Giriş
Alma Artırılmış Nesil artık yeni teknolojidir. RAG, geleneksel arama tabanlı yaklaşımların yerini alıyor ve belge ortamıyla sohbet yaratıyor. RAG'ın başlangıcından bu yana, standart RAG yaklaşımını geliştirmek için çeşitli yöntemler önerilmiştir. RAG'daki en büyük engel doğru belgeyi almaktır. Yalnızca doğru belgeleri aldığımızda, Yüksek Lisans doğru yanıtları üretebilecektir. Bu kılavuzda, RAG'da Erişimi geliştirmek için oluşturulmuş bir yaklaşım olan HyDE'den (Varsayımsal Belge Gömme) bahsedeceğiz.
Öğrenme hedefleri
- RAG'ın sınırlamalarının ve daha iyi belge alma ihtiyacının farkına varın.
- HyDE'nin alma doğruluğunu iyileştirmedeki rolünü anlayın.
- Daha iyi erişim için varsayımsal belgeler oluşturmayı öğrenin.
- Verimli erişim için HyDE'yi LangChain ile uygulayın.
- HyDE'nin halüsinasyonları azaltmadaki etkinliğini değerlendirin.
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
RAG Uygulamasının Karşılaştığı Zorluklar
Alma Artırılmış Nesil çok popüler ve şu anda yaygın olarak kullanılıyor. Basit bir RAG (Geri Alma Artırılmış Üretim), ham metni almayı, onu daha küçük parçalara ayırmayı, tüm parçalar için yerleştirmeler oluşturmayı ve yerleştirmeleri bir vektör deposunda saklamayı içerir. Daha sonra bir kullanıcı bir sorgu sağladığında, kullanıcı sorgusu ile parçalar arasındaki benzerliği karşılaştırır ve benzer parçaları alırız. Son olarak, kullanıcı sorgusu benzer parçalarla birlikte Büyük Dil Modeli Nihai cevabı oluşturmak için. Bu normal Geri Alma Artırılmış Nesildir.

Bu düzenli ve sade Geri Alma Artırılmış Neslinin birçok kusuru var. Parçalamanın kendisinden başlayarak. Parçalamanın tek bir boyutu yoktur. Belgeleri parçalamanın boyutu büyük ölçüde üzerinde çalıştığımız Büyük Dil Modellerinin türüne bağlıdır ve bazen daha iyi sonuçlar elde etmek için birden fazla boyutu denemek zorunda kalırız. Daha sonra bu kılavuzun ana odağı olan Geri Alma geliyor.
RAG, Büyük Dil Modellerinin halüsinasyon görmesini önlemek için geliştirildi. Bu büyük ölçüde vektör depolarından kullanıcı sorgusu aracılığıyla alınan benzer bilgilere bağlıdır. Geri Alma iyi değilse Büyük Dil Modeli ya halüsinasyon görecek ya da kullanıcı tarafından sağlanan soruya yanıt vermeyecektir. Alma işlemini iyileştirmenin bir yolu Varsayımsal Belge Gömmeleridir.
Varsayımsal Belge Gömme (HyDE) Nedir?
Varsayımsal Belge Yerleştirmeleri (HyDE), RAG tabanlı çözümlerde karşılaşılan zayıf Alma işlemlerinin üstesinden gelmeye yönelik dönüştürücü çözümlerden biridir. Adından da anlaşılacağı gibi HyDE, Büyük Dil Modelinin bu girdileri alabilmesi ve daha iyi bir yanıt üretebilmesi için benzer belgelerin daha iyi alınmasına yardımcı olacak Varsayımsal Belgeler oluşturarak çalışır.
HyDE'yi aşağıdaki diyagramla anlayalım:
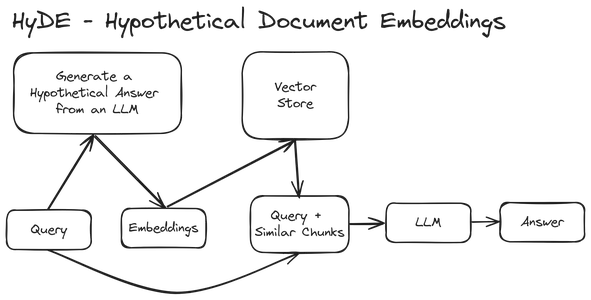
İlk adım bir kullanıcı sorgusunun alınmasını içerir. Artık normal bir RAG sisteminde, kullanıcı sorgusunu yerleştirmelere dönüştürüyoruz ve benzer parçaları almak için bunu vektör deposuna gönderiyoruz. Ancak Varsayımsal Belge Gömmelerde, kullanıcı sorgusunu alırız ve ardından soruya Varsayımsal bir Yanıt oluşturmak için onu Büyük Dil Modeline aktarırız. Dolayısıyla LLM, kullanıcı sorusunu alır ve ilk kullanıcı sorgusundan benzer metin kalıplarına sahip sahte bir Varsayımsal Cevap/Belge oluşturmaya çalışır. Daha sonra bu Varsayımsal Belgeyi gömme vektörlerine dönüştürüyoruz ve ardından bu gömmeleri vektör deposundan benzer parçaları almak için kullanıyoruz. Son olarak, bu benzer parçaları orijinal sorguya bağlarız ve nihai cevabı oluşturmak için bunları birlikte LLM'ye iletiriz.
