Giriş
Çocukların yaptığı çizimleri hayata geçirebilen özel bir bilgisayar programı hayal edin. Çocukların çizdiği o renkli ve yaratıcı resimleri biliyor musunuz? Bu program, bu çizimleri neredeyse sihir gibi, gerçek görünümlü görüntülere dönüştürebilir! Ve buna Pix2Pix denir. Sihirbazın bir deste kartla nasıl harika numaralar yapabileceğini biliyoruz. Benzer şekilde Pix2Pix çizimlerle harika şeyler yapabilir. Pix2Pix, bilgisayarların resimleri anlama ve onlarla çalışma biçiminde önemli bir değişikliğe neden oldu. Yarattığı resimler üzerinde gerçekten dikkatli bir kontrole sahip olmamızı sağlar. Görüntüleri oluşturmak ve değiştirmek için süper bir güce sahip olmak gibi!
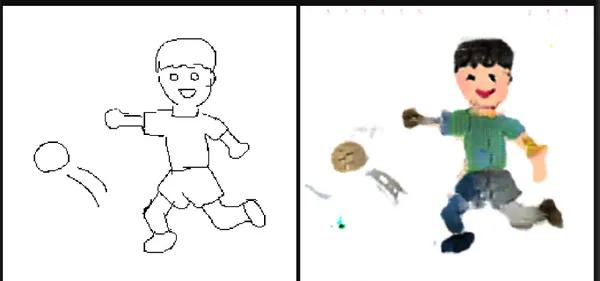
Öğrenme hedefleri
- Pix2Pix'in ne olduğunu, nasıl çalıştığını öğrenin ve gerçek dünyadaki uygulamalarını keşfedin
- Bina cephelerinden oluşan bir veri kümesi kullanarak çizimleri resimlere dönüştürmek için Pix2Pix'i kullanarak bunu deneyin.
- Uygulamada pix2pix'in çalışmasını anlamak ve birçok görüntüden görüntüye çeviri görevinin karşılaştığı sorunu pix2pix'in nasıl çözdüğünü anlamak
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Genel Rekabet Ağı (GAN'lar)
Yapay zeka alanındaki en heyecan verici son buluşlardan biri, Üretken Rekabet Ağı veya GAN. Bu güçlü sinir ağları; resimler, müzik ve metin dahil olmak üzere yeni içerikler oluşturabilir. GAN'lar iki sinir ağından oluşur. Biri içeriği oluşturan oluşturucu, diğeri ise oluşturulan içeriği yargılayan ayrıştırıcıdır.
İçerik Oluşturucu içerik oluşturmaktan sorumludur. Rastgele gürültü veya verilerle başlar ve onu aşamalı olarak anlamlı bir şeye dönüştürür. Örneğin görüntü oluşturmada sıfırdan görüntü oluşturabilir. Güzel, özgün görüntülere benzeyecek şekilde rastgele piksel değerlerini ayarlayarak başlayabilir. Ayırıcının rolü, oluşturucu tarafından oluşturulan içeriği değerlendirmektir. İçeriğin gerçek mi yoksa sahte mi olduğuna karar verir. Daha fazla içeriği inceleyip jeneratöre geri bildirim sağladıkça, eğitim devam ettikçe daha iyi hale gelir.
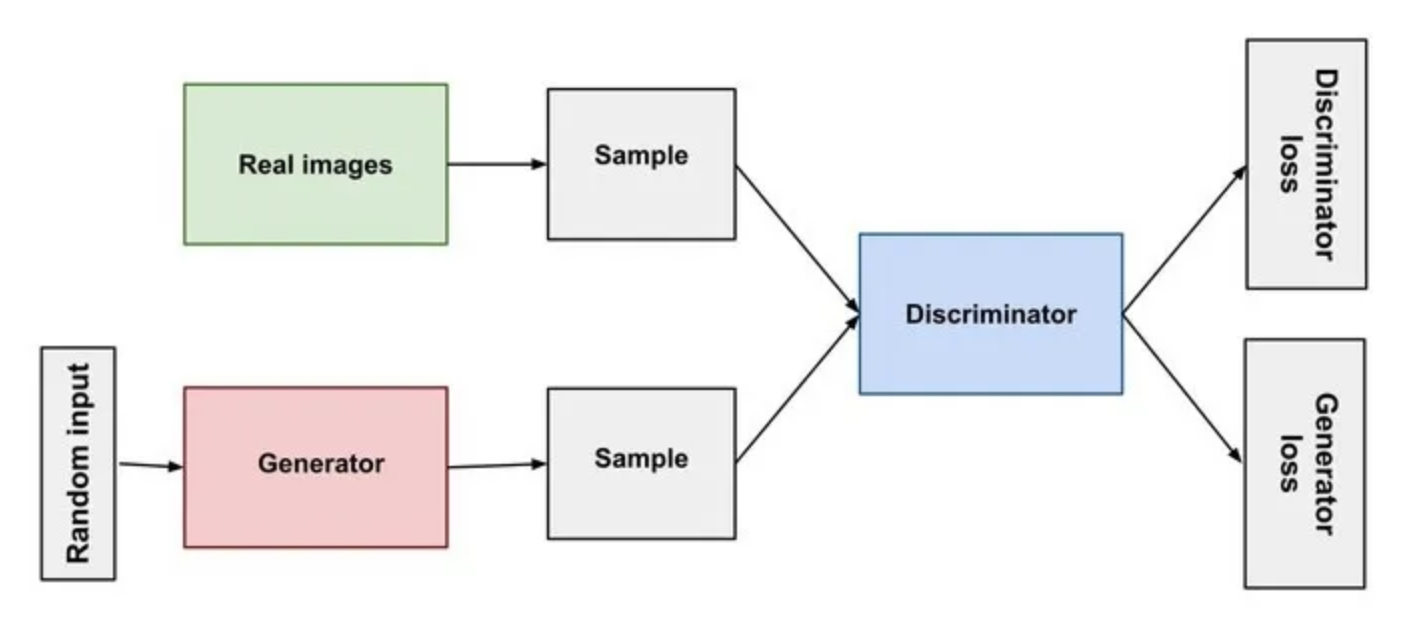
Kaynak: Neptune.ai
GAN'ın eğitim sürecinin tamamı, Çekişmeli eğitim olarak bilinir. Anlamak çok basit. Oluşturucu, başlangıçta mükemmel olmaktan uzak içerik oluşturur. Ayırıcı içeriği değerlendirir. Bu, gerçek ile sahteyi ayırmaya çalıştığı anlamına gelir. Jeneratör, ayrıştırıcıdan geri bildirim alır ve içeriğini daha ikna edici hale getirecek şekilde ayarlar ve burada öncekinden daha iyi içerik sağlar. Jeneratörün iyileştirmelerine yanıt olarak ayırıcı, sahte içeriği tespit etme yeteneğini geliştirir. Bu şekilde, çekişmeli eğitim GAN'ları daha güçlü hale getirmeye devam ediyor.
