Amazon SageMaker це повністю керована служба машинного навчання (ML). За допомогою SageMaker науковці та розробники даних можуть швидко та легко створювати та навчати моделі ML, а потім безпосередньо розгортати їх у готовому до виробництва середовищі. Він надає інтегрований екземпляр блокнота Jupyter для створення легкого доступу до ваших джерел даних для дослідження й аналізу, тож вам не потрібно керувати серверами. Він також забезпечує загальні Алгоритми ML які оптимізовані для ефективної роботи з надзвичайно великими даними в розподіленому середовищі.
Висновок у реальному часі SageMaker ідеально підходить для робочих навантажень, які мають вимоги до інтерактивності в режимі реального часу та малої затримки. За допомогою висновків SageMaker у реальному часі ви можете розгортати кінцеві точки REST, які підтримуються певним типом екземпляра з певним обсягом обчислень і пам’яті. Розгортання кінцевої точки реального часу SageMaker є лише першим кроком на шляху до виробництва для багатьох клієнтів. Ми хочемо мати можливість максимізувати продуктивність кінцевої точки для досягнення цільової кількості транзакцій за секунду (TPS), дотримуючись вимог щодо затримки. Значна частина оптимізації продуктивності для висновків полягає в тому, щоб переконатися, що ви вибрали правильний тип екземпляра та підрахували кінцеву точку.
У цьому дописі описано найкращі методи навантажувального тестування кінцевої точки SageMaker, щоб знайти правильну конфігурацію для кількості екземплярів і розміру. Це може допомогти нам зрозуміти мінімальні вимоги до інсталяції, щоб відповідати нашим вимогам щодо затримки та TPS. Після цього ми заглибимося в те, як ви можете відстежувати та розуміти показники та продуктивність кінцевої точки SageMaker за допомогою Amazon CloudWatch метрики.
Спочатку ми перевіряємо продуктивність нашої моделі на одному екземплярі, щоб визначити TPS, який вона може обробляти відповідно до наших прийнятних вимог до затримки. Потім ми екстраполюємо результати, щоб визначити кількість екземплярів, які нам потрібні для обробки нашого робочого трафіку. Нарешті, ми моделюємо трафік на виробничому рівні та налаштовуємо тести навантаження для кінцевої точки SageMaker у реальному часі, щоб підтвердити, що наша кінцева точка може впоратися з навантаженням на виробничому рівні. Нижче наведено повний набір коду для прикладу GitHub сховище.
Огляд рішення
Для цієї посади ми розгортаємо попередньо навчених Hugging Face Модель DistilBERT від Hugging Face Hub. Ця модель може виконувати низку завдань, але ми надсилаємо корисне навантаження спеціально для аналізу настроїв і класифікації тексту. З цим зразком корисного навантаження ми прагнемо досягти 1000 TPS.
Розгорніть кінцеву точку в реальному часі
Ця публікація передбачає, що ви знайомі з тим, як розгорнути модель. Звертатися до Створіть кінцеву точку та розгорніть свою модель щоб зрозуміти внутрішні особливості розміщення кінцевої точки. Наразі ми можемо швидко вказати на цю модель у Hugging Face Hub і розгорнути кінцеву точку в реальному часі за допомогою наступного фрагмента коду:
Давайте швидко протестуємо нашу кінцеву точку за допомогою зразка корисного навантаження, яке ми хочемо використовувати для навантажувального тестування:

Зверніть увагу, що ми підтримуємо кінцеву точку за допомогою єдиного Обчислювальна хмара Amazon Elastic (Amazon EC2) екземпляр типу ml.m5.12xlarge, який містить 48 vCPU і 192 ГіБ пам’яті. Кількість vCPU є хорошим показником паралельності, яку може обробляти примірник. Загалом, рекомендується тестувати різні типи екземплярів, щоб переконатися, що ми маємо екземпляр із ресурсами, які використовуються належним чином. Щоб переглянути повний список екземплярів SageMaker і їх відповідну обчислювальну потужність для логічного висновку в реальному часі, зверніться до Ціни на Amazon SageMaker.
Показники для відстеження
Перш ніж ми зможемо приступити до навантажувального тестування, важливо зрозуміти, які показники слід відстежувати, щоб зрозуміти розбивку продуктивності кінцевої точки SageMaker. CloudWatch — це основний інструмент реєстрації, який використовує SageMaker, щоб допомогти вам зрозуміти різні показники, які описують продуктивність кінцевої точки. Ви можете використовувати журнали CloudWatch для налагодження викликів кінцевої точки; тут записуються всі оператори реєстрації та друку, які є у вашому коді висновку. Для отримання додаткової інформації див Як працює Amazon CloudWatch.
