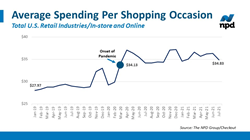
Verilerimizi normal hale getirmek için Standart Ölçekleyici kullandık ve bir dağılım grafiği çizdik.
Şimdi kümelere puan vermek için DBSCAN'ı import edeceğiz. Başarısız olursa, -1 gösterecektir.
Şimdi sonuçlarımız var ama hangi değerin min, max olduğunu ve -1 değerimizin olup olmadığını nasıl kontrol edeceğiz? Kümedeki en küçük değeri kontrol etmek için arg min değerini kullanacağız.
Sonuçtan -1 olan altı değer görebiliriz.
Şimdi bir dağılım grafiği çizelim.
Uyguladığımız yukarıdaki yöntemler tek değişkenli aykırı değerler üzerindedir.
Çok değişkenli aykırı değer tespitleri için çok değişkenli aykırı değerleri anlamamız gerekir.
Örneğin, Araba okumalarını alıyoruz. Biri aracın hareket ettiği hızı kaydeden veya ölçen kilometre sayacı için ve ikincisi araba tekerleğinin dakikada yaptığı dönüş sayısını kaydeden rpm okuması için iki okuma ölçer gördük.
Kilometre sayacının 0-60 mph aralığında ve rpm'de 0-750 gösterdiğini varsayalım. Gelen tüm değerlerin birbiriyle ilişkili olması gerektiğini varsayıyoruz. Kilometre sayacı 50 hızı gösteriyorsa ve rpm 0 girişi gösteriyorsa, okumalar yanlıştır. Kilometre sayacı sıfırdan büyük bir değer gösteriyorsa, bu araba hareket ediyor demektir, bu nedenle rpm değerlerinin daha yüksek olması gerekir, ancak bizim durumumuzda 0 değerini gösterir. yani, Çok değişkenli aykırı değerler.
C. Mahalanobis Mesafe Yöntemi
DBSCAN'de öklid uzaklık metriklerini kullandık ama bu durumda Mahalanobis uzaklık yönteminden bahsediyoruz. DBSCAN ile Mahalanobis mesafesini de kullanabiliriz.
DBSCAN(eps=0.5, min_samples=3, metric='mahalanobis', metric_params={'V':np.cov(X)}, algorithm='brute', leaf_size=30, n_jobs=-1)Öklid neden birbiriyle ilişkili varlıklar için uygun değildir? Öklid mesafesi bulamıyor veya iki noktanın ne kadar yakın olduğuna dair yanlış veri veriyor.
Mahalanobis yöntemi, noktalar arasındaki mesafeyi ve temiz veri olan dağılımı kullanır. Öklid mesafesi genellikle iki nokta arasındadır ve z-skoru, x eksi ortalama ile hesaplanır ve standart sapmaya bölünür. Mahalanobis'te z-skoru, x eksi ortalama bölü kovaryans matrisidir.
Bu nedenle, kovaryans matrisine bölmenin ne gibi bir etkisi vardır? Veri kümenizdeki değişkenler yüksek oranda ilişkiliyse, kovaryans değerleri yüksek olacaktır.
Benzer şekilde, kovaryans değerleri düşükse, veriler ilişkili değilse mesafe önemli ölçüde azalmaz. O kadar iyi iş çıkarıyor ki, değişken sorunlarının hem ölçeğini hem de korelasyonunu ele alıyor.
Kod
Veri kümesi şuradan alınabilir: Anomaly-/caret.csv ana sayfada · aster28/Anomaly- (github.com)
df = pd.read_csv('caret.csv').iloc[:, [0,4,6]] df.head()

