Організації використовують свої дані для вирішення складних проблем, починаючи з невеликих ітераційних експериментів і вдосконалюючи рішення. Хоча силу експериментів не можна ігнорувати, організації повинні бути обережними щодо економічної ефективності таких експериментів. Якщо витрачати час на створення базової інфраструктури для проведення експериментів, це ще більше збільшує вартість.
Розробникам потрібне інтегроване середовище розробки (IDE) для дослідження даних і налагодження робочих процесів, а також різні обчислювальні профілі для виконання цих робочих процесів. Якщо ви обираєте Amazon EMR для таких випадків використання ви можете використовувати IDE під назвою Amazon EMR Studio для дослідження даних, перетворення, керування версіями та налагодження, а також запускати завдання Spark для обробки великого обсягу даних. Розгортання Amazon EMR на Amazon EKS спрощує управління, знижує витрати та покращує продуктивність. Однак інженеру з обробки даних або ІТ-адміністратору потрібно витратити час на створення базової інфраструктури, налаштування безпеки та створення керованої кінцевої точки для підключення користувачів. Це означає, що такі проекти повинні чекати, поки ці експерти створять інфраструктуру.
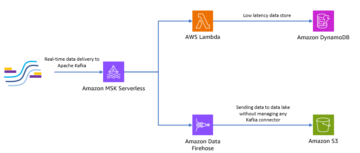
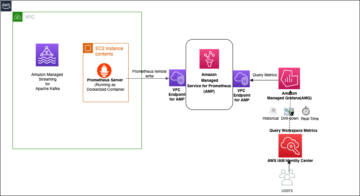
У цій публікації ми покажемо, як інженер даних або ІТ-адміністратор може використовувати Еталонна архітектура AWS Analytics (ARA), щоб прискорити розгортання інфраструктури, заощаджуючи час і гроші вашої організації на ці експерименти з аналітикою даних. Ми використовуємо бібліотеку для розгортання Amazon Elastic Kubernetes (Amazon EKS), налаштуйте його для використання Amazon EMR на EKS і розгорніть віртуальний кластер а також керовані кінцеві точки та EMR Studio. Потім ви можете виконувати завдання на віртуальному кластері або запускати пошуковий аналіз даних за допомогою Блокноти Юпітера на Amazon EMR Studio та Amazon EMR на EKS. Наведена нижче архітектура представляє інфраструктуру, яку ви розгортатимете за допомогою еталонної архітектури AWS Analytics.

Передумови
Щоб слідувати, вам потрібно мати обліковий запис AWS, який завантажується з Набір хмарних розробок AWS (AWS CDK). Інструкції див Запуск завантаження. У наступному посібнику використовується TypeScript і потрібна версія AWS CDK 2 або пізнішої. Якщо у вас не встановлено AWS CDK, див Встановіть AWS CDK.
Налаштуйте проект AWS CDK
Щоб розгортати ресурси за допомогою ARA, спочатку потрібно налаштувати проект AWS CDK і інсталювати бібліотеку ARA. Виконайте наступні дії:
- Створіть папку з назвою emr-eks-app:
- Ініціалізуйте проект AWS CDK у порожньому каталозі та виконайте таку команду:
- Встановіть бібліотеку ARA:
- У lib/emr-eks-app.ts імпортуйте бібліотеку ARA наступним чином. Перший рядок викликає бібліотеку ARA, другий визначає політики AWS Identity and Access Management (IAM):
Створіть і визначте кластер EKS і обчислювальну потужність
Створити ЕМР на ЕКС віртуальний кластер, спочатку потрібно розгорнути кластер EKS. Бібліотека ARA визначає конструкцію під назвою EmrEksCluster. Конструкція забезпечує кластер EKS, дозволяє Ролі IAM для облікових записів служб, а також розгортає набір допоміжних контролерів, як-от контролер диспетчера сертифікатів (потрібний для керованої кінцевої точки, яка використовується Amazon EMR Studio), а також засіб автоматичного масштабування кластера, щоб створити еластичний кластер і заощадити кошти, коли в кластер не надсилається завдання. .