Pix2Pix
Görüntü dönüştürme ve manipülasyon kavramı geleneksel görüntü işleme teknikleriyle başlamıştır. Bunlara görüntü yeniden boyutlandırma, renk düzeltme ve filtreleme dahildir. Ancak bu geleneksel yöntemlerin, görüntüden görüntüye çeviri gibi daha karmaşık görevlerle ilgili sınırlamaları vardı. Makine öğrenimi, özellikle de derin öğrenme, görüntü dönüşümü alanında devrim yarattı. CNN'ler Günümüzde görüntü işleme görevlerinin otomatikleştirilmesi önemli hale geldi. Bununla birlikte, Üretken Rekabetçi Ağların (GAN'ler) geliştirilmesi, görüntüden görüntüye çeviride başarıya işaret etti.
Pix2Pix, görüntü çeviri görevleri için kullanılan bir derin öğrenme modelidir. Pix2Pix'in arkasındaki temel fikir, bir alandan bir giriş görüntüsü almak ve başka bir alanda buna karşılık gelen bir çıktı görüntüsü oluşturmaktır. Görüntüleri bir stilden diğerine çevirir. Bu yaklaşıma koşullu GAN'lar adı verilir çünkü Pix2Pix, giriş görüntüsünün jeneratörü koşullandırdığı koşullu bir kurulum kullanır. Pix2Pix, GAN mimarisini Koşullu GAN (cGAN) adı verilen koşullu bir biçimde kullanır. Koşula bağlı olarak çıktı üretilecektir.
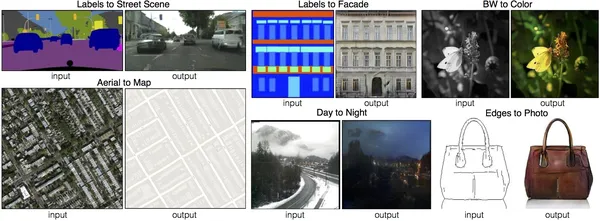
Koşullu Üretken Çekişmeli Ağ veya CGAN, GAN çerçevesinin, oluşturulan görüntüler üzerinde hassas kontrol sağlayan gelişmiş bir sürümüdür. Belirli bir kategoride görüntüler oluşturabilir. Pix2Pix GAN, bir görüntü oluşturma sürecinin verilen başka bir görüntünün varlığına bağlı olduğu bir CGAN örneğidir. Resimde pix2pix'in yarattığı harikaları görebiliyoruz. Etiketten sokak manzaraları, etiketten cepheler, siyah beyazdan renkliye, havadan görünümlerden gerçek haritaya, Gündüz fotoğraflarından gece görünümüne ve kenarlara dayalı fotoğraflar oluşturabilirim.
Resimden Resme Çeviri Zorlukları
Görüntüden görüntüye çeviri, özellikle amaç bir etki alanındaki görüntüyü başka bir etki alanındaki görüntüye dönüştürmek olduğunda zorlu bir bilgisayarlı görme görevidir. Burada temel içeriği ve yapıyı korumak zorundadır. Görüntüden görüntüye çevirideki zorluk, girdi ve çıktı alanları arasındaki karmaşık ilişkilerin yakalanmasında yatmaktadır. Bu soruna çığır açan çözümlerden biri Pix2Pix'tir.
Oluşturulan görüntülerde bazen bulanıklık veya çarpıklık gibi sorunlar yaşanabilir. Pix2pix, iki ağ kullanarak görüntülerin daha iyi görünmesini sağlamaya çalışır: biri görüntüleri oluşturan (oluşturucu), diğeri ise gerçek görünüp görünmediğini kontrol eden (ayırıcı). Ayırıcı, jeneratörün daha keskin ve gerçek resimlere daha çok benzeyen görüntüler oluşturmasına yardımcı olur, böylece bulanıklık ve bozulma ile ilgili sorunlar daha az olur.
Görüntü renklendirme gibi görevlerde, oluşturulan görüntüdeki renkler komşu bölgelere yayılarak gerçekçi olmayan renk dağılımına neden olabilir. Pix2pix, renklendirme sürecini daha iyi kontrol etmek için koşullu GAN'lar gibi teknikleri kullanır. Bu, renklendirmenin daha doğal ve daha az dağınık görünmesini sağlar.
Pix2Pix Mimarisi
Pix2Pix'in mimarisi iki ana bileşenden oluşur: Jeneratör ve Ayırıcı. Oluşturucu ve ayırıcı modellerin oluşturulmasında yaygın bir yaklaşım, Evrişim-BatchNormalizasyon-ReLU gibi katmanlardan oluşan standart yapı taşlarının kullanılmasını içerir. Derin evrişimli sinir ağları oluşturmak için bu yapı taşlarını birleştirin.
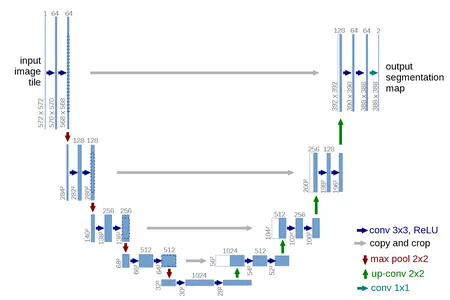
U-NET Jeneratör Modeli
Burada jeneratör için U-Net model mimarisi kullanılmıştır. Geleneksel kodlayıcı-kod çözücü modeli, bir görüntüyü girdi olarak alır ve onu birkaç katman için alt örnekler. İşlem, görüntüdeki bir katmanın birkaç katman için yukarı örneklenmesine ve son görüntünün çıktısına kadar devam eder. UNet mimarisi aynı zamanda görüntünün tekrar alt örneklemesini ve üst örneklemesini de içerir. Ancak buradaki fark, kodlayıcı ve kod çözücüde aynı boyuttaki katmanlar arasındaki bağlantıları atlamak zorunda olmasıdır. Bağlantıları atla, modelin düşük seviyeli ve yüksek seviyeli özellikleri birleştirmesine olanak tanıyarak alt örnekleme işlemi sırasında bilgi kaybı sorununu giderir.
U şeklinin üst kısmı, özellik kanallarının sayısını arttırırken giriş görüntüsünün uzamsal boyutlarını kademeli olarak azaltan bir dizi evrişim ve havuz katmanından oluşur. Ağın bu özel kısmı, giriş görüntüsünden bağlamsal bilgilerin yakalanmasından sorumludur. U-Net, görüntü segmentasyon görevleri için derin öğrenmede temel bir mimari haline geldi. Son olarak bu jeneratör, gerçek görüntülerden ayırt edilemeyen görüntüler üretecektir.
