1ศูนย์เทคโนโลยีควอนตัม มหาวิทยาลัยแห่งชาติสิงคโปร์ ประเทศสิงคโปร์
2ภาควิชาวิศวกรรมไฟฟ้าและคอมพิวเตอร์ คณะวิศวกรรมศาสตร์ National University of Singapore ประเทศสิงคโปร์
พบบทความนี้ที่น่าสนใจหรือต้องการหารือ? Scite หรือแสดงความคิดเห็นใน SciRate.
นามธรรม
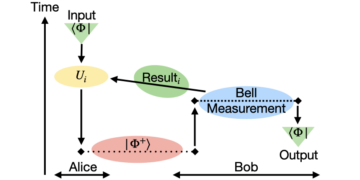
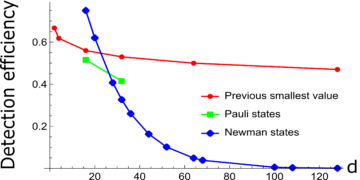
เราเริ่มต้นการศึกษาการแลกเปลี่ยนระหว่างการสำรวจและการแสวงประโยชน์ในการเรียนรู้ออนไลน์เกี่ยวกับคุณสมบัติของสถานะควอนตัม เมื่อให้สิทธิ์ Oracle เข้าถึงสถานะควอนตัมที่ไม่รู้จักตามลำดับ ในแต่ละรอบ เราได้รับมอบหมายให้เลือกสิ่งที่สังเกตได้จากชุดของการกระทำที่มีเป้าหมายเพื่อเพิ่มมูลค่าความคาดหวังสูงสุดต่อสถานะ (รางวัล) ข้อมูลที่ได้รับเกี่ยวกับสถานะที่ไม่รู้จักจากรอบที่แล้วสามารถนำมาใช้เพื่อค่อยๆ ปรับปรุงทางเลือกของการกระทำ ซึ่งจะช่วยลดช่องว่างระหว่างรางวัลและรางวัลสูงสุดที่ได้รับจากชุดการกระทำที่กำหนด (ความเสียใจ) เราให้ขอบเขตล่างตามทฤษฎีของข้อมูลต่างๆ เกี่ยวกับความเสียใจสะสมที่ผู้เรียนที่ดีที่สุดต้องเผชิญ และแสดงให้เห็นว่าอย่างน้อยต้องปรับขนาดเป็นรากที่สองของจำนวนรอบที่เล่น นอกจากนี้ เรายังตรวจสอบการพึ่งพาอาศัยกันของความเสียใจสะสมกับจำนวนการกระทำที่มีอยู่และมิติของช่องว่างที่แฝงอยู่ นอกจากนี้ เรายังจัดแสดงกลยุทธ์ที่เหมาะสมที่สุดสำหรับกลุ่มโจรที่มีจำนวนอาวุธจำกัดและสถานะผสมทั่วไป
[เนื้อหาฝัง]
► ข้อมูล BibTeX
► ข้อมูลอ้างอิง
[1] T. Lattimore และ C. Szepesvári “อัลกอริทึมโจร”. สำนักพิมพ์มหาวิทยาลัยเคมบริดจ์. (2020).
https://doi.org/10.1017/9781108571401
[2] อ. สลิฟกินส์. “ความรู้เบื้องต้นเกี่ยวกับกลุ่มโจรติดอาวุธหลายมือ”. รากฐานและแนวโน้มในการเรียนรู้ของเครื่อง 12, 1–286 (2019)
https://doi.org/10.1561/2200000068
[3] S. Bubeck และ N. Cesa-Bianchi “การวิเคราะห์ความเสียใจของปัญหาโจรติดอาวุธหลายกลุ่มทั้งแบบสุ่มและไม่สุ่ม” รากฐานและแนวโน้มในการเรียนรู้ของเครื่อง 5, 1–122 (2012)
https://doi.org/10.1561/2200000024
[4] D. Bouneffouf, I. Rish และ C. Aggarwal “การสำรวจการใช้งานกลุ่มโจรหลายอาวุธและบริบท”. ในปี 2020 IEEE Congress on Evolutionary Computation (CEC) หน้า 1–8. (2020).
https://doi.org/10.1109/CEC48606.2020.9185782
[5] L. Tang, R. Rosales, A. Singh และ D. Agarwal “การเลือกรูปแบบโฆษณาอัตโนมัติผ่านโจรตามบริบท” ในรายงานการประชุม ACM International Conference on Information and Knowledge Management ครั้งที่ 22 หน้า 1587–1594. สมาคมเพื่อคอมพิวเตอร์ (2013).
https://doi.org/10.1145/2505515.2514700
[6] M. Cohen, I. Lobel และ R. Paes Leme “การกำหนดราคาแบบไดนามิกตามคุณลักษณะ” วิทยาการจัดการ 66, 4921–4943 (2020).