Fonksiyon mesafesini x= Yok, veri= Yok ve Kovaryans = Yok olarak tanımladık. Fonksiyonun içinde, verilerin ortalamasını aldık ve oradaki değerin kovaryans değerini kullandık. Aksi takdirde, kovaryans matrisini hesaplayacağız. T devrik anlamına gelir.
Örneğin, dizi boyutu beş veya altı ise ve bunun iki değişkenli olmasını istiyorsanız, o zaman matrisi transpoze etmemiz gerekir.
np.random.multivariate_normal(mean, cov, size = 5)
array([[ 0.0509196, 0.536808 ], [ 0.1081547, 0.9308906], [ 0.4545248, 1.4000731], [ 0.9803848, 0.9660610], [ 0.8079491 , 0.9687909]])np.random.multivariate_normal(mean, cov, size = 5).T
array([[ 0.0586423, 0.8538419, 0.2910855, 5.3047358, 0.5449706], [ 0.6819089, 0.8020285, 0.7109037, 0.9969768, -0.7155739]])Lineer cebir olan ve lineer cebir üzerinde gerçekleştirilecek farklı fonksiyonları olan sp.linalg kullandık. Matrisin tersi için inv işlevine sahiptir. Matrisin çarpılması için araç olarak NumPy noktası.
scipy'yi sp olarak içe aktar def mesafe(x=Yok, veri=Yok, cov=Yok): x_m = x - np.mean(veri) if değilse cov: cov = np.cov(data.values.T) inv_cov = sp. linalg.inv(cov) left = np.dot(x_m, inv_cov) m_distance = np.dot(left, x_m.T) dönüş m_distance.diagonal() df_g= df[['karat', 'derinlik', 'fiyat' ]].head(50) df_g['m_distance'] = mesafe(x=df_g, data=df[['karat', 'derinlik', 'fiyat']]) df_g.head()

B. Tukey'nin aykırı değer saptama yöntemi
Tukey yöntemi ayrıca genellikle Box and Whisker veya Box plot yöntemi olarak da adlandırılır.
Tukey yöntemi, Üst ve alt aralığı kullanır.
Üst aralık = 75. Yüzdelik -k*IQR
Alt aralık = 25. Yüzdelik dilim + k* IQR

Yaş değişkenli Titanik verilerimizi bir kutu grafiği kullanarak görelim.
sns.boxplot(titanik['yaş'].değerler)

Resimde Seaborn tarafından oluşturulan kutu lekesinin 55 ile 80 yaş arasındaki birçok noktanın çeyrekler içinde olmayan aykırı değerler olduğunu gösterdiğini görebiliriz. outliers_detect fonksiyonu yaparak alt ve üst aralığı tespit edeceğiz.
def outliers_detect(x, k = 1.5): x = np.array(x).copy().astype(float) first = np.quantile(x, .25) third = np.quantile(x, .75) # IQR hesaplama iqr = üçüncü - birinci #Üst aralık ve alt aralık alt = birinci - (k * iqr) üst = üçüncü + (k * iqr) dönüş alt, üst
outliers_detect(titanik['yaş'], k = 1.5)
(2.5, 54.5)
D. PyCaret ile Tespit
PyCaret tarafından algılama için aynı veri setini kullanacağız.
pycaret.anomaly'den import * setup_anomaly_data = setup(df)
Pycaret, aykırı değerleri tespit etmek için denetimsiz bir öğrenme modeli kullanan açık kaynaklı bir makine öğrenimidir. Veri kümesini pycaret'te kullanmak için bir get_data yöntemine sahiptir, algılamadan önce ön işleme görevi için set_up'a sahiptir, genellikle veri çerçevesini alır ama aynı zamanda ignore_features, vb. gibi birçok başka özelliği de vardır.
Diğer yöntemler, bir algoritma kullanmak için create_model. İlk önce İzolasyon Ormanını kullanacağız.
ifor = create_model("iforest") plot_model(ifor) ifor_predictions = tahmin_modeli(ifor, data = df) print(ifor_predictions) ifor_anomaly = ifor_predictions[ifor_predictions["Anormallik"] == 1] print(ifor_anomaly.head()) print( ifor_anomaly.shape)
Anormallik 1, aykırı değerleri gösterir ve Anormallik 0, aykırı değerleri göstermez.

Buradaki sarı renk, aykırı değerleri gösterir.
Şimdi başka bir algoritmaya bakalım, K En Yakın Komşular (KNN)
knn = create_model("knn") plot_model(knn) knn_pred = tahmin_model(knn, data = df) print(knn_pred) knn_anomaly = knn_pred[knn_pred["Anormallik"] == 1] knn_anomaly.head() knn_anomaly.shape

Şimdi bir kümeleme algoritması kullanacağız.
clus = create_model("cluster") plot_model(clus) clus_pred = tahmin_model(clus, data = df) print(clus_pred) clus_anomaly = clus_predictions[clus_pred["Anormallik"] == 1] print(clus_anomaly.head()) clus_anomaly. şekil

