Gartner, Inc. ประมาณการว่า ค่าใช้จ่ายข้อมูลที่ไม่ดี องค์กรโดยเฉลี่ย 12.9 ล้านเหรียญสหรัฐต่อปี
เราจัดการกับข้อมูลขนาดเพตะไบต์ทุกวัน และปัญหาด้านคุณภาพข้อมูลก็พบได้ทั่วไปกับข้อมูลปริมาณมหาศาลเช่นนี้ ข้อมูลที่ไม่ดีทำให้องค์กรต้องเสียเงิน ชื่อเสียง และเวลา ดังนั้นจึงเป็นเรื่องสำคัญมากที่จะต้องติดตามและตรวจสอบคุณภาพของข้อมูลอย่างต่อเนื่อง
ข้อมูลที่ไม่ดีรวมถึงข้อมูลที่ไม่ถูกต้อง ข้อมูลขาดหายไป ข้อมูลที่ไม่ถูกต้อง ข้อมูลที่ไม่สอดคล้องกัน และข้อมูลซ้ำ ข้อมูลที่ไม่ถูกต้องจะส่งผลให้เกิดการวิเคราะห์ข้อมูลที่ไม่ถูกต้อง ส่งผลให้เกิดการตัดสินใจที่ไม่ดีและกลยุทธ์ที่ไม่มีประสิทธิภาพ
คุณภาพของข้อมูล Experian พบว่าบริษัทโดยเฉลี่ยสูญเสียรายได้ 12% เนื่องจากข้อมูลไม่เพียงพอ นอกจากเงินแล้ว บริษัทต่างๆ ยังสูญเสียเวลาโดยเปล่าประโยชน์อีกด้วย
การระบุความผิดปกติในข้อมูลก่อนการประมวลผลจะช่วยให้องค์กรได้รับข้อมูลเชิงลึกที่มีค่ามากขึ้นเกี่ยวกับพฤติกรรมของลูกค้าและช่วยลดค่าใช้จ่าย
ไลบรารีความคาดหวังที่ยอดเยี่ยมช่วยให้องค์กรตรวจสอบและยืนยันความผิดปกติดังกล่าวในข้อมูลด้วยกฎนอกกรอบมากกว่า 200 กฎที่พร้อมใช้งาน
Great Expectations เป็นไลบรารี Python แบบโอเพ่นซอร์สที่ช่วยเราในการตรวจสอบความถูกต้องของข้อมูล คาดหวังที่ดี ให้ชุดของวิธีการหรือฟังก์ชั่นที่จะ ช่วยวิศวกรข้อมูล ตรวจสอบชุดข้อมูลที่กำหนดอย่างรวดเร็ว
ในบทความนี้ เราจะพิจารณาขั้นตอนที่เกี่ยวข้องในการตรวจสอบความถูกต้องของข้อมูลโดยไลบรารี Great Expectations
GE เป็นเหมือนการทดสอบหน่วยสำหรับข้อมูล GE จัดเตรียมการยืนยันที่เรียกว่าความคาดหวังเพื่อใช้กฎบางอย่างกับข้อมูลภายใต้การทดสอบ ตัวอย่างเช่น ID/หมายเลขกรมธรรม์ไม่ควรว่างเปล่าสำหรับเอกสารกรมธรรม์ประกันภัย ในการตั้งค่าและดำเนินการ GE คุณต้องทำตามขั้นตอนด้านล่าง แม้ว่าจะมีหลายวิธีในการทำงานกับ GE (โดยใช้ CLI) แต่ฉันจะอธิบายวิธีการตั้งค่าแบบเป็นโปรแกรมในบทความนี้ ซอร์สโค้ดทั้งหมดที่อธิบายในบทความนี้มีอยู่ในนี้ repo GitHub.
