Son güncelleme: Ocak 2021.
Bu blog, belge iş akışlarınızı otomatikleştirmek için herhangi bir RPA aracıyla OCR'yi kullanmanın kapsamlı bir özetidir. En yeni makine öğrenimi tabanlı OCR teknolojilerinin kural veya şablon kurulumu gerektirmediğini keşfediyoruz.

RPA'lar veya Robotik Süreç otomasyonu, tekrarlayan iş görevlerini ortadan kaldırmayı amaçlayan yazılım araçlarıdır. Maliyetleri düşürmek ve çalışanların daha yüksek değerli iş çalışmalarına odaklanmalarına yardımcı olmak için daha fazla CIO onlara yöneliyor. Örnekler arasında, web sitelerindeki yorumlara yanıt verme veya müşteri siparişi işleme yer alır. Biraz daha karmaşık görevler, el yazısı formlar ve faturalar – bunların tipik olarak bir eski sistemden diğerine taşınması gerekir – diyelim ki e-posta istemcinizden veri çıkarmanız gereken SAP ERP sisteminize. Sorunlu kısım budur.
Bu belgelerden veri yakalayan çoğu OCR aracı şablon tabanlıdır (örneğin Abbyy Flexicapture) ve yarı yapılandırılmış belgelerde iyi ölçeklendirme yapmayın. Genellikle API sağlayan yeni nesil makine öğrenimi tabanlı çözümler vardır.
Belgelerden anahtar / değer çiftlerini yakalayabilen entegrasyonlar - kurumsal sistemler genellikle eskidir ve harici API'lerle entegrasyona açık değildir. Öte yandan, RPA'lar, belgeleri klasörlerden almak ve sonuçları ERP'lere veya CRM'lere girmek gibi bu eski sistem iş akışlarını idare etmek için oluşturulmuştur.
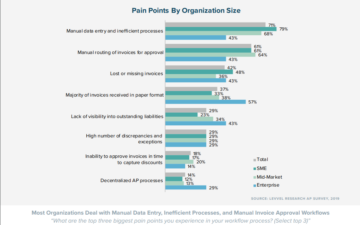
Robotik Süreç Otomasyonu (RPA) ve makine öğrenimi hiper otomasyona doğru geliştikçe, Belge Sınıflandırma, Çıkarma ve Optik Karakter Tanıma gibi karmaşık görevleri yerine getirmek için makine öğrenimi ile birlikte yazılım botlarını kullanabiliriz. Yakın zamanda yapılan bir çalışmada, RPA'ları kullanan bir görev için işlevlerin yalnızca% 29'unu otomatikleştirerek, tek başına finans departmanlarının, 25,000 tam kapasiteli bir kuruluş için yılda 878,000 $ maliyetle insan hatalarından kaynaklanan 40 saatten fazla yeniden çalışma tasarrufu sağladığı söylendi. zaman muhasebesi personeli [1]. Bu blogda, OCR'leri RPA'larla kullanmayı öğrenecek ve iş akışlarını anlama belgesine derinlemesine dalacağız. İçindekiler tablosu aşağıdadır.
Tanımlar ve Genel Bakış
Genel olarak RPA, yazılım-donanım botları aracılığıyla yönetim görevlerini otomatikleştirmeye yardımcı olan bir teknolojidir. Bu botlar, kullanıcı arayüzlerinden yararlanır; verileri yakalamak ve uygulamaları insanlar gibi manipüle etmek için. Örneğin, bir RPA, bir GUI'de gerçekleştirilen bir dizi göreve bakabilir, örneğin hareketli imleçler, API'lere bağlanabilir, verileri kopyalayıp yapıştırabilir ve koda dönüşen bir RPA tel çerçevesinde aynı eylem dizisini formüle edebilir. Ayrıca, bu görevler gelecekte insan müdahalesi olmadan gerçekleştirilebilir. Optik Karakter Tanıma (OCR), herhangi bir işlevsel robotik süreç otomasyonu (RPA) çözümünün çok önemli bir özelliğidir. Bu teknoloji, resimler veya resimler gibi farklı kaynaklardan metin okumak ve çıkarmak için kullanılır. pdfs elle yakalamadan dijital formata dönüştürün.
Öte yandan, Belge anlama, belge verilerini okumayı, yorumlamayı ve bunlara göre hareket etmeyi otomatik olarak tanımlamak için kullanılan terimdir. Bu süreçte en önemlisi, yazılım botlarının tüm görevleri kendisi gerçekleştirmesidir. Bu botlar, belgeleri dijital yardımcılar olarak anlamak için Yapay Zeka ve Makine Öğreniminin gücünden yararlanır. Bu şekilde, belge anlayışının belge işleme, AI ve RPA'nın kesiştiği noktada ortaya çıktığını söyleyebiliriz.

