Data Lake ได้รับความนิยมในการจัดเก็บข้อมูลจำนวนมหาศาลจากแหล่งที่มาที่หลากหลายด้วยวิธีที่ปรับขนาดได้และคุ้มต้นทุน เมื่อจำนวนผู้ใช้ข้อมูลเพิ่มมากขึ้น ผู้ดูแลระบบ Data Lake มักจะต้องใช้การควบคุมการเข้าถึงแบบละเอียดสำหรับโปรไฟล์ผู้ใช้ที่แตกต่างกัน พวกเขาอาจจำเป็นต้องจำกัดการเข้าถึงบางตารางหรือคอลัมน์ ขึ้นอยู่กับประเภทของผู้ใช้ที่ส่งคำขอ นอกจากนี้ ธุรกิจบางครั้งต้องการให้แอปพลิเคชันภายนอกเข้าถึงข้อมูลได้ แต่ไม่แน่ใจว่าจะทำอย่างไรอย่างปลอดภัย เพื่อจัดการกับความท้าทายเหล่านี้ องค์กรต่างๆ สามารถหันมาใช้ GraphQL และ การก่อตัวของทะเลสาบ AWS.
GraphQL มอบวิธีที่มีประสิทธิภาพ ปลอดภัย และยืดหยุ่นในการสืบค้นและเรียกค้นข้อมูล AWS AppSync เป็นบริการสำหรับสร้าง GraphQL API ที่สามารถสืบค้นฐานข้อมูล ไมโครเซอร์วิส และ API หลายรายการจากตำแหน่งข้อมูล GraphQL ที่รวมเป็นหนึ่งเดียว
ผู้ดูแลระบบ Data Lake สามารถใช้ Lake Formation เพื่อควบคุมการเข้าถึง Data Lake Lake Formation นำเสนอการควบคุมการเข้าถึงแบบละเอียดสำหรับการจัดการสิทธิ์ของผู้ใช้และกลุ่มที่ระดับตาราง คอลัมน์ และเซลล์ จึงสามารถรับประกันความปลอดภัยของข้อมูลและการปฏิบัติตามข้อกำหนดได้ นอกจากนี้ Lake Formation นี้ยังทำงานร่วมกับบริการอื่นๆ ของ AWS เช่น อเมซอน อาเธน่าทำให้เหมาะอย่างยิ่งสำหรับการสืบค้น Data Lake ผ่าน API
ในโพสต์นี้ เราจะสาธิตวิธีสร้างแอปพลิเคชันที่สามารถดึงข้อมูลจาก Data Lake ผ่าน GraphQL API และส่งมอบผลลัพธ์ให้กับผู้ใช้ประเภทต่างๆ ตามสิทธิ์การเข้าถึงข้อมูลเฉพาะของพวกเขา แอปพลิเคชันตัวอย่างที่อธิบายในโพสต์นี้สร้างโดย AWS Partner เทคโนโลยี เน็ตโซล.
ภาพรวมโซลูชัน
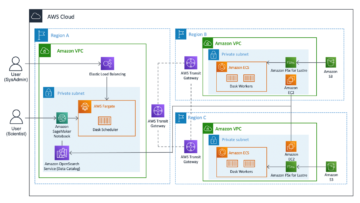
โซลูชันของเราใช้ บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) เพื่อจัดเก็บข้อมูล AWS กาว Data Catalog เพื่อจัดเก็บสคีมาของข้อมูล และ Lake Formation เพื่อให้การกำกับดูแลออบเจ็กต์ AWS Glue Data Catalog โดยการใช้การเข้าถึงตามบทบาท เรายังใช้ อเมซอน EventBridge เพื่อบันทึกเหตุการณ์ใน Data Lake ของเราและเปิดตัวกระบวนการดาวน์สตรีม สถาปัตยกรรมโซลูชันจะแสดงอยู่ในแผนภาพต่อไปนี้
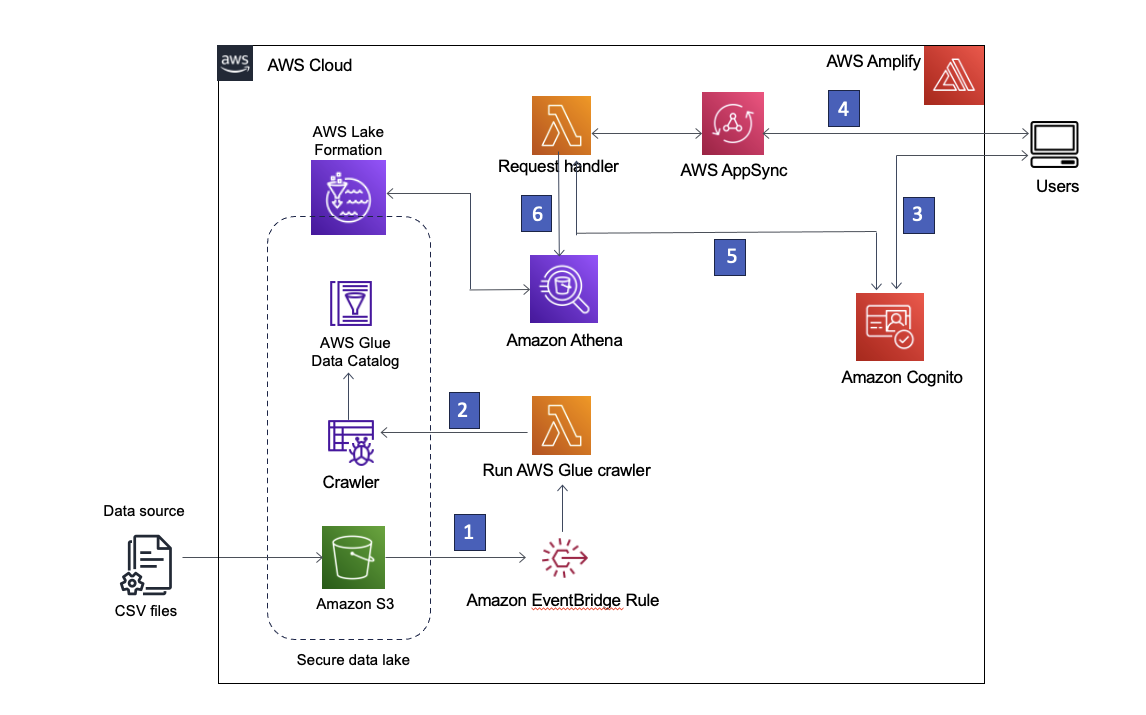
รูปที่ 1 – สถาปัตยกรรมโซลูชัน
ต่อไปนี้เป็นคำอธิบายทีละขั้นตอนของโซลูชัน:
- Data Lake ถูกสร้างขึ้นในบัคเก็ต S3 ที่ลงทะเบียนกับ Lake Formation เมื่อใดก็ตามที่มีข้อมูลใหม่เข้ามา กฎ EventBridge จะถูกเรียกใช้
- กฎ EventBridge รันไฟล์ AWS แลมบ์ดา ฟังก์ชันเพื่อเริ่มโปรแกรมรวบรวมข้อมูล AWS Glue เพื่อค้นหาข้อมูลใหม่และอัปเดตการเปลี่ยนแปลงสคีมาเพื่อให้สามารถสืบค้นข้อมูลล่าสุดได้
หมายเหตุ: โปรแกรมรวบรวมข้อมูล AWS Glue สามารถเปิดใช้งานได้โดยตรงจากเหตุการณ์ Amazon S3 ตามที่อธิบายไว้ในนี้ โพสต์บล็อก. - AWS ขยาย อนุญาตให้ผู้ใช้ลงชื่อเข้าใช้งาน Amazon Cognito Co ในฐานะผู้ให้บริการข้อมูลประจำตัว Cognito ตรวจสอบข้อมูลประจำตัวของผู้ใช้และส่งคืนโทเค็นการเข้าถึง
- ผู้ใช้ที่ได้รับการตรวจสอบสิทธิ์จะเรียกใช้ AWS AppSync GraphQL API ผ่าน Amplify โดยดึงข้อมูลจาก Data Lake ฟังก์ชัน Lambda ทำงานเพื่อจัดการกับคำขอ
- ฟังก์ชัน Lambda ดึงรายละเอียดผู้ใช้จาก Cognito และถือว่า AWS Identity และการจัดการการเข้าถึง (IAM) บทบาทที่เกี่ยวข้องกับกลุ่มผู้ใช้ Cognito ของผู้ใช้ที่ร้องขอ
