ซีรีส์สามส่วนนี้สาธิตวิธีการใช้โครงข่ายประสาทเทียมแบบกราฟ (GNN) และ อเมซอนเนปจูน เพื่อสร้างคำแนะนำภาพยนตร์โดยใช้ IMDb และ Box Office Mojo Movies/TV/OTT แพ็คเกจข้อมูลที่สามารถขอลิขสิทธิ์ได้ ซึ่งให้ข้อมูลเมตาด้านความบันเทิงที่หลากหลาย รวมถึงการให้คะแนนของผู้ใช้มากกว่า 1 พันล้านรายการ เครดิตสำหรับนักแสดงและทีมงานกว่า 11 ล้านคน; ภาพยนตร์ ทีวี และความบันเทิง 9 ล้านเรื่อง; และข้อมูลการรายงานบ็อกซ์ออฟฟิศทั่วโลกจากกว่า 60 ประเทศ ลูกค้าสื่อและความบันเทิงของ AWS จำนวนมากอนุญาตให้ใช้ข้อมูล IMDb ผ่าน การแลกเปลี่ยนข้อมูล AWS เพื่อปรับปรุงการค้นพบเนื้อหาและเพิ่มการมีส่วนร่วมและการรักษาลูกค้า
In 1 หมายเลขเราได้พูดคุยเกี่ยวกับการประยุกต์ใช้ GNN และวิธีการแปลงและเตรียมข้อมูล IMDb สำหรับการสืบค้น ในโพสต์นี้ เราจะพูดถึงกระบวนการใช้ Neptune เพื่อสร้างการฝังที่ใช้ในการค้นหานอกแคตตาล็อกของเราในตอนที่ 3 เราก็ข้ามไปเช่นกัน อเมซอน ดาวเนปจูน MLฟีเจอร์แมชชีนเลิร์นนิง (ML) ของ Neptune และโค้ดที่เราใช้ในกระบวนการพัฒนาของเรา ในส่วนที่ 3 เราจะแนะนำวิธีการใช้การฝังกราฟความรู้ของเรากับกรณีการใช้งานการค้นหานอกแค็ตตาล็อก
ภาพรวมโซลูชัน
ชุดข้อมูลที่เชื่อมต่อกันขนาดใหญ่มักประกอบด้วยข้อมูลที่มีค่าซึ่งอาจเป็นเรื่องยากที่จะดึงออกมาโดยใช้การสืบค้นตามสัญชาตญาณของมนุษย์เพียงอย่างเดียว เทคนิค ML สามารถช่วยค้นหาความสัมพันธ์ที่ซ่อนอยู่ในกราฟที่มีความสัมพันธ์นับพันล้าน ความสัมพันธ์เหล่านี้มีประโยชน์ในการแนะนำผลิตภัณฑ์ ทำนายความน่าเชื่อถือของเครดิต ระบุการฉ้อโกง และกรณีการใช้งานอื่นๆ อีกมากมาย
Neptune ML ทำให้สามารถสร้างและฝึกโมเดล ML ที่เป็นประโยชน์บนกราฟขนาดใหญ่ได้ในเวลาไม่กี่ชั่วโมงแทนที่จะใช้เวลาเป็นสัปดาห์ เพื่อบรรลุสิ่งนี้ Neptune ML ใช้เทคโนโลยี GNN ที่ขับเคลื่อนโดย อเมซอน SageMaker และ ไลบรารีกราฟเชิงลึก (DGL) (ซึ่งเป็น โอเพนซอร์ส). GNN เป็นสาขาที่เกิดขึ้นใหม่ในปัญญาประดิษฐ์ (ดูตัวอย่าง การสำรวจที่ครอบคลุมเกี่ยวกับโครงข่ายประสาทกราฟ). สำหรับบทช่วยสอนภาคปฏิบัติเกี่ยวกับการใช้ GNN กับ DGL โปรดดู การเรียนรู้กราฟเครือข่ายประสาทด้วย Deep Graph Library.