In lib/emr-eks-app.ts, додайте наступний рядок:
Щоб дізнатися більше про властивості, які можна налаштувати, див EmrEksClusterProps. Є два обов'язкові параметри EmrEksCluster побудувати: Перший eksAdminRoleArn роль є обов’язковою та використовується для взаємодії з площиною керування Kubernetes. Ця роль повинна мати адміністративні дозволи на створити або оновити кластер. Другий параметр autoscaling, цей параметр також дозволяє вибрати механізм автомасштабування Карпентер or рідний Kubernetes Cluster Autoscaler. У цьому блозі ми будемо використовувати Karpenter, і ми рекомендуємо його використовувати через швидше автомасштабування, спрощене керування вузлом і надання. Тепер ви готові визначити обчислювальну потужність.
Одним із способів визначення робочих вузлів в Amazon EKS є використання груп керованих вузлів. Ми використовуємо одну групу вузлів під назвою tooling, де розміщено coredns, вхідний контролер, менеджер сертифікатів, Карпентер і будь-який інший модуль, необхідний для роботи EMR на завданнях EKS або ManagedEndpoint. Ми також визначаємо значення за замовчуванням Karpenter Провізіори які визначають потужність, яка буде використана для робіт, поданих EMR на EKS. Ці провайдери оптимізовані для різних випадків використання Spark (важливі роботи, некритичні роботи, експерименти та інтерактивні сесії). Конструкція також дозволяє вам надсилати власний провайдер, визначений маніфестом Kubernetes, за допомогою методу під назвою addKarpenterProvisioner. Давайте обговоримо попередньо визначені Provisioners.
Конфігурації провайдерів за замовчуванням
Провайдери за замовчуванням встановлені для швидкого експериментування завжди створюється за замовчуванням. Однак, якщо ви не хочете ними користуватися, ви можете встановити defaultNodeGroups параметр до false в EmrEksCluster властивості під час створення. Провайдери визначаються таким чином і створюються в кожній із підмереж, які використовуються Amazon EKS:
- Критичний провайдер – Він призначений для підтримки робочих місць із агресивними SLA та чутливий до часу. Провайдер використовує екземпляри On-Demand, які не зупиняються, на відміну від спотових екземплярів, і їхній життєвий цикл проходить через одне із завдань. Вузли використовують сховища екземплярів, які є дисками NVMe, фізично підключеними до хосту, які забезпечують високу пропускну здатність вводу-виводу, що забезпечує кращу продуктивність Spark, оскільки він використовується як тимчасове сховище для розливу та перемішування дисків. Типи екземплярів, які використовуються у вузлі, належать до сімейства m6gd. Примірники використовують AWS Гравітон процесор, який пропонує краща ціна/продуктивність, ніж процесори x86. Щоб використовувати цей провайдер у своїх завданнях, ви можете скористатися наступним зразок конфігурації, на який є посилання в перевизначення конфігурації ЕМР на подання роботи ЕКС.
- Некритичний провайдер – Цей Provisioner використовує точкові екземпляри, щоб заощадити на роботах, які не залежать від часу, або роботах, які використовуються для експериментів. Цей вузол використовує точкові екземпляри, оскільки завдання не є критичними та можуть бути перервані. Ці екземпляри можна зупинити, якщо екземпляр буде відновлено. Типи екземплярів, які використовуються у вузлі, належать до сімейства m6gd, драйвер — On-Demand, а виконавці — екземпляри на місці.
- Провайдер блокнота – Провайдер призначений для запуску керованих кінцевих точок, які використовуються Amazon EMR Studio для дослідження даних за допомогою Amazon EMR на EKS. Екземпляри належать до сімейства t3 і є On-Demand для драйвера та Spot Instances для виконавців, щоб зберегти низьку вартість. Якщо екземпляри виконавця зупинено, Karpenter запускає нові. Якщо екземпляри виконавця надто часто зупиняються, ви можете визначити власні, які використовують екземпляри On-Demand.
