Автопілот Amazon SageMaker допомагає завершити робочий процес наскрізного машинного навчання (ML), автоматизуючи етапи розробки функцій, навчання, налаштування та розгортання моделі ML для висновків. Ви надаєте SageMaker Autopilot набір табличних даних і цільовий атрибут для прогнозування. Потім SageMaker Autopilot автоматично вивчає ваші дані, тренує, налаштовує, рангує та знаходить найкращу модель. Нарешті, ви можете розгорнути цю модель у виробництві для висновків одним клацанням миші.
Що нового?
Нещодавно запущена функція, Звіти про якість моделі автопілота SageMakerтепер звітує про показники вашої моделі, щоб забезпечити кращу видимість ефективності вашої моделі для проблем регресії та класифікації. Ви можете використовувати ці показники, щоб отримати більше інформації про найкращу модель у таблиці лідерів моделей.
Ці показники та звіти, доступні на новій вкладці «Ефективність» у розділі «Деталі моделі» найкращої моделі, включають матриці плутанини, площу під кривою робочих характеристик приймача (AUC-ROC) і площу під кривою точності відкликання. (AUC-PR). Ці показники допомагають зрозуміти хибно-позитивні/хибно-негативні результати (FP/FN), компроміси між справжніми спрацьовуваннями (TP) і хибно-позитивними (FP), а також компроміси між точністю та запам’ятовуванням для оцінки найкращих характеристик продуктивності моделі.
Запуск експерименту SageMaker Autopilot
Набір даних
Ми використовуємо Набір банківських маркетингових даних UCI щоб продемонструвати звіти про якість моделі автопілота SageMaker. Ці дані містять атрибути клієнта, такі як вік, тип роботи, сімейний стан та інші, які ми використовуватимемо, щоб передбачити, чи відкриє клієнт рахунок у банку. Набір даних стосується цього рахунку як строкового депозиту. Це робить наш випадок проблемою бінарної класифікації – прогноз буде або «так», або «ні». SageMaker Autopilot згенерує кілька моделей від нашого імені, щоб найкраще передбачити потенційних клієнтів. Потім ми розглянемо звіт про якість моделі для SageMaker Autopilot найкраща модель.
Передумови
Щоб почати експеримент SageMaker Autopilot, ви повинні спочатку розмістити свої дані в Служба простого зберігання Amazon (Amazon S3) відро. Укажіть сегмент і префікс, які ви хочете використовувати для навчання. Переконайтеся, що відро знаходиться в тому самому регіоні, що й експеримент SageMaker Autopilot. Ви також повинні переконатися, що автопілот ролі Identity and Access Management (IAM) має дозволи на доступ до даних в Amazon S3.
Створення експерименту
У вас є кілька варіантів створення експерименту SageMaker Autopilot у SageMaker Studio. Відкривши нову програму запуску, ви можете отримати прямий доступ до SageMaker Autopilot. Якщо ні, ви можете вибрати піктограму ресурсів SageMaker ліворуч. Далі можна вибрати Експерименти та випробування з випадаючого меню.
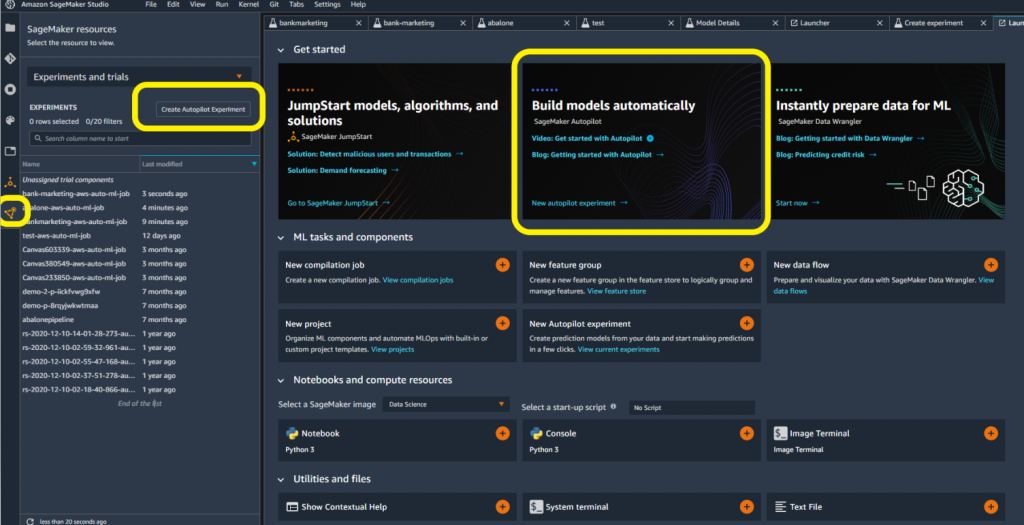
- Дайте назву своєму експерименту.
- Підключіться до джерела даних, вибравши сегмент Amazon S3 і назву файлу.
- Виберіть розташування вихідних даних в Amazon S3.
- Виберіть цільовий стовпець для свого набору даних. У цьому випадку ми націлюємося на стовпець «y», щоб вказати так/ні.
- За бажанням укажіть назву кінцевої точки, якщо ви бажаєте, щоб SageMaker Autopilot автоматично розгортав кінцеву точку моделі.
- Залиште всі інші розширені параметри за замовчуванням і виберіть Створити експеримент.