ในโพสต์นี้ เราจะแสดงวิธีใช้ Neptune ในไปป์ไลน์ของเราเพื่อสร้างการฝัง
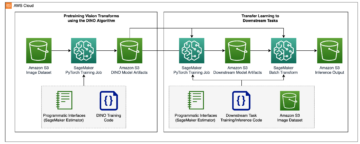
แผนภาพต่อไปนี้แสดงการไหลของข้อมูล IMDb โดยรวมตั้งแต่การดาวน์โหลดไปจนถึงการสร้างแบบฝัง
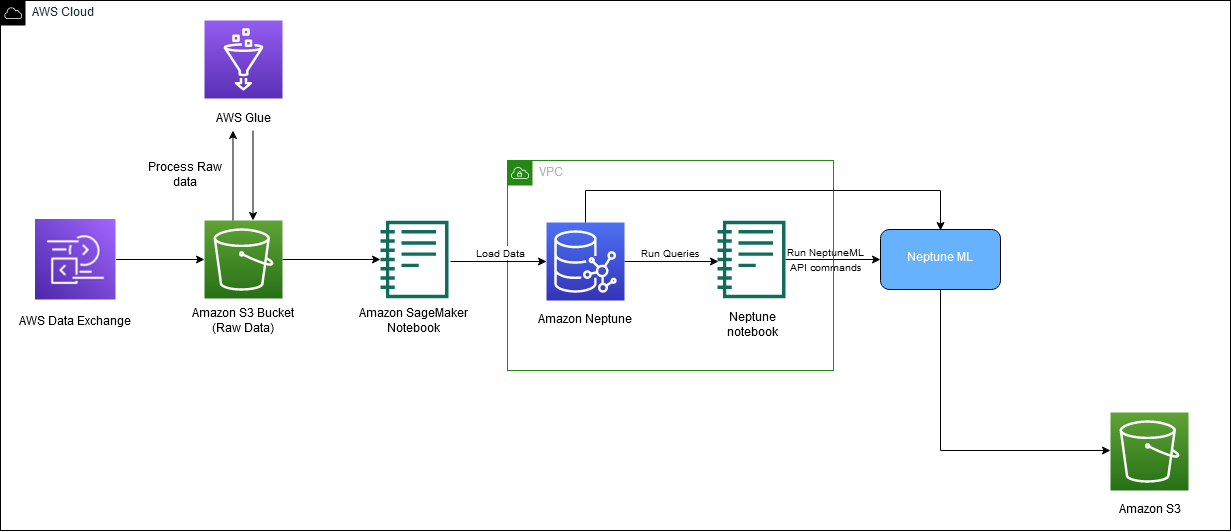
เราใช้บริการของ AWS ต่อไปนี้เพื่อปรับใช้โซลูชัน:
ในโพสต์นี้ เราจะแนะนำคุณเกี่ยวกับขั้นตอนระดับสูงต่อไปนี้:
- ตั้งค่าตัวแปรสภาพแวดล้อม
- สร้างงานส่งออก
- สร้างงานประมวลผลข้อมูล
- ส่งงานอบรม.
- ดาวน์โหลดการฝัง
รหัสสำหรับคำสั่ง Neptune ML
เราใช้คำสั่งต่อไปนี้เป็นส่วนหนึ่งของการนำโซลูชันนี้ไปใช้:
เราใช้ neptune_ml export เพื่อตรวจสอบสถานะหรือเริ่มกระบวนการส่งออก Neptune ML และ neptune_ml training เพื่อเริ่มต้นและตรวจสอบสถานะของงานฝึกอบรมโมเดล Neptune ML
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับคำสั่งเหล่านี้และคำสั่งอื่นๆ โปรดดูที่ ใช้ Neptune workbench magics ในสมุดบันทึกของคุณ.