Yani burada yapmaya çalıştığımız şey, gömme vektörlerin benzerliğini yanıtlamak için bir sorgu gerçekleştirmek yerine, daha iyi sonuçlar verecek şekilde gömme vektörlerin benzerliğini yanıtlamak için bir yanıt gerçekleştirmeye çalışıyoruz.
Varsayımsal Belge Yerleştirmenin (HyDE) Özellikleri
- Gelişmiş Alma Doğruluğu: HyDE, kullanıcı sorgularına dayalı olarak Varsayımsal Yanıtların/Belgelerin oluşturulduğu yeni bir yaklaşım sunarak, anahtar kelimelerin ötesinde arama amacının daha ayrıntılı bir şekilde anlaşılmasına olanak tanır. Dolayısıyla bunları gömme vektörlerine kodlamak, anlamsal olarak daha alakalı parçaların bulunmasında geri alma sistemlerini gerçekten geliştirecektir.
- Azalan Halüsinasyonlar: RAG'ın LLM Halüsinasyonlarını azaltmak için tanıtıldığını tartışmıştık. Bunlar, LLM'ye aktarılan, alınan bağlama dayalı olacaktır, bu nedenle bunları LLM'ye yanlış ve anlamlı olmayan parçalar halinde vermek, halüsinasyonlara ve dolayısıyla yanlış yanıtlara yol açacaktır. HyDE, varsayımsal belgeleri aracılığıyla en uygun parçaları toplamaya çalışacak ve böylece halüsinasyon olasılığını azaltacaktır.
HyDE Uygulamada – LangChain
Bu bölümde Varsayımsal Belge Gömmelerini sıfırdan oluşturacağız ve ilgili içeriği ne kadar iyi aldığını göreceğiz. Bununla birlikte, Varsayımsal Belge Yerleştirmeleri için LangChain'deki bir uygulamaya bile bakacağız.
Python kütüphanelerini indirip kurarak başlayacağız:
pip install -q langchain langchain-google-genai sentence-transformers chromadbAşağıdaki kütüphaneleri kuruyoruz:
- uzun zincir: LangChain, farklı LLM'lerle çalışmanın ve onlarla uygulamalar oluşturmanın kolay bir yolunu sunar. Farklı LLM sağlayıcıları ve farklı yerleştirme modelleri arasında kolayca geçiş yapmamızı sağlar.
- langchain-google-genai: Bu modül, Google tarafından geliştirilen Büyük Dil Modelleri etrafında bir sarmalayıcı sağlar. Langchain, bu kütüphane sayesinde Bileşenlerini Gemini gibi Google LLM'lerle kolayca entegre etmemize olanak tanıyor. Kitaplık, Google'ın Gömme modelinin sarmalayıcısını bile içerir.
- cümle dönüştürücüler: Bu kütüphane farklı tipte gömme modelleri için destek sağlar. Tüm bu yerleştirme modelleri HuggingFace Hub'da mevcuttur ve açık kaynaktır. LangChain ve hatta LlamaIndex'in açık kaynaklı gömme modelleriyle çalışabilmemiz için bu kütüphane gereklidir.
- kromadb: Bu kütüphane, gömme vektörlerinin saklanması için destek sağlar. Chromadb, hem getirdiğimiz belgelerin hem de kullanıcı sorgularının gömme vektörlerini saklayan bir vektör deposu gibi davranır. Verilen kullanıcı sorgusu için benzer belgeleri alabilmemiz için benzerlik araması yapmak gereklidir.
HyDE'nin uygulanması
HyDE'yi belirli adımları izleyerek uygulayalım:
Adım 1: Yüksek Lisans ve Yerleştirme Modellerinin Yüklenmesi.
LLM'yi ve yerleştirme modellerini yükleyerek başlayalım. Bunun için aşağıdaki kodla çalışacağız:
# --- Setting API KEY ---
import os
os.environ['GOOGLE_API_KEY']='YOUR GOOGLE API KEY'
# --- Model Loading ---
# Import the necessary modules from the langchain_google_genai package.
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_google_genai import ChatGoogleGenerativeAI
# Create a ChatGoogleGenerativeAI Object and convert system messages to human-readable format.
llm = ChatGoogleGenerativeAI(model="gemini-pro", convert_system_message_to_human=True)
# Create a GoogleGenerativeAIEmbeddings object for embedding our Prompts and documents
Embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001")açıklama
- API Anahtarını ayarlayarak başlıyoruz.