Наступні link надає більше деталей про те, як визначено кожен із провайдерів. Одна властивість імпорту, яка визначена в постачальниках за замовчуванням, є одна для кожної AZ. Це важливо, оскільки дозволяє зменшити вартість передачі між мережами AZ, коли Spark запускає перемішування.
Для цієї публікації ми використовуємо стандартні Provisioners, тому вам не потрібно додавати жодних рядків коду для цього розділу. Якщо ви хочете додати власних провайдерів, ви можете скористатися цим методом addKarpenterProvisioner застосовувати власні маніфести. Ви можете використовувати допоміжні методи в Utils клас, як readYamlDocument щоб прочитати документ YAML і loadYaml завантажити файли YAML і передати їх як аргументи addKarpenterProvisioner метод.
Розгорніть віртуальний кластер і роль виконання
Віртуальний кластер — це простір імен Kubernetes, у якому зареєстровано Amazon EMR; коли ви надсилаєте завдання, модулі драйвера та виконавця працюють у пов’язаному просторі імен. The EmrEksCluster construct пропонує метод під назвою addEmrVirtualCluster, який створює для вас віртуальний кластер. Метод приймає EmrVirtualClusterOptions як параметр, який має такі атрибути:
- ім'я – Ім’я вашого віртуального кластера.
- createNamespace – Додаткове поле, яке створює простір імен EKS. Це тип Boolean і за замовчуванням він не створює окремого простору імен EKS, тому ваш віртуальний кластер створюється в просторі імен за замовчуванням.
- eksNamespace – Ім’я простору імен EKS, який буде пов’язано з віртуальним кластером EMR. Якщо простір імен не вказано, конструкція використовує простір імен за замовчуванням.
- In
lib/emr-eks-app.ts, додайте такий рядок, щоб створити віртуальний кластер:Тепер ми створюємо роль виконання, яка є роллю IAM, яка використовується драйвером і виконавцем для взаємодії зі службами AWS. Перш ніж ми зможемо створити роль виконання для Amazon EMR, нам потрібно спочатку створити
ManagedPolicy. Зверніть увагу, що в наведеному нижче коді ми створюємо політику, щоб дозволити доступ до сегмента Amazon Simple Storage Service (Amazon S3) і журналів Amazon CloudWatch. - In
lib/emr-eks-app.ts, додайте такий рядок, щоб створити політику:Якщо ви хочете використовувати каталог даних AWS Glue, додайте його дозвіл у попередній політиці.
Тепер ми створюємо роль виконання для Amazon EMR на EKS за допомогою політики, визначеної на попередньому кроці за допомогою
createExecutionRoleметод екземпляра. Модулі драйверів і виконавців можуть взяти на себе цю роль для доступу та обробки даних. Роль визначається таким чином, що її можуть прийняти лише модулі у просторі імен віртуального кластера. Щоб дізнатися більше про умову, реалізовану цим методом для обмеження доступу до ролі лише для модулів, створених Amazon EMR на EKS у просторі імен віртуального кластера, див. Використання ролей виконання завдань з Amazon EMR на EKS. - In
lib/emr-eks-app.ts, додайте такий рядок, щоб створити роль виконання:Попередній код створює роль IAM під назвою
execRoleJobіз політикою IAM, визначеною вemrekspolicyі охоплює простір іменdataanalysis. - Нарешті, ми виводимо параметри, важливі для виконання завдання:
Розгорніть Amazon EMR Studio та налаштуйте користувачів
Щоб розгорнути EMR Studio для дослідження даних і створення завдань, бібліотека ARA має конструкцію під назвою NotebookPlatform. Ця конструкція дозволяє розгортати стільки EMR Studios, скільки вам потрібно (в межах ліміту облікового запису), налаштовувати для них режим автентифікації, який вам підходить, і призначати їм користувачів. Щоб дізнатися більше про режими автентифікації, доступні в Amazon EMR Studio, див Виберіть режим автентифікації для Amazon EMR Studio.