- จากนั้นฟังก์ชัน Lambda จะเรียกใช้การสืบค้น Athena กับตาราง Data Lake และส่งคืนผลลัพธ์ไปยัง AWS AppSync ซึ่งจะส่งคืนผลลัพธ์ให้กับผู้ใช้
เบื้องต้น
หากต้องการปรับใช้โซลูชันนี้ คุณต้องดำเนินการดังต่อไปนี้ก่อน:
เตรียมการอนุญาตการสร้างทะเลสาบ
เข้าสู่ระบบเพื่อ คอนโซล LakeFormation และเพิ่มตัวเองเป็นผู้ดูแลระบบ หากคุณลงชื่อเข้าใช้ Lake Formation เป็นครั้งแรก คุณสามารถทำได้โดยเลือกเพิ่มตัวเองบนหน้าจอ ยินดีต้อนรับสู่ Lake Formation และเลือกเริ่มต้นใช้งานดังแสดงในรูปที่ 2

รูปที่ 2 – เพิ่มตัวคุณเองเป็นผู้ดูแล Lake Formation
หรือคุณสามารถเลือกบทบาทผู้ดูแลระบบและงานในแถบนำทางด้านซ้าย และเลือกจัดการผู้ดูแลระบบเพื่อเพิ่มตัวคุณเอง คุณควรเห็นชื่อผู้ใช้ IAM ของคุณภายใต้ผู้ดูแลระบบ Data Lake ที่มีสิทธิ์การเข้าถึงแบบเต็มเมื่อดำเนินการเสร็จสิ้น
เลือกการตั้งค่าแค็ตตาล็อกข้อมูลในแถบนำทางด้านซ้าย และตรวจสอบให้แน่ใจว่าไม่ได้เลือกกล่องควบคุมการเข้าถึง IAM สองกล่อง ดังแสดงในรูปที่ 3 คุณต้องการให้ Lake Formation ไม่ใช่ IAM เพื่อควบคุมการเข้าถึงฐานข้อมูลใหม่
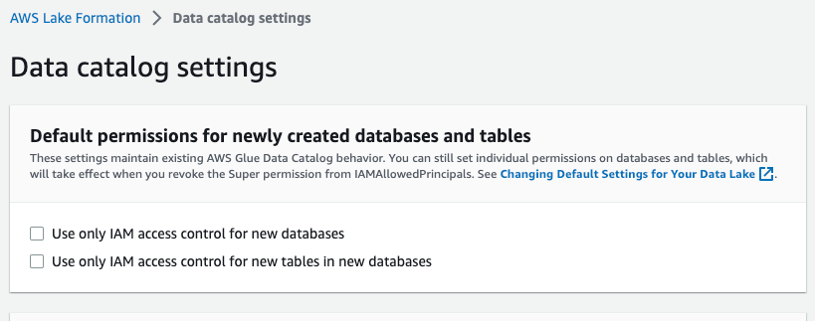
รูปที่ 3 – การตั้งค่าแค็ตตาล็อกข้อมูลการก่อตัวของทะเลสาบ
ปรับใช้โซลูชัน
หากต้องการสร้างโซลูชันในสภาพแวดล้อม AWS ของคุณ ให้เปิดใช้สแต็ก AWS CloudFormation ต่อไปนี้: ![]()
ทรัพยากรต่อไปนี้จะเปิดตัวผ่านเทมเพลต CloudFormation:
- Amazon VPC และส่วนประกอบเครือข่าย (ซับเน็ต กลุ่มความปลอดภัย และเกตเวย์ NAT)
- บทบาท IAM
- Lake Formation ที่ห่อหุ้มบัคเก็ต S3, โปรแกรมรวบรวมข้อมูล AWS Glue และฐานข้อมูล AWS Glue
- ฟังก์ชั่นแลมบ์ดา
- กลุ่มผู้ใช้ Cognito
- AWS AppSync GraphQL API
- กฎ EventBridge
หลังจากปรับใช้ทรัพยากรที่ต้องการจากสแต็ก CloudFormation แล้ว คุณต้องสร้างฟังก์ชัน Lambda สองฟังก์ชันและอัปโหลดชุดข้อมูลไปยัง Amazon S3 Lake Formation จะควบคุม Data Lake ที่ถูกจัดเก็บไว้ในบัคเก็ต S3
สร้างฟังก์ชันแลมบ์ดา
เมื่อใดก็ตามที่มีการวางไฟล์ใหม่ลงในบัคเก็ต S3 ที่กำหนด กฎ EventBridge จะถูกเรียกใช้ ซึ่งเปิดใช้ฟังก์ชัน Lambda เพื่อเริ่มต้นโปรแกรมรวบรวมข้อมูล AWS Glue โปรแกรมรวบรวมข้อมูลจะอัปเดต AWS Glue Data Catalog เพื่อให้สอดคล้องกับการเปลี่ยนแปลงใดๆ ในสคีมา
เมื่อแอปพลิเคชันทำการสืบค้นข้อมูลผ่าน GraphQL API ฟังก์ชันตัวจัดการคำขอ Lambda จะถูกเรียกใช้เพื่อประมวลผลการสืบค้นและส่งกลับผลลัพธ์
หากต้องการสร้างฟังก์ชัน Lambda ทั้งสองนี้ ให้ดำเนินการดังนี้
- ลงชื่อเข้าใช้คอนโซล Lambda
- เลือกฟังก์ชัน Lambda ของตัวจัดการคำขอที่มีชื่อ
dl-dev-crawlerLambdaFunction. - ค้นหาไฟล์ฟังก์ชัน Lambda ของโปรแกรมรวบรวมข้อมูลในไฟล์
lambdas/crawler-lambdaโฟลเดอร์ใน repo git ที่คุณโคลนไปยังเครื่องของคุณ - คัดลอกและวางโค้ดในไฟล์นั้นไปยังส่วนโค้ดของ
dl-dev-crawlerLambdaFunctionในคอนโซล Lambda ของคุณ จากนั้นเลือก Deploy เพื่อปรับใช้ฟังก์ชัน
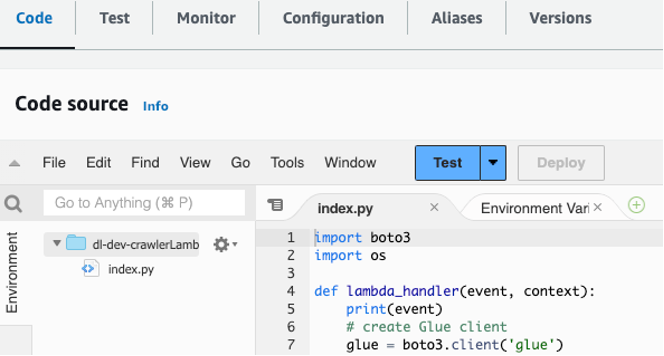
รูปที่ 4 – คัดลอกและวางโค้ดลงในฟังก์ชัน Lambda
- ทำซ้ำขั้นตอนที่ 2 ถึง 4 สำหรับฟังก์ชันตัวจัดการคำขอที่มีชื่อ
dl-dev-requestHandlerLambdaFunctionโดยใช้โค้ดในlambdas/request-handler-lambda.
