Організації вирішили створювати озера даних поверх Служба простого зберігання Amazon (Amazon S3) протягом багатьох років. Озеро даних є найпопулярнішим вибором для організацій для зберігання всіх своїх організаційних даних, створених різними командами, у різних бізнес-доменах, у всіх різних форматах і навіть за історію. Відповідно до дослідження, середня компанія спостерігає зростання обсягу своїх даних зі швидкістю, що перевищує 50% на рік, зазвичай керуючи в середньому 33 унікальними джерелами даних для аналізу.
Команди часто намагаються відтворити тисячі завдань із реляційних баз даних із однаковим шаблоном вилучення, перетворення та завантаження (ETL). Потрібно багато зусиль для підтримки станів завдань і планування цих окремих завдань. Цей підхід допомагає командам додавати таблиці з невеликими змінами, а також підтримує статус завдання з мінімальними зусиллями. Це може призвести до значного покращення графіка розробки та легкого відстеження завдань.
У цій публікації ми покажемо вам, як легко скопіювати всі ваші реляційні сховища даних в озеро транзакційних даних автоматизованим способом за допомогою одного завдання ETL за допомогою Apache Iceberg і Клей AWS.
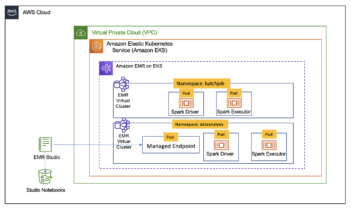
Архітектура рішення
Є озера даних зазвичай організовано використання окремих сегментів S3 для трьох рівнів даних: необробленого рівня, що містить дані в оригінальній формі, етапного рівня, що містить проміжні оброблені дані, оптимізовані для споживання, і аналітичного рівня, що містить агреговані дані для конкретних випадків використання. На необробленому рівні таблиці зазвичай організовано на основі їхніх джерел даних, тоді як таблиці на рівні етапу організовано на основі бізнес-доменів, до яких вони належать.
Ця публікація надає AWS CloudFormation шаблон, який розгортає завдання AWS Glue, яке зчитує шлях Amazon S3 для одного джерела даних необробленого рівня озера даних і завантажує дані в таблиці Apache Iceberg на рівні сцени за допомогою Підтримка AWS Glue для фреймворків озера даних. Завдання очікує, що таблиці в необробленому шарі будуть структуровані відповідним чином Служба міграції бази даних AWS (AWS DMS) поглинає їх: схему, потім таблицю, потім файли даних.
Це рішення використовує Зберігання параметрів AWS Systems Manager для конфігурації столу. Ви повинні змінити цей параметр, вказавши таблиці, які ви хочете обробляти, і спосіб, включаючи таку інформацію, як первинний ключ, розділи та пов’язаний бізнес-домен. Завдання використовує цю інформацію для автоматичного створення бази даних (якщо вона ще не існує) для кожного домену бізнесу, створення таблиць Iceberg і виконання завантаження даних.
Нарешті, ми можемо використовувати Амазонка Афіна для запиту даних у таблицях Iceberg.
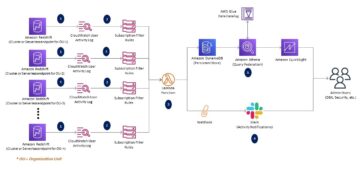
Наступна схема ілюструє цю архітектуру.

Ця реалізація має такі міркування:
- Усі таблиці з джерела даних повинні мати первинний ключ для реплікації за допомогою цього рішення. Первинний ключ може бути одним стовпцем або складеним ключем із кількома стовпцями.
- Якщо озеро даних містить таблиці, які не потребують змін або не мають первинного ключа, ви можете виключити їх із конфігурації параметрів і запровадити традиційні процеси ETL, щоб ввести їх в озеро даних. Це виходить за рамки цієї публікації.
- Якщо є додаткові джерела даних, які потрібно отримати, ви можете розгорнути кілька стеків CloudFormation, по одному для обробки кожного джерела даних.
- Завдання AWS Glue розроблено для обробки даних у два етапи: початкове завантаження, яке виконується після того, як AWS DMS завершить завдання повного завантаження, і поступове завантаження, яке виконується за розкладом, який застосовує файли збору змінених даних (CDC), отримані AWS DMS. Інкрементна обробка виконується за допомогою an Закладка AWS Glue.
