Bu makale, Veri Bilimi Blogathon.
Giriş
Genel olarak, makine öğrenimi dört türe ayrılabilir: denetimli makine öğrenimi, denetimsiz makine öğrenimi, yarı denetimli makine öğrenimi ve pekiştirmeli öğrenim. Denetimli makine öğrenimi, veri biliminin en kolay ve daha az karmaşık türü veya dalı olan bir makine öğrenimi türüdür. Makale, veri biliminde pekiştirmeli öğrenmeyi ve meta-güçlendirmeli öğrenmeyi tartışacaktır. Bu makale, meta-güçlendirmeli öğrenmenin ve çalışma mekanizmasının arkasındaki temel fikri ve temel sezgiyi anlamaya yardımcı olacaktır. Takviyeli öğrenme kavramını tekrar gözden geçirerek başlayacağız ve hızlı bir şekilde meta-takviyeli öğrenmeye ve onun temel sezgisine geçeceğiz.
Takviye Öğrenme
Takviyeli öğrenme, üç ana şeyin mevcut olduğu bir tür makine öğrenimidir: aracı, çevre ve aracının eylemleri. Burada etmen, makine öğrenimi modeli veya henüz başlangıçta eğitilmemiş algoritmadır. Ajan ortama konur. Şimdi temsilci eylemleri gerçekleştirecek ve yapılan eylemlere ve sonuçlara göre temsilciye bazı puanlar verilir.
Modele veya etmene verilen puanlara göre etmen ortamda kalmayı ve uygun davranmayı öğrenir ve pekiştirmeli öğrenmede modelin eğitimi bu şekilde yapılır.
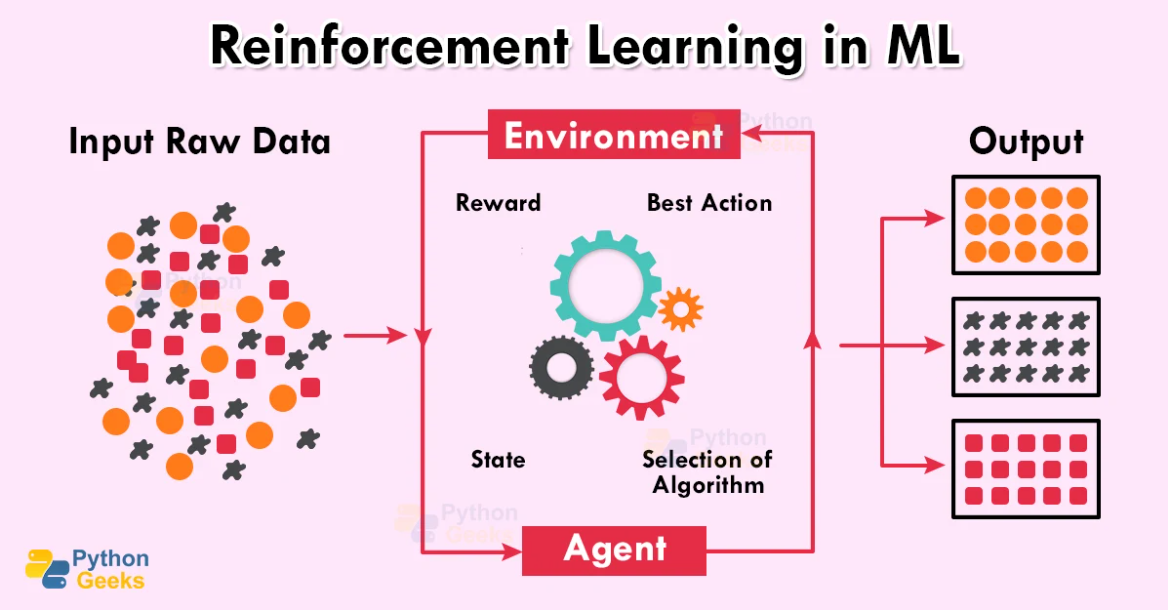
Yukarıdaki görüntüde, bazı girdi verilerinin modele beslendiğini görebiliriz. Veriler sisteme sağlandıktan sonra, etmen ortama göre en uygun modeli seçecek, model aynı algoritma ve girdi verileri ile bunların çıktılarına dayalı olarak eğitilecek ve bazı puanlar modeli. Artık model, ayar yaparak ve verilen puanlara bakarak en uygun algoritmayı kolayca seçebilir.
