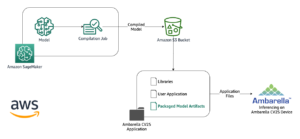
ในคอมพิวเตอร์วิทัศน์ การแบ่งส่วนความหมายเป็นงานของการจำแนกทุกพิกเซลในภาพด้วยคลาสจากชุดป้ายกำกับที่รู้จัก ซึ่งพิกเซลที่มีป้ายกำกับเดียวกันจะมีลักษณะเฉพาะร่วมกัน มันสร้างมาสก์การแบ่งส่วนของภาพอินพุต ตัวอย่างเช่น รูปภาพต่อไปนี้แสดงรูปแบบการแบ่งส่วนของ cat ฉลาก.
 |
 |
ในเดือนพฤศจิกายน 2018, อเมซอน SageMaker ประกาศเปิดตัวอัลกอริธึมการแบ่งส่วนความหมายของ SageMaker ด้วยอัลกอริทึมนี้ คุณสามารถฝึกโมเดลของคุณด้วยชุดข้อมูลสาธารณะหรือชุดข้อมูลของคุณเอง ชุดข้อมูลการแบ่งเซ็กเมนต์รูปภาพยอดนิยมประกอบด้วยชุดข้อมูล Common Objects in Context (COCO) และ PASCAL Visual Object Classes (PASCAL VOC) แต่คลาสของป้ายกำกับมีจำกัด และคุณอาจต้องการฝึกโมเดลบนออบเจ็กต์เป้าหมายที่ไม่รวมอยู่ใน ชุดข้อมูลสาธารณะ ในกรณีนี้ คุณสามารถใช้ ความจริงของ Amazon SageMaker เพื่อติดป้ายกำกับชุดข้อมูลของคุณเอง
ในโพสต์นี้ ฉันสาธิตวิธีแก้ไขปัญหาต่อไปนี้:
- การใช้ Ground Truth เพื่อติดป้ายกำกับชุดข้อมูลการแบ่งส่วนความหมาย
- การแปลงผลลัพธ์จาก Ground Truth เป็นรูปแบบอินพุตที่จำเป็นสำหรับอัลกอริธึมการแบ่งส่วนความหมายในตัวของ SageMaker
- การใช้อัลกอริทึมการแบ่งส่วนความหมายเพื่อฝึกแบบจำลองและทำการอนุมาน
การติดฉลากข้อมูลการแบ่งส่วนความหมาย
ในการสร้างโมเดลแมชชีนเลิร์นนิงสำหรับการแบ่งส่วนความหมาย เราจำเป็นต้องติดป้ายกำกับชุดข้อมูลที่ระดับพิกเซล Ground Truth ให้คุณมีตัวเลือกในการใช้คำอธิบายประกอบที่เป็นมนุษย์ผ่าน อังคารเครื่องกลเติร์กผู้ขายที่เป็นบุคคลภายนอก หรือพนักงานส่วนตัวของคุณเอง หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับแรงงาน โปรดดูที่ สร้างและจัดการแรงงาน. หากคุณไม่ต้องการจัดการพนักงานติดฉลากด้วยตัวเอง Amazon SageMaker Ground Truth Plus เป็นอีกตัวเลือกที่ยอดเยี่ยมในฐานะบริการติดฉลากข้อมูลแบบเบ็ดเสร็จใหม่ที่ช่วยให้คุณสามารถสร้างชุดข้อมูลการฝึกอบรมคุณภาพสูงได้อย่างรวดเร็วและลดต้นทุนได้มากถึง 40% สำหรับโพสต์นี้ ฉันจะแสดงวิธีติดป้ายกำกับชุดข้อมูลด้วยตนเองด้วยฟีเจอร์การแบ่งส่วนอัตโนมัติของ Ground Truth และการติดป้ายกำกับฝูงชนด้วยทีมงาน Mechanical Turk
การติดฉลากด้วยตนเองด้วย Ground Truth