เบื้องต้น
หากต้องการติดตามโพสต์นี้ คุณควรมีสิ่งต่อไปนี้:
- An บัญชี AWS
- ความคุ้นเคยกับ SageMaker, Amazon S3 และ AWS CloudFormation
- ข้อมูลกราฟที่โหลดลงในกระจุกดาวเนปจูน (ดู 1 หมายเลข สำหรับข้อมูลเพิ่มเติม)
ตั้งค่าตัวแปรสภาพแวดล้อม
ก่อนที่เราจะเริ่มต้น คุณจะต้องตั้งค่าสภาพแวดล้อมของคุณโดยตั้งค่าตัวแปรต่อไปนี้: s3_bucket_uri และ processed_folder. s3_bucket_uri เป็นชื่อของบัคเก็ตที่ใช้ในตอนที่ 1 และ processed_folder คือตำแหน่ง Amazon S3 สำหรับเอาต์พุตจากงานส่งออก
สร้างงานส่งออก
ในส่วนที่ 1 เราสร้างสมุดบันทึก SageMaker และบริการส่งออกเพื่อส่งออกข้อมูลของเราจากคลัสเตอร์ Neptune DB ไปยัง Amazon S3 ในรูปแบบที่จำเป็น
เมื่อโหลดข้อมูลของเราแล้ว และสร้างบริการส่งออกแล้ว เราต้องสร้างงานส่งออกเพื่อเริ่มต้น ในการทำเช่นนี้เราใช้ NeptuneExportApiUri และสร้างพารามิเตอร์สำหรับงานส่งออก ในโค้ดต่อไปนี้ เราใช้ตัวแปร expo และ export_params. ตั้งค่า expo เพื่อคุณ NeptuneExportApiUri มูลค่าที่คุณสามารถหาได้จาก Outputs แท็บของ CloudFormation stack ของคุณ สำหรับ export_paramsเราใช้จุดสิ้นสุดของคลัสเตอร์เนปจูนของคุณและระบุค่าสำหรับ outputS3pathซึ่งเป็นตำแหน่ง Amazon S3 สำหรับเอาต์พุตจากงานส่งออก
ในการส่งงานส่งออกให้ใช้คำสั่งต่อไปนี้:
ในการตรวจสอบสถานะของงานส่งออก ให้ใช้คำสั่งต่อไปนี้:
หลังจากงานของคุณเสร็จสิ้น ให้ตั้งค่า processed_folder ตัวแปรเพื่อให้ตำแหน่ง Amazon S3 ของผลลัพธ์ที่ประมวลผล:
สร้างงานประมวลผลข้อมูล
เมื่อส่งออกเสร็จแล้ว เราสร้างงานการประมวลผลข้อมูลเพื่อเตรียมข้อมูลสำหรับกระบวนการฝึกอบรม Neptune ML ซึ่งสามารถทำได้หลายวิธี สำหรับขั้นตอนนี้ คุณสามารถเปลี่ยน job_name และ modelType ตัวแปรต่าง ๆ แต่พารามิเตอร์อื่น ๆ จะต้องคงเดิมทั้งหมด ส่วนหลักของรหัสนี้คือ modelType พารามิเตอร์ ซึ่งสามารถเป็นแบบจำลองกราฟที่ต่างกัน (heterogeneous) หรือกราฟความรู้ (kge).
รวมถึงงานส่งออกด้วย training-data-configuration.json. ใช้ไฟล์นี้เพื่อเพิ่มหรือลบโหนดหรือขอบใดๆ ที่คุณไม่ต้องการให้สำหรับการฝึกอบรม (ตัวอย่างเช่น ถ้าคุณต้องการทำนายการเชื่อมโยงระหว่างสองโหนด คุณสามารถลบลิงก์นั้นในไฟล์การกำหนดค่านี้) สำหรับโพสต์บล็อกนี้ เราใช้ไฟล์การกำหนดค่าดั้งเดิม สำหรับข้อมูลเพิ่มเติม โปรดดูที่ การแก้ไขไฟล์คอนฟิกูเรชันการฝึก.
