Amazon Adaçayı Yapıcı tamamen yönetilen bir makine öğrenimi (ML) hizmetidir. SageMaker ile veri bilimcileri ve geliştiriciler, makine öğrenimi modellerini hızlı ve kolay bir şekilde oluşturup eğitebilir ve ardından bunları üretime hazır barındırılan bir ortama doğrudan dağıtabilir. Keşif ve analiz için veri kaynaklarınıza kolay erişim için entegre bir Jupyter yazma not defteri örneği sağlar, böylece sunucuları yönetmenize gerek kalmaz. Ayrıca ortak sağlar ML algoritmaları dağıtılmış bir ortamda son derece büyük verilere karşı verimli çalışacak şekilde optimize edilmiştir.
SageMaker gerçek zamanlı çıkarımı, gerçek zamanlı, etkileşimli, düşük gecikmeli gereksinimleri olan iş yükleri için idealdir. SageMaker gerçek zamanlı çıkarım ile, belirli bir miktarda bilgi işlem ve belleğe sahip belirli bir örnek türü tarafından desteklenen REST uç noktalarını konuşlandırabilirsiniz. Bir SageMaker gerçek zamanlı uç noktasını devreye almak, birçok müşteri için üretim yolundaki yalnızca ilk adımdır. Gecikme gereksinimlerine bağlı kalarak saniye başına işlem (TPS) hedefine ulaşmak için uç noktanın performansını en üst düzeye çıkarmak istiyoruz. Çıkarım için performans optimizasyonunun büyük bir kısmı, uygun bulut sunucusu tipini seçtiğinizden ve bir uç noktayı geriye doğru saydığınızdan emin olmaktır.
Bu gönderi, örnek sayısı ve boyut için doğru yapılandırmayı bulmak üzere bir SageMaker uç noktasının yük testi için en iyi uygulamaları açıklamaktadır. Bu, gecikme ve TPS gereksinimlerimizi karşılamak için sağlanan minimum örnek gereksinimlerini anlamamıza yardımcı olabilir. Buradan, SageMaker uç noktasının metriklerini ve performansını nasıl takip edebileceğinizi ve anlayabileceğinizi inceleyeceğiz. Amazon Bulut İzleme ölçütler.
Kabul edilebilir gecikme gereksinimlerimize göre işleyebileceği TPS'yi belirlemek için önce modelimizin performansını tek bir eşgörünüm üzerinde kıyaslarız. Ardından, üretim trafiğimizi yönetmek için ihtiyaç duyduğumuz örnek sayısına karar vermek için bulguları tahmin ediyoruz. Son olarak, üretim düzeyindeki trafiği simüle ediyoruz ve uç noktamızın üretim düzeyindeki yükü kaldırabileceğini doğrulamak için gerçek zamanlı bir SageMaker uç noktası için yük testleri kuruyoruz. Örnek için tüm kod seti aşağıda mevcuttur. GitHub deposu.
Çözüme genel bakış
Bu gönderi için, önceden eğitilmiş bir Sarılma Yüz DistilBERT modeli itibaren sarılma yüz hub. Bu model bir dizi görevi gerçekleştirebilir, ancak özellikle duygu analizi ve metin sınıflandırması için bir yük göndeririz. Bu örnek yük ile 1000 TPS'ye ulaşmaya çalışıyoruz.
