У цій публікації ми демонструємо Kubeflow на AWS (спеціальний дистрибутив Kubeflow для AWS) і переваги, які він додає порівняно з Kubeflow з відкритим вихідним кодом завдяки інтеграції високооптимізованих хмарних сервісів AWS, готових до роботи в корпоративному середовищі.
Kubeflow — це платформа машинного навчання (ML) з відкритим вихідним кодом, призначена для того, щоб зробити розгортання робочих процесів ML на Kubernetes простим, портативним і масштабованим. Kubeflow надає багато компонентів, у тому числі центральну інформаційну панель, багатокористувацькі блокноти Jupyter, Kubeflow Pipelines, KFServing і Katib, а також розподілених навчальних операторів для TensorFlow, PyTorch, MXNet і XGBoost, для створення простих, масштабованих і портативних робочих процесів МЛ. .
AWS нещодавно запустила Kubeflow v1.4 як частину власного дистрибутива Kubeflow (під назвою Kubeflow на AWS), який оптимізує завдання науки про дані та допомагає створювати високонадійні, безпечні, портативні та масштабовані системи машинного навчання зі зниженими операційними витратами завдяки інтеграції з керованими службами AWS. . Ви можете використовувати цей дистрибутив Kubeflow для створення систем машинного навчання поверх нього Послуга Amazon Elastic Kubernetes (Amazon EKS) для створення, навчання, налаштування та розгортання моделей ML для різноманітних випадків використання, включаючи комп’ютерне бачення, обробку природної мови, переклад мовлення та фінансове моделювання.
Проблеми з відкритим кодом Kubeflow
Коли ви використовуєте проект Kubeflow з відкритим вихідним кодом, він розгортає всі компоненти площини керування Kubeflow і площини даних на робочих вузлах Kubernetes. Служби компонентів Kubeflow розгортаються як частина площини керування Kubeflow, а всі розгортання ресурсів, пов’язані з Jupyter, навчанням моделі, налаштуванням і хостингом, розгортаються на площині даних Kubeflow. Площина керування Kubeflow і площина даних можуть працювати на одному або різних робочих вузлах Kubernetes. Ця публікація присвячена компонентам площини керування Kubeflow, як показано на наступній діаграмі.

Ця модель розгортання може не забезпечувати готовність для підприємства через такі причини:
- Усі важкі компоненти інфраструктури рівня керування Kubeflow, включаючи базу даних, сховище та автентифікацію, розгорнуті в самому робочому вузлі кластера Kubernetes. Це ускладнює реалізацію високодоступної архітектури плану керування Kubeflow із постійним станом у разі збою робочого вузла.
- Згенеровані артефакти Kubeflow (такі як екземпляри MySQL, журнали модулів або сховище MinIO) з часом зростають і потребують змінного розміру обсягів сховища з можливостями постійного моніторингу, щоб задовольнити зростаючий попит на сховище. Оскільки площина керування Kubeflow ділиться ресурсами з робочими навантаженнями площини даних Kubeflow (наприклад, для навчальних завдань, конвеєрів і розгортань), правильний розмір і масштабування кластерів і сховищ Kubernetes може стати складним завданням і призвести до збільшення операційних витрат.
- Kubernetes обмежує розмір файлу журналу, причому більшість установок зберігає останній ліміт у 10 МБ. За замовчуванням журнали модулів стають недоступними після досягнення цієї верхньої межі. Журнали також можуть стати недоступними, якщо модулі вилучено, аварійно завершено, видалено або заплановано на іншому вузлі, що може вплинути на доступність журналу програми та можливості моніторингу.
Kubeflow на AWS
Kubeflow на AWS надає чіткий шлях до використання Kubeflow із такими службами AWS:
- Балансувальник навантаження програми для безпечного керування зовнішнім трафіком через HTTPS
- Amazon CloudWatch для постійного керування журналами
- AWS Когніто для автентифікації користувача за допомогою безпеки транспортного рівня (TLS)
- Контейнери глибокого навчання AWS для високооптимізованих зображень сервера ноутбуків Jupyter
- Еластична файлова система Amazon (Amazon EFS) або Amazon FSx для Luster для простого, масштабованого та безсерверного рішення для зберігання файлів для підвищення ефективності навчання
- Amazon EKS для керованих кластерів Kubernetes
- Служба реляційних баз даних Amazon (Amazon RDS) для високомасштабованих конвеєрів і сховища метаданих
- Менеджер секретів AWS для захисту секретів, необхідних для доступу до ваших програм
- Служба простого зберігання Amazon (Amazon S3) для зручного сховища артефактів конвеєрів
Ці інтеграції служби AWS із Kubeflow (як показано на наступній схемі) дозволяють нам відокремити критичні частини площини керування Kubeflow від Kubernetes, забезпечуючи безпечну, масштабовану, стійку та економічно оптимізовану конструкцію.