https://doi.org/10.1287/mnsc.2019.3485
[7] ว. ทอมป์สัน. “ในความน่าจะเป็นที่ความน่าจะเป็นที่ไม่ทราบค่าหนึ่งมีค่ามากกว่าอีกค่าหนึ่งเมื่อพิจารณาจากหลักฐานของสองตัวอย่าง” Biometrika 25, 285–294 (1933)
https://doi.org/10.1093/biomet/25.3-4.285
[8] เอช. ร็อบบินส์ “ลักษณะบางประการของการออกแบบการทดลองตามลำดับ”. แถลงการณ์ของ American Mathematical Society 58, 527–535 (1952)
https://doi.org/10.1090/S0002-9904-1952-09620-8
[9] TL Lai และ H. Robbins “กฎการจัดสรรแบบปรับได้ที่มีประสิทธิภาพเชิงเส้นกำกับ” ความก้าวหน้าทางคณิตศาสตร์ประยุกต์ 6, 4–22 (1985).
https://doi.org/10.1016/0196-8858(85)90002-8
[10] P. Auer, N. Cesa-Bianchi และ P. Fischer “การวิเคราะห์ปัญหากลุ่มโจรหลายอาวุธแบบจำกัดเวลา”. เครื่องจักร เรียนรู้. 47, 235–256 (2002).
https://doi.org/10.1023/A:1013689704352
[11] B. Casale, G. Di Molfetta, H. Kadri, และ L. Ralaivola "กลุ่มโจรควอนตัม" ควอนตัมแมช อินเทล. 2 (2020).
https://doi.org/10.1007/s42484-020-00024-8
[12] D. Wang, X. You, T. Li และ A. Childs “อัลกอริธึมการสำรวจควอนตัมสำหรับกลุ่มโจรติดอาวุธ” ในรายงานการประชุม AAAI เรื่องปัญญาประดิษฐ์ เล่มที่ 35 หน้า 10102–10110 (2021).
[13] P. Rebentrost, Y. Hamoudi, M. Ray, X. Wang, S. Yang และ M. Santha “อัลกอริธึมควอนตัมสำหรับการป้องกันความเสี่ยงและการเรียนรู้แบบจำลองไอซิง” ฟิสิกส์ รายได้ ก 103, 012418 (2021)
https://doi.org/10.1103/PhysRevA.103.012418
[14] โอชามีร์ “ความซับซ้อนของการเพิ่มประสิทธิภาพเชิงเส้นของโจร”. ใน รายงานการประชุมวิชาการทฤษฎีการเรียนรู้ ครั้งที่ 28. เล่มที่ 40 ของ Proceedings of Machine Learning Research, หน้า 1523–1551 พีเอ็มแอลอาร์ (2015).
[15] P. Rusmevichientong และ J. Tsitsiklis “กลุ่มโจรที่ปรับพารามิเตอร์เชิงเส้น”. คณิตศาสตร์วิจัยปฏิบัติการ 35 (2008).
https://doi.org/10.1287/moor.1100.0446
[16] เจ. แบร์รี่, ดี.ที. แบร์รี่ และ เอส. แอรอนสัน “กระบวนการตัดสินใจมาร์คอฟที่สังเกตได้บางส่วนควอนตัม” ฟิสิกส์ รายได้ ก 90, 032311 (2014).
https://doi.org/10.1103/PhysRevA.90.032311
[17] ม. หญิง, ย. เฟิง และ ส. หญิง “นโยบายที่เหมาะสมที่สุดสำหรับกระบวนการตัดสินใจของควอนตัมมาร์คอฟ” International Journal of Automation and Computing 18, 410–421 (2021)
https://doi.org/10.1007/s11633-021-1278-z
[18] M. Paris และ J. Rehacek “การประมาณสถานะควอนตัม”. บริษัท สำนักพิมพ์สปริงเกอร์ จำกัด (2010). พิมพ์ครั้งที่ 1.
https://doi.org/10.1007/b98673
[19] ส.แอรอนสัน. "เอกซเรย์เงาของรัฐควอนตัม" ในการประชุมวิชาการ ACM SIGACT ประจำปีครั้งที่ 50 เรื่องทฤษฎีคอมพิวเตอร์ หน้า 325–338. STOC 2018. สมาคมเพื่อคอมพิวเตอร์ (2018).
https://doi.org/10.1145/3188745.3188802
[20] S. Aaronson, X. Chen, E. Hazan, S. Kale และ A. Nayak “การเรียนรู้สถานะควอนตัมออนไลน์”. วารสารกลศาสตร์สถิติ: ทฤษฎีและการทดลอง 2019 (2018).
https://doi.org/10.1088/1742-5468/ab3988
[21] J. Bretagnolle และ C. Huber “Estimation des densités: risque minimax”. Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebiete 47, 119–137 (1979)
https://doi.org/10.1007/BF00535278
[22] M. Müller-Lennert, F. Dupuis, O. Szehr, S. Fehr และ M. Tomamichel “เกี่ยวกับเอนโทรปีของ Quantum Rényi: การวางแนวใหม่และคุณสมบัติบางอย่าง” วารสารคณิตศาสตร์ฟิสิกส์ 54, 122203 (2013).