Gerçek zamanlı bir uç nokta dağıtın
Bu gönderi, bir modelin nasıl konuşlandırılacağını bildiğinizi varsayar. bakın Uç noktanızı oluşturun ve modelinizi dağıtın bir uç noktayı barındırmanın ardındaki dahili unsurları anlamak için. Şimdilik, Hugging Face Hub'da bu modeli hızlı bir şekilde işaret edebilir ve aşağıdaki kod parçasıyla gerçek zamanlı bir uç nokta konuşlandırabiliriz:
Yük testi için kullanmak istediğimiz örnek yük ile uç noktamızı hızlı bir şekilde test edelim:

Son noktayı tek bir kullanarak desteklediğimizi unutmayın. Amazon Elastik Bilgi İşlem Bulutu (Amazon EC2) 5.12 vCPU ve 48 GiB bellek içeren ml.m192xlarge tipi bulut sunucusu. vCPU'ların sayısı, örneğin işleyebileceği eşzamanlılığın iyi bir göstergesidir. Genel olarak, uygun şekilde kullanılan kaynaklara sahip bir bulut sunucumuz olduğundan emin olmak için farklı bulut sunucusu türlerini test etmeniz önerilir. Gerçek zamanlı Çıkarım için SageMaker örneklerinin tam listesini ve bunlara karşılık gelen işlem gücünü görmek için bkz. Amazon SageMaker Fiyatlandırması.
İzlenecek metrikler
Yük testine başlamadan önce, SageMaker uç noktanızın performans dökümünü anlamak için hangi ölçümleri izlememiz gerektiğini anlamamız önemlidir. CloudWatch, uç noktanızın performansını açıklayan farklı ölçümleri anlamanıza yardımcı olmak için SageMaker'ın kullandığı birincil günlük kaydı aracıdır. Uç nokta çağrılarınızda hata ayıklamak için CloudWatch günlüklerini kullanabilirsiniz; çıkarım kodunuzdaki tüm günlük kaydı ve yazdırma ifadeleri burada yakalanır. Daha fazla bilgi için bkz. Amazon CloudWatch nasıl çalışır?.
CloudWatch'ın SageMaker için kapsadığı iki farklı ölçüm türü vardır: örnek düzeyi ve çağırma ölçümleri.
Örnek düzeyinde metrikler
Dikkate alınması gereken ilk parametre grubu, örnek düzeyindeki metriklerdir: CPUUtilization ve MemoryUtilization (GPU tabanlı örnekler için, GPUUtilization). İçin CPUUtilization, CloudWatch'ta ilk başta %100'ün üzerinde yüzdeler görebilirsiniz. için farkına varmak önemlidir CPUUtilization, tüm CPU çekirdeklerinin toplamı görüntüleniyor. Örneğin, uç noktanızın arkasındaki örnek 4 vCPU içeriyorsa bu, kullanım aralığının %400'e kadar olduğu anlamına gelir. MemoryUtilizationise %0-100 aralığındadır.
Özellikle, kullanabilirsiniz CPUUtilization yeterli veya fazla miktarda donanıma sahip olup olmadığınızı daha iyi anlamak için. Yeterince kullanılmayan bir örneğiniz varsa (%30'dan az), bulut sunucusu türünüzü potansiyel olarak küçültebilirsiniz. Tersine, yaklaşık %80-90 kullanım oranınız varsa, daha fazla bilgi işlem/belleğe sahip bir bulut sunucusu seçmek faydalı olacaktır. Testlerimizden, donanımınızın yaklaşık %60-70 oranında kullanılmasını öneriyoruz.
Çağrı metrikleri
Adından da anlaşılacağı gibi, çağrı ölçümleri, uç noktanıza yapılan herhangi bir çağrının uçtan uca gecikmesini izleyebileceğimiz yerdir. Uç noktanızın karşılaşıyor olabileceği hata sayılarını ve ne tür hataları (5xx, 4xx vb.) yakalamak için çağırma ölçümlerini kullanabilirsiniz. Daha da önemlisi, uç nokta aramalarınızın gecikme dökümünü anlayabilirsiniz. Bunun çoğu ile yakalanabilir ModelLatency ve OverheadLatency aşağıdaki diyagramda gösterildiği gibi metrikler.