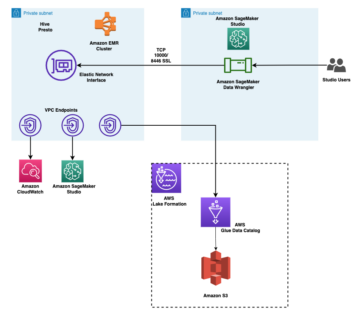
ในเดือนธันวาคม 2019 Ground Truth ได้เพิ่มคุณสมบัติการแบ่งส่วนอัตโนมัติให้กับอินเทอร์เฟซผู้ใช้การติดฉลากการแบ่งกลุ่มความหมายเพื่อเพิ่มปริมาณงานการติดฉลากและปรับปรุงความแม่นยำ สำหรับข้อมูลเพิ่มเติม โปรดดูที่ การแบ่งส่วนออบเจ็กต์อัตโนมัติเมื่อดำเนินการติดป้ายกำกับการแบ่งเซ็กเมนต์เชิงความหมายด้วย Amazon SageMaker Ground Truth. ด้วยคุณสมบัติใหม่นี้ คุณสามารถเร่งกระบวนการติดฉลากในงานแบ่งกลุ่มได้ แทนที่จะวาดรูปหลายเหลี่ยมที่กระชับพอดีหรือใช้เครื่องมือแปรงเพื่อจับภาพวัตถุในภาพ คุณวาดเพียงสี่จุดที่: ที่จุดบนสุด ล่างสุด ซ้ายสุด และขวาสุดของวัตถุ Ground Truth ใช้จุดทั้งสี่นี้เป็นอินพุตและใช้อัลกอริธึม Deep Extreme Cut (DEXTR) เพื่อสร้างหน้ากากที่กระชับพอดีรอบวัตถุ สำหรับบทช่วยสอนที่ใช้ Ground Truth สำหรับการติดป้ายกำกับการแบ่งส่วนความหมายของรูปภาพ โปรดดูที่ การแบ่งส่วนความหมายของรูปภาพ. ต่อไปนี้คือตัวอย่างวิธีที่เครื่องมือแบ่งกลุ่มอัตโนมัติสร้างรูปแบบการแบ่งกลุ่มโดยอัตโนมัติหลังจากที่คุณเลือกจุดสุดขั้วสี่จุดของวัตถุ


การติดฉลาก Crowdsourcing ด้วยพนักงานเครื่องกล Turk
หากคุณมีชุดข้อมูลขนาดใหญ่และไม่ต้องการติดป้ายกำกับรูปภาพด้วยตนเองเป็นร้อยเป็นพัน คุณสามารถใช้ Mechanical Turk ซึ่งจัดหาบุคลากรตามสั่ง ปรับขนาดได้ และทำงานที่มนุษย์สามารถทำได้ดีกว่าคอมพิวเตอร์ ซอฟต์แวร์เครื่องกล Turk เสนองานอย่างเป็นทางการให้กับพนักงานหลายพันคนที่เต็มใจทำงานทีละน้อยตามความสะดวก ซอฟต์แวร์ยังดึงงานที่ทำและเรียบเรียงให้คุณซึ่งเป็นผู้ขอซึ่งจ่ายเงินให้กับคนงานสำหรับงานที่น่าพอใจ (เท่านั้น) ในการเริ่มต้นใช้งาน Mechanical Turk โปรดดูที่ บทนำเกี่ยวกับ Amazon เครื่องกล Turk.
สร้างงานติดฉลาก
ต่อไปนี้คือตัวอย่างงานการติดฉลาก Mechanical Turk สำหรับชุดข้อมูลเต่าทะเล ชุดข้อมูลเต่าทะเลมาจากการแข่งขัน Kaggle การตรวจจับใบหน้าเต่าทะเลและฉันเลือก 300 ภาพของชุดข้อมูลเพื่อการสาธิต เต่าทะเลไม่ใช่คลาสทั่วไปในชุดข้อมูลสาธารณะ ดังนั้นจึงสามารถแสดงสถานการณ์ที่ต้องติดป้ายกำกับชุดข้อมูลขนาดใหญ่
- บนคอนโซล SageMaker ให้เลือก งานติดฉลาก ในบานหน้าต่างนำทาง
- Choose สร้างงานติดฉลาก.