E. PyOD ile Anormallik Tespiti
PyOD, çok değişkenli verilerde aykırı değerlerin tespiti için bir python kitaplığıdır. Hem denetimli hem de denetimsiz öğrenme için iyidir.
pyod.models.iforest'tan IForest'i pyod.models.knn'den içe aktarın KNN'yi içe aktarın
Kütüphaneyi ve algoritmayı içe aktardık.
pyod.utils.data'dan pyod.utils.data'dan create_data'yı içe aktar pyod.utils.example'dan değerlendirme_yazısını içe aktar , n_features=300,contamination=contamine,random_state=100)
cname_alg = 'KNN' # algoritmanın adı K En Yakın Komşular c = KNN() c.fit(X_train) #Algoritmayı uydur y_trainpred = c.labels_ y_trainscores = c.decision_scores_ y_testpred = c.predict(X_test) y_testscores = c.decision_function(X_test) print("Eğitim Verileri:") Assessment_print(cname_alg, y_train, y_train_scores) print("Test Verileri:") Assessment_print(cname_alg, y_test, y_test_scores) görselleştir(cname_alg, X_train, y_train, X_test, y_test, y_trainpred,y_testpred, show_figure=Doğru, save_figure=Doğru)

IForest algoritmasını kullanacağız.
fname_alg = 'IForest' # algoritmanın adı K En Yakın Komşular f = IForest() f.fit(X_train) #Algoritmayı uydur y_train_pred = c.labels_ y_train_scores = c.decision_scores_ y_test_pred = c.predict(X_test) y_test_scores = c.decision_function(X_test) print("Eğitim Verileri:") Assessment_print(fname_alg, y_train_pred, y_train_scores) print("Test Verileri:") accept_print(fname_alg, y_test_pred, y_test_scores) görselleştir(fname_alg, X_train, y_train, X_test, y_test_pred, y_train_pred,y_test_pred, show_figure=Doğru, save_figure=Doğru)

F. Peygamber Tarafından Anomali Tespiti
Hava yolcusu veri setini zaman serisi ile kullanacağız Prophet/example_air_passengers.csv at main · aster28/prophet (github.com)
peygamberden ithalat peygamberi peygamberden ithalat tahmincisi import Peygamber m = Peygamber()
veri = pd.read_csv('air_pass.csv') veri.head()

data.columns = ['ds', 'y'] data['y'] = np.where(veri['y'] != 0, np.log(veri['y']), 0)
y sütununun Günlüğü, negatif bir değer sağlamaz. Verilerimizi tren, test olarak ayırdık ve tahmini değişken tahmininde sakladık.
tren, test= train_test_split(veri, rastgele_durum =42) m.fit(tren[['ds','y']]) tahmin = m.predict(test) def tespit(tahmin): tahmin = tahmin[['ds ', 'yhat', 'yhat_lower', 'yhat_upper']].copy() tahmin['gerçek']= veri['y'] tahmin['anomali'] =0 tahmin.loc[forcast['gerçek'] > tahmin['yhat_upper'], 'anomali']=1 tahmin.loc[forcast['gerçek']< tahmin['yhat_lower'], 'anomali']=-1 tahmin['imp']=0 in_range = tahmin ['yhat_upper']-forcast['yhat_lower'] forcast.loc[forcast['anomaly']==1, 'imp'] = tahmin['gerçek']-forcast['yhat_upper']/in_range forcast.loc[ tahmin['anomali']==-1, 'imp']= tahmin['yhat_lower']-tahmin['gerçek']/aralık içinde geri dönüş tahmini
algılamak (tahmin)
Anomaliyi -1 olarak aldık.