Після завершення експерименту ви зможете побачити результати в SageMaker Studio. SageMaker Autopilot представить найкращу модель серед різних моделей, які він навчає. Ви можете переглянути деталі та результати для різних випробувань, але ми використаємо найкращу модель, щоб продемонструвати використання звітів про якість моделі.
- Виберіть модель і клацніть правою кнопкою миші, щоб Відкрити в деталях моделі.
- У деталях моделі виберіть продуктивність вкладка. Це показує показники моделі через візуалізації та графіки.
- під продуктивністьвиберіть Завантажте звіти про ефективність як PDF.


Інтерпретація звіту про якість моделі автопілота SageMaker
Звіт про якість моделі підсумовує роботу SageMaker Autopilot і деталі моделі. Ми зосередимося на форматі PDF звіту, але ви також можете отримати доступ до результатів у форматі JSON. Оскільки SageMaker Autopilot визначив наш набір даних як проблему бінарної класифікації, SageMaker Autopilot прагнув максимізувати Показник якості F1 знайти найкращу модель. SageMaker Autopilot вибирає це за замовчуванням. Однак існує можливість вибору інших об’єктивних показників, таких як точність і AUC. Оцінка F1 нашої моделі становить 0.61. Щоб інтерпретувати оцінку F1, спочатку потрібно зрозуміти матрицю плутанини, яка пояснюється у звіті про якість моделі у виведеному PDF-файлі.
Матриця плутанини
Матриця плутанини допомагає візуалізувати продуктивність моделі шляхом порівняння різних класів і міток. Експеримент SageMaker Autopilot створив матрицю плутанини, яка показує фактичні мітки як рядки, а попередні мітки як стовпці у звіті про якість моделі. У верхньому лівому кутку показано клієнтів, які не відкривали рахунок у банку, які правильно передбачила модель як «ні». Це справжні негативи (TN). У правому нижньому полі показані клієнти, які відкрили рахунок у банку, і модель правильно передбачила «так». Це справжні позитиви (TP).

У нижньому лівому куті показано кількість помилкові негативи (FN). Модель передбачила, що клієнт не відкриє рахунок, але клієнт відкрив. У верхньому правому куті показано кількість помилкові позитиви (FP). Модель передбачила, що клієнт відкриє рахунок, але клієнт це зробив НЕ насправді так і зробіть.
Показники звіту про якість моделі
Звіт про якість моделі пояснює, як розрахувати частота помилкових позитивних результатів (FPR) і справжній позитивний показник (TPR).
Частота відкликань або помилкових позитивних результатів (FPR) вимірює частку фактичних негативів, які були помилково передбачені як відкриття рахунку (позитиви). Діапазон становить від 0 до 1, і менше значення вказує на кращу точність прогнозування.

Зауважте, що FPR також виражається як 1-Specificity, де Specificity або True Negative Rate (TNR) — це частка TN, правильно ідентифікованих як такі, що не відкривають рахунок (негативні).