- ป้อนชื่อสำหรับงานของคุณ
- สำหรับ ตั้งค่าข้อมูลเข้าให้เลือก ตั้งค่าข้อมูลอัตโนมัติ.
สิ่งนี้สร้างรายการของข้อมูลที่ป้อน - สำหรับ ตำแหน่ง S3 สำหรับชุดข้อมูลอินพุตให้ป้อนพาธสำหรับชุดข้อมูล

- สำหรับ หมวดหมู่งานเลือก ภาพ.
- สำหรับ การเลือกงานให้เลือก การแบ่งส่วนความหมาย.

- สำหรับ ประเภทคนงานให้เลือก อังคารเครื่องกลเติร์ก.
- กำหนดการตั้งค่าของคุณสำหรับการหมดเวลางาน เวลาหมดอายุของงาน และราคาต่องาน

- เพิ่มป้ายกำกับ (สำหรับโพสต์นี้
sea turtle) และให้คำแนะนำในการติดฉลาก - Choose สร้างบัญชีตัวแทน.

หลังจากที่คุณตั้งค่างานการติดฉลาก คุณสามารถตรวจสอบความคืบหน้าในการติดฉลากบนคอนโซล SageMaker เมื่อทำเครื่องหมายว่าเสร็จสมบูรณ์แล้ว คุณสามารถเลือกงานเพื่อตรวจสอบผลลัพธ์และใช้สำหรับขั้นตอนต่อไป

การแปลงชุดข้อมูล
หลังจากที่คุณได้รับผลลัพธ์จาก Ground Truth แล้ว คุณสามารถใช้อัลกอริทึมในตัวของ SageMaker เพื่อฝึกโมเดลในชุดข้อมูลนี้ได้ ขั้นแรก คุณต้องเตรียมชุดข้อมูลที่ติดป้ายกำกับเป็นอินเทอร์เฟซอินพุตที่ร้องขอสำหรับอัลกอริธึมการแบ่งส่วนความหมายของ SageMaker
ช่องทางการป้อนข้อมูลที่ร้องขอ
การแบ่งส่วนความหมายของ SageMaker คาดว่าชุดข้อมูลการฝึกอบรมของคุณจะถูกจัดเก็บบน บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (อเมซอน เอส3). ชุดข้อมูลใน Amazon S3 คาดว่าจะนำเสนอในสองช่องทาง หนึ่งช่องสำหรับ train และหนึ่งสำหรับ validationโดยใช้สี่ไดเร็กทอรี สองไดเร็กทอรีสำหรับรูปภาพ และอีกสองไดเร็กทอรีสำหรับคำอธิบายประกอบ คาดว่าคำอธิบายประกอบจะเป็นภาพ PNG ที่ไม่มีการบีบอัด ชุดข้อมูลอาจมีการแมปป้ายชื่อที่อธิบายวิธีการสร้างการแมปคำอธิบายประกอบ หากไม่เป็นเช่นนั้น อัลกอริทึมจะใช้ค่าเริ่มต้น สำหรับการอนุมาน จุดปลายยอมรับภาพที่มี an image/jpeg ชนิดของเนื้อหา. ต่อไปนี้เป็นโครงสร้างที่จำเป็นของช่องข้อมูล:
ภาพ JPG ทุกภาพในรถไฟและไดเร็กทอรีการตรวจสอบความถูกต้องมีภาพป้ายกำกับ PNG ที่สอดคล้องกันซึ่งมีชื่อเหมือนกันใน train_annotation และ validation_annotation ไดเรกทอรี หลักการตั้งชื่อนี้ช่วยให้อัลกอริทึมเชื่อมโยงป้ายกำกับกับรูปภาพที่เกี่ยวข้องระหว่างการฝึก รถไฟ, train_annotation, การตรวจสอบ และ validation_annotation ช่องทางบังคับ. คำอธิบายประกอบเป็นภาพ PNG แบบช่องสัญญาณเดียว รูปแบบใช้งานได้ตราบใดที่ข้อมูลเมตา (โหมด) ในรูปภาพช่วยให้อัลกอริทึมอ่านรูปภาพคำอธิบายประกอบเป็นจำนวนเต็ม 8 บิตที่ไม่ได้ลงนามในช่องสัญญาณเดียว