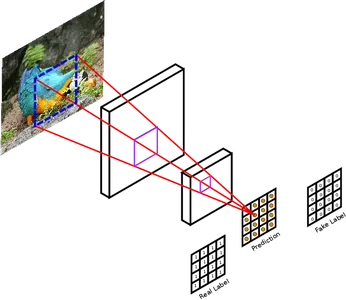
PatchGAN Ayırıcı Modeli
Ayrımcı modelini girdi olarak iki görüntü alacak şekilde tasarlayın. Kaynak etki alanından bir görüntü ve hedef etki alanından bir görüntü alır. Birincil görev, görüntünün gerçek olma veya jeneratör tarafından oluşturulmuş olma olasılığını değerlendirmek ve belirlemektir.
Ayırıcı model, görüntüleri sınıflandırmak için derin evrişimli sinir ağına sahip geleneksel bir GAN kullanır. Pix2Pix ayırıcı, geleneksel GAN yerine PatchGAN kullanıyor. Tam giriş görüntüsünü gerçek veya sahte olarak sınıflandırmak yerine, görüntünün parçalarını tanımlamak için bu derin evrişimli sinir ağını tasarlayın. Gerçek ve oluşturulan görüntüleri daha küçük, örtüşmeyen parçalara böler ve her birini ayrı ayrı değerlendirir. PatchGAN, oluşturucuya ayrıntılı geri bildirim sunar ve yerel görüntü ayrıntılarını iyileştirmeye odaklanmasına olanak tanır. Bu, jeneratör trenini daha iyi hale getirir. İnce ayrıntıları korumanın çok önemli olduğu bazı görevlerde gerçekten faydalıdır. Bu görevler görüntünün süper çözünürlüğünü içerir. Yüksek çözünürlüklü ve gerçekçi sonuçlar oluşturmaya yardımcı olur.
Pix2Pix Uygulamaları
Şimdi pix2pix'in bazı uygulamalarına bakalım.
- Mimari tasarım: Pix2Pix, bina tasarımlarının kaba taslaklarını ayrıntılı mimari planlara dönüştürebilir. Bu, mimarların daha iyi binalar tasarlamasına yardımcı olur.
- Stil Transferi: Bir görüntünün stilini diğerine aktarabilir. Ünlü bir tablonun stilini alıp bir fotoğrafa uygulayabiliyor.
- Navigasyon sistemleri: Pix2Pix'in navigasyon sistemlerinde uygulaması vardır. Sokak görünümü görüntüsünü yakalayabiliriz ve Pix2Pix'i kullanarak bunu doğru haritalara dönüştürebiliriz. Otonom navigasyon sistemleri için değerli olabilir.
- Tıbbi Görüntüleme: Pix2Pix, tıbbi görüntülemede tıbbi görüntüleri geliştirebilir ve çevirebilir. Yüksek çözünürlüklü görüntüler, daha iyi tedavi sağlamak için tıp endüstrisinde her zaman faydalıdır. Bu Pix2Pix, düşük çözünürlüklü MRI taramalarını yüksek çözünürlüklü taramalara dönüştürmeye veya X-ışını görüntülerinden CT görüntüleri oluşturmaya yardımcı olur.
- Sanat ve Yaratıcılık: Pix2Pix'i yaratıcı amaçlar için kullanın. Kullanıcı girdisine dayalı olarak benzersiz ve sanatsal görüntüler veya animasyonlar oluşturur.
Pix2Pix Kullanan Şirketler
Şimdi pix2pix kullanan bazı şirketleri görelim.
- kerpiç yaratıcı bulut ürünlerine yönelik özellikler geliştirmek için Pix2Pix'i kullandı. Eskizlerin gerçekçi görüntülere dönüştürülmesini ve görüntülerin bir stilden diğerine çevrilmesini içerir. Pix2Pix ayrıca Adobe tarafından makine öğrenimi modellerinin eğitimi için sentetik veriler oluşturmak amacıyla da kullanılıyor.
- Google harita ve fotoğraf ürün özelliklerini geliştirmek için Pix2Pix'i kullandı. Uydu görüntülerinden gerçekçi sokak görünümleri oluşturur ve siyah beyaz fotoğrafları renklendirir.
- Nvidia AI platformu için pix2pix'i kullanıyor. Makine öğrenimi modellerinin eğitimi için sentetik veri kümeleri oluşturma yeteneğine sahiptir. Ayrıca görüntüler için yeni stiller yaratır.
- Google'ın Magenta Stüdyosu makine öğrenimi ve sanatı araştıran bir araştırma projesidir. Google'ın Magenta Studio'su birçok sanat yapımı aracı oluşturmak için Pix2Pix'i kullandı. Magenta Studio, görüntü çevirisi, görüntü tamamlama ve görüntü içi boyama gibi farklı sanat türleri oluşturmak için Pix2Pix'i kullanan birçok Colab Notebook'u piyasaya sürdü. Görüntüyü iç boyama, görüntülerden nesnelerin çıkarılmasını veya görüntünün eksik kısımlarının doldurulmasını içerir. Magenta Studio ayrıca çeşitli sanat formları üretmek için Pix2Pix'i kullanan çok sayıda Magenta modelini de piyasaya sürdü. Bu modeller arasında düşük çözünürlüklü olanlardan yüksek çözünürlüklü görüntüler üreten Pix2PixHD; Farklı sanatsal tarzlardan ilham alan görüntüler yaratan Disco Diffusion ve gerçekçiliği hayal gücüyle harmanlayan görüntüler üreten GANPaint.
Uygulama
Gerekli tüm kütüphaneleri ve modülleri içe aktararak başlayalım. Eksik modül bulursanız pip komutunu kullanarak bunları içe aktarın.
import numpy as np
from matplotlib import pylab as plt
import cv2
import tensorflow as tf
import tensorflow.keras.layers as layers
from tensorflow.keras.models import Model
from glob import glob
import time
import os
Veri kümesi
Bu projede kullandığımız veri seti Kaggle'da mevcuttur ve buradan indirebilirsiniz. okuyun.
Bağlantı: https://www.kaggle.com/datasets/balraj98/facades-dataset
Bu veri seti bina cephelerinin görüntülerini ve bunlara karşılık gelen segmentasyonları içerir. Eğitim ve test alt kümelerine bölündü. Toplamda 506 adet bina cephe görseli bulunmaktadır.

