ภูเขาน้ำแข็งอาปาเช่ เป็นรูปแบบตารางเปิดสำหรับชุดข้อมูลการวิเคราะห์ขนาดใหญ่มาก ซึ่งจะรวบรวมข้อมูลเมตาดาต้าเกี่ยวกับสถานะของชุดข้อมูลขณะที่ชุดข้อมูลมีการพัฒนาและเปลี่ยนแปลงตลอดเวลา เพิ่มตารางลงในเครื่องมือคำนวณ ได้แก่ Spark, Trino, PrestoDB, Flink และ Hive โดยใช้รูปแบบตารางประสิทธิภาพสูงที่ทำงานเหมือนกับตาราง SQL Iceberg ได้รับความนิยมอย่างมากจากการรองรับธุรกรรม ACID ใน data lake และคุณสมบัติต่างๆ เช่น schema และการพัฒนาพาร์ติชัน การเดินทางข้ามเวลา และการย้อนกลับ
การรวม Apache Iceberg ได้รับการสนับสนุนโดยบริการวิเคราะห์ของ AWS ได้แก่ อเมซอน EMR, อเมซอน อาเธน่าและ AWS กาว. Amazon EMR สามารถจัดเตรียมคลัสเตอร์ด้วย Spark, Hive, Trino และ Flink ที่สามารถเรียกใช้ Iceberg เริ่มต้นด้วย Amazon EMR เวอร์ชัน 6.5.0 คุณทำได้ ใช้ Iceberg กับคลัสเตอร์ EMR ของคุณ โดยไม่ต้องมีการดำเนินการบูตสแตรป ในช่วงต้นปี 2022 AWS ประกาศความพร้อมใช้งานทั่วไปของธุรกรรม Athena ACID ซึ่งขับเคลื่อนโดย Apache Iceberg ที่เพิ่งเปิดตัว เอ็นจิ้นแบบสอบถาม Athena เวอร์ชัน 3 ให้การรวมที่ดีขึ้นกับรูปแบบตารางภูเขาน้ำแข็ง AWS Glue 3.0 และใหม่กว่า รองรับเฟรมเวิร์ก Apache Iceberg สำหรับทะเลสาบข้อมูล
ในโพสต์นี้ เราจะพูดถึงสิ่งที่ลูกค้าต้องการใน Data Lake ที่ทันสมัย และวิธีที่ Apache Iceberg ช่วยตอบสนองความต้องการของลูกค้า จากนั้นเราจะอธิบายถึงวิธีแก้ปัญหาเพื่อสร้างทะเลสาบข้อมูล Iceberg ที่มีประสิทธิภาพสูงและกำลังพัฒนา บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) และประมวลผลข้อมูลส่วนเพิ่มโดยการเรียกใช้คำสั่งแทรก อัปเดต และลบ SQL สุดท้าย เราจะแสดงวิธีปรับแต่งประสิทธิภาพกระบวนการเพื่อปรับปรุงประสิทธิภาพการอ่านและเขียน
Apache Iceberg จัดการกับสิ่งที่ลูกค้าต้องการใน Data Lake สมัยใหม่ได้อย่างไร
ลูกค้าจำนวนมากขึ้นเรื่อยๆ กำลังสร้าง Data Lake ด้วยข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง เพื่อรองรับผู้ใช้ แอปพลิเคชัน และเครื่องมือวิเคราะห์จำนวนมาก Data Lake มีความต้องการเพิ่มขึ้นเพื่อรองรับฐานข้อมูล เช่น คุณลักษณะต่างๆ เช่น ธุรกรรม ACID การอัปเดตและการลบในระดับบันทึก การเดินทางข้ามเวลา และการย้อนกลับ Apache Iceberg ได้รับการออกแบบมาเพื่อรองรับคุณสมบัติเหล่านี้ใน Data Lake ขนาดเพตะไบต์ที่คุ้มค่าบน Amazon S3
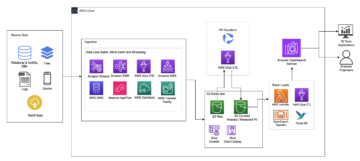
Apache Iceberg ตอบสนองความต้องการของลูกค้าด้วยการรวบรวมข้อมูลเมตาดาต้าที่หลากหลายเกี่ยวกับชุดข้อมูลในเวลาที่สร้างไฟล์ข้อมูลแต่ละไฟล์ มีสามชั้นในสถาปัตยกรรมของตารางภูเขาน้ำแข็ง: แคตตาล็อกภูเขาน้ำแข็ง ชั้นข้อมูลเมตา และชั้นข้อมูล ดังที่แสดงในรูปต่อไปนี้ (แหล่ง).

