การเตรียมข้อมูลเป็นองค์ประกอบหลักของไปป์ไลน์แมชชีนเลิร์นนิง (ML) ในความเป็นจริง ผู้เชี่ยวชาญด้านข้อมูลใช้เวลาประมาณ 80 เปอร์เซ็นต์ในการเตรียมข้อมูล ในตลาดที่มีการแข่งขันสูงนี้ ทีมต่างๆ ต้องการวิเคราะห์ข้อมูลและดึงข้อมูลเชิงลึกที่มีความหมายมากขึ้นอย่างรวดเร็ว ลูกค้ากำลังใช้วิธีที่มีประสิทธิภาพและเห็นภาพมากขึ้นในการสร้างระบบประมวลผลข้อมูล
Amazon SageMaker ข้อมูล Wrangler ลดความซับซ้อนของกระบวนการเตรียมข้อมูลและวิศวกรรมคุณลักษณะ ลดเวลาที่ใช้จากสัปดาห์เหลือเป็นนาทีด้วยการจัดเตรียมอินเทอร์เฟซแบบภาพเดียวสำหรับนักวิทยาศาสตร์ข้อมูลในการเลือก ล้างข้อมูล สร้างคุณลักษณะ และทำให้การเตรียมข้อมูลอัตโนมัติในเวิร์กโฟลว์ ML โดยไม่ต้องเขียนโค้ดใดๆ คุณสามารถนำเข้าข้อมูลจากแหล่งข้อมูลหลายแหล่ง เช่น บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3), อเมซอน อาเธน่า, อเมซอน Redshiftและเกล็ดหิมะ ตอนนี้คุณสามารถใช้ อเมซอน EMR เป็นแหล่งข้อมูลใน Data Wrangler เพื่อเตรียมข้อมูลสำหรับ ML อย่างง่ายดาย
การวิเคราะห์ การแปลง และการเตรียมข้อมูลจำนวนมากเป็นขั้นตอนพื้นฐานของวิทยาการข้อมูลและเวิร์กโฟลว์ ML ผู้เชี่ยวชาญด้านข้อมูลเช่นนักวิทยาศาสตร์ข้อมูลต้องการใช้ประโยชน์จากพลังของ Apache Spark, รังและ โอมเพี้ยง ทำงานบน Amazon EMR เพื่อการเตรียมข้อมูลที่รวดเร็ว แต่ช่วงการเรียนรู้สูงชัน ลูกค้าของเราต้องการความสามารถในการเชื่อมต่อกับ Amazon EMR เพื่อเรียกใช้การสืบค้น SQL แบบเฉพาะกิจบน Hive หรือ Presto เพื่อสืบค้นข้อมูลใน metastore ภายในหรือ metastore ภายนอก (เช่น AWS Glue Data Catalog) และเตรียมข้อมูลด้วยการคลิกเพียงไม่กี่ครั้ง
