การปรับแต่งโมเดลเป็นกระบวนการทดลองในการค้นหาพารามิเตอร์และการกำหนดค่าที่เหมาะสมที่สุดสำหรับโมเดลแมชชีนเลิร์นนิง (ML) ซึ่งจะให้ผลลัพธ์ตามที่ต้องการด้วยชุดข้อมูลการตรวจสอบความถูกต้อง การเพิ่มประสิทธิภาพวัตถุประสงค์เดียวด้วยเมตริกประสิทธิภาพเป็นวิธีการทั่วไปในการปรับแต่งโมเดล ML อย่างไรก็ตาม นอกเหนือจากประสิทธิภาพที่คาดการณ์ได้ อาจมีวัตถุประสงค์หลายอย่างที่ต้องพิจารณาสำหรับการใช้งานบางอย่าง ตัวอย่างเช่น,
- ความเป็นธรรม – จุดมุ่งหมายในที่นี้คือการสนับสนุนให้แบบจำลองลดอคติในผลลัพธ์ของแบบจำลองระหว่างกลุ่มย่อยบางกลุ่มในข้อมูล โดยเฉพาะอย่างยิ่งเมื่อมนุษย์อยู่ภายใต้การตัดสินใจด้วยอัลกอริทึม ตัวอย่างเช่น ใบสมัครขอสินเชื่อไม่เพียงแต่ต้องแม่นยำเท่านั้น แต่ยังต้องไม่มีอคติต่อประชากรกลุ่มย่อยต่างๆ ด้วย
- เวลาอนุมาน – จุดมุ่งหมายที่นี่คือการลดเวลาอนุมานระหว่างการเรียกใช้แบบจำลอง ตัวอย่างเช่น ระบบการรู้จำเสียงต้องไม่เพียงเข้าใจภาษาถิ่นต่างๆ ของภาษาเดียวกันอย่างถูกต้องเท่านั้น แต่ยังต้องทำงานภายในระยะเวลาที่กำหนดซึ่งกระบวนการทางธุรกิจยอมรับได้
- ประสิทธิภาพพลังงาน – จุดมุ่งหมายคือการฝึกโมเดลประหยัดพลังงานที่มีขนาดเล็กลง ตัวอย่างเช่น โมเดลโครงข่ายประสาทเทียมถูกบีบอัดสำหรับการใช้งานบนอุปกรณ์พกพา และลดการใช้พลังงานโดยธรรมชาติโดยการลดจำนวน FLOPS ที่จำเป็นสำหรับการส่งผ่านเครือข่าย
วิธีการเพิ่มประสิทธิภาพแบบหลายวัตถุประสงค์แสดงถึงการแลกเปลี่ยนที่แตกต่างกันระหว่างเมตริกที่ต้องการ สิ่งนี้สามารถเกี่ยวข้องกับการค้นหาขั้นต่ำทั่วโลกของฟังก์ชันวัตถุประสงค์ภายใต้ชุดของข้อจำกัดในเมตริกต่างๆ ที่ได้รับความพึงพอใจพร้อมกัน
การปรับโมเดลอัตโนมัติของ Amazon SageMaker (AMT) ค้นหาเวอร์ชันที่ดีที่สุดของโมเดลโดยการเรียกใช้งานการฝึกอบรม SageMaker จำนวนมากในชุดข้อมูลของคุณโดยใช้อัลกอริทึมและช่วงของไฮเปอร์พารามิเตอร์ จากนั้นจะเลือกค่าไฮเปอร์พารามิเตอร์ที่ส่งผลให้โมเดลทำงานได้ดีที่สุด โดยวัดด้วยเมตริก (เช่น ความแม่นยำ auc การเรียกคืน) ที่คุณกำหนด ด้วยการปรับแต่งโมเดลอัตโนมัติของ Amazon SageMaker คุณสามารถค้นหาเวอร์ชันที่ดีที่สุดสำหรับโมเดลของคุณได้โดยการเรียกใช้งานการฝึกอบรมในชุดข้อมูลของคุณด้วย กลยุทธ์การค้นหาที่หลากหลาย เช่น Bayesian, Random search, Grid search และ Hyperband
Amazon SageMaker ชี้แจง สามารถตรวจจับอคติที่อาจเกิดขึ้นระหว่างการเตรียมข้อมูล หลังการฝึกโมเดล และในโมเดลที่คุณปรับใช้ ปัจจุบันมีเมตริกให้เลือก 21 แบบ เมตริกเหล่านี้ยังมีให้ใช้งานอย่างเปิดเผยด้วย ชี้แจง แพ็คเกจ python และที่เก็บ github โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม. คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับการวัดอคติด้วยเมตริกจาก Amazon SageMaker Clarify ได้ที่ เรียนรู้ว่า Amazon SageMaker Clarify ช่วยตรวจจับอคติได้อย่างไร.
ในบล็อกนี้ เราจะแสดงวิธีปรับแต่งโมเดล ML ด้วย Amazon SageMaker AMT โดยอัตโนมัติสำหรับวัตถุประสงค์ด้านความถูกต้องและความยุติธรรมโดยการสร้างเมตริกแบบรวมรายการเดียว เราแสดงกรณีการใช้บริการทางการเงินของการคาดการณ์ความเสี่ยงด้านเครดิตด้วยเมตริกที่แม่นยำ พื้นที่ใต้เส้นโค้ง (AUC) เพื่อวัดประสิทธิภาพและตัวชี้วัดอคติของ ความแตกต่างของสัดส่วนที่เป็นบวกในฉลากที่คาดการณ์ไว้ (DPPL) จาก SageMaker Clarify เพื่อวัดความไม่สมดุลในการคาดคะเนแบบจำลองสำหรับกลุ่มประชากรต่างๆ รหัสสำหรับตัวอย่างนี้มีอยู่บน GitHub.
