อมูลขนาดใหญ่)
การฝังมิติที่สูงขึ้นสามารถบันทึกความสัมพันธ์ที่มีรายละเอียดมากขึ้นระหว่างคำ แต่ต้องใช้ข้อมูลมากขึ้นในการเรียนรู้ เลเยอร์การฝังเป็นตารางการค้นหาที่แปลงแต่ละคำที่มีอยู่ในเมทริกซ์เป็นเวกเตอร์ที่มีขนาดเฉพาะ
แบบจำลองการตรวจจับความผิดปกติที่ไม่ได้รับการดูแล
ในโลกแห่งความเป็นจริง ข้อมูลส่วนใหญ่ไม่ได้ติดป้ายกำกับ และการติดป้ายกำกับข้อมูลนั้นมีราคาแพงและใช้เวลานาน ดังนั้น เราจะใช้แบบจำลองที่ไม่มีผู้ดูแลสำหรับการประเมินของเรา
- SOM - Self-Organizing Map (SOM) เป็นวิธีการเรียนรู้แบบแข่งขันที่น้ำหนักของเซลล์ประสาทได้รับการปรับปรุงให้แข่งขันได้แทนที่จะใช้การเรียนรู้แบบย้อนกลับ SOM ประกอบด้วยแผนผังของเซลล์ประสาท โดยแต่ละตัวมีเวกเตอร์น้ำหนักที่มีขนาดเท่ากันกับเวกเตอร์อินพุต เวกเตอร์น้ำหนักจะเริ่มต้นด้วยน้ำหนักสุ่มก่อนเริ่มการฝึก ระหว่างการฝึก ข้อมูลแต่ละรายการจะถูกเปรียบเทียบกับเซลล์ประสาทของแผนที่ตามเมตริกระยะทาง (เช่น ระยะทางแบบยุคลิด) และจะถูกจับคู่กับหน่วยจับคู่ที่ดีที่สุด (BMU) ซึ่งเป็นเซลล์ประสาทที่มีระยะทางน้อยที่สุดจากเวกเตอร์อินพุต
น้ำหนักของ BMU ได้รับการอัปเดตด้วยน้ำหนักของเวกเตอร์อินพุต และเซลล์ประสาทที่อยู่ใกล้เคียงจะได้รับการอัปเดตตามรัศมีย่าน (sigma) เนื่องจากเซลล์ประสาทแข่งขันกันเองเพื่อเป็นหน่วยจับคู่ที่ดีที่สุด กระบวนการนี้จึงเรียกว่าการเรียนรู้แบบแข่งขัน ในท้ายที่สุด เซลล์ประสาทของตัวอย่างปกติจะอยู่ใกล้กว่าเซลล์ที่ผิดปกติ คะแนนความผิดปกติถูกกำหนดโดยข้อผิดพลาดเชิงปริมาณ ซึ่งเป็นความแตกต่างระหว่างตัวอย่างอินพุตและน้ำหนักของหน่วยที่ตรงกันที่ดีที่สุด ข้อผิดพลาดเชิงปริมาณที่สูงขึ้นบ่งชี้ว่ามีความเป็นไปได้สูงที่ตัวอย่างจะเป็นความผิดปกติ - แดกเอ็มเอ็ม – Deep Autoencoding Gaussian Mixture Model (DAGMM) เป็นวิธีการประมาณค่าความหนาแน่นที่อนุมานว่าความผิดปกตินั้นอยู่ในพื้นที่ที่มีความน่าจะเป็นต่ำ เครือข่ายแบ่งออกเป็นสองส่วน: เครือข่ายการบีบอัดซึ่งใช้ในการฉายข้อมูลในมิติที่ต่ำกว่าโดยใช้ตัวเข้ารหัสอัตโนมัติ และเครือข่ายการประเมินซึ่งใช้ในการประมาณค่าพารามิเตอร์ของโมเดลผสม Gaussian DAGMM ประมาณค่า k ของส่วนผสมแบบเกาส์ โดยที่ k สามารถเป็นตัวเลขใดๆ ก็ได้ตั้งแต่ 1 ถึง N (จำนวนจุดข้อมูล) และสันนิษฐานว่าจุดปกติอยู่ในบริเวณที่มีความหนาแน่นสูง หมายความว่าความน่าจะเป็นที่จะถูกสุ่มตัวอย่างจาก ส่วนผสมของ Gaussian มีค่าสูงกว่าสำหรับตัวอย่างที่ผิดปกติ คะแนนความผิดปกติกำหนดโดยพลังงานโดยประมาณของตัวอย่าง
- ราสเร – เลเยอร์การกู้คืนพื้นผิวที่แข็งแกร่งสำหรับการตรวจจับความผิดปกติที่ไม่มีผู้ดูแลคือวิธีการสร้างข้อผิดพลาดขึ้นใหม่ ซึ่งในขั้นแรกจะฉายข้อมูลไปยังมิติที่ต่ำกว่าโดยใช้ตัวเข้ารหัสอัตโนมัติ จากนั้นการแทนแบบแฝงจะถูกฉายภาพแบบมุมฉากไปยังพื้นที่ย่อยเชิงเส้นที่แข็งแกร่งต่อค่าผิดปกติ จากนั้นตัวถอดรหัสจะสร้างเอาต์พุตใหม่จากพื้นที่ย่อยเชิงเส้น ในวิธีนี้ ข้อผิดพลาดในการสร้างใหม่ที่สูงขึ้นบ่งชี้ว่ามีความเป็นไปได้สูงที่ตัวอย่างจะผิดปกติ
- ส้ม-DAGMM- แผนที่ที่จัดระเบียบตัวเอง (SOM) – แบบจำลองการผสมแบบเกาส์เซียนเข้ารหัสอัตโนมัติเชิงลึก (DAGMM) เป็นแบบจำลองการประมาณค่าความหนาแน่นด้วย เช่นเดียวกับ DAGMM มันยังประมาณการแจกแจงความน่าจะเป็นของจุดข้อมูลปกติและจัดประเภทจุดข้อมูลเป็นความผิดปกติหากมีความเป็นไปได้ต่ำที่จะถูกสุ่มตัวอย่างจากการแจกแจงที่เรียนรู้ ข้อแตกต่างหลักระหว่าง SOM-DAGMM และ DAGMM คือ SOM-DAGMM รวมพิกัดมาตรฐานของ SOM สำหรับตัวอย่างอินพุต ซึ่งให้ข้อมูลโทโพโลยีที่ขาดหายไปในกรณีของ DAGMM ไปยังเครือข่ายการประมาณค่า วัตถุประสงค์ยังคล้ายกับ DAGMM ตรงที่คะแนนความผิดปกติถูกกำหนดโดยพลังงานโดยประมาณของตัวอย่าง และพลังงานต่ำบ่งชี้ว่ามีความเป็นไปได้สูงที่ตัวอย่างจะเป็นความผิดปกติ
ต่อไป เราจะจัดการกับความท้าทายในการจัดการแอตทริบิวต์ที่เป็นหมวดหมู่
การเข้ารหัสแอตทริบิวต์ตามหมวดหมู่ส่งผลกระทบต่อโมเดลอย่างไร
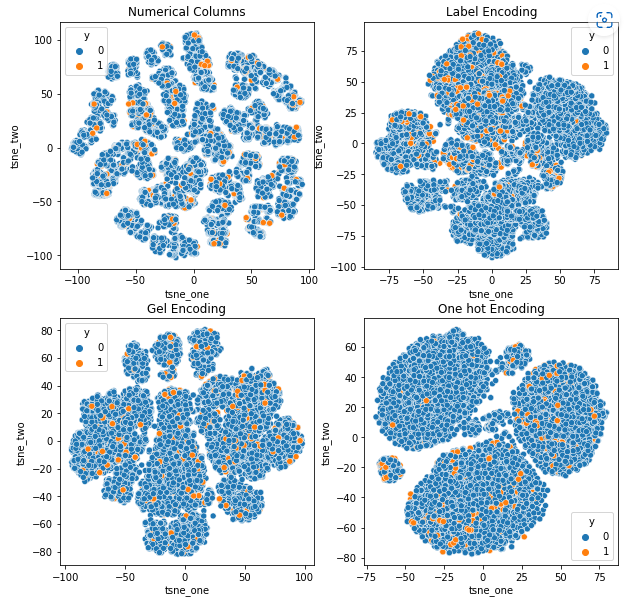