บทความในบล็อกนี้จะกล่าวถึงวิธีที่ลูกค้าสามารถค้นหาและเชื่อมต่อกับคลัสเตอร์ Amazon EMR ที่มีอยู่โดยใช้ประสบการณ์การมองเห็นใน SageMaker Data Wrangler พวกเขาสามารถตรวจสอบฐานข้อมูล ตาราง สคีมา และแบบสอบถาม Presto ด้วยภาพเพื่อเตรียมพร้อมสำหรับการสร้างแบบจำลองหรือการรายงาน จากนั้นพวกเขาสามารถทำโปรไฟล์ข้อมูลได้อย่างรวดเร็วโดยใช้อินเทอร์เฟซแบบภาพเพื่อประเมินคุณภาพข้อมูล ระบุความผิดปกติหรือข้อมูลที่ขาดหายไปหรือผิดพลาด และรับข้อมูลและคำแนะนำเกี่ยวกับวิธีการแก้ไขปัญหาเหล่านี้ นอกจากนี้ พวกเขายังสามารถวิเคราะห์ ทำความสะอาด และสร้างคุณสมบัติด้วยความช่วยเหลือจากการวิเคราะห์ในตัวเพิ่มเติมมากกว่าหนึ่งโหล และการแปลงในตัวเพิ่มเติมอีก 300+ รายการที่สนับสนุนโดย Spark โดยไม่ต้องเขียนโค้ดแม้แต่บรรทัดเดียว
ภาพรวมโซลูชัน
ผู้เชี่ยวชาญด้านข้อมูลสามารถค้นหาและเชื่อมต่อกับคลัสเตอร์ EMR ที่มีอยู่ได้อย่างรวดเร็วโดยใช้การกำหนดค่า SageMaker Studio นอกจากนี้ ผู้เชี่ยวชาญด้านข้อมูลสามารถยุติคลัสเตอร์ EMR ได้ด้วยการคลิกเพียงไม่กี่ครั้ง SageMaker Studio ใช้เทมเพลตที่กำหนดไว้ล่วงหน้าและการสร้างคลัสเตอร์ EMR ตามความต้องการ. ด้วยความช่วยเหลือของเครื่องมือเหล่านี้ ลูกค้าสามารถกระโดดเข้าสู่สมุดบันทึกอเนกประสงค์ SageMaker Studio และเขียนโค้ดใน Apache Spark, Hive, Presto หรือ PySpark เพื่อดำเนินการเตรียมข้อมูลตามขนาด เนื่องจากเส้นโค้งการเรียนรู้ที่สูงชันสำหรับการสร้างรหัส Spark เพื่อเตรียมข้อมูล ผู้เชี่ยวชาญด้านข้อมูลบางรายอาจไม่พอใจกับขั้นตอนนี้ ด้วย Amazon EMR เป็นแหล่งข้อมูลสำหรับ Amazon SageMaker Data Wrangler ตอนนี้คุณสามารถเชื่อมต่อกับ Amazon EMR ได้อย่างรวดเร็วและง่ายดายโดยไม่ต้องเขียนโค้ดแม้แต่บรรทัดเดียว
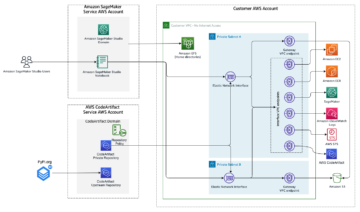
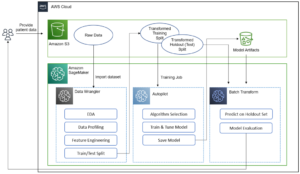
ไดอะแกรมต่อไปนี้แสดงถึงส่วนประกอบต่างๆ ที่ใช้ในโซลูชันนี้
เราสาธิตตัวเลือกการตรวจสอบสิทธิ์สองตัวเลือกที่สามารถใช้เพื่อสร้างการเชื่อมต่อกับคลัสเตอร์ EMR สำหรับแต่ละตัวเลือก เราปรับใช้สแต็คที่ไม่ซ้ำกัน การก่อตัวของ AWS Cloud แม่แบบ
