Çok etiketli NLP, belirli bir metin girişine tek bir etiket yerine birden çok etiket atama görevini ifade eder. Metin sınıflandırması veya duyarlılık analizi gibi geleneksel NLP görevlerinde, her girdiye içeriğine göre tipik olarak tek bir etiket atanır. Bununla birlikte, birçok gerçek dünya senaryosunda, bir metin parçası birden çok kategoriye ait olabilir veya aynı anda birden çok duyguyu ifade edebilir.
Çok etiketli NLP önemlidir çünkü metin verilerinden daha incelikli ve karmaşık bilgiler yakalamamıza izin verir. Örneğin, müşteri geri bildirim analizi alanında, bir müşteri incelemesi aynı anda hem olumlu hem de olumsuz duyguları ifade edebilir veya bir ürün veya hizmetin birden çok yönüne değinebilir. Bu tür girdilere birden çok etiket atayarak, müşterinin geri bildirimlerini daha kapsamlı bir şekilde anlayabilir ve endişelerini gidermek için daha hedefli eylemler gerçekleştirebiliriz.
Bu makale, Provectus'un çok etiketli NLP kullanımıyla ilgili kayda değer bir vakayı incelemektedir.
Arka Plan:
Bir müşteri, kendisine yardım etme talebiyle bize ulaştı. belirli bir türdeki etiketleme belgelerini otomatikleştirin. İlk bakışta, görev basit ve kolayca çözülebilir gibi görünüyordu. Ancak vaka üzerinde çalışırken tutarsız açıklamalara sahip bir veri kümesiyle karşılaştık. Müşterimiz, zaman içinde değişen sınıf sayıları ve inceleme ekibindeki değişikliklerle ilgili zorluklarla karşılaşmış olsa da, bir dizi ek açıklama içeren çeşitli bir veri kümesi oluşturmak için önemli çabalar sarf etmişti. Etiketlerde bazı dengesizlikler ve belirsizlikler olsa da, bu veri seti analiz ve daha fazla araştırma için değerli bir fırsat sağladı.
Veri kümesine daha yakından bakalım, ölçümleri ve yaklaşımımızı inceleyelim ve Provectus'un çok etiketli metin sınıflandırma sorununu nasıl çözdüğünü özetleyelim.
Veri setinde 14,354 benzersiz sınıf (etiket) ile 124 gözlem vardır. Görevimiz, her gözleme bir veya daha fazla sınıf atamaktır.
Tablo 1, veri kümesi için tanımlayıcı istatistikler sağlar.
Ortalama olarak, tek bir sınıfı tanımlayan ortalama 261 farklı metinle, gözlem başına yaklaşık iki sınıfımız var.

Tablo 1: Veri Kümesi İstatistiği
Şekil 1'de, üst grafikte sınıfların dağılımını görüyoruz ve veri setinde en yüksek oluşum sıklığına sahip belirli sayıda HEAD etiketimiz var. Ayrıca, sınıfların çoğunluğunun düşük bir oluşum sıklığına sahip olduğuna dikkat edin.
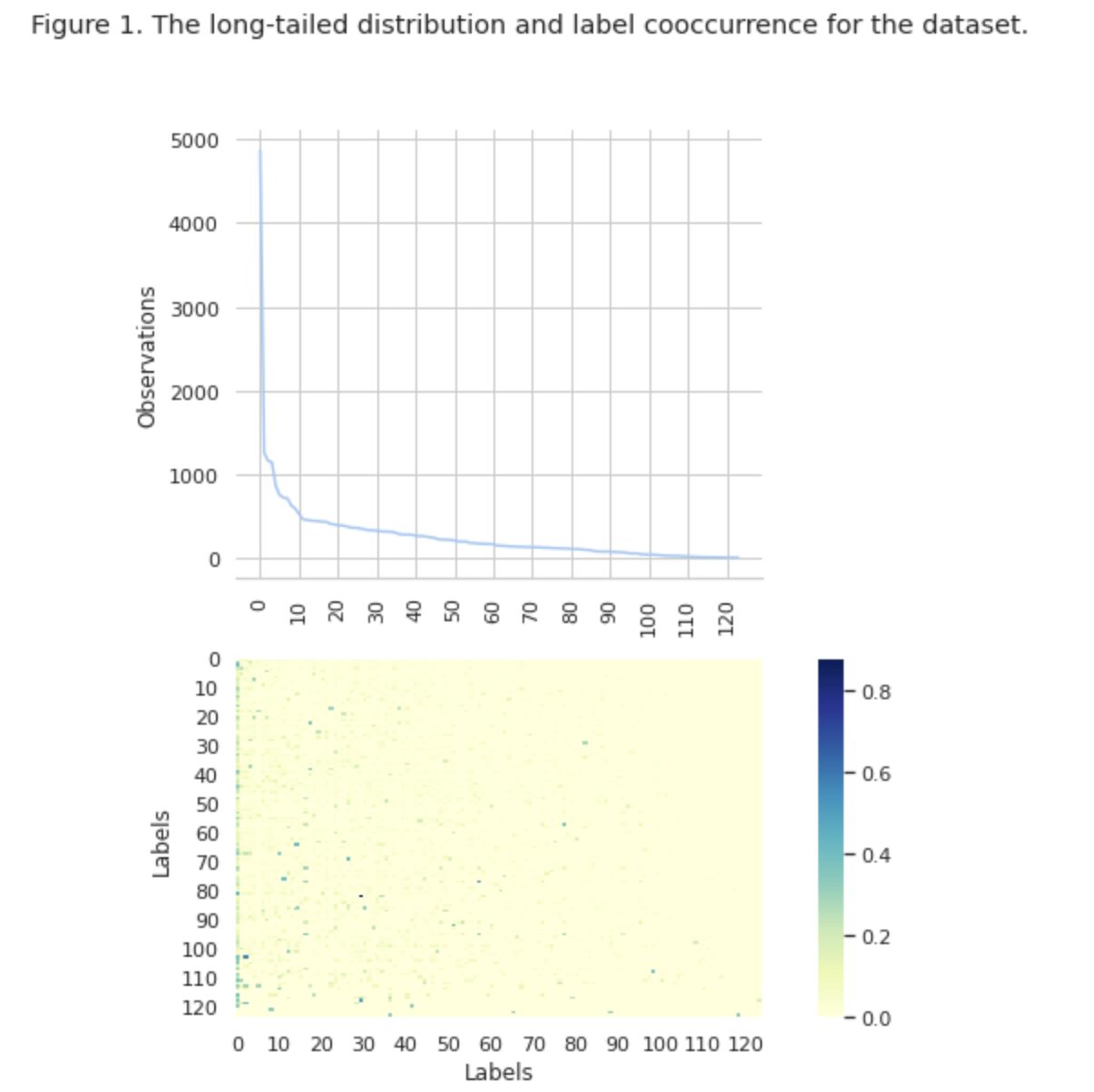
Alttaki grafikte, veri setinde en iyi temsil edilen sınıflar ile düşük öneme sahip sınıflar arasında sık sık çakışma olduğunu görüyoruz.