ขั้นตอนที่ 1: ตั้งค่าการกำหนดค่าข้อมูล
GE มีแนวคิดของร้านค้า ร้านค้าไม่ได้เป็นเพียงตำแหน่งทางกายภาพบนดิสก์ที่สามารถจัดเก็บความคาดหวัง (กฎ/การยืนยัน) รายละเอียดการรัน รายละเอียดจุดตรวจ ผลการตรวจสอบ และเอกสารข้อมูล (ผลการตรวจสอบเวอร์ชัน HTML แบบคงที่) คลิกที่นี่ เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับร้านค้า
GE รองรับแบ็คเอนด์ของร้านค้าต่างๆ ในบทความนี้ เราใช้แบ็กเอนด์และค่าเริ่มต้นของที่เก็บไฟล์ GE รองรับระบบแบ็กเอนด์ของร้านค้าอื่นๆ เช่น AWS (Amazon Web Services) S3, Azure Blobs, PostgreSQL เป็นต้น อ้างอิงถึง รู้เพิ่มเติมเกี่ยวกับแบ็กเอนด์. ข้อมูลโค้ดด้านล่างแสดงการกำหนดค่าข้อมูลอย่างง่าย:
STORE_FOLDER = "/Users/saisyam/work/github/great-expectations-sample/ge_data"
#Setup data config
data_context_config = DataContextConfig( datasources = {}, store_backend_defaults = FilesystemStoreBackendDefaults(root_directory=STORE_FOLDER)
) context = BaseDataContext(project_config = data_context_config)
การกำหนดค่าด้านบนใช้แบ็กเอนด์ที่เก็บไฟล์โดยค่าเริ่มต้น GE จะสร้างโฟลเดอร์ที่จำเป็นโดยอัตโนมัติเพื่อเรียกใช้ความคาดหวัง เราจะเพิ่มแหล่งข้อมูลในขั้นตอนถัดไป
ขั้นตอนที่ 2: ตั้งค่าการกำหนดค่าแหล่งข้อมูล
GE รองรับแหล่งข้อมูลสามประเภท:
- นุ่น
- จุดประกาย
- SQLAlchemy
การกำหนดค่าแหล่งข้อมูลบอกให้ GE ใช้เครื่องมือการดำเนินการเฉพาะเพื่อประมวลผลชุดข้อมูลที่ให้มา ตัวอย่างเช่น หากคุณกำหนดค่าแหล่งข้อมูลของคุณให้ใช้เครื่องมือการดำเนินการของ Pandas คุณต้องจัดเตรียมเฟรมข้อมูลของ Pandas พร้อมข้อมูลให้กับ GE เพื่อดำเนินการตามความคาดหวังของคุณ ด้านล่างนี้เป็นตัวอย่างสำหรับการใช้ Pandas เป็นแหล่งข้อมูล:
datasource_config = { "name": "sales_datasource", "class_name": "Datasource", "module_name": "great_expectations.datasource", "execution_engine": { "module_name": "great_expectations.execution_engine", "class_name": "PandasExecutionEngine", }, "data_connectors": { "default_runtime_data_connector_name": { "class_name": "RuntimeDataConnector", "module_name": "great_expectations.datasource.data_connector", "batch_identifiers": ["default_identifier_name"], }, },