Існує дев’ять кроків, щоб виконати цей підручник:
- Налаштуйте вихідну кінцеву точку для AWS DMS.
- Розгорніть рішення за допомогою AWS CloudFormation.
- Перегляньте завдання реплікації AWS DMS.
- За бажанням додайте дозволи на шифрування та дешифрування або Формування озера AWS.
- Перегляньте конфігурацію таблиці в Parameter Store.
- Виконайте початкове завантаження даних.
- Виконайте поступове завантаження даних.
- Моніторинг прийому таблиці.
- Заплануйте поступове пакетне завантаження даних.
Передумови
Перш ніж почати цей підручник, ви повинні бути знайомі з Iceberg. Якщо ви ні, ви можете почати з копіювання однієї таблиці, дотримуючись інструкцій у Реалізуйте UPSERT на основі CDC в озері даних за допомогою Apache Iceberg і AWS Glue. Додатково налаштуйте наступне:
Налаштуйте вихідну кінцеву точку для AWS DMS
Перш ніж створити наше завдання AWS DMS, нам потрібно налаштувати вихідну кінцеву точку для підключення до вихідної бази даних:
- На консолі AWS DMS виберіть Кінцеві точки у навігаційній панелі.
- Вибирати Створити кінцеву точку.
- Якщо ваша база даних працює на Amazon RDS, виберіть Виберіть екземпляр RDS DB, а потім виберіть екземпляр зі списку. В іншому випадку виберіть джерело механізму та надайте інформацію про підключення через Менеджер секретів AWS або вручну.
- для Ідентифікатор кінцевої точки, введіть назву кінцевої точки; наприклад, source-postgresql.
- Вибирати Створити кінцеву точку.
Розгорніть рішення за допомогою AWS CloudFormation
Створіть стек CloudFormation за допомогою наданого шаблону. Виконайте наступні дії:
- Вибирати Стек запуску:

- Вибирати МАЙБУТНІ.
- Укажіть назву стека, наприклад
transactionaldl-postgresql. - Введіть необхідні параметри:
- DMSS3EndpointIAMRoleARN – Роль IAM ARN для AWS DMS для запису даних в Amazon S3.
- ReplicationInstanceArn – Примірник реплікації AWS DMS ARN.
- S3BucketStage – Ім’я наявного сегмента, що використовується для рівня етапу озера даних.
- S3BucketGlue – Назва наявного сегмента S3 для зберігання сценаріїв AWS Glue.
- S3BucketRaw – Назва наявного сегмента, який використовується для необробленого шару озера даних.
- SourceEndpointArn – Кінцева точка AWS DMS ARN, яку ви створили раніше.
- SourceName – Довільний ідентифікатор джерела даних для реплікації (наприклад,
postgres). Це використовується для визначення шляху S3 озера даних (необробленого шару), де зберігатимуться дані.
- Не змінюйте такі параметри:
- SourceS3BucketBlog – Назва сегмента, де зберігається наданий сценарій AWS Glue.
- SourceS3BucketPrefix – Назва префікса сегмента, де зберігається наданий сценарій AWS Glue.
- Вибирати МАЙБУТНІ двічі
- Select Я визнаю, що AWS CloudFormation може створювати ресурси IAM із користувацькими іменами.
- Вибирати Створити стек.
Приблизно через 5 хвилин стек CloudFormation розгортається.
Перегляньте завдання реплікації AWS DMS
Розгортання AWS CloudFormation створило для вас цільову кінцеву точку AWS DMS. Через два особливих налаштування кінцевої точки дані надсилатимуться в Amazon S3 у міру потреби.
- На консолі AWS DMS виберіть Кінцеві точки у навігаційній панелі.
- Знайдіть і виберіть кінцеву точку, яка починається з
dmsIcebergs3endpoint. - Перегляньте налаштування кінцевої точки:
DataFormatвказано якparquet.TimestampColumnNameдодасть стовпецьlast_update_timeіз датою створення записів на Amazon S3.

Розгортання також створює завдання реплікації AWS DMS, яке починається з dmsicebergtask.
- Вибирати Завдання реплікації на панелі навігації та знайдіть завдання.
Ви побачите, що Тип завдання позначено як Повне завантаження, постійна реплікація. AWS DMS виконає початкове повне завантаження існуючих даних, а потім створить додаткові файли зі змінами, внесеними до вихідної бази даних.