Robotlar, OCR ve ML ile belgeleri anlamayı nasıl öğrenebilir?
Önce Document Understanding'e derinlemesine dalmadan önce, Robots for Document Understanding'in rolünden bahsedelim. Bu tamamen görünmez yardımcılar hayatımızı çok daha rahat hale getiriyor. Filmlerden ve dizilerden farklı olarak, bu robotlar, bir masaüstüne oturan ve görevleri gerçekleştirmek için düğmelere basılan fiziksel cihazlar veya yapay zeka programları değildir. Bunları, bizim gibi uygulamaları okuyarak ve kullanarak belgeleri işlemek için eğitilmiş dijital asistanlar olarak düşünebiliriz. İşlevsel açıdan, robotlar bir sürecin performansını ve verimliliğini iyileştirmede iyidir. Yine de bağımsız bir yazılım oldukları için süreci değerlendiremez ve bilişsel kararlar veremezler. Bununla birlikte, makine öğrenimi başarılı bir şekilde entegre edilirse, robotik daha dinamik ve uyarlanabilir hale gelecektir. Örneğin, ön ve orta ofis genelinde belge işleme, veri yönetimi ve diğer işlevler için kullanılan robotlar, yinelenen girişleri ortadan kaldırmak veya süreçteki bilinmeyen sistem istisnalarını çözmek gibi daha akıllı eylemler gerçekleştirecektir. Ayrıca robotlar, yapay zeka (AI) kullanarak belgelerdeki verileri okumak, çıkarmak, yorumlamak ve bunlara göre hareket etmek üzere eğitilir.
Şirketler, iş akışlarını iyileştirmek için akıllı OCR'yi RPA ile nasıl entegre edebilir?
Belge verilerinin çıkarılması, belgenin anlaşılması için çok önemli bir bileşendir. Bu bölümde, OCR'yi RPA ile nasıl entegre edebileceğimizi veya bunun tersini tartışacağız. İlk olarak, hepimiz şablonlar, stil, biçimlendirme ve bazen dil açısından farklı türde belgeler olduğunu biliyorduk. Bu nedenle, bu belgelerden verileri çıkarmak için basit bir OCR tekniğine güvenemeyiz. Bu sorunu çözmek için, farklı belge yapılarından verileri işlemek için OCR içinde hem kural tabanlı yaklaşımları hem de model tabanlı yaklaşımları kullanacağız. Şimdi OCR yapan şirketlerin belge türlerine göre mevcut sistemlerine RPA'ları nasıl entegre edebileceklerini göreceğiz.
Yapılandırılmış Belgeler: Bu tür belgelerde, düzenler ve şablonlar genellikle sabittir ve neredeyse tutarlıdır. Örneğin, pasaport veya ehliyet gibi Hükümet tarafından verilmiş kimliklerle KYC yapan bir kuruluşu düşünün. Tüm bu belgeler aynı olacak ve Kimlik Numarası, Kişinin Adı, Yaşı ve aynı pozisyonlardaki diğer birkaç kişi ile aynı alanlara sahip olacaktır. Ancak yalnızca ayrıntılar değişir. Tablo taşması veya dosyalanmamış veriler gibi birkaç kısıtlama olabilir.
Genellikle, önerilen yaklaşım, yapılandırılmış belgeler için bilgileri çıkarmak için bir şablon veya kural tabanlı motor kullanır. Bunlar, normal ifadeleri veya basit konum eşleştirme ve OCR'yi içerebilir. Bu nedenle, bilgi çıkarmayı otomatikleştirmek için yazılım robotlarını entegre etmek için, önceden var olan şablonları kullanabilir veya yapılandırılmış verilerimiz için kurallar oluşturabiliriz. Kural tabanlı yaklaşımı kullanmanın bir dezavantajı vardır, çünkü sabit parçalara dayanır, form yapısındaki küçük değişiklikler bile kuralların bozulmasına neden olabilir.
Yarı Yapılandırılmış Belgeler: Bu belgeler aynı bilgilere sahiptir ancak farklı konumlarda düzenlenmiştir. Örneğin, düşünün faturalar 8-12 özdeş alan içerir. birkaç faturalar, satıcı adresi üstte bulunabilir ve diğerlerinde altta bulunabilir. Tipik olarak bu kural tabanlı yaklaşımlar yüksek doğruluklar vermez; bu nedenle, OCR kullanarak bilgi çıkarma için resme makine öğrenimi ve derin öğrenme modelleri getiriyoruz. Alternatif olarak, bazı durumlarda hem kuralları hem de ML modellerini içeren hibrit modelleri kullanabiliriz. Birkaç popüler önceden eğitilmiş model, belgelerden bilgi çıkarmak için FastRCNN, Attention OCR, Graph Convolutions'tır. Ancak yine bu modellerin birkaç dezavantajı vardır; dolayısıyla, doğruluk veya güven puanı gibi metrikleri kullanarak algoritma performansını ölçüyoruz. Model, somut kurallar yerine öğrenme kalıpları olduğu için, düzeltmelerden hemen sonra başlangıçta hatalar yapabilir. Bununla birlikte, bu dezavantajların çözümü - ML modeli ne kadar çok örnek işlerse, doğruluğu sağlamak için o kadar çok kalıp öğrenir.