}
context.add_datasource(**datasource_config)
โปรดดูที่ เอกสารนี้ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับแหล่งข้อมูล
ขั้นตอนที่ 3: สร้างชุดความคาดหวังและเพิ่มความคาดหวัง
ขั้นตอนนี้เป็นส่วนสำคัญ ในขั้นตอนนี้ เราจะสร้างชุดและเพิ่มความคาดหวังให้กับชุด คุณสามารถพิจารณาชุดเป็นกลุ่มของความคาดหวังที่จะทำงานเป็นชุด ความคาดหวังที่เราสร้างขึ้นในที่นี้คือการตรวจสอบตัวอย่างรายงานการขาย คุณสามารถดาวน์โหลด sales.csv ไฟล์
ข้อมูลโค้ดด้านล่างแสดงวิธีสร้างชุดและเพิ่มความคาดหวัง เราจะเพิ่มความคาดหวังสองอย่างให้กับห้องสวีทของเรา
# Create expectations suite and add expectations
suite = context.create_expectation_suite(expectation_suite_name="sales_suite", overwrite_existing=True) expectation_config_1 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_in_set", kwargs={ "column": "product_group", "value_set": ["PG1", "PG2", "PG3", "PG4", "PG5", "PG6"] }
) suite.add_expectation(expectation_configuration=expectation_config_1) expectation_config_2 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_unique", kwargs={ "column": "id" }
) suite.add_expectation(expectation_configuration=expectation_config_2)
context.save_expectation_suite(suite, "sales_suite")
ความคาดหวังแรก “expect_column_values_to_be_in_set” ตรวจสอบว่าค่าของคอลัมน์ (กลุ่มผลิตภัณฑ์) เท่ากับค่าใดๆ ใน value_set ที่กำหนดหรือไม่ ความคาดหวังที่สองตรวจสอบว่าค่าคอลัมน์ "id" ไม่ซ้ำกันหรือไม่
เมื่อเพิ่มและบันทึกความคาดหวังแล้ว ตอนนี้เราสามารถเรียกใช้ความคาดหวังเหล่านี้ในชุดข้อมูลซึ่งเราจะเห็นในขั้นตอนที่ 4
ขั้นตอนที่ 4: โหลดและตรวจสอบข้อมูล