на Правила картографування є два типи правил:
- Правило вибору з назвою вихідної схеми та таблиць, які будуть отримані з вихідної бази даних. За замовчуванням він використовує зразок бази даних, наданий у попередніх вимогах,
dms_sampleі всі таблиці з ключовим словом %. - Два правила перетворення, які включають у цільові файли на Amazon S3 назву схеми та назву таблиці як стовпці. Це використовується нашим завданням AWS Glue, щоб знати, яким таблицям відповідають файли в озері даних.
Щоб дізнатися більше про те, як налаштувати це для ваших власних джерел даних, див Правила вибору та дії.

Давайте змінимо деякі конфігурації, щоб завершити підготовку до завдання.
- на Дії меню, виберіть Змінювати.
- У Параметри завдання розділ під Зупиніть завдання після повного завантаженнявиберіть Зупинити після застосування кешованих змін.
Таким чином ми можемо контролювати початкове завантаження та поступове створення файлу як два різні кроки. Ми використовуємо цей двоетапний підхід, щоб запускати завдання AWS Glue один раз на кожному кроці.
- під Журнали завданьвиберіть Увімкніть журнали CloudWatch.
- Вибирати зберегти.
- Зачекайте приблизно 1 хвилину, поки статус завдання міграції бази даних не відобразиться як Готовий.
Додайте дозволи на шифрування та дешифрування або Lake Formation
За бажанням ви можете додати дозволи на шифрування та дешифрування або Lake Formation.
Додайте дозволи на шифрування та дешифрування
Якщо ваші сегменти S3, які використовуються для необроблених і сценічних шарів, зашифровано за допомогою Служба управління ключами AWS (AWS KMS) керованих клієнтом ключів, потрібно додати дозволи, щоб дозволити роботі AWS Glue отримати доступ до даних:
Додайте дозволи на формування озера
Якщо ви керуєте дозволами за допомогою Lake Formation, вам потрібно дозволити роботі AWS Glue створювати бази даних і таблиці вашого домену через роль IAM GlueJobRole.
- Надайте дозвіл на створення баз даних (інструкції див Створення бази даних).
- Надайте SUPER дозволи для
defaultбази даних. - Надайте дозволи на розташування даних.
- Якщо ви створюєте бази даних вручну, надайте дозволи на створення таблиць для всіх баз даних. Відноситься до Надання дозволів таблиці за допомогою консолі Lake Formation і методу іменованого ресурсу or Надання дозволів каталогу даних за допомогою методу LF-TBAC відповідно до вашого випадку використання.
Після завершення наступного етапу початкового завантаження даних переконайтеся, що ви також додали дозволи для споживачів на запити до таблиць. Роль посади стане власником усіх створених таблиць, а адміністратор озера даних зможе надавати гранти додатковим користувачам.
Перегляньте конфігурацію таблиці в Parameter Store
Завдання AWS Glue, яке виконує введення даних у таблиці Iceberg, використовує специфікацію таблиці, надану в Parameter Store. Виконайте наступні кроки, щоб переглянути сховище параметрів, яке було автоматично налаштовано для вас. Якщо потрібно, змініть відповідно до власних потреб.
- На консолі «Сховище параметрів» виберіть Мої параметри у навігаційній панелі.
Стек CloudFormation створив два параметри:
iceberg-configдля конфігурації завданьiceberg-tablesдля конфігурації столу
- Виберіть параметр айсберг-таблиці.
Структура JSON містить інформацію, яку AWS Glue використовує для читання даних і запису таблиць Iceberg у цільовому домені:
- Один об'єкт на стіл – Ім’я об’єкта створюється за допомогою імені схеми, крапки та імені таблиці; наприклад,
schema.table. - первинний ключ – Це має бути зазначено для кожної вихідної таблиці. Ви можете надати один стовпець або список стовпців, розділених комами (без пробілів).
- partitionCols – Додатково розбиває стовпці для цільових таблиць. Якщо ви не хочете створювати розділені таблиці, укажіть порожній рядок. В іншому випадку надайте один стовпець або список стовпців, розділених комами (без пробілів).