Veri kümesini tren/değer/test kümelerine bölme sürecini değiştirdik. Geleneksel bir yöntem kullanmak yerine, etiket ilişkilerinin kanıtlarının iyi dengelenmiş bir dağılımını sağlamak için yinelemeli katmanlaştırmayı kullandık. Bunun için kullandık Scikit çoklu öğrenme
from skmultilearn.model_selection import iterative_train_test_split mlb = MultiLabelBinarizer() def balanced_split(df, mlb, test_size=0.5): ind = np.expand_dims(np.arange(len(df)), axis=1) mlb.fit_transform(df["tag"]) labels = mlb.transform(df["tag"]) ind_train, _, ind_test, _ = iterative_train_test_split( ind, labels, test_size ) return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:, 0]] df_train, df_tmp = balanced_split(df, test_size=0.4)
df_val, df_test = balanced_split(df_tmp, test_size=0.5)
Aşağıdaki dağılımı elde ettik:
- Eğitim veri seti, verilerin %60'ını içerir ve 124 etiketin tamamını kapsar
- Doğrulama veri seti, verilerin %20'sini içerir ve 124 etiketin tamamını kapsar
- Test veri seti, verilerin %20'sini içerir ve 124 etiketin tamamını kapsar
Çok etiketli sınıflandırma, tek bir veri örneğine birden çok etiket atamamıza izin veren bir tür denetimli makine öğrenimi algoritmasıdır. Modelin yalnızca iki kategoriyi tahmin ettiği ikili sınıflandırmadan ve modelin bir örnek için birden çok sınıftan yalnızca birini tahmin ettiği çok sınıflı sınıflandırmadan farklıdır.
Çok etiketli sınıflandırma performansı için değerlendirme ölçütleri, sınıflandırma probleminin doğasında var olan farklılıklar nedeniyle çok sınıflı (veya ikili) sınıflandırmada kullanılanlardan doğası gereği farklıdır. Daha ayrıntılı bilgi Wikipedia'da bulunabilir.
Bize en uygun metrikleri seçtik:
- Hassas model tarafından yapılan toplam pozitif tahminler arasındaki gerçek pozitif tahminlerin oranını ölçer.
- Geri çağırmak tüm gerçek pozitif örnekler arasındaki gerçek pozitif tahminlerin oranını ölçer.
- F1-skor kesinlik ve geri çağırmanın harmonik ortalamasıdır ve ikisi arasındaki dengeyi yeniden sağlamaya yardımcı olur.
- Hamming kaybı yanlış tahmin edilen etiketlerin oranıdır
biz de takip ediyoruz tahmin edilen etiket sayısı kümede { etiket sayısı olarak tanımlanır, bunun için F1 puanı > 0 elde ederiz}.
Çok Etiketli Sınıflandırma, her örneğin yalnızca tek bir sınıf etiketiyle ilişkilendirildiği geleneksel tek etiketli sınıflandırmanın aksine, tek bir örneğin veya örneğin birden çok etiket veya sınıflandırmayla ilişkilendirilebildiği bir tür denetimli öğrenme problemidir.
Çok etiketli sınıflandırma problemlerini çözmek için iki ana teknik kategorisi vardır:
- Problem dönüştürme yöntemleri
- Algoritma uyarlama yöntemleri
Problem dönüştürme yöntemleri, çok etiketli sınıflandırma görevlerini birden çok tek etiketli sınıflandırma görevlerine dönüştürmemizi sağlar. Örneğin, İkili İlişki (BR) temel yaklaşımı, her etiketi ayrı bir ikili sınıflandırma problemi olarak ele alır. Bu durumda, çok etiketli problem, çoklu tek etiketli problemlere dönüştürülür.
Algoritma uyarlama yöntemleri, görevi birden çok tek etiketli sınıflandırma görevine dönüştürmeden, çok etiketli verileri yerel olarak işlemek için algoritmaların kendisini değiştirir. Bu yaklaşımın bir örneği, BERT modeliçok etiketli metin sınıflandırması da dahil olmak üzere çeşitli NLP görevleri için ince ayar yapılabilen, önceden eğitilmiş dönüştürücü tabanlı bir dil modelidir. BERT, problem dönüşümüne ihtiyaç duymadan çok etiketli verileri doğrudan işlemek için tasarlanmıştır.
Çok etiketli metin sınıflandırması için BERT kullanma bağlamında, standart yaklaşım, kayıp fonksiyonu olarak Binary Cross-Entropy (BCE) kaybını kullanmaktır. BCE kaybı, ikili sınıflandırma problemleri için yaygın olarak kullanılan bir kayıp fonksiyonudur ve her bir etiket için kaybı bağımsız olarak hesaplayarak ve ardından kayıpları toplayarak çok etiketli sınıflandırma problemlerini ele alacak şekilde kolayca genişletilebilir. Bu durumda, BCE kayıp fonksiyonu, tahmin edilen olasılıklar ile gerçek etiketler arasındaki hatayı ölçer; burada tahmin edilen olasılıklar, BERT modelindeki son sigmoid aktivasyon katmanından elde edilir.