Sınırlı Veri Senaryosu
Takviyeli öğrenme modellerinin zaman karmaşıklığı, modeli eğitmek için çok zaman gerektirdiklerinden yüksektir. RL modeli, başarılı bir model ortaya çıkarmak için çok sayıda hesaplama yapan ve aynı zamanda daha yüksek hesaplama gücü gerektiren model türüdür. İyi pekiştirmeli öğrenme modelleri, modelden daha iyi doğruluk ve sonuçlar elde etmek için önemli veri boyutları üzerinde eğitilir.
Ancak her durumda pekiştirmeli öğrenme modelini eğitmek için çok fazla veriye ve zamana sahip olmak mümkündür. Bu gibi durumlarda, meta-güçlendirmeli öğrenme, bu tür görevlerin yerine getirilmesine yardımcı olur. Bu senaryoda meta-güçlendirme bilgisi, mevcut sınırlı verilerle aynı modeli daha hızlı hazırlamak için kullanılır.
Meta-Güçlendirmeli Öğrenme
Meta-takviyeli öğrenme, sınırlı veri ve zamanla takviyeli öğrenme modellerini eğitmek için kullanılan bir takviyeli öğrenme türüdür. Bu yaklaşım, temel olarak, problem tanımıyla ilgili çok fazla verinin olmadığı ve mümkün olduğu kadar hızlı bir model hazırlama ihtiyacının olduğu modelleri eğitmek için kullanılır.
Bu yaklaşımda en çok model yapısının başlangıç durumu kullanılır. Burada, aracıyı eğitmek için model aracının temel veya daha az aşaması kullanılır ve daha sonra aracının bu bilgisine bağlı olarak, sonraki adımlar otomatik olarak gerçekleştirilir.
Örneğin, sinir ağları söz konusu olduğunda, sinir ağlarının temel yapısı veya başlangıç yapısı incelenir. Şimdi modeli daha fazla eğitmek için, ilk adımlardan elde edilen bilgiler ve aynı görevde mevcut olan kaynaklar, sınırlı verilerle sonraki modeli eğitmek ve hazırlamak için kullanılır.

Yukarıdaki görselde ajanın ortama göre hareket ettiğini ve yaptıklarıyla ödüllendirildiğini görebiliriz. Burada ajan çevreyi gözlemler ve parametreleri ona göre ayarlar. Buradaki temel fark, temsilcinin önceki ödülleri ve gözlemleri dikkate alması ve bu belirli bilgileri bir sonraki adımı gerçekleştirmek için kullanmasıdır.

Yukarıdaki Görselde bir ajanı ve ortamı görebiliyoruz. Temsilci arka planda işlem yapar ve faaliyetlerine göre ödüllendirilir. Bu süreç birden çok kez gerçekleşir ve ajan önceki gözlemler ve ödüller ile ilgilenir ve bir sonraki adımda ortama göre hareket edecek politikalar yapılır. Bu, modelin görevi sınırlı verilerle ve eğitim için fazla zaman harcamadan çok verimli bir şekilde gerçekleştirmesine yardımcı olacaktır.
Takviye ve Meta-Güçlendirmeli Öğrenme
Pekiştirme modelinin yapısına göre her iki teknik de aynıdır ancak modelin çalışma mekanizmasında aralarında ufak bir fark vardır. Takviyeli öğrenmede, model çevrede eylemler gerçekleştirir ve belirli etkinlikler oluşturmak için sonuçlarla ödüllendirilir. Burada, önceki adımlardan elde edilen veriler veya gözlemler, aşağıdaki eylemi gerçekleştirmek için kullanılmaz.
Meta-güçlendirmeli öğrenmede etmen ortama göre hareket eder ve harekete geçer. Aracı belirli adımlar için ayarı gözlemler ve sonuçlara göre ödüllendirilir. Hayır, bir sonraki adımda, ajan yine ortamlarda hareket eder, ancak burada ajan, önceki adımdaki gözlemleri ve ödülleri de hatırlayacaktır.
Meta-güçlendirmeli öğrenmenin daha hızlı ve daha verimli çalışmasını sağlayan bu ikisi arasındaki temel fark budur. Önceki adımlardan elde edilen bilgiler kaydedilir ve sonraki adımların gerçekleştirilmesine yardımcı olur, bu da modeli sınırlı verilerle bile eğitmeye yardımcı olur.
Sonuç
Bu yazıda pekiştirmeli ve meta pekiştirmeli öğrenme tekniklerini temel fikirleri, çekirdek sezgileri ve çalışma mekanizmalarıyla tartıştık. Bu teknikle ilgili bilgi; kişinin RL algoritmalarının konseptini daha iyi anlamasına yardımcı olur ve bununla ilgili karmaşık görüşme sorularını çok verimli bir şekilde yanıtlamasına olanak tanır.