แค็ตตาล็อก Iceberg เก็บตัวชี้ข้อมูลเมตาไปยังไฟล์ข้อมูลเมตาของตารางปัจจุบัน เมื่อคิวรีแบบใช้เลือกข้อมูลกำลังอ่านตาราง Iceberg เอ็นจิ้นการสืบค้นจะไปที่แค็ตตาล็อกของ Iceberg ก่อน แล้วจึงดึงตำแหน่งของไฟล์ข้อมูลเมตาปัจจุบัน เมื่อใดก็ตามที่มีการอัปเดตตาราง Iceberg จะมีการสร้างสแน็ปช็อตใหม่ของตาราง และตัวชี้ข้อมูลเมตาจะชี้ไปที่ไฟล์ข้อมูลเมตาของตารางปัจจุบัน
ต่อไปนี้คือตัวอย่างแคตตาล็อก Iceberg ที่มีการใช้งาน AWS Glue คุณสามารถดูชื่อฐานข้อมูล ตำแหน่ง (เส้นทาง S3) ของตาราง Iceberg และตำแหน่งข้อมูลเมตา

ชั้นข้อมูลเมตามีไฟล์สามประเภท: ไฟล์ข้อมูลเมตา รายการรายการ และไฟล์รายการในลำดับชั้น ที่ด้านบนสุดของลำดับชั้นคือไฟล์ข้อมูลเมตา ซึ่งเก็บข้อมูลเกี่ยวกับสคีมาของตาราง ข้อมูลพาร์ติชัน และสแน็ปช็อต ภาพรวมชี้ไปที่รายการรายการ รายการรายการมีข้อมูลเกี่ยวกับไฟล์รายการแต่ละรายการที่ประกอบกันเป็นสแนปชอต เช่น ตำแหน่งของไฟล์รายการ พาร์ติชันที่เป็นของไฟล์ และขอบเขตล่างและบนสำหรับคอลัมน์พาร์ติชันสำหรับไฟล์ข้อมูลที่ติดตาม ไฟล์รายการติดตามไฟล์ข้อมูลตลอดจนรายละเอียดเพิ่มเติมเกี่ยวกับแต่ละไฟล์ เช่น รูปแบบไฟล์ ไฟล์ทั้งสามทำงานในลำดับชั้นเพื่อติดตามสแน็ปช็อต สคีมา การแบ่งพาร์ติชัน คุณสมบัติ และไฟล์ข้อมูลในตารางไอซ์เบิร์ก
ชั้นข้อมูลมีไฟล์ข้อมูลแต่ละไฟล์ของตารางภูเขาน้ำแข็ง Iceberg รองรับรูปแบบไฟล์ที่หลากหลาย เช่น Parquet, ORC และ Avro เนื่องจากตาราง Iceberg ติดตามไฟล์ข้อมูลแต่ละไฟล์ แทนที่จะชี้ไปยังตำแหน่งพาร์ติชันที่มีไฟล์ข้อมูลเท่านั้น จึงแยกการดำเนินการเขียนออกจากการดำเนินการอ่าน คุณสามารถเขียนไฟล์ข้อมูลเมื่อใดก็ได้ แต่ยอมรับการเปลี่ยนแปลงอย่างชัดเจนเท่านั้น ซึ่งจะสร้างเวอร์ชันใหม่ของไฟล์สแน็ปช็อตและข้อมูลเมตา
ภาพรวมโซลูชัน
ในโพสต์นี้ เราจะแนะนำวิธีแก้ปัญหาในการสร้างทะเลสาบข้อมูล Apache Iceberg ที่มีประสิทธิภาพสูงบน Amazon S3 ประมวลผลข้อมูลส่วนเพิ่มด้วยการแทรก อัพเดต และลบคำสั่ง SQL และปรับแต่งตาราง Iceberg เพื่อปรับปรุงประสิทธิภาพการอ่านและเขียน ไดอะแกรมต่อไปนี้แสดงสถาปัตยกรรมของโซลูชัน

เพื่อสาธิตวิธีแก้ปัญหานี้ เราใช้ บทวิจารณ์ของลูกค้า Amazon ชุดข้อมูลในบัคเก็ต S3 (s3://amazon-reviews-pds/parquet/). ในกรณีการใช้งานจริง จะเป็นข้อมูลดิบที่จัดเก็บไว้ในบัคเก็ต S3 ของคุณ เราสามารถตรวจสอบขนาดข้อมูลได้ด้วยโค้ดต่อไปนี้ใน อินเทอร์เฟซบรรทัดคำสั่ง AWS AWS (AWS CLI):
จำนวนวัตถุทั้งหมดคือ 430 และขนาดรวมคือ 47.4 GiB
ในการตั้งค่าและทดสอบโซลูชันนี้ เราทำตามขั้นตอนระดับสูงต่อไปนี้:
- ตั้งค่าบัคเก็ต S3 ในโซนที่ดูแลจัดการเพื่อจัดเก็บข้อมูลที่แปลงแล้วในรูปแบบตาราง Iceberg
- เปิดใช้งานคลัสเตอร์ EMR ด้วยการกำหนดค่าที่เหมาะสมสำหรับ Apache Iceberg
- สร้างสมุดบันทึกใน EMR Studio
- กำหนดค่าเซสชัน Spark สำหรับ Apache Iceberg
- แปลงข้อมูลเป็นรูปแบบตาราง Iceberg และย้ายข้อมูลไปยังโซนที่ดูแลจัดการ
- เรียกใช้คำสั่งแทรก อัปเดต และลบใน Athena เพื่อประมวลผลข้อมูลส่วนเพิ่ม
- ดำเนินการปรับแต่งประสิทธิภาพ
เบื้องต้น
ในการปฏิบัติตามแนวทางปฏิบัตินี้ คุณต้องมี บัญชี AWS ด้วย AWS Identity และการจัดการการเข้าถึง บทบาท (IAM) ที่มีสิทธิ์เข้าถึงเพียงพอเพื่อจัดเตรียมทรัพยากรที่จำเป็น
ตั้งค่าบัคเก็ต S3 สำหรับข้อมูล Iceberg ในโซนที่ดูแลจัดการในที่จัดเก็บข้อมูลดิบของคุณ
เลือกภูมิภาคที่คุณต้องการสร้างบัคเก็ต S3 และระบุชื่อเฉพาะ:
เปิดใช้คลัสเตอร์ EMR เพื่อเรียกใช้งาน Iceberg โดยใช้ Spark
คุณสามารถสร้างคลัสเตอร์ EMR จาก คอนโซลการจัดการ AWS, Amazon EMR CLI หรือ ชุดพัฒนา AWS Cloud (AWS CDK) สำหรับโพสต์นี้ เราจะแนะนำวิธีการสร้างคลัสเตอร์ EMR จากคอนโซล
- บนคอนโซล Amazon EMR ให้เลือก สร้างคลัสเตอร์.
- Choose ตัวเลือกขั้นสูง.
- สำหรับ การกำหนดค่าซอฟต์แวร์ให้เลือก Amazon EMR รุ่นล่าสุด ในเดือนมกราคม 2023 รุ่นล่าสุดคือ 6.9.0 Iceberg ต้องการรุ่น 6.5.0 ขึ้นไป
- เลือก JupyterEnterpriseเกตเวย์ และ จุดประกาย เป็นซอฟต์แวร์ที่จะติดตั้ง
- สำหรับ แก้ไขการตั้งค่าซอฟต์แวร์ให้เลือก เข้าสู่การกำหนดค่า และป้อน
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - ปล่อยให้การตั้งค่าอื่น ๆ เป็นค่าเริ่มต้นและเลือก ถัดไป.

- สำหรับ ฮาร์ดแวร์ให้ใช้การตั้งค่าเริ่มต้น
- Choose ถัดไป.
- สำหรับ ชื่อคลัสเตอร์ป้อนชื่อ เราใช้
iceberg-blog-cluster. - ปล่อยให้การตั้งค่าที่เหลือไม่เปลี่ยนแปลงและเลือก ถัดไป.