The ModelLatency metrik, bir SageMaker uç noktasının arkasındaki model kapsayıcısı içinde çıkarımın aldığı süreyi yakalar. Model kabının, çıkarım için ilettiğiniz tüm özel çıkarım kodlarını veya komut dosyalarını da içerdiğini unutmayın. Bu birim, bir başlatma ölçümü olarak mikrosaniye cinsinden kaydedilir ve hedef gecikmenizi karşılayıp karşılamadığınızı görmek için genellikle CloudWatch genelinde bir yüzdelik dilim (p99, p90 vb.) grafiği çizebilirsiniz. Aşağıdakiler gibi çeşitli faktörlerin model ve kapsayıcı gecikmesini etkileyebileceğini unutmayın:
- Özel çıkarım komut dosyası – İster kendi kapsayıcınızı uygulamış olun, ister özel çıkarım işleyicileri ile SageMaker tabanlı bir kapsayıcı kullanmış olun, özellikle gecikmenize çok fazla zaman katan tüm işlemleri yakalamak için betiğinizin profilini çıkarmak en iyi uygulamadır.
- Iletişim protokolü – Model kapsayıcısı içindeki model sunucusuna REST ve gRPC bağlantılarını göz önünde bulundurun.
- Model çerçevesi optimizasyonları – Bu çerçeveye özeldir, örneğin TensorFlowTF Sunumuna özel ayarlayabileceğiniz bir dizi ortam değişkeni vardır. Hangi kabı kullandığınızı kontrol ettiğinizden emin olun ve betik içine veya kapsayıcıya enjekte edilecek ortam değişkenleri olarak ekleyebileceğiniz çerçeveye özgü optimizasyonlar varsa.
OverheadLatency SageMaker'ın isteği aldığı andan müşteriye bir yanıt döndürene kadar olan süre eksi model gecikmesi ile ölçülür. Bu kısım büyük ölçüde kontrolünüz dışındadır ve SageMaker genel giderlerinin aldığı sürenin altına düşer.
Bir bütün olarak uçtan uca gecikme, çeşitli faktörlere bağlıdır ve bunların toplamı olmak zorunda değildir. ModelLatency artı OverheadLatency. Örneğin, müşteriniz yapıyorsa InvokeEndpoint Müşterinin bakış açısından internet üzerinden API çağrısı, uçtan uca gecikme internet + ModelLatency + OverheadLatency. Bu nedenle, uç noktanın kendisini doğru bir şekilde kıyaslamak için uç noktanızı yük testi yaparken, uç nokta metriklerine odaklanmanız önerilir (ModelLatency, OverheadLatency, ve InvocationsPerInstance) SageMaker uç noktasını doğru bir şekilde karşılaştırmak için. Uçtan uca gecikmeyle ilgili tüm sorunlar daha sonra ayrı ayrı izole edilebilir.
Uçtan uca gecikme için dikkate alınması gereken birkaç soru:
- Uç noktanızı çağıran müşteri nerede?
- İstemciniz ile SageMaker çalışma zamanı arasında herhangi bir aracı katman var mı?
Otomatik ölçeklendirme
Bu gönderide özellikle otomatik ölçeklendirmeyi ele almıyoruz, ancak iş yüküne göre doğru sayıda örnek sağlamak için bu önemli bir husustur. Trafik düzeninize bağlı olarak bir otomatik ölçeklendirme politikası SageMaker uç noktanıza. gibi farklı ölçeklendirme seçenekleri vardır. TargetTrackingScaling, SimpleScaling, ve StepScaling. Bu, uç noktanızın trafik düzeninize göre otomatik olarak ölçeklenip küçülmesine olanak tanır.
Yaygın bir seçenek, tanımladığınız bir CloudWatch metriğini veya özel metriğini belirtebileceğiniz ve buna göre ölçeklendirebileceğiniz hedef izlemedir. Otomatik ölçeklendirmenin sık kullanımı, InvocationsPerInstance metrik. Belirli bir TPS'de bir darboğaz belirledikten sonra, trafiğin yoğun yüklerini kaldırabilmek için ölçeği daha fazla sayıda örneğe ölçeklendirmek için genellikle bunu bir ölçüm olarak kullanabilirsiniz. Otomatik ölçeklendirme SageMaker uç noktalarının daha ayrıntılı bir dökümünü almak için bkz. Amazon SageMaker'da otomatik ölçeklendirme çıkarım uç noktalarını yapılandırma.