Yapılandırılmamış Belgeler: RPA, günümüzde yapılandırılmamış verileri doğrudan yönetememektedir, bu nedenle robotların önce OCR kullanarak yapılandırılmış verileri çıkarmasını ve oluşturmasını gerektirir. Yapılandırılmış ve yarı yapılandırılmış belgelerin aksine, yapılandırılmamış veriler birkaç anahtar/değer çiftine sahip değildir. Örneğin, birkaç faturalar, herhangi bir anahtar adı olmayan bir satıcı adresi görüyoruz; benzer şekilde tarih, fatura numarası gibi diğer alanlarda da aynı şeyi gözlemliyoruz. Makine öğrenimi modellerinin bunları doğru bir şekilde işlemesi için robotların yazılı metni e-posta, telefon numarası, adres vb. gibi eyleme geçirilebilir verilere nasıl çevireceğini öğrenmesi gerekir. Ardından model 7 veya 10 basamaklı sayı kalıplarının çıkarılması gerektiğini öğrenecektir. telefon numaraları ve metin olarak beş haneli kodlar ve farklı isimler içeren büyük metinler olarak. Bu modelleri daha doğru hale getirmek için Adlandırılmış Varlık Tanıma ve Kelime Gömme gibi Doğal Dil İşleme (NLP) tekniklerini de kullanabiliriz.
Genel olarak belgelerin anlaşılması için, önce verileri anlamak ve ardından RPA'larla OCR uygulamak çok önemlidir. Daha sonra, bir süreci adım adım haritalandırmak yerine, kuralları ve makine öğrenimi algoritmalarını entegre ederek yukarıda tartışıldığı gibi güçlü OCR yetenekleriyle olduğu gibi süreci kaydederek bir robota "benim yaptığım gibi yapmasını" öğretebiliriz. Yazılım robotu, ekrandaki tıklamalarınızı ve eylemlerinizi takip eder ve ardından bunları düzenlenebilir bir iş akışına dönüştürür. Tamamen yerel programlarda çalışıyorsanız, bilmeniz gereken bu kadardır.
RPA geliştiricilerinin karşılaştığı OCR Zorlukları
OCRR'yi farklı belgeler için RPA'larla nasıl entegre edebileceğimizi gördük, ancak robotların iyi işlemesi gereken birkaç zorluk var. Şimdi onları tartışalım!
- Zayıf veya Tutarsız Veriler: Veriler, Belge Anlama'da çok önemli bir rol oynar. Çoğu durumda belgeler, metin taraması sırasında belge biçimlendirmesini kaybetme olasılığının olduğu (yani kalın, italik ve altı çizili her zaman tanınmayan) kameralar kullanılarak taranır. Bazen OCR, metni yanlış şekilde ayıklayarak yazım hatalarına, düzensiz paragraf kesmelerine neden olabilir ve bu da robotların genel performansını düşürür. Bu nedenle, tüm eksik değerleri ele almak ve verileri daha yüksek hassasiyetle yakalamak, OCR için daha yüksek doğruluk elde etmek için çok önemlidir.
- Belgelerde Yanlış Sayfa Yönlendirmesi: Sayfa Yönü ve Eğiklik de OCR'nin yanlış metin düzeltmesine yol açan yaygın sorunlardan biridir. Bu genellikle, veri toplama aşamasında belgeler yanlış tarandığında meydana gelir. Bunun üstesinden gelmek için, robotlara sayfaya otomatik sığdırma, taranan belgenin kalitesinin artmasını ve çıktıda doğru verileri alabilmeleri için otomatik filtreleme gibi birkaç işlev bildirmemiz gerekecek.
- Entegrasyon Sorunları: Tüm RPA araçları uzak masaüstü ortamlarında iyi performans göstermez - otomasyonda çökmelere ve kritik sorunlara neden olurlar. Dahası, RPA geliştiricisinin belirli bir durum için hangi OCR çözümünün en iyi olacağını bilmesi gerekir. Ayrıca, belirli otomasyon araçlarıyla çalışmak için, RPA geliştiricisinin yalnızca Microsoft, Google tarafından oluşturulan sınırlı OCR teknolojisini seçmesi gerekir. Bu nedenle, özel algoritmalarımızı ve modellerimizi entegre etmek bazen zordur.
- Metnin tamamı karıştırılmış metindir: Gerçek hayattaki kullanım durumları için, genel bir OCR tarafından yakalanan metnin tümü karıştırılır ve botların önemli işlemleri gerçekleştirmek için kullanabileceği anlamlı bilgiler içermez. RPA geliştiricileri, yararlı uygulamalar oluşturabilmek için güçlü makine öğrenimi desteğine ihtiyaç duyar.
Belge Anlama İş Akışına Yönelik Pipeline
Önceki bölümlerde, botların farklı Belge türleri için OCR gerçekleştirmeye nasıl yardımcı olduğunu gördük. Ancak OCR, görüntüleri veya diğer dosyaları metne dönüştüren bir tekniktir. Şimdi, bu bölümde, belgeleri toplamanın en başından itibaren anlamlı bilgileri istenen formatta saklamak için Belge Anlama iş akışına bakacağız.