- Choose สร้างคลัสเตอร์.
สร้างสมุดบันทึกใน EMR Studio
ตอนนี้เราจะแนะนำวิธีการสร้างสมุดบันทึกใน EMR Studio จากคอนโซล
- บนคอนโซล IAM สร้างบทบาทบริการ EMR Studio.
- บนคอนโซล Amazon EMR ให้เลือก อีเอ็มอาร์ สตูดิโอ.
- Choose สมัครที่นี่.
พื้นที่ สมัครที่นี่ หน้าปรากฏในแท็บใหม่
- Choose สร้างสตูดิโอ ในแท็บใหม่
- ป้อนชื่อ เราใช้ภูเขาน้ำแข็งสตูดิโอ
- เลือก VPC และซับเน็ตเดียวกันกับคลัสเตอร์ EMR และกลุ่มความปลอดภัยเริ่มต้น
- Choose AWS Identity และการจัดการการเข้าถึง (IAM) สำหรับการตรวจสอบสิทธิ์ และเลือกบทบาทบริการ EMR Studio ที่คุณเพิ่งสร้างขึ้น
- เลือกเส้นทาง S3 สำหรับ การสำรองข้อมูลพื้นที่ทำงาน.
- Choose สร้างสตูดิโอ.
- หลังจากสร้าง Studio แล้ว ให้เลือก URL การเข้าถึง Studio
- บนแดชบอร์ด EMR Studio เลือก สร้างพื้นที่ทำงาน.
- ป้อนชื่อสำหรับพื้นที่ทำงานของคุณ เราใช้
iceberg-workspace. - แสดง การกำหนดค่าขั้นสูง และเลือก แนบพื้นที่ทำงานกับคลัสเตอร์ EMR.
- เลือกคลัสเตอร์ EMR ที่คุณสร้างไว้ก่อนหน้านี้
- Choose สร้างพื้นที่ทำงาน.
- เลือกชื่อพื้นที่ทำงานเพื่อเปิดแท็บใหม่
ในบานหน้าต่างนำทาง มีสมุดบันทึกที่มีชื่อเดียวกับพื้นที่ทำงาน ในกรณีของเรา มันคือพื้นที่ทำงานบนภูเขาน้ำแข็ง
- เปิดสมุดบันทึก
- เมื่อได้รับแจ้งให้เลือกเคอร์เนล ให้เลือก จุดประกาย.
กำหนดค่าเซสชัน Spark สำหรับ Apache Iceberg
ใช้โค้ดต่อไปนี้ ระบุชื่อบัคเก็ต S3 ของคุณเอง:
สิ่งนี้ตั้งค่าการกำหนดค่าเซสชัน Spark ต่อไปนี้:
- spark.sql.catalog.demo – ลงทะเบียนแค็ตตาล็อก Spark ชื่อเดโม ซึ่งใช้ปลั๊กอินแคตตาล็อก Iceberg Spark
- spark.sql.catalog.demo.catalog-impl – แค็ตตาล็อก Spark สาธิตใช้ AWS Glue เป็นแคตตาล็อกจริงเพื่อจัดเก็บฐานข้อมูล Iceberg และข้อมูลตาราง
- spark.sql.catalog.demo.warehouse – แค็ตตาล็อก Spark สาธิตเก็บข้อมูลเมตาและไฟล์ข้อมูลของ Iceberg ทั้งหมดภายใต้เส้นทางรูทที่กำหนดโดยคุณสมบัตินี้:
s3://iceberg-curated-blog-data. - spark.sql.ส่วนขยาย – เพิ่มการรองรับส่วนขยาย Iceberg Spark SQL ซึ่งอนุญาตให้คุณเรียกใช้ขั้นตอน Iceberg Spark และคำสั่ง SQL เฉพาะของ Iceberg เท่านั้น (คุณใช้คำสั่งนี้ในขั้นตอนต่อไป)
- spark.sql.catalog.demo.io-impl – Iceberg ช่วยให้ผู้ใช้สามารถเขียนข้อมูลไปยัง Amazon S3 ผ่าน S3FileIO AWS Glue Data Catalog ใช้ FileIO นี้โดยค่าเริ่มต้น และแค็ตตาล็อกอื่นๆ สามารถโหลด FileIO นี้โดยใช้คุณสมบัติแคตตาล็อก io-impl
แปลงข้อมูลเป็นรูปแบบตารางภูเขาน้ำแข็ง
คุณสามารถใช้ Spark บน Amazon EMR หรือ Athena เพื่อโหลดตาราง Iceberg ในเซสชัน Spark ของโน้ตบุ๊ก EMR Studio Workspace ให้รันคำสั่งต่อไปนี้เพื่อโหลดข้อมูล:
หลังจากที่คุณรันโค้ด คุณควรพบคำนำหน้าสองรายการที่สร้างขึ้นในพาธ S3 ของคลังข้อมูลของคุณ (s3://iceberg-curated-blog-data/reviews.db/all_reviews): ข้อมูลและข้อมูลเมตา
ประมวลผลข้อมูลส่วนเพิ่มโดยใช้การแทรก อัพเดต และลบคำสั่ง SQL ใน Athena
Athena เป็นเครื่องมือสืบค้นแบบไร้เซิร์ฟเวอร์ที่คุณสามารถใช้เพื่อดำเนินการอ่าน เขียน อัปเดต และปรับให้เหมาะสมเทียบกับตาราง Iceberg เพื่อแสดงให้เห็นว่ารูปแบบ Data Lake ของ Apache Iceberg สนับสนุนการนำเข้าข้อมูลส่วนเพิ่มอย่างไร เราจึงเรียกใช้คำสั่งแทรก อัปเดต และลบ SQL บน Data Lake