สร้างเลเยอร์สำหรับตัวจัดการคำขอ Lambda
ตอนนี้คุณต้องอัปโหลดโค้ดไลบรารีเพิ่มเติมที่จำเป็นสำหรับฟังก์ชัน Lambda ของตัวจัดการคำขอ
- เลือก เลเยอร์ ในเมนูด้านซ้ายแล้วเลือก สร้างเลเยอร์.
- ใส่ชื่อเช่น
appsync-lambda-layer. - ดาวน์โหลดนี้ ไฟล์ ZIP ของเลเยอร์แพ็คเกจ ไปยังเครื่องท้องถิ่นของคุณ
- อัปโหลดไฟล์ ZIP โดยใช้ไฟล์ อัพโหลด ปุ่มบน สร้างเลเยอร์ หน้า.
- Choose งูหลาม 3.7 เป็นรันไทม์สำหรับเลเยอร์
- Choose สร้างบัญชีตัวแทน.
- เลือก ฟังก์ชั่น บนเมนูด้านซ้ายและเลือก
dl-dev-requestHandlerฟังก์ชันแลมบ์ดา - เลื่อนลงไปที่ เลเยอร์ ส่วนและเลือก เพิ่มเลเยอร์.
- เลือก เลเยอร์ที่กำหนดเอง จากนั้นเลือกเลเยอร์ที่คุณสร้างไว้ด้านบน
- คลิก เพิ่ม.
อัปโหลดข้อมูลไปยัง Amazon S3
นำทางไปยังไดเร็กทอรีรากของที่เก็บ git ที่โคลนไว้ และรันคำสั่งต่อไปนี้เพื่ออัปโหลดชุดข้อมูลตัวอย่าง แทนที่ bucket_name ตัวยึดตำแหน่งที่มีบัคเก็ต S3 ที่จัดเตรียมโดยใช้เทมเพลต CloudFormation คุณสามารถรับชื่อบัคเก็ตได้จากคอนโซล CloudFormation โดยไปที่ Outputs แท็บพร้อมปุ่ม datalakes3bucketName ดังแสดงในภาพด้านล่าง
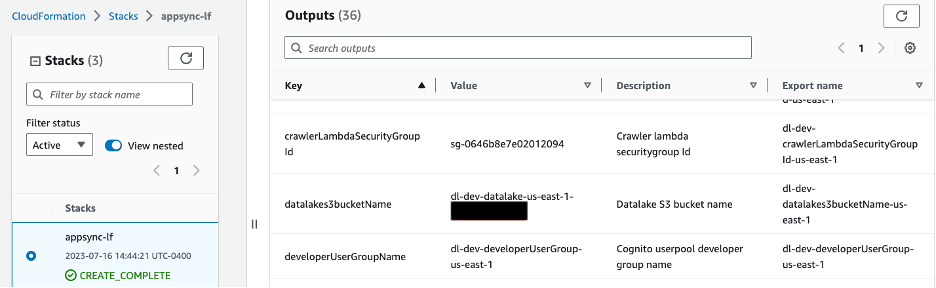
รูปที่ 5 – ชื่อบัคเก็ต S3 ที่แสดงในแท็บ CloudFormation Outputs
ป้อนคำสั่งต่อไปนี้ในโฟลเดอร์โปรเจ็กต์ของคุณในเครื่องภายในเพื่ออัปโหลดชุดข้อมูลไปยังบัคเก็ต S3
ตอนนี้เรามาดูสิ่งประดิษฐ์ที่ปรับใช้แล้ว
ทะเลสาบข้อมูล
บัคเก็ต S3 เก็บข้อมูลตัวอย่างสำหรับสองเอนทิตี: บริษัทและเจ้าของที่เกี่ยวข้อง บัคเก็ตได้รับการลงทะเบียนกับ Lake Formation ดังแสดงในรูปที่ 6 ซึ่งจะช่วยให้ Lake Formation สามารถสร้างและจัดการแค็ตตาล็อกข้อมูลและจัดการสิทธิ์ในข้อมูลได้

รูปที่ 6 – คอนโซล Lake Formation แสดงตำแหน่งของ Data Lake
ฐานข้อมูลถูกสร้างขึ้นเพื่อเก็บสคีมาของข้อมูลที่มีอยู่ใน Amazon S3 โปรแกรมรวบรวมข้อมูล AWS Glue ใช้เพื่ออัปเดตการเปลี่ยนแปลงใดๆ ในสคีมาในบัคเก็ต S3 โปรแกรมรวบรวมข้อมูลนี้ได้รับอนุญาตให้สร้างตาราง ALTER และ DROP ในฐานข้อมูลโดยใช้ Lake Formation
ใช้การควบคุมการเข้าถึง Data Lake
มีการสร้างบทบาท IAM สองบทบาท dl-us-east-1-developer และ dl-us-east-1-business-analystซึ่งแต่ละกลุ่มถูกกำหนดให้กับกลุ่มผู้ใช้ Cognito ที่แตกต่างกัน แต่ละบทบาทจะได้รับการมอบหมายการอนุญาตที่แตกต่างกันผ่าน Lake Formation บทบาทนักพัฒนาจะได้รับสิทธิ์เข้าถึงทุกคอลัมน์ใน Data Lake ในขณะที่บทบาทนักวิเคราะห์ธุรกิจจะได้รับสิทธิ์ในการเข้าถึงเฉพาะคอลัมน์ข้อมูลที่ไม่สามารถระบุตัวตนได้ (PII) เท่านั้น