Ця конструкція створює всі необхідні ролі та політики IAM, необхідні Amazon EMR Studio. Він також створює сегмент S3, де Amazon EMR Studio зберігає всі ноутбуки. Відро зашифровано за допомогою a керований клієнтом ключ (CMK), згенерований стеком AWS CDK. У наступних кроках показано, як створити власну EMR Studio за допомогою конструкції.
Конструкція платформи ноутбука приймає NotebookPlatformProps як властивість, що дозволяє вам визначити вашу EMR Studio, простір імен, ім’я EMR Studio та режим її автентифікації.
- In
lib/emr-eks-app.ts, додайте наступний рядок:Для цієї публікації ми використовуємо користувачів IAM, щоб ви могли легко відтворити її у своєму обліковому записі. Однак, якщо у вас уже є федерація IAM або єдиний вхід (SSO), ви можете використовувати їх замість користувачів IAM. Щоб дізнатися більше про параметри
NotebookPlatformProps, відноситься до NotebookPlatformProps.Далі нам потрібно створити та призначити користувачів Amazon EMR Studio. Для цього в конструкції є метод під назвою
addUserякий бере список користувачів і або призначає їх Amazon EMR Studio у разі SSO, або оновлює політику IAM, щоб дозволити доступ до Amazon EMR Studio для наданих користувачів IAM. Користувач також може мати кілька керованих кінцевих точок, і кожен користувач може визначити свою версію Amazon EMR. Вони можуть використовувати інший набір екземплярів Amazon Elastic Compute Cloud (Amazon EC2) і різні дозволи, використовуючи ролі виконання завдань. - In
lib/emr-eks-app.ts, додайте наступний рядок:У попередньому коді, для стислості, ми повторно використовуємо ту саму політику IAM, яку ми створили в ролі виконання.
Зауважте, що конструкція оптимізує кількість створених керованих кінцевих точок. Якщо дві кінцеві точки мають однакові назви, створюється лише одна.
- Тепер, коли ми визначили наше розгортання, ми можемо його розгорнути:
Ви можете знайти зразок проекту, який містить усі кроки проходження, на наступному GitHub Сховище.
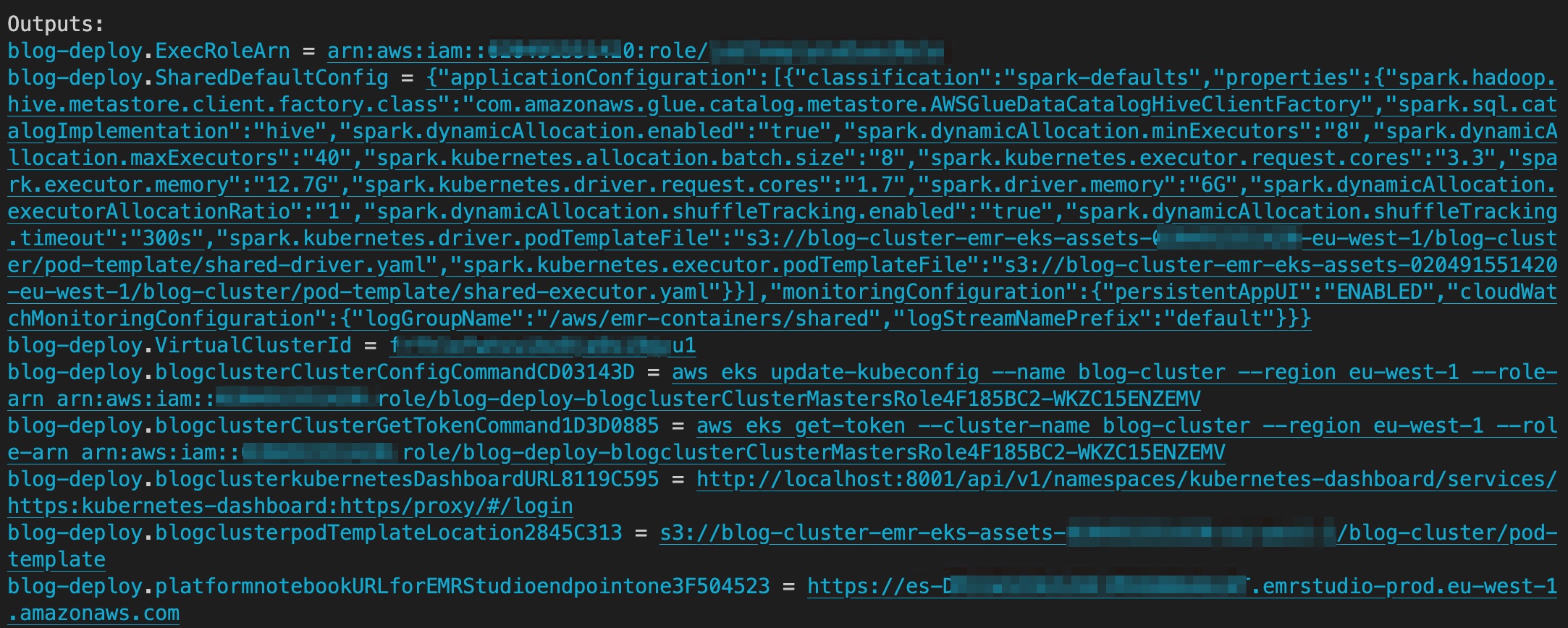
Після завершення розгортання вихідні дані містять сегмент S3, що містить активи для podTemplate, посилання на EMR Studio та ідентифікатор віртуального кластера EMR Studio. На наступному знімку екрана показано вихідні дані AWS CDK після завершення розгортання.