ในขั้นตอนนี้ เราจะโหลดไฟล์ CSV ของเราลงใน pandas.DataFrame และสร้างจุดตรวจสอบเพื่อเรียกใช้ความคาดหวังที่เราสร้างขึ้นด้านบน
# load and validate data
df = pd.read_csv("./sales.csv") batch_request = RuntimeBatchRequest( datasource_name="sales_datasource", data_connector_name="default_runtime_data_connector_name", data_asset_name="product_sales", runtime_parameters={"batch_data":df}, batch_identifiers={"default_identifier_name":"default_identifier"}
) checkpoint_config = { "name": "product_sales_checkpoint", "config_version": 1, "class_name":"SimpleCheckpoint", "expectation_suite_name": "sales_suite"
}
context.add_checkpoint(**checkpoint_config)
results = context.run_checkpoint( checkpoint_name="product_sales_checkpoint", validations=[ {"batch_request": batch_request} ]
)
เราสร้างคำขอเป็นชุดสำหรับข้อมูลของเรา โดยระบุชื่อแหล่งข้อมูล ซึ่งจะบอกให้ GE ใช้เครื่องมือดำเนินการเฉพาะ ในกรณีของเราคือ Pandas เราสร้างการกำหนดค่าจุดตรวจแล้วตรวจสอบคำขอแบทช์ของเรากับจุดตรวจสอบ คุณสามารถเพิ่มคำขอแบบกลุ่มได้หลายรายการหากความคาดหวังมีผลกับข้อมูลในชุดงานในจุดตรวจสอบเดียว เมธอด `run_checkpoint` ส่งคืนผลลัพธ์ในรูปแบบ JSON และสามารถใช้สำหรับการประมวลผลหรือการวิเคราะห์เพิ่มเติม
ผลสอบ
เมื่อเราดำเนินการตามความคาดหวังในชุดข้อมูลของเราแล้ว GE จะสร้างแดชบอร์ด HTML แบบคงที่พร้อมผลลัพธ์สำหรับจุดตรวจสอบของเรา ผลลัพธ์ประกอบด้วยจำนวนความคาดหวังที่ได้รับการประเมิน ความคาดหวังที่สำเร็จ ความคาดหวังที่ไม่สำเร็จ และเปอร์เซ็นต์ความสำเร็จ บันทึกใด ๆ ที่ไม่ตรงกับความคาดหวังที่กำหนดจะถูกเน้นบนหน้า ด้านล่างนี้เป็นตัวอย่างสำหรับการดำเนินการที่ประสบความสำเร็จ:
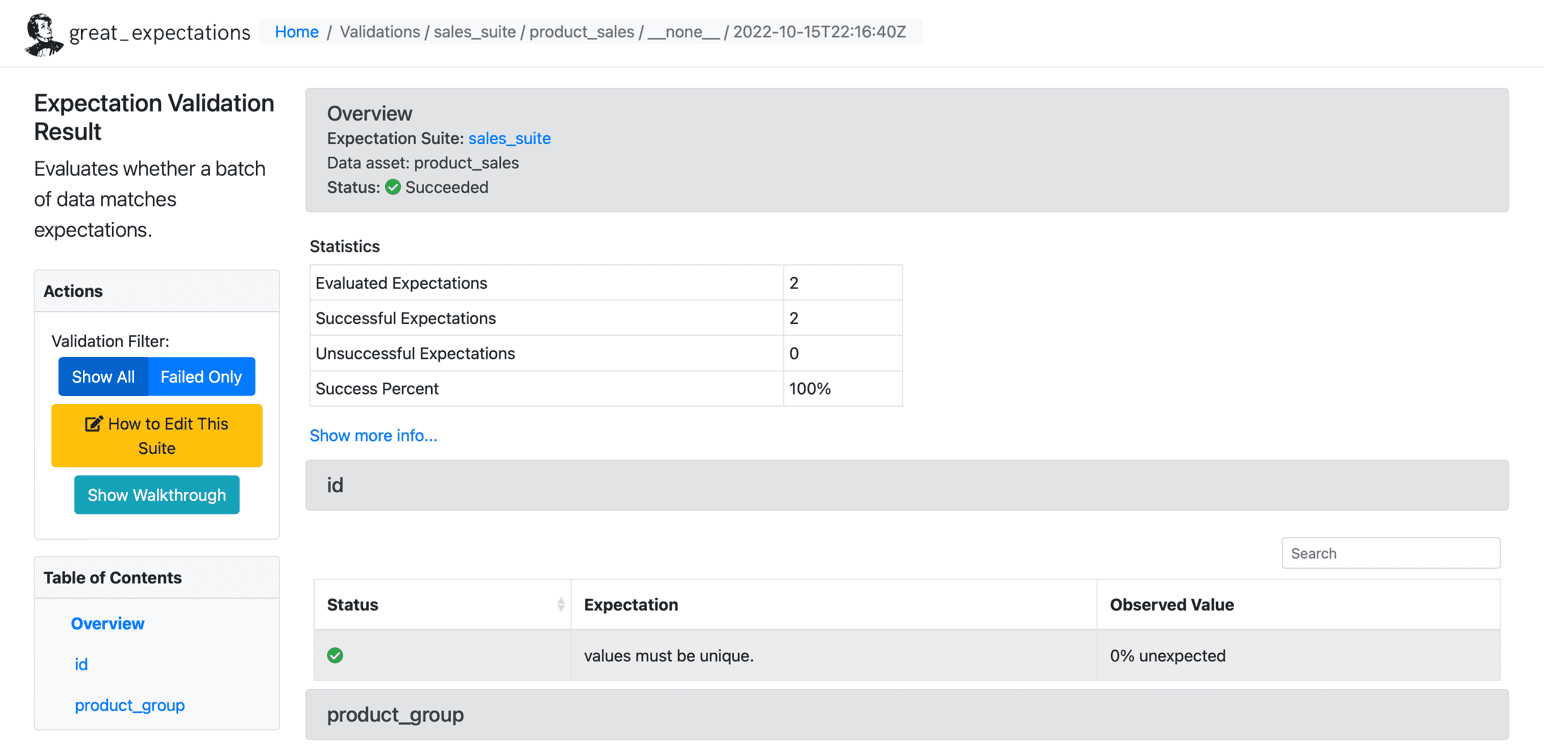
ที่มา: ความคาดหวังที่ยิ่งใหญ่
ด้านล่างนี้เป็นตัวอย่างของความคาดหวังที่ล้มเหลว:
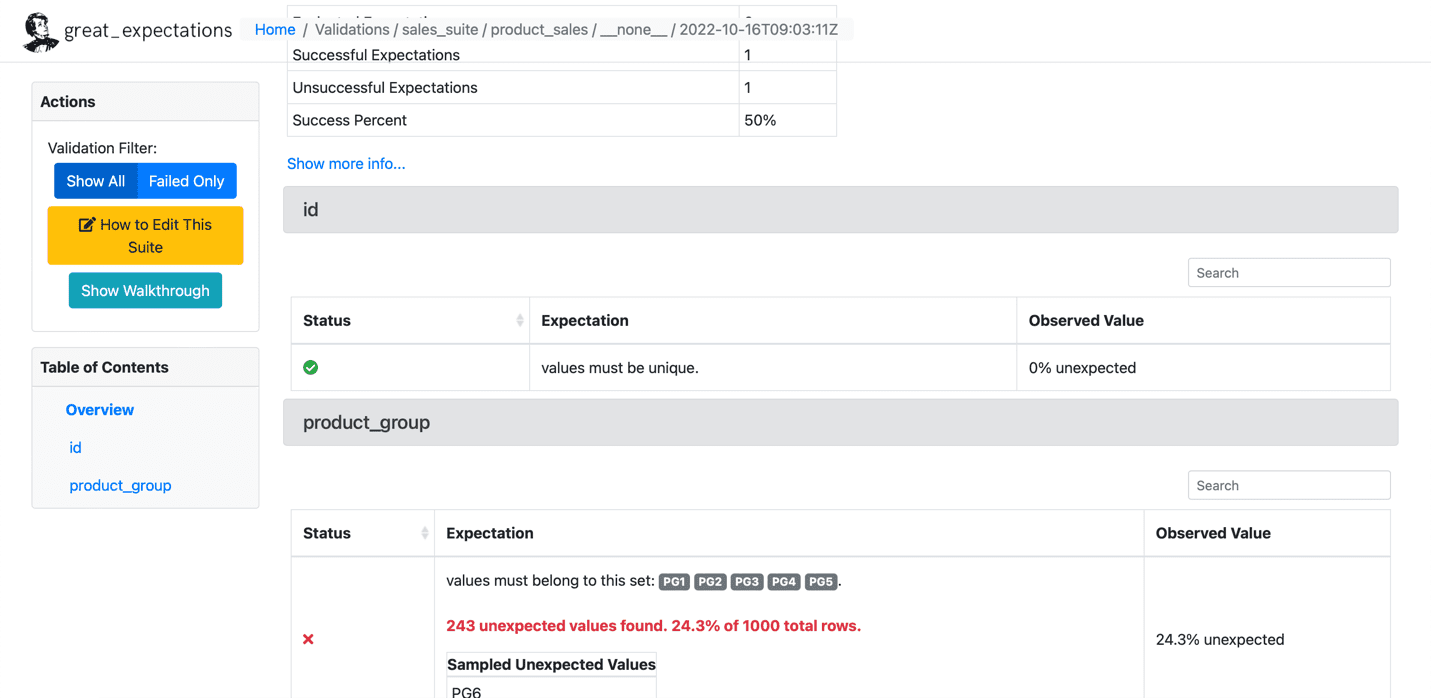
ที่มา: ความคาดหวังที่ยิ่งใหญ่