Існує два різних типи показників CloudWatch для SageMaker: показники рівня екземпляра та показники виклику.
Показники на рівні екземпляра
Перший набір параметрів, який слід розглянути, — це показники рівня екземпляра: CPUUtilization та MemoryUtilization (для екземплярів на основі GPU, GPUUtilization). Для CPUUtilization, спочатку в CloudWatch ви можете побачити відсотки вище 100%. Це важливо усвідомлювати для CPUUtilization, відображається сума всіх ядер ЦП. Наприклад, якщо екземпляр за вашою кінцевою точкою містить 4 vCPU, це означає, що діапазон використання становить до 400%. MemoryUtilization, з іншого боку, знаходиться в діапазоні 0–100%.
Зокрема, ви можете використовувати CPUUtilization щоб глибше зрозуміти, чи є у вас достатня або навіть надлишкова кількість обладнання. Якщо у вас є екземпляр, який використовується недостатньо (менше 30%), ви потенційно можете зменшити тип свого екземпляра. І навпаки, якщо ви використовуєте приблизно 80–90%, було б корисно вибрати екземпляр із більшою обчислювальною системою/пам’яттю. Згідно з нашими тестами, ми пропонуємо приблизно 60–70% використання вашого обладнання.
Метрики виклику
Як випливає з назви, метрики викликів – це те, де ми можемо відстежувати наскрізну затримку будь-яких викликів до вашої кінцевої точки. Ви можете використовувати показники виклику, щоб фіксувати кількість помилок і типи помилок (5xx, 4xx тощо), з якими може стикатися ваша кінцева точка. Що ще важливіше, ви можете зрозуміти розбивку затримки викликів вашої кінцевої точки. Багато з цього можна зафіксувати ModelLatency та OverheadLatency метрики, як показано на наступній діаграмі.

Команда ModelLatency метрика фіксує час, який займає логічний висновок у контейнері моделі за кінцевою точкою SageMaker. Зверніть увагу, що контейнер моделі також містить будь-який настроюваний код висновку або сценарії, які ви передали для висновку. Ця одиниця фіксується в мікросекундах як метрика виклику, і, як правило, ви можете побудувати графік процентиля для CloudWatch (p99, p90 і так далі), щоб побачити, чи ви досягаєте цільової затримки. Зауважте, що кілька факторів можуть впливати на затримку моделі та контейнера, наприклад:
- Спеціальний сценарій висновку – Незалежно від того, чи реалізовано ви власний контейнер, чи використовуєте контейнер на основі SageMaker із спеціальними обробниками висновків, найкраще профілювати свій сценарій, щоб уловлювати будь-які операції, які конкретно додають багато часу до вашої затримки.
- Протокол зв'язку – Розглянемо підключення REST проти gRPC до сервера моделі в контейнері моделі.
- Оптимізація каркаса моделі – Це специфічні рамки, наприклад з TensorFlow, є кілька змінних середовища, які можна налаштувати, які стосуються обслуговування TF. Обов’язково перевірте, який контейнер ви використовуєте, і чи є якісь специфічні для фреймворку оптимізації, які ви можете додати в сценарій або як змінні середовища для введення в контейнер.
OverheadLatency вимірюється з моменту отримання SageMaker запиту до повернення відповіді клієнту мінус затримка моделі. Ця частина значною мірою знаходиться поза вашим контролем і підпадає під час, який витрачається SageMaker.
Наскрізна затримка в цілому залежить від низки факторів і не обов’язково є сумою ModelLatency плюс OverheadLatency. Наприклад, якщо ваш клієнт робить InvokeEndpoint Виклик API через Інтернет, з точки зору клієнта, наскрізна затримка становитиме Інтернет + ModelLatency + OverheadLatency. Таким чином, під час навантажувального тестування вашої кінцевої точки, щоб точно порівняти саму кінцеву точку, рекомендується зосередитися на показниках кінцевої точки (ModelLatency, OverheadLatency та InvocationsPerInstance), щоб точно порівняти кінцеву точку SageMaker. Тоді будь-які проблеми, пов’язані з наскрізною затримкою, можна виділити окремо.
Кілька запитань щодо наскрізної затримки:
- Де клієнт, який викликає вашу кінцеву точку?
