Editörün notu: Bu, tarım için yapay zeka odaklı araçlar geliştiren Güney Afrikalı bir girişim olan Aerobotics'te Veri Başkanı Michael Malahe tarafından yazılan bir konuk gönderisidir.
Aerobotics, Güney Afrika, Cape Town merkezli, dünya çapında 18 ülkede faaliyet gösteren bir tarım teknolojisi şirketidir. Misyonumuz, dünyayı beslemek için akıllı araçlar sağlamaktır. Bunu, yetiştirme sezonunda doğru zamanda gerekli müdahaleleri yapabilmeleri için platformumuz Aeroview'de çiftçilere eyleme geçirilebilir veriler ve içgörüler sağlayarak başarmayı amaçlıyoruz. Baskın veri kaynağımız havadan insansız hava aracı görüntüleridir: bir meyve bahçesindeki ağaçların ve meyvelerin görsel ve multispektral görüntülerini yakalar.
Bu yazıda nasıl kullandığımıza bakıyoruz Amazon Adaçayı Yapıcı ve TensorFlow, gölgelik alanı ve sağlık gibi önemli miktarlarda ağaç başına ölçümler sağlayan ve ölü ve eksik ağaçların konumlarını sağlayan Tree Insights ürünümüzü geliştirmek için. Çiftçiler bu bilgileri sulama hatlarını sabitlemek, değişken oranlarda gübre uygulamak ve yedek ağaç siparişi vermek gibi hassas müdahaleler yapmak için kullanır. Aşağıda, çiftçilerin ağaçlarının sağlığını anlamak ve bu kararlardan bazılarını almak için kullandıkları aracın bir görüntüsü yer almaktadır.

Bu kararları vermek üzere bu bilgileri sağlamak için, öncelikle her bir ön plan pikselini tek bir benzersiz ağaca doğru bir şekilde atamalıyız. Bu örnek segmentasyon görevi için olabildiğince doğru olmamız önemlidir, bu nedenle büyük ölçekli karşılaştırmalarda etkili olan bir makine öğrenimi (ML) modeli kullanıyoruz. Model şunun bir çeşididir: Maske R-CNN, özellik çıkarma için bir evrişimli sinir ağını (CNN) algılama, sınıflandırma ve bölümleme için birkaç ek bileşenle eşleştirir. Aşağıdaki görüntüde, belirli bir ağaca ait piksellerin bir konturla özetlendiği bazı tipik çıktıları gösteriyoruz.

Çıktılara baktığınızda, sorunun çözüldüğünü düşünebilirsiniz.
Meydan okuma
Tarımsal verileri analiz etme ve modellemedeki temel zorluk, çeşitli boyutlarda oldukça çeşitli olmasıdır.
Aşağıdaki görüntü, ağaçların boyutundaki varyasyonun bazı uçlarını ve bunların net bir şekilde ayrılabilme derecesini göstermektedir.

Ceviz ağaçları korusunda, veri tabanımızdaki en büyük ağaçlardan biri 654 mXNUMX'dir.2 (tipik bir hızda dolaşmak için bir dakikadan biraz fazla). Korunun sağındaki sarmaşıklar 50 cm genişliğindedir (tipik bir saksı bitkisinin boyutu). Ölçekten bağımsız olarak doğru segmentasyonlar sağlamak için modellerimizin bu varyasyonlara toleranslı olması gerekir.
Ek bir zorluk, varyasyon kaynaklarının statik olmamasıdır. Çiftçiler son derece yenilikçidir ve en iyi uygulamalar zaman içinde önemli ölçüde değişebilir. Bir örnek, ağaçların birbirine bir ayak kadar yakın dikildiği, elma için ultra yüksek yoğunluklu ekimdir. Bir diğeri, aşağıdaki görüntüde olduğu gibi havadan görüntüleri gizleyen koruyucu ağların benimsenmesidir.