Yük testi
Testi uygun ölçekte nasıl yükleyebileceğimizi göstermek için Locust'u kullanmamıza rağmen, uç noktanızın arkasındaki örneği doğru boyutlandırmaya çalışıyorsanız, SageMaker Çıkarım Öneri Aracı daha verimli bir seçenektir. Üçüncü taraf yük testi araçlarıyla, uç noktaları farklı örnekler arasında manuel olarak dağıtmanız gerekir. Çıkarım Tavsiye Edici ile, test yüklemek istediğiniz bir örnek türleri dizisini kolayca iletebilirsiniz ve SageMaker hızla çalışmaya başlar iş fırsatları bu örneklerin her biri için.
keçiboynuzu
Bu örnek için kullandığımız keçiboynuzu, Python kullanarak uygulayabileceğiniz açık kaynaklı bir yük testi aracı. Locust, diğer birçok açık kaynaklı yük testi aracına benzer, ancak birkaç özel avantajı vardır:
- Kolay kurulum – Bu gönderide gösterdiğimiz gibi, özel uç noktanız ve yükünüz için kolayca yeniden düzenlenebilen basit bir Python betiğini ileteceğiz.
- Dağıtılmış ve ölçeklenebilir – Locust olay tabanlıdır ve kullanır gecekondu kaputun altında. Bu, yüksek oranda eşzamanlı iş yüklerini test etmek ve binlerce eşzamanlı kullanıcıyı simüle etmek için çok kullanışlıdır. Locust çalıştıran tek bir işlemle yüksek TPS elde edebilirsiniz, ancak aynı zamanda dağıtılmış yük oluşturma Bu gönderide inceleyeceğimiz gibi, ölçeği birden çok işleme ve istemci makineye ölçeklendirmenizi sağlayan özellik.
- Çekirge metrikleri ve kullanıcı arabirimi – Locust ayrıca uçtan uca gecikmeyi bir ölçüm olarak yakalar. Bu, testlerinizin tam bir resmini çizmek için CloudWatch ölçümlerinizi tamamlamanıza yardımcı olabilir. Tüm bunlar, eşzamanlı kullanıcıları, çalışanları ve daha fazlasını izleyebileceğiniz Locust kullanıcı arayüzünde yakalanır.
Locust'u daha iyi anlamak için, belgeleme.
Amazon EC2 kurulumu
Locust'u sizin için uygun olan herhangi bir ortamda kurabilirsiniz. Bu gönderi için bir EC2 bulut sunucusu kurduk ve testlerimizi gerçekleştirmek için Locust'u oraya kuruyoruz. Bir c5.18xlarge EC2 bulut sunucusu kullanıyoruz. İstemci tarafı bilgi işlem gücü de dikkate alınması gereken bir şeydir. İstemci tarafında bilgi işlem gücünüzün tükendiği zamanlarda, bu genellikle yakalanmaz ve yanlışlıkla bir SageMaker uç nokta hatası olarak algılanır. İstemcinizi, test ettiğiniz yükü kaldırabilecek yeterli bilgi işlem gücüne sahip bir konuma yerleştirmeniz önemlidir. EC2 bulut sunucumuz için bir Ubuntu Derin Öğrenme AMI kullanıyoruz, ancak makinede Locust'u düzgün bir şekilde kurabildiğiniz sürece herhangi bir AMI'yi kullanabilirsiniz. EC2 bulut sunucunuzu nasıl başlatacağınızı ve ona nasıl bağlanacağınızı anlamak için öğreticiye bakın. Amazon EC2 Linux bulut sunucularını kullanmaya başlayın.