Şimdi aşağıdaki Şekil 2'ye daha yakından bakalım.
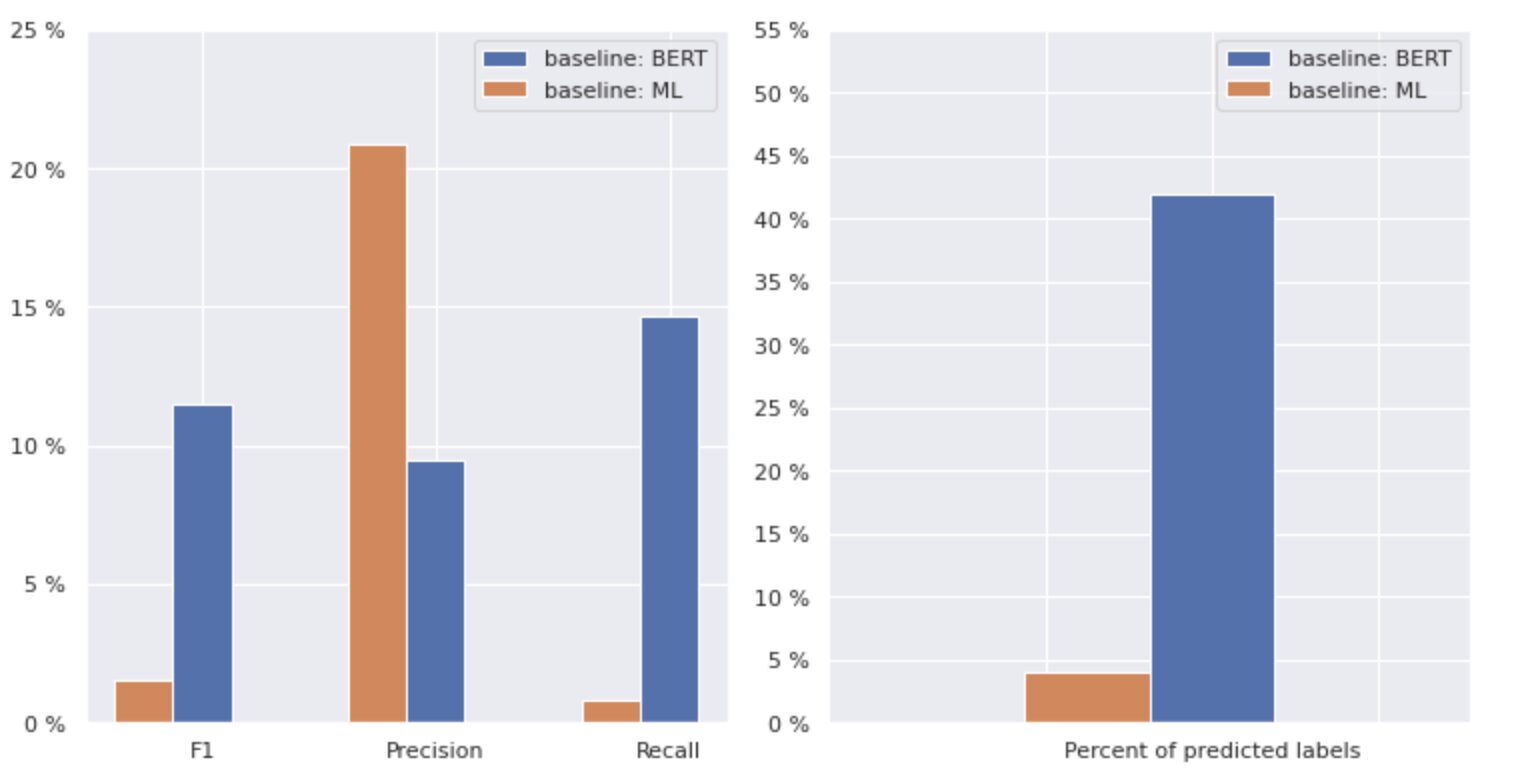
Şekil 2. Temel modeller için ölçümler
Soldaki grafik, "temel: BERT" ve "temel: ML" için metriklerin karşılaştırmasını gösterir. Böylece, “temel: BERT” için F1 ve Geri Çağırma puanlarının yaklaşık 1.5 kat daha yüksek olduğu, “temel: ML” için Kesinliğin ise model 2'den 1 kat daha yüksek olduğu görülebilir. sağda gösterilen tahmini sınıflar, "temel: BERT"nin sınıfları "temel: ML"den 10 kat daha fazla tahmin ettiğini görüyoruz.
"Temel: BERT" için maksimum sonuç tüm sınıfların %50'sinden az olduğundan, sonuçlar oldukça cesaret kırıcıdır. Bu sonuçları nasıl iyileştirebileceğimizi bulalım.
Seçkin makaleye dayanarak “Uzun Kuyruklu Sınıf Dağılımı ile Çok Etiketli Metin Sınıflandırması için Dengeleme Yöntemleri”, dağıtım dengeli kayıp bizim için en uygun yaklaşım olabileceğini öğrendik.
Dağıtım dengeli kayıp
Dağılım dengeli kayıp, sınıf dağılımındaki dengesizlikleri ele almak için çok etiketli metin sınıflandırma problemlerinde kullanılan bir tekniktir. Bu problemlerde, bazı sınıfların diğerlerine kıyasla çok daha yüksek oluşma sıklığı vardır, bu da modelin bu daha sık sınıflara doğru yanlı olmasına neden olur.
Bu konuyu ele almak için dağılım dengeli kayıp, kayıp fonksiyonundaki her örneğin katkısını dengelemeyi amaçlar. Bu, veri kümesindeki görülme sıklığının tersine dayalı olarak her örneğin kaybının yeniden ağırlıklandırılmasıyla elde edilir. Bunu yaparak, daha az sıklıkta yapılan sınıfların katkısı artırılır ve daha sık yapılan sınıfların katkısı azaltılır, böylece genel sınıf dağılımı dengelenir.