ไปที่คอนโซล Athena แล้วเลือก ตัวแก้ไขแบบสอบถาม. หากนี่เป็นครั้งแรกที่คุณใช้ตัวแก้ไขแบบสอบถาม Athena คุณต้องทำ กำหนดค่าตำแหน่งผลลัพธ์ของแบบสอบถาม เป็นบัคเก็ต S3 ที่คุณสร้างไว้ก่อนหน้านี้ คุณควรจะเห็นว่าตาราง review.all_reviews พร้อมสำหรับการสอบถาม เรียกใช้แบบสอบถามต่อไปนี้เพื่อตรวจสอบว่าคุณโหลดตาราง Iceberg สำเร็จแล้ว:
ประมวลผลข้อมูลส่วนเพิ่มโดยการรันคำสั่งแทรก อัพเดต และลบ SQL:
การปรับแต่งประสิทธิภาพ
ในส่วนนี้ เราจะแนะนำวิธีต่างๆ เพื่อปรับปรุงประสิทธิภาพการอ่านและเขียนของ Apache Iceberg
กำหนดค่าคุณสมบัติของตาราง Apache Iceberg
Apache Iceberg เป็นรูปแบบตาราง และสนับสนุนคุณสมบัติของตารางเพื่อกำหนดค่าลักษณะการทำงานของตาราง เช่น การอ่าน เขียน และแค็ตตาล็อก คุณสามารถปรับปรุงประสิทธิภาพการอ่านและเขียนบนตาราง Iceberg ได้โดยการปรับคุณสมบัติของตาราง
ตัวอย่างเช่น หากคุณสังเกตว่าคุณเขียนไฟล์ขนาดเล็กมากเกินไปสำหรับตาราง Iceberg คุณสามารถกำหนดค่าขนาดไฟล์เขียนให้เขียนไฟล์น้อยลงแต่มีขนาดใหญ่ขึ้น เพื่อช่วยปรับปรุงประสิทธิภาพการสืบค้น
| อสังหาริมทรัพย์ | ค่าเริ่มต้น | รายละเอียด |
| write.target-ขนาดไฟล์ไบต์ | 536870912 (512 MB) | ควบคุมขนาดของไฟล์ที่สร้างขึ้นเพื่อกำหนดเป้าหมายจำนวนไบต์นี้ |
ใช้รหัสต่อไปนี้เพื่อเปลี่ยนรูปแบบตาราง:
การแบ่งพาร์ติชันและการเรียงลำดับ
ในการทำให้การสืบค้นทำงานเร็ว ยิ่งอ่านข้อมูลน้อยยิ่งดี Iceberg ใช้ประโยชน์จากข้อมูลเมตามากมายที่บันทึกในขณะเขียนและอำนวยความสะดวกในเทคนิคต่างๆ เช่น การวางแผนการสแกน การแบ่งพาร์ติชัน การตัด และสถิติระดับคอลัมน์ เช่น ค่าต่ำสุด/สูงสุด เพื่อข้ามไฟล์ข้อมูลที่ไม่มีบันทึกที่ตรงกัน เราจะแนะนำวิธีการวางแผนการสแกนแบบสอบถามและการแบ่งพาร์ติชันใน Iceberg และวิธีที่เราใช้เพื่อปรับปรุงประสิทธิภาพการค้นหา
การวางแผนการสแกนแบบสอบถาม
สำหรับข้อความค้นหาที่กำหนด ขั้นตอนแรกในเครื่องมือสืบค้นข้อมูลคือการวางแผนการสแกน ซึ่งเป็นกระบวนการค้นหาไฟล์ในตารางที่จำเป็นสำหรับแบบสอบถาม การวางแผนในตาราง Iceberg มีประสิทธิภาพมาก เนื่องจากข้อมูลเมตาที่สมบูรณ์ของ Iceberg สามารถใช้เพื่อตัดไฟล์ข้อมูลเมตาที่ไม่จำเป็น นอกเหนือจากการกรองไฟล์ข้อมูลที่ไม่มีข้อมูลที่ตรงกัน ในการทดสอบของเรา เราสังเกตว่า Athena สแกนข้อมูล 50% หรือน้อยกว่าสำหรับข้อความค้นหาที่ระบุในตาราง Iceberg เปรียบเทียบกับข้อมูลต้นฉบับก่อนแปลงเป็นรูปแบบ Iceberg
การกรองมีสองประเภท:
- การกรองข้อมูลเมตา – Iceberg ใช้ข้อมูลเมตาสองระดับเพื่อติดตามไฟล์ในภาพรวม: รายการรายการและไฟล์รายการ ก่อนอื่นจะใช้รายการรายการซึ่งทำหน้าที่เป็นดัชนีของไฟล์รายการ ในระหว่างการวางแผน Iceberg จะกรองรายการโดยใช้ช่วงค่าพาร์ติชันในรายการรายการโดยไม่อ่านไฟล์รายการทั้งหมด จากนั้นจะใช้ไฟล์รายการที่เลือกเพื่อรับไฟล์ข้อมูล
- การกรองข้อมูล – หลังจากเลือกรายการไฟล์รายการแล้ว Iceberg จะใช้ข้อมูลพาร์ติชันและสถิติระดับคอลัมน์สำหรับไฟล์ข้อมูลแต่ละไฟล์ที่จัดเก็บไว้ในไฟล์รายการเพื่อกรองไฟล์ข้อมูล ในระหว่างการวางแผน เพรดิเคตเคียวรีจะถูกแปลงเป็นเพรดิเคตบนข้อมูลพาร์ติชัน และนำไปใช้ก่อนเพื่อกรองไฟล์ข้อมูล จากนั้น สถิติของคอลัมน์ เช่น การนับค่าระดับคอลัมน์ การนับ Null ขอบเขตล่าง และขอบเขตบนจะถูกใช้เพื่อกรองไฟล์ข้อมูลที่ไม่ตรงกับเพรดิเคตคิวรี ด้วยการใช้ขอบเขตบนและล่างเพื่อกรองไฟล์ข้อมูลในเวลาวางแผน Iceberg ปรับปรุงประสิทธิภาพการสืบค้นอย่างมาก
การแบ่งพาร์ติชันและการเรียงลำดับ