Locust UI'ye 8089 numaralı bağlantı noktasından erişilebilir. EC2 Örneği için gelen güvenlik grubu kurallarımızı ayarlayarak bunu açabiliriz. EC22 bulut sunucusuna SSH yapabilmemiz için 2 numaralı bağlantı noktasını da açıyoruz. Kaynağın kapsamını EC2 bulut sunucusuna erişmekte olduğunuz belirli IP adresine göre belirlemeyi düşünün.

EC2 bulut sunucunuza bağlandıktan sonra, bir Python sanal ortamı kuruyoruz ve CLI aracılığıyla açık kaynaklı Locust API'sini yüklüyoruz:
Artık uç noktamızın yük testi için Locust ile çalışmaya hazırız.
Çekirge testi
Tüm Locust yük testleri, bir Çekirge dosyası sağladığınız Bu Locust dosyası, yük testi için bir görev tanımlar; burası Boto3'ümüzü tanımladığımız yer invoke_endpoint API çağrısı. Aşağıdaki koda bakın:
Önceki kodda, invoke uç nokta çağrı parametrelerinizi özel model başlatmanıza uyacak şekilde ayarlayın. biz kullanıyoruz InvokeEndpoint Locust dosyasında aşağıdaki kod parçasını kullanan API; bu bizim yük testi çalıştırma noktamızdır. Kullandığımız Locust dosyası locust_script.py.
Artık Locust komut dosyamız hazır olduğuna göre, örneğimizin ne kadar trafiği kaldırabileceğini öğrenmek için tek örneğimizi stres testi yapmak üzere dağıtılmış Locust testleri yapmak istiyoruz.
Locust dağıtılmış mod, tek işlemli Locust testinden biraz daha inceliklidir. Dağıtılmış modda, bir birincil ve birden çok çalışanımız var. Birincil çalışan, çalışanlara istek gönderen eşzamanlı kullanıcıları nasıl oluşturacakları ve kontrol edecekleri konusunda talimat verir. bizim dağıtılmış.sh komut dosyasında, varsayılan olarak 240 kullanıcının 60 çalışana dağıtılacağını görüyoruz. Not --headless Locust CLI'deki bayrak, Locust'un UI özelliğini kaldırır.
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
Dağıtılmış testi önce uç noktayı destekleyen tek bir örnek üzerinde çalıştırıyoruz. Buradaki fikir, gecikme gereksinimlerimiz dahilinde kalırken hedef TPS'mize ulaşmak için ihtiyaç duyduğumuz örnek sayısını anlamak için tek bir örneği tamamen en üst düzeye çıkarmak istiyoruz. Kullanıcı arayüzüne erişmek istiyorsanız, Locust_UI ortam değişkenini True yapın ve EC2 bulut sunucunuzun genel IP'sini alın ve 8089 numaralı bağlantı noktasını URL ile eşleyin.
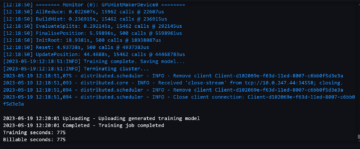
Aşağıdaki ekran görüntüsü CloudWatch ölçümlerimizi göstermektedir.

Sonunda, başlangıçta 200 TPS elde etmemize rağmen, aşağıdaki ekran görüntüsünde gösterildiği gibi EC5 istemci tarafı günlüklerimizde 2xx hataları fark etmeye başladığımızı fark ettik.
Bunu, örnek düzeyindeki ölçümlerimize bakarak da doğrulayabiliriz, özellikle CPUUtilization.
 Burada fark ediyoruz
Burada fark ediyoruz CPUUtilization yaklaşık %4,800'de. ml.m5.12x.large örneğimizde 48 vCPU vardır (48 * 100 = 4800~). Bu, tüm örneği doyuruyor ve bu da 5xx hatalarımızı açıklamaya yardımcı oluyor. artışı da görüyoruz. ModelLatency.