เทมเพลต CloudFormation ดำเนินการต่อไปนี้เมื่อเลือกแต่ละตัวเลือก:
- สร้างโดเมน Studio ในโหมด VPC เท่านั้น พร้อมกับชื่อโปรไฟล์ผู้ใช้
studio-user. - สร้างบล็อคส่วนประกอบ รวมถึง VPC, จุดสิ้นสุด, เครือข่ายย่อย, กลุ่มความปลอดภัย, คลัสเตอร์ EMR และทรัพยากรที่จำเป็นอื่นๆ เพื่อให้เรียกใช้ตัวอย่างได้สำเร็จ
- สำหรับคลัสเตอร์ EMR ให้เชื่อมต่อ AWS Glue Data Catalog เป็น metastore สำหรับ EMR Hive และ Presto สร้างตาราง Hive ใน EMR และเติมข้อมูลจากชุดข้อมูลสนามบินของสหรัฐฯ
- สำหรับเทมเพลต LDAP CloudFormation ให้สร้างไฟล์ Amazon Elastic Compute Cloud (อเมซอน EC2) อินสแตนซ์เพื่อโฮสต์เซิร์ฟเวอร์ LDAP เพื่อตรวจสอบสิทธิ์ผู้ใช้ Hive และ Presto LDAP
ตัวเลือกที่ 1: โปรโตคอลไดเรกทอรีการเข้าถึงที่มีน้ำหนักเบา
สำหรับเทมเพลต CloudFormation การตรวจสอบสิทธิ์ LDAP เราจัดเตรียมอินสแตนซ์ Amazon EC2 ด้วยเซิร์ฟเวอร์ LDAP และกำหนดค่าคลัสเตอร์ EMR เพื่อใช้เซิร์ฟเวอร์นี้สำหรับการตรวจสอบสิทธิ์ นี่คือการเปิดใช้งาน TLS
ตัวเลือกที่ 2: ไม่รับรองความถูกต้อง
ในเทมเพลต CloudFormation การตรวจสอบสิทธิ์แบบไม่มีการตรวจสอบสิทธิ์ เราใช้คลัสเตอร์ EMR มาตรฐานที่ไม่ได้เปิดใช้งานการตรวจสอบสิทธิ์
ปรับใช้ทรัพยากรด้วย AWS CloudFormation
ทำตามขั้นตอนต่อไปนี้เพื่อปรับใช้สภาพแวดล้อม:
- เข้าสู่ระบบเพื่อ คอนโซลการจัดการ AWS ในฐานะที่เป็น AWS Identity และการจัดการการเข้าถึง (IAM) ผู้ใช้โดยเฉพาะอย่างยิ่งผู้ใช้ที่เป็นผู้ดูแลระบบ
- Choose เรียกใช้ Stack เพื่อเปิดใช้เทมเพลต CloudFormation สำหรับสถานการณ์การตรวจสอบสิทธิ์ที่เหมาะสม ตรวจสอบให้แน่ใจว่าภูมิภาคที่ใช้ในการปรับใช้ CloudFormation stack ไม่มี Studio Domain อยู่แล้ว หากคุณมีโดเมน Studio ในภูมิภาคใดภูมิภาคหนึ่งอยู่แล้ว คุณสามารถเลือกภูมิภาคอื่นได้
- สแต็กการเปิดตัว LDAP