เพื่อให้เข้าใจถึงผลกระทบของการเข้ารหัสต่างๆ ในชุดข้อมูล เราจะใช้ t-SNE เพื่อแสดงภาพการแสดงข้อมูลในมิติต่ำสำหรับการเข้ารหัสต่างๆ t-SNE ฉายข้อมูลมิติสูงลงในพื้นที่มิติที่ต่ำกว่า ทำให้เห็นภาพได้ง่ายขึ้น เมื่อเปรียบเทียบการแสดงภาพ t-SNE และผลลัพธ์ที่เป็นตัวเลขของการเข้ารหัสที่แตกต่างกันของชุดข้อมูลเดียวกัน ความแตกต่างจะสังเกตได้จากการแสดงผลลัพธ์และความเข้าใจในผลกระทบของการเข้ารหัสต่อชุดข้อมูล
การแสดง t-SNE ของชุดข้อมูลประกันภัยรถยนต์
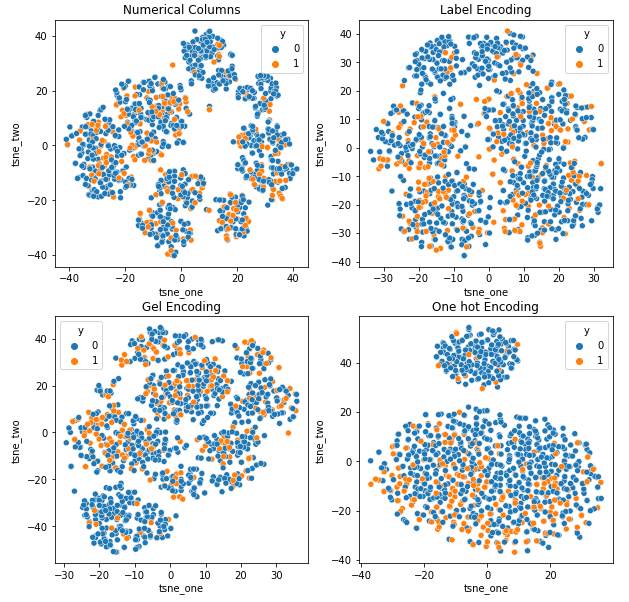
การแสดง t-SNE ของชุดข้อมูลการประกันภัยรถยนต์
-
ข้อมูลอยู่ใกล้กันมากกว่าเนื่องจากจำนวนแถวสูงกว่าในชุดข้อมูลประกันภัยรถยนต์ แยกออกได้ยากด้วยมิติที่เพิ่มขึ้นในการเข้ารหัสแบบ One Hot
-
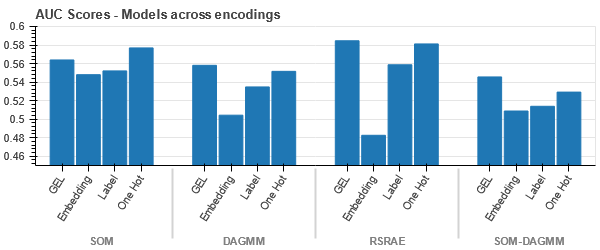
การเข้ารหัส GEL ดีกว่าการเข้ารหัส One Hot ในทุกกรณี ยกเว้น DAGMM
การแสดง t-SNE ของชุดข้อมูลการอ้างสิทธิ์ยานพาหนะ
-
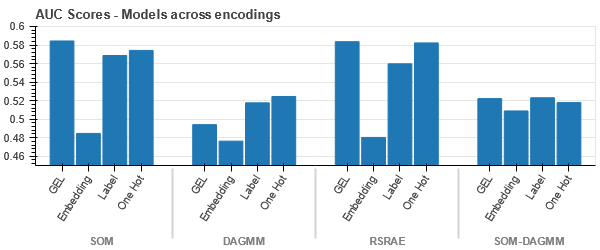
ข้อมูลถูกผูกไว้อย่างแน่นหนาในทุกกรณี ทำให้แยกได้ยากด้วยมิติข้อมูลที่เพิ่มขึ้น นี่เป็นสาเหตุหนึ่งที่ทำให้โมเดลมีประสิทธิภาพต่ำเนื่องจากขนาดที่เพิ่มขึ้น
- SOM มีประสิทธิภาพดีกว่าโมเดลอื่นๆ ทั้งหมดสำหรับชุดข้อมูลนี้ ถึงกระนั้น เลเยอร์การฝังจะเหมาะสมกว่าในกรณีส่วนใหญ่ ซึ่งช่วยให้เรามีทางเลือกอื่นแทนการเข้ารหัส คุณลักษณะหมวดหมู่ เพื่อตรวจจับสิ่งผิดปกติ
สรุป
บทความนี้นำเสนอภาพรวมโดยย่อของข้อมูลการตรวจสอบ การตรวจจับความผิดปกติ และการเข้ารหัสตามหมวดหมู่ สิ่งสำคัญคือต้องเข้าใจว่าการจัดการแอตทริบิวต์ที่เป็นหมวดหมู่ในข้อมูลการตรวจสอบเป็นสิ่งที่ท้าทาย ด้วยการทำความเข้าใจผลกระทบของการเข้ารหัสแอตทริบิวต์ในโมเดล เราสามารถปรับปรุงความแม่นยำในการตรวจจับความผิดปกติในชุดข้อมูลได้ ประเด็นสำคัญจากบทความนี้คือ:
- เมื่อขนาดของข้อมูลเพิ่มขึ้น สิ่งสำคัญคือต้องใช้วิธีการเข้ารหัสทางเลือกสำหรับแอตทริบิวต์ที่เป็นหมวดหมู่ เช่น การเข้ารหัสแบบ GEL และการฝังเลเยอร์ เนื่องจากการเข้ารหัส One Hot ไม่เหมาะสม
- โมเดลเดียวใช้ไม่ได้กับชุดข้อมูลทั้งหมด สำหรับชุดข้อมูลแบบตาราง ความรู้ด้านโดเมนมีความสำคัญอย่างยิ่ง
- การเลือกวิธีการเข้ารหัสขึ้นอยู่กับการเลือกรุ่น
รหัสสำหรับการประเมินโมเดลมีอยู่ใน GitHub.