Görünüşe göre tek örneğimiz devriliyor ve gözlemlediğimiz 200 TPS'yi geçen bir yükü sürdürecek hesaplamaya sahip değil. Hedef TPS 1000, o halde instance sayımızı 5'e çıkarmaya çalışalım. Üretim ortamında bu daha da fazla olmalı çünkü belli bir noktadan sonra 200 TPS'de hatalar gözlemliyorduk.

Hem Locust UI hem de CloudWatch günlüklerinde, uç noktayı destekleyen beş örnekle yaklaşık 1000 TPS'ye sahip olduğumuzu görüyoruz.

 Bu donanım kurulumuna rağmen hata almaya başlarsanız mutlaka izleyin.
Bu donanım kurulumuna rağmen hata almaya başlarsanız mutlaka izleyin. CPUUtilization uç nokta barındırma hizmetinizin arkasındaki tüm resmi anlamak için. Büyütmeniz mi yoksa küçültmeniz mi gerektiğini görmek için donanım kullanımınızı anlamak çok önemlidir. Bazen kapsayıcı düzeyindeki sorunlar 5xx hatalarına yol açar, ancak eğer CPUUtilization düşükse, donanımınız değil, kapsayıcı veya model düzeyindeki bir şeyin bu sorunlara yol açabileceğini gösterir (örneğin, çalışan sayısı için uygun ortam değişkeni ayarlanmamış). Öte yandan, bulut sunucunuzun tamamen doyduğunu fark ederseniz, bu, ya mevcut bulut sunucusu filonuzu artırmanız ya da daha küçük bir filo ile daha büyük bir bulut sunucusunu denemeniz gerektiğinin bir işaretidir.
5 TPS'yi işlemek için örnek sayısını 100'e çıkarmamıza rağmen, ModelLatency metrik hala yüksek. Bu, örneklerin doygunluğundan kaynaklanmaktadır. Genel olarak, bulut sunucusunun kaynaklarını %60-70 arasında kullanmayı hedeflemenizi öneririz.
Temizlemek
Yük testinden sonra, kullanmayacağınız tüm kaynakları SageMaker konsolu veya silme_bitiş noktası Boto3 API çağrısı. Ek olarak, EC2 bulut sunucunuzu veya hangi istemci kurulumunuz varsa durdurduğunuzdan emin olun ki burada da başka ücret ödemeyin.
Özet
Bu gönderide, SageMaker gerçek zamanlı uç noktanızı nasıl yük testi yapabileceğinizi açıkladık. Performans dökümünüzü anlamak için uç noktanızı yük testi yaparken hangi ölçümleri değerlendirmeniz gerektiğini de ele aldık. kontrol ettiğinizden emin olun SageMaker Çıkarım Öneri Aracı örnek doğru boyutlandırma ve daha fazla performans optimizasyonu tekniğini daha iyi anlamak için.
Yazarlar Hakkında
 Marc Karp SageMaker Servis ekibine sahip bir ML Mimarıdır. Müşterilerin ML iş yüklerini uygun ölçekte tasarlamasına, dağıtmasına ve yönetmesine yardımcı olmaya odaklanıyor. Boş zamanlarında seyahat etmekten ve yeni yerler keşfetmekten hoşlanır.
Marc Karp SageMaker Servis ekibine sahip bir ML Mimarıdır. Müşterilerin ML iş yüklerini uygun ölçekte tasarlamasına, dağıtmasına ve yönetmesine yardımcı olmaya odaklanıyor. Boş zamanlarında seyahat etmekten ve yeni yerler keşfetmekten hoşlanır.