- Botunuzu kullanarak belgeyi bir klasörden besleyin: Bu, botlar aracılığıyla belgelerin anlaşılmasına ulaşmanın ilk adımıdır. Burada, bir bulut platformunda (bir API kullanarak) veya yerel bir makineden bulunan belgeyi alacağız. Bazı durumlarda, belgelerimiz web sayfalarındaysa, belgeleri zamanında getirebilecekleri botlar aracılığıyla kazıma komut dosyalarını otomatikleştirebiliriz.
- Belge Türü: Verileri getirdikten sonra, belgenin türünü ve bunların sistemlerimizde kaydedildiği formatı anlamak önemlidir, çünkü bazen farklı kaynaklardan çeşitli dosya formatlarında veri alıyoruz. PDF, PNG ve JPG. Sadece dosya türleri değil, bazen belgeler telefon kameralarıyla tarandığında, görüntü çarpıklığı, döndürme, parlaklık veya düşük çözünürlük gibi birkaç zorlu sorun da ele alınmalıdır. Bu nedenle, botların bu belgeleri yapılandırılmış, yarı yapılandırılmış veya yapılandırılmamış kategorilere ayırmasını ve böylece genel bir biçimde kaydetmesini sağlamalıyız. Sınıflandırma görevi, belgeleri şablonlarla karşılaştırarak ve yazı tipleri, dil, anahtar/değer çiftlerinin varlığı, tablolar vb. gibi özellikleri analiz ederek gerçekleştirilir.
- Verilerin OCR ile Çıkarılması: Pekala, botlar belgelerimizi genel bir formatta düzenleyip sınıflandırdığına göre, şimdi onları OCR tekniğini kullanarak dijitalleştirmenin zamanı geldi. Bununla birlikte, metni, konumunu görüntülerden eş koordinatlarda elde edeceğiz. Bu, sonraki adımlar için belgeleri ve verileri standartlaştırmaya yardımcı olur. Ayrıca, OCR yazılımının 't' ile 'i' veya '0' ile 'O' gibi karakterleri doğru bir şekilde ayırt edemediği durumlarda da karşılaşıyoruz. OCR yazılımını kullanarak atlatmak istediğiniz hatalar, OCR teknolojisi bir belgenin nüanslarını kalitesine veya orijinal biçimine göre analiz edemediğinde yeni baş ağrılarına dönüşebilir. Bir sonraki adımda tartışacağımız, Makine Öğreniminin devreye girdiği yer burasıdır.
- Botlar kullanarak Akıllı OCR için ML / DL'den yararlanma: Veriler dijitalleştirildikten sonra, OCR yazılımı üzerinde çalıştığı belge türünü ve neyin alakalı olduğunu anlamalıdır. Ancak geleneksel OCR yazılımı, belge sınıflandırma çabalarını ölçeklendirmekte zorlanabilir. Bu nedenle yazılım botları, OCR'leri daha akıllı hale getirmek için makine öğrenimi ve derin öğrenme tekniklerinden yararlanılarak bilişsel yeteneklerle eğitilmelidir. Makine öğrenimi tabanlı OCR çözümleri bir belge türünü tanımlayabilir ve bunu işletmeniz tarafından kullanılan bilinen bir belge türüyle eşleştirebilir. Ayrıca, yapılandırılmamış belgelerdeki metin bloklarını ayrıştırıp anlayabilirler. Çözüm, belgenin kendisi hakkında daha fazla bilgi edindikten sonra, niyet ve anlama dayalı olarak ilgili bilgileri çıkarmaya başlayabilir.
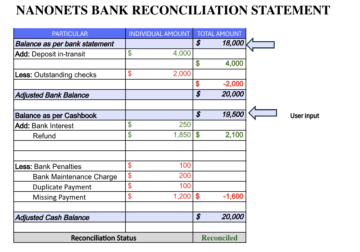
- Daha İyi Veri Çıkarma ve Sınıflandırma: Veri çıkarma, Belge Anlama'nın temelidir. Bu adımda RPA'ları OCR ile Entegre Etme hakkındaki önceki bölümde tartışıldığı gibi, belge türüne göre veri çıkarma tekniğini seçin. RPA'lar aracılığıyla, ister kural tabanlı ister ML tabanlı veya hibrit model OCR tekniği olsun, hangi çıkarıcının kullanılacağını kolayca yapılandırabiliriz. Bilgi çıkarıldıktan sonra döndürülen güven ve performans ölçütlerine dayanarak, yazılım robotları bunları daha fazla analiz için istediğimiz formatta kaydedecektir. Aşağıda, ayıklayıcıları nasıl yapılandırabileceğimizi ve UIPath tarafından bir RPA aracında güven düzeyini nasıl ayarlayabileceğimizin bir resmi bulunmaktadır.