Запам'ятовування/Чутливість/Справжній позитивний рівень (TPR) вимірює частку фактичних позитивних результатів, які були передбачені як відкриття рахунку. Діапазон також становить від 0 до 1, і більше значення вказує на кращу точність прогнозування. Це також відоме як запам'ятовування/чутливість. Ця міра виражає здатність знаходити всі відповідні екземпляри в наборі даних.
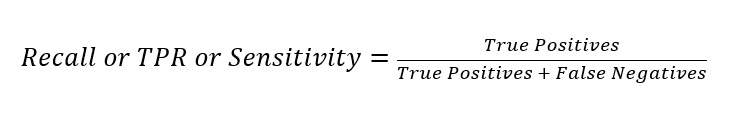
Точність вимірює частку фактичних позитивних результатів, які були прогнозовані як позитивні, серед усіх прогнозованих як позитивні. Діапазон становить від 0 до 1, і більше значення вказує на кращу точність. Точність виражає частку точок даних, які наша модель вважає релевантними, і які насправді є релевантними. Точність є хорошим показником, який слід враховувати, особливо коли витрати на FP високі, наприклад, під час виявлення електронного спаму.

Наша модель показує точність 0.53 і відкликання 0.72.
Оцінка F1 демонструє нашу цільову метрику, яка є гармонійним середнім значенням точності та запам’ятовування. Оскільки наш набір даних незбалансований на користь багатьох прогнозів «ні», F1 враховує як FP, так і FN, щоб надати однакову вагу точності та запам’ятовуванню.
У звіті пояснюється, як інтерпретувати ці показники. Це може допомогти, якщо ви не знайомі з цими термінами. У нашому прикладі точність і запам’ятовування є важливими показниками для задачі двійкової класифікації, оскільки вони використовуються для обчислення оцінки F1. У звіті пояснюється, що оцінка F1 може варіюватися від 0 до 1. Найкраща можлива продуктивність буде оцінюватися в 1, тоді як 0 вказуватиме на найгіршу. Пам’ятайте, що показник F1 нашої моделі становить 0.61.

Оцінка Fβ це зважене гармонічне середнє значення точності та відкликання. Крім того, показник F1 такий самий, як Fβ з β=1. У звіті наводиться оцінка Fβ класифікатора, де β приймає 0.5, 1 і 2.

Таблиця показників
Залежно від проблеми ви можете виявити, що SageMaker Autopilot максимізує іншу метрику, наприклад точність, для проблеми класифікації кількох класів. Незалежно від типу проблеми, звіти про якість моделі створюють таблицю, яка підсумовує показники вашої моделі, доступні як у вбудованому звіті, так і у звіті PDF. Ви можете дізнатися більше про метричну таблицю в документація.

