Taranan belgelerden veri çıkarmak mı istiyorsunuz? Denemek Nanonetler™ ileri AI tabanlı OCR Tarayıcı bilgileri ayıklamak ve düzenlemek için taranmış döküman otomatik olarak.
Giriş
Dünya kolaylık sağlamak için kağıtlardan ve el yazılarından dijital belgelere geçerken, görüntülerin ve taranan belgelerin anlamlı verilere dönüştürülmesinin önemi hızla arttı.
Çok sayıda araştırma tesisi ve şirket (örn. Google, AWS, Nanonets vb.), yüksek doğrulukta belge verisi çıkarma ihtiyacına ayak uydurmak için bilgisayarla görme ve Doğal Dil İşleme (NLP) alanlarındaki teknolojilere derinlemesine odaklandı.
Derin öğrenme teknolojilerinin çiçek açması, ayıklanabilecek veri türüne dev bir sıçrama sağladı; artık yalnızca metni ayıklamakla sınırlı değiliz, aynı zamanda tablolar ve anahtar/değer çiftleri gibi diğer veri yapılarını da çıkarmakla sınırlıyız. Artık birçok çözüm, bireylerin ve işletme sahiplerinin belge verilerinin çıkarılması konusundaki ihtiyaçlarını karşılamak için çeşitli ürünler sunmaktadır.
Bu makale, taranan belgelerden veri çıkarmak için kullanılan mevcut teknolojiye dalmakta ve ardından Python'da kısa bir uygulamalı eğitim vermektedir. Ayrıca, şu anda piyasada bulunan ve bu alanda en iyi teklifleri sunan popüler çözümlerden bazılarına da bakacağız.

Veri Çıkarma nedir?
Veri çıkarma, insanlar tarafından daha fazla veri işlemeye izin vermek için yapılandırılmamış verileri programlar tarafından yorumlanabilir bilgilere dönüştürme işlemidir. Burada, taranan belgelerden çıkarılacak en yaygın veri türlerinden birkaçını listeliyoruz.
Metin Verileri
Taranan belgelerden veri çıkarmada en yaygın ve en önemli görev metin çıkarmaktır. Bu süreç, görünüşte basit olsa da, taranan belgeler genellikle görüntü formatında sunulduğundan aslında çok zordur. Ek olarak, çıkarma yöntemleri büyük ölçüde metin türlerine bağlıdır. Metin çoğu zaman yoğun basılı biçimlerde bulunurken, daha az iyi taranmış belgelerden veya büyük ölçüde değişen stillere sahip el yazısı harflerden seyrek metin çıkarma yeteneği de aynı derecede önemlidir. Böyle bir süreç, programların görüntüleri, daha fazla analiz için yapılandırılmamış verilerden (belirli biçimlendirme olmadan) yapılandırılmış verilere daha fazla düzenleyebileceğimiz, makine tarafından kodlanmış metne dönüştürmesine izin verecektir.
tablolar
Tablo biçimleri, insan gözüyle kolayca yorumlanabildiğinden, veri depolama için en popüler yaklaşımdır. Taranan belgelerden tablo çıkarma işlemi, karakter algılamanın ötesinde bir teknoloji gerektirir - uygun bir tablo çıkarma gerçekleştirmek ve bu bilgileri daha fazla hesaplama için yapılandırılmış verilere dönüştürmek için satırları ve diğer görsel özellikleri algılamak gerekir. Bilgisayarlı görü yöntemleri (aşağıdaki bölümlerde ayrıntılı olarak açıklanmıştır), yüksek doğrulukta tablo çıkarımı elde etmek için yoğun olarak kullanılmaktadır.

Anahtar/Değer Çiftleri
Veri depolama için belgelerde sıklıkla benimsediğimiz alternatif bir biçim, anahtar/değer çiftleridir (KVP'ler).

KVP'ler esasen iki veri öğesidir - bir anahtar ve bir değer - tek olarak birbirine bağlanır. Anahtar, alınacak değer için benzersiz bir tanımlayıcı olarak kullanılır. Klasik bir KVP örneği, sözlüklerin anahtar olduğu ve karşılık gelen tanımların değerler olduğu sözlüktür. Bu çiftler, genellikle fark edilmese de, aslında belgelerde çok sık kullanılmaktadır: anketlerdeki ad, yaş ve faturalardaki öğelerin fiyatları gibi soruların tümü dolaylı olarak KVP'lerdir.