สื่อที่แสดงในบทความนี้ไม่ได้เป็นของ Analytics Vidhya และถูกใช้ตามดุลยพินิจของผู้เขียน
ที่เกี่ยวข้อง
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- เกี่ยวกับเรา
- ข้างบน
- ตาม
- ความถูกต้อง
- นอกจากนี้
- ที่อยู่
- ทั้งหมด
- ช่วยให้
- ทางเลือก
- เสมอ
- การวิเคราะห์
- การวิเคราะห์ วิทยา
- และ
- การตรวจจับความผิดปกติ
- วิธีการ
- บทความ
- ที่ได้รับมอบหมาย
- ที่เกี่ยวข้อง
- สันนิษฐาน
- แอตทริบิวต์
- การตรวจสอบบัญชี
- อัตโนมัติ
- ใช้ได้
- ตาม
- เพราะ
- จะกลายเป็น
- ก่อน
- กำลัง
- ด้านล่าง
- มาตรฐาน
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- ที่ใหญ่ที่สุด
- ขอบเขต
- ยี่ห้อ
- ไม่ได้
- จับ
- รถ
- ประกันภัยรถยนต์
- บัตร
- กรณี
- กรณี
- หมวดหมู่
- ท้าทาย
- ความท้าทาย
- ท้าทาย
- โอกาส
- ตัวอักษร
- ทางเลือก
- ข้อเรียกร้อง
- การเรียกร้อง
- ชั้น
- ชั้นเรียน
- การจัดหมวดหมู่
- แยกประเภท
- ชัดเจน
- ใกล้ชิด
- รหัส
- สี
- อย่างธรรมดา
- ชุมชน
- บริษัท
- เมื่อเทียบกับ
- เปรียบเทียบ
- แข่งขัน
- การแข่งขัน
- ซับซ้อน
- แนวคิด
- ความลับ
- ประกอบด้วย
- มี
- ต่อเนื่องกัน
- ไทม์ไลน์การ
- ราคา
- สร้าง
- เครดิต
- บัตรเครดิต
- ข้อมูล
- จุดข้อมูล
- ชุดข้อมูล
- วันที่
- การซื้อขาย
- ลดลง
- ลึก
- การเรียนรู้ลึก ๆ
- ขึ้นอยู่กับ
- รายละเอียด
- การตรวจพบ
- กำหนด
- ความแตกต่าง
- ต่าง
- ยาก
- Dimension
- มิติ
- โดยตรง
- ดุลพินิจ
- ระยะทาง
- แตกต่าง
- การกระจาย
- แบ่งออก
- โดเมน
- คนขับรถ
- ในระหว่าง
- แต่ละ
- ง่ายดาย
- ทั้ง
- พลังงาน
- ความผิดพลาด
- ข้อผิดพลาด
- ประมาณการ
- ประมาณ
- ประมาณการ
- ฯลฯ
- ประเมินค่า
- การประเมินผล
- การประเมินผล
- ตัวอย่าง
- ตัวอย่าง
- ยกเว้น
- แพง
- อย่างยิ่ง
- ต้องเผชิญกับ
- ปัจจัย
- ลักษณะ
- คุณสมบัติ
- ชื่อจริง
- ป่า
- การหลอกลวง
- ฉ้อโกง
- ราคาเริ่มต้นที่
- เชื้อเพลิง
- เพศ
- กลุ่ม
- การจัดการ
- จุดสูง
- สูงกว่า
- ร้อน
- อย่างไรก็ตาม
- HTTPS
- เป็นลูกผสม
- ระบุ
- ส่งผลกระทบ
- สำคัญ
- ปรับปรุง
- in
- ประกอบด้วย
- รวมถึง
- เงินได้
- เพิ่มขึ้น
- เพิ่มขึ้น
- ที่เพิ่มขึ้น
- บ่งชี้ว่า
- ข้อมูล
- ระบบสารสนเทศ