ความเป็นธรรมในการทำนายความเสี่ยงด้านเครดิต
อุตสาหกรรมการให้สินเชื่อเครดิตอาศัยคะแนนเครดิตอย่างมากในการดำเนินการขอสินเชื่อ โดยทั่วไป คะแนนเครดิตจะสะท้อนถึงประวัติของผู้สมัครในการยืมและจ่ายเงินคืน และผู้ให้กู้จะอ้างถึงคะแนนเหล่านี้เมื่อพิจารณาถึงความน่าเชื่อถือทางเครดิตของแต่ละบุคคล บริษัทชำระเงินและธนาคารสนใจที่จะสร้างระบบที่สามารถช่วยระบุความเสี่ยงที่เกี่ยวข้องกับแอปพลิเคชันเฉพาะและจัดหาผลิตภัณฑ์สินเชื่อที่แข่งขันได้ สามารถใช้แบบจำลองการเรียนรู้ของเครื่อง (ML) เพื่อสร้างระบบที่ประมวลผลข้อมูลประวัติผู้สมัครและคาดการณ์โปรไฟล์ความเสี่ยงด้านเครดิต ข้อมูลอาจรวมถึงประวัติทางการเงินและการจ้างงานของผู้สมัคร ข้อมูลประชากร และบริบทสินเชื่อ/เงินกู้ใหม่ มีความไม่แน่นอนทางสถิติเสมอกับแบบจำลองใดๆ ที่คาดการณ์ว่าผู้สมัครรายใดรายหนึ่งจะผิดนัดชำระหนี้ในอนาคตหรือไม่ ระบบจำเป็นต้องจัดให้มีการแลกเปลี่ยนระหว่างการปฏิเสธแอปพลิเคชันที่อาจผิดนัดเมื่อเวลาผ่านไปและการยอมรับแอปพลิเคชันที่น่าเชื่อถือในที่สุด
เจ้าของธุรกิจของระบบดังกล่าวจำเป็นต้องรับรองความถูกต้องและคุณภาพของแบบจำลองตามข้อกำหนดการปฏิบัติตามกฎระเบียบที่มีอยู่และที่จะเกิดขึ้น พวกเขามีหน้าที่ปฏิบัติต่อลูกค้าอย่างยุติธรรมและให้ความโปร่งใสในการตัดสินใจ พวกเขาอาจต้องการให้แน่ใจว่าการคาดคะเนแบบจำลองในเชิงบวกจะไม่เกิดความไม่สมดุลระหว่างกลุ่มต่างๆ (เช่น เพศ เชื้อชาติ ชาติพันธุ์ สถานะการย้ายถิ่นฐาน และอื่นๆ) เมื่อรวบรวมข้อมูลที่จำเป็นแล้ว การฝึกอบรมโมเดล ML มักจะปรับให้เหมาะสมสำหรับประสิทธิภาพการคาดคะเนเป็นวัตถุประสงค์หลักด้วยเมตริก เช่น ความแม่นยำในการจำแนกประเภทหรือคะแนน AUC อีกทางเลือกหนึ่ง แบบจำลองที่มีวัตถุประสงค์ด้านประสิทธิภาพที่กำหนดสามารถถูกจำกัดด้วยเมตริกความเป็นธรรม เพื่อให้มั่นใจว่าข้อกำหนดบางอย่างได้รับการบำรุงรักษา เทคนิคหนึ่งที่จะจำกัดโมเดลคือการปรับไฮเปอร์พารามิเตอร์ที่คำนึงถึงความเป็นธรรม ด้วยการใช้กลยุทธ์เหล่านี้ โมเดลผู้สมัครที่ดีที่สุดสามารถมีอคติต่ำกว่าโมเดลที่ไม่มีข้อจำกัด ในขณะที่ยังคงประสิทธิภาพการทำนายที่สูง

ในสถานการณ์ที่ปรากฎในแผนผังนี้
- โมเดล ML สร้างขึ้นจากข้อมูลโปรไฟล์เครดิตของลูกค้าในอดีต การฝึกโมเดลและกระบวนการปรับแต่งไฮเปอร์พารามิเตอร์ช่วยเพิ่มประสิทธิภาพสูงสุดสำหรับวัตถุประสงค์หลายประการ รวมถึงความแม่นยำในการจำแนกประเภทและความยุติธรรม โมเดลถูกนำไปใช้กับกระบวนการทางธุรกิจที่มีอยู่ในระบบการผลิต
- โปรไฟล์เครดิตลูกค้าใหม่ได้รับการประเมินสำหรับความเสี่ยงด้านเครดิต หากมีความเสี่ยงน้อยก็สามารถผ่านกระบวนการอัตโนมัติได้ แอปพลิเคชันที่มีความเสี่ยงสูงอาจรวมถึงการตรวจสอบโดยมนุษย์ก่อนที่จะมีการตัดสินใจยอมรับหรือปฏิเสธขั้นสุดท้าย
การตัดสินใจและเมตริกที่รวบรวมระหว่างการออกแบบและการพัฒนา การปรับใช้ และการดำเนินการสามารถจัดทำเป็นเอกสารได้ การ์ดโมเดล SageMaker และแบ่งปันกับผู้มีส่วนได้ส่วนเสีย
กรณีการใช้งานนี้สาธิตวิธีลดอคติของโมเดลกับกลุ่มเฉพาะโดยการปรับไฮเปอร์พารามิเตอร์แบบละเอียดสำหรับเมตริกวัตถุประสงค์แบบรวมที่มีทั้งความแม่นยำและความยุติธรรมด้วยการปรับโมเดลอัตโนมัติของ SageMaker เราใช้ชุดข้อมูลเครดิตของเยอรมันใต้ (ชุดข้อมูลเครดิตของเยอรมันใต้)
ข้อมูลผู้สมัครสามารถแบ่งออกเป็นประเภทต่อไปนี้:
- ข้อมูลประชากร
- ข้อมูลทางการเงิน
- ประวัติการทำงาน
- วัตถุประสงค์ในการกู้ยืม
ในตัวอย่างนี้ เราพิจารณาเฉพาะกลุ่มประชากร 'แรงงานต่างชาติ' และปรับแบบจำลองที่คาดการณ์การตัดสินใจขอสินเชื่อด้วยความแม่นยำสูงและมีอคติต่ำต่อกลุ่มย่อยนั้น
มีหลายแบบ ตัวชี้วัดอคติ ที่สามารถใช้ในการประเมินความเป็นธรรมของระบบในส่วนที่เกี่ยวกับกลุ่มย่อยเฉพาะในข้อมูล ในที่นี้ เราใช้ค่าสัมบูรณ์ของความแตกต่างในสัดส่วนที่เป็นบวกในป้ายกำกับที่คาดคะเน (พปชร) จาก SageMaker ชี้แจง พูดง่ายๆ ก็คือ DPPL วัดความแตกต่างของการมอบหมายงานในระดับเชิงบวก (เครดิตดี) ระหว่างแรงงานที่ไม่ใช่ชาวต่างชาติและแรงงานต่างชาติ
ตัวอย่างเช่น หาก 4.5% ของแรงงานต่างชาติทั้งหมดถูกกำหนดป้ายกำกับเชิงบวกโดยแบบจำลอง และ 13.7% ของคนงานที่ไม่ใช่ชาวต่างชาติทั้งหมดถูกกำหนดป้ายกำกับเชิงบวก จากนั้น DPPL = 0.137 – 0.045 = 0.092.