Sonuç
Belirli bir veri kümesindeki aykırı değerleri bulma işlemine anormallik tespiti denir. Aykırı değerler, veri kümesindeki diğer nesne değerlerinden farklı olan ve normal davranmayan veri nesneleridir.
Anomali algılama görevleri, aykırı değerleri bir küme olarak tanımlamak için mesafeye dayalı ve yoğunluğa dayalı kümeleme yöntemlerini kullanabilir.
Burada anomali saptamanın çeşitli yöntemlerini tartışıyoruz ve bunları Titanic, Air yolcuları ve Caret'in üç veri kümesindeki kodu kullanarak açıklıyoruz.
Anahtar Noktalar
1. Aykırı değerler veya anormallik tespiti, Box-Whisker yöntemi veya DBSCAN kullanılarak tespit edilebilir.
2. İlişkili olmayan maddeler için Öklid mesafesi yöntemi kullanılır.
3. Mahalanobis yöntemi, Çok Değişkenli aykırı değerlerle kullanılır.
4. Tüm değerler veya noktalar aykırı değerler değildir. Bazıları çöp olması gereken sesler. Aykırı değerler, ayarlanması gereken geçerli verilerdir.
5. PyCaret'i, anormalliğin bir olduğu, sarı renklerle gösterildiği ve aykırı değerin 0 olduğu yerde aykırı değer olmadığı farklı algoritmalar kullanarak aykırı değerlerin tespiti için kullandık.
6. Python Outlier algılama kitaplığı olan PyOD'yi kullandık. 40'tan fazla algoritmaya sahiptir. Denetimli ve denetimsiz teknikler kullanılır.
7. Peygamber'i kullandık ve aykırı değerleri ana hatlarıyla belirtmek için tespit işlevini tanımladık.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/01/learning-different-techniques-of-anomaly-detection/
- 1
- 10
- 11
- 7
- a
- Hakkımızda
- yukarıdaki
- adresleri
- Düzeltilmiş
- HAVA
- algoritma
- algoritmalar
- Türkiye
- analytics
- Analitik Vidhya
- ve
- anomali tespiti
- Başka
- uygulamalı
- Dizi
- göre
- önce
- arasında
- kutu
- hesaplanmış
- denilen
- yapamam
- araba
- dava
- Kontrol
- Kapanış
- Küme
- kümeleme
- kod
- renk
- Sütun
- Sütunlar
- COM
- nasıl
- Ilişki
- çevrimiçi kurslar düzenliyorlar.
- veri
- veri kümeleri
- derinlik
- algılandı
- Bulma
- sapma
- farklı
- takdir
- tartışmak
- mesafe
- dağıtım
- bölünmüş
- Dont
- DOT
- her
- Efekt
- sağlar
- kişiler
- vb
- Eter (ETH)
- örnek
- Açıklamak
- başarısız
- Özellikler
- bulmak
- bulma
- Ad
- Şamandıra
- Tahmin
- orman
- ÇERÇEVE
- itibaren
- işlev
- fonksiyonlar
- GitHub
- Vermek
- verilmiş
- Tercih Etmenizin
- grafik
- mutlu
- okuyun
- Yüksek
- daha yüksek
- büyük ölçüde
- Ne kadar
- HTTPS
- belirlemek
- görüntü
- ithalat
- in
- gösterir
- evirme
- izolasyon
- sorunlar
- IT
- ürün
- kendisi
- öğrenme
- Kütüphane
- Düşük
- makine
- makine öğrenme
- yapılmış
- Ana
- yapmak
- Yapımı
- çok
- Matris
- maksimum
- anlamına geliyor
- önlemler
- medya
- yöntem
- yöntemleri
- Metrikleri
- model
- modelleri
- Daha
- hareketli
- isim
- gerek
- negatif
- komşular
- normal
- normalde
- numara
- dizi
- nesne
- nesneler
- ONE
- açık kaynak
- Diğer
- aksi takdirde
- taslak
- Sahip olunan
- Platon
- Plato Veri Zekası
- PlatoVeri
- noktaları
- tahmin
- fiyat
- süreç
- Python
- rasgele
- menzil
- Okuma
- gerçek
- kayıtlar
- Indirimli
- DİNLENME
- sonuç
- Sonuçlar
- dönüş
- aynı
- ölçek
- Seaborn
- İkinci
- Shape
- meli
- şov
- gösterilen
- Gösteriler
- önemli ölçüde
- ALTINCI
- beden
- So
- biraz
- hız
- bölmek
- durmak
- standart
- standları
- saklı
- Bizi daha iyi tanımak için
- alır
- konuşma
- Görev
- görevleri
- teknikleri
- test
- The
- Orada.
- Üçüncü
- üç
- zaman
- için
- Tren
- Eğitim
- anlamak
- denetimsiz öğrenme
- us
- kullanım
- genellikle
- kullanır
- değer
- Değerler
- çeşitli
- araç
- Ne
- tekerlek
- olup olmadığını
- hangi
- irade
- içinde
- X
- zefirnet
- sıfır