- Якщо ви хочете використовувати власне джерело даних, скористайтеся наведеним нижче кодом JSON і замініть текст великими літерами з наданого шаблону. Якщо ви використовуєте наданий зразок джерела даних, збережіть налаштування за замовчуванням:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Вибирати зберегти зміни.
Виконайте початкове завантаження даних
Тепер, коли необхідну конфігурацію завершено, ми завантажуємо початкові дані. Цей крок включає три частини: введення даних із вихідної реляційної бази даних у необроблений шар озера даних, створення таблиць Iceberg на рівні сцени озера даних і перевірка результатів за допомогою Athena.
Передайте дані в необроблений шар озера даних
Щоб отримати дані з реляційного джерела даних (PostgreSQL, якщо ви використовуєте наданий зразок) до нашого транзакційного озера даних за допомогою Iceberg, виконайте такі дії:
- На консолі AWS DMS виберіть Завдання міграції бази даних у навігаційній панелі.
- Виберіть завдання реплікації, яке ви створили, і на Дії меню, виберіть Перезапустити/Відновити.
- Зачекайте приблизно 5 хвилин, доки завершиться завдання реплікації. Ви можете відстежувати таблиці, завантажені на Статистика вкладка завдання реплікації.

Через кілька хвилин завдання завершується повідомленням Повне завантаження завершено.
- На консолі Amazon S3 виберіть відро, яке ви визначили як необроблений шар.
Під префіксом S3, визначеним у AWS DMS (наприклад, postgres), ви повинні побачити ієрархію папок із такою структурою:
- схема
- назва таблиці
LOAD00000001.parquetLOAD0000000N.parquet
- назва таблиці

Якщо ваше відро S3 порожнє, перегляньте Усунення проблем із завданнями міграції в AWS Database Migration Service перед виконанням завдання AWS Glue.
Створюйте та вводьте дані в таблиці Iceberg
Перш ніж запустити завдання, давайте ознайомимося зі сценарієм завдання AWS Glue, що надається як частина стеку CloudFormation, щоб зрозуміти його поведінку.
- На консолі AWS Glue Studio виберіть Джобс у навігаційній панелі.
- Шукайте роботу, з якої починається
IcebergJob-і суфікс імені стека CloudFormation (наприклад,IcebergJob-transactionaldl-postgresql). - Виберіть роботу.

Сценарій завдання отримує необхідну конфігурацію зі сховища параметрів. Функція getConfigFromSSM() повертає конфігурації, пов’язані з завданням, наприклад вихідні та цільові сегменти, звідки потрібно читати та записувати дані. Змінна ssmparam_table_values містити інформацію, пов’язану з таблицею, як-от домен даних, ім’я таблиці, стовпці розділу та первинний ключ таблиць, які потрібно отримати. Перегляньте наступний код Python:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']Сценарій використовує довільну назву каталогу для Iceberg, яка визначається як my_catalog. Це реалізовано в каталозі даних AWS Glue за допомогою конфігурацій Spark, тому операція SQL, яка вказує на my_catalog, буде застосована до каталогу даних. Перегляньте наступний код:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
Сценарій повторює таблиці, визначені в Parameter Store, і виконує логіку для виявлення, чи існує таблиця та чи вхідні дані є початковим завантаженням або upsert:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')Команда initialLoadRecordsSparkSQL() функція завантажує початкові дані, якщо у файлах S3 немає стовпця операції. AWS DMS додає цей стовпець лише до файлів даних Parquet, створених за допомогою безперервної реплікації (CDC). Завантаження даних виконується за допомогою команди INSERT INTO з SparkSQL. Перегляньте наступний код:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Тепер ми запускаємо завдання AWS Glue, щоб ввести вихідні дані в таблиці Iceberg. Стек CloudFormation додає --datalake-formats параметр, додаючи необхідні бібліотеки Iceberg до завдання.
- Вибирати Виконати роботу.
- Вибирати Робота виконується стежити за станом. Дочекайтеся статусу Запуск успішно виконано.
Перевірте завантажені дані
Щоб підтвердити, що завдання обробило дані належним чином, виконайте такі дії:
- На консолі Athena виберіть Редактор запитів у навігаційній панелі.
- Перевірити
AwsDataCatalogвибрано як джерело даних. - під Database, виберіть область даних, яку ви хочете дослідити, на основі конфігурації, яку ви визначили в сховищі параметрів. Якщо використовується наданий зразок бази даних, використовуйте
sports.