Надсилайте вакансії

Оскільки ми використовуємо провайдери за замовчуванням, ми будемо використовувати podTemplate який визначається конструкцією, доступною на Репозиторій ARA GitHub. Вони завантажуються для вас конструкцією у відро S3 під назвою <clustername>-emr-eks-assets; вам потрібно лише посилатися на них у своїй роботі Spark. У цьому завданні ви також використовуєте параметри завдання у вихідних даних наприкінці розгортання AWS CDK. Ці параметри дають вам змогу використовувати каталог даних AWS Glue і впроваджувати найкращі практики Spark на Kubernetes, наприклад dynamicAllocation і под. В кінці cdk deploy ARA виведе зразки конфігурацій завдань із переліченими раніше найкращими методами, які можна використовувати для подання завдання. Подати роботу можна наступним чином.
Запуск завдання – це одиниця роботи, наприклад файл Spark JAR, який надсилається до EMR кластера EKS. Починаємо роботу за допомогою start-job-run команда. Примітка, яку можна використовувати SparkSubmitParameters щоб вказати шлях Amazon S3 до шаблону модуля, як показано в такій команді:
Код приймає такі значення:
- – Ідентифікатор віртуального кластера EMR
- – Назва вашої роботи Spark
- – Роль виконання, яку ви створили
- – URI Amazon S3 вашого завдання Spark
- – URI Amazon S3 шаблону модуля драйвера, який ви отримуєте з вихідних даних AWS CDK
- – URI Amazon S3 шаблону модуля виконавця
- – Назва вашої групи журналів CloudWatch
- – Ваш префікс потоку журналу CloudWatch
Ви можете перейти до консолі Amazon EMR, щоб перевірити статус свого завдання та переглянути журнали. Ви також можете перевірити статус, запустивши describe-job-run команда:
Досліджуйте дані за допомогою Amazon EMR Studio
У цьому розділі ми покажемо, як можна створити робочий простір в Amazon EMR Studio та підключитися до керованої кінцевої точки Amazon EKS з робочого простору. У вихідних даних скористайтеся посиланням на Amazon EMR Studio, щоб перейти до розгортання EMR Studio. Ви повинні ввійти за допомогою IAM ім'я користувача ви надали в addUser метод.