การแบ่งพาร์ติชันเป็นวิธีการจัดกลุ่มระเบียนที่มีค่าคอลัมน์หลักเดียวกันไว้ด้วยกันเป็นลายลักษณ์อักษร ประโยชน์ของการแบ่งพาร์ติชันคือการสืบค้นที่รวดเร็วขึ้นซึ่งเข้าถึงข้อมูลเพียงบางส่วน ตามที่อธิบายไว้ก่อนหน้านี้ในการวางแผนการสแกนแบบสอบถาม: การกรองข้อมูล Iceberg ทำให้การแบ่งพาร์ติชันเป็นเรื่องง่ายโดยรองรับการแบ่งพาร์ติชันแบบซ่อน ในลักษณะที่ Iceberg สร้างค่าของพาร์ติชันโดยรับค่าคอลัมน์และแปลงทางเลือก
ในกรณีการใช้งานของเรา อันดับแรก เราเรียกใช้การสืบค้นต่อไปนี้บนตาราง Iceberg ที่ไม่ได้แบ่งพาร์ติชัน จากนั้นเราจะแบ่งตาราง Iceberg ตามหมวดหมู่ของบทวิจารณ์ ซึ่งจะใช้ในเงื่อนไขการค้นหา WHERE เพื่อกรองข้อมูลออก ด้วยการแบ่งพาร์ติชัน แบบสอบถามสามารถสแกนข้อมูลน้อยลงมาก ดูรหัสต่อไปนี้:
รันคำสั่ง select ต่อไปนี้บนตาราง all_reviews ที่ไม่ได้แบ่งพาร์ติชันเทียบกับตารางที่แบ่งพาร์ติชันเพื่อดูความแตกต่างของประสิทธิภาพ:
ตารางต่อไปนี้แสดงการปรับปรุงประสิทธิภาพของการแบ่งพาร์ติชันข้อมูล โดยมีการปรับปรุงประสิทธิภาพประมาณ 50% และสแกนข้อมูลน้อยลง 70%
| ชื่อชุดข้อมูล | ชุดข้อมูลที่ไม่แบ่งพาร์ติชัน | ชุดข้อมูลที่แบ่งพาร์ติชัน |
| รันไทม์ (วินาที) | 8.20 | 4.25 |
| ข้อมูลที่สแกน (MB) | 131.55 | 33.79 |
โปรดทราบว่ารันไทม์คือรันไทม์เฉลี่ยที่มีการรันหลายครั้งในการทดสอบของเรา
เราเห็นการปรับปรุงประสิทธิภาพที่ดีหลังจากการแบ่งพาร์ติชัน อย่างไรก็ตาม สามารถปรับปรุงเพิ่มเติมได้โดยใช้สถิติระดับคอลัมน์จากไฟล์รายการ Iceberg เพื่อใช้สถิติระดับคอลัมน์อย่างมีประสิทธิภาพ คุณต้องการจัดเรียงบันทึกเพิ่มเติมตามรูปแบบการสืบค้น การเรียงลำดับชุดข้อมูลทั้งหมดโดยใช้คอลัมน์ที่มักใช้ในการสืบค้นจะจัดลำดับข้อมูลใหม่ในลักษณะที่แต่ละไฟล์ข้อมูลจบลงด้วยช่วงค่าเฉพาะสำหรับคอลัมน์เฉพาะ หากใช้คอลัมน์เหล่านี้ในเงื่อนไขการสืบค้น จะช่วยให้เอ็นจินการสืบค้นสามารถข้ามไฟล์ข้อมูลได้มากขึ้น ซึ่งจะทำให้การสืบค้นรวดเร็วยิ่งขึ้น
Copy-on-write เทียบกับ Read-on-Merge
เมื่อใช้การอัปเดตและลบบนตาราง Iceberg ใน Data Lake มีสองวิธีที่กำหนดโดยคุณสมบัติของตาราง Iceberg:
- คัดลอกบนเขียน – ด้วยแนวทางนี้ เมื่อมีการเปลี่ยนแปลงในตาราง Iceberg ไม่ว่าจะอัปเดตหรือลบ ไฟล์ข้อมูลที่เกี่ยวข้องกับบันทึกที่ได้รับผลกระทบจะถูกทำซ้ำและอัปเดต บันทึกจะถูกปรับปรุงหรือลบออกจากไฟล์ข้อมูลที่ทำซ้ำ สแน็ปช็อตใหม่ของตารางภูเขาน้ำแข็งจะถูกสร้างขึ้นและชี้ไปยังไฟล์ข้อมูลเวอร์ชันที่ใหม่กว่า ทำให้การเขียนโดยรวมช้าลง อาจมีบางสถานการณ์ที่จำเป็นต้องเขียนพร้อมกันโดยมีข้อขัดแย้ง จึงต้องลองใหม่อีกครั้ง ซึ่งจะเพิ่มเวลาในการเขียนมากยิ่งขึ้น ในทางกลับกัน เมื่ออ่านข้อมูล ไม่จำเป็นต้องมีกระบวนการเพิ่มเติม แบบสอบถามจะดึงข้อมูลจากไฟล์ข้อมูลเวอร์ชันล่าสุด
- ผสานเมื่ออ่าน – ด้วยวิธีนี้ เมื่อมีการอัปเดตหรือลบในตาราง Iceberg ไฟล์ข้อมูลที่มีอยู่จะไม่ถูกเขียนใหม่ ไฟล์ลบใหม่จะถูกสร้างขึ้นแทนเพื่อติดตามการเปลี่ยนแปลง สำหรับการลบ ไฟล์ลบใหม่จะถูกสร้างขึ้นพร้อมกับบันทึกที่ถูกลบ เมื่ออ่านตารางภูเขาน้ำแข็ง ไฟล์ลบจะถูกนำไปใช้กับข้อมูลที่เรียกมาเพื่อกรองบันทึกการลบออก สำหรับการอัปเดต ไฟล์ลบใหม่จะถูกสร้างขึ้นเพื่อทำเครื่องหมายบันทึกที่อัปเดตว่าลบแล้ว จากนั้นไฟล์ใหม่จะถูกสร้างขึ้นสำหรับเรกคอร์ดเหล่านั้น แต่มีค่าที่อัปเดต เมื่ออ่านตาราง Iceberg ทั้งไฟล์ที่ลบและไฟล์ใหม่จะถูกนำไปใช้กับข้อมูลที่ดึงมาเพื่อแสดงการเปลี่ยนแปลงล่าสุดและให้ผลลัพธ์ที่ถูกต้อง ดังนั้น สำหรับการสืบค้นที่ตามมา ขั้นตอนพิเศษในการรวมไฟล์ข้อมูลกับการลบและไฟล์ใหม่จะเกิดขึ้น ซึ่งโดยปกติจะเพิ่มเวลาการสืบค้น ในทางกลับกัน การเขียนอาจเร็วกว่าเนื่องจากไม่จำเป็นต้องเขียนไฟล์ข้อมูลที่มีอยู่ใหม่