- Daha sonra gerekli sınıfları langchain_google_genai modülünden içe aktarıyoruz; bunlar arasında ChatGoogleGenerativeAI ve GoogleGenerativeAIEmbeddings yer alıyor.
- Öncelikle Gemini-pro olan model adını ve sistem mesajlarının True olarak ayarladığımız insan tarafından okunabilir formata dönüştürülüp dönüştürülmeyeceğini söyleyen bir ChatGoogleGenerativeAI Nesnesi oluşturuyoruz.
- Daha sonra İstemleri ve belgeleri gömmek için bir GoogleGenerativeAIEmbeddings Nesnesi oluşturuyoruz. Bunun için gömme-001 modelini kullanıyoruz.
Bunu ziyaret edebilirsin Link ücretsiz API Anahtarınızı almak için. API Anahtarını aldıktan sonra yukarıdaki kodu “GOOGLE API ANAHTARINIZ” yerine yapıştırın.
Adım2: Veri Yükleme
Genel bir Erişim Artırılmış Üretiminin ilk adımı veri yüklemeyi içerir. İşte oluşturulan kod Dil Zinciri Verilen URL'den veri almak ve yüklemek için.
# --- Data Loading ---
# Import the WebBaseLoader class from the langchain_community.document_loaders module.
from langchain_community.document_loaders import WebBaseLoader
# Create a WebBaseLoader object with the URL of the blog post to load.
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/")
# Load the blog post and store the documents in the `docs` variable.
docs = loader.load()- WebBaseLoader sınıfını langchain_community.document_loaders modülünden içe aktarıyoruz. Web'den belge yüklemek için bu sınıfla çalışılabilir.
- Daha sonra Loader isimli WebBaseLoader sınıfının bir örneğini oluşturuyoruz ve “https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/” URL’sini WebBaseLoader’ın yapıcısına iletiyoruz.
- Loader nesnesinde load() yöntemini çağırıyoruz. Bu işlev, belgeleri verilen web URL'sinden getirir ve yükler. Yüklenen dokümanlar dokümanlar değişkeninde saklanır.
Yukarıdaki kodu çalıştırdıktan sonra, dokümanlar değişkeni verilen web URL'sinden alınan belgeleri içerecektir. Verileri yükledikten sonra, gerektiğinde yalnızca ilgili verileri çıkarabilmek/alabilmek için bunları daha küçük parçalara ayırmamız gerekir. Bunu gerçekleştirmek için aşağıdaki kodla çalışacağız.
Adım 3: Veri Bölme / Parçalar Oluşturma
Şimdi verileri bölüp parçalar oluşturalım.
# --- Splitting / Creating Chunks ---
# Import the RecursiveCharacterTextSplitter class from the
# langchain.text_splitter module.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Create a RecursiveCharacterTextSplitter object using the provided
# chunk size and overlap.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300,
chunk_overlap=50)
# Split the documents in the `docs` variable into smaller chunks and
#store the resulting splits in the `splits` variable.
splits = text_splitter.split_documents(docs)açıklama
- RecursiveCharacterTextSplitter sınıfını langchain.text_splitter modülünden import ediyoruz. Bu sınıf, indirdiğimiz belgeler için parçalar oluşturmak için kullanışlıdır.
- Daha sonra RecursiveCharacterTextSplitter sınıfının text_splitter adında bir örneğini oluşturacağız. Bu nesneye chunk_size=300 ve chunk_overlap=50'yi iletiyoruz. Bu, 300 boyutlu parçalar oluşturduğumuzu ve her komşu parçanın 50 jetonluk bir parça örtüşmesine sahip olacağını söyler.
- Son olarak text_splitter nesnesi üzerinde split_documents() fonksiyonunu çağırıyoruz. Bu işlev, değişken dokümanlarda saklanan belgeleri, verilen yığın boyutuna ve örtüşmeye göre parçalara böler.
Adım4: Belgelerin Saklanması
Artık belgelerimizi oluşturduk ve parçalara ayırdık, bir sonraki adım bu belgeleri daha sonra alabilmemiz için bir vektör deposunda saklamaktır.
Bunun kodu şöyle olacaktır:
# --- Creating Embeddings by Passing Hyde Embeddings to Vector Store ---
from langchain_community.vectorstores import Chroma
# passing the hyde embeddings to create and store embeddings
vectorstore = Chroma.from_documents(documents=splits,
collection_name='my-collection',
embedding=Embeddings)
# Creating Retriever
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 4})açıklama
- Belge parçaları için bir ChromaDB vektör deposu oluşturmak amacıyla birlikte çalışacağımız langchain_community.vectorstore modülünden Chroma sınıfını içe aktarıyoruz.
- Şimdi, Vectorstore adında bir Chroma nesnesi oluşturuyoruz ve vektör deposunu oluşturmak için from_documents() işlevini çağırıyoruz, vektörleştirme için bölmeler sağlıyoruz, 'koleksiyonum' koleksiyon_adı'nı veriyoruz ve gömme için Yerleştirmeleri veriyoruz.