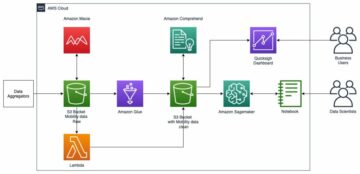
สถาปัตยกรรมโซลูชัน
รูปภาพด้านล่างแสดงภาพรวมระดับสูงของสถาปัตยกรรมของงานการปรับโมเดลอัตโนมัติด้วย XGBoost บน Amazon SageMaker
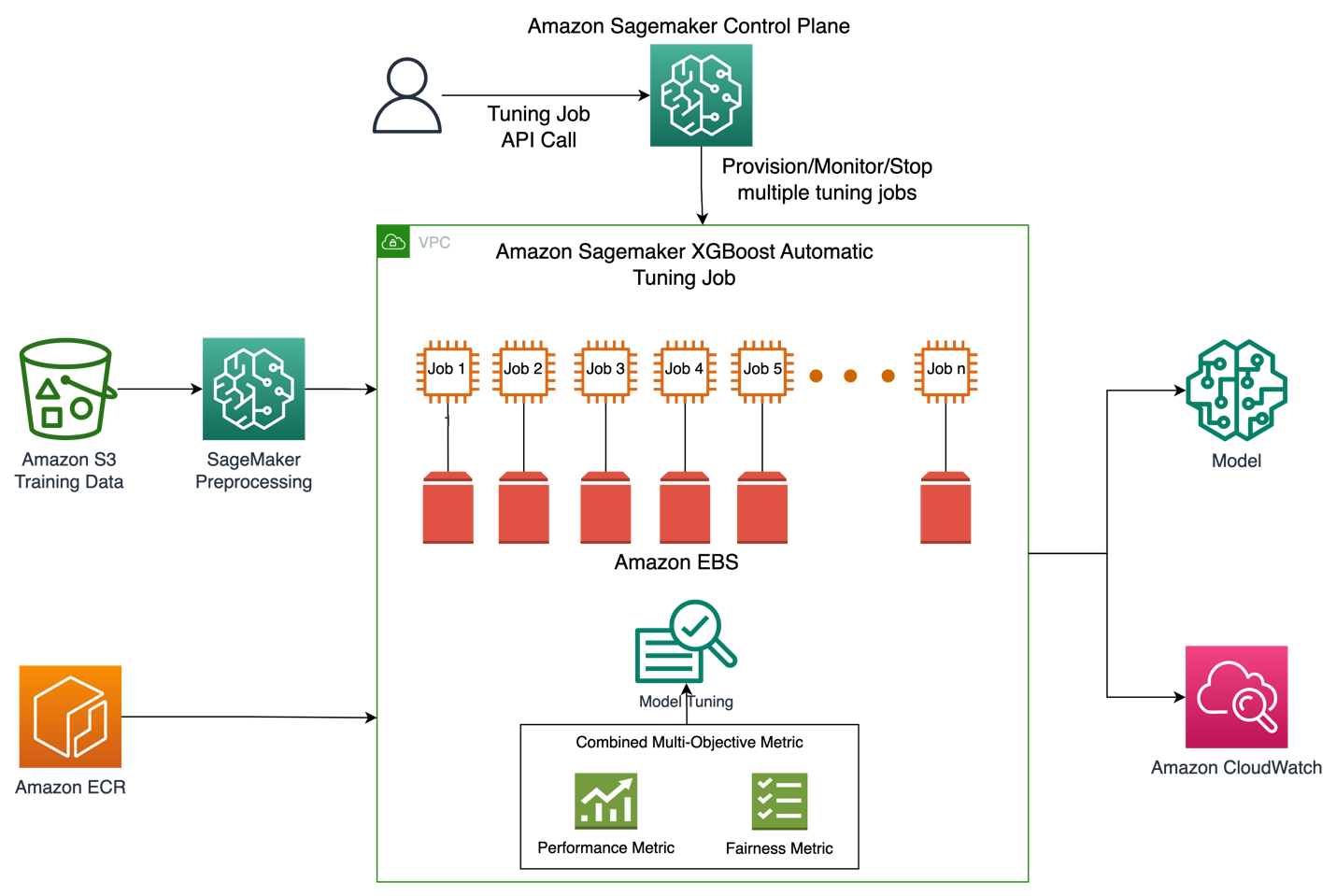
ในโซลูชัน SageMaker Processing จะประมวลผลล่วงหน้าชุดข้อมูลการฝึกอบรมจาก Amazon S3 Amazon SageMaker Automatic Tuning จำลองงานฝึกอบรม SageMaker หลายรายการด้วยอินสแตนซ์ EC2 และปริมาณ EBS ที่เกี่ยวข้อง มีการโหลดคอนเทนเนอร์สำหรับอัลกอริทึม (XGBoost) จาก Amazon ECR ในแต่ละงาน SageMaker AMT ค้นหาเวอร์ชันที่ดีที่สุดของโมเดลโดยการเรียกใช้งานการฝึกอบรมจำนวนมากในชุดข้อมูลที่ประมวลผลล่วงหน้าโดยใช้สคริปต์อัลกอริทึมที่ระบุและช่วงของไฮเปอร์พารามิเตอร์ ตัววัดเอาต์พุตได้รับการบันทึกใน Amazon CloudWatch เพื่อการตรวจสอบ
ไฮเปอร์พารามิเตอร์ที่เรากำลังปรับในกรณีการใช้งานนี้มีดังนี้:
- การทางพิเศษแห่งประเทศไทย – การหดตัวของขนาดขั้นตอนใช้ในการอัปเดตเพื่อป้องกันการโอเวอร์ฟิต
- ขั้นต่ำ_เด็ก_น้ำหนัก – ผลรวมขั้นต่ำของน้ำหนักอินสแตนซ์ (เฮสเซียน) ที่จำเป็นในเด็ก
- แกมมา – ต้องลดการสูญเสียขั้นต่ำเพื่อสร้างพาร์ติชันเพิ่มเติมบนโหนดลีฟของทรี
- ความลึกสูงสุด - ความลึกสูงสุดของต้นไม้
สามารถค้นหาคำจำกัดความของไฮเปอร์พารามิเตอร์เหล่านี้และอื่นๆ ที่มีใน SageMaker AMT ได้ โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม.