- ไม่มีสแต็คเปิดใช้งานการรับรองความถูกต้อง

- สแต็กการเปิดตัว LDAP
- Choose ถัดไป.
- สำหรับ ชื่อกองป้อนชื่อสำหรับสแต็ก (เช่น
dw-emr-blog). - ปล่อยให้ค่าอื่นๆ เป็นค่าเริ่มต้น
- หากต้องการดำเนินการต่อ ให้เลือก ถัดไป จากหน้ารายละเอียดสแต็กและตัวเลือกสแต็ก สแตก LDAP ใช้ข้อมูลรับรองต่อไปนี้:
- ชื่อผู้ใช้:
david - รหัสผ่าน:
welcome123
- ชื่อผู้ใช้:
- ในหน้ารีวิว ให้เลือกช่องทำเครื่องหมายเพื่อยืนยันว่า AWS CloudFormation อาจสร้างทรัพยากร
- Choose สร้าง stack. รอจนกว่าสถานะของสแต็กจะเปลี่ยนจาก
CREATE_IN_PROGRESSไปยังCREATE_COMPLETE. กระบวนการนี้มักใช้เวลา 10–15 นาที

หมายเหตุ: หากคุณต้องการลองหลายกอง โปรดทำตามขั้นตอนในส่วนการล้างข้อมูล จำไว้ว่าคุณต้อง ลบโดเมน SageMaker Studio ก่อนที่สแต็กถัดไปจะเปิดได้สำเร็จ
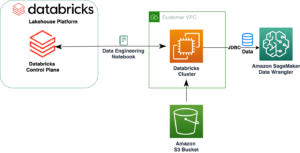
ตั้งค่า Amazon EMR เป็นแหล่งข้อมูลใน Data Wrangler
ในส่วนนี้ เราจะพูดถึงการเชื่อมต่อกับคลัสเตอร์ Amazon EMR ที่มีอยู่ซึ่งสร้างผ่านเทมเพลต CloudFormation เป็นแหล่งข้อมูลใน Data Wrangler
สร้างกระแสข้อมูลใหม่
ในการสร้างโฟลว์ข้อมูลของคุณ ให้ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล SageMaker ให้เลือก สตูดิโอ Amazon SageMaker ในบานหน้าต่างนำทาง
- Choose เปิดสตูดิโอ.
- ใน Launcher ให้เลือก การไหลของข้อมูลใหม่. หรืออีกทางหนึ่งบน เนื้อไม่มีมัน เมนูดรอปดาวน์ เลือก ใหม่ จากนั้นเลือก โฟลว์ Data Wrangler
- การสร้างโฟลว์ใหม่อาจใช้เวลาสักครู่ หลังจากสร้างโฟลว์แล้ว คุณจะเห็น นำเข้าข้อมูล หน้า.

เพิ่ม Amazon EMR เป็นแหล่งข้อมูลใน Data Wrangler
บนเมนู เพิ่มแหล่งข้อมูล ให้เลือก อเมซอน EMR.

คุณสามารถเรียกดูคลัสเตอร์ EMR ทั้งหมดที่บทบาทการดำเนินการของ Studio มีสิทธิ์ดู คุณมีสองตัวเลือกในการเชื่อมต่อกับคลัสเตอร์ หนึ่งคือผ่าน UI แบบโต้ตอบและอีกอันหนึ่งคือไปก่อน สร้างความลับโดยใช้ AWS Secrets Manager ด้วย JDBC URL รวมถึงข้อมูลคลัสเตอร์ EMR จากนั้นจัดเตรียม ARN ลับของ AWS ที่จัดเก็บไว้ใน UI เพื่อเชื่อมต่อกับ Presto ในบล็อกนี้ เราทำตามตัวเลือกแรก เลือกหนึ่งในคลัสเตอร์ต่อไปนี้ที่คุณต้องการใช้ คลิกที่ ถัดไปและเลือก ปลายทาง.

เลือก โอมเพี้ยง เชื่อมต่อกับ อเมซอน อีเอ็มอาร์ สร้างชื่อเพื่อระบุการเชื่อมต่อของคุณ แล้วคลิก ถัดไป

เลือก การยืนยันตัวตน พิมพ์ LDAP หรือ No Authentication แล้วคลิก เชื่อมต่อ.
- สำหรับ Lightweight Directory Access Protocol (LDAP) ให้ระบุชื่อผู้ใช้และรหัสผ่านที่จะตรวจสอบสิทธิ์


- คุณจะเชื่อมต่อกับ EMR Presto โดยไม่ต้องให้ข้อมูลรับรองผู้ใช้ภายใน VPC เข้าสู่หน้า SQL explorer ของ Data Wrangler สำหรับ EMR

เมื่อเชื่อมต่อแล้ว คุณสามารถดูโครงสร้างฐานข้อมูลและการแสดงตัวอย่างตารางหรือสคีมาแบบโต้ตอบได้ คุณยังสามารถค้นหา สำรวจ และแสดงข้อมูลเป็นภาพจาก EMR สำหรับการแสดงตัวอย่าง คุณจะเห็นขีดจำกัด 100 ระเบียนตามค่าเริ่มต้น สำหรับการสืบค้นที่กำหนดเอง คุณสามารถระบุคำสั่ง SQL ในกล่องตัวแก้ไขแบบสอบถาม และเมื่อคุณคลิก วิ่ง ปุ่ม การสืบค้นจะดำเนินการกับเครื่องมือ Presto ของ EMR