เมื่อต้องการทดสอบผลกระทบของทั้งสองวิธี คุณสามารถรันโค้ดต่อไปนี้เพื่อตั้งค่าคุณสมบัติของตาราง Iceberg:
เรียกใช้การอัปเดต ลบ และเลือกคำสั่ง SQL ใน Athena เพื่อแสดงความแตกต่างของรันไทม์สำหรับ copy-on-write เทียบกับการผสานเมื่ออ่าน:
ตารางต่อไปนี้สรุปรันไทม์ของคิวรี
| สอบถาม | คัดลอกเมื่อเขียน | ผสานเมื่ออ่าน | ||||
| อัพเดท | ลบ | SELECT | อัพเดท | ลบ | SELECT | |
| รันไทม์ (วินาที) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| ข้อมูลที่สแกน (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
โปรดทราบว่ารันไทม์คือรันไทม์เฉลี่ยที่มีการรันหลายครั้งในการทดสอบของเรา
ดังที่ผลการทดสอบของเราแสดงให้เห็น มีการแลกเปลี่ยนเสมอในสองวิธี วิธีการใช้ขึ้นอยู่กับกรณีการใช้งานของคุณ โดยสรุป การพิจารณาลงมาที่เวลาแฝงในการอ่านและเขียน คุณสามารถอ้างอิงตารางต่อไปนี้และเลือกสิ่งที่ถูกต้องได้
| . | คัดลอกเมื่อเขียน | ผสานเมื่ออ่าน |
| ข้อดี | อ่านได้เร็วขึ้น | เขียนได้เร็วขึ้น |
| จุดด้อย | เขียนราคาแพง | เวลาแฝงที่สูงขึ้นในการอ่าน |
| ควรใช้เมื่อไร | เหมาะสำหรับการอ่านบ่อยๆ การอัปเดตและการลบไม่บ่อย หรือการอัปเดตแบบกลุ่มใหญ่ | เหมาะสำหรับตารางที่มีการอัปเดตและลบบ่อย |
การบีบอัดข้อมูล
หากไฟล์ข้อมูลของคุณมีขนาดเล็ก คุณอาจมีไฟล์เป็นพันหรือล้านไฟล์ในตาราง Iceberg สิ่งนี้จะเพิ่มการดำเนินการ I/O อย่างมากและทำให้การสืบค้นช้าลง นอกจากนี้ Iceberg ยังติดตามไฟล์ข้อมูลแต่ละไฟล์ในชุดข้อมูล ไฟล์ข้อมูลเพิ่มเติมนำไปสู่ข้อมูลเมตาที่มากขึ้น สิ่งนี้จะเพิ่มค่าใช้จ่ายและการดำเนินการ I/O ในการอ่านไฟล์ข้อมูลเมตา เพื่อปรับปรุงประสิทธิภาพคิวรี ขอแนะนำให้กระชับไฟล์ข้อมูลขนาดเล็กให้เป็นไฟล์ข้อมูลขนาดใหญ่
เมื่ออัปเดตและลบบันทึกในตาราง Iceberg หากใช้วิธีอ่าน-ผสาน คุณอาจจบลงด้วยการลบขนาดเล็กจำนวนมากหรือไฟล์ข้อมูลใหม่ การรันการบีบอัดจะรวมไฟล์ทั้งหมดเหล่านี้และสร้างไฟล์ข้อมูลเวอร์ชันใหม่กว่า สิ่งนี้ทำให้ไม่จำเป็นต้องกระทบยอดระหว่างการอ่าน ขอแนะนำให้มีงานบีบอัดเป็นประจำเพื่อให้ส่งผลกระทบต่อการอ่านน้อยที่สุดในขณะที่ยังคงรักษาความเร็วในการเขียนให้เร็วขึ้น
เรียกใช้คำสั่งบีบอัดข้อมูลต่อไปนี้ จากนั้นเรียกใช้คิวรีแบบเลือกจาก Athena:
ตารางต่อไปนี้เปรียบเทียบรันไทม์ก่อนและหลังการบีบอัดข้อมูล คุณสามารถเห็นการปรับปรุงประสิทธิภาพประมาณ 40%
| สอบถาม | ก่อนการกระชับข้อมูล | หลังจากการกระชับข้อมูล |
| รันไทม์ (วินาที) | 97.75 | วินาที 32.676 |
| ข้อมูลที่สแกน (MB) | M 137.16 | M 189.19 |
โปรดทราบว่าแบบสอบถามแบบใช้เลือกทำงานบน all_reviews ตารางหลังการดำเนินการอัปเดตและลบ ก่อนและหลังการบีบอัดข้อมูล รันไทม์คือรันไทม์เฉลี่ยที่มีการรันหลายครั้งในการทดสอบของเรา
ทำความสะอาด
หลังจากที่คุณทำตามคำแนะนำการแก้ปัญหาเพื่อดำเนินการตามกรณีการใช้งาน ให้ทำตามขั้นตอนต่อไปนี้เพื่อล้างทรัพยากรของคุณและหลีกเลี่ยงค่าใช้จ่ายเพิ่มเติม:
- วางตารางและฐานข้อมูล AWS Glue จาก Athena หรือเรียกใช้โค้ดต่อไปนี้ในสมุดบันทึกของคุณ:
- บนคอนโซล EMR Studio เลือก พื้นที่ทำงาน ในบานหน้าต่างนำทาง
- เลือกพื้นที่ทำงานที่คุณสร้างขึ้นและเลือก ลบ.
- บนคอนโซล EMR ให้ไปที่ สตูดิโอ หน้า.
- เลือกสตูดิโอที่คุณสร้างแล้วเลือก ลบ.
- บนคอนโซล EMR เลือก เครือข่ายวิสาหกิจ ในบานหน้าต่างนำทาง
- เลือกคลัสเตอร์และเลือก ยุติ.