รูปที่ 7 –สิทธิ์อนุญาต Data Lake ของคอนโซล Lake Formation ที่กำหนดให้กับบทบาทกลุ่ม
สคีมา GraphQL
GraphQL API สามารถดูได้จากคอนโซล AWS AppSync ที่ Companies type มีแอตทริบิวต์หลายรายการที่อธิบายเจ้าของบริษัท
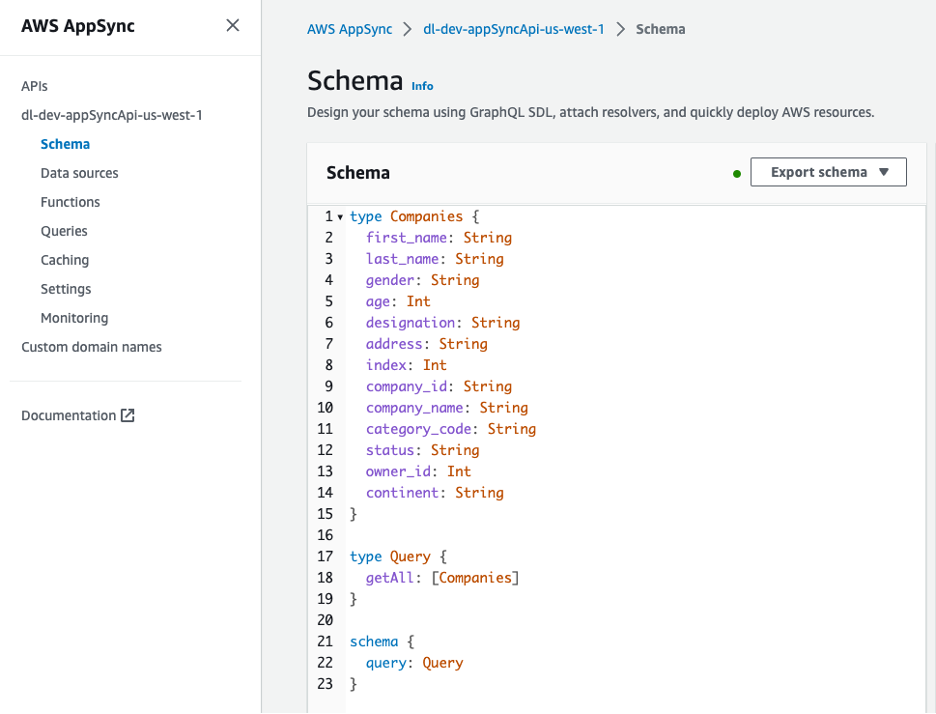
รูปที่ 8 – สคีมาสำหรับ GraphQL API
แหล่งข้อมูลสำหรับ GraphQL API คือฟังก์ชัน Lambda ซึ่งจัดการคำขอ
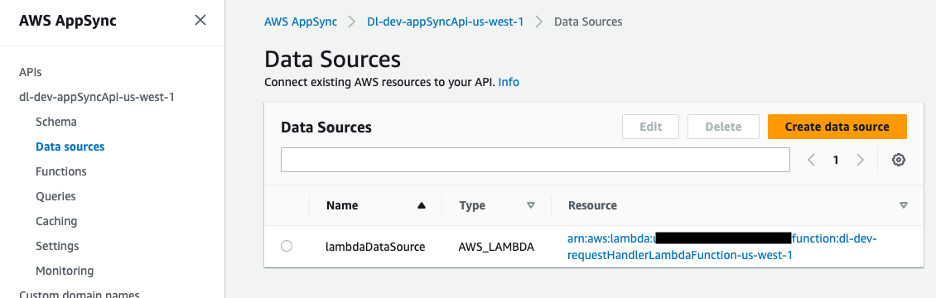
รูปที่ 9 – แหล่งข้อมูล AWS AppSync ที่แมปกับฟังก์ชัน Lambda
การจัดการคำขอ GraphQL API
ฟังก์ชัน Lambda ตัวจัดการคำขอ GraphQL API จะดึง ID พูลผู้ใช้ Cognito จากตัวแปรสภาพแวดล้อม การใช้ไลบรารี boto3 คุณสร้างไคลเอ็นต์ Cognito และใช้ get_group วิธีการรับบทบาท IAM ที่เกี่ยวข้องกับกลุ่มผู้ใช้ Cognito
คุณใช้ฟังก์ชันตัวช่วยในฟังก์ชัน Lambda เพื่อรับบทบาท
การใช้ บริการโทเค็นความปลอดภัย AWS (AWS STS) ผ่านไคลเอ็นต์ boto3 คุณสามารถรับบทบาท IAM และรับข้อมูลรับรองชั่วคราวที่จำเป็นในการเรียกใช้การสืบค้น Athena
เราส่งข้อมูลประจำตัวชั่วคราวเป็นพารามิเตอร์เมื่อสร้างไคลเอ็นต์ Boto3 Amazon Athena ของเรา
athena_client = boto3.client('athena', aws_access_key_id=access_key, aws_secret_access_key=secret_key, aws_session_token=session_token)ไคลเอนต์และการสืบค้นจะถูกส่งผ่านไปยังฟังก์ชันตัวช่วยการสืบค้น Athena ของเรา ซึ่งดำเนินการสืบค้นและส่งกลับรหัสการสืบค้น ด้วย ID แบบสอบถาม เราสามารถอ่านผลลัพธ์จาก S3 และรวมเป็นพจนานุกรม Python เพื่อส่งคืนในการตอบกลับ
การเปิดใช้งานการเข้าถึง Data Lake ฝั่งไคลเอ็นต์
ในฝั่งไคลเอ็นต์ AWS Amplify ได้รับการกำหนดค่าด้วยพูลผู้ใช้ Amazon Cognito สำหรับการตรวจสอบสิทธิ์ เราจะไปที่คอนโซล Amazon Cognito เพื่อดูกลุ่มผู้ใช้และกลุ่มที่สร้างขึ้น
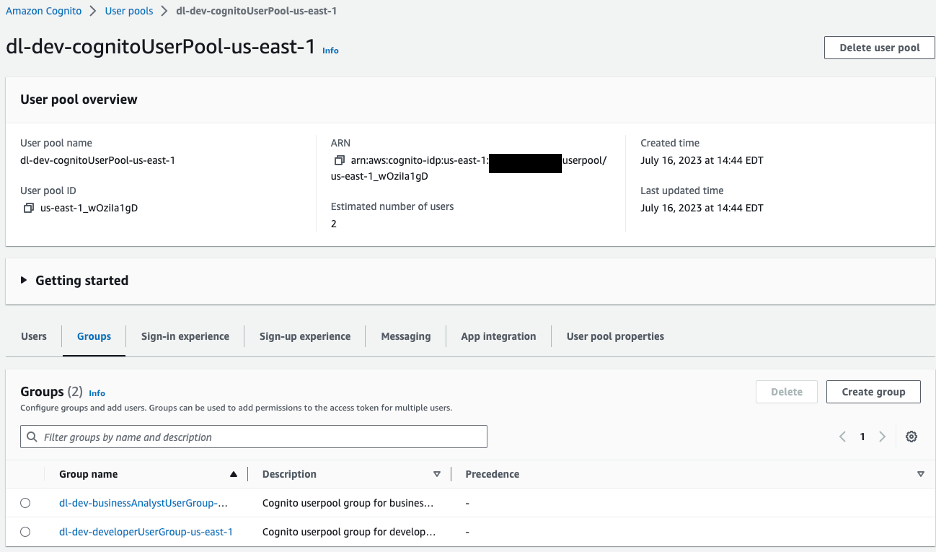
รูปที่ 10 –กลุ่มผู้ใช้ Amazon Cognito
สำหรับแอปพลิเคชันตัวอย่างของเรา เรามีกลุ่มผู้ใช้สองกลุ่ม:
dl-dev-businessAnalystUserGroup– นักวิเคราะห์ธุรกิจที่มีสิทธิ์จำกัดdl-dev-developerUserGroup– นักพัฒนาที่มีสิทธิ์เต็มรูปแบบ