ผลงานจากงานติดฉลาก Ground Truth
ผลลัพธ์ที่สร้างจากงานการติดฉลาก Ground Truth มีโครงสร้างโฟลเดอร์ดังต่อไปนี้:
มาสก์การแบ่งส่วนจะถูกบันทึกไว้ใน s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. รูปภาพคำอธิบายประกอบแต่ละภาพเป็นไฟล์ .png ที่ตั้งชื่อตามดัชนีของรูปภาพต้นฉบับและเวลาที่การติดป้ายกำกับรูปภาพนี้เสร็จสมบูรณ์ ตัวอย่างเช่น ต่อไปนี้คือรูปภาพต้นฉบับ (Image_1.jpg) และรูปแบบการแบ่งส่วนซึ่งสร้างโดยทีมงาน Mechanical Turk (0_2022-02-10T17:41:04.724225.png) โปรดสังเกตว่าดัชนีของหน้ากากแตกต่างจากตัวเลขในชื่อภาพต้นทาง
 |
 |
รายการผลลัพธ์จากงานการติดฉลากอยู่ใน /manifests/output/output.manifest ไฟล์. เป็นไฟล์ JSON และแต่ละบรรทัดจะบันทึกการจับคู่ระหว่างรูปภาพต้นฉบับกับป้ายกำกับและข้อมูลเมตาอื่นๆ บรรทัด JSON ต่อไปนี้บันทึกการแมประหว่างรูปภาพต้นฉบับที่แสดงกับคำอธิบายประกอบ:
รูปภาพต้นทางเรียกว่า Image_1.jpg และชื่อของคำอธิบายประกอบคือ 0_2022-02-10T17:41: 04.724225.png ในการเตรียมข้อมูลให้เป็นรูปแบบช่องข้อมูลที่จำเป็นของอัลกอริทึมการแบ่งส่วนความหมายของ SageMaker เราจำเป็นต้องเปลี่ยนชื่อคำอธิบายประกอบเพื่อให้มีชื่อเดียวกับภาพ JPG ต้นทาง และเรายังต้องแบ่งชุดข้อมูลออกเป็น train และ validation ไดเร็กทอรีสำหรับรูปภาพต้นฉบับและคำอธิบายประกอบ
แปลงผลลัพธ์จากงานการติดฉลาก Ground Truth เป็นรูปแบบอินพุตที่ร้องขอ
ในการแปลงเอาต์พุต ให้ทำตามขั้นตอนต่อไปนี้:
- ดาวน์โหลดไฟล์ทั้งหมดจากงานการติดป้ายกำกับจาก Amazon S3 ไปยังไดเร็กทอรีในเครื่อง:
- อ่านไฟล์ Manifest และเปลี่ยนชื่อของคำอธิบายประกอบเป็นชื่อเดียวกับรูปภาพต้นฉบับ:
- แยกชุดข้อมูลรถไฟและการตรวจสอบความถูกต้อง:
- สร้างไดเร็กทอรีในรูปแบบที่จำเป็นสำหรับช่องทางข้อมูลอัลกอริธึมการแบ่งส่วนความหมาย:
- ย้ายรถไฟและรูปภาพการตรวจสอบความถูกต้องและคำอธิบายประกอบไปยังไดเร็กทอรีที่สร้างขึ้น
- สำหรับรูปภาพ ใช้รหัสต่อไปนี้:
- สำหรับคำอธิบายประกอบ ให้ใช้รหัสต่อไปนี้:
- อัปโหลดชุดข้อมูลการฝึกและการตรวจสอบความถูกต้อง รวมถึงชุดข้อมูลคำอธิบายประกอบไปยัง Amazon S3:
การฝึกอบรมแบบจำลองการแบ่งส่วนความหมายของ SageMaker
ในส่วนนี้ เราจะอธิบายขั้นตอนต่างๆ ในการฝึกโมเดลการแบ่งส่วนความหมายของคุณ