- ลบบัคเก็ต S3 และทรัพยากรอื่นๆ ที่คุณสร้างขึ้นโดยเป็นส่วนหนึ่งของข้อกำหนดเบื้องต้นสำหรับโพสต์นี้
สรุป
ในโพสต์นี้ เราแนะนำเฟรมเวิร์ก Apache Iceberg และวิธีที่ช่วยแก้ไขความท้าทายบางอย่างที่เรามีใน Data Lake สมัยใหม่ จากนั้นเราจะแนะนำวิธีแก้ปัญหาในการประมวลผลข้อมูลส่วนเพิ่มใน Data Lake โดยใช้ Apache Iceberg สุดท้าย เราได้เจาะลึกเกี่ยวกับการปรับแต่งประสิทธิภาพเพื่อปรับปรุงประสิทธิภาพการอ่านและเขียนสำหรับกรณีการใช้งานของเรา
เราหวังว่าโพสต์นี้จะให้ข้อมูลที่เป็นประโยชน์สำหรับคุณในการตัดสินใจว่าคุณต้องการนำ Apache Iceberg มาใช้ในโซลูชัน Data Lake ของคุณหรือไม่
เกี่ยวกับผู้เขียน
 ฟลอร่า วู เป็น Sr. Resident Architect ที่ AWS Data Lab เธอช่วยลูกค้าองค์กรสร้างกลยุทธ์การวิเคราะห์ข้อมูลและสร้างโซลูชันเพื่อเร่งผลลัพธ์ทางธุรกิจของพวกเขา ในเวลาว่าง เธอชอบเล่นเทนนิส เต้นซัลซ่า และท่องเที่ยว
ฟลอร่า วู เป็น Sr. Resident Architect ที่ AWS Data Lab เธอช่วยลูกค้าองค์กรสร้างกลยุทธ์การวิเคราะห์ข้อมูลและสร้างโซลูชันเพื่อเร่งผลลัพธ์ทางธุรกิจของพวกเขา ในเวลาว่าง เธอชอบเล่นเทนนิส เต้นซัลซ่า และท่องเที่ยว
 แดเนียลลี่ เป็น Sr. Solutions Architect ที่ Amazon Web Services เขามุ่งเน้นที่การช่วยเหลือลูกค้าในการพัฒนา ปรับใช้ และปรับใช้บริการและกลยุทธ์ระบบคลาวด์ เมื่อไม่ได้ทำงาน เขาชอบใช้เวลานอกบ้านกับครอบครัว
แดเนียลลี่ เป็น Sr. Solutions Architect ที่ Amazon Web Services เขามุ่งเน้นที่การช่วยเหลือลูกค้าในการพัฒนา ปรับใช้ และปรับใช้บริการและกลยุทธ์ระบบคลาวด์ เมื่อไม่ได้ทำงาน เขาชอบใช้เวลานอกบ้านกับครอบครัว
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- สามารถ
- เกี่ยวกับเรา
- ข้างบน
- เร่งความเร็ว
- เข้า
- การจัดการการเข้าถึง
- การกระทำ
- การกระทำ
- นอกจากนี้
- เพิ่มเติม
- ที่อยู่
- ที่อยู่
- เพิ่ม
- นำมาใช้
- ความได้เปรียบ
- หลังจาก
- กับ
- ทั้งหมด
- ช่วยให้
- เสมอ
- อเมซอน
- อเมซอน EMR
- Amazon Web Services
- วิเคราะห์
- การวิเคราะห์
- และ
- ประกาศ
- อาปาเช่
- การใช้งาน
- ประยุกต์
- เข้าใกล้
- วิธีการ
- เหมาะสม
- สถาปัตยกรรม
- ที่เกี่ยวข้อง
- การยืนยันตัวตน
- ความพร้อมใช้งาน
- ใช้ได้
- เฉลี่ย
- หลีกเลี่ยง
- AWS
- AWS กาว
- ตาม
- เพราะ
- กลายเป็น
- ก่อน
- ประโยชน์
- ดีกว่า
- ระหว่าง
- ที่ใหญ่กว่า
- บูต
- สร้าง
- การก่อสร้าง
- ธุรกิจ
- จับ
- จับ
- กรณี
- กรณี
- แค็ตตาล็อก
- แคตตาล็อก
- หมวดหมู่
- ความท้าทาย
- เปลี่ยนแปลง
- การเปลี่ยนแปลง
- ตรวจสอบ
- ทางเลือก
- Choose
- การจัดหมวดหมู่
- เมฆ
- บริการคลาวด์
- Cluster
- รหัส
- คอลัมน์
- คอลัมน์
- รวมกัน
- อย่างไร
- ผูกมัด
- เมื่อเทียบกับ
- สมบูรณ์
- คำนวณ
- พร้อมกัน
- สภาพ
- การกำหนดค่า
- การพิจารณา
- ปลอบใจ
- การแปลง
- แปลง
- ค่าใช้จ่ายที่มีประสิทธิภาพ
- ค่าใช้จ่าย
- ได้
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- curated
- ปัจจุบัน
- ลูกค้า
- ลูกค้า
- การเต้นรำ
- หน้าปัด
- ข้อมูล
- วิเคราะห์ข้อมูล
- ดาต้าเลค
- การประมวลผล
- คลังข้อมูล
- ฐานข้อมูล
- ชุดข้อมูล
- ลึก
- ดำน้ำลึก
- ค่าเริ่มต้น
- กำหนด
- ทดลอง
- สาธิต
- ขึ้นอยู่กับ
- ได้รับการออกแบบ
- รายละเอียด
- พัฒนา
- พัฒนาการ
- ความแตกต่าง
- ต่าง
- สนทนา
- Dont
- ลง
- เป็นคุ้งเป็นแคว
- หล่น
- ในระหว่าง
- แต่ละ
- ก่อน
- ก่อน
- บรรณาธิการ
- มีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- ทั้ง
- ขจัด
- เปิดการใช้งาน
- การเปิดใช้งาน
- สิ้นสุด
- เครื่องยนต์
- เครื่องยนต์
- เข้าสู่
- Enterprise
- ลูกค้าองค์กร
- อีเธอร์ (ETH)
- แม้
- วิวัฒนาการ
- คาย
- การพัฒนา
- ตัวอย่าง
- ที่มีอยู่
- ที่มีอยู่
- อธิบาย
- ส่วนขยาย
- พิเศษ
- อำนวยความสะดวก
- ครอบครัว
- FAST
- เร็วขึ้น
- คุณสมบัติ
- รูป
- เนื้อไม่มีมัน