Ön İşleme
Bir sonraki adımımız verileri yüklemek ve sorun açıklamamıza göre ön işleme tabi tutmaktır. Bunun için gerekli tüm adımları yapacak bir fonksiyon tanımlayacağız. Görüntü gruplarını ve bunlara karşılık gelen etiketleri yükler, bunları önceden işler ve bunları modelinize beslenmeye hazır NumPy dizileri olarak döndürür. Öncelikle hem test resimlerinin hem de test etiketlerinin bulunduğu yolları belirliyoruz. İki dizindeki tüm dosyaları bulmak için glob işlevini kullanır. img_A ve img_2 olmak üzere iki boş liste oluşturun. Bu boş listeler, 1. ve 2. gruptaki önceden işlenmiş görüntüleri depolayacaktır. Döngü oluşturulduktan sonra, 1. ve 2. gruptan gelen dosya yolu çiftleri arasında yinelenir. Her çift için, openCV kullanarak görüntüleri okuyun ve bunları değişkenlerde saklayın.
Renk Kanalları
Derin öğrenme modeli giriş spesifikasyonlarına uyum sağlamak için genellikle gerekli olan bir adım olan, görüntülerin renk kanallarını tersine çeviriyoruz. Daha sonra görselleri 256×256 piksel boyutuna getiriyoruz ve son olarak ön işleme tabi tutulan görselleri ilgili listelerine ekliyoruz. Toplu işteki tüm görüntüleri işledikten sonra kod, img_A ve img_B listelerini NumPy dizilerine dönüştürür ve piksel değerlerini [-1, 1] aralığına ölçeklendirir. Son olarak işlenmiş görüntüleri img_A ve img_B olarak döndürür.
def load_data(batch_size): path1=sorted(glob('../test_picture/*')) path2=sorted(glob('../test_label/*')) i=np.random.randint(0,27) batch1=path1[i*batch_size:(i+1)*batch_size] batch2=path2[i*batch_size:(i+1)*batch_size] img_A=[] img_B=[] for filename1,filename2 in zip(batch1,batch2): img1=cv2.imread(filename1) img2=cv2.imread(filename2) img1=img1[...,::-1] img2=img2[...,::-1] img1=cv2.resize(img1,(256,256),interpolation=cv2.INTER_AREA) img2=cv2.resize(img2,(256,256),interpolation=cv2.INTER_AREA) img_A.append(img1) img_B.append(img2) img_A=np.array(img_A)/127.5-1 img_B=np.array(img_B)/127.5-1 return img_A,img_B Benzer şekilde tren verileri için de aynısını yapacak başka bir fonksiyon oluşturmamız gerekiyor. Daha önce test verileri için tüm ön işleme adımlarını yapmıştık ve son olarak listedeki tüm görüntüleri kaydettik ve sonuna kadar var oldular. Ancak burada tren verilerinin ön işlenmesi için hepsini sonuna kadar saklamamıza gerek yok. Böylece jeneratör fonksiyonunu kullanıyoruz. Getiri ifadesi bir üreteç işlevi oluşturmak için kullanılır. Geçerli toplu iş için işlenmiş görüntüleri img_A ve img_B olarak verir ve eğitim verilerini bir kerede belleğe yüklemeden toplu olarak yinelemenize olanak tanır. Jeneratörlerin güzelliği budur.
# GeneratorFunction
def load_batch(batch_size): path1=sorted(glob('../train_picture/*')) path2=sorted(glob('../train_label/*')) n_batches=int(len(path1)/batch_size) for i in range(n_batches): batch1=path1[i*batch_size:(i+1)*batch_size] batch2=path2[i*batch_size:(i+1)*batch_size] img_A,img_B=[],[] for filename1,filename2 in zip(batch1,batch2): img1=cv2.imread(filename1) img2=cv2.imread(filename2) img1=img1[...,::-1] img2=img2[...,::-1] img1=cv2.resize(img1,(256,256),interpolation=cv2.INTER_AREA) img2=cv2.resize(img2,(256,256),interpolation=cv2.INTER_AREA) img_A.append(img1) img_B.append(img2) img_A=np.array(img_A)/127.5-1 img_B=np.array(img_B)/127.5-1 yield img_A,img_B Daha sonra, içinde ihtiyaç duyulan tüm fonksiyonları tanımlayacağımız pix2pix adında bir sınıf tanımlayacağız. Çıktıyı görselleştirmek için bir yapıcı, oluşturucu, ayırıcı, eğitim yöntemi ve sample_images tanımlayacağız. Bu yöntemlerin her birini ayrıntılı olarak öğreneceğiz.
class pix2pix(): def __init__(self): pass def build_generator(self): pass def build_discriminator(self): pass def train(self,epochs,batch_size=1): pass def sample_images(self, epoch): pass Yapıcı Yöntemi
Öncelikle yapıcı metodunu tanımlayacağız. Bu yöntem pix2pix modelinizin niteliklerini ve bileşenlerini başlatır. Bir sınıfın nesnesi oluşturulduğunda otomatik olarak çağrılan benzersiz bir yöntemdir. Görüntünün boyutlarını ve kanal sayısını tanımladık. Görüntülerin 256×256 piksel ve 3 renk kanalı (RGB) olması bekleniyor. self.gf ve self.df, sırasıyla oluşturucu ve ayırıcı modeller için filtrelerin (kanalların) sayısını tanımlayan niteliklerdir.
Daha sonra, model eğitimi için belirli bir öğrenme oranına ve beta parametresine sahip bir Adam optimizer kullanacağımız bir optimizer tanımlayacağız. Daha sonra ayırıcı model oluşturulur. İkili çapraz entropi kaybı ve daha önce tanımlanan Adam optimizer ile yapılandırılmıştır. Ayrıca birleştirilmiş modelin eğitimi sırasında ayırıcının ağırlıklarını da donduruyoruz. Self.combined özelliği, jeneratör ve ardından ayırıcıdan oluşan birleştirilmiş modeli temsil eder. Jeneratör sahte görüntüler üretir ve ayrıştırıcı bunların geçerliliğine karar verir. Bu birleştirilmiş model, jeneratörü daha gerçekçi görüntüler üretmesi için eğitir.
def __init__(self): self.img_rows=256 self.img_cols=256 self.channels=3 self.img_shape=(self.img_rows,self.img_cols,self.channels) patch=int(self.img_rows/(2**4)) # 2**4 = 16 self.disc_patch=(patch,patch,1) self.gf=64 self.df=64 optimizer=tf.keras.optimizers.legacy.Adam(learning_rate=0.0002, beta_1=0.5) self.discriminator=self.build_discriminator() #self.discriminator.summary() self.discriminator.compile(loss='binary_crossentropy', optimizer=optimizer) self.generator=self.build_generator() #self.generator.summary() img_A=layers.Input(shape=self.img_shape)#picture--label img_B=layers.Input(shape=self.img_shape)#label--real img=self.generator(img_A) self.discriminator.trainable=False valid=self.discriminator([img,img_A]) self.combined=Model(img_A,valid) self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)Oluşturma Jeneratörü
Bir sonraki adımımız bir jeneratör inşa etmek. Bu yöntem, pix2pix tarzı bir GAN'daki jeneratör modelinin mimarisini tanımlar. Bunun içinde iki farklı fonksiyona ihtiyacımız var. Bunlar conv2d ve deconv2d'dir. conv2d, isteğe bağlı toplu normalleştirmeyle evrişimsel bir katman oluşturan yardımcı bir işlevdir. Giriş tensörünü, kanal sayısını, çekirdek boyutunu ve toplu normalleştirmenin kullanılıp kullanılmayacağını belirten bir boolean olan bn'yi alır. 2 boyutlu bir evrişim, LeakyReLU aktivasyonu ve isteğe bağlı toplu normalleştirme uygular ve elde edilen tensörü döndürür.