ติดตามสมุดบันทึกตัวอย่างและตั้งค่าช่องข้อมูล
คุณสามารถปฏิบัติตามคำแนะนำใน อัลกอริธึม Semantic Segmentation พร้อมใช้งานแล้วใน Amazon SageMaker เพื่อใช้อัลกอริทึมการแบ่งเซ็กเมนต์เชิงความหมายกับชุดข้อมูลที่คุณติดป้ายกำกับ ตัวอย่างนี้ สมุดบันทึก แสดงตัวอย่างแบบ end-to-end ที่แนะนำอัลกอริทึม ในสมุดบันทึก คุณจะได้เรียนรู้วิธีฝึกอบรมและโฮสต์โมเดลการแบ่งส่วนความหมายโดยใช้เครือข่ายแบบหมุนวนทั้งหมด (FCN) อัลกอริทึมโดยใช้ ชุดข้อมูล Pascal VOC สำหรับการฝึกอบรม เนื่องจากฉันไม่ได้วางแผนที่จะฝึกโมเดลจากชุดข้อมูล Pascal VOC ฉันจึงข้ามขั้นตอนที่ 3 (การเตรียมข้อมูล) ในสมุดบันทึกนี้ แต่ฉันสร้างโดยตรงแทน train_channel, train_annotation_channe, validation_channelและ validation_annotation_channel โดยใช้ตำแหน่ง S3 ที่ฉันเก็บภาพและคำอธิบายประกอบไว้:
ปรับไฮเปอร์พารามิเตอร์สำหรับชุดข้อมูลของคุณเองในตัวประมาณของ SageMaker
ฉันติดตามสมุดบันทึกและสร้างวัตถุตัวประมาณ SageMaker (ss_estimator) เพื่อฝึกอัลกอริทึมการแบ่งส่วนของฉัน สิ่งหนึ่งที่เราต้องปรับแต่งสำหรับชุดข้อมูลใหม่คือใน ss_estimator.set_hyperparameters: เราต้องเปลี่ยน num_classes=21 ไปยัง num_classes=2 (turtle และ background) และฉันก็เปลี่ยนไป epochs=10 ไปยัง epochs=30 เพราะ 10 มีไว้เพื่อการสาธิตเท่านั้น จากนั้นฉันก็ใช้อินสแตนซ์ p3.2xlarge สำหรับการฝึกโมเดลโดยการตั้งค่า instance_type="ml.p3.2xlarge". การฝึกอบรมเสร็จสิ้นใน 8 นาที ที่สุด มิโอยู (Mean Intersection over Union) ที่ 0.846 ทำได้ที่ epoch 11 ด้วย a pix_acc (เปอร์เซ็นต์ของพิกเซลในภาพของคุณที่จัดประเภทอย่างถูกต้อง) ที่ 0.925 ซึ่งถือว่าค่อนข้างดีสำหรับชุดข้อมูลขนาดเล็กนี้
ผลการอนุมานแบบจำลอง
ฉันโฮสต์โมเดลในอินสแตนซ์ ml.c5.xlarge ราคาประหยัด:
สุดท้าย ฉันได้เตรียมชุดทดสอบของภาพเต่า 10 ภาพเพื่อดูผลอนุมานของโมเดลการแบ่งส่วนที่ผ่านการฝึกอบรม:
ภาพต่อไปนี้แสดงผล

หน้ากากแบ่งกลุ่มของเต่าทะเลดูแม่นยำ และฉันพอใจกับผลลัพธ์ที่ได้รับการฝึกอบรมจากชุดข้อมูล 300 ภาพที่ติดป้ายกำกับโดยพนักงานเครื่องกลของเติร์ก คุณยังสามารถสำรวจเครือข่ายอื่น ๆ ที่มีอยู่เช่น เครือข่ายการแยกวิเคราะห์ฉากพีระมิด (PSP) or DeepLab-V3 ในสมุดบันทึกตัวอย่างพร้อมชุดข้อมูลของคุณ
ทำความสะอาด
ลบปลายทางเมื่อคุณทำเสร็จแล้วเพื่อหลีกเลี่ยงค่าใช้จ่ายที่ต่อเนื่อง:
สรุป