สร้างงานประมวลผลข้อมูลของคุณด้วยรหัสต่อไปนี้:
ในการตรวจสอบสถานะของงานส่งออก ให้ใช้คำสั่งต่อไปนี้:
ส่งงานอบรม
หลังจากงานประมวลผลเสร็จสิ้น เราสามารถเริ่มงานฝึกอบรมซึ่งเป็นที่ที่เราสร้างการฝังของเรา เราขอแนะนำอินสแตนซ์ประเภท ml.m5.24xlarge แต่คุณสามารถเปลี่ยนให้เหมาะกับความต้องการในการประมวลผลของคุณได้ ดูรหัสต่อไปนี้:
เราพิมพ์ตัวแปร training_results เพื่อรับ ID สำหรับงานฝึกอบรม ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบสถานะงานของคุณ:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
ดาวน์โหลดการฝัง
หลังจากงานฝึกอบรมของคุณเสร็จสิ้น ขั้นตอนสุดท้ายคือการดาวน์โหลดการฝังดิบของคุณ ขั้นตอนต่อไปนี้แสดงวิธีดาวน์โหลดการฝังที่สร้างโดยใช้ KGE (คุณสามารถใช้กระบวนการเดียวกันสำหรับ RGCN)
ในโค้ดต่อไปนี้ เราใช้ neptune_ml.get_mapping() และ get_embeddings() เพื่อดาวน์โหลดไฟล์แผนที่ (mapping.info) และไฟล์การฝังดิบ (entity.npy). จากนั้น เราจำเป็นต้องจับคู่การฝังที่เหมาะสมกับ ID ที่เกี่ยวข้อง
หากต้องการดาวน์โหลด RGCN ให้ทำตามขั้นตอนเดียวกันกับชื่องานการฝึกใหม่โดยประมวลผลข้อมูลโดยตั้งค่าพารามิเตอร์ modelType เป็น heterogeneousจากนั้นฝึกโมเดลของคุณโดยตั้งค่าพารามิเตอร์ modelName เป็น rgcn เห็น โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม สำหรับรายละเอียดเพิ่มเติม เสร็จแล้วโทร get_mapping และ get_embeddings ฟังก์ชั่นการดาวน์โหลดใหม่ของคุณ การทำแผนที่.ข้อมูล และ เอนทิตี.npy ไฟล์. หลังจากที่คุณมีเอนทิตีและไฟล์การแมปแล้ว กระบวนการสร้างไฟล์ CSV จะเหมือนกัน
สุดท้าย อัปโหลดการฝังของคุณไปยังตำแหน่ง Amazon S3 ที่คุณต้องการ:
ตรวจสอบให้แน่ใจว่าคุณจำตำแหน่ง S3 นี้ได้ คุณจะต้องใช้ตำแหน่งนี้ในตอนที่ 3
ทำความสะอาด
เมื่อคุณใช้โซลูชันเสร็จแล้ว อย่าลืมล้างทรัพยากรใดๆ เพื่อหลีกเลี่ยงค่าใช้จ่ายที่ต่อเนื่อง
สรุป
ในโพสต์นี้ เราได้กล่าวถึงวิธีใช้ Neptune ML เพื่อฝึกการฝัง GNN จากข้อมูล IMDb
การประยุกต์ใช้การฝังกราฟความรู้ที่เกี่ยวข้องบางส่วนเป็นแนวคิด เช่น การค้นหานอกแค็ตตาล็อก คำแนะนำเนื้อหา การโฆษณาที่ตรงเป้าหมาย การคาดคะเนลิงก์ที่ขาดหายไป การค้นหาทั่วไป และการวิเคราะห์ตามรุ่น การค้นหานอกแค็ตตาล็อกคือกระบวนการค้นหาเนื้อหาที่คุณไม่ได้เป็นเจ้าของ และค้นหาหรือแนะนำเนื้อหาที่อยู่ในแคตตาล็อกของคุณที่ใกล้เคียงกับสิ่งที่ผู้ใช้ค้นหามากที่สุด เราเจาะลึกการค้นหานอกแค็ตตาล็อกมากขึ้นในตอนที่ 3