Bu tekniğin, uzun kuyruklu sınıf dağılım problemlerinde modellerin performansını iyileştirmede etkili olduğu gösterilmiştir. Model, sık sınıfların etkisini azaltarak ve seyrek sınıfların etkisini artırarak, verilerdeki kalıpları daha iyi yakalayabilir ve daha dengeli tahminler üretebilir.

Yeniden Örnekleme Sınıfının Uygulanması
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np class ResampleLoss(nn.Module): def __init__( self, use_sigmoid=True, partial=False, loss_weight=1.0, reduction="mean", reweight_func=None, weight_norm=None, focal=dict(focal=True, alpha=0.5, gamma=2), map_param=dict(alpha=10.0, beta=0.2, gamma=0.1), CB_loss=dict(CB_beta=0.9, CB_mode="average_w"), logit_reg=dict(neg_scale=5.0, init_bias=0.1), class_freq=None, train_num=None, ): super(ResampleLoss, self).__init__() assert (use_sigmoid is True) or (partial is False) self.use_sigmoid = use_sigmoid self.partial = partial self.loss_weight = loss_weight self.reduction = reduction if self.use_sigmoid: if self.partial: self.cls_criterion = partial_cross_entropy else: self.cls_criterion = binary_cross_entropy else: self.cls_criterion = cross_entropy # reweighting function self.reweight_func = reweight_func # normalization (optional) self.weight_norm = weight_norm # focal loss params self.focal = focal["focal"] self.gamma = focal["gamma"] self.alpha = focal["alpha"] # mapping function params self.map_alpha = map_param["alpha"] self.map_beta = map_param["beta"] self.map_gamma = map_param["gamma"] # CB loss params (optional) self.CB_beta = CB_loss["CB_beta"] self.CB_mode = CB_loss["CB_mode"] self.class_freq = ( torch.from_numpy(np.asarray(class_freq)).float().cuda() ) self.num_classes = self.class_freq.shape[0] self.train_num = train_num # only used to be divided by class_freq # regularization params self.logit_reg = logit_reg self.neg_scale = ( logit_reg["neg_scale"] if "neg_scale" in logit_reg else 1.0 ) init_bias = ( logit_reg["init_bias"] if "init_bias" in logit_reg else 0.0 ) self.init_bias = ( -torch.log(self.train_num / self.class_freq - 1) * init_bias ) self.freq_inv = ( torch.ones(self.class_freq.shape).cuda() / self.class_freq ) self.propotion_inv = self.train_num / self.class_freq def forward( self, cls_score, label, weight=None, avg_factor=None, reduction_override=None, **kwargs ): assert reduction_override in (None, "none", "mean", "sum") reduction = ( reduction_override if reduction_override else self.reduction ) weight = self.reweight_functions(label) cls_score, weight = self.logit_reg_functions( label.float(), cls_score, weight ) if self.focal: logpt = self.cls_criterion( cls_score.clone(), label, weight=None, reduction="none", avg_factor=avg_factor, ) # pt is sigmoid(logit) for pos or sigmoid(-logit) for neg pt = torch.exp(-logpt) wtloss = self.cls_criterion( cls_score, label.float(), weight=weight, reduction="none" ) alpha_t = torch.where(label == 1, self.alpha, 1 - self.alpha) loss = alpha_t * ((1 - pt) ** self.gamma) * wtloss loss = reduce_loss(loss, reduction) else: loss = self.cls_criterion( cls_score, label.float(), weight, reduction=reduction ) loss = self.loss_weight * loss return loss def reweight_functions(self, label): if self.reweight_func is None: return None elif self.reweight_func in ["inv", "sqrt_inv"]: weight = self.RW_weight(label.float()) elif self.reweight_func in "rebalance": weight = self.rebalance_weight(label.float()) elif self.reweight_func in "CB": weight = self.CB_weight(label.float()) else: return None if self.weight_norm is not None: if "by_instance" in self.weight_norm: max_by_instance, _ = torch.max(weight, dim=-1, keepdim=True) weight = weight / max_by_instance elif "by_batch" in self.weight_norm: weight = weight / torch.max(weight) return weight def logit_reg_functions(self, labels, logits, weight=None): if not self.logit_reg: return logits, weight if "init_bias" in self.logit_reg: logits += self.init_bias if "neg_scale" in self.logit_reg: logits = logits * (1 - labels) * self.neg_scale + logits * labels if weight is not None: weight = ( weight / self.neg_scale * (1 - labels) + weight * labels ) return logits, weight def rebalance_weight(self, gt_labels): repeat_rate = torch.sum( gt_labels.float() * self.freq_inv, dim=1, keepdim=True ) pos_weight = ( self.freq_inv.clone().detach().unsqueeze(0) / repeat_rate ) # pos and neg are equally treated weight = ( torch.sigmoid(self.map_beta * (pos_weight - self.map_gamma)) + self.map_alpha ) return weight def CB_weight(self, gt_labels): if "by_class" in self.CB_mode: weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) elif "average_n" in self.CB_mode: avg_n = torch.sum( gt_labels * self.class_freq, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, avg_n)).cuda() ) elif "average_w" in self.CB_mode: weight_ = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) weight = torch.sum( gt_labels * weight_, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) elif "min_n" in self.CB_mode: min_n, _ = torch.min( gt_labels * self.class_freq + (1 - gt_labels) * 100000, dim=1, keepdim=True, ) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, min_n)).cuda() ) else: raise NameError return weight def RW_weight(self, gt_labels, by_class=True): if "sqrt" in self.reweight_func: weight = torch.sqrt(self.propotion_inv) else: weight = self.propotion_inv if not by_class: sum_ = torch.sum(weight * gt_labels, dim=1, keepdim=True) weight = sum_ / torch.sum(gt_labels, dim=1, keepdim=True) return weight def reduce_loss(loss, reduction): """Reduce loss as specified. Args: loss (Tensor): Elementwise loss tensor. reduction (str): Options are "none", "mean" and "sum". Return: Tensor: Reduced loss tensor. """ reduction_enum = F._Reduction.get_enum(reduction) # none: 0, elementwise_mean:1, sum: 2 if reduction_enum == 0: return loss elif reduction_enum == 1: return loss.mean() elif reduction_enum == 2: return loss.sum() def weight_reduce_loss(loss, weight=None, reduction="mean", avg_factor=None): """Apply element-wise weight and reduce loss. Args: loss (Tensor): Element-wise loss. weight (Tensor): Element-wise weights. reduction (str): Same as built-in losses of PyTorch. avg_factor (float): Avarage factor when computing the mean of losses. Returns: Tensor: Processed loss values. """ # if weight is specified, apply element-wise weight if weight is not None: loss = loss * weight # if avg_factor is not specified, just reduce the loss if avg_factor is None: loss = reduce_loss(loss, reduction) else: # if reduction is mean, then average the loss by avg_factor if reduction == "mean": loss = loss.sum() / avg_factor # if reduction is 'none', then do nothing, otherwise raise an error elif reduction != "none": raise ValueError( 'avg_factor can not be used with reduction="sum"' ) return loss def binary_cross_entropy( pred, label, weight=None, reduction="mean", avg_factor=None
): # weighted element-wise losses if weight is not None: weight = weight.float() loss = F.binary_cross_entropy_with_logits( pred, label.float(), weight, reduction="none" ) loss = weight_reduce_loss( loss, reduction=reduction, avg_factor=avg_factor ) return loss
DBL kaybı
loss_func = ResampleLoss( reweight_func="rebalance", loss_weight=1.0, focal=dict(focal=True, alpha=0.5, gamma=2), logit_reg=dict(init_bias=0.05, neg_scale=2.0), map_param=dict(alpha=0.1, beta=10.0, gamma=0.405), class_freq=class_freq, train_num=train_num,
) """
class_freq - list of frequencies for each class,
train_num - size of train dataset """
Veri setini yakından inceleyerek, parametrenin şu sonuca vardık:
= 0.405.
eşik ayarı
Modelimizi geliştirmenin bir diğer adımı, hem eğitim aşamasında hem de doğrulama ve test aşamalarında eşiği ayarlama süreciydi. f1 skoru, kesinlik ve geri çağırma gibi metriklerin eşik düzeyine bağımlılıklarını hesapladık ve en yüksek metrik puanına göre eşiği seçtik. Aşağıda bu sürecin fonksiyon uygulamasını görebilirsiniz.
Eşiği ayarlayarak F1 puanının optimizasyonu:
def optimise_f1_score(true_labels: np.ndarray, pred_labels: np.ndarray): best_med_th = 0.5 true_bools = [tl == 1 for tl in true_labels] micro_thresholds = (np.array(range(-45, 15)) / 100) + best_med_th f1_results, pre_results, recall_results = [], [], [] for th in micro_thresholds: pred_bools = [pl > th for pl in pred_labels] test_f1 = f1_score(true_bools, pred_bools, average="micro", zero_division=0) test_precision = precision_score( true_bools, pred_bools, average="micro", zero_division=0 ) test_recall = recall_score( true_bools, pred_bools, average="micro", zero_division=0 ) f1_results.append(test_f1) prec_results.append(test_precision) recall_results.append(test_recall) best_f1_idx = np.argmax(f1_results) return micro_thresholds[best_f1_idx]Değerlendirme ve taban çizgisiyle karşılaştırma
Bu yaklaşımlar, yeni bir model geliştirmemize ve taban çizgisiyle karşılaştırılan aşağıdaki sonucu elde etmemize olanak sağladı: Aşağıdaki Şekil 3'teki BERT.

Şekil 3. Temel ve daha yeni yaklaşıma göre karşılaştırma ölçümleri.
Sınıflandırmayla ilgili metrikleri karşılaştırarak, performans ölçülerinde neredeyse 5-6 kat önemli bir artış görüyoruz:
F1 puanı %12 → %55'ten yükselirken, Kesinlik %9'dan %59'a ve Geri Çağırma %15'ten → %51'e yükseldi.
Şekil 3'teki sağ grafikte gösterilen değişikliklerle artık sınıfların %80'ini tahmin edebiliyoruz.
Sınıf dilimleri
Etiketlerimizi dört gruba ayırdık: HEAD, MEDIUM, TAIL ve ZERO. Her grup, benzer miktarda destekleyici veri gözlemi içeren etiketler içerir.
Şekil 4'te görüldüğü gibi, grupların dağılımları belirgindir. Gül kutusu (HEAD) negatif çarpık bir dağılıma sahip, orta kutu (ORTA) pozitif çarpık bir dağılıma sahip ve yeşil kutu (KUYRUK) normal dağılıma sahip görünüyor.
Tüm gruplar ayrıca kutu çiziminde bıyıkların dışındaki noktalar olan aykırı değerlere sahiptir. HEAD grubunun bir MAJOR sınıfı üzerinde büyük etkisi vardır.
Ek olarak, veri setindeki minimum oluşum sayısı nedeniyle (tüm gözlemlerin %3'ünden azı) modelin öğrenemediği ve tanıyamadığı etiketleri içeren “ZERO” adlı ayrı bir grup belirledik.