หากคุณสำรวจกลุ่มเหล่านี้ คุณจะเห็นบทบาท IAM ที่เกี่ยวข้องกับแต่ละกลุ่ม นี่คือบทบาท IAM ที่กำหนดให้กับผู้ใช้เมื่อพวกเขาตรวจสอบสิทธิ์ Athena จะรับบทบาทนี้เมื่อสืบค้น Data Lake
หากคุณดูสิทธิ์สำหรับบทบาท IAM นี้ คุณจะสังเกตเห็นว่าบทบาทนี้ไม่มีการควบคุมการเข้าถึงต่ำกว่าระดับตาราง คุณต้องมีการควบคุมดูแลเพิ่มเติมอีกชั้นที่ Lake Formation มอบให้เพื่อเพิ่มการควบคุมการเข้าถึงแบบละเอียด
หลังจากที่ผู้ใช้ได้รับการตรวจสอบและรับรองความถูกต้องโดย Cognito แล้ว Amplify จะใช้โทเค็นการเข้าถึงเพื่อเรียกใช้ AWS AppSync GraphQL API และดึงข้อมูล ขึ้นอยู่กับกลุ่มของผู้ใช้ ฟังก์ชัน Lambda จะรับบทบาทกลุ่มผู้ใช้ Cognito ที่สอดคล้องกัน เมื่อใช้บทบาทสมมติ ระบบจะเรียกใช้แบบสอบถาม Athena และผลลัพธ์จะส่งคืนให้กับผู้ใช้
สร้างผู้ใช้ทดสอบ
สร้างผู้ใช้สองคน คนหนึ่งสำหรับนักพัฒนาและอีกคนหนึ่งสำหรับนักวิเคราะห์ธุรกิจ และเพิ่มพวกเขาลงในกลุ่มผู้ใช้
- ไปที่ Cognito และเลือกกลุ่มผู้ใช้
dl-dev-cognitoUserPoolที่สร้างขึ้นแล้ว - Choose สร้างผู้ใช้ และระบุรายละเอียดเพื่อสร้างผู้ใช้นักวิเคราะห์ธุรกิจรายใหม่ ชื่อผู้ใช้สามารถเป็นได้ นักวิเคราะห์ธุรกิจ. ปล่อยให้ที่อยู่อีเมลว่างไว้ และป้อนรหัสผ่าน
- เลือก ผู้ใช้ และเลือกผู้ใช้ที่คุณเพิ่งสร้างขึ้น
- เพิ่มผู้ใช้รายนี้ในกลุ่มนักวิเคราะห์ธุรกิจโดยเลือก เพิ่มผู้ใช้ในกลุ่ม ปุ่ม
- ทำตามขั้นตอนเดียวกันเพื่อสร้างผู้ใช้รายอื่นด้วยชื่อผู้ใช้ ผู้พัฒนา และเพิ่มผู้ใช้ในกลุ่มนักพัฒนา
ทดสอบวิธีแก้ปัญหา
หากต้องการทดสอบโซลูชันของคุณ ให้เปิดแอปพลิเคชัน React บนเครื่องของคุณ
- ในไดเร็กทอรีโปรเจ็กต์โคลน ให้ไปที่
react-appไดเรกทอรี - ติดตั้งการพึ่งพาโครงการ
- ติดตั้ง Amplify CLI:
- สร้างไฟล์ใหม่ที่เรียกว่า
.envโดยรันคำสั่งต่อไปนี้ จากนั้นใช้โปรแกรมแก้ไขข้อความเพื่ออัปเดตค่าตัวแปรสภาพแวดล้อมในไฟล์
ใช้ Outputs ของสแต็กคอนโซล CloudFormation ของคุณเพื่อรับค่าที่ต้องการจากคีย์ดังต่อไปนี้:
REACT_APP_APPSYNC_URL |
appsyncApiEndpoint |
REACT_APP_CLIENT_ID |
cognitoUserPoolClientId |
REACT_APP_USER_POOL_ID |
cognitoUserPoolId |
- เพิ่มตัวแปรก่อนหน้าให้กับสภาพแวดล้อมของคุณ
- สร้างโค้ดที่จำเป็นในการโต้ตอบกับ API โดยใช้ ขยาย CodeGen. ในแท็บเอาต์พุตของคอนโซล Cloudformation ให้ค้นหา AWS Appsync API ID ของคุณถัดจาก
appsyncApiIdกุญแจ