ขั้นแรก เราสาธิตสถานการณ์พื้นฐานของเมตริกวัตถุประสงค์ด้านประสิทธิภาพเดียวสำหรับการปรับไฮเปอร์พารามิเตอร์ด้วย Automatic Model Tuning จากนั้น เราจะสาธิตสถานการณ์ที่ปรับให้เหมาะสมของเมตริกหลายวัตถุประสงค์ที่ระบุว่าเป็นการรวมกันของเมตริกประสิทธิภาพและเมตริกความเป็นธรรม
การปรับไฮเปอร์พารามิเตอร์เมตริกเดียว (พื้นฐาน)
มีเมตริกหลายรายการให้เลือกสำหรับงานปรับแต่งเพื่อประเมินงานฝึกอบรมแต่ละงาน ตามข้อมูลโค้ดด้านล่าง เราระบุเมตริกวัตถุประสงค์เดียวเป็น objective_metric_name. งานการปรับไฮเปอร์พารามิเตอร์จะส่งคืนงานการฝึกที่ให้ค่าที่ดีที่สุดสำหรับเมตริกวัตถุประสงค์ที่เลือก
ในสถานการณ์พื้นฐานนี้ เรากำลังปรับหาพื้นที่ใต้เส้นโค้ง (AUC) ดังที่เห็นด้านล่าง สิ่งสำคัญคือต้องทราบว่าเรากำลังปรับ AUC ให้เหมาะสมเท่านั้น และไม่ได้ปรับให้เหมาะสมสำหรับตัวชี้วัดอื่นๆ เช่น ความเป็นธรรม
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner hyperparameter_ranges = {'eta': ContinuousParameter(0, 1), 'min_child_weight': IntegerParameter(1, 10), 'gamma': IntegerParameter(1, 5), 'max_depth': IntegerParameter(1, 10)} objective_metric_name = 'validation:auc' tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10,
) tuning_job_name = "xgb-tuner-{}".format(strftime("%d-%H-%M-%S", gmtime()))
inputs = {'train': train_data_path, 'validation': val_data_path}
tuner.fit(inputs, job_name=tuning_job_name)
tuner.wait()
tuner_metrics = sagemaker.HyperparameterTuningJobAnalytics(tuning_job_name)ในบริบทนี้ max jobs ช่วยให้เราสามารถระบุได้ว่างานฝึกอบรมใดงานหนึ่งจะได้รับการปรับจูนกี่ครั้ง และค้นหางานฝึกอบรมที่ดีที่สุดได้จากที่นั่น
การปรับไฮเปอร์พารามิเตอร์หลายวัตถุประสงค์ (ปรับให้เหมาะสม)
เราต้องการเพิ่มประสิทธิภาพเมตริกวัตถุประสงค์หลายรายการด้วยการปรับไฮเปอร์พารามิเตอร์ตามที่อธิบายไว้ในนี้ กระดาษ. อย่างไรก็ตาม SageMaker AMT ยังคงยอมรับเพียงเมตริกเดียวเป็นอินพุต
เพื่อจัดการกับความท้าทายนี้ เราแสดงเมตริกหลายรายการเป็นฟังก์ชันเมตริกเดียวและเพิ่มประสิทธิภาพเมตริกนี้:
- สูงสุดM(y1,y2,θ)
- y1,y2เป็นเมตริกที่แตกต่างกัน ตัวอย่างเช่น คะแนน AUC และ DPPL
- M(⋅,⋅,θ)เป็นฟังก์ชันสเกลาไรเซชันและกำหนดพารามิเตอร์โดยพารามิเตอร์คงที่
น้ำหนักที่มากขึ้นช่วยให้วัตถุประสงค์เฉพาะนั้นดีขึ้นในการปรับแต่งโมเดล น้ำหนักอาจแตกต่างกันไปในแต่ละกรณี และคุณอาจต้องลองน้ำหนักที่แตกต่างกันสำหรับกรณีการใช้งานของคุณ ในตัวอย่างนี้ น้ำหนักสำหรับ AUC และ DPPL ได้รับการตั้งค่าแบบฮิวริสติก มาดูกันว่าสิ่งนี้จะมีลักษณะอย่างไรในโค้ด คุณสามารถดูงานการฝึกอบรมที่ส่งคืนเมตริกเดียวตามฟังก์ชันการรวมคะแนน AUC สำหรับประสิทธิภาพและ DPPL เพื่อความยุติธรรม ช่วงการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์สำหรับหลายวัตถุประสงค์จะเหมือนกับวัตถุประสงค์เดียว เรากำลังส่งเมตริกการตรวจสอบความถูกต้องเป็น "auc" แต่เบื้องหลังเรากำลังส่งคืนผลลัพธ์ของฟังก์ชันเมตริกแบบรวมตามที่อธิบายไว้ในรายการฟังก์ชันด้านล่าง:
นี่คือฟังก์ชั่นการเพิ่มประสิทธิภาพหลายวัตถุประสงค์:
objective_metric_name = 'validation:auc'
tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10
)นี่คือฟังก์ชันสำหรับการคำนวณคะแนน AUC:
def eval_auc_score(predt, dtrain):
fY = [1 if p > 0.5 else 0 for p in predt]
y = dtrain.get_label()
auc_score = roc_auc_score(y, fY)
return auc_scoreนี่คือฟังก์ชันสำหรับการคำนวณคะแนน DPPL:
def eval_dppl(predt, dtrain):
dtrain_np = dmatrix_to_numpy(dtrain)
# groups: an np array containing 1 or 2
groups = dtrain_np[:, -1]
# sensitive_facet_index: boolean column indicating sensitive group
sensitive_facet_index = pd.Series(groups - 1, dtype=bool)
# positive_predicted_label_index: boolean column indicating positive predicted labels
positive_label_index = pd.Series(predt > 0.5)
return abs(DPPL(predt, sensitive_facet_index, positive_label_index))นี่คือฟังก์ชันสำหรับเมตริกรวม:
def eval_combined_metric(predt, dtrain):
auc_score = eval_auc_score(predt, dtrain)
DPPL = eval_dppl(predt, dtrain)
# Assign weight of 3 to AUC and 1 to DPPL
# Maximize (1-DPPL) for the purpose of minimizing DPPL combined_metric = ((3*auc_score)+(1-DPPL))/4 print("DPPL, AUC Score, Combined Metric: ", DPPL, auc_score, combined_metric)
return "auc", combined_metricการทดลองและผลลัพธ์
การสร้างข้อมูลสังเคราะห์สำหรับชุดข้อมูลอคติ
ชุดข้อมูลเครดิตของเยอรมันใต้ดั้งเดิมมีบันทึก 1000 รายการ และเราสร้างบันทึกอีก 100 รายการแบบสังเคราะห์เพื่อสร้างชุดข้อมูลที่อคติในการคาดคะเนแบบจำลองไม่เอื้ออำนวยต่อแรงงานต่างชาติ สิ่งนี้ทำขึ้นเพื่อจำลองอคติที่สามารถแสดงออกในโลกแห่งความเป็นจริง บันทึกใหม่ของแรงงานต่างชาติที่ระบุว่าเป็นผู้สมัคร "เครดิตไม่ดี" ถูกอนุมานจากแรงงานต่างชาติที่มีอยู่ซึ่งมีป้ายกำกับเดียวกัน
มีห้องสมุด/เทคนิคมากมายในการสร้างข้อมูลสังเคราะห์และเราใช้ คลังข้อมูลสังเคราะห์ (ดีพีแอลวี).