https://doi.org/10.1063/1.4838856
[23] M. Wilde, A. Winter และ D. Yang “การสนทนาที่แข็งแกร่งสำหรับความสามารถแบบคลาสสิกของการพัวพัน-การทำลายและแชนเนล Hadamard ผ่านเอนโทรปีสัมพัทธ์ Rényi แบบแซนด์วิช” การสื่อสารในฟิสิกส์คณิตศาสตร์ 331, 593–622 (2014)
https://doi.org/10.1007/s00220-014-2122-x
[24] ว. โฮฟดิง. “อสมการความน่าจะเป็นสำหรับผลบวกของตัวแปรสุ่มที่มีขอบเขต”. วารสารสมาคมสถิติอเมริกัน 58, 13–30 (1963)
https://doi.org/10.1080/01621459.1963.10500830
[25] พี. เออร์. “การใช้ขอบเขตความเชื่อมั่นสำหรับการแสวงหาผลประโยชน์-การสำรวจการแลกเปลี่ยน”. เจ มัค เรียนรู้. ความละเอียด 3, 397–422 (2003).
https://doi.org/10.5555/944919.944941
[26] D. Varsha, T. Hayes และ S.Kakade “การเพิ่มประสิทธิภาพเชิงเส้นสุ่มภายใต้ความคิดเห็นของโจร” ใน รายงานการประชุมวิชาการทฤษฎีการเรียนรู้ ครั้งที่ 21. หน้า 355–366. (2008).
[27] พี. รุสเมวิเชียรทอง และ เจ.เอ็น. ซิตซิคลิส. “กลุ่มโจรที่ปรับพารามิเตอร์เชิงเส้น”. คณิตศาสตร์วิจัยปฏิบัติการ 35, 395–411 (2010).
https://doi.org/10.1287/moor.1100.0446
[28] Y. Abbasi-Yadkori, D. Pál และ Cs. เซเปสวารี. “ปรับปรุงอัลกอริทึมสำหรับโจรสุ่มเชิงเส้น” ในความก้าวหน้าในระบบประมวลผลข้อมูลประสาท เล่มที่ 24 Curran Associates, Inc. (2011)
[29] ที.แอล.ลาย. “การจัดสรรการรักษาแบบปรับตัวกับปัญหากลุ่มโจรติดอาวุธ”. พงศาวดารของสถิติ 15, 1091 – 1114 (1987)
https://doi.org/10.1214/aos/1176350495
[30] M. Guţă, J. Kahn, R. Kueng และ JA Tropp “การตรวจเอกซเรย์แบบด่วนที่มีขอบเขตข้อผิดพลาดที่เหมาะสมที่สุด” วารสารฟิสิกส์ A: คณิตศาสตร์และทฤษฎี 53, 204001 (2020).
https://doi.org/10.1088/1751-8121/ab8111
[31] T. Lattimore และ B. Hao “การดึงเฟสโจร”. ในความก้าวหน้าในระบบประมวลผลข้อมูลประสาท เล่มที่ 34 หน้า 18801–18811 Curran Associates, Inc. (2021)
อ้างโดย
[1] Zongqi Wan, Zhijie Zhang, Tongyang Li, Jialin Zhang และ Xiaoming Sun, “Quantum Multi-Armed Bandits และ Stochastic Linear Bandits Enjoys Logarithmic Regrets”, arXiv: 2205.14988.
[2] Xinyi Chen, Elad Hazan, Tongyang Li, Zhou Lu, Xinzhao Wang และ Rui Yang, “การเรียนรู้ออนไลน์แบบปรับตัวของสถานะควอนตัม”, arXiv: 2206.00220.
การอ้างอิงข้างต้นมาจาก are อบต./นาซ่าโฆษณา (ปรับปรุงล่าสุดสำเร็จ 2022-07-24 00:26:50 น.) รายการอาจไม่สมบูรณ์เนื่องจากผู้จัดพิมพ์บางรายไม่ได้ให้ข้อมูลอ้างอิงที่เหมาะสมและครบถ้วน
On บริการอ้างอิงของ Crossref ไม่พบข้อมูลอ้างอิงงาน (ความพยายามครั้งสุดท้าย 2022-07-24 00:26:48)
บทความนี้เผยแพร่ใน Quantum ภายใต้ the ครีเอทีฟคอมมอนส์แบบแสดงที่มา 4.0 สากล (CC BY 4.0) ใบอนุญาต ลิขสิทธิ์ยังคงอยู่กับผู้ถือลิขสิทธิ์ดั้งเดิม เช่น ผู้เขียนหรือสถาบันของพวกเขา