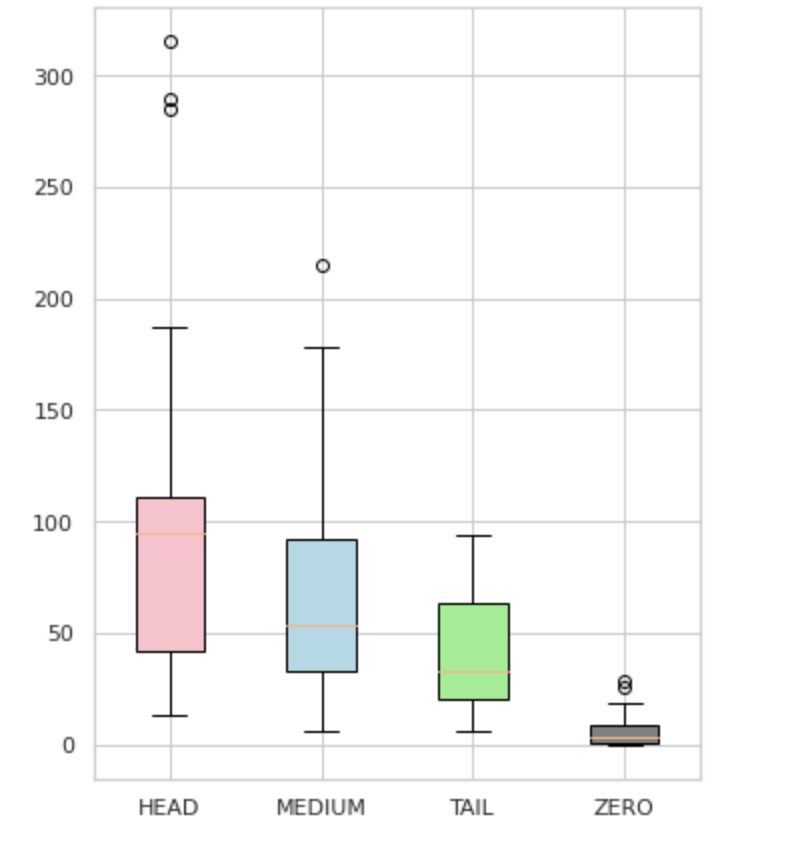
Şekil 4. Gruplara karşı etiket sayıları
Tablo 2, verilerin test alt kümesi için her bir etiket grubu başına metrikler hakkında bilgi sağlar.
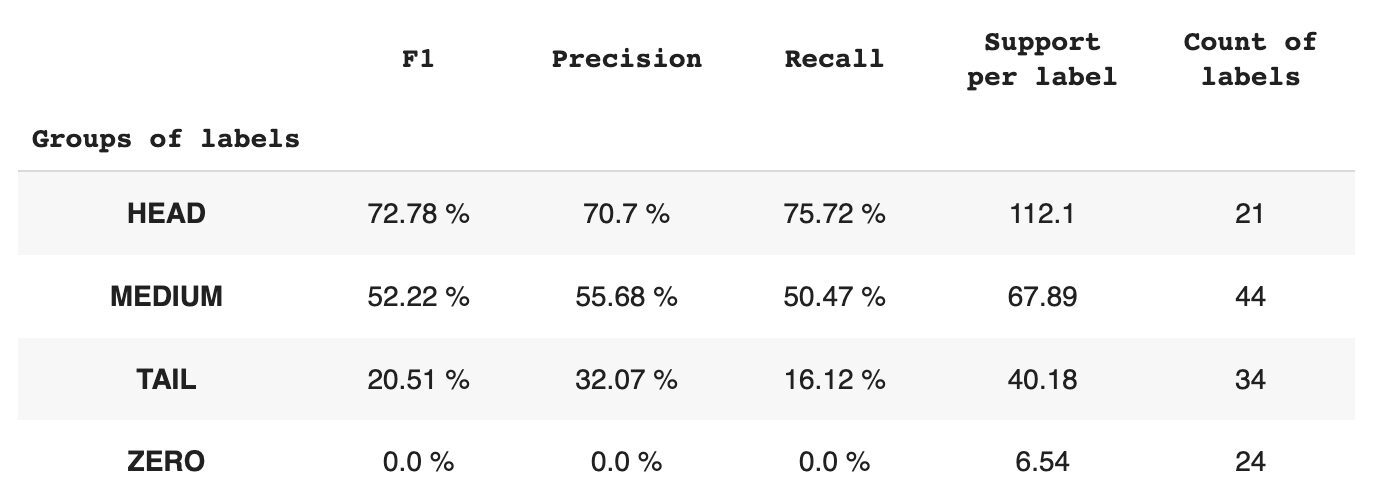
Tablo 2. Grup başına ölçümler.
- HEAD grubu, etiket başına ortalama 21 destek gözlemi içeren 112 etiket içerir. Bu grup aykırı değerlerden etkilenir ve veri kümesindeki yüksek temsilinden dolayı ölçümleri yüksektir: F1 - %73, Kesinlik - %71, Geri Çağırma - %75.
- MEDIUM grubu, HEAD grubundan yaklaşık iki kat daha düşük olan ortalama 44 gözlem desteğine sahip 67 etiketten oluşur. Bu grup için metriklerin %50 oranında düşmesi bekleniyor: F1 – %52, Kesinlik – %56, Geri Çağırma – %51.
- TAIL grubu, en fazla sayıda sınıfa sahiptir, ancak tümü, etiket başına ortalama 40 destek gözlemi ile veri kümesinde zayıf bir şekilde temsil edilir. Sonuç olarak, metrikler önemli ölçüde düşer: F1 - %21, Kesinlik - %32, Geri Çağırma - %16.
- ZERO grubu, potansiyel olarak veri kümesindeki düşük oluşumları nedeniyle modelin hiç tanıyamadığı sınıfları içerir. Bu gruptaki 24 etiketin her birinin ortalama 7 destek gözlemi vardır.
Şekil 5, Tablo 2'de sunulan bilgileri görselleştirerek etiket grubu başına metriklerin görsel bir sunumunu sağlar.