Bizi Önemli Noktalar bu makaleden:
1. Takviyeli öğrenme, etmen, çevre ve onun eylemleri ve gözlemleriyle ilgilenen bir veri bilimi dalıdır.
2. Normal Pekiştirme algoritmalarında, önceki adımdaki veriler veya gözlemler bir sonraki görevi gerçekleştirmek için kullanılmaz.
3. Meta-güçlendirmeli öğrenmede, önceki adımın gözlemleri ve ödülleri kaydedilir ve aracının eylemlerinin bir sonraki dönemine dahil edilir.
4. Meta-Güçlendirmeli öğrenme, yalnızca sınırlı miktarda verinin mevcut olduğu ve çalışmanın daha fazla zaman almadan hızlı bir şekilde tamamlanması gereken görevleri gerçekleştirmek için faydalı olabilir.
Yazarla İletişime Geçmek İster misiniz?
Parth Shukla'yı takip edin @AnalitikVidhya, LinkedIn, Twitter, ve Orta daha fazla içerik için.
Parth Shukla ile iletişime geçin @Parth Şukla | portföy or Parth Şukla | E-posta benimle iletişime geçmek için
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2022/12/meta-reinforcement-learning-in-data-science/
- a
- Hakkımızda
- yukarıdaki
- Göre
- doğruluk
- Başarmak
- Hareket
- Action
- eylemler
- faaliyetler
- eylemler
- Danışman
- algoritma
- algoritmalar
- miktar
- analytics
- ve
- cevap
- yaklaşım
- uygun
- uygun olarak
- göre
- yazar
- otomatik olarak
- mevcut
- ödül
- layık
- arka fon
- temel
- temel
- arkasında
- olmak
- faydalı
- İYİ
- Daha iyi
- arasında
- şube
- hangi
- dava
- durumlarda
- sınıflandırılmış
- Tamamlandı
- karmaşık
- karmaşıklık
- hesaplamalar
- kavram
- UAF ile
- içerik
- çekirdek
- veri
- veri bilimi
- Fırsatlar
- bağlı
- fark
- takdir
- tartışmak
- tartışılan
- kolay
- kolayca
- verimli biçimde
- çevre
- ortamları
- çağ
- Eter (ETH)
- Hatta
- örnek
- HIZLI
- Daha hızlı
- Fed
- takip etme
- Airdrop Formu
- itibaren
- daha fazla
- gelecek
- Tercih Etmenizin
- yardım et
- yardımcı olur
- okuyun
- Yüksek
- daha yüksek
- Ne kadar
- HTTPS
- Fikir
- görüntü
- in
- dahil
- bilgi
- ilk
- başlangıçta
- giriş
- görüşme
- görüşme soruları
- tanıtmak
- IT
- bilgi
- öğrenme
- Sınırlı
- bakıyor
- makine
- makine öğrenme
- yapılmış
- Ana
- YAPAR
- mekanizma
- medya
- ML
- model
- modelleri
- Daha
- çoğu
- hareket
- çoklu
- gerek
- ihtiyaçlar
- ağlar
- nöral ağlar
- sonraki
- gözlemler
- ONE
- Sahip olunan
- parametreler
- Bölüm
- belirli
- yapmak
- icra
- yer
- Platon
- Plato Veri Zekası
- PlatoVeri
- noktaları
- politikaları
- mümkün
- güçler
- Hazırlamak
- mevcut
- önceki
- Sorun
- süreç
- sağlanan
- yayınlanan
- koymak
- Sorular
- hızla
- kaydedilmiş
- düzenli
- ilgili
- hatırlamak
- gerektirir
- gerektirir
- Kaynaklar
- Sonuçlar
- ödüllendirdi
- "Rewards"
- aynı
- Bilim
- ayar
- gösterilen
- önemli
- boyutları
- biraz
- aşamaları
- başlama
- Eyalet
- Açıklama
- kalmak
- adım
- Basamaklar
- yapı
- okudu
- Ders çalışma
- başarılı
- böyle
- sistem
- alır
- alma
- Görev
- görevleri
- teknikleri
- The
- ve bazı Asya
- işler
- üç
- zaman
- zamanlar
- için
- Tren
- eğitilmiş
- Eğitim
- ezgileri
- türleri
- anlamak
- Geniş
- hangi
- irade
- olmadan
- İş
- çalışma
- zefirnet