- Чи існують проміжні рівні між вашим клієнтом і середовищем виконання SageMaker?
Автоматичне масштабування
У цій публікації ми не розглядаємо автоматичне масштабування, але це важливий момент, щоб забезпечити правильну кількість екземплярів відповідно до робочого навантаження. Залежно від моделей трафіку ви можете прикріпити політика автоматичного масштабування до кінцевої точки SageMaker. Існують різні варіанти масштабування, наприклад TargetTrackingScaling, SimpleScaling та StepScaling. Це дозволяє вашій кінцевій точці автоматично масштабуватись і зменшувати залежно від моделі трафіку.
Поширеним варіантом є цільове відстеження, де ви можете вказати метрику CloudWatch або спеціальну метрику, яку ви визначили, і масштабувати її на основі цього. Частим використанням автоматичного масштабування є відстеження InvocationsPerInstance метрика. Визначивши вузьке місце на певному TPS, ви часто можете використовувати це як показник для масштабування до більшої кількості екземплярів, щоб мати можливість обробляти пікове навантаження трафіку. Щоб отримати детальнішу інформацію про автоматичне масштабування кінцевих точок SageMaker, див Налаштування кінцевих точок висновку автомасштабування в Amazon SageMaker.
Тестування навантаженням
Незважаючи на те, що ми використовуємо Locust, щоб показати, як ми можемо завантажувати тест у масштабі, якщо ви намагаєтесь визначити правильний розмір екземпляра за кінцевою точкою, SageMaker Inference Recommender є більш ефективним варіантом. За допомогою інструментів навантажувального тестування сторонніх виробників вам доведеться вручну розгортати кінцеві точки в різних екземплярах. За допомогою Inference Recommender ви можете просто передати масив типів екземплярів, для яких ви хочете завантажити тест, і SageMaker запуститься роботи для кожного з цих випадків.
сарана
Для цього прикладу ми використовуємо сарана, інструмент тестування навантаження з відкритим кодом, який можна реалізувати за допомогою Python. Locust подібний до багатьох інших інструментів навантажувального тестування з відкритим вихідним кодом, але має кілька особливих переваг:
- простота установки – Як ми демонструємо в цій публікації, ми передамо простий сценарій Python, який можна легко змінити для вашої конкретної кінцевої точки та корисного навантаження.
- Розподілений і масштабований – Locust базується на подіях і використовує gevent під капотом. Це дуже корисно для тестування висококонкурентних робочих навантажень і імітації тисяч одночасних користувачів. Ви можете досягти високого TPS за допомогою одного процесу, запущеного Locust, але він також має розподілене генерування навантаження функція, яка дає змогу розширити до кількох процесів і клієнтських машин, як ми розглянемо в цій публікації.
- Показники та інтерфейс користувача Locust – Locust також фіксує наскрізну затримку як метрику. Це може допомогти доповнити ваші показники CloudWatch, щоб скласти повну картину ваших тестів. Усе це фіксується в інтерфейсі користувача Locust, де ви можете відстежувати одночасних користувачів, працівників тощо.
Щоб краще зрозуміти Locust, перегляньте їх документація.
Налаштування Amazon EC2
Ви можете налаштувати Locust у будь-якому сумісному середовищі. Для цієї публікації ми створили екземпляр EC2 і встановили там Locust для проведення наших тестів. Ми використовуємо примірник c5.18xlarge EC2. Також слід враховувати обчислювальну потужність на стороні клієнта. Іноді, коли у вас закінчується обчислювальна потужність на стороні клієнта, це часто не фіксується та помилково сприймається як помилка кінцевої точки SageMaker. Важливо розмістити клієнта в місці з достатньою обчислювальною потужністю, яке може впоратися з навантаженням, яке ви тестуєте. Для нашого екземпляра EC2 ми використовуємо Ubuntu Deep Learning AMI, але ви можете використовувати будь-який AMI, якщо ви можете правильно налаштувати Locust на машині. Щоб зрозуміти, як запустити екземпляр EC2 і підключитися до нього, перегляньте посібник Почніть роботу з примірниками Amazon EC2 Linux.
Інтерфейс користувача Locust доступний через порт 8089. Ми можемо відкрити його, налаштувавши наші правила групи безпеки вхідного потоку для екземпляра EC2. Ми також відкриваємо порт 22, щоб мати змогу підключитися до екземпляра EC2 через SSH. Подумайте про обмеження джерела до конкретної IP-адреси, з якої ви отримуєте доступ до примірника EC2.