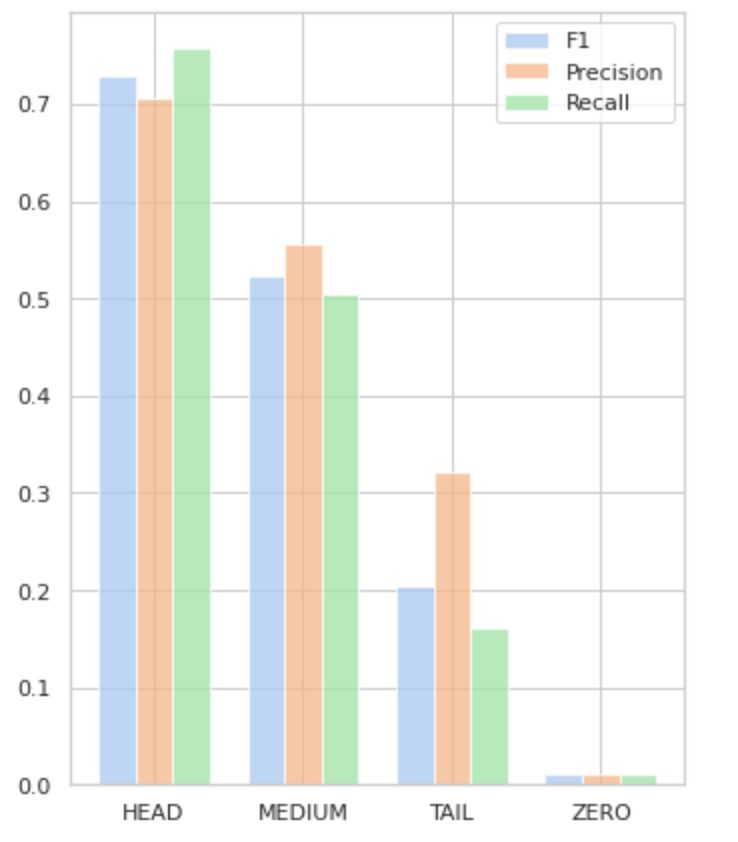
Şekil 5. Metrikler ve etiket grupları. Tüm SIFIR değerleri = 0.
Bu kapsamlı makalede, görünüşte basit olan çok etiketli metin sınıflandırma görevinin, geleneksel yöntemler uygulandığında zorlayıcı olabileceğini gösterdik. Sınıf dengesizliği sorununu çözmek için dağıtım dengeleme kayıp fonksiyonlarının kullanılmasını önerdik.
Önerdiğimiz yaklaşımın performansını klasik yöntemle karşılaştırdık ve gerçek dünya iş ölçümlerini kullanarak değerlendirdik. Sonuçlar, sınıf dengesizliklerini ve etiket birlikte oluşumlarını ele almak için kayıp fonksiyonlarını kullanmanın çok etiketli metin sınıflandırması için uygun bir çözüm sunduğunu göstermektedir.
Önerilen kullanım örneği, çok etiketli metin sınıflandırmasıyla uğraşırken farklı yaklaşımları ve teknikleri göz önünde bulundurmanın önemini ve sınıf dengesizliklerini ele alırken dağıtım dengeleme kayıp fonksiyonlarının potansiyel faydalarını vurgulamaktadır.
Benzer bir sorunla karşı karşıyaysanız ve belge işleme operasyonlarını kolaylaştırın kuruluşunuz içinde, lütfen benimle veya Provectus ekibiyle iletişime geçin. Süreçlerinizi otomatikleştirmek için daha verimli yöntemler bulmanıza yardımcı olmaktan memnuniyet duyarız.
Oleksii Babych Provectus'ta bir Makine Öğrenimi Mühendisidir. Fizik geçmişi ile mükemmel analitik ve matematik becerilerine sahiptir ve bilimsel araştırmalar ve SPIE Photonics West dahil olmak üzere uluslararası konferans sunumları yoluyla değerli deneyimler kazanmıştır. Oleksii, sağlık ve fintech sektörleri için uçtan uca, büyük ölçekli AI/ML çözümleri oluşturma konusunda uzmanlaşmıştır. İş sorunlarını belirlemekten üretim makine öğrenimi modellerini dağıtmaya ve çalıştırmaya kadar makine öğrenimi geliştirme yaşam döngüsünün her aşamasında yer alır.
Rinat Akhmetov Provectus'ta Makine Öğrenimi Çözüm Mimarıdır. Makine Öğreniminde (özellikle Bilgisayarla Görme alanında) sağlam bir pratik geçmişe sahip olan Rinat, en büyük ikinci tutkusu programlama olan bir inek, veri meraklısı, yazılım mühendisi ve işkoliktir. Provectus'ta Rinat, konsept aşamalarının keşfedilmesi ve kanıtlanmasından sorumludur ve karmaşık yapay zeka projelerinin yürütülmesine liderlik eder.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/2023/03/multilabel-nlp-analysis-class-imbalance-loss-function-approaches.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-label-nlp-an-analysis-of-class-imbalance-and-loss-function-approaches
- :dır-dir
- 1
- 10
- 100
- %15
- 67
- 7
- 9
- a
- Yapabilmek
- Hakkımızda
- Başarmak
- elde
- eylemler
- Etkinleştirme
- adaptasyon
- adres
- adresleme
- AI
- AI / ML
- Amaçları
- algoritma
- algoritmalar
- Türkiye
- veriyor
- Alfa
- arasında
- miktar
- analiz
- Analitik
- analiz
- ve
- çıktı
- uygulamalı
- Tamam
- yaklaşım
- yaklaşımlar
- yaklaşık olarak
- ARE
- göre
- AS
- yönleri
- atanmış
- yardım
- ilişkili
- At
- ayrıca otomasyonun
- ortalama
- arka fon
- Bakiye
- merkezli
- Temel
- BE
- Çünkü
- altında
- faydaları
- İYİ
- beta
- Daha iyi
- arasında
- önyargı
- Biggest
- Alt
- kutu
- yerleşik
- iş
- by
- hesaplanmış
- CAN
- yapamam
- ele geçirmek
- dava
- kategoriler
- CB
- belli
- zorluklar
- zor
- değişiklikler
- ücret
- sınıf
- sınıflar
- klasik
- sınıflandırma
- müşteri
- yakından
- yakın
- çoğunlukla
- karşılaştırıldığında
- karşılaştırarak
- karşılaştırma
- karmaşık
- kapsamlı
- bilgisayar
- Bilgisayar görüşü
- bilgisayar
- kavram
- Endişeler
- sonucuna
- Konferans
- düşünen
- UAF ile
- içeren
- içerik
- bağlam
- katkı
- kapaklar
- Oluşturma
- müşteri
- devir
- veri
- ilgili
- azaltmak
- tanımlı
- göstermek
- gösterdi
- dağıtma
- tasarlanmış
- detaylı
- gelişme
- farklılıkları
- farklı
- direkt olarak