Найкращий постійний класифікатор – класифікатор, який служить простою базовою лінією для порівняння з іншими більш складними класифікаторами – завжди передбачає мітку постійної більшості, яку надає користувач. У нашому випадку «константна» модель передбачає «ні», оскільки це найпоширеніший клас і вважається негативною міткою. Метрики для навчених моделей класифікаторів (таких як f1, f2 або відкликання) можна порівняти з показниками для постійного класифікатора, тобто базової лінії. Це гарантує, що навчена модель працює краще, ніж постійний класифікатор. Показники Fβ (f0_5, f1 і f2, де β приймає значення 0.5, 1 і 2 відповідно) є зваженим гармонічним середнім значенням точності та запам’ятовування. Це досягає свого оптимального значення при 1 і найгіршого значення при 0.
У нашому випадку найкращий постійний класифікатор завжди передбачає «ні». Таким чином, точність є високою — 0.89, але показники запам’ятовування, точності та Fβ дорівнюють 0. Якщо набір даних ідеально збалансований, де немає жодного класу більшості чи меншості, ми побачили б набагато цікавіші можливості для точності, запам’ятовування, і Fβ оцінки постійного класифікатора.
Крім того, ви можете переглянути ці результати у форматі JSON, як показано в наступному прикладі. Ви можете отримати доступ як до файлів PDF, так і до JSON через інтерфейс користувача, а також SDK для Amazon SageMaker Python використовуючи елемент S3OutputPath OutputDataConfig структуру в Створити AutoMLJob/Опишіть AutoMLJob Відповідь API.
{ "version" : 0.0, "dataset" : { "item_count" : 9152, "evaluation_time" : "2022-03-16T20:49:18.661Z" }, "binary_classification_metrics" : { "confusion_matrix" : { "no" : { "no" : 7468, "yes" : 648 }, "yes" : { "no" : 295, "yes" : 741 } }, "recall" : { "value" : 0.7152509652509652, "standard_deviation" : 0.00439996600081394 }, "precision" : { "value" : 0.5334773218142549, "standard_deviation" : 0.007335840278445563 }, "accuracy" : { "value" : 0.8969624125874126, "standard_deviation" : 0.0011703516093899595 }, "recall_best_constant_classifier" : { "value" : 0.0, "standard_deviation" : 0.0 }, "precision_best_constant_classifier" : { "value" : 0.0, "standard_deviation" : 0.0 }, "accuracy_best_constant_classifier" : { "value" : 0.8868006993006993, "standard_deviation" : 0.0016707401772078998 }, "true_positive_rate" : { "value" : 0.7152509652509652, "standard_deviation" : 0.00439996600081394 }, "true_negative_rate" : { "value" : 0.9201577131591917, "standard_deviation" : 0.0010233756436643213 }, "false_positive_rate" : { "value" : 0.07984228684080828, "standard_deviation" : 0.0010233756436643403 }, "false_negative_rate" : { "value" : 0.2847490347490348, "standard_deviation" : 0.004399966000813983 },
………………….
ROC і AUC
Залежно від типу проблеми у вас можуть бути різні порогові значення для того, що прийнятно як FPR. Наприклад, якщо ви намагаєтеся передбачити, чи відкриє клієнт обліковий запис, для компанії може бути більш прийнятним мати вищу ставку FP. Може бути ризикованішим пропустити надання пропозицій клієнтам, яким неправильно передбачили «ні», на відміну від пропозиції клієнтів, яким неправильно передбачили «так». Зміна цих порогових значень для створення різних FPR вимагає від вас створення нових матриць плутанини.
Алгоритми класифікації повертають безперервні значення, відомі як ймовірності передбачення. Ці ймовірності повинні бути перетворені в двійкове значення (для двійкової класифікації). У задачах бінарної класифікації поріг (або поріг прийняття рішення) — це значення, яке дихотомізує ймовірності до простого двійкового рішення. Для нормалізованих прогнозованих ймовірностей у діапазоні від 0 до 1 порогове значення встановлено на 0.5 за замовчуванням.
Для моделей двійкової класифікації корисним показником оцінки є площа під кривою робочих характеристик приймача (ROC). Звіт про якість моделі включає графік ROC зі швидкістю TP на осі Y і FPR на осі X. Площа під робочою характеристикою приймача (AUC-ROC) представляє компроміс між TPR і FPR.
Ви створюєте криву ROC, беручи двійковий предиктор класифікації, який використовує порогове значення, і призначаючи мітки з ймовірностями передбачення. Коли ви змінюєте поріг для моделі, ви охоплюєте дві крайнощі. Коли TPR і FPR дорівнюють 0, це означає, що все позначено «ні», а коли і TPR, і FPR дорівнюють 1, це означає, що все позначено «так».
Випадковий предиктор, який позначає «Так» половину часу та «Ні» іншу половину часу, матиме ROC, який є прямою діагональну лінію (червона пунктирна лінія). Ця лінія розрізає одиничний квадрат на два трикутники однакового розміру. Отже, площа під кривою дорівнює 0.5. Значення AUC-ROC, що дорівнює 0.5, означало б, що ваш предиктор був не кращим у розрізненні двох класів, ніж випадкове вгадування, відкриє клієнт рахунок чи ні. Чим ближче значення AUC-ROC до 1.0, тим кращі його прогнози. Значення нижче 0.5 вказує на те, що ми могли б змусити нашу модель створювати кращі прогнози, змінивши відповідь, яку вона нам дає. Для нашої найкращої моделі AUC становить 0.93.

Крива точного відкликання
Звіт про якість моделі також створив криву точного запам’ятовування (PR), щоб побудувати точність (вісь y) і запам’ятовування (вісь x) для різних порогових значень – подібно до кривої ROC. Криві PR, які часто використовуються в інформаційному пошуку, є альтернативою кривим ROC для проблем класифікації з великим перекосом у розподілі класів.
Для цих класів незбалансованих наборів даних криві PR стають особливо корисними, коли позитивний клас меншості цікавіший за негативний клас більшості. Пам’ятайте, що наша модель демонструє точність 0.53 і відкликання 0.72. Крім того, пам’ятайте, що найкращий класифікатор констант не може розрізняти «так» і «ні». Це передбачало б випадковий клас або постійний клас кожного разу.
Крива для збалансованого набору даних між «так» і «ні» буде горизонтальною лінією на 0.5, і, таким чином, матиме площу під кривою PR (AUPRC) як 0.5. Щоб створити PRC, ми будуємо різні моделі на кривій із різними пороговими значеннями, так само, як і для кривої ROC. За нашими даними AUPRC становить 0.61.