ในโพสต์นี้ ฉันแสดงวิธีปรับแต่งการติดฉลากข้อมูลการแบ่งเซ็กเมนต์เชิงความหมายและการฝึกโมเดลโดยใช้ SageMaker ขั้นแรก คุณสามารถตั้งค่างานการติดฉลากด้วยเครื่องมือแบ่งกลุ่มอัตโนมัติ หรือใช้พนักงานเครื่องกลของเติร์ก (รวมถึงตัวเลือกอื่นๆ) หากคุณมีออบเจ็กต์มากกว่า 5,000 รายการ คุณสามารถใช้การติดป้ายกำกับข้อมูลอัตโนมัติได้ จากนั้นคุณแปลงผลลัพธ์จากงานการติดฉลาก Ground Truth เป็นรูปแบบอินพุตที่จำเป็นสำหรับการฝึกอบรมการแบ่งส่วนความหมายในตัวของ SageMaker หลังจากนั้น คุณสามารถใช้อินสแตนซ์การประมวลผลแบบเร่งความเร็ว (เช่น p2 หรือ p3) เพื่อฝึกโมเดลการแบ่งส่วนเชิงความหมายด้วยสิ่งต่อไปนี้ สมุดบันทึก และปรับใช้โมเดลกับอินสแตนซ์ที่คุ้มค่ากว่า (เช่น ml.c5.xlarge) สุดท้าย คุณสามารถตรวจทานผลการอนุมานในชุดข้อมูลทดสอบของคุณด้วยโค้ดสองสามบรรทัด
เริ่มต้นใช้งาน SageMaker semantic segmentation การติดฉลากข้อมูล และ การฝึกโมเดล ด้วยชุดข้อมูลที่คุณชื่นชอบ!
เกี่ยวกับผู้เขียน
 คารายาง เป็นนักวิทยาศาสตร์ข้อมูลใน AWS Professional Services เธอหลงใหลในการช่วยให้ลูกค้าบรรลุเป้าหมายทางธุรกิจด้วยบริการคลาวด์ของ AWS เธอได้ช่วยองค์กรต่างๆ ในการสร้างโซลูชัน ML ในหลายอุตสาหกรรม เช่น การผลิต ยานยนต์ ความยั่งยืนด้านสิ่งแวดล้อม และการบินและอวกาศ
คารายาง เป็นนักวิทยาศาสตร์ข้อมูลใน AWS Professional Services เธอหลงใหลในการช่วยให้ลูกค้าบรรลุเป้าหมายทางธุรกิจด้วยบริการคลาวด์ของ AWS เธอได้ช่วยองค์กรต่างๆ ในการสร้างโซลูชัน ML ในหลายอุตสาหกรรม เช่น การผลิต ยานยนต์ ความยั่งยืนด้านสิ่งแวดล้อม และการบินและอวกาศ
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- เกี่ยวกับเรา
- เร่งความเร็ว
- เร่ง
- ถูกต้อง
- บรรลุ
- ประสบความสำเร็จ
- ข้าม
- ที่เพิ่ม
- การบินและอวกาศ
- ขั้นตอนวิธี
- อัลกอริทึม
- ทั้งหมด
- อเมซอน
- ประกาศ
- อื่น
- รอบ
- ภาคี
- อัตโนมัติ
- อัตโนมัติ
- ยานยนต์
- ใช้ได้
- AWS
- พื้นหลัง
- เพราะ
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- สร้าง
- built-in
- ธุรกิจ
- จับ
- กรณี
- บาง
- เปลี่ยนแปลง
- ช่อง
- Choose
- ชั้น
- ชั้นเรียน
- จัด
- เมฆ
- บริการคลาวด์
- รหัส
- ร่วมกัน
- การแข่งขัน
- สมบูรณ์
- คอมพิวเตอร์
- คอมพิวเตอร์
- การคำนวณ
- ความมั่นใจ
- ปลอบใจ
- เนื้อหา
- ความสะดวกสบาย
- ตรงกัน
- ค่าใช้จ่ายที่มีประสิทธิภาพ
- ค่าใช้จ่าย