під Таблиці та види, ми можемо побачити список таблиць, створених завданням AWS Glue.
- Виберіть меню параметрів (три крапки) біля назви першої таблиці, а потім виберіть Попередній перегляд даних.
Ви можете бачити дані, завантажені в таблиці Iceberg. 
Виконайте поступове завантаження даних
Тепер ми починаємо фіксувати зміни з нашої реляційної бази даних і застосовувати їх до озера транзакційних даних. Цей крок також складається з трьох частин: запис змін, застосування їх до таблиць Iceberg і перевірка результатів.
Зберігайте зміни з реляційної бази даних
Через вказану нами конфігурацію завдання реплікації зупинилося після виконання фази повного завантаження. Тепер ми перезапустимо завдання, щоб додати додаткові файли зі змінами в необроблений рівень озера даних.
- На консолі AWS DMS виберіть завдання, яке ми створили та запустили раніше.
- на Дії меню, виберіть Резюме.
- Вибирати Почати завдання щоб почати запис змін.
- Щоб ініціювати створення нового файлу в озері даних, виконайте вставки, оновлення або видалення в таблицях вихідної бази даних за допомогою бажаного інструменту адміністрування бази даних. Якщо ви використовуєте приклад бази даних, ви можете виконати такі команди SQL:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- На сторінці деталей завдання AWS DMS виберіть Таблиця статистики вкладку, щоб побачити внесені зміни.

- Відкрийте необроблений рівень озера даних, щоб знайти новий файл із поступовими змінами всередині кожного префікса таблиці, наприклад під
sporting_eventпрефікс.
Запис зі змінами для sporting_event Таблиця виглядає так, як на знімку екрана нижче.

Зверніть увагу на Op стовпець на початку позначено оновленням (U). Крім того, друге значення дати/часу є контрольним стовпцем, доданим AWS DMS із часом фіксації зміни.

Застосуйте зміни до таблиць Iceberg за допомогою AWS Glue
Тепер ми знову запускаємо завдання AWS Glue, і воно автоматично оброблятиме лише нові додаткові файли, оскільки закладку завдання ввімкнено. Давайте розглянемо, як це працює.
Команда dedupCDCRecords() функція виконує дедуплікацію даних, оскільки кілька змін до одного ідентифікатора запису можуть бути зафіксовані в одному файлі даних на Amazon S3. Дедуплікація виконується на основі last_update_time стовпець, доданий AWS DMS, який вказує позначку часу, коли було зафіксовано зміну. Перегляньте наступний код Python:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFНа лінії 99 upsertRecordsSparkSQL() функція виконує upsert подібним чином до початкового завантаження, але цього разу за допомогою команди SQL MERGE.
Перегляньте внесені зміни
Відкрийте консоль Athena та запустіть запит, який вибирає змінені записи у вихідній базі даних. Якщо використовується наданий зразок бази даних, використовуйте один із таких запитів SQL:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Моніторинг прийому таблиці
Сценарій завдання AWS Glue закодовано за допомогою простих Обробка винятків Python для виявлення помилок під час обробки конкретної таблиці. Закладка завдання зберігається після успішного завершення обробки кожної таблиці, щоб уникнути повторної обробки таблиць у разі повторної спроби виконання завдання для таблиць із помилками.
Команда Інтерфейс командного рядка AWS (AWS CLI) забезпечує a get-job-bookmark команда для AWS Glue, яка надає інформацію про статус закладки для кожної обробленої таблиці.
- На консолі AWS Glue Studio виберіть завдання ETL.
- Виберіть Робота виконується та скопіюйте ідентифікатор запуску завдання.
- Виконайте наступну команду на терміналі, автентифікованому для AWS CLI, замінивши
<GLUE_JOB_RUN_ID>у рядку 1 зі значенням, яке ви скопіювали. Якщо ваш стек CloudFormation не має іменіtransactionaldl-postgresql, введіть назву вашої роботи у рядку 2 сценарію:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunУ цьому рішенні, якщо обробка таблиці спричиняє виняткову ситуацію, завдання AWS Glue не завершиться збоєм відповідно до цієї логіки. Натомість таблицю буде додано до масиву, який буде надруковано після завершення завдання. У такому випадку завдання буде позначено як невдале після спроби обробити решту таблиць, виявлених у джерелі необроблених даних. Таким чином, таблиці без помилок не повинні чекати, поки користувач ідентифікує та вирішить проблему в конфліктуючих таблицях. Користувач може швидко виявити запуски завдань, у яких виникли проблеми, використовуючи статус виконання завдань AWS Glue, і визначити, які конкретні таблиці викликають проблему, використовуючи журнали CloudWatch для виконання завдань.