conv2d gibi, bu da isteğe bağlı bırakma ve toplu normalleştirme ile aktarılmış bir evrişimsel katman (aynı zamanda ters evrişimli veya yukarı örnekleme katmanı olarak da bilinir) oluşturmaya yönelik bir yardımcı işlevdir. Kanal sayısı, çekirdek boyutu ve bırakma oranı ile birleştirmek için bir önceki katmandan bir giriş tensörü olan bir giriş tensörü gerekir. Bir yukarı örnekleme katmanı, evrişim, aktivasyon, bırakma (belirtilmişse), toplu normalleştirme, skip_input ile birleştirme uygular ve elde edilen tensörü döndürür.
Jeneratör modeli, giriş katmanından başlayarak birkaç katmandan oluşur. Daha sonra bir dizi evrişimli (conv2d) ve ters evrişimli (deconv2d) katmanlardan geçer. Burada d1 ila d7, kanal sayısını artırırken boyutları giderek azaltan evrişimli katmanlardır. Benzer şekilde u1 ila u7, kanal sayısını azaltırken boyutları giderek artıran ters evrişimli katmanlardır. Atlama bağlantıları, giriş görüntüsünden çıkışa kadar ince ayrıntıların korunmasına yardımcı olarak pix2pix çerçevesindeki görüntüden görüntüye çeviri gibi görevlere uygun olmasını sağlar. Son katman, tanh aktivasyon fonksiyonuna sahip evrişimli bir katmandır. Bu, çıktı görüntüsünü üretir. Giriş görüntüsüyle (self.channels) aynı sayıda kanala sahiptir ve hedef alana benzeyen bir görüntü oluşturmayı amaçlar.
def build_generator(self): def conv2d(layer_input,filters,f_size=(4,4),bn=True): d=layers.Conv2D(filters,kernel_size=f_size,strides=(2,2), padding='same')(layer_input) d=layers.LeakyReLU(0.2)(d) if bn: d=layers.BatchNormalization()(d) return d def deconv2d(layer_input,skip_input,filters,f_size=(4,4),dropout_rate=0): u=layers.UpSampling2D((2,2))(layer_input) u=layers.Conv2D(filters,kernel_size=f_size,strides=(1,1), padding='same',activation='relu')(u) if dropout_rate: u=layers.Dropout(dropout_rate)(u) u=layers.BatchNormalization()(u) u=layers.Concatenate()([u,skip_input]) return u d0=layers.Input(shape=self.img_shape) d1=conv2d(d0,self.gf,bn=False) d2=conv2d(d1,self.gf*2) d3=conv2d(d2,self.gf*4) d4=conv2d(d3,self.gf*8) d5=conv2d(d4,self.gf*8) d6=conv2d(d5,self.gf*8) d7=conv2d(d6,self.gf*8) u1=deconv2d(d7,d6,self.gf*8,dropout_rate=0.5) u2=deconv2d(u1,d5,self.gf*8,dropout_rate=0.5) u3=deconv2d(u2,d4,self.gf*8,dropout_rate=0.5) u4=deconv2d(u3,d3,self.gf*4) u5=deconv2d(u4,d2,self.gf*2) u6=deconv2d(u5,d1,self.gf) u7=layers.UpSampling2D((2,2))(u6) output_img=layers.Conv2D(self.channels,kernel_size=(4,4),strides=(1,1), padding='same',activation='tanh')(u7) return Model(d0,output_img)Ayırıcı Oluştur
Bir sonraki adımımız bir ayrımcı model oluşturmaktır. Bu yöntem, pix2pix tarzı bir GAN'daki ayırıcı modelin mimarisini tanımlar. Jeneratördeki conv2d fonksiyonuna benzer şekilde burada d_layer fonksiyonunu tanımlayacağız. Bu yardımcı işlev, isteğe bağlı toplu normalleştirmeyle evrişimsel bir katman oluşturur. Giriş tensörünü, kanal sayısını, çekirdek boyutunu ve toplu normalleştirmenin kullanılıp kullanılmayacağını belirten bir boolean olan bn'yi alır. 2 boyutlu bir evrişim, LeakyReLU aktivasyonu ve isteğe bağlı toplu normalleştirme uygular ve elde edilen tensörü döndürür. Ayırıcı modelin, her biri self.img_shape tarafından tanımlanan bir şekle sahip img_A ve img_B olmak üzere iki giriş katmanı vardır.
Bu girişler görüntü çiftlerini temsil eder: biri kaynak etki alanından (img_A) ve diğeri hedef etki alanından (img_B). img_A ve img_B giriş görüntüleri, birleştirilmiş görüntüler oluşturmak için kanal ekseni (eksen=-1) boyunca birleştirilir. Ayırıcı mimarisi, artan filtrelerle d1'den d4'e kadar evrişimli katmanlardan oluşur. Bu katmanlar, özellikleri çıkarırken giriş görüntüsünün uzamsal boyutlarını altörnekler. Son katman, sigmoid aktivasyon fonksiyonuna sahip evrişimli bir katmandır. Giriş görüntü çiftinin gerçek veya sahte olma olasılığını temsil eden tek kanallı bir çıktı üretir. Giriş görüntü çiftini gerçek veya sahte olarak sınıflandırmak için bu çıkışı kullanın.
def build_discriminator(self): def d_layer(layer_input,filters,f_size=(4,4),bn=True): d=layers.Conv2D(filters,kernel_size=f_size,strides=(2,2), padding='same')(layer_input) d=layers.LeakyReLU(0.2)(d) if bn: d=layers.BatchNormalization()(d) return d img_A=layers.Input(shape=self.img_shape) img_B=layers.Input(shape=self.img_shape) combined_imgs=layers.Concatenate(axis=-1)([img_A,img_B]) d1=d_layer(combined_imgs,self.df,bn=False) d2=d_layer(d1,self.df*2) d3=d_layer(d2,self.df*4) d4=d_layer(d3,self.df*8) validity=layers.Conv2D(1,kernel_size=(4,4),strides=(1,1),padding='same', activation='sigmoid')(d4) return Model([img_A,img_B],validity)Eğitim
Modeli çağırıldığında eğiten eğitim yöntemini oluşturmamız gerekiyor. “Geçerli” dizi, gerçek görüntü etiketlerini temsil eden numpy dizisi biçimindeki dizilerden oluşur. Benzer şekilde, "sahte" dizi, sahte (oluşturulmuş) görüntü etiketlerini temsil eden numpy dizisindeki sıfırlardan oluşur. Daha sonra, belirlenen sayıda çağ boyunca yineleme yapmak için bir for döngüsü başlatırız. Her dönemde, o spesifik dönem için geçen süreyi kaydetmek üzere bir zamanlayıcı başlatırız. Eğitim verilerini her çağdaki gruplar halinde yüklemek için bir oluşturucu kullanılır; bu, img_A (girdi) ve img_B (hedef) görüntü çiftlerini sağlar.