- Bu, parçalarımız için gömme vektörleri oluşturmak için Google Embeddings modelimizi kullanacaktır. Artık vektör mağazamız hazır ve tüm parçalarımız için yerleştirmeleri içeriyor.
- Şimdi benzer parçaları vektör mağazamızdan almamıza olanak tanıyan bir alıcı oluşturacağız.
- Bunun için Vectorstore'dan as_retriever() fonksiyonu aracılığıyla bir Retriever nesnesi oluşturuyoruz. Daha sonra, en iyi 4 benzer belgeyi almak için arama_tipini “benzerlik” olarak ayarlayıp arama parametrelerini search_kwargs ile {“k”: 4} olarak belirleyerek alıcıyı benzerlik tabanlı aramalar için yapılandırıyoruz.
Adım 5: HyDE Oluşturmak için Bilgi İstemi Şablonu Oluşturma
Artık nihayet veri yükleme, ön işleme ve depolama kısmını tamamladık. Şimdi kullanıcı sorgularına yönelik varsayımsal belgeler oluşturmak için bir Bilgi İstemi Şablonu oluşturacağız. Bunun kodunu aşağıda bulabilirsiniz:
# Importing the Prompt Template
from langchain.prompts import ChatPromptTemplate
# Creating the Prompt Template
template = """For the given question try to generate a hypothetical answer
Only generate the answer and nothing else:
Question: {question}
"""
Prompt = ChatPromptTemplate.from_template(template)
query = Prompt.format(question = 'What are different Chain of Thought(CoT) Prompting?')
hypothetical_answer = llm.invoke(query).content
print(hypothetical_answer)açıklama
- Büyük Dil Modeline sorulara dayalı varsayımsal cevaplar üretmesini söyleyen İstemi içeren bir Bilgi İstemi Şablonu tanımlarız.
- Daha sonra tanımlı şablon dizesini ayrıştırarak bunu Prompt adlı bir ChatPromptTemplate nesnesine aktarıyoruz.
- Daha sonra Prompt.format(question='Görev Ayrıştırma Nedir?') kullanarak şablonu belirli bir soruyla biçimlendirerek bir sorgu oluşturun.
- Daha sonra oluşturulan Sorgu İstemi ile dil modelini çağırmak için llm nesnesini çağırıyoruz.
- Son olarak sonuçtan .content dosyasına erişerek oluşturulan varsayımsal cevabın içeriğini alıyoruz. Daha sonra LLM tarafından oluşturulan içeriği görüntülemek için yazdırıyoruz.
Adım 6: Nihai sonuçlar için kodun çalıştırılması
Yukarıdakilerin çalıştırılması, verilen kullanıcı sorgusuna dayalı olarak Büyük Dil Modeli tarafından oluşturulan Varsayımsal Belge/Cevapla sonuçlanacaktır.

Kullanıcı sorgusuna dayanarak şunu görebiliriz: Büyük Dil Modeli olası bir cevabı, yani Varsayımsal Belgeyi üretti. Şimdi vektör depomuzdan bu Varsayımsal Cevap/Belge ile ilgili belgeleri almaya çalışalım.
# retrieval with hypothetical answer/document
similar_docs = retriever.get_relevant_documents(hypothetical_answer)
for doc in similar_docs:
print(doc.page_content)
print()- Yukarıdaki kodda retriever nesnesinin .get_relevant_documents() fonksiyonunu çağırıyoruz. Bu fonksiyona az önce oluşturduğumuz Hypothetical_answer'ı iletiyoruz.
- Bu daha sonra vektör deposundan 4 ilgili parçayı alacak ve bunu benzer_docs değişkeninde saklayacaktır.
- Daha sonra benzer parçaların listesini yineleyerek her belge parçasının içeriğini yazdırırız.
Kodu çalıştırdıktan sonra, alınan ilgili belgeleri aşağıda görebiliriz.

Adım 7: İlgili Belgelerin Alınması
Alınan dört parçanın tamamının, kullanıcı tarafından sorulan orijinal sorguyla yakın bir ilişkisi olduğunu görebiliriz. Özellikle ilk 3 parça, Büyük Dil Modeli'nin yanıtı oluşturmak için ihtiyaç duyduğu bol miktarda bilgiye sahiptir. İlgili belgeleri düz İstemden almayı deneyelim. Bunun kodu şöyle olacaktır:
# retrieval with original query
similar_docs = retriever.get_relevant_documents('What are different
Chain of Thought(CoT) Prompting?')