Після підключення до екземпляра EC2 ми налаштовуємо віртуальне середовище Python і встановлюємо Locust API з відкритим кодом через CLI:
Тепер ми готові працювати з Locust для навантажувального тестування нашої кінцевої точки.
Випробування на сарану
Усі тести на навантаження Locust проводяться на основі a Файл сарани які ви надаєте. Цей файл Locust визначає завдання для тесту навантаження; тут ми визначаємо наш Boto3 виклик API invoke_endpoint. Дивіться наступний код:
У попередньому коді налаштуйте параметри виклику кінцевої точки виклику відповідно до конкретної моделі виклику. Ми використовуємо InvokeEndpoint API, що використовує наступний фрагмент коду у файлі Locust; це наша точка запуску тесту навантаження. Файл Locust, який ми використовуємо locust_script.py.
Тепер, коли у нас є готовий сценарій Locust, ми хочемо запустити розподілені тести Locust для стрес-тестування нашого єдиного екземпляра, щоб дізнатися, який обсяг трафіку може обробляти наш екземпляр.
Розподілений режим Locust має трохи більше нюансів, ніж однопроцесний тест Locust. У розподіленому режимі у нас є один основний і кілька робітників. Основний робочий файл інструктує робочих, як створювати та контролювати одночасних користувачів, які надсилають запит. В нашому пошир.ш сценарію ми бачимо, що за замовчуванням 240 користувачів буде розподілено між 60 працівниками. Зверніть увагу, що --headless прапорець у Locust CLI видаляє функцію інтерфейсу користувача Locust.
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
Спочатку ми запускаємо розподілений тест на одному екземплярі, що підтримує кінцеву точку. Ідея полягає в тому, що ми хочемо повністю максимізувати один екземпляр, щоб зрозуміти кількість екземплярів, потрібну для досягнення нашої цільової TPS, залишаючись у межах наших вимог до затримки. Зверніть увагу: якщо ви хочете отримати доступ до інтерфейсу користувача, змініть Locust_UI для змінної середовища значення True і прийняти загальнодоступну IP-адресу вашого екземпляра EC2 і зіставити порт 8089 з URL-адресою.
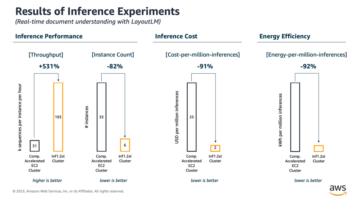
На наступному знімку екрана показано наші показники CloudWatch.

Зрештою ми помічаємо, що хоча спочатку ми досягаємо TPS 200, ми починаємо помічати помилки 5xx у наших клієнтських журналах EC2, як показано на наступному знімку екрана.
Ми також можемо перевірити це, переглянувши наші показники на рівні екземпляра, зокрема CPUUtilization.
 Тут ми помічаємо
Тут ми помічаємо CPUUtilization майже на 4,800%. Наш екземпляр ml.m5.12x.large має 48 vCPU (48 * 100 = 4800~). Це насичує весь екземпляр, що також допомагає пояснити наші помилки 5xx. Ми також бачимо збільшення ModelLatency.
Схоже, що наш єдиний екземпляр руйнується і не має обчислювальних ресурсів, щоб підтримувати навантаження понад 200 TPS, які ми спостерігаємо. Наша цільова кількість TPS становить 1000, тому давайте спробуємо збільшити кількість екземплярів до 5. Це може бути ще більше у робочих умовах, оскільки ми спостерігали помилки при 200 TPS після певного моменту.

Ми бачимо в журналах інтерфейсу користувача Locust і CloudWatch, що TPS становить майже 1000 із п’ятьма примірниками, які підтримують кінцеву точку.

 Якщо ви починаєте відчувати помилки навіть із таким налаштуванням апаратного забезпечення, обов’язково відстежуйте
Якщо ви починаєте відчувати помилки навіть із таким налаштуванням апаратного забезпечення, обов’язково відстежуйте CPUUtilization щоб зрозуміти повну картину вашого хостингу кінцевої точки. Дуже важливо розуміти, як використовується ваше апаратне забезпечення, щоб зрозуміти, чи потрібно вам збільшити чи навіть зменшити масштаб. Іноді проблеми на рівні контейнера призводять до помилок 5xx, але якщо CPUUtilization низький, це вказує на те, що причиною цих проблем може бути не ваше обладнання, а щось на рівні контейнера чи моделі (наприклад, не встановлена належна змінна середовища для кількості працівників). З іншого боку, якщо ви помітили, що ваш екземпляр повністю насичений, це означає, що вам потрібно або збільшити поточний парк екземплярів, або спробувати більший екземпляр із меншим парком.