เกี่ยวกับผู้เขียน
 แมทธิว โรดส์ เป็นนักวิทยาศาสตร์ข้อมูลที่ฉันทำงานใน Amazon ML Solutions Lab เขาเชี่ยวชาญในการสร้างท่อส่งแมชชีนเลิร์นนิงที่เกี่ยวข้องกับแนวคิดต่างๆ เช่น การประมวลผลภาษาธรรมชาติและการมองเห็นด้วยคอมพิวเตอร์
แมทธิว โรดส์ เป็นนักวิทยาศาสตร์ข้อมูลที่ฉันทำงานใน Amazon ML Solutions Lab เขาเชี่ยวชาญในการสร้างท่อส่งแมชชีนเลิร์นนิงที่เกี่ยวข้องกับแนวคิดต่างๆ เช่น การประมวลผลภาษาธรรมชาติและการมองเห็นด้วยคอมพิวเตอร์
 ดิวา ภาร์กาวี เป็นนักวิทยาศาสตร์ด้านข้อมูลและผู้นำด้านสื่อและความบันเทิงในแนวดิ่งที่ Amazon ML Solutions Lab ซึ่งเธอแก้ปัญหาทางธุรกิจที่มีมูลค่าสูงให้กับลูกค้า AWS โดยใช้แมชชีนเลิร์นนิง เธอทำงานเกี่ยวกับการทำความเข้าใจภาพ/วิดีโอ ระบบแนะนำกราฟความรู้ กรณีการใช้งานโฆษณาเชิงคาดการณ์
ดิวา ภาร์กาวี เป็นนักวิทยาศาสตร์ด้านข้อมูลและผู้นำด้านสื่อและความบันเทิงในแนวดิ่งที่ Amazon ML Solutions Lab ซึ่งเธอแก้ปัญหาทางธุรกิจที่มีมูลค่าสูงให้กับลูกค้า AWS โดยใช้แมชชีนเลิร์นนิง เธอทำงานเกี่ยวกับการทำความเข้าใจภาพ/วิดีโอ ระบบแนะนำกราฟความรู้ กรณีการใช้งานโฆษณาเชิงคาดการณ์
 เการาฟ เรเล เป็นนักวิทยาศาสตร์ข้อมูลที่ Amazon ML Solution Lab ซึ่งเขาทำงานร่วมกับลูกค้า AWS ในแนวดิ่งต่างๆ เพื่อเร่งการใช้แมชชีนเลิร์นนิงและบริการ AWS Cloud เพื่อแก้ปัญหาความท้าทายทางธุรกิจ
เการาฟ เรเล เป็นนักวิทยาศาสตร์ข้อมูลที่ Amazon ML Solution Lab ซึ่งเขาทำงานร่วมกับลูกค้า AWS ในแนวดิ่งต่างๆ เพื่อเร่งการใช้แมชชีนเลิร์นนิงและบริการ AWS Cloud เพื่อแก้ปัญหาความท้าทายทางธุรกิจ
 การัน สินด์วานี เป็นนักวิทยาศาสตร์ข้อมูลที่ Amazon ML Solutions Lab ซึ่งเขาสร้างและปรับใช้โมเดลการเรียนรู้เชิงลึก เขาเชี่ยวชาญในด้านคอมพิวเตอร์วิทัศน์ เวลาว่างชอบเดินป่า
การัน สินด์วานี เป็นนักวิทยาศาสตร์ข้อมูลที่ Amazon ML Solutions Lab ซึ่งเขาสร้างและปรับใช้โมเดลการเรียนรู้เชิงลึก เขาเชี่ยวชาญในด้านคอมพิวเตอร์วิทัศน์ เวลาว่างชอบเดินป่า
 โซจิ อาเดชินะ เป็นนักวิทยาศาสตร์ประยุกต์ที่ AWS ซึ่งเขาได้พัฒนาแบบจำลองกราฟเครือข่ายนิวรอลสำหรับแมชชีนเลิร์นนิงในงานเกี่ยวกับกราฟด้วยแอปพลิเคชันเพื่อการฉ้อโกงและการละเมิด กราฟความรู้ ระบบผู้แนะนำ และวิทยาศาสตร์เพื่อชีวิต ในเวลาว่าง เขาชอบอ่านหนังสือและทำอาหาร