6. Doğrulama ve Güçlendirme İçgörüleri: OCR ve Makine Öğrenimi modelleri, bilgi çıkarma açısından yüzde yüz doğru değildir, bu nedenle robotların yardımıyla bir insan müdahalesi katmanı eklemek sorunu çözebilir. Bu doğrulamanın çalışma şekli, robotlar düşük doğruluk ve istisnalarla uğraşırken, bir çalışanın verileri doğrulamak veya istisnaları ele almak için bir talep alabileceği ve bir tıklamayla herhangi bir belirsizliği çözebileceği eylem merkezine derhal bir bildirim göndermesidir. Ayrıca, tahminlerde bulunmak için zaman içinde verileri belgelemek ve dolandırıcılık, tekrarlama ve diğer hataları gösterebilecek olası anormallikleri tespit etmek için Yapay Zeka potansiyelinin kilidini açabiliriz.
Robotları Belge Anlama ile entegre etmenin faydaları
- İşlemi Otomatikleştirin: Belgelerin anlaşılması için botları entegre etmenin temel nedeni, tüm süreci baştan sona otomatikleştirmektir. Tek yapmamız gereken botların öğrenmesi, arkanıza yaslanıp rahatlaması için bir iş akışı oluşturmak. Doğrulama işlemi sırasında, herhangi bir hata veya sahtekarlığın tespit edildiği yerlerde botlar tarafından bildirilen sorunları ele almamız gerekebilir.
- Makine Öğrenimi Olan Botlar: Otomasyon sürecinde botları makine öğrenimine karşı dirençli hale getirebiliriz. Yani robotlar, Makine Öğrenimi modellerinin nasıl performans gösterdiğini öğrenebilir ve böylece, belgelerin metin ve bilgi çıkarma için daha yüksek doğruluk ve performans elde etmek için modelleri geliştirebilir.
- Çok Çeşitli Belge İşleme İşlemleri: Tablo ve bilgi çıkarma gibi genel görevler için, farklı belge türleri için farklı derin öğrenme boru hatları oluşturmamız gerekecek. Bu, çok sayıda uygulama oluşturmaya ve farklı sunucularda çeşitli modelleri konuşlandırmaya yol açar ve bu da çok çaba ve zaman gerektirir. Botlar geniş bir belge yelpazesi için resimdeyken, yalnızca botların onları sınıflandırabileceği ve ardından farklı görevler için uygun modeli kullanabileceği tek bir ardışık düzene sahip olabilirdik. Ayrıca çeşitli hizmetleri API'ler aracılığıyla entegre edebilir ve verilerin alınması açısından diğer kuruluşlarla iletişim kurabiliriz.
- Dağıtımı Kolay: Ardışık düzenler oluşturulduktan sonra belgelerin anlaşılması için dağıtım süreci sadece bir dakika sürer. Eğitimden sonra botlar tarafından dışa aktarılan API'lere sahip olabiliriz veya yerel sistemlerimizde kullanılabilecek özel bir RPA çözümü oluşturabiliriz. Bu tür bir dağıtım, işletmeleri de optimize edebilir ve çok minimum riskle harcamaları azaltabilir.
Nanonets girin
NanoNets, kullanıcıların veri toplamasına olanak tanıyan bir Makine Öğrenimi platformudur. faturalar, makbuzlar ve diğer belgeler herhangi bir şablon kurulumu olmadan. Arkada çalışan, OCR, tablo çıkarma, anahtar/değer çifti çıkarma gibi her türlü belge anlama görevini yerine getirebilen son teknoloji derin öğrenme ve bilgisayarla görme algoritmalarımız var. Genellikle API'ler olarak dışa aktarılır veya farklı kullanım durumlarına göre şirket içinde dağıtılabilirler. İşte birkaç örnek,
- Fatura Modeli: Anahtar alanları tanımlayın Faturalar Alıcı Adı, Fatura Kimliği, Tarih, Tutar vb.
- Makbuz Modeli: Satıcı Adı, Numarası, Tarih, Miktar vb. Gibi Makbuzlardan anahtar alanları tanımlayın.
- Ehliyet (ABD): Ehliyet No, DOB, Son Kullanma Tarihi, Veriliş Tarihi vb. Gibi temel alanları tanımlayın.
- Özgeçmişler: Deneyim, eğitim, beceri setleri, aday bilgileri vb. Ayıklayın.
Bu iş akışlarını daha hızlı ve sağlam hale getirmek için, belgelerinizin herhangi bir şablon olmadan sorunsuz otomasyonu için bir RPA aracı olan UiPath'i kullanıyoruz. Bir sonraki bölümde, belge anlamak için UiPath Connect'i Nanonet'lerle nasıl kullanabileceğinizi inceleyeceğiz. RPA pazarındaki en büyük 3 oyuncu UiPath, Automation Anywhere ve Mavi Prizma. Bu blog Uipath'a odaklanıyor.
UiPath ile NanoNet'ler
Önceki bölümlerimizde boru hattını anlamak için bir belge oluşturmayı öğrendik. Çeşitli noktalarda farklı görevler için farklı yaklaşımlar ve algoritmalar bulunduğundan, temel OCR, RPA'lar ve Makine öğrenimi bilgisi gerektirir. Ayrıca, şablonlarımızı anlayan, eğiten ve dağıtan Sinir Ağları oluşturmak için çok çaba harcamalıyız. Bu nedenle, rahat olmak ve belgeleri yüklemek, sınıflandırmak, OCR oluşturmak, makine öğrenimi modellerini entegre etmek kadar her şeyi otomatikleştirmek için Nanonets'te, Belge Anlama için sorunsuz bir ardışık düzen oluşturmak için Ui Yolu üzerinde çalışıyoruz. Aşağıda bunun nasıl çalıştığına dair bir resim var.