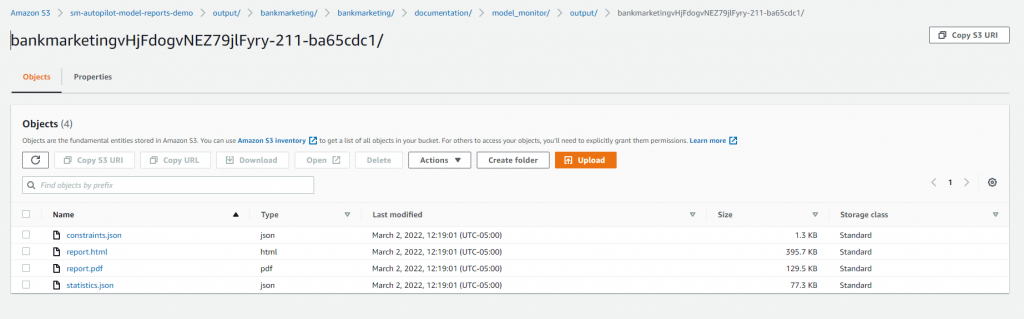
Вихід звіту про якість моделі
Ви можете знайти звіт про якість моделі в сегменті Amazon S3, який ви вказали під час визначення вихідного шляху перед запуском експерименту SageMaker AutoPilot. Ви знайдете звіти під documentation/model_monitor/output/<autopilot model name>/ prefix збережено як PDF.
Висновок
Звіти про якість моделі SageMaker Autopilot дозволяють швидко переглянути результати експерименту SageMaker Autopilot і поділитися ними. Ви можете легко завершити навчання та налаштування моделі за допомогою SageMaker Autopilot, а потім посилатися на створені звіти для інтерпретації результатів. Незалежно від того, чи скористаєтеся ви найкращою моделлю SageMaker Autopilot, чи іншою кандидатурою, ці результати можуть стати корисною відправною точкою для оцінки попереднього навчання та налаштування моделі. Звіти про якість моделі автопілота SageMaker допомагають скоротити час, необхідний для написання коду та створення візуальних елементів для оцінки продуктивності та порівняння.
Ви можете легко включити autoML у свої бізнес-кейси сьогодні без необхідності створювати команду з обробки даних. SageMaker документація надає численні зразки, які допоможуть вам розпочати роботу.
Про авторів
 Пітер Чанг є архітектором рішень для AWS і прагне допомогти клієнтам розкрити інформацію на основі їхніх даних. Він розробляє рішення, щоб допомогти організаціям приймати рішення на основі даних як у державному, так і в приватному секторах. Він має всі сертифікати AWS, а також два сертифікати GCP. Він любить каву, готує, веде активну діяльність і проводить час із сім’єю.
Пітер Чанг є архітектором рішень для AWS і прагне допомогти клієнтам розкрити інформацію на основі їхніх даних. Він розробляє рішення, щоб допомогти організаціям приймати рішення на основі даних як у державному, так і в приватному секторах. Він має всі сертифікати AWS, а також два сертифікати GCP. Він любить каву, готує, веде активну діяльність і проводить час із сім’єю.
 Арунпрасат Шанкар є архітектором спеціалізованих рішень із штучного інтелекту та машинного навчання (AI / ML) з AWS, допомагаючи світовим клієнтам ефективно та ефективно масштабувати свої рішення в галузі ШІ в хмарі. У вільний час Арун із задоволенням дивиться науково-фантастичні фільми та слухає класичну музику.
Арунпрасат Шанкар є архітектором спеціалізованих рішень із штучного інтелекту та машинного навчання (AI / ML) з AWS, допомагаючи світовим клієнтам ефективно та ефективно масштабувати свої рішення в галузі ШІ в хмарі. У вільний час Арун із задоволенням дивиться науково-фантастичні фільми та слухає класичну музику.
 Алі Такбірі є спеціалістом з AI/ML, архітектором рішень і допомагає клієнтам за допомогою машинного навчання вирішувати їхні бізнес-задачі в хмарі AWS.
Алі Такбірі є спеціалістом з AI/ML, архітектором рішень і допомагає клієнтам за допомогою машинного навчання вирішувати їхні бізнес-задачі в хмарі AWS.