โซจิ อาเดชินะ เป็นนักวิทยาศาสตร์ประยุกต์ที่ AWS ซึ่งเขาได้พัฒนาแบบจำลองกราฟเครือข่ายนิวรอลสำหรับแมชชีนเลิร์นนิงในงานเกี่ยวกับกราฟด้วยแอปพลิเคชันเพื่อการฉ้อโกงและการละเมิด กราฟความรู้ ระบบผู้แนะนำ และวิทยาศาสตร์เพื่อชีวิต ในเวลาว่าง เขาชอบอ่านหนังสือและทำอาหาร
 วิทยาสาคร รวิปาติ เป็นผู้จัดการที่ Amazon ML Solutions Lab ซึ่งเขาใช้ประสบการณ์มากมายในระบบแบบกระจายขนาดใหญ่และความหลงใหลในแมชชีนเลิร์นนิงเพื่อช่วยลูกค้า AWS ในอุตสาหกรรมประเภทต่างๆ เร่งการนำ AI และระบบคลาวด์ไปใช้
วิทยาสาคร รวิปาติ เป็นผู้จัดการที่ Amazon ML Solutions Lab ซึ่งเขาใช้ประสบการณ์มากมายในระบบแบบกระจายขนาดใหญ่และความหลงใหลในแมชชีนเลิร์นนิงเพื่อช่วยลูกค้า AWS ในอุตสาหกรรมประเภทต่างๆ เร่งการนำ AI และระบบคลาวด์ไปใช้
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- เกี่ยวกับเรา
- การล่วงละเมิด
- เร่งความเร็ว
- ข้าม
- เพิ่มเติม
- ข้อมูลเพิ่มเติม
- การนำมาใช้
- การโฆษณา
- หลังจาก
- AI
- ทั้งหมด
- คนเดียว
- อเมซอน
- ห้องปฏิบัติการโซลูชัน Amazon ML
- การวิเคราะห์
- และ
- การใช้งาน
- ประยุกต์
- ใช้
- เหมาะสม
- AREA
- เทียม
- ปัญญาประดิษฐ์
- AWS
- ตาม
- ระหว่าง
- พันล้าน
- พันล้าน
- บล็อก
- กล่อง
- บ็อกซ์ออฟฟิศ
- สร้าง
- การก่อสร้าง
- สร้าง
- ธุรกิจ
- โทรศัพท์
- กรณี
- กรณี
- แค็ตตาล็อก
- ความท้าทาย
- เปลี่ยนแปลง
- โหลด
- ตรวจสอบ
- ปิดหน้านี้
- เมฆ
- การยอมรับระบบคลาวด์
- บริการคลาวด์
- Cluster
- รหัส
- หมู่คน
- สมบูรณ์
- ครอบคลุม
- คอมพิวเตอร์
- วิสัยทัศน์คอมพิวเตอร์
- การคำนวณ
- แนวความคิด
- ความประพฤติ
- องค์ประกอบ
- งานที่เชื่อมต่อ
- เนื้อหา
- ตรงกัน
- ประเทศ
- สร้าง
- ที่สร้างขึ้น
- เครดิต
- เครดิต
- ลูกค้า
- การมีส่วนร่วมของลูกค้า
- ลูกค้า
- ข้อมูล
- การประมวลผล
- นักวิทยาศาสตร์ข้อมูล
- ชุดข้อมูล
- ลึก
- การเรียนรู้ลึก ๆ
- ลึก
- Deploys
- รายละเอียด
- พัฒนาการ
- พัฒนา
- ดีจีแอล
- ต่าง
- การค้นพบ
- สนทนา
- กล่าวถึง
- กระจาย
- ระบบกระจาย
- Dont
- ดาวน์โหลด
- ทั้ง
- กากกะรุน
- ปลายทาง
- มีส่วนร่วม
- ความบันเทิง
- เอกลักษณ์
- สิ่งแวดล้อม
- อีเธอร์ (ETH)
- ตัวอย่าง
- ประสบการณ์
- ส่งออก
- สารสกัด
- ลักษณะ
- สองสาม
- สนาม
- เนื้อไม่มีมัน
- ไฟล์
- หา
- หา
- ไหล
- ปฏิบัติตาม
- ดังต่อไปนี้
- รูป
- การหลอกลวง
- ราคาเริ่มต้นที่
- เต็ม
- ฟังก์ชั่น
- General
- สร้าง
- รุ่น
- ได้รับ
- เหตุการณ์ที่