ยอมรับตัวเลือกเริ่มต้นทั้งหมดสำหรับคำสั่งข้างต้นโดยกด เข้าสู่ ในแต่ละพร้อมท์
- เริ่มแอปพลิเคชัน
คุณสามารถยืนยันได้ว่าแอปพลิเคชันกำลังทำงานอยู่โดยไปที่ http://localhost:3000 และลงชื่อเข้าใช้ในฐานะผู้ใช้นักพัฒนาซอฟต์แวร์ที่คุณสร้างไว้ก่อนหน้านี้
ตอนนี้คุณมีแอปพลิเคชันที่ทำงานอยู่แล้ว มาดูกันว่าแต่ละบทบาทจะได้รับบริการอย่างไร companies จุดสิ้นสุด
ขั้นแรก ให้ลงชื่อเป็นบทบาทนักพัฒนา ซึ่งมีสิทธิ์เข้าถึงทุกฟิลด์ และสร้างคำขอ API ไปยังตำแหน่งข้อมูลของบริษัท โปรดทราบว่าช่องใดที่คุณสามารถเข้าถึงได้
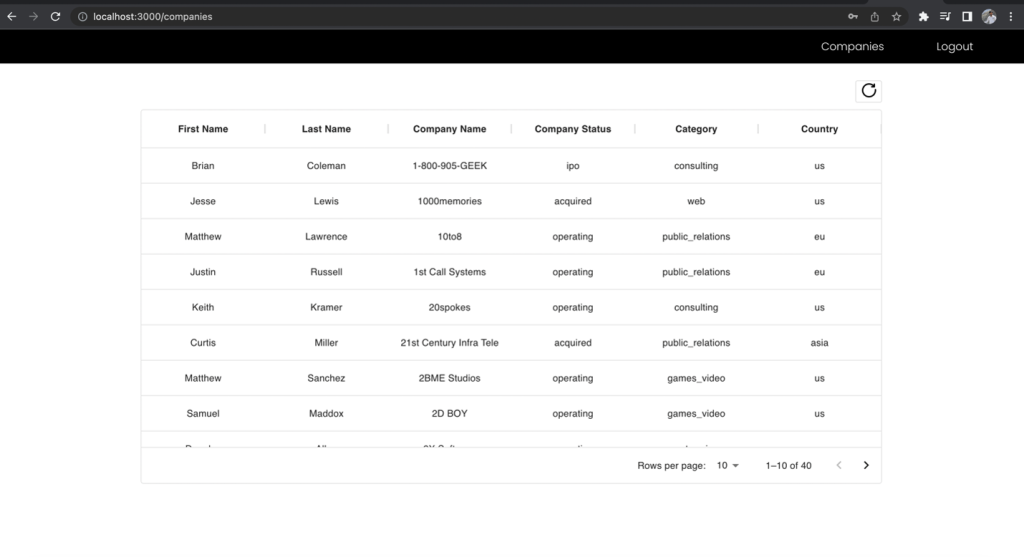
รูปที่ 11 –ผลลัพธ์สำหรับบทบาทของนักพัฒนา
ตอนนี้ ลงชื่อเข้าใช้ในฐานะผู้ใช้นักวิเคราะห์ธุรกิจ และทำการร้องขอไปยังจุดสิ้นสุดเดียวกัน และเปรียบเทียบฟิลด์ที่รวมไว้
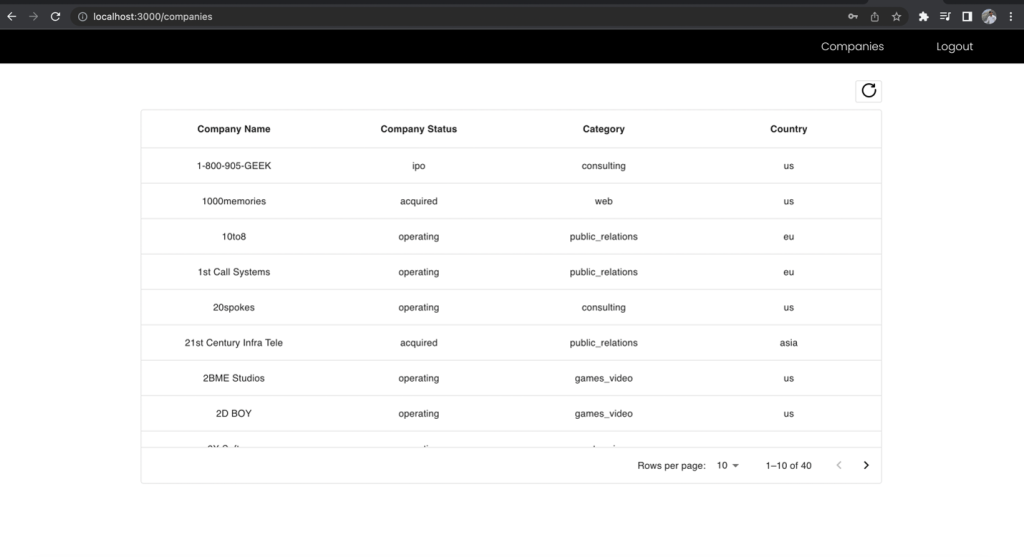
รูปที่ 12 –ผลลัพธ์สำหรับบทบาทนักวิเคราะห์ธุรกิจ
คอลัมน์ชื่อและนามสกุลของรายชื่อบริษัทจะไม่รวมอยู่ในมุมมองนักวิเคราะห์ธุรกิจ แม้ว่าคุณจะทำการร้องขอไปยังจุดสิ้นสุดเดียวกันก็ตาม สิ่งนี้แสดงให้เห็นถึงพลังของการใช้ตำแหน่งข้อมูล GraphQL ที่รวมเป็นหนึ่งเดียวร่วมกับบทบาท IAM กลุ่มผู้ใช้ Cognito หลายบทบาทที่แมปกับสิทธิ์ Lake Formation เพื่อจัดการการเข้าถึงข้อมูลของคุณตามบทบาท
การทำความสะอาด
หลังจากคุณทดสอบโซลูชันเสร็จแล้ว ให้ล้างทรัพยากรต่อไปนี้เพื่อหลีกเลี่ยงการเรียกเก็บเงินในอนาคต:
- ล้างบัคเก็ต S3 ที่สร้างโดยเทมเพลต CloudFormation
- ลบสแตก CloudFormation เพื่อลบบัคเก็ต S3 และทรัพยากรอื่นๆ
สรุป
ในโพสต์นี้ เราได้แสดงให้คุณเห็นวิธีการให้บริการข้อมูลอย่างปลอดภัยใน Data Lake แก่ผู้ใช้ที่ได้รับการรับรองความถูกต้องของแอปพลิเคชัน React ตามสิทธิ์การเข้าถึงตามบทบาทของพวกเขา เพื่อให้บรรลุเป้าหมายนี้ คุณใช้ GraphQL API ใน AWS AppSync, การควบคุมการเข้าถึงแบบละเอียดจาก Lake Formation และ Cognito สำหรับการตรวจสอบสิทธิ์ผู้ใช้ตามกลุ่มและแมปผู้ใช้กับบทบาท IAM คุณยังใช้ Athena เพื่อสืบค้นข้อมูลอีกด้วย
สำหรับการอ่านที่เกี่ยวข้องในหัวข้อนี้ โปรดดู การแสดงข้อมูลขนาดใหญ่ด้วย AWS AppSync, Amazon Athena และ AWS Amplify และ ออกแบบสถาปัตยกรรม data mesh โดยใช้ AWS Lake Formation และ AWS Glue.
คุณจะใช้แนวทางนี้ในการให้บริการข้อมูลจาก Data Lake ของคุณหรือไม่? แจ้งให้เราทราบในความคิดเห็น!