Şimdi bunların her birini gözden geçirelim ve Nanonetleri UiPath ile nasıl entegre edebileceğimizi öğrenelim.
Adım 1: UiPath'te Kaydolun ve UiPath Studio'yu İndirin
Bir iş akışı oluşturmak için önce UiPath'te bir hesap oluşturmamız gerekecek. Mevcut bir kullanıcıysanız, UiPath panonuzu yeniden yönlendirerek doğrudan hesabınıza giriş yapabilirsiniz. Ardından, ücretsiz olan UiPath Studio'yu (Community Edition) indirip yüklemeniz gerekecek.
2. Adım: Nanonet Bileşenini İndirin
Ardından, fatura işleme hattıNanonets Bağlayıcısını aşağıdaki bağlantıdan indirmeniz gerekecek.
-> NanoNets OCR - RPA Bileşeni
Aşağıda UiPath Marketplace ve Nanonets Bileşeninin bir ekran görüntüsü bulunmaktadır. Ayrıca, bunu indirmek için bir Windows işletim sisteminden UiPath'te oturum açtığınızdan emin olun.

İndirdiğiniz dosyalar aşağıda listelenen dosyaları içermelidir,
UiPath OCR Predict ├── Main.xaml
└── project.json
Adım 3: Main.xaml dosyasını Nanonets Bileşenini açın
Nanonets UiPath'in çalışıp çalışmadığını kontrol etmek için, Ui Path Studio'yu kullanarak indirilen Nanonets bileşeninden Main.xml dosyanızı açabilirsiniz. Ardından, belge işleme için sizin için önceden oluşturulmuş boru hattınızı görebilirsiniz.