- Сценарій завдання реалізує цю функцію за допомогою такого коду Python:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')На наступному знімку екрана показано, як журнали CloudWatch шукають таблиці, які викликають помилки під час обробки.

Узгоджено з Об’єктив аналізу даних добре архітектурної системи AWS практики, ви можете адаптувати більш складні механізми контролю для виявлення та сповіщення зацікавлених сторін, коли в конвеєрах даних з’являються помилки. Наприклад, ви можете використовувати Amazon DynamoDB контрольна таблиця для зберігання всіх таблиць і виконання завдань з помилками, або за допомогою Служба простих сповіщень Amazon (Amazon SNS) до надсилати оповіщення операторам коли виконуються певні критерії.
Заплануйте поступове пакетне завантаження даних
Стек CloudFormation розгортає Amazon EventBridge правило (вимкнено за замовчуванням), яке може ініціювати виконання завдання AWS Glue за розкладом. Щоб надати власний розклад і активувати правило, виконайте такі дії:
- На консолі EventBridge виберіть Правила у навігаційній панелі.
- Шукайте правило з префіксом назви стека CloudFormation, а потім
JobTrigger(наприклад,transactionaldl-postgresql-JobTrigger-randomvalue). - Виберіть правило.
- під Розклад заходіввиберіть Редагувати.
Розклад за замовчуванням налаштовано на кожну годину.
- Надайте графік виконання роботи.
- Крім того, ви можете використовувати Вираз cron EventBridge шляхом вибору Дрібнозернистий графік.

- Коли ви завершите налаштування виразу cron, виберіть МАЙБУТНІ тричі, і нарешті вибрати Правило оновлення щоб зберегти зміни.
Правило створюється вимкненим за замовчуванням, щоб ви могли спочатку запустити початкове завантаження даних.
- Активуйте правило, вибравши включити.
Ви можете використовувати Моніторинг для перегляду викликів правил або безпосередньо на AWS Glue Запуск завдання подробиці
Висновок
Після розгортання цього рішення ви автоматизували надходження своїх таблиць в єдине джерело реляційних даних. Організаціям, які використовують озеро даних як центральну платформу даних, зазвичай потрібно обробляти кілька, іноді навіть десятки джерел даних. Крім того, дедалі більше випадків використання вимагають від організацій впровадження транзакційних можливостей для озера даних. Ви можете використовувати це рішення, щоб прискорити впровадження таких можливостей у всіх ваших реляційних джерелах даних, щоб створити нові бізнес-випадки використання, автоматизувавши процес впровадження, щоб отримати більше цінності від ваших даних.
Про авторів
 Луїс Херардо Баеза є архітектором великих даних у лабораторії даних Amazon Web Services (AWS). Він має 12-річний досвід надання допомоги організаціям у сферах охорони здоров’я, фінансах та освіті запровадити програми корпоративної архітектури, хмарні обчислення та можливості аналізу даних. Наразі Луїс допомагає організаціям у Латинській Америці прискорити стратегічні ініціативи щодо даних.
Луїс Херардо Баеза є архітектором великих даних у лабораторії даних Amazon Web Services (AWS). Він має 12-річний досвід надання допомоги організаціям у сферах охорони здоров’я, фінансах та освіті запровадити програми корпоративної архітектури, хмарні обчислення та можливості аналізу даних. Наразі Луїс допомагає організаціям у Латинській Америці прискорити стратегічні ініціативи щодо даних.
 Сайкіран Редді Енугу є архітектором даних у лабораторії даних Amazon Web Services (AWS). Він має 10-річний досвід впровадження процесів завантаження, трансформації та візуалізації даних. Зараз SaiKiran допомагає організаціям у Північній Америці запровадити сучасні архітектури даних, такі як озера даних і мережа даних. Він має досвід роботи у сфері роздрібної торгівлі, авіакомпаній та фінансів.