Jeneratör, görüntü üretmek için giriş görüntülerini kullanır. Ayırıcı, gerçek görüntü çiftlerini gerçek olarak sınıflandırmak ve gerçek görüntülerin kaybını hesaplamak için eğitim alır. Benzer şekilde, ayırıcı, oluşturulan görüntü çiftlerini sahte olarak sınıflandırmak için eğitim alır ve ardından sahte görüntülerin kaybını hesaplar. Toplam ayırıcı kaybı, hem gerçek hem de sahte görüntüler için kayıpların ortalaması alınarak belirlenir. Jeneratörün eğitim hedefi, ayrımcıyı aldatarak onları gerçek olarak sınıflandırmasını sağlayacak görüntüler oluşturmaktır.
def train(self,epochs,batch_size=1): valid=np.ones((batch_size,)+self.disc_patch) fake=np.zeros((batch_size,)+self.disc_patch) for epoch in range(epochs): start=time.time() for batch_i,(img_A,img_B) in enumerate(load_batch(1)): gen_imgs=self.generator.predict(img_A) d_loss_real = self.discriminator.train_on_batch([img_B, img_A], valid) d_loss_fake = self.discriminator.train_on_batch([gen_imgs, img_A], fake) d_loss = 0.5 * np.add(d_loss_real, d_loss_fake) g_loss = self.combined.train_on_batch(img_A,valid) if batch_i % 500 == 0: print ("[Epoch %d] [Batch %d] [D loss: %f] [G loss: %f]" % (epoch,batch_i, d_loss,g_loss)) self.sample_images(epoch) print('Time for epoch {} is {} sec'.format(epoch,time.time()-start))Visualizations
Sample_images yöntemi, eğitim sırasında oluşturucunun ilerlemesini görselleştirmek için örnek görüntüler oluşturur ve görüntüler. Burada r ve c 3 olarak ayarlanmıştır; bu, görüntülenen görsellerin ızgarasının 3 satır ve 3 sütundan oluşacağını gösterir. Burada 3 çift giriş ve hedef görüntü yüklenir. Jeneratör, giriş görüntülerine dayalı olarak sahte görüntüler oluşturmak için kullanılır. Görüntüler daha sonra görüntüleme amacıyla tek bir dizide birleştirilir. Doğru görselleştirme için piksel değerleri [-1, 1] ila [0, 1] aralığında yeniden ölçeklendirilir. Görüntüler alt noktalarda görüntülenir. Şekil, dosya adı olarak çağ numarasına sahip bir görüntü dosyası olarak kaydedilir.
def sample_images(self, epoch): r, c = 3, 3 img_A, img_B =load_data(3) fake_A = self.generator.predict(img_A) gen_imgs = np.concatenate([img_A, fake_A, img_B]) # Rescale images 0 - 1 gen_imgs = 0.5 * gen_imgs + 0.5 titles = ['Input Image', 'Predicted Image', 'Ground Truth'] fig, axs = plt.subplots(r, c) cnt = 0 for i in range(r): for j in range(c): axs[i,j].imshow(gen_imgs[cnt]) axs[i,j].set_title(titles[i]) axs[i,j].axis('off') cnt += 1 fig.savefig("./%d.png" % (epoch)) plt.show()Sonuçlar
Gerekli tüm yöntemleri tanımladıktan sonra ana yöntemi çağırmalısınız. pip2pix sınıfından gan adında bir nesne oluşturun. Daha sonra, dönem sayısını ve toplu iş boyutunu belirterek modeli eğitin.
Her dönemden sonra, tahmin edilen görüntü, girdi ve gerçek görüntülerle birlikte görüntülenecektir. Eğitim devam ettikçe resimdeki değişiklikleri gözlemleyebilirsiniz. Dönem sayısı arttıkça görüntü daha kesin olacaktır. Sonunda, temel gerçeklik görüntüsünden ayırt edilemez bir görüntü elde edeceksiniz. GAN'ların gücü budur.
if __name__ == '__main__': gan = pix2pix() gan.train(epochs=50, batch_size=1)1. dönemin sonucu:

10 dönem sonunda sonuç:

50 dönem sonundaki sonuç:

Sonuç
Pix2Pix'in başarısı, verilerden öğrenme ve yalnızca gerçekçi değil aynı zamanda sanatsal açıdan anlamlı görüntüler oluşturma kapasitesinde yatmaktadır. İster gündüz sahnelerini gece sahnelerine dönüştürün, ister siyah beyaz fotoğrafları canlı renklere dönüştürün, Pix2Pix kapasitesini kanıtlamıştır. Pix2Pix, sanatçıların ve tasarımcıların görüntüleri yenilikçi ve yaratıcı yollarla dönüştürmesine ve değiştirmesine olanak tanıyarak yaratıcı bir süper güç haline geldi. Teknoloji ilerlemeye devam ettikçe Pix2Pix daha da şaşırtıcı fırsatların önünü açıyor. Sanat ve yapay zekayı birleştirmeyi seven herkes için keşfedilmesi heyecan verici bir alan.
Önemli Noktalar
- Pix2Pix, fikirlerimizden harika fotoğraflar çekmemize yardımcı olan akıllı bir bilgisayar arkadaşıdır. Dijital dünya için sihir gibi!
- Pix2Pix, bilgisayarlı görme ve görüntü işlemede devrim niteliğinde bir teknoloji haline geldi.
- Heyecan verici olanakların yanı sıra eğitim istikrarı ve önemli veri kümelerine duyulan ihtiyaç gibi zorluklar da sunuyor.
- Google'ın makine öğrenimi ve sanatı araştıran bir araştırma projesi olan Magenta Studio, farklı sanat yapma araçları oluşturmak için Pix2Pix'i kullandı.
- Bu yazıda pix2pix'in gerçekte nasıl çalıştığını gördük ve onun büyülü gücünü anladık.