จากข้อมูลโค้ดต่อไปนี้ เราจะเห็นว่าข้อมูลสังเคราะห์ถูกสร้างขึ้นด้วย DPPLV ด้วยชุดข้อมูลเครดิตของเยอรมันใต้ได้อย่างไร:
# Parameters for generated data
# How many rows of synthetic data
num_rows = 100 # Select all foreign workers who were accepted (foreign_worker value 1 credit_risk 1)
ForeignWorkerData = training_data.loc[(training_data['foreign_worker'] == 1) & (training_data['credit_risk'] == 1)] # Fit Foreign Worker data to SDV model
model = GaussianCopula()
model.fit(ForeignWorkerData) # Generate Synthetic foreign worker data based on rows stated
SynthForeignWorkers = model.sample(Rows)เราสร้างบันทึกสังเคราะห์ใหม่ 100 รายการของแรงงานต่างชาติโดยพิจารณาจากแรงงานต่างชาติที่ได้รับการยอมรับในชุดข้อมูลดั้งเดิม ตอนนี้เราจะนำบันทึกเหล่านั้นและแปลงป้ายกำกับ “credit_risk” เป็น 0 (เครดิตเสีย) สิ่งนี้จะถือว่าแรงงานต่างชาติเหล่านี้มีเครดิตไม่ดีอย่างไม่เป็นธรรม ดังนั้นจึงเป็นการแทรกอคติเข้าไปในชุดข้อมูลของเรา
SynthForeignWorkers.loc[SynthForeignWorkers['credit_risk'] == 1, 'credit_risk'] = 0เราสำรวจอคติในชุดข้อมูลผ่านกราฟด้านล่าง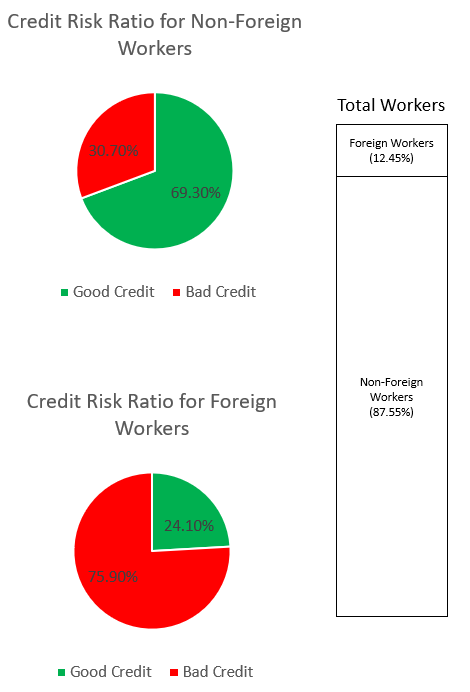
กราฟวงกลมด้านบนแสดงเปอร์เซ็นต์ของแรงงานที่ไม่ใช่ชาวต่างชาติที่มีป้ายกำกับว่าเครดิตดีหรือเครดิตไม่ดี และกราฟวงกลมด้านล่างแสดงเหมือนกันสำหรับแรงงานต่างชาติ เปอร์เซ็นต์ของแรงงานต่างชาติที่ถูกระบุว่าเป็น "เครดิตไม่ดี" คือ 75.90% และมีค่ามากกว่า 30.70% ของแรงงานที่ไม่ใช่ชาวต่างชาติที่ถูกระบุว่าเหมือนกัน แถบสแต็กแสดงเปอร์เซ็นต์การแจกแจงเกือบใกล้เคียงกันของคนงานทั้งหมดทั่วทั้งหมวดหมู่ของแรงงานต่างชาติและไม่ใช่ต่างชาติ
เราต้องการหลีกเลี่ยงโมเดล ML จากการเรียนรู้อคติที่รุนแรงต่อแรงงานต่างชาติไม่ว่าจะผ่านคุณสมบัติที่ชัดเจนหรือคุณสมบัติพร็อกซีโดยนัยในข้อมูล ด้วยวัตถุประสงค์เพิ่มเติมด้านความเป็นธรรม เราแนะนำโมเดล ML เพื่อลดอคติด้านความน่าเชื่อถือที่ลดลงต่อแรงงานต่างชาติ
ประสิทธิภาพของโมเดลหลังการปรับแต่งทั้งในด้านประสิทธิภาพและความเที่ยงตรง
แผนภูมินี้แสดงกราฟความหนาแน่นของงานปรับแต่งสูงสุด 100 รายการที่ดำเนินการโดย SageMaker AMT และค่าเมตริกวัตถุประสงค์รวมที่สอดคล้องกัน ทั้งๆที่เราได้กำหนดไว้ max jobs ถึง 100 สามารถเปลี่ยนแปลงได้ภายใต้ดุลยพินิจของผู้ใช้ เมตริกที่รวมกันคือการรวมกันของ AUC และ DPPL โดยมีฟังก์ชันดังนี้ (3*AUC + (1-DPPL)) / 4. เหตุผลที่เราใช้ (1-DPPL) แทน (DPPL) เนื่องจากเราต้องการเพิ่มวัตถุประสงค์รวมกันให้ได้มากที่สุดสำหรับ DPPL ที่ต่ำที่สุดเท่าที่จะเป็นไปได้ (DPPL ที่ต่ำกว่าหมายถึงอคติต่อแรงงานต่างชาติที่ลดลง) โครงเรื่องแสดงวิธีที่ AMT ช่วยระบุไฮเปอร์พารามิเตอร์ที่ดีที่สุดสำหรับโมเดล XGBoost ที่ส่งคืนค่าเมตริกการประเมินรวมสูงสุดที่ 0.68
ประสิทธิภาพของโมเดลด้วยเมตริกแบบรวม
ด้านล่างเราจะดูที่แผนภูมิด้านหน้าพาเรโตสำหรับแต่ละเมตริกของ AUC และ DPPL แผนภูมิ Pareto Front ใช้ที่นี่เพื่อแสดงภาพการแลกเปลี่ยนระหว่างวัตถุประสงค์หลายรายการ ในกรณีนี้คือค่าเมตริกสองค่า (AUC และ DPPL) จุดบนส่วนหน้าของเส้นโค้งถือว่าดีพอๆ กัน และไม่สามารถปรับปรุงเมตริกหนึ่งได้โดยไม่ลดทอนอีกเมตริกหนึ่ง แผนภูมิ Pareto ช่วยให้เราเห็นว่างานต่างๆ ดำเนินการอย่างไรเทียบกับเส้นฐาน (วงกลมสีแดง) ในแง่ของเมตริกทั้งสอง นอกจากนี้ยังแสดงให้เราเห็นงานที่เหมาะสมที่สุด (สามเหลี่ยมสีเขียว) ตำแหน่งของวงกลมสีแดงและสามเหลี่ยมสีเขียวมีความสำคัญเนื่องจากช่วยให้เราเข้าใจว่าเมตริกที่รวมกันของเรานั้นทำงานจริงตามที่คาดไว้และเพิ่มประสิทธิภาพสำหรับเมตริกทั้งสองอย่างแท้จริงหรือไม่ รหัสสำหรับสร้างแผนภูมิด้านหน้าพาเรโตรวมอยู่ในสมุดบันทึกใน GitHub.