Створіть робочу область
Щоб створити робочу область, виконайте такі кроки:
- Увійдіть у EMR Studio, створену AWS CDK.
- Вибирати Створити робочу область.
- Введіть назву робочої області та необов’язковий опис.
- Select дозволяти Workspace Collaboration якщо ви хочете працювати з іншими користувачами Studio в цьому робочому просторі в режимі реального часу.
- Вибирати Створити робочу область.

Створивши робочу область, виберіть її зі списку робочих областей, щоб відкрити середовище JupyterLab.
На наступному знімку екрана показано, як виглядає термінал. Додаткову інформацію про інтерфейс користувача див Зрозумійте інтерфейс користувача Workspace.
Підключіться до EMR на керованій кінцевій точці EKS
Ви можете легко підключитися до EMR на керованій кінцевій точці EKS з робочого простору.
- На панелі навігації на Кластери меню, виберіть Кластер EMR на EKS та цінності Кластерний тип.
Віртуальні кластери відображаються у спадному меню EMR Cluster у EKS, а кінцева точка – у спадному меню Endpoint. Якщо є кілька кінцевих точок, вони з’являються тут, і ви можете легко перемикатися між кінцевими точками з робочої області. - Виберіть відповідну кінцеву точку та виберіть «Приєднати».

Робота з зошитом
Тепер ви можете відкрити блокнот і підключитися до бажаного ядра, щоб виконувати свої завдання. Наприклад, ви можете вибрати ядро PySpark, як показано на наступному знімку екрана.
Досліджуйте свої дані
Першим кроком нашої вправи з дослідження даних є створення сеансу Spark, а потім завантаження набору даних про таксі Нью-Йорка з сегмента S3 у кадр даних. Використовуйте наступний блок коду, щоб завантажити дані у кадр даних. Скопіюйте URI Amazon S3 для місця, де знаходиться набір даних в Amazon S3.
Після завантаження даних у кадр даних ми замінюємо дані current_date стовпець із фактичною поточною датою, підрахуйте кількість рядків і збережіть дані у файл Parquet:
На наступному знімку екрана показано результат роботи нашого ноутбука в Amazon EMR Studio та PySpark, що працює в Amazon EMR на EKS.
Прибирати
Щоб очистити після цього поста, запустіть cdk destroy.
Висновок
У цій публікації ми показали, як за допомогою ARA можна швидко розгорнути інфраструктуру аналізу даних і почати експериментувати зі своїми даними. Ви можете знайти повний приклад, згаданий у цій публікації, у розділі GitHub сховище. Еталонна архітектура AWS Analytics реалізує загальний шаблон Analytics і найкращі практики AWS, щоб запропонувати вам готові конструкції для ваших експериментів. Одним із шаблонів є сітка даних, яку ви можете використовувати в цьому блог.
Ви також можете досліджувати інші конструкції, запропоновані в цій бібліотеці щоб поекспериментувати зі службами AWS Analytics перед перенесенням вашого робочого навантаження на виробництво.
Про авторів
 Лотфі Мухіб є старшим архітектором рішень, який працює в команді державного сектору Amazon Web Services. Він допомагає клієнтам державного сектору в регіоні EMEA реалізувати їхні ідеї, створювати нові послуги та впроваджувати інновації для громадян. У вільний час Лотфі захоплюється їздою на велосипеді та бігом.
Лотфі Мухіб є старшим архітектором рішень, який працює в команді державного сектору Amazon Web Services. Він допомагає клієнтам державного сектору в регіоні EMEA реалізувати їхні ідеї, створювати нові послуги та впроваджувати інновації для громадян. У вільний час Лотфі захоплюється їздою на велосипеді та бігом.