- Çizimleri gerçek görünümlü bina resimlerine dönüştürmek için Pix2Pix'i bina cephesi verileriyle nasıl kullanacağımızı öğrendik ve bize pratik bir anlayış kazandırdık.
Sıkça Sorulan Sorular
C. Pix2Pix, görüntü çeviri görevleri için kullanabileceğiniz bir derin öğrenme modelidir. Pix2Pix'in arkasındaki temel fikir, bir alandan bir giriş görüntüsü almak ve başka bir alanda buna karşılık gelen bir çıktı görüntüsü oluşturmaktır. Görüntüleri bir stilden diğerine çevirir.
C. Pix2Pix iki sinir ağını birleştirir: bir oluşturucu ve bir ayırıcı. Ayırıcı bunları değerlendirirken jeneratör görüntüler oluşturur. Rekabetçi bir şekilde birlikte çalışarak zaman içinde oluşturulan görüntülerin kalitesini artırırlar.
C. Pix2Pix'in haritaları uydu görüntülerine dönüştürme, eskizlerden ayrıntılı yüzler oluşturma, farklı tarzlarda sanat oluşturma, siyah beyaz fotoğrafları renkliye dönüştürme gibi birçok uygulaması vardır.
C. Evet, Pix2Pix modellerinde belirli veri kümelerinin ince ayarının yapılması, bunları belirli görevlere veya stillere uyarlayabilir ve bu görevler için daha iyi sonuçlar elde edilmesini sağlayabilir.
A. Jeneratör bir kodlayıcı-kod çözücü mimarisini kullanır. Burada kodlayıcı, giriş görüntüsünden özellikleri çıkarır ve kod çözücü, çıkarılan özelliklere dayalı olarak çıkış görüntüsünü üretir.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/10/pix2pix-unleashed-transforming-images-with-creative-superpower/
- :vardır
- :dır-dir
- :olumsuzluk
- :Neresi
- $UP
- 1
- 10
- 13
- 16
- 1st
- 27
- 2D
- 50
- 500
- 9
- a
- kabiliyet
- Göre
- doğru
- başarı
- Etkinleştirme
- aslında
- Adem
- uyarlamak
- eklemek
- Ayrıca
- adresleme
- ayar
- kerpiç
- ileri
- düşmanca
- Sonra
- tekrar
- AI
- AI platformu
- Amaçları
- hizalamak
- Türkiye
- Izin
- veriyor
- neredeyse
- boyunca
- Ayrıca
- her zaman
- şaşırtıcı
- an
- analytics
- Analitik Vidhya
- ve
- animasyonlar
- Başka
- herhangi
- kimse
- Uygulama
- uygulamaları
- geçerlidir
- Tamam
- yaklaşım
- mimarlar
- mimari
- mimari
- ARE
- Dizi
- Sanat
- göre
- yapay
- yapay zeka
- artistik
- sanatsal olarak
- Sanatçılar
- AS
- sordu
- At
- öznitelikleri
- Otantik
- yazar
- otomatik olarak
- ayrıca otomasyonun
- özerk
- mevcut
- ortalama
- eksen
- AXS
- merkezli
- BE
- güzel
- Güzellik
- Çünkü
- müşterimiz
- olur
- başladı
- arkasında
- olmak
- beta
- Daha iyi
- arasında
- Siyah
- Karışım
- Blokları
- blogathon
- her ikisi de
- inşa etmek
- bina
- binalar
- fakat
- by
- hesaplanması
- çağrı
- denilen
- CAN
- Kapasite
- ele geçirmek
- Yakalama
- Kartlar
- dikkatli
- Kategoriler
- neden
- meydan okuma
- zorluklar
- zor
- değişiklik
- değişiklikler
- değiştirme
- Telegram Kanal
- kanallar
- Çekler
- Çocuk
- sınıf
- sınıflandırmak
- bulut
- kod
- renk
- renkli
- Sütunlar
- birleştirmek
- kombine
- biçerdöverler
- birleştirme
- nasıl
- ortak
- Şirketler
- rekabet
- tamamlama
- karmaşık
- bileşenler
- aşağıdakileri içerir:
- bilgisayar
- Bilgisayar görüşü
- bilgisayarlar
- bilgisayar
- kavram
- koşul
- şartlı
- koşullar
- yapılandırılmış
- Bağlantılar
- oluşan
- oluşur
- inşa
- içeren
- içerik
- bağlamsal
- devam ediyor
- kontrol
- dönüştürmek
- dönüştürme
- inandırıcı
- evrişimli sinir ağı
- çekirdek
- uyan
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- oluşturur
- Oluşturma
- Yaratıcı
- yaratıcılık
- çok önemli
- akım
- veri
- veri kümeleri
- gün
- güverte
- azalan
- derin
- derin öğrenme
- tanımlamak
- tanımlı
- tanımlar
- tanımlarken
- bağlıdır
- Dizayn
- belirlenen
- tasarımcıları
- tasarımlar
- ayrıntı
- detaylı
- ayrıntılar
- belirlemek
- Belirlemek
- kararlı
- geliştirmek
- gelişme
- fark
- farklı
- Yayılma
- dijital
- boyutlar
- dizinleri
- takdir
- ekran
- görüntülenen
- görüntüler
- ayırmak
- dağıtım
- çeşitli
- böler
- do
- yok
- domain
- etki
- yapılmış
- Dont
- indir
- çekmek
- Çizimler
- sırasında
- her
- Daha erken
- kenarları
- ya
- istihdam
- boş
- etkinleştirmek
- sağlar
- son
- artırmak
- çağ
- devirler
- Eter (ETH)
- değerlendirmek
- Hatta
- sonunda
- Her
- inceler
- örnek
- heyecan verici
- mevcut
- beklenen
- keşfetmek
- araştırıyor
- Keşfetmek
- anlamlı
- Hulasa
- yüzler
- sahte
- ünlü
- uzak
- Özellikler(Hazırlık aşamasında)
- Özellikler
- Fed
- geribesleme
- az
- daha az
- alan
- Incir
- şekil
- fileto
- dosyalar
- dolgu
- süzme
- filtreler
- son
- Nihayet
- bulmak
- ince
- Ad
- odak
- takip
- İçin
- Airdrop Formu
- formlar
- iskelet
- Dondurmak
- arkadaş
- itibaren
- tam
- işlev
- fonksiyonlar
- Gans
- oluşturmak
- oluşturulan
- üretir
- üreten
- nesil
- üretken
- üretici ters ağlar
- jeneratör