4. Adım: Model Kimliğinizi, API Anahtarınızı ve API Uç Noktanızı Nanonets APP'sinden toplayın
Ardından, Nanonets APP'deki herhangi bir eğitimli OCR modelini kullanabilir ve Model Kimliği, API Anahtarı ve uç noktayı toplayabilirsiniz. Bunları hızlı bir şekilde bulmanız için aşağıda daha fazla ayrıntı bulunmaktadır.
Model Kimliği: Nanonets hesabınıza giriş yapın ve "Modellerim" e gidin. Yeni bir model eğitebilir veya mevcut bir modelin Uygulama Kimliğini kopyalayabilirsiniz.

API Uç Noktası: API uç noktanızı bulmak için mevcut herhangi bir modeli seçebilir ve Entegre Et'e tıklayabilirsiniz. Aşağıda uç noktalarınızın nasıl göründüğüne dair bir örnek verilmiştir.
https://app.nanonets.com/api/v2/OCR/Model/XXXXXXX-4840-4c27-8940-d3add200779e/LabelUrls/

3. API Anahtarı: API Anahtarı sekmesine gidin ve mevcut herhangi bir API Anahtarını kopyalayabilir veya yeni bir tane oluşturabilirsiniz.

Adım 5: Yönteminizi ve Değişkenlerinizi UI Yoluna almak için HTTP İsteği ekleyin
Şimdi Modelinizi Nanonetlerden UI Yoluna entegre etmek için, HTTP İsteğine ilk tıklamayı yapacaksınız ve Giriş bölümünde sol gezinme bölümünde bulunan EndPoint'i ekleyeceksiniz. Aşağıda bir ekran görüntüsü var.

Daha sonra, UiPath stüdyonuzdan Nanonets API'sine bir bağlantı kurmak için tüm değişkenlerinizi ekleyin. Bu bölümü alt bölmede "Değişkenler Sekmesi" nde bulabilirsiniz. Ekran görüntüsü aşağıdadır, API Anahtarınızı, Uç Noktanızı ve modelinizin Model Kimliğini burada güncellemeniz / kopyalamanız gerekir.

6. Adım: Tahminler için Dosya Konumu Ekleyin
Son olarak, aşağıdaki ekran görüntüsünde gösterildiği gibi dosya konumunuzu öznitelikler sekmesinin altına ekleyebilir ve çıktılarınızı tahmin etmek için üst gezinme bölümünüzdeki oynat düğmesine basabilirsiniz.

Voila! İşte aşağıdaki ekran görüntüsünde talep ettiğimiz belge için çıktılarımız. Daha fazlasını işlemek için dosya konumlarınızı ekleyebilir ve çalıştır düğmesine basabilirsiniz.

Adım 7 - Çıkışı CSV / ERP'ye Aktarın
Son olarak, çıktımızı istediğiniz formatta özelleştirmek için Main.XML dosyasındaki ardışık düzeninize yeni bloklar ekleyebiliriz. Bunu, çevrimdışı dosyalar veya API Çağrıları aracılığıyla mevcut herhangi bir ERP sistemine de aktarabiliriz.