- keşif
- farklı
- dağıtım
- Dağılımlar
- çeşitli
- bölünmüş
- belge
- evraklar
- yapıyor
- domain
- Damla
- her
- kolayca
- Etkili
- verimli
- çabaları
- etkinleştirmek
- son uca
- mühendis
- hayran
- eşit olarak
- hata
- özellikle
- Eter (ETH)
- değerlendirilir
- Her
- kanıt
- örnek
- mükemmel
- infaz
- beklenen
- deneyim
- keşif
- keşfetmek
- ekspres
- f1
- yüzlü
- karşı
- geribesleme
- şekil
- son
- bulma
- fintech
- Ad
- Şamandıra
- takip etme
- İçin
- bulundu
- kesir
- Sıklık
- sık
- itibaren
- işlev
- fonksiyonel
- fonksiyonlar
- daha fazla
- Kazanç
- verilmiş
- Bakış
- grafik
- Yeşil
- grup
- Grubun
- sap
- mutlu
- Var
- baş
- sağlık
- yardım et
- yardımcı olur
- Yüksek
- daha yüksek
- en yüksek
- özeti
- Ne kadar
- Nasıl Yapılır
- Ancak
- HTML
- http
- HTTPS
- tespit
- belirlenmesi
- dengesizlik
- darbe
- etkiledi
- uygulama
- ithalat
- önem
- önemli
- iyileştirmek
- geliştirme
- in
- içerir
- Dahil olmak üzere
- hatalı olarak
- Artırmak
- artmış
- artan
- bağımsız
- Endüstri
- bilgi
- doğal
- giriş
- örnek
- yerine
- Uluslararası
- yatırım
- ilgili
- konu
- IT
- ONUN
- jpg
- sadece bir
- KDNuggets
- etiket
- etiketleme
- Etiketler
- dil
- büyük ölçekli
- büyük
- tabaka
- İlanlar
- ÖĞRENİN
- öğrendim
- öğrenme
- seviye
- hayat
- Liste
- Bakın
- kayıp
- kayıp
- Düşük
- makine
- makine öğrenme
- yapılmış
- Ana
- büyük
- çoğunluk
- çok
- haritalama
- matematik
- maksimum
- önlemler
- orta
- yöntem
- yöntemleri
- metrik
- Metrikleri
- en az
- ML
- MLB
- model
- modelleri
- değiştirmek
- modül
- Daha
- daha verimli
- çoğu
- çoklu
- adlı
- gerek
- negatif
- olumsuz
- yeni
- nlp
- normal
- dikkate değer
- numara
- sayılar
- dizi
- elde etmek
- elde
- of
- teklif
- on
- ONE
- Fırsat
- karşı
- Opsiyonlar
- kuruluşlar
- Diğer
- aksi takdirde
- dışında
- ödenmemiş
- tüm
- parametre
- tutku
- desen
- yüzde
- performans
- Fizik
- parça
- Platon
- Plato Veri Zekası
- PlatoVeri
- Lütfen
- noktaları
- POS
- pozitif
- potansiyel
- potansiyel
- Pratik
- Hassas
- tahmin
- tahmin
- Tahminler
- öngörür
- Sunumlar
- sundu
- Sorun
- sorunlar
- süreç
- Süreçler
- işleme
- üretmek
- PLATFORM
- üretim
- Programlama
- Projeler
- kanıt
- kavramın ispatı
- önerilen
- sağlamak
- sağlanan
- sağlar
- sağlama
- pytorch
- yükseltmek
- menzil
- daha doğrusu
- Gerçek dünya
- yeniden dengelemeye
- tekrarlamak
- tanımak
- azaltmak
- Indirimli
- azaltarak
- ifade eder
- ilişkiler
- ilgisi
- uygun
- temsil
- temsil
- talep
- araştırma
- sonuç
- Ortaya çıkan
- Sonuçlar
- dönüş
- İade
- yorum
- ROSE
- koşu
- s
- aynı
- senaryolar
- Bilimsel araştırma
- İkinci
- arayan
- seçilmiş
- SELF
- duygu
- ayrı
- hizmet
- set
- Setleri
- Shape
- gösterilen
- Gösteriler
- önem
- önemli
- önemli ölçüde
- benzer
- Basit
- aynı anda
- tek
- beden
- becerileri
- So
- Yazılım
- Yazılım Mühendisi
- katı
- çözüm
- Çözümler
- ÇÖZMEK
- biraz
- uzmanlaşmış
- Belirtilen
- Aşama
- aşamaları
- standart
- istatistik
- adım
- basit
- böyle
- uygun
- denetimli öğrenme
- destek
- Destek
- tablo
- TAG
- Bizi daha iyi tanımak için
- Hedeflenen
- Görev
- görevleri
- takım
- teknikleri
- test
- Test yapmak
- Metin Sınıflandırması
- o
- The
- Bilgi
- ve bazı Asya
- Onları
- kendilerini
- Bunlar
- eşik
- İçinden
- zaman
- zamanlar
- için
- üst
- meşale
- Toplam
- dokunma
- karşı
- iz
- geleneksel
- Tren
- Eğitim
- Dönüştürmek
- Dönüşüm
- transforme
- dönüşüm
- davranır
- gerçek
- tipik
- belirsizlikler
- anlayış
- benzersiz
- us
- kullanım
- kullanım durumu
- Kullanılması
- onaylama
- Değerli
- Değerler
- çeşitli
- yaşayabilir
- vizyonumuz
- vs
- ağırlık
- Batısında
- hangi
- süre
- Vikipedi
- irade
- ile
- içinde
- olmadan
- işlenmiş
- zefirnet
- sıfır