- jeneratörler
- almak
- verilmiş
- Verilmesi
- gol
- Goes
- Google'ın
- Grid
- Zemin
- çığır açan
- vardı
- Var
- sahip olan
- yardım et
- faydalı
- yardımcı olur
- okuyun
- Yüksek
- üst düzey
- yüksek çözünürlük
- Ne kadar
- Nasıl Yapılır
- Ancak
- HTTPS
- i
- Fikir
- fikirler
- belirlemek
- if
- görüntü
- görüntü üretimi
- Resim parçalama
- görüntüleri
- hayal gücü
- Görüntüleme
- uygulama
- ithalat
- önemli
- ithal
- gelişmiş
- iyileştirmeler
- geliştirir
- geliştirme
- in
- dahil
- içerir
- Dahil olmak üzere
- Artırmak
- Artışlar
- artan
- belirten
- Bireysel olarak
- sanayi
- bilgi
- başlangıçta
- başlatmak
- yenilikçi
- giriş
- girişler
- içeride
- ilham
- örnek
- yerine
- İstihbarat
- içine
- buluşlar
- çağrılan
- içerir
- sorunlar
- IT
- ONUN
- keras
- çocuklar
- Bilmek
- bilinen
- etiket
- Etiketler
- son olarak
- tabaka
- katmanları
- ÖĞRENİN
- öğrendim
- öğrenme
- miras
- az
- Lets
- leverages
- kütüphaneler
- yalan
- hayat
- sevmek
- sınırlamaları
- Liste
- Listeler
- yük
- yükleme
- yükler
- yerel
- Bakın
- kayıp
- kayıp
- makine
- makine öğrenme
- sihirli
- Ana
- ağırlıklı olarak
- yapmak
- YAPAR
- Yapımı
- hile
- tavır
- çok
- harita
- Haritalar
- işaretlenmiş
- matplotlib
- maksimum genişlik
- anlamlı
- anlamına geliyor
- medya
- tıbbi
- tıbbi Görüntüleme
- Bellek
- yöntem
- yöntemleri
- eksik
- model
- modelleri
- Modüller
- Daha
- çoğu
- MRG
- Music
- şart
- Doğal (Madenden)
- Navigasyon
- gerekli
- gerek
- gerekli
- komşu
- Neptün
- ağ
- ağlar
- sinirsel
- sinir ağı
- nöral ağlar
- yeni
- sonraki
- gece
- Gürültü
- dizüstü bilgisayarlar
- numara
- sayısız
- dizi
- nesne
- nesnel
- nesneler
- gözlemek
- of
- kapalı
- Teklifler
- sık sık
- on
- bir Zamanlar
- ONE
- olanlar
- bir tek
- OpenCV
- açılır
- Fırsatlar
- or
- OS
- Diğer
- bizim
- dışarı
- sonuçlar
- çıktı
- tekrar
- Sahip olunan
- boyama
- çift
- çiftleri
- parametre
- Bölüm
- belirli
- parçalar
- geçmek
- Patch
- Yamalar
- MÜKEMMEL OLAN YERİ BULUN
- Fotoğraf
- fotoğraflar
- Fotoğraflar
- resim
- Fotoğraf Galerisi
- piksel
- platform
- Platon
- Plato Veri Zekası
- PlatoVeri
- olanakları
- güç kelimesini seçerim
- güçlü
- Pratik
- Pratik uygulamalar
- gerek
- tahmin
- varlık
- mevcut
- korunması
- önceki
- Önceden
- birincil
- olasılık
- Sorun
- sorunlar
- süreç
- işlenmiş
- işleme
- üretmek
- üretir
- PLATFORM
- Ürünler
- Programı
- Ilerleme
- ilerleyen
- aşamalı olarak
- proje
- uygun
- kanıtlanmış
- sağlar
- sağlama
- yayınlanan
- amaçlı
- kalite
- R
- rasgele
- menzil
- oran
- Okumak
- hazır
- gerçek
- Gerçek dünya
- реалистичный,en
- Gerçekten mi
- alır
- son
- kayıt
- azaltmak
- ilişkin
- bölgeler
- İlişkiler
- serbest
- kaldırma
- temsil etmek
- temsil
- temsil
- gereklidir
- araştırma
- benzer,
- bu
- yanıt
- sorumlu
- sonuç
- Ortaya çıkan
- Sonuçlar
- dönüş
- İade
- ters
- devrimci
- devrim
- RGB
- Rol
- aynı
- uydu
- uydu görüntüleri
- kaydedilmiş
- terazi
- tarar
- Sahneler
- Bilim
- çizik
- SEC
- görmek
- görüldü
- bölünme
- SELF
- Dizi
- set
- kurulum
- birkaç
- Shape
- gösterilen
- önemli
- benzer
- benzer şekilde
- Basit
- tek
- beden
- daha küçük
- akıllı
- So
- Çözümler
- çözer
- biraz
- bir şey
- bazen
- Kaynak
- uzaysal
- özel
- özel
- özellikle
- özellikler
- Belirtilen
- bölmek
- yayılma
- istikrar
- standart
- başlama
- XNUMX dakika içinde!
- başlar
- Açıklama
- adım
- Basamaklar
- mağaza
- sokak
- yapı
- stüdyo
- stil
- Daha sonra
- önemli
- başarı
- böyle
- uygun
- süper güç
- sentetik
- sentetik veri
- Sistemler
- Bizi daha iyi tanımak için
- alınan
- alır
- Hedef
- Görev
- görevleri
- teknikleri
- Teknoloji
- tensorflow
- test
- metin
- göre
- o
- The
- Kaynak
- ve bazı Asya
- Onları
- sonra
- Orada.
- Bunlar
- onlar
- işler
- Re-Tweet
- Bu
- İçinden
- için
- zaman
- başlıkları
- için
- birlikte
- araçlar
- üst
- Toplam
- geleneksel
- Tren
- Eğitim
- trenler
- transfer
- Dönüştürmek
- Dönüşüm
- dönüşüm
- çevirmek
- Çeviri
- tedavi
- hileler
- Hakikat
- DÖNÜŞ
- Dönüş
- iki
- türleri
- altında yatan
- anlamak
- anlayış
- anladım
- benzersiz
- dışarı çıktı
- kadar
- us
- kullanım
- Kullanılmış
- işe yarar
- kullanıcı
- kullanım
- kullanma
- kullanılan
- kullanır
- geçerli
- geçerlik
- Değerli
- Değerler
- değişkenler
- çeşitli
- versiyon
- canlı
- Görüntüle
- Gösterim
- vizyonumuz
- görüntüleme
- görselleştirmek
- oldu
- Yol..
- yolları
- we
- webp
- Ne
- Nedir
- ne zaman
- olup olmadığını
- hangi
- süre
- beyaz
- bütün
- irade
- ile
- içinde
- olmadan
- İş
- birlikte çalışmak
- çalışma
- çalışır
- X
- X-ışını
- Evet
- Yol ver
- verim
- sen
- zefirnet