Ancak, tabloların aksine, KVP'ler genellikle bilinmeyen formatlarda bulunur ve bazen kısmen el yazısıyla yazılır. Örneğin, anahtarlar kutulara önceden yazdırılabilir ve değerler form doldurulurken elle yazılır. Bu nedenle, KVP çıkarma işlemini otomatik olarak gerçekleştirmek için temeldeki yapıları bulmak, en gelişmiş tesisler ve laboratuvarlar için bile devam eden bir araştırma sürecidir.
rakamlar
Son olarak, çıkarmak veya çıkarmak da çok önemlidir. veri yakala taranan bir belgedeki rakamlardan. Pasta grafikler ve çubuk grafikler gibi istatistiksel göstergeler genellikle belgeler için önemli bilgiler içerir. İyi bir veri çıkarma işlemi, daha sonra kullanılmak üzere şekillerden kısmen veri çıkarmak için açıklamalardan ve sayılardan çıkarım yapabilmelidir.
Taranan belgelerden veri çıkarmak mı istiyorsunuz? Nanonetler verin™ daha yüksek doğruluk, daha fazla esneklik, işlem sonrası ve geniş bir entegrasyon seti için bir dönüş!
Veri Çıkarmanın Arkasındaki Teknolojiler
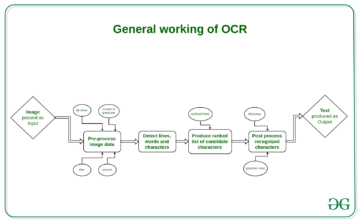
Veri çıkarma iki ana süreç etrafında döner: Optik Karakter Tanıma (OCR) ardından Doğal Dil İşleme (NLP).
OCR çıkarma, metin görüntülerini makinede kodlanmış metne dönüştürme işlemiyken, ikincisi anlam çıkarmak için kelimeler üzerinde yapılan analizlerdir. Genellikle OCR ile birlikte, daha kapsamlı çıkarma için tablolar ve KVP'ler gibi yukarıda belirtilen veri türlerini çıkarmak için kutu ve çizgi algılama gibi diğer bilgisayarlı görme teknikleri bulunur.
Veri çıkarma hattının arkasındaki temel gelişmeler, bilgisayarla görme ve doğal dil işleme (NLP) alanlarına büyük katkı sağlayan derin öğrenmedeki ilerlemelerle sıkı sıkıya bağlantılıdır.
Derin öğrenme nedir?
Derin öğrenme, yapay zeka çağının hype arkasında büyük bir role sahiptir ve sayısız uygulamada sürekli olarak ön plana itilmiştir. Geleneksel mühendislikte amacımız, belirli bir girdiden çıktı üreten bir sistem/fonksiyon tasarlamaktır; Öte yandan derin öğrenme, sözde aracılığıyla yeni görünmeyen verilere genişletilebilecek ara ilişkiyi bulmak için girdilere ve çıktılara dayanır. sinir ağı.
Bir sinir ağı veya çok katmanlı bir algılayıcı (MLP), insan beyninin nasıl öğrendiğinden ilham alan bir makine öğrenimi mimarisidir. Ağ, biyolojik nöronları taklit eden ve farklı bilgiler verildiğinde “aktive olan” nöronları içerir. Nöron kümeleri katmanları oluşturur ve çoklu katmanlar, çoklu formların tahmin amaçlarına hizmet etmek için bir ağ oluşturmak üzere birlikte istiflenir (yani, görüntü sınıflandırmaları veya nesne algılamaları için sınırlayıcı kutular).

Bilgisayarla görme alanında, bir tür sinir ağı varyasyonu yoğun bir şekilde uygulanmaktadır - evrişimli sinir ağları (CNN'ler). Bir CNN, geleneksel katmanlar yerine, özellik çıkarımı için tensörler (veya yüksek boyutlu vektörler) boyunca kayan evrişimli çekirdekleri benimser. Sonunda geleneksel ağ katmanlarıyla birlikte, CNN'ler görüntü ile ilgili görevlerde çok başarılıdır ve ayrıca OCR çıkarma ve diğer özellik algılama için temel oluşturur.