เราได้ตั้งค่า GE ในสี่ขั้นตอนและประสบความสำเร็จตามความคาดหวังในชุดข้อมูลที่กำหนด GE มีคุณลักษณะขั้นสูงเพิ่มเติม เช่น การเขียนความคาดหวังที่คุณกำหนดเอง ซึ่งเราจะกล่าวถึงในบทความต่อๆ ไป หลายองค์กรใช้ GE อย่างกว้างขวางเพื่อปรับแต่งความต้องการของลูกค้าและเขียนความคาดหวังที่กำหนดเอง
สายสยามดัมปุริ มาพร้อมกับประสบการณ์ในการพัฒนาซอฟต์แวร์มากกว่า 18 ปี และมีความกระตือรือร้นในการสำรวจเทคโนโลยีและเครื่องมือใหม่ๆ ปัจจุบันเขาทำงานเป็น Sr. Cloud Architect ที่ Anblicks, TX, US ในขณะที่ไม่ได้เขียนโค้ด เขาจะยุ่งอยู่กับการถ่ายภาพ ทำอาหาร และท่องเที่ยว
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/2023/01/overcome-data-quality-issues-great-expectations.html?utm_source=rss&utm_medium=rss&utm_campaign=overcome-your-data-quality-issues-with-great-expectations
- 1
- 11
- 18 +
- 9
- a
- เกี่ยวกับเรา
- ข้างบน
- ที่เพิ่ม
- สูง
- กับ
- ทั้งหมด
- อเมซอน
- Amazon Web Services
- การวิเคราะห์
- การวิเคราะห์
- และ
- นอกเหนือ
- ใช้
- บทความ
- บทความ
- อัตโนมัติ
- ใช้ได้
- เฉลี่ย
- AWS
- สีฟ้า
- แบ็กเอนด์
- ไม่ดี
- ข้อมูลไม่ดี
- ก่อน
- ด้านล่าง
- ที่เรียกว่า
- กรณี
- การตรวจสอบ
- ลูกค้า
- เมฆ
- รหัส
- การเข้ารหัส
- คอลัมน์
- ร่วมกัน
- บริษัท
- บริษัท
- แนวคิด
- องค์ประกอบ
- พิจารณา
- สิ่งแวดล้อม
- การปรุงอาหาร
- ค่าใช้จ่าย
- หน้าปก
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- สำคัญมาก
- ขณะนี้
- ประเพณี
- ลูกค้า
- พฤติกรรมของลูกค้า
- ปรับแต่ง
- ประจำวัน
- หน้าปัด
- ข้อมูล
- การวิเคราะห์ข้อมูล
- คุณภาพของข้อมูล
- ชุดข้อมูล
- จัดการ
- การตัดสินใจ
- ค่าเริ่มต้น
- รายละเอียด
- พัฒนาการ
- เอกสาร
- ดาวน์โหลด
- เครื่องยนต์
- ประมาณการ
- ฯลฯ
- อีเธอร์ (ETH)
- ประเมิน
- ตัวอย่าง
- ดำเนินการ
- การปฏิบัติ
- ความคาดหวัง
- ความคาดหวัง
- ประสบการณ์
- อธิบาย
- อธิบาย
- สำรวจ
- ล้มเหลว
- คุณสมบัติ
- เนื้อไม่มีมัน
- ชื่อจริง
- ปฏิบัติตาม
- ฟอร์บ
- รูป
- พบ
- FRAME
- ราคาเริ่มต้นที่
- ฟังก์ชั่น
- ต่อไป
- อนาคต
- ได้รับ
- ge
- กำหนด
- ยิ่งใหญ่
- บัญชีกลุ่ม
- ช่วย
- จะช่วยให้