Herhangi bir yardım için support@nanonets.com adresinden bizimle iletişime geçin.
Webinar

Önümüzdeki Salı RPA ile OCR'da yapılacak bir Webinar için bize katılın, Buraya kaydol.
Referanslar
[2] Belge Anlama - AI Belge İşleme
[3] RPA OCR - yükselen süreç otomasyonu | GÜZEL
[4] Belge Anlayışını Optimize Etmek İçin Yapay Zeka Nasıl Kullanılır
[5] https://www.uipath.com/product/document-understanding
[6] Fatura OCR'si için UiPath İş Akışında NanoNets'i Kullanma
Daha fazla Okuma
Son gönderilerimiz ilginizi çekebilir:
Güncelleme:
Belge anlamada OCR, RPA'nın kullanımı ve etkisi hakkında daha fazla okuma materyali eklendi.
Kaynak: https://nanonets.com/blog/ocr-with-rpa-and-document-understanding-uipath/
- '
- &
- 000
- 2021
- 7
- Hesap
- muhasebe
- Action
- avantaj
- AI
- algoritma
- algoritmalar
- Türkiye
- analiz
- api
- API'ler
- uygulamayı yükleyeceğiz
- Uygulama
- uygulamaları
- Sanat
- yapay zeka
- Yapay zeka (AI)
- Yapay Zeka ve Makine Öğrenimi
- Otomasyon
- her yerde otomasyon
- İYİ
- Biggest
- Blog
- Bot
- botlar
- inşa etmek
- bina
- iş
- Kameralar
- durumlarda
- Sebeb olmak
- neden
- karakter tanıma
- sınıflandırma
- bulut
- Bulut Platformu
- kod
- bilişsel
- Toplama
- yorumlar
- ortak
- topluluk
- Şirketler
- bileşen
- Bilgisayar görüşü
- güven
- içindekiler
- Düzeltmeler
- maliyetler
- gösterge paneli
- veri
- veri yönetimi
- anlaşma
- derin öğrenme
- Geliştirici
- geliştiriciler
- Cihaz
- dijital
- evraklar
- Atlatmak
- sürme
- Eğitim
- verim
- E-posta
- çalışanların
- Son nokta
- kuruluş
- vb
- veriyi çıkar
- çıkarma
- Özellikler(Hazırlık aşamasında)
- Özellikler
- Alanlar
- Nihayet
- maliye
- Ad
- odak
- Airdrop Formu
- biçim
- dolandırıcılık
- Ücretsiz
- gelecek
- Gartner
- genel
- gif
- Tercih Etmenizin
- rehberlik
- kullanma
- baş ağrısı
- okuyun
- Yüksek
- Ne kadar
- Nasıl Yapılır
- HTTPS
- Kocaman
- İnsanlar
- melez
- belirlemek
- görüntü
- darbe
- Artırmak
- bilgi
- bilgi
- bilgi çıkarma
- İstihbarat
- niyet
- sorunlar
- IT
- anahtar
- bilgi
- KYC
- dil
- son
- öncülük etmek
- önemli
- ÖĞRENİN
- öğrendim
- öğrenme
- seviye
- Kaldıraç
- Lisans
- Sınırlı
- LINK
- yerel
- yer
- makine öğrenme
- yönetim
- pazar
- çarşı
- Maç
- ölçmek
- Tüccar
- Metrikleri
- Microsoft
- ML
- model
- filmler
- Doğal lisan
- Doğal Dil İşleme
- Navigasyon
- ağlar
- sinirsel
- nöral ağlar
- nlp
- tebliğ
- sayılar
- OCR
- açık
- işletme
- işletim sistemi
- Operasyon
- optik karakter tanıma
- sipariş
- Diğer
- Diğer
- pasaport
- performans
- resim
- platform
- Popüler
- Mesajlar
- güç kelimesini seçerim
- Hassas
- Tahminler
- Proses Otomasyonu
- Programlar
- proje
- kalite
- yükseltmeler
- menzil
- RE
- Okuma
- azaltmak
- Sonuçlar
- yorum
- robot
- Robotik Proses Otomasyonu
- robotik
- robotlar
- rpa
- kurallar
- koşmak
- koşu
- özsu
- tasarruf
- ölçek
- tarama
- kazıma
- Ekran
- sorunsuz
- Satıcılar
- Dizi
- Hizmetler
- set
- Basit
- So
- Software
- Yazılım botları
- Çözümler
- ÇÖZMEK
- geçirmek
- başlama
- Eyalet
- Ders çalışma
- destek
- sistem
- Sistemler
- masa çıkarma
- Teknolojileri
- Teknoloji
- Gelecek
- zaman
- üst
- Eğitim
- ui
- UiPath
- Güncelleme
- us
- Amerika Birleşik Devletleri
- kullanımın söz
- kullanıcılar
- değer
- Karşı
- vizyonumuz
- ağ
- Webinar
- web siteleri
- DSÖ
- pencereler
- içinde
- İş
- iş akışı
- çalışır
- XML
- yıl
- Youtube