ในสถานการณ์สมมตินี้ ค่า DPPL ที่ต่ำกว่าจะเป็นที่ต้องการมากกว่า (อคติน้อยลง) ในขณะที่ AUC ที่สูงขึ้นจะดีกว่า (ประสิทธิภาพที่เพิ่มขึ้น)
ที่นี่ เส้นฐาน (วงกลมสีแดง) แสดงถึงสถานการณ์ที่เมตริกวัตถุประสงค์คือ AUC เพียงอย่างเดียว กล่าวอีกนัยหนึ่ง พื้นฐานไม่พิจารณา DPPL เลย และปรับให้เหมาะสมสำหรับ AUC เท่านั้น (ไม่มีการปรับแต่งเพื่อความเป็นธรรม) เราเห็นว่าพื้นฐานมีคะแนน AUC ที่ดีที่ 0.74 แต่ทำงานได้ไม่ดีในด้านความเป็นธรรมด้วยคะแนน DPPL ที่ 0.75
โมเดลที่ปรับให้เหมาะสม (สามเหลี่ยมสีเขียว) แสดงถึงโมเดลตัวเลือกที่ดีที่สุดเมื่อปรับละเอียดสำหรับเมตริกรวมที่มีอัตราส่วนน้ำหนัก 3:1 สำหรับ AUC:DPPL เราพบว่าโมเดลที่ได้รับการปรับปรุงมีคะแนน AUC ที่ดีที่ 0.72 และยังมีคะแนน DPPL ต่ำที่ 0.43 (อคติต่ำ) งานปรับแต่งนี้พบการกำหนดค่าโมเดลที่ DPPL สามารถต่ำกว่าค่าพื้นฐานได้อย่างมาก โดย AUC ลดลงไม่มากนัก โมเดลที่มีคะแนน DPPL ต่ำกว่านั้นสามารถระบุได้ด้วยการเลื่อนสามเหลี่ยมสีเขียวไปทางซ้ายตามแนว Pareto Front เราจึงบรรลุวัตถุประสงค์รวมของรูปแบบที่ทำงานได้ดีและเป็นธรรมสำหรับกลุ่มย่อยของแรงงานต่างด้าว
ในแผนภูมิด้านล่าง เราจะเห็นผลลัพธ์ของการคาดการณ์จากแบบจำลองพื้นฐานและแบบจำลองที่ปรับให้เหมาะสม แบบจำลองที่ได้รับการปรับปรุงโดยมีวัตถุประสงค์รวมของประสิทธิภาพและความเป็นธรรมคาดการณ์ผลลัพธ์เชิงบวกสำหรับแรงงานต่างชาติ 30.6% เมื่อเทียบกับ 13.9% จากแบบจำลองพื้นฐาน โมเดลที่ปรับให้เหมาะสมจึงลดอคติของโมเดลกับกลุ่มย่อยนี้

สรุป
บล็อกแสดงให้คุณใช้การปรับให้เหมาะสมแบบหลายวัตถุประสงค์ด้วย SageMaker Automatic Model Tuning สำหรับแอปพลิเคชันในโลกแห่งความเป็นจริง ในหลายกรณี ข้อมูลที่เก็บรวบรวมในโลกแห่งความเป็นจริงอาจมีอคติกับกลุ่มย่อยบางกลุ่ม การเพิ่มประสิทธิภาพแบบหลายวัตถุประสงค์โดยใช้การปรับโมเดลอัตโนมัติช่วยให้ลูกค้าสร้างโมเดล ML ได้อย่างง่ายดาย ซึ่งปรับให้เหมาะสมที่สุดนอกเหนือจากความแม่นยำ เราแสดงตัวอย่างการคาดการณ์ความเสี่ยงด้านเครดิตและพิจารณาเฉพาะเรื่องความเป็นธรรมสำหรับแรงงานต่างด้าว เราแสดงให้เห็นว่าเป็นไปได้ที่จะเพิ่มเมตริกอื่นให้สูงสุด เช่น ความเที่ยงตรง ในขณะที่ฝึกโมเดลที่มีประสิทธิภาพสูงต่อไป หากสิ่งที่คุณได้อ่านไปกระตุ้นความสนใจของคุณ คุณอาจลองใช้ตัวอย่างโค้ดที่โฮสต์ใน Github โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม.
เกี่ยวกับผู้แต่ง
 มูนิช ดาบรา เป็นสถาปนิกโซลูชันอาวุโสที่ Amazon Web Services (AWS) สิ่งที่เขาสนใจในปัจจุบันคือ AI/ML, การวิเคราะห์ข้อมูล และความสามารถในการสังเกต เขามีภูมิหลังที่แข็งแกร่งในการออกแบบและสร้างระบบกระจายที่ปรับขนาดได้ เขาชอบช่วยเหลือลูกค้าในการคิดค้นและเปลี่ยนแปลงธุรกิจของพวกเขาใน AWS ลิงค์อิน: /mdabra
มูนิช ดาบรา เป็นสถาปนิกโซลูชันอาวุโสที่ Amazon Web Services (AWS) สิ่งที่เขาสนใจในปัจจุบันคือ AI/ML, การวิเคราะห์ข้อมูล และความสามารถในการสังเกต เขามีภูมิหลังที่แข็งแกร่งในการออกแบบและสร้างระบบกระจายที่ปรับขนาดได้ เขาชอบช่วยเหลือลูกค้าในการคิดค้นและเปลี่ยนแปลงธุรกิจของพวกเขาใน AWS ลิงค์อิน: /mdabra
 ฮาซัน ปุณณวลา เป็นสถาปนิกอาวุโสโซลูชัน AI/ML ที่ AWS Hasan ช่วยลูกค้าในการออกแบบและปรับใช้แอปพลิเคชันการเรียนรู้ของเครื่องในการผลิตบน AWS เขามีประสบการณ์การทำงานมากกว่า 12 ปีในฐานะนักวิทยาศาสตร์ข้อมูล ผู้ปฏิบัติงานด้านแมชชีนเลิร์นนิง และนักพัฒนาซอฟต์แวร์ ในเวลาว่าง Hasan ชอบที่จะสำรวจธรรมชาติและใช้เวลากับเพื่อนและครอบครัว
ฮาซัน ปุณณวลา เป็นสถาปนิกอาวุโสโซลูชัน AI/ML ที่ AWS Hasan ช่วยลูกค้าในการออกแบบและปรับใช้แอปพลิเคชันการเรียนรู้ของเครื่องในการผลิตบน AWS เขามีประสบการณ์การทำงานมากกว่า 12 ปีในฐานะนักวิทยาศาสตร์ข้อมูล ผู้ปฏิบัติงานด้านแมชชีนเลิร์นนิง และนักพัฒนาซอฟต์แวร์ ในเวลาว่าง Hasan ชอบที่จะสำรวจธรรมชาติและใช้เวลากับเพื่อนและครอบครัว
 โมฮัมหมัด (Moh) Tahsin เป็นผู้ช่วยสถาปนิก AI/ML Specialist Solutions สำหรับ AWS Moh มีประสบการณ์สอนนักเรียนเกี่ยวกับแนวคิด AI ที่มีความรับผิดชอบ และมีความกระตือรือร้นในการถ่ายทอดแนวคิดเหล่านี้ผ่านสถาปัตยกรรมบนระบบคลาวด์ ในเวลาว่างเขาชอบยกน้ำหนัก เล่นเกม และสำรวจธรรมชาติ