Öte yandan, NLP, zaman serisi verilerine odaklanan başka bir ağ grubuna bağımlıdır. Bir görüntünün birbirinden bağımsız olduğu görüntülerin aksine, önceki veya sonraki kelimeler de dikkate alındığında metin tahmini büyük ölçüde fayda sağlayabilir. Son birkaç yılda, bir ağ ailesi, yani uzun kısa süreli anılar (LSTM'ler), mevcut sonuçları tahmin etmek için önceki sonuçları girdi olarak alır. İkili LSTM'ler, hem önceki hem de sonraki sonuçların dikkate alındığı tahmin çıktısını geliştirmek için sıklıkla benimsendi. Bununla birlikte, son yıllarda, sıralı zaman serilerini işleyen geleneksel ağlardan daha iyi sonuçlara yol açan yüksek esnekliği nedeniyle bir dikkat mekanizması kullanan bir transformatör kavramı yükselmeye başlıyor.
Veri Çıkarma Uygulamaları
Veri çıkarmanın temel amacı, yapılandırılmamış belgelerdeki verileri, metin, şekiller ve veri yapılarının son derece hassas bir şekilde alınmasının sayısal ve bağlamsal analiz için çok yardımcı olabileceği yapılandırılmış biçimlere dönüştürmektir. Bu analizler özellikle işletmeler için çok yardımcı olabilir:
İşletme
Ticari şirketler ve büyük kuruluşlar, günlük olarak benzer formatlarda binlerce evrak işiyle uğraşıyor - Büyük bankalar çok sayıda benzer başvuru alıyor ve araştırma ekiplerinin istatistiksel analiz yapmak için form yığınlarını analiz etmesi gerekiyor. Bu nedenle, belgelerden veri çıkarmanın ilk adımının otomasyonu, insan kaynaklarının fazlalığını önemli ölçüde azaltır ve çalışanların bilgileri girmek yerine verileri analiz etmeye ve uygulamaları gözden geçirmeye odaklanmasını sağlar.
- Uygulamaları Doğrulama — Şirketler, ister el yazısıyla, ister yalnızca başvuru formları aracılığıyla tonlarca başvuru alıyor. Çoğu zaman, bu başvurulara doğrulama amacıyla kişisel kimlikler eşlik edebilir. Pasaportlar veya kartlar gibi taranan kimlik belgeleri genellikle benzer formatlarda toplu olarak gelir. Bu nedenle, iyi yazılmış bir veri çıkarıcı, verileri (metinler, tablolar, şekiller, KVP'ler) hızlı bir şekilde makine tarafından anlaşılabilir metinlere dönüştürebilir, bu da bu görevlerde çalışma saatlerini önemli ölçüde azaltabilir ve ayıklama yerine uygulama seçimine odaklanabilir.
- ödeme mutabakatı — Ödeme Uzlaştırması, ağırlıklı olarak belgelerden veri çıkarma etrafında dönen hesaplar arasındaki sayıların eşleşmesini sağlamak için banka hesap özetlerini karşılaştırma sürecidir - önemli büyüklükte ve çeşitli gelir akışı kaynaklarına sahip bir şirket için zorlu bir konu. Veri çıkarma, bu süreci kolaylaştırabilir ve çalışanların hatalı verilere odaklanmasına ve nakit akışıyla ilgili olası dolandırıcılık olaylarını keşfetmesine olanak tanır.
- İstatistiksel Analiz — Müşterilerden veya deney katılımcılarından gelen geri bildirimler, şirketler ve kuruluşlar tarafından ürünlerini ve hizmetlerini geliştirmek için kullanılır ve kapsamlı bir geri bildirim değerlendirmesi için genellikle istatistiksel bir analiz gerekir. Bununla birlikte, anket verileri çok sayıda formatta bulunabilir veya çeşitli formatlarda metinler arasında gizlenmiş olabilir. Veri çıkarma, belgelerdeki açık verileri gruplar halinde göstererek süreci kolaylaştırabilir, faydalı süreçleri bulma sürecini kolaylaştırabilir ve nihayetinde verimliliği artırabilir.
- Geçmiş Kayıtları Paylaşma — Sağlık hizmetlerinden banka hizmetlerine geçişe kadar, büyük endüstriler genellikle başka yerlerde mevcut olabilecek yeni müşteri bilgilerine ihtiyaç duyar. Örneğin, taşınma nedeniyle hastane değiştiren bir hasta, yeni hastaneye yardımcı olabilecek önceden mevcut tıbbi kayıtlara sahip olabilir. Bu gibi durumlarda, kişinin tüm bilgileri otomatik olarak doldurması için taranmış bir kayıt geçmişini yeni hastaneye getirmesi gerektiğinden iyi bir veri çıkarma yazılımı kullanışlı olur. Bu sadece uygun olmakla kalmaz, aynı zamanda özellikle sağlık sektöründe önemli hasta kayıtlarının gözden kaçırılmasına ilişkin kapsamlı riskleri de önleyebilir.