Geniş ve değişen varyasyonların olduğu bu alanda, müşterilerimize güvenilir içgörüler sağlamak için doğru modeller sürdürmemiz gerekiyor. Modeller karşılaştığımız her zorlu yeni örnekle gelişmeli ve onları güvenle dağıtmalıyız.
Bu zorluğa ilk yaklaşımımızda, sahip olduğumuz tüm veriler üzerinde eğitim aldık. Bununla birlikte, ölçeklenirken, tüm verilerimiz üzerinde eğitimin gerçekleştirilemez hale geldiği noktaya çabucak geldik ve bunu yapmanın maliyeti, deneyler için bir engel haline geldi.
çözüm
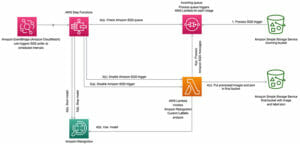
Uç vakalarda farklılıklar olmasına rağmen, standart vakalarımızda çok fazla fazlalık olduğunu fark ettik. Amacımız, modellerimizin yalnızca en dikkat çekici veriler üzerinde eğitildiği ve her örneği görmeye gerek kalmadan birleşebileceği bir noktaya gelmekti. Bunu başarmaya yönelik yaklaşımımız, ilk önce veri kümesi oluşturma ve örnekleme için farklı yaklaşımlarla deney yapmanın basit olduğu bir ortam yaratmaktı. Aşağıdaki diyagram, bunu sağlayan veri ön işleme için genel iş akışımızı göstermektedir.

Sonuç, eğitim örneklerinin bireysel dosyalar olarak mevcut olmasıdır. Amazon Basit Depolama Hizmeti (Amazon S3), çokbantlı görüntüler gibi büyük verilerle, referanslar ve depolanmış zengin meta verilerle ilgisi Amazon Kırmızıya Kaydırma tablolar. Bu, veri kümelerini tek bir sorgu ile oluşturmayı önemsiz hale getirir ve tren zamanında rastgele erişim modelleriyle ayrı örneklerin alınmasını mümkün kılar. Kullanırız BOŞALT Amazon S3'te değişmez bir veri kümesi oluşturmak için ve bizim dosyamızdaki dosyaya bir referans oluşturuyoruz. Amazon İlişkisel Veritabanı Hizmeti Eğitim kaynağı ve değerlendirme sonucu takibi için kullandığımız (Amazon RDS) veritabanı. Aşağıdaki koda bakın:
Kutucuk meta verilerini sorgulama kolaylığı, verilerimizin alt kümelerini hızla oluşturmamıza ve test etmemize olanak tanıdı ve sonunda toplam 1.1 milyondan yalnızca 3.1 milyon örnek gördükten sonra yakınsama için eğitim alabildik. Bu alt çağ yakınsaması, işlem maliyetlerimizi düşürmede çok faydalı oldu ve bu arada verilerimizi daha iyi anladık.
Eğitim maliyetlerimizi düşürmek için attığımız ikinci adım, bilgi işlemimizi optimize etmekti. Kullandık TensorFlow profil oluşturucu bu adımda yoğun bir şekilde:
Eğitim için kullanıyoruz Amazon Adaçayı Yapıcı tarafından sağlanan P3 örnekleriyle Amazon Elastik Bilgi İşlem Bulutu (Amazon EC2) ve başlangıçta örneklerdeki NVIDIA Tesla V100 GPU'ların şişirildiğini gördük
giriş hattındaki CPU hesaplaması tarafından kontrol edilir. Darboğazın hafifletilmesine yönelik genel model, verimli iş parçacığı paralelliği sağlamak için hesaplamanın çoğunu yerel Python kodundan TensorFlow işlemlerine mümkün olduğunca kaydırmaktı. En büyük fayda şuna geçmekti: tf.io Verimi% 41 artıran veri toplama ve seriyi kaldırma için. Aşağıdaki koda bakın:
Bu yaklaşımın bir bonus özelliği, yerel dosyalar ile Amazon S3 depolaması arasında geçiş yapmanın, tarafından sağlanan dosya nesnesi soyutlaması nedeniyle hiçbir kod değişikliği gerektirmemesiydi. Dosya.
Kalan son darboğazın, varsayılan TensorFlow CPU paralellik ayarlarından geldiğini bulduk. SageMaker hiperparametre ayarlama işi (aşağıdakilere bakın örnek yapılandırma).
CPU darboğazı kaldırıldığında, GPU optimizasyonuna geçtik ve karışık hassasiyet eğitimi kullanarak V100'ün Tensor Çekirdeklerinden en iyi şekilde yararlandık:
The karışık hassasiyet kılavuzu sağlam bir referanstır, ancak karışık kesinlik kullanımına geçiş, yarı hassasiyette gerçekleşen işlemlerin kötü koşullandırılmamasını veya yetersiz kalmamasını sağlamak için yine de biraz dikkatli olmayı gerektirir. Kritik olan bazı özel durumlar, uçbirim etkinleştirmeleri ve özel düzenleme terimleriydi. Aşağıdaki koda bakın:
Bunu uyguladıktan sonra, tek bir V100 için aşağıdaki karşılaştırma sonuçlarını ölçtük.
| Hassas | CPU paralelliği | Parti boyutu | Saniyede örnek |
| tek | varsayılan | 8 | 9.8 |
| karışık | varsayılan | 16 | 19.3 |
| karışık | optimize | 16 | 22.4 |
Karışık hassasiyete geçmenin etkisi, eğitim hızının kabaca iki katına çıkması ve SageMaker tarafından keşfedilen optimum CPU paralellik ayarlarını kullanmanın etkisinin% 16'lık ek bir artış olmasıydı.
Büyüdükçe bu girişimleri uygulamak, bir modelin eğitim maliyetini 122 dolardan 68 dolara düşürürken, veri kümemiz 228 bin örnekten 3.1 milyona çıktı ve örnek başına maliyette 24 kat azalma sağladı.
Sonuç
Eğitim süresi ve maliyetindeki bu azalma, veri dağıtımımızdaki değişikliklere hızlı ve ucuz bir şekilde adapte olabileceğimiz anlamına geldi. Aşağıdaki resim gibi sık sık insanlar için bile kafa karıştıran yeni vakalarla karşılaşıyoruz.