Хоча ми збільшили кількість екземплярів до 5 для обробки 100 TPS, ми бачимо, що ModelLatency показник все ще високий. Це пов’язано з насиченістю екземплярів. Загалом ми пропонуємо використовувати ресурси інстанції на 60–70%.
Прибирати
Після навантажувального тестування обов’язково очистіть усі ресурси, які ви не використовуватимете, через консоль SageMaker або через delete_endpoint Виклик Boto3 API. Крім того, переконайтеся, що ви зупинили свій екземпляр EC2 або будь-яке інше налаштування клієнта, щоб не стягувати жодних додаткових витрат.
Підсумки
У цій публікації ми описали, як можна навантажувати тестування кінцевої точки SageMaker у реальному часі. Ми також обговорили, які показники слід оцінювати під час навантажувального тестування кінцевої точки, щоб зрозуміти розподіл продуктивності. Обов'язково перевірте SageMaker Inference Recommender для подальшого розуміння правильного розміру екземпляра та інших методів оптимізації продуктивності.
Про авторів
 Марк Карп є архітектором ML у команді SageMaker Service. Він зосереджується на допомозі клієнтам проектувати, розгортати та керувати робочими навантаженнями ML у масштабі. У вільний час він любить подорожувати та досліджувати нові місця.
Марк Карп є архітектором ML у команді SageMaker Service. Він зосереджується на допомозі клієнтам проектувати, розгортати та керувати робочими навантаженнями ML у масштабі. У вільний час він любить подорожувати та досліджувати нові місця.
 Рам Вегіражу є архітектором ML у команді SageMaker Service. Він зосереджується на допомозі клієнтам створювати й оптимізувати свої рішення AI/ML на Amazon SageMaker. У вільний час любить подорожувати та писати.
Рам Вегіражу є архітектором ML у команді SageMaker Service. Він зосереджується на допомозі клієнтам створювати й оптимізувати свої рішення AI/ML на Amazon SageMaker. У вільний час любить подорожувати та писати.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- Здатний
- вище
- прийнятний
- доступ
- доступною
- доступ до
- точно
- Achieve
- через
- доповнення
- адреса
- після
- проти
- AI / ML
- прицілювання
- ВСІ
- дозволяє
- хоча
- Amazon
- Amazon EC2
- Amazon SageMaker
- кількість
- аналіз
- та
- API
- навколо
- масив
- приєднувати
- авторство
- автоматичний
- автоматично
- доступний
- AWS
- назад
- підтриманий
- підтримка
- заснований
- оскільки
- за
- буття
- еталонний тест
- користь
- Переваги
- КРАЩЕ
- передового досвіду
- між
- тіло
- Пробій
- будувати
- C + +
- call
- Виклики
- Може отримати
- захоплення
- захвати
- Залучайте
- певний
- зміна
- вантажі
- перевірка
- клас
- класифікація
- клієнт
- код
- загальний
- сумісний
- обчислення
- одночасно
- Проводити
- конфігурація
- підтвердити
- З'єднуватися
- підключений
- Зв'язки
- Вважати
- розгляду
- Консоль
- Контейнер
- містить
- контекст
- контроль
- Відповідний
- може
- обкладинка
- охоплює
- центральний процесор
- створювати
- вирішальне значення
- Поточний
- виготовлений на замовлення
- Клієнти
- дані
- глибокий
- глибоке навчання
- глибше
- дефолт
- Визначає
- демонструвати
- Залежно
- залежить
- розгортання
- розгортання
- описувати
- описаний
- дизайн
- розробників
- різний
- безпосередньо
- обговорювалися
- дисплей
- розподілений
- Ні
- Не знаю
- вниз
- кожен
- легко
- ефективний
- продуктивно
- або
- дозволяє
- кінець в кінець
- Кінцева точка
- Весь
- Навколишнє середовище
- помилка
- помилки
- істотний
- Ефір (ETH)
- Навіть
- приклад
- виняток
- виконувати
- зазнають
- Пояснювати
- дослідження
- дослідити
- Дослідження