Taranan belgelerden veri çıkarmak mı istiyorsunuz? Nanonetler verin™ daha yüksek doğruluk, daha fazla esneklik, işlem sonrası ve geniş bir entegrasyon seti için bir dönüş!
Öğreticiler
Veri çıkarma işleminin nasıl gerçekleştirileceğine dair daha net bir görünüm sağlamak için, tarama belgelerinden veri çıkarma işlemi gerçekleştirmeye ilişkin iki grup yöntem gösteriyoruz.
Çizilmeden Bina
Aşağıdaki gibi PyTesseract motoru aracılığıyla OCR motoru çıkaran basit bir veri oluşturulabilir:
try: from PIL import Image
except ImportError: import Image
import pytesseract # If you don't have tesseract executable in your PATH, include the following:
pytesseract.pytesseract.tesseract_cmd = r'<full_path_to_your_tesseract_executable>'
# Example tesseract_cmd = r'C:Program Files (x86)Tesseract-OCRtesseract' # Simple image to string
print(pytesseract.image_to_string(Image.open('test.png'))) # List of available languages
print(pytesseract.get_languages(config='')) # French text image to string
print(pytesseract.image_to_string(Image.open('test-european.jpg'), lang='fra')) # In order to bypass the image conversions of pytesseract, just use relative or absolute image path
# NOTE: In this case you should provide tesseract supported images or tesseract will return error
print(pytesseract.image_to_string('test.png')) # Batch processing with a single file containing the list of multiple image file paths
print(pytesseract.image_to_string('images.txt')) # Timeout/terminate the tesseract job after a period of time
try: print(pytesseract.image_to_string('test.jpg', timeout=2)) # Timeout after 2 seconds print(pytesseract.image_to_string('test.jpg', timeout=0.5)) # Timeout after half a second
except RuntimeError as timeout_error: # Tesseract processing is terminated pass # Get bounding box estimates
print(pytesseract.image_to_boxes(Image.open('test.png'))) # Get verbose data including boxes, confidences, line and page numbers
print(pytesseract.image_to_data(Image.open('test.png'))) # Get information about orientation and script detection
print(pytesseract.image_to_osd(Image.open('test.png'))) # Get a searchable PDF
pdf = pytesseract.image_to_pdf_or_hocr('test.png', extension='pdf')
with open('test.pdf', 'w+b') as f: f.write(pdf) # pdf type is bytes by default # Get HOCR output
hocr = pytesseract.image_to_pdf_or_hocr('test.png', extension='hocr') # Get ALTO XML output
xml = pytesseract.image_to_alto_xml('test.png')Kodla ilgili daha fazla bilgi için, onların resmi kontrol edebilirsiniz. dokümantasyon.
Basit bir deyişle, kod, belirli bir görüntüden metinler ve sınırlayıcı kutular gibi verileri çıkarır. Oldukça kullanışlı olsa da, eğitim için önemli hesaplama güçleri nedeniyle motor hiçbir yerde gelişmiş çözümler tarafından sağlananlar kadar güçlü değildir.
Google Doküman API'sini Kullanma
def async_detect_document(gcs_source_uri, gcs_destination_uri):
"""OCR with PDF/TIFF as source files on GCS""" import json import re from google.cloud import vision from google.cloud import storage # Supported mime_types are: 'application/pdf' and 'image/tiff' mime_type = 'application/pdf' # How many pages should be grouped into each json output file. batch_size = 2 client = vision.ImageAnnotatorClient() feature = vision.Feature( type_=vision.Feature.Type.DOCUMENT_TEXT_DETECTION) gcs_source = vision.GcsSource(uri=gcs_source_uri) input_config = vision.InputConfig( gcs_source=gcs_source, mime_type=mime_type) gcs_destination = vision.GcsDestination(uri=gcs_destination_uri) output_config = vision.OutputConfig( gcs_destination=gcs_destination, batch_size=batch_size) async_request = vision.AsyncAnnotateFileRequest( features=[feature], input_config=input_config, output_config=output_config) operation = client.async_batch_annotate_files( requests=[async_request]) print('Waiting for the operation to finish.') operation.result(timeout=420) # Once the request has completed and the output has been # written to GCS, we can list all the output files. storage_client = storage.Client() match = re.match(r'gs://([^/]+)/(.+)', gcs_destination_uri) bucket_name = match.group(1) prefix = match.group(2) bucket = storage_client.get_bucket(bucket_name) # List objects with the given prefix. blob_list = list(bucket.list_blobs(prefix=prefix)) print('Output files:') for blob in blob_list: print(blob.name) # Process the first output file from GCS. # Since we specified batch_size=2, the first response contains # the first two pages of the input file. output = blob_list[0] json_string = output.download_as_string() response = json.loads(json_string) # The actual response for the first page of the input file. first_page_response = response['responses'][0] annotation = first_page_response['fullTextAnnotation'] # Here we print the full text from the first page. # The response contains more information: # annotation/pages/blocks/paragraphs/words/symbols # including confidence scores and bounding boxes print('Full text:n') print(annotation['text'])Sonuç olarak, Google'ın belge yapay zekası, belgelerden çok sayıda bilgiyi yüksek doğrulukla çıkarmanıza olanak tanır. Ayrıca hizmet, hem normal hem de vahşi görüntüler için metin çıkarma da dahil olmak üzere belirli kullanımlar için de sunulmaktadır.