เกี่ยวกับผู้เขียน
 รานา ดัตต์ เป็น Principal Solutions Architect ที่ Amazon Web Services เขามีพื้นฐานในการออกแบบสถาปัตยกรรมแพลตฟอร์มซอฟต์แวร์ที่ปรับขนาดได้สำหรับบริษัทบริการทางการเงิน การดูแลสุขภาพ และโทรคมนาคม และมีความหลงใหลในการช่วยเหลือลูกค้าสร้างบน AWS
รานา ดัตต์ เป็น Principal Solutions Architect ที่ Amazon Web Services เขามีพื้นฐานในการออกแบบสถาปัตยกรรมแพลตฟอร์มซอฟต์แวร์ที่ปรับขนาดได้สำหรับบริษัทบริการทางการเงิน การดูแลสุขภาพ และโทรคมนาคม และมีความหลงใหลในการช่วยเหลือลูกค้าสร้างบน AWS
 รันชิธ รายาโปรลู เป็นสถาปนิกโซลูชันอาวุโสที่ AWS ที่ทำงานร่วมกับลูกค้าในแปซิฟิกตะวันตกเฉียงเหนือ เขาช่วยลูกค้าออกแบบและดำเนินการโซลูชัน Well-Architected ใน AWS ซึ่งแก้ไขปัญหาทางธุรกิจและเร่งการนำบริการของ AWS ไปใช้ เขามุ่งเน้นไปที่เทคโนโลยีด้านความปลอดภัยและเครือข่ายของ AWS เพื่อพัฒนาโซลูชันในระบบคลาวด์ในอุตสาหกรรมแนวดิ่งต่างๆ Ranjith อาศัยอยู่ในพื้นที่ซีแอตเทิลและชอบกิจกรรมกลางแจ้ง
รันชิธ รายาโปรลู เป็นสถาปนิกโซลูชันอาวุโสที่ AWS ที่ทำงานร่วมกับลูกค้าในแปซิฟิกตะวันตกเฉียงเหนือ เขาช่วยลูกค้าออกแบบและดำเนินการโซลูชัน Well-Architected ใน AWS ซึ่งแก้ไขปัญหาทางธุรกิจและเร่งการนำบริการของ AWS ไปใช้ เขามุ่งเน้นไปที่เทคโนโลยีด้านความปลอดภัยและเครือข่ายของ AWS เพื่อพัฒนาโซลูชันในระบบคลาวด์ในอุตสาหกรรมแนวดิ่งต่างๆ Ranjith อาศัยอยู่ในพื้นที่ซีแอตเทิลและชอบกิจกรรมกลางแจ้ง
 จัสติน เลโต เป็นสถาปนิกโซลูชันอาวุโสที่ Amazon Web Services โดยมีความเชี่ยวชาญในด้านฐานข้อมูล การวิเคราะห์ Big Data และการเรียนรู้ของเครื่อง ความหลงใหลของเขาคือการช่วยให้ลูกค้านำระบบคลาวด์ไปใช้ได้ดียิ่งขึ้น ในเวลาว่าง เขาสนุกกับการล่องเรือนอกชายฝั่งและเล่นเปียโนแจ๊ส เขาอาศัยอยู่ในนิวยอร์กซิตี้กับภรรยาและลูกสาวตัวน้อยของเขา
จัสติน เลโต เป็นสถาปนิกโซลูชันอาวุโสที่ Amazon Web Services โดยมีความเชี่ยวชาญในด้านฐานข้อมูล การวิเคราะห์ Big Data และการเรียนรู้ของเครื่อง ความหลงใหลของเขาคือการช่วยให้ลูกค้านำระบบคลาวด์ไปใช้ได้ดียิ่งขึ้น ในเวลาว่าง เขาสนุกกับการล่องเรือนอกชายฝั่งและเล่นเปียโนแจ๊ส เขาอาศัยอยู่ในนิวยอร์กซิตี้กับภรรยาและลูกสาวตัวน้อยของเขา
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/using-aws-appsync-and-aws-lake-formation-to-access-a-secure-data-lake-through-a-graphql-api/
- :มี
- :เป็น
- :ไม่
- $ ขึ้น
- 1
- 10
- 100
- 11
- 12
- 13
- 14
- 200
- 27
- 32
- 7
- 8
- 9
- a
- สามารถ
- เกี่ยวกับเรา
- ข้างบน
- เร่งความเร็ว
- เข้า
- การจัดการการเข้าถึง
- การเข้าถึงข้อมูล
- บรรลุผล
- บรรลุ
- ข้าม
- กิจกรรม
- เพิ่ม
- เพิ่มเติม
- นอกจากนี้
- ที่อยู่
- การบริหาร
- ผู้ดูแลระบบ
- การนำมาใช้
- กับ
- ทั้งหมด
- ช่วยให้
- ด้วย
- อเมซอน
- อเมซอน อาเธน่า
- Amazon Cognito Co
- Amazon Web Services
- จำนวน
- ขยาย
- an
- นักวิเคราะห์
- นักวิเคราะห์
- การวิเคราะห์
- และ
- อื่น
- ใด
- API
- APIs
- app
- การใช้งาน
- การใช้งาน
- เข้าใกล้
- สถาปัตยกรรม
- เป็น
- AREA
- มาถึง
- AS
- ที่ได้รับมอบหมาย
- ที่เกี่ยวข้อง
- สมมติ
- สันนิษฐาน
- ถือว่า
- At
- แอตทริบิวต์
- รับรองความถูกต้อง
- รับรองความถูกต้อง
- ตรวจสอบสิทธิ์
- การยืนยันตัวตน
- ใช้ได้
- หลีกเลี่ยง
- AWS
- การก่อตัวของ AWS Cloud
- AWS กาว
- การก่อตัวของทะเลสาบ AWS
- ทารก
- พื้นหลัง
- บาร์
- ตาม
- BE
- รับ
- ด้านล่าง
- ดีกว่า
- ใหญ่
- ข้อมูลขนาดใหญ่
- Black
- ร่างกาย
- ในกล่องสี่เหลี่ยม
- สร้าง
- สร้าง
- กำ
- ธุรกิจ
- ธุรกิจ
- แต่
- ปุ่ม
- by
- ที่เรียกว่า
- CAN
- สามารถรับ
- จับ
- แค็ตตาล็อก
- แคตตาล็อก
- CD
- เซลล์
- บาง
- ความท้าทาย
- เปลี่ยนแปลง
- การเปลี่ยนแปลง
- โหลด
- Choose
- เลือก
- เมือง
- ไคลเอนต์
- เมฆ
- การยอมรับระบบคลาวด์
- รหัส
- คอลัมน์
- คอลัมน์
- COM
- บริษัท
- เปรียบเทียบ
- การปฏิบัติตาม
- ส่วนประกอบ
- การกำหนดค่า
- ยืนยัน
- ปลอบใจ
- ผู้บริโภค
- ควบคุม
- การควบคุม
- ตรงกัน
- ค่าใช้จ่ายที่มีประสิทธิภาพ
- ไม้เลื้อย
- สร้าง
- ที่สร้างขึ้น
- การสร้าง
- หนังสือรับรอง
- ลูกค้า
- ข้อมูล
- การเข้าถึงข้อมูล
- วิเคราะห์ข้อมูล
- ดาต้าเลค
- ความปลอดภัยของข้อมูล
- ฐานข้อมูล
- ฐานข้อมูล
- ค่าเริ่มต้น
- ส่งมอบ
- สาธิต
- แสดงให้เห็นถึง
- การอ้างอิง
- ทั้งนี้ขึ้นอยู่กับ
- ปรับใช้
- นำไปใช้
- อธิบาย
- ลักษณะ
- ออกแบบ
- กำหนด