- експорт
- надзвичайно
- Особа
- фактори
- Фолс
- знайомий
- особливість
- кілька
- філе
- в кінці кінців
- знайти
- Перший
- ФЛЕТ
- Сфокусувати
- фокусується
- після
- формат
- Рамки
- частий
- від
- Повний
- повністю
- далі
- Загальне
- в цілому
- отримати
- отримання
- добре
- графік
- великий
- Group
- Групи
- обробляти
- щасливий
- апаратні засоби
- допомога
- допомогу
- допомагає
- тут
- Високий
- дуже
- капот
- господар
- відбувся
- хостинг
- Як
- How To
- HTML
- HTTPS
- Концентратор
- ідея
- ідеальний
- ідентифікований
- ідентифікувати
- Impact
- здійснювати
- реалізовані
- імпорт
- важливо
- in
- includes
- Augmenter
- збільшений
- вказує
- індикація
- інформація
- спочатку
- встановлювати
- екземпляр
- інтегрований
- інтерактивний
- інтернет
- викликає
- IP
- IP-адреса
- ізольований
- питання
- IT
- сам
- json
- великий
- в значній мірі
- більше
- Затримка
- запуск
- шарів
- вести
- провідний
- вивчення
- рівень
- Linux
- список
- трохи
- загрузка
- вантажі
- розташування
- Довго
- шукати
- серія
- низький
- машина
- навчання за допомогою машини
- Машинки для перманенту
- зробити
- Робить
- управляти
- вдалося
- вручну
- багато
- карта
- Максимізувати
- засоби
- Зустрічатися
- засідання
- пам'ять
- метрика
- Метрика
- може бути
- мінімальний
- ML
- режим
- модель
- Моделі
- монітор
- більше
- більш ефективний
- множинний
- ім'я
- майже
- обов'язково
- Необхідність
- Нові
- ноутбук
- номер
- ONE
- відкрити
- з відкритим вихідним кодом
- операції
- оптимізація
- Оптимізувати
- оптимізований
- варіант
- Опції
- порядок
- Інше
- поза
- власний
- фарбувати
- параметри
- частина
- Пройшов
- Минуле
- шлях
- Викрійки
- моделі
- Peak
- виконувати
- продуктивність
- перспектива
- вибирати
- картина
- частина
- місце
- місця
- plato
- Інформація про дані Платона
- PlatoData
- плюс
- точка
- пошта
- потенційно
- влада
- практика
- практики
- Прогноз
- первинний
- друк
- проблеми
- процес
- процеси
- Production
- профіль
- правильний
- правильно
- забезпечувати
- забезпечує
- забезпечення
- громадськість
- Python
- питань
- швидко
- діапазон
- готовий
- реального часу
- реалізувати
- отримує
- рекомендований
- регіон
- пов'язаний
- запросити
- Вимога
- ресурси
- відповідь
- REST
- результат
- результати
- Умови повернення
- Правила
- прогін
- біг
- мудрець
- Висновок SageMaker
- шкала
- Масштабування
- Вчені
- Оцінка масштабу
- scripts
- другий
- безпеку
- Здається,
- SELF
- відправка
- настрій
- обслуговування
- виступаючої
- комплект
- установка
- налаштування
- установка
- кілька
- Повинен
- показаний
- Шоу
- підпис
- аналогічний
- простий
- просто
- один
- Розмір
- менше
- So
- Рішення
- що в сім'ї щось
- Source
- Джерела
- Ікра
- конкретний
- конкретно
- Спін
- standard
- старт
- почалася
- заяви
- Крок
- Як і раніше
- Стоп
- стрес
- прагнути
- такі
- достатній
- костюм
- Super
- доповнювати
- Приймати
- приймає
- Мета
- Завдання
- завдання
- команда
- методи
- тест
- Тестовий пробіг
- Тестування
- Тести
- Класифікація тексту
- Команда
- Джерело
- їх
- третя сторона
- тисячі
- через
- час
- times
- до
- інструмент
- інструменти
- TPS
- трек
- Відстеження
- трафік
- поїзд
- Transactions
- Подорож
- правда
- підручник
- Типи
- Ubuntu
- ui
- при
- розуміти
- розуміння
- блок
- URL
- us
- використання
- користувачі
- використовувати
- використовувати
- використовує
- використовує
- різноманітність
- перевірити
- через
- Віртуальний
- Що
- Чи
- який
- в той час як
- волі
- в
- Work
- робочий
- робочі
- б
- лист
- вашу
- зефірнет