Bakın okuyun Daha fazla bilgi için.
Veri Çıkarma Sunan Güncel Çözümler
Belge verilerinin çıkarılması için API'lere sahip büyük şirketlerin yanı sıra, yüksek doğruluk sağlayan çeşitli çözümler vardır. PDF OCR'si Hizmetler. Farklı yönlerde uzmanlaşmış çeşitli PDF OCR seçeneklerinin yanı sıra umut verici sonuçlar veren bazı yeni araştırma prototiplerini sunuyoruz*:
*Yan Not: Vahşi doğada görüntüler gibi görevlere yönelik birden çok OCR hizmeti vardır. Şu anda yalnızca PDF belgesi okumaya odaklandığımız için bu hizmetleri atladık.
- Google API'sı — En büyük çevrimiçi hizmet sağlayıcılarından biri olan Google, öncü bilgisayarlı görü teknolojisiyle belge çıkarmada çarpıcı sonuçlar sunuyor. Kullanım oldukça düşükse hizmetlerini ücretsiz olarak kullanabilir, ancak API çağrıları arttıkça fiyat artar.
- Derin Okuyucu — Derin Okuyucu, ACCV Konferansı 2019'da yayınlanan bir araştırma çalışmasıdır. belge eşleştirme, metin alma ve gürültüyü azaltan görüntüler. Verilerin düzenli bir şekilde alınmasını ve kaydedilmesini sağlayan tablolar ve anahtar/değer çifti çıkarma gibi ek özellikler vardır.
- Nanonets ™ — Oldukça yetenekli bir derin öğrenme ekibiyle Nanonets™ PDF OCR, tamamen şablondan ve kuraldan bağımsızdır. Bu nedenle, Nanonets™ yalnızca belirli PDF türleri üzerinde çalışmakla kalmaz, aynı zamanda metin almak için herhangi bir belge türüne de uygulanabilir.
Taranan belgelerden veri çıkarmak mı istiyorsunuz? Nanonetler verin™ daha yüksek doğruluk, daha fazla esneklik, işlem sonrası ve geniş bir entegrasyon seti için bir dönüş!
Sonuç
Sonuç olarak, bu makale, arkasındaki zorluklar ve bu süreç için gereken teknoloji de dahil olmak üzere, taranan belgelerden veri çıkarılmasına yönelik kapsamlı bir açıklama sunmaktadır.
Farklı yöntemlerin iki öğreticisi sunulur ve bunu kullanıma hazır olarak sunan mevcut çözümler de referans olarak sunulur.