- Go
- กราฟ
- กราฟ
- มือบน
- ยาก
- ช่วย
- เป็นประโยชน์
- ซ่อนเร้น
- ระดับสูง
- ชั่วโมง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTML
- HTTPS
- เป็นมนุษย์
- identiques
- ระบุ
- การดำเนินการ
- การดำเนินการ
- ปรับปรุง
- in
- รวมถึง
- รวมทั้ง
- เพิ่ม
- ดัชนี
- อุตสาหกรรม
- ข้อมูล
- ข้อมูล
- ตัวอย่าง
- แทน
- Intelligence
- รวมถึง
- IT
- การสัมภาษณ์
- JSON
- คีย์
- ความรู้
- ห้องปฏิบัติการ
- ภาษา
- ใหญ่
- ขนาดใหญ่
- ชื่อสกุล
- นำ
- การเรียนรู้
- ยกระดับ
- ห้องสมุด
- License
- ชีวิต
- วิทยาศาสตร์สิ่งมีชีวิต
- LINK
- การเชื่อมโยง
- ที่ตั้ง
- เครื่อง
- เรียนรู้เครื่อง
- หลัก
- ทำให้
- ผู้จัดการ
- หลาย
- แผนที่
- การทำแผนที่
- ภาพบรรยากาศ
- กลาง
- สมาชิก
- เมตาดาต้า
- ล้าน
- หายไป
- ML
- แบบ
- โมเดล
- ข้อมูลเพิ่มเติม
- หนัง
- ชื่อ
- โดยธรรมชาติ
- ประมวลผลภาษาธรรมชาติ
- จำเป็นต้อง
- ความต้องการ
- เกตุ
- ตามเครือข่าย
- เครือข่าย
- เครือข่ายประสาทเทียม
- ใหม่
- โหนด
- สมุดบันทึก
- Office
- ต่อเนื่อง
- เป็นต้นฉบับ
- อื่นๆ
- ทั้งหมด
- ของตนเอง
- แพ็คเกจ
- พารามิเตอร์
- พารามิเตอร์
- ส่วนหนึ่ง
- กิเลส
- ท่อ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เป็นไปได้
- โพสต์
- อำนาจ
- ขับเคลื่อน
- คาดการณ์
- ทำนาย
- เตรียมการ
- พิมพ์
- ปัญหาที่เกิดขึ้น
- กระบวนการ
- การประมวลผล
- ผลิตภัณฑ์
- โปรไฟล์
- ให้
- ให้
- พิสัย
- การให้คะแนน
- ดิบ
- การอ่าน
- แนะนำ
- แนะนำ
- แนะนำ
- แนะนำ
- ที่เกี่ยวข้อง
- ความสัมพันธ์
- ยังคง
- จำ
- เอาออก
- การรายงาน
- จำเป็นต้องใช้
- แหล่งข้อมูล
- ผลสอบ
- ความจำ
- sagemaker
- เดียวกัน
- วิทยาศาสตร์
- นักวิทยาศาสตร์
- ค้นหา
- ค้นหา
- ชุด
- บริการ
- บริการ
- ชุด
- การตั้งค่า
- น่า
- โชว์
- ทางออก
- โซลูชัน
- แก้
- แก้ปัญหา
- ความเชี่ยวชาญ
- กอง
- เริ่มต้น
- Status
- ขั้นตอน
- ขั้นตอน
- จัดเก็บ
- ส่ง
- อย่างเช่น
- สูท
- การสำรวจ
- ระบบ
- เป้าหมาย
- งาน
- เทคนิค
- เทคโนโลยี
- พื้นที่
- พื้นที่
- ของพวกเขา
- ตลอด
- เวลา
- ชื่อ
- ไปยัง
- รถไฟ
- การฝึกอบรม
- แปลง
- จริง
- เกี่ยวกับการสอน
- tv
- ความเข้าใจ
- ใช้
- ใช้กรณี
- ผู้ใช้งาน
- มีคุณค่า
- ความคุ้มค่า
- กว้างใหญ่
- รุ่น
- แนวดิ่ง
- วิสัยทัศน์
- วิธี
- สัปดาห์ที่ผ่านมา
- อะไร
- ที่
- กว้าง
- ช่วงกว้าง
- จะ
- การทำงาน
- โรงงาน
- ของคุณ
- ลมทะเล