 Ram Vegiraju SageMaker Servis ekibine sahip bir ML Mimarıdır. Müşterilerin AI/ML çözümlerini Amazon SageMaker'da oluşturmasına ve optimize etmesine yardımcı olmaya odaklanıyor. Boş zamanlarında seyahat etmeyi ve yazmayı sever.
Ram Vegiraju SageMaker Servis ekibine sahip bir ML Mimarıdır. Müşterilerin AI/ML çözümlerini Amazon SageMaker'da oluşturmasına ve optimize etmesine yardımcı olmaya odaklanıyor. Boş zamanlarında seyahat etmeyi ve yazmayı sever.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- Yapabilmek
- yukarıdaki
- kabul edilebilir
- erişim
- ulaşılabilir
- erişme
- tam olarak
- Başarmak
- karşısında
- ilave
- adres
- Sonra
- karşı
- AI / ML
- hedefleyen
- Türkiye
- veriyor
- Rağmen
- Amazon
- Amazon EC2
- Amazon Adaçayı Yapıcı
- miktar
- analiz
- ve
- api
- etrafında
- Dizi
- iliştirmek
- yazma
- Oto
- otomatik olarak
- mevcut
- AWS
- Arka
- arka çıkılmış
- destek
- merkezli
- Çünkü
- arkasında
- olmak
- kıyaslama
- yarar
- faydaları
- İYİ
- en iyi uygulamalar
- arasında
- vücut
- Arıza
- inşa etmek
- C + +
- çağrı
- aramalar
- Alabilirsin
- ele geçirmek
- yakalar
- Yakalamak
- belli
- değişiklik
- yükler
- Kontrol
- sınıf
- sınıflandırma
- müşteri
- kod
- ortak
- uyumlu
- hesaplamak
- eşzamanlı
- Davranış
- yapılandırma
- Onaylamak
- Sosyal medya
- bağlı
- Bağlantılar
- Düşünmek
- dikkate
- konsolos
- Konteyner
- içeren
- bağlam
- kontrol
- uyan
- olabilir
- kapak
- kapaklar
- işlemci
- yaratmak
- çok önemli
- akım
- görenek
- Müşteriler
- veri
- derin
- derin öğrenme
- derin
- Varsayılan
- tanımlar
- göstermek
- bağlı
- bağlıdır
- dağıtmak
- dağıtma
- tanımlamak
- tarif edilen
- Dizayn
- geliştiriciler
- farklı
- direkt olarak
- tartışılan
- ekran
- dağıtıldı
- Değil
- Dont
- aşağı
- her
- kolayca
- verimli
- verimli biçimde
- ya
- sağlar
- son uca
- Son nokta
- Tüm
- çevre
- hata
- Hatalar
- gerekli
- Eter (ETH)
- Hatta
- örnek
- istisna
- yürütmek
- yaşıyor
- Açıklamak
- keşif
- keşfetmek
- Keşfetmek
- ihracat
- son derece
- Yüz
- faktörler
- Falls
- tanıdık
- Özellikler(Hazırlık aşamasında)
- az
- fileto
- Nihayet
- bulmak
- Ad
- FİLO
- odak
- odaklanır
- takip etme
- biçim
- iskelet
- sık
- itibaren
- tam
- tamamen
- daha fazla
- genel
- genellikle
- almak
- alma
- Tercih Etmenizin
- grafik
- büyük
- grup
- Grubun
- sap
- mutlu
- donanım
- yardım et
- yardım
- yardımcı olur
- okuyun
- Yüksek
- büyük ölçüde
- başlık
- ev sahibi
- ev sahipliği yaptı
- hosting
- Ne kadar
- Nasıl Yapılır
- HTML
- HTTPS
- merkez
- Fikir
- ideal
- tespit
- belirlemek
- darbe
- uygulamak
- uygulanan
- ithalat
- önemli
- in
- içerir
- Artırmak
- artmış
- gösterir
- belirti
- bilgi
- başlangıçta