 Сандіпан Бхаумік є старшим спеціалістом із аналітики та архітектором рішень у Лондоні. Він працював із клієнтами в різних галузях, як-от банківські та фінансові послуги, охорона здоров’я, енергетика та комунальні послуги, виробництво та роздрібна торгівля, допомагаючи їм вирішувати складні завдання за допомогою великомасштабних платформ даних. В AWS він зосереджується на стратегічних облікових записах у Великобританії та Ірландії та допомагає клієнтам прискорити їхню подорож до хмари та впроваджувати інновації за допомогою аналітики AWS і сервісів машинного навчання. Він любить грати в бадмінтон і читати книги.
Сандіпан Бхаумік є старшим спеціалістом із аналітики та архітектором рішень у Лондоні. Він працював із клієнтами в різних галузях, як-от банківські та фінансові послуги, охорона здоров’я, енергетика та комунальні послуги, виробництво та роздрібна торгівля, допомагаючи їм вирішувати складні завдання за допомогою великомасштабних платформ даних. В AWS він зосереджується на стратегічних облікових записах у Великобританії та Ірландії та допомагає клієнтам прискорити їхню подорож до хмари та впроваджувати інновації за допомогою аналітики AWS і сервісів машинного навчання. Він любить грати в бадмінтон і читати книги.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/accelerate-your-data-exploration-and-experimentation-with-the-aws-analytics-reference-architecture-library/
- 1
- 10
- 100
- 11
- 6G
- 7
- 9
- a
- МЕНЮ
- прискорювати
- доступ
- управління доступом
- рахунки
- Рахунки
- через
- дії
- Додає
- адміністративний
- після
- агресивний
- ВСІ
- розподіл
- дозволяє
- вже
- хоча
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- аналіз
- аналітика
- та
- Apache
- додаток
- з'являтися
- Застосовувати
- відповідний
- архітектура
- аргументація
- Активи
- асоційований
- приєднувати
- Атрибути
- Authentication
- авторство
- автоматичний
- доступний
- AWS
- Клей AWS
- AWS Identity and Access Management (IAM)
- Banking
- заснований
- оскільки
- перед тим
- нижче
- КРАЩЕ
- передового досвіду
- Краще
- між
- Блокувати
- Блог
- книги
- будувати
- будівельник
- званий
- Виклики
- потужність
- випадок
- випадків
- каталог
- обережний
- CD
- сертифікат
- проблеми
- перевірка
- Вибирати
- громадяни
- клас
- класифікація
- клієнт
- хмара
- кластер
- код
- Колонка
- COM
- загальний
- повний
- комплекс
- обчислення
- стан
- З'єднуватися
- Консоль
- будувати
- містить
- контроль
- контролер
- Коштувати
- витрати
- створювати
- створений
- створює
- створення
- створення
- критичний
- Поточний
- Клієнти
- налаштувати
- дані
- аналіз даних
- Analytics даних
- інженер даних
- Дата
- дата, час
- присвячених
- дефолт
- Визначає
- розгортання
- розгортання
- розгортання
- розгортає
- description
- деталі
- розробка
- різний
- обговорювати
- документ
- Ні
- Не знаю
- водій
- кожен
- легко
- ефект
- або
- в регіоні EMEA
- включений
- дозволяє
- дозволяє
- зашифрованих
- Кінцева точка
- інженер
- Навколишнє середовище
- Ефір (ETH)
- приклад
- виконання
- Здійснювати
- експеримент
- experts
- дослідження
- Дослідницький аналіз даних
- дослідити
- завод
- сім'я
- швидше
- Федерація
- поле
- філе
- Файли
- фінансовий
- фінансові послуги
- знайти
- Перший
- фокусується
- стежити
- після
- слідує
- FRAME
- від
- Повний
- Функції