for doc in similar_docs:
print(doc.page_content)
print()Çıktılar :
Types of CoT Prompts#
Two main types of CoT Prompting:
Chain-of-thought (CoT) prompting (Wei et al. 2022) generates a
sequence of short sentences to describe reasoning logics step by
step, known as reasoning chains or rationales, to eventually lead to
the final answer. The benefit of CoT is more pronounced for complicated
reasoning tasks, while using
Chain-of-Thought (CoT)#
Table of Contents
Basic Prompting
Zero-Shot
Few-shot
Tips for Example Selection
Tips for Example Ordering
Instruction Prompting
Self-Consistency Sampling
Chain-of-Thought (CoT)
Types of CoT Prompts
Tips and Extensions
Automatic Prompt Design
Augmented Language ModelsBurada, elde edilen belgelerin Varsayımsal Belgeleri Yerleştirme Yaklaşımı ile karşılaştırıldığında derinlemesine bilgi içermediğini görüyoruz. Öyleyse Hyde yoluyla alınan bu belgeleri LLM'ye iletelim ve ürettiği çıktıyı görelim.
# Creating the Prompt Template
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
Prompt = ChatPromptTemplate.from_template(template)
# Creating a function to format the retrieved docs
def format_docs(docs):
return "nn".join(doc.page_content for doc in docs)
formatted_docs = format_docs(similar_docs)
Query_Prompt = Prompt.format(context=formatted_docs,
question="What are different Chain of Thought(CoT) Prompting?")
print(Query_Prompt)
response = llm.invoke(Query_Prompt)
print(response.content)açıklama
- Şimdi yeni bir Bilgi İstemi Şablonu oluşturuyoruz. Bu şablon, oluşturulan Varsayımsal Belge ve orijinal kullanıcı sorgusu aracılığıyla alınan belgeleri almak üzere tasarlanmıştır.
- Daha sonra tanımlanan Prompt Template dizesini ayrıştırarak Prompt adında bir ChatPromptTemplate nesnesini başlatırız.
- Alınan belgeleri biçimlendirmek için format_docs(docs) işlevini oluşturun. Langchain Belge Nesnelerinin bir listesini alır ve ardından her Belge Nesnesinden metin içeriğini çıkarır ve bunları birleştirir.
- Daha sonra, biçimlendirilmiş içeriği içeren biçimlendirilmiş_docs oluşturmak için format_docs() işlevini benzer_docs'a uygularız.
- Bilgi İstemi şablonunu biçimlendirilmiş bağlamla ve "Düşünce Zinciri(CoT)Promptinh'den farklı olan nedir?" sorusuyla biçimlendirerek bir Sorgu İstemi Query_Prompt oluşturun.
- Son olarak LLM'yi .invoke() fonksiyonu ile çağırıyoruz ve az önce oluşturduğumuz Query_Prompt'u aktarıyoruz. LLM, Varsayımsal Cevap yoluyla alınan belgeleri içeren Query_Prompt'u alacak ve kullanıcı sorgusuna son bir yanıt oluşturacak ve ardından içeriği yazdıracağız.
Kodu çalıştırdıktan sonra Büyük Dil Modeli, kullanıcı sorgusuna aşağıdaki yanıtı oluşturdu.

Alınan belgelerde Varsayımsal Yanıt'a ulaşabildiğimizi ve ardından herhangi bir halüsinasyon olmadan kullanıcı sorusuna doğru bir yanıt üretebildiğimizi fark edebiliriz. Şimdi, bu, Varsayımsal Belge Yerleştirmeleri gerçekleştirmenin manuel işlemidir; burada, Varsayımsal Yanıt oluşturmak için bir bilgi istemi tanımlayarak ve ardından bu Yanıt ve belge parçaları için benzer bir arama gerçekleştirerek bunu sıfırdan yapabiliriz.
HyDE Langchain'in Önceden Tanımlanmış İşlevlerini Kullanma
Neyse ki Langchain, HyDE için önceden tanımlanmış bir sınıfla birlikte geliyor. Aşağıdaki kod üzerinden bir göz atalım:
from langchain_google_genai import GoogleGenerativeAI
from langchain_google_genai import GoogleGenerativeAIEmbeddings
llm = GoogleGenerativeAI(model="gemini-pro")
Emebeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/")
docs = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300,chunk_overlap=50)
splits = text_splitter.split_documents(docs)
from langchain.chains import HypotheticalDocumentEmbedder
hyde_embeddings = HypotheticalDocumentEmbedder.from_llm(llm,
Embeddings,
prompt_key = "web_search")
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,
collection_name='collection-1',
embedding=hyde_embeddings)
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 4})
from langchain.schema.runnable import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain.prompts import PromptTemplate, ChatPromptTemplate
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
def format_docs(docs):
return "nn".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
response = rag_chain.invoke("What are different Chain of Thought(CoT) prompting?")
print(response)
Web'den indirdiğimiz belgeleri parçaladığımız kısma kadar kod aynıdır.
açıklama
- HypotheticalDocumentEmbedder'ı langchain.chains modülünden içe aktarıyoruz. Bu sınıf Varsayımsal Cevapların oluşturulması, bunların yerleştirilmesi ve benzer parçaların alınmasıyla ilgilenecektir.