โมฮัมหมัด (Moh) Tahsin เป็นผู้ช่วยสถาปนิก AI/ML Specialist Solutions สำหรับ AWS Moh มีประสบการณ์สอนนักเรียนเกี่ยวกับแนวคิด AI ที่มีความรับผิดชอบ และมีความกระตือรือร้นในการถ่ายทอดแนวคิดเหล่านี้ผ่านสถาปัตยกรรมบนระบบคลาวด์ ในเวลาว่างเขาชอบยกน้ำหนัก เล่นเกม และสำรวจธรรมชาติ
 ซิงเฉินหม่า เป็นนักวิทยาศาสตร์ประยุกต์ที่ AWS เขาทำงานในทีมบริการสำหรับ SageMaker Automatic Model Tuning
ซิงเฉินหม่า เป็นนักวิทยาศาสตร์ประยุกต์ที่ AWS เขาทำงานในทีมบริการสำหรับ SageMaker Automatic Model Tuning
 ราหุล สุรกะ เป็น Enterprise Solution Architect ที่ AWS จากอินเดีย Rahul มีประสบการณ์มากกว่า 22 ปีในด้านการออกแบบสถาปัตยกรรมและเป็นผู้นำโปรแกรมการเปลี่ยนแปลงธุรกิจขนาดใหญ่ในหลายกลุ่มอุตสาหกรรม ความสนใจของเขาคือข้อมูลและการวิเคราะห์ การสตรีม และแอปพลิเคชัน AI/ML
ราหุล สุรกะ เป็น Enterprise Solution Architect ที่ AWS จากอินเดีย Rahul มีประสบการณ์มากกว่า 22 ปีในด้านการออกแบบสถาปัตยกรรมและเป็นผู้นำโปรแกรมการเปลี่ยนแปลงธุรกิจขนาดใหญ่ในหลายกลุ่มอุตสาหกรรม ความสนใจของเขาคือข้อมูลและการวิเคราะห์ การสตรีม และแอปพลิเคชัน AI/ML
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/tune-ml-models-for-additional-objectives-like-fairness-with-sagemaker-automatic-model-tuning/
- 1
- 10
- 100
- 28
- a
- เกี่ยวกับเรา
- แน่นอน
- ยอมรับได้
- การยอมรับ
- ได้รับการยอมรับ
- ยอมรับ
- ยอมรับ
- ความถูกต้อง
- ถูกต้อง
- แม่นยำ
- ประสบความสำเร็จ
- ข้าม
- จริง
- นอกจากนี้
- เพิ่มเติม
- ที่อยู่
- หลังจาก
- กับ
- AI
- AI / ML
- ขั้นตอนวิธี
- อัลกอริทึม
- ทั้งหมด
- ช่วยให้
- คนเดียว
- แม้ว่า
- เสมอ
- อเมซอน
- อเมซอน SageMaker
- Amazon Web Services
- Amazon Web Services (AWS)
- การวิเคราะห์
- และ
- อื่น
- การใช้งาน
- การใช้งาน
- ประยุกต์
- การประยุกต์ใช้
- เข้าใกล้
- สถาปัตยกรรม
- AREA
- พื้นที่
- แถว
- ที่ได้รับมอบหมาย
- ภาคี
- ที่เกี่ยวข้อง
- อัตโนมัติ
- อัตโนมัติ
- อัตโนมัติ
- ใช้ได้
- หลีกเลี่ยง
- AWS
- กลับ
- พื้นหลัง
- ไม่ดี
- ธนาคาร
- บาร์
- ตาม
- baseline
- เบย์เซียน
- เพราะ
- ก่อน
- หลัง
- เบื้องหลัง
- กำลัง
- ด้านล่าง
- ที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- อคติ
- บล็อก
- การยืม
- ด้านล่าง
- รายละเอียด
- สร้าง
- การก่อสร้าง
- สร้าง
- ธุรกิจ
- กระบวนการทางธุรกิจ
- การเปลี่ยนแปลงทางธุรกิจ
- ผู้สมัคร
- ไม่ได้
- กรณี
- หมวดหมู่
- หมวดหมู่
- บาง
- ท้าทาย
- แผนภูมิ
- เด็ก
- ทางเลือก
- Choose
- เลือก
- วงกลม
- ชั้น
- การจัดหมวดหมู่
- เมฆ
- รหัส
- คอลัมน์
- การผสมผสาน
- รวม
- ร่วมกัน
- การแข่งขัน
- การปฏิบัติตาม
- การคำนวณ
- แนวความคิด
- องค์ประกอบ
- การกำหนดค่า
- พิจารณา
- ถือว่า
- ข้อ จำกัด
- การบริโภค
- ภาชนะ
- สิ่งแวดล้อม
- อย่างต่อเนื่อง
- แปลง
- ตรงกัน
- ได้
- สร้าง
- การสร้าง
- เครดิต
- ความน่าเชื่อถือ
- ปัจจุบัน
- ขณะนี้
- เส้นโค้ง
- ลูกค้า
- ลูกค้า
- ข้อมูล
- วิเคราะห์ข้อมูล
- การเตรียมข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- ชุดข้อมูล
- การตัดสินใจ
- การตัดสินใจ
- การตัดสินใจ
- ค่าเริ่มต้น
- ประชากรศาสตร์
- ประชากร
- สาธิต
- แสดงให้เห็นถึง
- ปรับใช้
- นำไปใช้
- การใช้งาน
- ความลึก
- อธิบาย
- ออกแบบ
- การออกแบบ
- การกำหนด
- ผู้พัฒนา
- พัฒนาการ
- อุปกรณ์
- ความแตกต่าง
- ต่าง
- ดุลพินิจ
- แสดง
- กระจาย
- ระบบกระจาย
- หล่น
- ในระหว่าง
- แต่ละ
- อย่างง่ายดาย
- EBS
- อย่างมีประสิทธิภาพ
- ทั้ง
- การจ้าง
- ช่วยให้
- ส่งเสริม
- พลังงาน
- การใช้พลังงาน
- ทำให้มั่นใจ
- Enterprise
- พอ ๆ กัน
- โดยเฉพาะอย่างยิ่ง
- อีเธอร์ (ETH)
- ประเมินค่า
- ประเมิน
- การประเมินผล
- แม้
- ในที่สุด
- ตัวอย่าง
- ที่มีอยู่
- ที่คาดหวัง
- ประสบการณ์
- สำรวจ
- ด่วน
- อย่างเป็นธรรม
- ความเป็นธรรม
- ครอบครัว
- ไกล
- โปรดปราน
- คุณสมบัติ
- รูป
- สุดท้าย
- ทางการเงิน
- บริการทางการเงิน
- หา
- หา
- พบ
- ปลาย
- บริษัท
- พอดี
- การแก้ไข
- โฟกัส
- ดังต่อไปนี้
- ดังต่อไปนี้
- ต่างประเทศ
- พบ
- เพื่อน
- ราคาเริ่มต้นที่
- ด้านหน้า
- ฟังก์ชัน
- ฟังก์ชั่น
- ต่อไป
- อนาคต
- เกม
- เพศ
- โดยทั่วไป
- สร้าง
- สร้าง
- รุ่น
- ภาษาเยอรมัน
- GitHub
- กำหนด
- เหตุการณ์ที่
- Go
- ดี
- กราฟ
- กราฟ