- อินพุต
- ประกัน
- ความเหงา
- ปัญหา
- ปัญหา
- IT
- คีย์
- ทราบ
- ความรู้
- ที่รู้จักกัน
- ฉลาก
- การติดฉลาก
- ป้ายกำกับ
- ใหญ่
- ที่มีขนาดใหญ่
- ชั้น
- ชั้น
- นำ
- เรียนรู้
- ได้เรียนรู้
- การเรียนรู้
- ในประเทศ
- ที่ตั้งอยู่
- ค้นหา
- ปิด
- การสูญเสีย
- ต่ำ
- เครื่อง
- เรียนรู้เครื่อง
- เครื่อง
- หลัก
- ทำให้
- การทำ
- จำเป็น
- คู่มือ
- หลาย
- แผนที่
- การจับคู่
- มดลูก
- ความหมาย
- ภาพบรรยากาศ
- กลาง
- วิธี
- วิธีการ
- เมตริก
- ขั้นต่ำ
- หายไป
- บรรเทา
- สารผสม
- แบบ
- โมเดล
- ข้อมูลเพิ่มเติม
- มากที่สุด
- เครือข่าย
- เซลล์ประสาท
- ใหม่
- คุณสมบัติใหม่
- ปกติ
- จำนวน
- วัตถุประสงค์
- ONE
- ใบสั่ง
- อื่นๆ
- ประสิทธิภาพเหนือกว่า
- เอาชนะ
- ภาพรวม
- เป็นเจ้าของ
- พารามิเตอร์
- ส่วนหนึ่ง
- ส่วน
- การปฏิบัติ
- ดำเนินการ
- ส่วนบุคคล
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- จุด
- จุด
- น่าสงสาร
- ยอดนิยม
- เป็นไปได้
- ชอบ
- นำเสนอ
- นำเสนอ
- ราคา
- หลัก
- ก่อน
- ความน่าจะเป็น
- ปัญหา
- กระบวนการ
- อาชีพ
- โครงการ
- ข้อมูลโครงการ
- เงื้อม
- โครงการ
- คุณสมบัติ
- ให้
- ให้
- ให้
- การตีพิมพ์
- สุ่ม
- พิสัย
- จริง
- โลกแห่งความจริง
- เหตุผล
- การฟื้นตัว
- ภูมิภาค
- ความสัมพันธ์
- การซ่อมแซม
- แทนที่
- การแสดง
- แสดงให้เห็นถึง
- ต้อง
- ผล
- ส่งผลให้
- ผลสอบ
- แข็งแรง
- เดียวกัน
- วิทยาศาสตร์
- มีความละเอียดอ่อน
- แยก
- แสดง
- ซิกม่า
- คล้ายคลึงกัน
- ตั้งแต่
- เดียว
- ขนาด
- เล็ก
- มีขนาดเล็กกว่า
- So
- ช่องว่าง
- โดยเฉพาะ
- เริ่มต้น
- ยังคง
- อย่างเช่น
- ทนทุกข์ทรมาน
- เหมาะสม
- สนับสนุน
- พื้นผิว
- สังเคราะห์
- ระบบ
- ตาราง
- Takeaways
- เงื่อนไขการใช้บริการ
- พื้นที่
- โลก
- ดังนั้น
- ธรณีประตู
- อย่างแน่นหนา
- ต้องใช้เวลามาก
- ไปยัง
- รวม
- รถไฟ
- การฝึกอบรม
- เข้าใจ
- ความเข้าใจ
- เป็นเอกลักษณ์
- หน่วย
- การเรียนรู้โดยไม่ได้รับการดูแล
- ให้กับคุณ
- us
- ใช้
- ความคุ้มค่า
- ความคุ้มค่า
- พาหนะ
- ยานพาหนะ
- น้ำหนัก
- อะไร
- ความหมายของ
- ที่
- ในขณะที่
- จะ
- คำ
- คำ
- งาน
- โลก
- จะ
- ปี
- ลมทะเล