Сайкіран Редді Енугу є архітектором даних у лабораторії даних Amazon Web Services (AWS). Він має 10-річний досвід впровадження процесів завантаження, трансформації та візуалізації даних. Зараз SaiKiran допомагає організаціям у Північній Америці запровадити сучасні архітектури даних, такі як озера даних і мережа даних. Він має досвід роботи у сфері роздрібної торгівлі, авіакомпаній та фінансів.
 Нарендра Мерла є архітектором даних у лабораторії даних Amazon Web Services (AWS). Він має 12-річний досвід у розробці та виробництві конвеєрів даних у реальному часі та пакетно-орієнтованих даних, а також створення озер даних як у хмарі, так і в локальному середовищі. Зараз Нарендра допомагає організаціям у Північній Америці створювати та проектувати надійні архітектури даних, а також має досвід роботи в телекомунікаційному та фінансовому секторах.
Нарендра Мерла є архітектором даних у лабораторії даних Amazon Web Services (AWS). Він має 12-річний досвід у розробці та виробництві конвеєрів даних у реальному часі та пакетно-орієнтованих даних, а також створення озер даних як у хмарі, так і в локальному середовищі. Зараз Нарендра допомагає організаціям у Північній Америці створювати та проектувати надійні архітектури даних, а також має досвід роботи в телекомунікаційному та фінансовому секторах.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- МЕНЮ
- прискорювати
- доступ
- За
- визнавати
- через
- пристосовувати
- доданий
- Додатковий
- Додатково
- Додає
- адмін
- адміністрація
- прийняти
- Прийняття
- після
- авіакомпанія
- ВСІ
- вже
- Amazon
- Амазонка Афіна
- Amazon RDS
- Amazon Web Services
- Веб-служби Amazon (AWS)
- Америка
- аналіз
- аналітика
- та
- -Анджелесі
- Apache
- з'являтися
- додаток
- прикладної
- Застосування
- підхід
- приблизно
- архітектура
- масив
- асоційований
- автентифіковано
- автоматизувати
- Автоматизований
- автоматично
- автоматизація
- середній
- уникнути
- AWS
- AWS CloudFormation
- Клей AWS
- заснований
- кажани
- оскільки
- ставати
- перед тим
- початок
- Великий
- Великий даних
- будувати
- будівельник
- Створюємо
- бізнес
- Може отримати
- можливості
- шапки
- захоплення
- захопивши
- випадок
- випадків
- каталог
- Залучайте
- Викликати
- Причини
- викликаючи
- CDC
- центральний
- певний
- зміна
- Зміни
- вибір
- Вибирати
- Вибираючи
- вибраний
- хмара
- хмарних обчислень
- код
- Колонка
- Колони
- компанія
- повний
- обчислення
- конфігурація
- конфігурації
- підтвердити
- Конфлікти
- З'єднуватися
- зв'язку
- міркування
- Консоль
- Споживачі
- споживання
- містить
- продовжувати
- безперервний
- контроль
- може
- створювати
- створений
- створює
- створення
- створення
- Критерії
- В даний час
- виготовлений на замовлення
- клієнт
- налаштувати
- дані
- Analytics даних
- Озеро даних
- Платформа даних
- Database
- базами даних
- Дата
- дефолт
- певний
- розгортання
- розгорнути
- розгортання
- розгортання
- розгортає
- дизайн
- призначений
- проектування
- деталі
- виявлено
- розробка
- різний
- безпосередньо
- інвалід
- розділений
- Ні
- домен
- домени
- Не знаю
- під час
- кожен
- Раніше
- легко
- Освіта
- зусилля
- або
- включіть
- включений
- зашифрованих
- шифрування
- Кінцева точка
- двигун
- Що натомість? Створіть віртуальну версію себе у
- підприємство
- середовищах
- помилки
- Ефір (ETH)
- Навіть
- Кожен
- приклад
- перевищує
- Крім
- виняток
- існуючий
- існує
- очікуваний
- чекає
- досвід
- дослідити
- Розширення
- витяг
- не вдалося
- знайомий
- мода
- особливість
- кілька
- філе
- Файли
- в кінці кінців
- фінансування
- фінансовий
- знайти
- закінчення
- Перший
- потім