Bununla birlikte, aşağıdaki resimde gösterildiği gibi, modellerimiz için hızla standart durumlar haline gelirler.

Daha fazla cihaz kullanarak eğitimi hızlandırmaya devam etmeyi ve yararlanarak daha verimli hale getirmeyi hedefliyoruz. SageMaker yönetti Spot Örnekleri. Ayrıca, çevrimiçi öğrenme yeteneğine sahip SageMaker modelleri sunarak eğitim döngüsünü daha sıkı hale getirmeyi hedefliyoruz, böylece geliştirilmiş modeller neredeyse gerçek zamanlı olarak kullanılabilir. Bunları yerine getirdiğimizde, tarımın bize getirebileceği tüm çeşitlilikle başa çıkmak için iyi donanımlı olmalıyız. Amazon SageMaker hakkında daha fazla bilgi edinmek için şu adresi ziyaret edin: Ürün sayfası.
Bu gönderideki içerik ve görüşler üçüncü taraf yazara aittir ve AWS bu gönderinin içeriğinden veya doğruluğundan sorumlu değildir.
Yazar Hakkında
Michael Malahe tarım için yapay zeka odaklı araçlar geliştiren Güney Afrikalı bir girişim olan Aerobotics'te Veri Başkanı.
- erişim
- Ek
- Benimseme
- Afrika
- Afrika
- tarım
- Amazon
- Amazon EC2
- Amazon Adaçayı Yapıcı
- ALAN
- etrafında
- AWS
- kıyaslama
- İYİ
- en iyi uygulamalar
- Gölgelik
- durumlarda
- meydan okuma
- değişiklik
- sınıflandırma
- istemciler
- CNN
- kod
- şirket
- hesaplamak
- güven
- kas kütlesi inşasında ve
- içerik
- devam etmek
- evrişimli sinir ağı
- maliyetler
- ülkeler
- veri
- veritabanı
- ölü
- Bulma
- Cihaz
- keşfetti
- vızıldamak
- kenar
- Etkili
- çevre
- deneme
- çıkarma
- çiftçiler
- Özellikler(Hazırlık aşamasında)
- Ad
- biçim
- GPU
- GPU'lar
- Büyüyen
- Konuk
- Misafir Mesaj
- baş
- Sağlık
- Ne kadar
- HTTPS
- İnsanlar
- görüntü
- darbe
- Artırmak
- bilgi
- anlayışlar
- IT
- keras
- ÖĞRENİN
- öğrenme
- yerel
- makine öğrenme
- Yapımı
- ölçmek
- milyon
- Misyonumuz
- karışık
- ML
- model
- Modelleme
- ağ
- sinirsel
- sinir ağı
- Nvidia
- Online
- Çevrimiçi öğrenme
- işletme
- Operasyon
- Görüşler
- model
- piksel
- platform
- politika
- Hassas
- PLATFORM
- Koruyucu
- Python
- oranlar
- Sonuçlar
- sagemaker
- ölçek
- servis
- çalışma
- Basit
- beden
- So
- güney
- Güney Afrika
- hız
- başlangıç
- hafızası
- tensorflow
- Tesla
- test
- zaman
- Takip
- Eğitim
- us
- W
- iş akışı
- Dünya
- X