พื้นที่ ยกเลิกการสอบถาม ปุ่มช่วยให้สามารถยกเลิกการสืบค้นที่กำลังดำเนินอยู่หากใช้เวลานานผิดปกติ
ขั้นตอนสุดท้ายคือการนำเข้า เมื่อคุณพร้อมกับข้อมูลที่สอบถาม คุณมีตัวเลือกในการอัปเดตการตั้งค่าการสุ่มตัวอย่างสำหรับการเลือกข้อมูลตามประเภทการสุ่มตัวอย่าง (FirstK, Random หรือ Stratified) และขนาดการสุ่มตัวอย่างสำหรับการนำเข้าข้อมูลไปยัง Data Wrangler
คลิก นำเข้า. หน้าเตรียมจะถูกโหลด ทำให้คุณสามารถเพิ่มการแปลงและการวิเคราะห์ที่จำเป็นต่างๆ ลงในชุดข้อมูลได้

นำทางไปยัง DataFlow จากหน้าจอด้านบนและเพิ่มขั้นตอนเพิ่มเติมให้กับโฟลว์ตามความจำเป็นสำหรับการแปลงและการวิเคราะห์ คุณสามารถเรียกใช้รายงานข้อมูลเชิงลึกเพื่อระบุปัญหาด้านคุณภาพข้อมูลและรับคำแนะนำเพื่อแก้ไขปัญหาเหล่านั้น ลองดูตัวอย่างการแปลง
ไปที่ dataflow ของคุณ และนี่คือหน้าจอที่คุณควรเห็น แสดงให้เราเห็นว่าเรากำลังใช้ EMR เป็นแหล่งข้อมูลโดยใช้ตัวเชื่อมต่อ Presto

ให้คลิกที่ปุ่ม + ทางด้านขวาของประเภทข้อมูลแล้วเลือกเพิ่มการแปลง เมื่อคุณทำเช่นนั้น หน้าจอต่อไปนี้ควรปรากฏขึ้น:

มาสำรวจข้อมูลกัน เราเห็นว่ามีคุณสมบัติหลายอย่างเช่น iata_code, สนามบิน, เมือง, รัฐ, ประเทศ, ละติจูดและ ลองจิจูด. เราจะเห็นว่าชุดข้อมูลทั้งหมดอยู่ในประเทศเดียว ซึ่งก็คือสหรัฐอเมริกา และมีค่าที่หายไปในละติจูดและลองจิจูด ข้อมูลที่ขาดหายไปอาจทำให้เกิดอคติในการประมาณค่าพารามิเตอร์ และอาจลดความเป็นตัวแทนของตัวอย่างได้ ดังนั้น เราจำเป็นต้องดำเนินการบางอย่าง การใส่ความ และจัดการค่าที่หายไปในชุดข้อมูลของเรา

มาคลิกที่ เพิ่มขั้นตอน ปุ่มบนแถบนำทางด้านขวา เลือก จัดการหาย. การกำหนดค่าสามารถดูได้จากภาพหน้าจอต่อไปนี้ ภายใต้ แปลง, เลือก เปรต. เลือกประเภทคอลัมน์เป็น เป็นตัวเลข และชื่อคอลัมน์ ละติจูด และ ลองจิจูด. เราจะใส่ค่าที่ขาดหายไปโดยใช้ค่ามัธยฐานโดยประมาณ ดูตัวอย่างและเพิ่มการแปลง


ให้เราดูตัวอย่างการแปลงอื่น เมื่อสร้างโมเดลแมชชีนเลิร์นนิง คอลัมน์จะถูกลบออกหากซ้ำซ้อนหรือไม่ช่วยโมเดลของคุณ วิธีทั่วไปในการลบคอลัมน์คือการทิ้งคอลัมน์ ในชุดข้อมูลของเรา คุณลักษณะ ประเทศ สามารถทิ้งได้เนื่องจากชุดข้อมูลนี้มีไว้สำหรับข้อมูลสนามบินของสหรัฐอเมริกาโดยเฉพาะ มาดูกันว่าเราจะจัดการคอลัมน์ได้อย่างไร ลองคลิกที่ เพิ่มขั้นตอน ปุ่มบนแถบนำทางด้านขวา เลือก จัดการคอลัมน์. การกำหนดค่าสามารถดูได้จากภาพหน้าจอต่อไปนี้ ภายใต้ แปลงให้เลือก วางคอลัมน์และใต้ คอลัมน์ที่จะปล่อยให้เลือก ประเทศ.