- รายละเอียด
- dev
- พัฒนา
- ผู้พัฒนา
- นักพัฒนา
- ต่าง
- โดยตรง
- ค้นพบ
- หลาย
- do
- ไม่
- ทำ
- ลง
- หล่น
- แต่ละ
- ก่อน
- เสียงสะท้อน
- บรรณาธิการ
- อื่น
- อีเมล
- ช่วยให้
- ปลายทาง
- ทำให้มั่นใจ
- เข้าสู่
- หน่วยงาน
- สิ่งแวดล้อม
- อีเธอร์ (ETH)
- แม้
- เหตุการณ์
- ทุกๆ
- ตัวอย่าง
- การยกเว้น
- รัน
- สำรวจ
- ส่งออก
- ภายนอก
- สารสกัด
- สาขา
- รูป
- เนื้อไม่มีมัน
- ทางการเงิน
- บริการทางการเงิน
- หา
- ชื่อจริง
- ครั้งแรก
- มีความยืดหยุ่น
- มุ่งเน้นไปที่
- ดังต่อไปนี้
- ดังต่อไปนี้
- สำหรับ
- การสร้าง
- ราคาเริ่มต้นที่
- เต็ม
- ฟังก์ชัน
- ฟังก์ชั่น
- อนาคต
- ดึงดูด
- กําไร
- เกตเวย์
- ได้รับ
- ไป
- ไป
- การกำกับดูแล
- รับ
- กราฟคิวแอล
- บัญชีกลุ่ม
- กลุ่ม
- เติบโต
- จัดการ
- จัดการ
- มี
- he
- การดูแลสุขภาพ
- การช่วยเหลือ
- จะช่วยให้
- ของเขา
- ถือ
- ถือ
- บ้าน
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTML
- ที่ http
- HTTPS
- AMI
- ID
- ในอุดมคติ
- เอกลักษณ์
- การระบุตัวตนและการจัดการการเข้าถึง
- if
- ภาพ
- การดำเนินการ
- การดำเนินการ
- in
- ประกอบด้วย
- รวม
- รวมถึง
- อุตสาหกรรม
- ข้อมูล
- เริ่มต้น
- ติดตั้ง
- รวม
- โต้ตอบ
- เข้าไป
- เรียก
- IT
- jpg
- เพียงแค่
- คีย์
- กุญแจ
- ทราบ
- ทะเลสาบ
- ชล
- ชื่อสกุล
- ล่าสุด
- เปิดตัว
- เปิดตัว
- การเปิดตัว
- ชั้น
- การเรียนรู้
- ทิ้ง
- ซ้าย
- ให้
- ชั้น
- ห้องสมุด
- ถูก จำกัด
- รายการ
- ชีวิต
- ในประเทศ
- ที่ตั้ง
- ดู
- รัก
- เครื่อง
- เรียนรู้เครื่อง
- ทำ
- ทำ
- ทำให้
- การทำ
- จัดการ
- การจัดการ
- การจัดการ
- การทำแผนที่
- เมนู
- ตาข่าย
- วิธี
- microservices
- อาจ
- หลาย
- ต้อง
- ตนเอง
- ชื่อ
- ที่มีชื่อ
- นำทาง
- การเดินเรือ
- จำเป็นต้อง
- จำเป็น
- เครือข่าย
- ใหม่
- นิวยอร์ก
- เมืองนิวยอร์ก
- ถัดไป
- หมายเหตุ
- สังเกต..
- ตอนนี้
- จำนวน
- วัตถุ
- ได้รับ
- of
- เสนอ
- มักจะ
- on
- ONE
- เพียง
- ทำงาน
- ตัวเลือกเสริม (Option)
- Options
- or
- องค์กร
- อื่นๆ
- ของเรา
- ของเล่นกลางแจ้ง
- เอาท์พุท
- เกิน
- เจ้าของ
- แปซิฟิก
- หน้า
- หมีแพนด้า
- พารามิเตอร์
- หุ้นส่วน
- ส่ง
- ผ่าน
- กิเลส
- หลงใหล
- รหัสผ่าน
- การอนุญาต
- สิทธิ์
- PII
- วางไว้
- ตัวยึด
- แพลตฟอร์ม
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- สระ
- สระว่ายน้ำ
- ความนิยม
- โพสต์
- อำนาจ
- ที่มีประสิทธิภาพ
- นำเสนอ
- การกด
- หลัก
- สิทธิ์
- ปัญหาที่เกิดขึ้น
- ดำเนิน
- กระบวนการ
- กระบวนการ
- ดูรายละเอียด
- โครงการ
- ให้
- ให้
- ผู้จัดหา
- ให้
- หลาม
- เกิดปฏิกิริยา
- อ่าน
- การอ่าน
- บันทึก
- สะท้อน
- ลงทะเบียน
- ที่เกี่ยวข้อง
- เอาออก
- แทนที่
- กรุ
- ขอ
- การร้องขอ
- จำเป็นต้องใช้
- แหล่งข้อมูล
- ว่า
- คำตอบ
- จำกัด
- ผล
- ผลสอบ
- กลับ
- รับคืน
- บทบาท
- บทบาท
- ราก
- กฎ
- วิ่ง
- วิ่ง
- ทำงาน
- การล่องเรือ
- เดียวกัน
- ตัวอย่างชุดข้อมูล
- ที่ปรับขนาดได้
- จอภาพ
- ซีแอตเทิ
- Section
- ปลอดภัย
- อย่างปลอดภัย
- ความปลอดภัย
- โทเค็นการรักษาความปลอดภัย
- เห็น
- เลือก
- การเลือก
- ระดับอาวุโส
- ให้บริการ
- ให้บริการ
- บริการ
- บริการ
- การให้บริการ
- การตั้งค่า
- หลาย
- น่า
- แสดงให้เห็นว่า
- การแสดง
- แสดง
- ด้าน
- ลงชื่อ
- การลงชื่อ
- ง่าย
- So
- ซอฟต์แวร์
- ของแข็ง
- ทางออก
- โซลูชัน
- บาง
- บางครั้ง
- แหล่ง
- แหล่งที่มา
- โดยเฉพาะ
- กอง
- เริ่มต้น
- ข้อความที่เริ่ม
- Status
- ขั้นตอน
- ขั้นตอน
- การเก็บรักษา
- จัดเก็บ
- เก็บข้อมูล
- เก็บไว้
- ซับเน็ต
- ที่ประสบความสำเร็จ
- อย่างเช่น
- แน่ใจ
- ตาราง
- เอา
- งาน
- เทคโนโลยี
- โทรคมนาคม
- เทมเพลต
- ชั่วคราว
- ทดสอบ
- การทดสอบ
- ข้อความ
- ที่
- พื้นที่
- ของพวกเขา
- พวกเขา
- แล้วก็
- ดังนั้น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- แต่?
- ตลอด
- เวลา
- ไปยัง
- ร่วมกัน
- โทเค็น
- ราชสกุล
- หัวข้อ
- กลับ
- สอง
- ชนิด
- ชนิด
- ภายใต้
- ปึกแผ่น
- บันทึก
- การปรับปรุง
- URL
- us
- ใช้
- มือสอง
- ผู้ใช้งาน
- ชื่อผู้ใช้
- ผู้ใช้
- ใช้
- การใช้
- ความคุ้มค่า
- ตัวแปร
- ตัวแปร
- กว้างใหญ่
- การตรวจสอบแล้ว
- แนวดิ่ง
- รายละเอียด
- ต้องการ
- คือ
- ทาง..
- we
- เว็บ
- บริการเว็บ
- ยินดีต้อนรับ
- คือ
- เมื่อ
- เมื่อไรก็ตาม
- ที่
- ในขณะที่
- ภรรยา
- จะ
- กับ
- การทำงาน
- นิวยอร์ก
- เธอ
- ของคุณ
- ด้วยตัวคุณเอง
- ลมทะเล
- รหัสไปรษณีย์