- 2019
- Hakkımızda
- kesin
- Hesap
- doğru
- Başarmak
- ilave
- Ek
- ileri
- gelişmeler
- AI
- algoritmalar
- Türkiye
- zaten
- alternatif
- çözümlemek
- analiz
- Başka
- api
- API'ler
- Uygulama
- uygulamaları
- yaklaşım
- mimari
- etrafında
- göre
- yapay
- yapay zeka
- Dikkat
- Otomasyon
- mevcut
- AWS
- arka fon
- Banka
- Bankalar
- temel
- olmak
- İYİ
- Ötesinde
- Biggest
- sınır
- kutu
- inşa etmek
- iş
- işletmeler
- Kartlar
- durumlarda
- Nakit
- nakit akımı
- belli
- zorluklar
- zor
- Grafikler
- Ödeme Yap
- klasik
- bulut
- CNN
- kod
- nasıl
- ortak
- Şirketler
- şirket
- tamamen
- tamamladıktan
- kapsamlı
- hesaplama
- bilgisayar
- kavram
- Konferans
- güven
- bağlı
- sürekli
- içeren
- katkıda
- kolaylık
- Uygun
- dönüşümler
- çekirdek
- Kurumlar
- uyan
- olabilir
- çok önemli
- akım
- Şu anda
- müşteri
- Müşteriler
- veri
- veri işleme
- veri saklama
- anlaşma
- tarif edilen
- Dizayn
- ayrıntı
- Bulma
- farklı
- zor
- dijital
- evraklar
- kolayca
- verim
- çalışanların
- Motor
- Mühendislik
- özellikle
- esasen
- tahminleri
- vb
- değerlendirme
- olaylar
- örnek
- Dışında
- deneme
- keşfetmek
- kapsamlı, geniş
- Hulasa
- aile
- Özellikler(Hazırlık aşamasında)
- Özellikler
- geribesleme
- Alanlar
- bulma
- Ad
- Esneklik
- akış
- odak
- odaklanmış
- odaklanır
- odaklanma
- takip etme
- Forefront
- Airdrop Formu
- biçim
- formlar
- Ücretsiz
- Fransızca
- yerine getirmek
- tam
- daha fazla
- gol
- Tercih Etmenizin
- büyük
- çok
- kullanma
- hands-on
- baş
- sağlık
- Sağlık sektörü
- faydalı
- okuyun
- Yüksek
- daha yüksek
- büyük ölçüde
- tarih
- Hastanelerinden olan İstanbul Cerrahi Hastanesi'nde
- Ne kadar
- Nasıl Yapılır
- Ancak
- HTTPS
- insan
- İnsan Kaynakları
- İnsanlar
- görüntü
- önem
- önemli
- iyileştirmek
- dahil
- Dahil olmak üzere
- Gelir
- Artırmak
- bireysel
- bireyler
- Endüstri
- sanayi
- bilgi
- giriş
- ilham
- İstihbarat
- konu
- IT
- İş
- anahtar
- anahtarlar
- Labs
- dil
- Diller
- büyük
- önemli
- ÖĞRENİN
- öğrenme
- çizgi
- Liste
- Uzun
- makine
- makine öğrenme
- büyük
- çoğunluk
- adam
- tavır
- pazar
- Maç
- uygun
- tıbbi
- yöntemleri
- Daha
- çoğu
- En popüler
- hareketli
- çoklu
- yani
- Doğal (Madenden)
- ihtiyaçlar
- ağ
- ağlar
- normal
- sayılar
- sayısız
- teklif
- sunulan
- teklif
- teklifleri
- Teklifler
- resmi
- devam
- Online
- operasyon
- Opsiyonlar
- sipariş
- organizasyonlar
- Düzenlenmiş
- Diğer
- sahipleri
- Katılımcılar
- ödeme
- icra
- dönem
- kişisel
- Öncü
- Popüler
- potansiyel
- güç kelimesini seçerim
- tahmin
- tahmin
- mevcut
- güzel
- önceki
- fiyat
- süreç
- Süreçler
- işleme
- Ürünler
- Programı
- Programlar
- umut verici
- sağlamak
- sağlama
- amaçlı
- hızla
- RE
- Okuyucu
- Okuma
- teslim almak
- uzlaşma
- kayıtlar
- azaltmak
- ilişkin
- ilişki
- talep
- gerektirir
- gereklidir
- gerektirir
- araştırma
- Kaynaklar
- yanıt
- Sonuçlar
- dönüş
- riskler
- tarama
- saniye
- hizmet
- Hizmetler
- set
- birkaç
- kısa
- kısa dönem
- benzer
- Basit
- beri
- beden
- Software
- katı
- Çözümler
- biraz
- özel
- Dönme
- state-of-the-art
- ifadeleri
- istatistiksel
- hafızası
- dere
- güçlü
- yapılandırılmış
- önemli
- başarılı
- destekli
- Anket
- Hedeflenen
- görevleri
- takım
- teknikleri
- Teknolojileri
- Teknoloji
- test
- Dünya
- bu nedenle
- Binlerce
- İçinden
- zaman
- zamanlar
- birlikte
- Ton
- karşı
- geleneksel
- Eğitim
- Öğreticiler
- türleri
- anlamak
- benzersiz
- kullanım
- genellikle
- değer
- çeşitli
- Doğrulama
- Görüntüle
- vizyonumuz
- olup olmadığını
- süre
- içinde
- olmadan
- sözler
- İş
- işçiler
- Dünya
- olur
- XML
- yıl