คุณสามารถเพิ่มขั้นตอนต่อไปตามการแปลงต่างๆ ที่จำเป็นสำหรับชุดข้อมูลของคุณ ให้เรากลับไปที่การไหลของข้อมูลของเรา ตอนนี้คุณจะเห็นบล็อกอีกสองบล็อกที่แสดงการแปลงที่เราดำเนินการ ในสถานการณ์ของเรา คุณจะเห็น เปรต และ วางคอลัมน์.

ผู้ปฏิบัติงานด้าน ML ใช้เวลามากมายในการสร้างโค้ดวิศวกรรมฟีเจอร์ นำไปใช้กับชุดข้อมูลเริ่มต้น ฝึกโมเดลในชุดข้อมูลวิศวกรรม และประเมินความแม่นยำของโมเดล ด้วยลักษณะการทดลองของงานนี้ แม้แต่โครงการที่เล็กที่สุดก็ยังนำไปสู่การทำซ้ำหลายครั้ง โค้ดวิศวกรรมคุณลักษณะเดียวกันมักจะถูกรันซ้ำแล้วซ้ำอีก ทำให้เสียเวลาและทรัพยากรในการคำนวณจากการดำเนินการเดิมซ้ำๆ ในองค์กรขนาดใหญ่ สิ่งนี้สามารถทำให้เกิดการสูญเสียประสิทธิภาพการทำงานที่มากขึ้น เนื่องจากทีมต่างๆ มักจะเรียกใช้งานที่เหมือนกัน หรือแม้แต่เขียนโค้ดวิศวกรรมคุณลักษณะที่ซ้ำกัน เนื่องจากพวกเขาไม่มีความรู้ในการทำงานมาก่อน เพื่อหลีกเลี่ยงการประมวลผลคุณสมบัติซ้ำ ตอนนี้เราจะส่งออกคุณสมบัติที่แปลงแล้วของเราไปที่ ร้านค้าคุณลักษณะของ Amazon. ลองคลิกที่ + ทางด้านขวาของ วางคอลัมน์. เลือก ส่งออกไปที่ และเลือก Sagemaker Feature Store (ผ่านโน้ตบุ๊ก Jupyter).

คุณสามารถส่งออกคุณลักษณะที่คุณสร้างขึ้นได้อย่างง่ายดาย ที่เก็บฟีเจอร์ SageMaker โดยเลือกเป็นปลายทาง คุณสามารถบันทึกคุณลักษณะลงในกลุ่มคุณลักษณะที่มีอยู่หรือสร้างใหม่ได้


ตอนนี้เราได้สร้างฟีเจอร์ด้วย Data Wrangler และจัดเก็บฟีเจอร์เหล่านั้นใน Feature Store ได้อย่างง่ายดาย เราได้แสดงเวิร์กโฟลว์ตัวอย่างสำหรับวิศวกรรมฟีเจอร์ใน Data Wrangler UI จากนั้นเราได้บันทึกคุณลักษณะเหล่านั้นลงใน Feature Store โดยตรงจาก Data Wrangler โดยสร้างกลุ่มคุณลักษณะใหม่ สุดท้าย เราได้ดำเนินการประมวลผลเพื่อนำคุณสมบัติเหล่านั้นเข้าสู่ Feature Store Data Wrangler และ Feature Store ช่วยเราสร้างกระบวนการอัตโนมัติและทำซ้ำได้เพื่อปรับปรุงงานเตรียมข้อมูลของเราโดยต้องมีการเข้ารหัสขั้นต่ำ Data Wrangler ยังให้ความยืดหยุ่นแก่เราในการทำให้กระบวนการเตรียมข้อมูลเดียวกันเป็นไปโดยอัตโนมัติโดยใช้ งานที่กำหนด. นอกจากนี้ เรายังสามารถทำให้การฝึกอบรมหรือวิศวกรรมคุณลักษณะเป็นแบบอัตโนมัติด้วย SageMaker Pipelines (ผ่าน Jupyter Notebook) และปรับใช้กับจุดสิ้นสุดการอนุมานด้วยไปป์ไลน์การอนุมานของ SageMaker (ผ่าน Jupyter Notebook)