- Daha sonra, HypotheticalDocumentEmbedder nesnesini oluşturuyoruz ve .from_llm() fonksiyonunu çağırıyoruz, burada Varsayımsal Yanıt'ı (Gömmeler) oluşturmak için gerekli olacak olan llm'yi geçiyoruz ve Varsayımsal Yanıtlar için gömme vektörlerini oluşturmak için gerekli olacak ve İstem Anahtarı, yani LLM'nin Varsayımsal bir Cevap almak için internete başvurabileceği "web araması"
- Hyde_embeddings, Varsayımsal Yanıtları oluşturmak için gerekli olacak dahili bir İsteme bile sahip olacaktır.
- Daha sonra belgeleri Chroma Vector Store'da saklıyoruz. Burada Gömme modelini vermek yerine hyde_embeddings'i geçiyoruz, böylece Varsayımsal Yanıtın benzer parçalarını alabiliriz
- Daha sonra bir Bilgi İstemi Şablonu tanımlıyoruz ve geri getirici nesnemizi oluşturuyoruz.
- Daha sonra Prompt, Retriever, LLM ve Output Parser'ı kullanarak LCEL (Langchain Expression Language) aracılığıyla bir zincir oluşturup bunu rag_chain değişkenine atadık.
Artık rag_chain'in invoke() fonksiyonunu çağırabilir ve ona soruyu iletebiliriz. Rag_chain, sağlanan sorgudan bizim için Varsayımsal Yanıtlar oluşturmayla ilgilenecek, ardından bunlar için yerleştirme vektörleri oluşturacak ve vektör deposundan benzer parçaları alacaktır. Daha sonra bu parçaları Bilgi İstemi Şablonuna sığacak şekilde biçimlendirin ve son İstemi, alınan parçalara ve kullanıcı sorgusuna dayalı olarak bir yanıt oluşturacak olan Büyük Dil Modeline iletin.
Bu kodu çalıştırdıktan sonra oluşturulan çıktı aşağıdadır:

LLM'den oluşturulan cevabın, Varsayımsal Belge Yerleştirmelerini sıfırdan yaparken oluşturduğumuz cevaba benzer olduğunu görebiliriz. Ancak bu yerleşik Hyde'ın iyi sonuçlar üretmediğini unutmayın, bu nedenle ilerlemeden önce hem sıfırdan yaklaşımı hem de bu yaklaşımı test etmek daha iyidir. İşte burada HypotheticalDocumentEmbedder bu işi üstleniyor, böylece verimli RAG uygulamaları oluşturmaya başlayabiliriz.
Sonuç
Bu kılavuzda, Alma Artırılmış Üretim (RAG) sistemlerinde alma doğruluğunu iyileştirmeye yönelik bir strateji olan Varsayımsal Belge Yerleştirmeleri (HyDE) alanını derinlemesine inceledik. HyDE'den yararlanarak, yanıt oluşturmak için ilgili belgelerin doğru bir şekilde alınmasını da içeren geleneksel RAG uygulamalarının sınırlamalarının üstesinden gelmeyi hedefledik. LangChain'i kullanan HyDE'nin kılavuzu ve pratik uygulaması aracılığıyla, HyDE'nin geri alma doğruluğunu artırma ve halüsinasyonları azaltma potansiyelini araştırdık, böylece Büyük Dil Modellerinden (LLM'ler) daha güvenilir ve bağlamsal olarak anlamlı yanıtlara katkıda bulunduk. HyDE'nin inceliklerini ve pratik uygulamasını anlayarak daha verimli ve etkili RAG sistemlerinin önünü açabiliriz.
Önemli Noktalar
- RAG'ın öne çıkan bir teknoloji haline geldiğini ancak geleneksel yaklaşımların doğru belge alımında zorluklarla karşı karşıya olduğunu keşfettik.
- HyDE'nin, erişim doğruluğunu artırmak için kullanıcı sorgularına dayalı varsayımsal belgeler oluşturarak dönüştürücü bir çözüm sağladığını öğrendi.
- HyDE, anlamlı parçaların daha iyi alınması yoluyla halüsinasyonları azaltarak, Büyük Dil Modellerinden (LLM'ler) daha güvenilir yanıtlar alınmasına katkıda bulunur.
- HyDE'nin pratik uygulaması, veri yükleme, ön işleme, varsayımsal yanıtlar üretme, ilgili belgeleri alma ve LLM'lerle entegrasyon gibi adımları içerir.
- LangChain, RAG sistemlerine kolaylaştırılmış entegrasyon için HypotheticalDocumentEmbedder gibi önceden tanımlanmış sınıflar da dahil olmak üzere HyDE'nin verimli bir şekilde uygulanmasına yönelik araçlar ve kütüphaneler sağlar.