- kurmak
- örnek
- entegre
- interaktif
- Internet
- çağırır
- IP
- IP Adresi
- yalıtılmış
- sorunlar
- IT
- kendisi
- json
- büyük
- çok
- büyük
- Gecikme
- başlatmak
- katmanları
- öncülük etmek
- önemli
- öğrenme
- seviye
- linux
- Liste
- küçük
- yük
- yükler
- yer
- Uzun
- bakıyor
- Çok
- Düşük
- makine
- makine öğrenme
- Makineler
- yapmak
- Yapımı
- yönetmek
- yönetilen
- el ile
- çok
- harita
- Maksimuma çıkarmak
- anlamına geliyor
- Neden
- toplantı
- Bellek
- metrik
- Metrikleri
- olabilir
- asgari
- ML
- Moda
- model
- modelleri
- izlemek
- Daha
- daha verimli
- çoklu
- isim
- neredeyse
- zorunlu olarak
- gerek
- yeni
- defter
- numara
- ONE
- açık
- açık kaynak
- Operasyon
- optimizasyon
- optimize
- optimize
- seçenek
- Opsiyonlar
- sipariş
- Diğer
- dışında
- kendi
- boya
- parametreler
- Bölüm
- geçti
- geçmiş
- yol
- model
- desen
- zirve
- yapmak
- performans
- perspektif
- seçmek
- resim
- parça
- yer
- Yerler
- Platon
- Plato Veri Zekası
- PlatoVeri
- artı
- Nokta
- Çivi
- potansiyel
- güç kelimesini seçerim
- uygulama
- uygulamalar
- Predictor
- birincil
- sorunlar
- süreç
- Süreçler
- üretim
- Profil
- uygun
- uygun şekilde
- sağlamak
- sağlar
- hüküm
- halka açık
- Python
- Sorular
- hızla
- menzil
- hazır
- gerçek zaman
- gerçekleştirmek
- alır
- Tavsiye edilen
- bölge
- ilgili
- talep
- Yer Alan Kurallar
- Kaynaklar
- yanıt
- DİNLENME
- sonuç
- Sonuçlar
- İade
- kurallar
- koşmak
- koşu
- sagemaker
- SageMaker Çıkarımı
- ölçek
- ölçekleme
- bilim adamları
- Kapsam Belirleme
- scriptler
- İkinci
- güvenlik
- görünüyor
- SELF
- gönderme
- duygu
- hizmet
- servis
- set
- ayar
- ayarlar
- kurulum
- birkaç
- meli
- gösterilen
- Gösteriler
- işaret
- benzer
- Basit
- sadece
- tek
- beden
- daha küçük
- So
- Çözümler
- bir şey
- Kaynak
- kaynaklar
- Yumurtlamak
- özel
- özellikle
- Dönme
- standart
- başlama
- başladı
- ifadeleri
- adım
- Yine
- dur
- stres
- çabalamak
- böyle
- yeterli
- Takım elbise
- harika
- tamamlamak
- Bizi daha iyi tanımak için
- alır
- Hedef
- Görev
- görevleri
- takım
- teknikleri
- test
- Test sürüşü
- Test yapmak
- testleri
- Metin Sınıflandırması
- The
- Kaynak
- ve bazı Asya
- üçüncü şahıslara ait
- Binlerce
- İçinden
- zaman
- zamanlar
- için
- araç
- araçlar
- tps
- iz
- Takip
- trafik
- Tren
- işlemler
- Seyahat
- gerçek
- öğretici
- türleri
- Ubuntu
- ui
- altında
- anlamak
- anlayış
- birim
- URL
- us
- kullanım
- kullanıcılar
- kullanmak
- kullanılan
- kullanır
- Kullanılması
- çeşitlilik
- doğrulamak
- üzerinden
- Sanal
- Ne
- olup olmadığını
- hangi
- süre
- irade
- içinde
- İş
- işçi
- işçiler
- olur
- yazı yazıyor
- zefirnet