ทำความสะอาด
หากการทำงานกับ Data Wrangler ของคุณเสร็จสมบูรณ์ ให้เลือกสแต็คที่สร้างจากหน้า CloudFormation และลบออกเพื่อหลีกเลี่ยงการเสียค่าธรรมเนียมเพิ่มเติม
สรุป
ในโพสต์นี้ เราจะพูดถึงวิธีตั้งค่า Amazon EMR เป็นแหล่งข้อมูลใน Data Wrangler วิธีแปลงและวิเคราะห์ชุดข้อมูล และวิธีส่งออกผลลัพธ์ไปยังโฟลว์ข้อมูลเพื่อใช้ในโน้ตบุ๊ก Jupyter หลังจากแสดงภาพชุดข้อมูลของเราโดยใช้คุณสมบัติการวิเคราะห์ในตัวของ Data Wrangler แล้ว เราได้ปรับปรุงการไหลของข้อมูลของเราเพิ่มเติม การที่เราสร้างไปป์ไลน์การเตรียมข้อมูลโดยไม่เขียนโค้ดแม้แต่บรรทัดเดียวนั้นมีความสำคัญ
ในการเริ่มต้นใช้งาน Data Wrangler โปรดดูที่ เตรียมข้อมูล ML ด้วย Amazon SageMaker Data Wranglerและดูข้อมูลล่าสุดเกี่ยวกับ หน้าผลิตภัณฑ์ Data Wrangler.
เกี่ยวกับผู้แต่ง
 อาจารย์โกวินทราม เป็นสถาปนิกโซลูชันอาวุโสที่ AWS เขาทำงานร่วมกับลูกค้าเชิงกลยุทธ์ที่ใช้ AI/ML เพื่อแก้ปัญหาทางธุรกิจที่ซับซ้อน ประสบการณ์ของเขาอยู่ที่การให้คำแนะนำด้านเทคนิคตลอดจนความช่วยเหลือด้านการออกแบบสำหรับการปรับใช้แอปพลิเคชัน AI/ML ระดับปานกลางถึงขนาดใหญ่ ความรู้ของเขามีตั้งแต่สถาปัตยกรรมแอปพลิเคชันไปจนถึงข้อมูลขนาดใหญ่ การวิเคราะห์ และการเรียนรู้ของเครื่อง เขาชอบฟังเพลงขณะพักผ่อน สัมผัสประสบการณ์กลางแจ้ง และใช้เวลากับคนที่เขารัก
อาจารย์โกวินทราม เป็นสถาปนิกโซลูชันอาวุโสที่ AWS เขาทำงานร่วมกับลูกค้าเชิงกลยุทธ์ที่ใช้ AI/ML เพื่อแก้ปัญหาทางธุรกิจที่ซับซ้อน ประสบการณ์ของเขาอยู่ที่การให้คำแนะนำด้านเทคนิคตลอดจนความช่วยเหลือด้านการออกแบบสำหรับการปรับใช้แอปพลิเคชัน AI/ML ระดับปานกลางถึงขนาดใหญ่ ความรู้ของเขามีตั้งแต่สถาปัตยกรรมแอปพลิเคชันไปจนถึงข้อมูลขนาดใหญ่ การวิเคราะห์ และการเรียนรู้ของเครื่อง เขาชอบฟังเพลงขณะพักผ่อน สัมผัสประสบการณ์กลางแจ้ง และใช้เวลากับคนที่เขารัก