- після
- Для споживачів
- форма
- освіта
- Рамки
- від
- Повний
- функція
- генерується
- покоління
- отримати
- надавати
- гранти
- Зростання
- обробляти
- охорона здоров'я
- допомогу
- допомагає
- ієрархія
- історія
- проведення
- Як
- How To
- HTML
- HTTPS
- величезний
- IAM
- ідентифікований
- ідентифікатор
- ідентифікує
- ідентифікувати
- здійснювати
- реалізація
- реалізовані
- реалізації
- implements
- поліпшення
- in
- включати
- includes
- У тому числі
- Вхідний
- вказує
- індивідуальний
- інформація
- початковий
- ініціативи
- Вставки
- розуміння
- екземпляр
- замість
- інструкції
- Проміжний
- питання
- питання
- IT
- ітерація
- робота
- Джобс
- json
- тримати
- ключ
- ключі
- Знати
- lab
- озеро
- Latin
- Латинська Америка
- шар
- шарів
- вести
- УЧИТЬСЯ
- libraries
- МЕЖА
- Лінія
- список
- загрузка
- погрузка
- вантажі
- розташування
- подивитися
- ВИГЛЯДИ
- в
- Лос-Анджелес
- серія
- головний
- підтримує
- зробити
- вдалося
- управління
- менеджер
- управління
- вручну
- багато
- відображення
- позначено
- Меню
- Злиття
- повідомлення
- може бути
- міграція
- мінімальний
- хвилин
- протокол
- сучасний
- змінювати
- монітор
- моніторинг
- більше
- найбільш
- Найбільш популярний
- множинний
- ім'я
- Названий
- Імена
- Переміщення
- навігація
- Необхідність
- необхідний
- потреби
- Нові
- наступний
- На північ
- Північна Америка
- сповіщення
- номер
- об'єкт
- об'єкти
- ONE
- постійний
- OP
- операція
- оптимізований
- Опції
- організаційної
- організації
- Організований
- оригінал
- інакше
- поза
- власний
- власник
- pane
- параметр
- параметри
- частина
- частини
- шлях
- Викрійки
- виконувати
- виконанні
- виступає
- period
- Дозволи
- фаза
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- популярний
- пошта
- postgresql
- практики
- переважним
- передумови
- представити
- первинний
- Проблема
- процес
- процеси
- обробка
- Вироблений
- програми
- забезпечувати
- за умови
- забезпечує
- Python
- швидко
- підвищення
- ставка
- Сировина
- необроблені дані
- Читати
- реального часу
- запис
- облік
- замінювати
- тиражувати
- копіювання
- вимагати
- вимагається
- ресурс
- ресурси
- REST
- результати
- роздрібна торгівля
- повертати
- Умови повернення
- огляд
- міцний
- Роль
- Правило
- Правила
- прогін
- біг
- то ж
- зберегти
- сценарій
- розклад
- сфера
- scripts
- Пошук
- другий
- Сектори
- бачачи
- обраний
- вибирає
- вибір
- окремий
- Послуги
- комплект
- установка
- налаштування
- Повинен
- Показувати
- Шоу
- аналогічний
- простий
- з
- один
- So
- рішення
- Вирішує
- деякі
- складний
- Source
- Джерела
- пробіли
- Іскритися
- конкретний
- специфікація
- зазначений
- SPORTS
- SQL
- стек
- Стеки
- Стажування
- зацікавлених сторін
- старт
- почалася
- Починаючи
- починається
- Штати
- статистика
- Статус
- Крок
- заходи
- зупинений
- зберігання
- зберігати
- зберігати
- магазинів
- Стратегічний
- структура
- структурований
- студія
- Успішно
- такі
- Super
- підтримка
- Systems
- таблиця
- Мета
- Завдання
- завдання
- команда
- команди
- телеком
- шаблон
- термінал
- Команда
- Джерело
- їх
- тисячі
- три
- через
- час
- Терміни
- times
- відмітка часу
- до
- інструмент
- топ
- Усього:
- Відстеження
- традиційний
- транзакційний
- Перетворення
- Перетворення
- викликати
- підручник
- Типи
- при
- розуміти
- створеного
- Оновити
- Updates
- використання
- використання випадку
- користувач
- користувачі
- зазвичай
- значення
- перевірка
- вид
- візуалізації
- обсяг
- чекати
- Склад
- Web
- веб-сервіси
- який
- волі
- в
- без
- працює
- запис
- письмовий
- ямл
- рік
- років
- вашу
- зефірнет