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- ไฮไลต์
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTML
- HTTPS
- ใหญ่
- สำคัญ
- in
- ไม่เที่ยง
- อิงค์
- รวมถึง
- ข้อมูล
- ข้อมูลเชิงลึก
- ประกัน
- ร่วมมือ
- ปัญหา
- IT
- JSON
- KD นักเก็ต
- เรียนรู้
- ห้องสมุด
- โหลด
- ที่ตั้ง
- ดู
- สูญเสีย
- ปิด
- หลาย
- การจับคู่
- วิธี
- วิธีการ
- ล้าน
- หายไป
- เงิน
- การตรวจสอบ
- ข้อมูลเพิ่มเติม
- หลาย
- ชื่อ
- จำเป็น
- จำเป็นต้อง
- จำเป็น
- ใหม่
- เทคโนโลยีใหม่ ๆ
- ถัดไป
- จำนวน
- โอเพนซอร์ส
- องค์กร
- อื่นๆ
- เอาชนะ
- หมีแพนด้า
- ส่วนหนึ่ง
- หลงใหล
- การถ่ายภาพ
- กายภาพ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- นโยบาย
- postgresql
- กระบวนการ
- การประมวลผล
- การเขียนโปรแกรม
- ให้
- ให้
- ให้
- การให้
- หลาม
- คุณภาพ
- อย่างรวดเร็ว
- บันทึก
- ลดลง
- รายงาน
- ชื่อเสียง
- ขอ
- การร้องขอ
- ความต้องการ
- ผล
- ส่งผลให้
- ผลสอบ
- รับคืน
- รายได้
- กฎระเบียบ
- วิ่ง
- ขาย
- ที่สอง
- บริการ
- ชุด
- การตั้งค่า
- น่า
- แสดงให้เห็นว่า
- ง่าย
- เดียว
- ซอฟต์แวร์
- การพัฒนาซอฟต์แวร์
- บาง
- แหล่ง
- รหัสแหล่งที่มา
- แหล่งที่มา
- โดยเฉพาะ
- ขั้นตอน
- ขั้นตอน
- จัดเก็บ
- ร้านค้า
- กลยุทธ์
- ความสำเร็จ
- ที่ประสบความสำเร็จ
- ประสบความสำเร็จ
- อย่างเช่น
- ชุด
- รองรับ
- เทคโนโลยี
- บอก
- ทดสอบ
- การทดสอบ
- พื้นที่
- ที่มา
- ของพวกเขา
- สิ่ง
- สาม
- เวลา
- ไปยัง
- เครื่องมือ
- การเดินทาง
- TX
- ชนิด
- ภายใต้
- เป็นเอกลักษณ์
- หน่วย
- us
- USD
- ใช้
- ตรวจสอบความถูกต้อง
- การตรวจสอบ
- มีคุณค่า
- ความคุ้มค่า
- ต่างๆ
- ตรวจสอบ
- ไดรฟ์
- วิธี
- เว็บ
- บริการเว็บ
- ว่า
- ที่
- ในขณะที่
- จะ
- งาน
- การทำงาน
- เขียน
- การเขียน
- ปี
- ของคุณ
- ลมทะเล

![วิธีเพิ่มความเร็วการสืบค้น SQL โดยใช้ดัชนี [Python Edition] - KDnuggets](https://platoaistream.net/wp-content/uploads/2023/08/how-to-speed-up-sql-queries-using-indexes-python-edition-kdnuggets-360x203.png)