 อิชา ดุอา เป็นสถาปนิกโซลูชันอาวุโสที่ตั้งอยู่ในบริเวณอ่าวซานฟรานซิสโก เธอช่วยให้ลูกค้าระดับองค์กรของ AWS เติบโตขึ้นโดยเข้าใจเป้าหมายและความท้าทายของพวกเขา และแนะนำพวกเขาเกี่ยวกับวิธีที่พวกเขาสามารถออกแบบแอปพลิเคชันในลักษณะแบบเนทีฟบนคลาวด์ ในขณะเดียวกันก็ต้องแน่ใจว่าพวกเขามีความยืดหยุ่นและปรับขนาดได้ เธอหลงใหลเกี่ยวกับเทคโนโลยีแมชชีนเลิร์นนิงและความยั่งยืนของสิ่งแวดล้อม
อิชา ดุอา เป็นสถาปนิกโซลูชันอาวุโสที่ตั้งอยู่ในบริเวณอ่าวซานฟรานซิสโก เธอช่วยให้ลูกค้าระดับองค์กรของ AWS เติบโตขึ้นโดยเข้าใจเป้าหมายและความท้าทายของพวกเขา และแนะนำพวกเขาเกี่ยวกับวิธีที่พวกเขาสามารถออกแบบแอปพลิเคชันในลักษณะแบบเนทีฟบนคลาวด์ ในขณะเดียวกันก็ต้องแน่ใจว่าพวกเขามีความยืดหยุ่นและปรับขนาดได้ เธอหลงใหลเกี่ยวกับเทคโนโลยีแมชชีนเลิร์นนิงและความยั่งยืนของสิ่งแวดล้อม
 รุ่ยเจียง เป็นวิศวกรพัฒนาซอฟต์แวร์ที่ AWS ในเขตนิวยอร์กซิตี้ เธอเป็นสมาชิกของทีม SageMaker Data Wrangler ที่ช่วยพัฒนาโซลูชันทางวิศวกรรมสำหรับลูกค้าระดับองค์กรของ AWS เพื่อให้บรรลุความต้องการทางธุรกิจ นอกเวลางาน เธอชอบสำรวจอาหารใหม่ๆ ออกกำลังกายเพื่อชีวิต กิจกรรมกลางแจ้ง และท่องเที่ยว
รุ่ยเจียง เป็นวิศวกรพัฒนาซอฟต์แวร์ที่ AWS ในเขตนิวยอร์กซิตี้ เธอเป็นสมาชิกของทีม SageMaker Data Wrangler ที่ช่วยพัฒนาโซลูชันทางวิศวกรรมสำหรับลูกค้าระดับองค์กรของ AWS เพื่อให้บรรลุความต้องการทางธุรกิจ นอกเวลางาน เธอชอบสำรวจอาหารใหม่ๆ ออกกำลังกายเพื่อชีวิต กิจกรรมกลางแจ้ง และท่องเที่ยว
- AI
- ไอ อาร์ต
- เครื่องกำเนิดไออาร์ท
- หุ่นยนต์ไอ
- อเมซอน EMR
- อเมซอน SageMaker
- Amazon SageMaker ข้อมูล Wrangler
- การวิเคราะห์
- ปัญญาประดิษฐ์
- ใบรับรองปัญญาประดิษฐ์
- ปัญญาประดิษฐ์ในการธนาคาร
- หุ่นยนต์ปัญญาประดิษฐ์
- หุ่นยนต์ปัญญาประดิษฐ์
- ซอฟต์แวร์ปัญญาประดิษฐ์
- AWS Machine Learning AWS
- blockchain
- การประชุม blockchain ai
- เหรียญอัจฉริยะ
- ปัญญาประดิษฐ์สนทนา
- การประชุม crypto ai
- ดัล-อี
- การเรียนรู้ลึก ๆ
- google ai
- เรียนรู้เครื่อง
- เพลโต
- เพลโตไอ
- เพลโตดาต้าอินเทลลิเจนซ์
- เกมเพลโต
- เพลโตดาต้า
- เพลโตเกม
- ขนาดไอ
- วากยสัมพันธ์
- ลมทะเล