- далі
- генерується
- отримати
- GitHub
- Go
- Group
- Групи
- Hadoop
- охорона здоров'я
- допомогу
- допомагає
- тут
- Високий
- Вулик
- господар
- Як
- How To
- Однак
- HTML
- HTTPS
- IAM
- ідеї
- Особистість
- управління ідентифікацією та доступом
- Управління ідентифікацією та доступом (IAM)
- здійснювати
- реалізовані
- implements
- імпорт
- важливо
- поліпшується
- in
- промисловості
- інформація
- Інфраструктура
- оновлювати
- встановлювати
- екземпляр
- замість
- інструкції
- інтегрований
- взаємодіяти
- інтерактивний
- інтерфейс
- перерваний
- Ірландія
- IT
- робота
- Джобс
- подорож
- json
- тримати
- Кубернетес
- великий
- масштабний
- УЧИТЬСЯ
- вивчення
- Важіль
- бібліотека
- МЕЖА
- Лінія
- ліній
- LINK
- пов'язаний
- список
- Перераховані
- загрузка
- розташування
- Лондон
- ВИГЛЯДИ
- низький
- машина
- навчання за допомогою машини
- вдалося
- управління
- менеджер
- обов'язковий
- виробництво
- багато
- засоби
- механізм
- пам'ять
- Меню
- метод
- методика
- режим
- гроші
- більше
- множинний
- ім'я
- Названий
- Переміщення
- навігація
- необхідно
- Необхідність
- необхідний
- потреби
- мережу
- Нові
- Нью-Йорк
- вузол
- вузли
- ноутбук
- ноутбуки
- номер
- пропонувати
- запропонований
- Пропозиції
- ONE
- відкрити
- оптимізований
- Оптимізує
- організація
- організації
- Інше
- власний
- pane
- параметр
- параметри
- шлях
- Викрійки
- моделі
- продуктивність
- дозвіл
- Дозволи
- Фізично
- місце
- платформа
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- ігри
- Стручки
- Політика
- політика
- пошта
- влада
- практики
- переважним
- попередній
- проблеми
- процес
- процесор
- Production
- Профілі
- проект
- проектів
- властивості
- власність
- за умови
- забезпечує
- забезпечення
- громадськість
- швидко
- швидко
- Читати
- читання
- готовий
- реальний
- реального часу
- реалізувати
- рекомендувати
- облік
- зменшити
- знижує
- зареєстрований
- замінювати
- представляти
- запросити
- Вимагається
- ресурси
- обмежити
- результат
- роздрібна торгівля
- Роль
- ролі
- прогін
- біг
- користь
- то ж
- зберегти
- економія
- другий
- розділ
- сектор
- безпеку
- старший
- чутливий
- обслуговування
- Послуги
- Сесія
- комплект
- Показувати
- показаний
- Шоу
- перемішування
- підпис
- простий
- спрощений
- один
- Розмір
- невеликий
- So
- рішення
- Рішення
- ВИРІШИТИ
- Іскритися
- спеціаліст
- витрачати
- відпрацьований
- Spot
- SQL
- стек
- старт
- почалася
- Починаючи
- заяви
- Статус
- Крок
- заходи
- зупинений
- зберігання
- зберігати
- магазинів
- Стратегічний
- потік
- студія
- студії
- уявлення
- представляти
- представлений
- підмережі
- такі
- підходящий
- поставляється
- Підтримуючий
- перемикач
- приймає
- завдання
- команда
- шаблон
- тимчасовий
- термінал
- Команда
- Великобританія
- їх
- через
- пропускна здатність
- час
- до
- занадто
- Усього:
- переклад
- Перетворення
- перехід
- правда
- підручник
- Типи
- Машинопис
- Uk
- що лежить в основі
- блок
- Оновити
- Updates
- завантажено
- URI
- використання
- користувач
- Інтерфейс користувача
- користувачі
- комунальні послуги
- значення
- Цінності
- версія
- контроль версій
- вид
- Віртуальний
- обсяг
- чекати
- Web
- веб-сервіси
- Що
- який
- волі
- в
- Work
- працював
- робочий
- Робочі процеси
- робочий
- запис
- ямл
- вашу
- зефірнет