- ไฟล์
- กรอง
- กรอง
- ฟิลเตอร์
- ในที่สุด
- หา
- ชื่อจริง
- ครั้งแรก
- มุ่งเน้นไปที่
- ปฏิบัติตาม
- ดังต่อไปนี้
- รูป
- กรอบ
- บ่อย
- ราคาเริ่มต้นที่
- ต่อไป
- นอกจากนี้
- General
- สร้าง
- ได้รับ
- กำหนด
- ไป
- ดี
- อย่างมาก
- บัญชีกลุ่ม
- มือ
- เกิดขึ้น
- ช่วย
- การช่วยเหลือ
- จะช่วยให้
- ซ่อนเร้น
- ลำดับชั้น
- ระดับสูง
- ประสิทธิภาพสูง
- ที่มีประสิทธิภาพสูง
- รัง
- ความหวัง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- HTTPS
- AMI
- เอกลักษณ์
- การระบุตัวตนและการจัดการการเข้าถึง
- ส่งผลกระทบ
- ที่กระทบ
- การดำเนินการ
- การดำเนินงาน
- การดำเนินการ
- ปรับปรุง
- การปรับปรุง
- การปรับปรุง
- ช่วยเพิ่ม
- in
- รวมทั้ง
- เพิ่ม
- เพิ่มขึ้น
- เพิ่มขึ้น
- ดัชนี
- เป็นรายบุคคล
- ข้อมูล
- ติดตั้ง
- แทน
- บูรณาการ
- แนะนำ
- ไอโซเลท
- IT
- มกราคม
- งาน
- คีย์
- ห้องปฏิบัติการ
- ทะเลสาบ
- ใหญ่
- ที่มีขนาดใหญ่
- ความแอบแฝง
- ล่าสุด
- รุ่นล่าสุด
- ชั้น
- ชั้น
- นำ
- ระดับ
- LIMIT
- Line
- รายการ
- น้อย
- โหลด
- ที่ตั้ง
- ทำ
- ทำให้
- การจัดการ
- หลาย
- เครื่องหมาย
- ตลาด
- การจับคู่
- การจับคู่
- ผสาน
- เมตาดาต้า
- อาจ
- ล้าน
- ทันสมัย
- ข้อมูลเพิ่มเติม
- ย้าย
- หลาย
- ชื่อ
- ที่มีชื่อ
- นำทาง
- การเดินเรือ
- จำเป็นต้อง
- จำเป็น
- ความต้องการ
- ใหม่
- สมุดบันทึก
- วัตถุ
- เปิด
- การดำเนินการ
- การดำเนินการ
- การเพิ่มประสิทธิภาพ
- เพิ่มประสิทธิภาพ
- ใบสั่ง
- เป็นต้นฉบับ
- อื่นๆ
- กลางแจ้ง
- ทั้งหมด
- ของตนเอง
- บานหน้าต่าง
- ส่วนหนึ่ง
- เส้นทาง
- รูปแบบ
- ดำเนินการ
- การปฏิบัติ
- กายภาพ
- การวางแผน
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- เสียบเข้าไป
- จุด
- ยอดนิยม
- เป็นไปได้
- โพสต์
- ขับเคลื่อน
- ข้อกำหนดเบื้องต้น
- ขั้นตอน
- กระบวนการ
- การประมวลผล
- ก่อ
- คุณสมบัติ
- คุณสมบัติ
- ให้
- ให้
- การให้
- บทบัญญัติ
- พิสัย
- ดิบ
- ข้อมูลดิบ
- อ่าน
- การอ่าน
- จริง
- เมื่อเร็ว ๆ นี้
- แนะนำ
- บันทึก
- สะท้อน
- ภูมิภาค
- ลงทะเบียน
- ปกติ
- ปล่อย
- การเผยแพร่
- ที่เหลืออยู่
- จำเป็นต้องใช้
- ต้อง
- แหล่งข้อมูล
- ผล
- ผลสอบ
- รีวิว
- รวย
- บทบาท
- ราก
- วิ่ง
- วิ่ง
- เดียวกัน
- การสแกน
- วินาที
- Section
- ความปลอดภัย
- เลือก
- การเลือก
- serverless
- บริการ
- บริการ
- เซสชั่น
- ชุด
- ชุดอุปกรณ์
- การตั้งค่า
- การตั้งค่า
- น่า
- โชว์
- แสดงให้เห็นว่า
- ง่าย
- สถานการณ์
- ขนาด
- ช้า
- เล็ก
- ภาพย่อ
- So
- ซอฟต์แวร์
- ทางออก
- โซลูชัน
- บาง
- จุดประกาย
- โดยเฉพาะ
- ความเร็ว
- การใช้จ่าย
- SQL
- ที่เริ่มต้น
- สถานะ
- คำแถลง
- งบ
- สถิติ
- ขั้นตอน
- ขั้นตอน
- ยังคง
- การเก็บรักษา
- จัดเก็บ
- เก็บไว้
- ร้านค้า
- กลยุทธ์
- กลยุทธ์
- โครงสร้าง
- ข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง
- สตูดิโอ
- เครือข่ายย่อย
- ภายหลัง
- ประสบความสำเร็จ
- อย่างเช่น
- เพียงพอ
- สรุป
- สนับสนุน
- ที่สนับสนุน
- ที่สนับสนุน
- รองรับ
- ตาราง
- ใช้เวลา
- การ
- เป้า
- งาน
- เทคนิค
- เทนนิส
- ทดสอบ
- การทดสอบ
- การทดสอบ
- พื้นที่
- ข้อมูล
- รัฐ
- ของพวกเขา
- ดังนั้น
- พัน
- สาม
- ตลอด
- เวลา
- การเดินทางข้ามเวลา
- ไปยัง
- ร่วมกัน
- เกินไป
- เครื่องมือ
- ด้านบน
- รวม
- ลู่
- การทำธุรกรรม
- การเปลี่ยนแปลง
- การเดินทาง
- การเดินทาง
- กลับ
- ชนิด
- ภายใต้
- เป็นเอกลักษณ์
- บันทึก
- ให้กับคุณ
- การปรับปรุง
- การปรับปรุง
- URL
- ใช้
- ใช้กรณี
- ผู้ใช้
- มักจะ
- VAL
- ความคุ้มค่า
- ความคุ้มค่า
- ตรวจสอบ
- รุ่น
- เดิน
- คำแนะนำ
- คลังสินค้า
- นาฬิกา
- วิธี
- เว็บ
- บริการเว็บ
- อะไร
- ว่า
- ที่
- ในขณะที่
- กว้าง
- ช่วงกว้าง
- จะ
- ไม่มี
- งาน
- การทำงาน
- โรงงาน
- จะ
- เขียน
- การเขียน
- ของคุณ
- ลมทะเล