- สร้าง
- ที่สร้างขึ้น
- ลูกค้า
- ปรับแต่ง
- ข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- ลึก
- สาธิต
- ปรับใช้
- ต่าง
- โดยตรง
- การวาดภาพ
- ในระหว่าง
- แต่ละ
- ช่วยให้
- จบสิ้น
- ปลายทาง
- เข้าสู่
- สิ่งแวดล้อม
- ที่จัดตั้งขึ้น
- ตัวอย่าง
- ยกเว้น
- ที่คาดหวัง
- คาดว่า
- สำรวจ
- สุดโต่ง
- ใบหน้า
- ลักษณะ
- ชื่อจริง
- ปฏิบัติตาม
- ดังต่อไปนี้
- รูป
- ราคาเริ่มต้นที่
- สร้าง
- เป้าหมาย
- ดี
- สีเทา
- ยิ่งใหญ่
- มีความสุข
- ช่วย
- การช่วยเหลือ
- จะช่วยให้
- ที่มีคุณภาพสูง
- เป็นเจ้าภาพ
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTTPS
- เป็นมนุษย์
- มนุษย์
- ร้อย
- ภาพ
- ภาพ
- การดำเนินการ
- ปรับปรุง
- ประกอบด้วย
- รวม
- เพิ่ม
- ดัชนี
- อุตสาหกรรม
- ข้อมูล
- อินพุต
- ตัวอย่าง
- อินเตอร์เฟซ
- การตัด
- แนะนำ
- IT
- การสัมภาษณ์
- งาน
- ที่รู้จักกัน
- ฉลาก
- การติดฉลาก
- ป้ายกำกับ
- ใหญ่
- เปิดตัว
- เรียนรู้
- การเรียนรู้
- ชั้น
- ถูก จำกัด
- Line
- เส้น
- รายการ
- ในประเทศ
- ที่ตั้ง
- วันหยุด
- นาน
- ดู
- เครื่อง
- เรียนรู้เครื่อง
- จัดการ
- จำเป็น
- ด้วยมือ
- การผลิต
- แผนที่
- การทำแผนที่
- หน้ากาก
- มาสก์
- มาก
- เชิงกล
- อาจ
- ML
- แบบ
- โมเดล
- ข้อมูลเพิ่มเติม
- หลาย
- ชื่อ
- การตั้งชื่อ
- การเดินเรือ
- เครือข่าย
- เครือข่าย
- ถัดไป
- สมุดบันทึก
- จำนวน
- เสนอ
- ตัวเลือกเสริม (Option)
- Options
- องค์กร
- อื่นๆ
- ของตนเอง
- หลงใหล
- เปอร์เซ็นต์
- ที่มีประสิทธิภาพ
- จุด
- รูปหลายเหลี่ยม
- ยอดนิยม
- เตรียมการ
- สวย
- ราคา
- ส่วนตัว
- กระบวนการ
- ก่อ
- มืออาชีพ
- ให้
- ให้
- สาธารณะ
- วัตถุประสงค์
- อย่างรวดเร็ว
- RE
- บันทึก
- แสดง
- จำเป็นต้องใช้
- ต้อง
- ผลสอบ
- ทบทวน
- เดียวกัน
- ที่ปรับขนาดได้
- นักวิทยาศาสตร์
- เอเชียตะวันออกเฉียงใต้
- การแบ่งส่วน
- เลือก
- บริการ
- บริการ
- ชุด
- การตั้งค่า
- Share
- โชว์
- แสดง
- ง่าย
- สถานการณ์
- เล็ก
- So
- ซอฟต์แวร์
- โซลูชัน
- แยก
- ข้อความที่เริ่ม
- การเก็บรักษา
- การพัฒนาอย่างยั่งยืน
- เป้า
- งาน
- ทีม
- ทดสอบ
- พื้นที่
- ที่มา
- สิ่ง
- ของบุคคลที่สาม
- พัน
- ตลอด
- ปริมาณงาน
- เวลา
- เครื่องมือ
- รถไฟ
- การฝึกอบรม
- แปลง
- สหภาพ
- ใช้
- การตรวจสอบ
- ผู้ขาย
- วิสัยทัศน์
- WHO
- งาน
- แรงงาน
- กำลังแรงงาน
- โรงงาน
- ของคุณ