Sık Sorulan Sorular
A. RAG, erişim ve oluşturmayı birleştirerek metin oluşturmaya yönelik bir çerçeve/araçtır. Bir kullanıcı sorgusuna dayalı olarak bir belge deposundan ilgili bilgileri alır ve ardından bu bilgileri bir yanıt oluşturmak için kullanır. Ancak, alınan bilgilerin sorgu için iyi bir eşleşme olmaması durumunda geleneksel RAG zorluk yaşayabilir.
C. RAG'daki en büyük engel doğru belgeleri almaktır. Geleneksel RAG, hatalı olabilecek salt kullanıcı sorgusu eşleştirmesine dayanır. HyDE, kullanıcı sorgusuna dayalı olarak "varsayımsal belgeler" oluşturarak bu sorunu çözer. Bu varsayımsal belgeler daha sonra belge deposundan daha ilgili bilgileri almak için kullanılır.
C. Kılavuz, HyDE'nin LangChain kütüphanesini kullanarak uygulanmasını araştırıyor. Varsayımsal belgelerin oluşturulmasını, bunların bir vektör deposunda saklanmasını ve varsayımsal belgelere dayalı olarak ilgili belgelerin alınmasını içerir.
C. Oluşturulan varsayımsal belgelerin kalitesi, alma doğruluğunu etkileyebilir. HyDE, geleneksel RAG'a kıyasla ekstra hesaplama kaynaklarına ihtiyaç duyar.
A. Langchain, HyDE sürecini basitleştiren HypotheticalDocumentEmbedder adlı yerleşik bir sınıf sağlar. Bu sınıf varsayımsal belgeler oluşturmayı, bunları yerleştirmeyi ve ilgili parçaları almayı yönetir.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2024/04/enhancing-rag-with-hypothetical-document-embedding/
- :vardır
- :dır-dir
- :olumsuzluk
- :Neresi
- $UP
- 11
- 2022
- 300
- 4
- 5
- 50
- 8
- a
- Yapabilmek
- Hakkımızda
- yukarıdaki
- erişme
- doğruluk
- doğru
- tam olarak
- eylemler
- adresleri
- Sonra
- Hedeflenen
- AL
- Türkiye
- Izin
- veriyor
- boyunca
- miktar
- an
- analytics
- Analitik Vidhya
- ve
- cevap
- cevaplar
- herhangi
- api
- Uygulama
- uygulamaları
- Tamam
- yaklaşım
- yaklaşımlar
- ARE
- etrafında
- göre
- AS
- sordu
- atamak
- At
- augmented
- Otomatik
- mevcut
- merkezli
- temel
- BE
- müşterimiz
- olmuştur
- önce
- altında
- yarar
- İYİ
- Daha iyi
- arasında
- Ötesinde
- Biggest
- bağlamak
- Blog
- blogathon
- her ikisi de
- bina
- yerleşik
- Demet
- fakat
- by
- çağrı
- denilen
- CAN
- hangi
- belli
- zincir
- zincirler
- zorluklar
- şansı
- sohbet
- sınıf
- sınıflar
- Kapanış
- kod
- birleştirme
- geliyor
- karşılaştırmak
- karşılaştırıldığında
- karmaşık
- bileşenler
- bilişimsel
- içermek
- içeren
- içeren
- içerik
- içindekiler
- bağlam
- katkıda bulunur
- katkıda
- dönüştürmek
- doğru
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- Oluşturma
- veri
- def
- tanımlamak
- tanımlı
- tanımlarken
- bağlıdır
- tanımlamak
- Dizayn
- tasarlanmış
- gelişmiş
- diyagram
- farklı
- takdir
- tartışılan
- ekran
- do
- docs
- belge
- evraklar
- yok
- yapıyor
- yapılmış
- indirildi
- indirme
- e
- E&T
- her
- kolayca
- kolay
- Etkili
- etki
- verimli
- verimli biçimde
- ya
- başka
- katıştırma
- kodlama
- artırmak
- artırılması
- çevre
- özellikle
- Eter (ETH)
- Hatta
- sonunda
- örnek
- keşfedilmeyi
- araştırıyor
- ifade
- uzantıları
- ekstra
- Hulasa
- Yüz
- yüzlü
- karşı
- sahte
- son
- Nihayet
- bulma
- Ad
- uygun
- kusurları
- odak
- takip etme
- İçin
- biçim
- ileri
- bulundu
- dört
- Ücretsiz
- itibaren
- işlev
- İkizler burcu
- genel
- oluşturmak
- oluşturulan
- üretir
- üreten
- nesil
- almak
- alma
- GitHub
- verilmiş
- Verilmesi
- Go
- gidiş
- Tercih Etmenizin
- Google'ın
- rehberlik
- Kolları
- Var
- yardım et
- okuyun
- Ne kadar
- Ancak
- HTTPS
- merkez
- SarılmaYüz
- insan tarafından okunabilir
- engel
- i
- if
- darbe
- uygulamak
- uygulama
- uygulanması
- ithalat
- ithal
- iyileştirmek
- gelişmiş
- geliştirme
- in
- derinlemesine
- yanlış
- başlangıç
- dahil
- içerir
- Dahil olmak üzere
- bilgi
- girişler
- kurmak
- yükleme
- örnek
- yerine
- entegre
- Bütünleştirme
- bütünleşme
- niyet
- Internet
- içine
- karmaşıklıklar
- tanıttı
- Tanıtımlar
- içerir
- IT
- yineleme
- ONUN
- kendisi
- Katıldı
- sadece
- anahtar
- anahtar kelimeler
- bilinen
- dil
- büyük
- çok
- sonra
- öncülük etmek
- izin
- Lets
- kaldıraç
- kütüphaneler
- Kütüphane
- sevmek
- sınırlamaları
- Liste
- lm
- yük
- yükleyici
- yükleme
- yükler
- Bakın
- Ana
- Manuel
- çok
- Maç
- uygun
- Mayıs..