- สีเขียว
- ตะแกรง
- บัญชีกลุ่ม
- กลุ่ม
- ให้คำแนะนำ
- หนัก
- ช่วย
- การช่วยเหลือ
- จะช่วยให้
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- จุดสูง
- สูงกว่า
- ที่สูงที่สุด
- ทางประวัติศาสตร์
- ประวัติ
- เป็นเจ้าภาพ
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- HTTPS
- เป็นมนุษย์
- มนุษย์
- การเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์
- การปรับแต่งไฮเปอร์พารามิเตอร์
- ICS
- ระบุ
- แยกแยะ
- ความไม่สมดุล
- การเข้าเมือง
- การดำเนินการ
- นำเข้า
- สำคัญ
- การปรับปรุง
- in
- ในอื่น ๆ
- ประกอบด้วย
- รวม
- รวมทั้ง
- เพิ่มขึ้น
- อินเดีย
- เป็นรายบุคคล
- อุตสาหกรรม
- เราสร้างสรรค์สิ่งใหม่ ๆ
- อินพุต
- ตัวอย่าง
- แทน
- อยากเรียนรู้
- สนใจ
- ผลประโยชน์
- รวมถึง
- IT
- ตัวเอง
- การสัมภาษณ์
- งาน
- ฉลาก
- ป้ายกำกับ
- ภาษา
- ใหญ่
- ชื่อสกุล
- ชั้นนำ
- เรียนรู้
- การเรียนรู้
- ผู้ให้กู้
- การให้กู้ยืมเงิน
- ชั้น
- LIMIT
- รายการ
- เงินกู้
- ดู
- ดูเหมือน
- ปิด
- ต่ำ
- เครื่อง
- เรียนรู้เครื่อง
- ทำ
- การทำ
- หลาย
- เครื่องหมาย
- เพิ่ม
- เพิ่ม
- สูงสุด
- วิธี
- วัด
- มาตรการ
- การวัด
- วิธีการ
- เมตริก
- ตัวชี้วัด
- อาจ
- การลด
- ขั้นต่ำ
- บรรเทา
- ML
- โทรศัพท์มือถือ
- อุปกรณ์มือถือ
- แบบ
- โมเดล
- เงิน
- การตรวจสอบ
- ข้อมูลเพิ่มเติม
- มากที่สุด
- การย้าย
- หลาย
- หลาย
- เป็นธรรมชาติ
- ธรรมชาติ
- จำเป็นต้อง
- จำเป็น
- เครือข่าย
- ประสาท
- เครือข่ายประสาท
- ใหม่
- ปม
- สมุดบันทึก
- จำนวน
- วัตถุประสงค์
- วัตถุประสงค์
- เสนอ
- ONE
- ทำงาน
- การดำเนินการ
- ตรงข้าม
- ดีที่สุด
- การเพิ่มประสิทธิภาพ
- เพิ่มประสิทธิภาพ
- การปรับให้เหมาะสม
- เพิ่มประสิทธิภาพ
- การเพิ่มประสิทธิภาพ
- เป็นต้นฉบับ
- อื่นๆ
- ผลิตภัณฑ์อื่นๆ
- ผล
- เกินดุล
- ภาพรวม
- เจ้าของ
- แพ็คเกจ
- พารามิเตอร์
- ในสิ่งที่สนใจ
- ที่ผ่านไป
- หลงใหล
- การจ่ายเงิน
- การชำระเงิน
- รูปแบบไฟล์ PDF
- เปอร์เซ็นต์
- ดำเนินการ
- การปฏิบัติ
- ที่มีประสิทธิภาพ
- ดำเนินการ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- จุด
- ประชากร
- ตำแหน่ง
- บวก
- เป็นไปได้
- ที่มีศักยภาพ
- ที่คาดการณ์
- คำทำนาย
- การคาดการณ์
- คาดการณ์
- ป้องกัน
- ประถม
- กระบวนการ
- กระบวนการ
- การประมวลผล
- การผลิต
- ผลิตภัณฑ์
- โปรไฟล์
- โปรแกรม
- ให้
- หนังสือมอบฉันทะ
- วัตถุประสงค์
- หลาม
- คุณภาพ
- เชื่อชาติ
- สุ่ม
- พิสัย
- อัตราส่วน
- อ่าน
- จริง
- โลกแห่งความจริง
- เหตุผล
- การรับรู้
- บันทึก
- สีแดง
- ลด
- ลด
- ลด
- สะท้อน
- หน่วยงานกำกับดูแล
- ปฏิบัติตามกฎระเบียบ
- กรุ
- แสดง
- แสดงให้เห็นถึง
- จำเป็นต้องใช้
- ความต้องการ
- รับผิดชอบ
- ผล
- ผลสอบ
- กลับ
- การคืน
- รับคืน
- ทบทวน
- ความเสี่ยง
- วิ่ง
- วิ่ง
- sagemaker
- การปรับโมเดลอัตโนมัติของ SageMaker
- เดียวกัน
- ความพึงพอใจ
- ที่ปรับขนาดได้
- สถานการณ์
- ฉาก
- นักวิทยาศาสตร์
- ค้นหา
- กลุ่ม
- ระดับอาวุโส
- มีความละเอียดอ่อน
- บริการ
- บริการ
- ชุด
- ที่ใช้ร่วมกัน
- น่า
- โชว์
- แสดงให้เห็นว่า
- สำคัญ
- อย่างมีความหมาย
- คล้ายคลึงกัน
- ง่าย
- พร้อมกัน
- เดียว
- ขนาด
- มีขนาดเล็กกว่า
- ซอฟต์แวร์
- ทางออก
- โซลูชัน
- บาง
- ภาคใต้
- ผู้เชี่ยวชาญ
- โดยเฉพาะ
- เฉพาะ
- ที่ระบุไว้
- การพูด
- การรู้จำเสียง
- ใช้จ่าย
- แยก
- กอง
- ผู้มีส่วนได้เสีย
- ระบุ
- ทางสถิติ
- Status
- ขั้นตอน
- ยังคง
- กลยุทธ์
- ที่พริ้ว
- แข็งแรง
- โครงสร้าง
- นักเรียน
- หรือ
- อย่างเช่น
- สังเคราะห์
- ข้อมูลสังเคราะห์
- สังเคราะห์
- ระบบ
- ระบบ
- เอา
- การเรียนการสอน
- ทีม
- เงื่อนไขการใช้บริการ
- พื้นที่
- ก้าวสู่อนาคต
- ของพวกเขา
- ตลอด
- เวลา
- ครั้ง
- ไปยัง
- ด้านบน
- รวม
- ไปทาง
- รถไฟ
- การฝึกอบรม
- แปลง
- การแปลง
- ความโปร่งใส
- รักษา
- เป็นปกติ
- ความไม่แน่นอน
- ภายใต้
- เข้าใจ
- ที่กำลังมา
- การปรับปรุง
- us
- การใช้
- ใช้
- ใช้กรณี
- ผู้ใช้งาน
- การตรวจสอบ
- ความถูกต้อง
- ความคุ้มค่า
- ความคุ้มค่า
- ต่างๆ
- รุ่น
- ไดรฟ์
- เว็บ
- บริการเว็บ
- น้ำหนัก
- อะไร
- ว่า
- ที่
- ในขณะที่
- WHO
- จะ
- ภายใน
- ไม่มี
- คำ
- งาน
- ผู้ปฏิบัติงาน
- แรงงาน
- โรงงาน
- โลก
- จะ
- XGBoost
- ปี
- ของคุณ
- ลมทะเล