 Прадіп Редді є старшим менеджером з продуктів у команді SageMaker Low/No Code ML, яка включає автопілот SageMaker, автоматичний тюнер моделі SageMaker. Поза роботою Прадіп любить читати, бігати та гуляти з комп’ютерами розміром з долоню, такими як raspberry pi, та іншими технологіями домашньої автоматизації.
Прадіп Редді є старшим менеджером з продуктів у команді SageMaker Low/No Code ML, яка включає автопілот SageMaker, автоматичний тюнер моделі SageMaker. Поза роботою Прадіп любить читати, бігати та гуляти з комп’ютерами розміром з долоню, такими як raspberry pi, та іншими технологіями домашньої автоматизації.
- Coinsmart. Найкраща в Європі біржа біткойн та криптовалют.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. БЕЗКОШТОВНИЙ ДОСТУП.
- CryptoHawk. Альткойн Радар. Безкоштовне випробування.
- Джерело: https://aws.amazon.com/blogs/machine-learning/automatically-generate-model-evaluation-metrics-using-sagemaker-autopilot-model-quality-reports/
- "
- 100
- 7
- МЕНЮ
- доступ
- рахунки
- активний
- просунутий
- AI
- алгоритми
- ВСІ
- Amazon
- серед
- Інший
- API
- ПЛОЩА
- штучний
- штучний інтелект
- Штучний інтелект і машинне навчання
- Атрибути
- Автоматизація
- доступний
- AWS
- Банк
- Базова лінія
- ставати
- КРАЩЕ
- border
- Box
- будувати
- Створюємо
- бізнес
- випадків
- проблеми
- Вибирати
- клас
- класів
- класифікація
- ближче
- хмара
- код
- кави
- Колонка
- порівняний
- комплекс
- комп'ютери
- замішання
- містить
- витрати
- може
- створений
- створення
- крива
- Клієнти
- дані
- наука про дані
- набір даних
- демонструвати
- розгортання
- розгортання
- Виявлення
- DID
- різний
- безпосередньо
- розподіл
- легко
- Кінцева точка
- Машинобудування
- особливо
- все
- приклад
- експеримент
- сім'я
- особливість
- в кінці кінців
- знахідки
- Перший
- Гнучкість
- Сфокусувати
- після
- формат
- породжувати
- Глобальний
- добре
- має
- допомога
- корисний
- допомагає
- Високий
- вище
- тримає
- Головна
- Головна Автоматизація
- Як
- How To
- HTTPS
- ICON
- Особистість
- важливо
- включати
- інформація
- розуміння
- Інтелект
- IT
- робота
- відомий
- етикетки
- великий
- більше
- УЧИТЬСЯ
- вивчення
- Важіль
- Лінія
- Прослуховування
- розташування
- машина
- навчання за допомогою машини
- Більшість
- РОБОТИ
- управління
- менеджер
- Маркетинг
- Матриця
- вимір
- Метрика
- меншість
- ML
- модель
- Моделі
- більше
- найбільш
- кіно
- музика
- номер
- численний
- пропонує
- Пропозиції
- відкрити
- відкриття
- операційний
- Опції
- організації
- Інше
- пристрасний
- продуктивність
- точка
- позитивний
- можливостей
- це можливо
- потенціал
- передбачати
- прогноз
- Прогнози
- представити
- приватний
- Проблема
- проблеми
- виробляти
- Product
- Production
- забезпечувати
- забезпечує
- громадськість
- якість
- швидко
- діапазон
- читання
- зменшити
- доречний
- звітом
- Звіти
- представляє
- ресурси
- відповідь
- результати
- біг
- шкала
- наука
- Сектори
- комплект
- Поділитись
- простий
- So
- Рішення
- ВИРІШИТИ
- спам
- Витрати
- площа
- почалася
- Статус
- зберігання
- студія
- Мета
- команда
- технології
- через
- час
- сьогодні
- TPR
- Навчання
- поїзда
- ui
- розкрити
- розуміти
- us
- використання
- значення
- різний
- вид
- видимість
- Чи
- ВООЗ
- без
- Work
- б