- anlamlı
- medya
- mesajları
- yöntem
- yöntemleri
- Azaltmak
- model
- modelleri
- modül
- Modüller
- Daha
- daha verimli
- isim
- adlı
- gerekli
- gerek
- gerekli
- ihtiyaçlar
- komşu
- yeni
- sonraki
- yok hayır
- normal
- notlar
- hiçbir şey değil
- Fark etme..
- şimdi
- detaylı
- nesne
- nesneler
- of
- on
- ONE
- bir tek
- açık
- açık kaynak
- or
- sipariş
- orijinal
- OS
- bizim
- çıktı
- Üstesinden gelmek
- üst üste gelmek
- Sahip olunan
- paket
- parametreler
- Bölüm
- geçmek
- geçti
- Geçen
- desen
- kaldırım döşemek
- yapmak
- icra
- parçalar
- yer
- Sade
- Platon
- Plato Veri Zekası
- PlatoVeri
- yoksul
- Popüler
- mümkün
- Çivi
- potansiyel
- Pratik
- uygulama
- uygulamalar
- önlemek
- Sorun
- süreç
- işleme
- üreten
- önemli
- istemleri
- belirgin
- önerilen
- sağlanan
- sağlayıcılar
- sağlar
- sağlama
- yayınlanan
- saf
- Python
- kalite
- sorgular
- sorgu
- soru
- Sorular
- paçavra
- Çiğ
- hazır
- Gerçekten mi
- alan
- muhakeme
- azaltarak
- başvurmak
- düzenli
- ilişki
- uygun
- güvenilir
- dayanır
- Kaynaklar
- Yanıtlamak
- yanıt
- yanıtları
- sonuç
- Ortaya çıkan
- Sonuçlar
- geri alma
- dönüş
- krallar gibi yaşamaya
- Rol
- koşu
- aynı
- Bilim
- çizik
- Ara
- aramalar
- Bölüm
- görmek
- görünmek
- seçim
- göndermek
- gönderdi
- Dizi
- set
- ayar
- kısa
- gösterilen
- benzer
- Basit
- basitleştirir
- beri
- beden
- boyutları
- daha küçük
- So
- çözüm
- Çözümler
- ÇÖZMEK
- bazen
- Kaynak
- özel
- belirten
- bölmek
- Splits
- standart
- başlama
- XNUMX dakika içinde!
- adım
- Basamaklar
- mağaza
- saklı
- mağaza
- depolamak
- Stratejileri
- aerodinamik
- dizi
- Çabalama
- Önerdi
- destek
- anahtar
- sistem
- Sistemler
- tablo
- ele almak
- Bizi daha iyi tanımak için
- alınan
- alır
- alma
- konuşma
- Görev
- görevleri
- Teknoloji
- söyleme
- anlatır
- şablon
- test
- metin
- metinsel
- o
- The
- Onları
- sonra
- Orada.
- böylece
- Bunlar
- Re-Tweet
- İçinden
- Böylece
- için
- ipuçları
- için
- birlikte
- Jeton
- araçlar
- üst
- geleneksel
- dönüştürücü
- çalışır
- gerçek
- denemek
- çalışıyor
- iki
- tip
- türleri
- anlamak
- anlayış
- URL
- us
- kullanım
- Kullanılmış
- işe yarar
- kullanıcı
- kullanım
- kullanma
- değişken
- çeşitli
- vektör
- vektörler
- çok
- Türkiye Dental Sosyal Medya Hesaplarından bizi takip edebilirsiniz.
- oldu
- Yol..
- we
- ağ
- webp
- İYİ
- vardı
- Ne
- ne zaman
- olup olmadığını
- hangi
- süre
- geniş ölçüde
- irade
- ile
- olmadan
- İş
- işlenmiş
- çalışma
- çalışır
- Yanlış
- verim
- zefirnet