Давайте обговоримо переваги інтеграції кожної служби та їхні рішення щодо безпеки, роботи конвеєрів ML і зберігання.
Безпечна автентифікація користувачів Kubeflow за допомогою Amazon Cognito
Хмарна безпека в AWS є найвищим пріоритетом, і ми інвестуємо в тісну інтеграцію безпеки Kubeflow безпосередньо в служби безпеки зі спільною відповідальністю AWS, як-от:
- Application Load Balancer (ALB) для керування зовнішнім трафіком
- Менеджер сертифікатів AWS (ACM) для підтримки TLS
- Ролі IAM для облікових записів служб (IRSA) для детального контролю доступу на рівні Kubernetes Pod
- Служба управління ключами AWS (AWS KMS) для керування ключами шифрування даних
- Щит AWS для захисту від DDoS
У цьому розділі ми зосередимося на інтеграції площини керування AWS Kubeflow із Amazon Cognito. Amazon Cognito усуває необхідність керувати та підтримувати рідне рішення Dex (провайдер OpenID Connect (OIDC) з відкритим кодом, що підтримується локальним LDAP) для автентифікації користувачів і полегшує керування секретами.
Ви також можете використовувати Amazon Cognito, щоб швидко й легко додати реєстрацію користувачів, вхід і контроль доступу до свого інтерфейсу Kubeflow. Amazon Cognito масштабується до мільйонів користувачів і підтримує вхід за допомогою постачальників соціальних ідентифікаторів (IdP), таких як Facebook, Google і Amazon, і корпоративних IdP через SAML 2.0. Це зменшує складність у вашому налаштуванні Kubeflow, роблячи його ефективним і простим у управлінні для досягнення ізоляції кількох користувачів.
Давайте розглянемо багатокористувацький потік автентифікації з інтеграціями Amazon Cognito, ALB і ACM із Kubeflow на AWS. Ця інтеграція включає низку ключових компонентів. Amazon Cognito налаштовано як IdP із зворотним викликом автентифікації, налаштованим для направлення запиту до Kubeflow після автентифікації користувача. У рамках налаштування Kubeflow створюється вхідний ресурс Kubernetes для керування зовнішнім трафіком до служби Istio Gateway. Контролер входу AWS ALB забезпечує балансування навантаження для цього входу. Ми використовуємо Амазонський маршрут 53 щоб налаштувати загальнодоступний DNS для зареєстрованого домену та створити сертифікати за допомогою ACM, щоб увімкнути автентифікацію TLS на балансирі навантаження.
На наступній діаграмі показано типовий робочий процес користувача під час входу в Amazon Cognito та перенаправлення до Kubeflow у відповідному просторі імен.

Робочий процес містить наступні кроки:
- Користувач надсилає запит HTTPS на центральну інформаційну панель Kubeflow, розміщену за балансувальником навантаження. Маршрут 53 перетворює FQDN на запис псевдоніма ALB.
- Якщо файл cookie відсутній, балансувальник навантаження перенаправляє користувача до кінцевої точки авторизації Amazon Cognito, щоб Amazon Cognito міг автентифікувати користувача.
- Після автентифікації користувача Amazon Cognito повертає користувача до балансувальника навантаження з кодом надання авторизації.
- Балансувальник навантаження представляє код надання авторизації кінцевій точці маркера Amazon Cognito.
- Отримавши дійсний код надання авторизації, Amazon Cognito надає маркер ідентифікатора та маркер доступу балансувальнику навантаження.
- Після того, як балансувальник навантаження успішно автентифікує користувача, він надсилає маркер доступу до кінцевої точки інформації про користувача Amazon Cognito та отримує заявки користувачів. Балансувальник навантаження підписує та додає претензії користувача до заголовка HTTP
x-amzn-oidc-*у форматі запиту веб-маркера JSON (JWT). - Запит від балансувальника навантаження надсилається до модуля Istio Ingress Gateway.
- Використовуючи фільтр посланника, Istio Gateway декодує
x-amzn-oidc-dataзначення, отримує поле електронної пошти та додає спеціальний заголовок HTTPkubeflow-userid, який використовується рівнем авторизації Kubeflow. - Політики керування доступом на основі ресурсів Istio застосовуються до вхідного запиту для підтвердження доступу до інформаційної панелі Kubeflow. Якщо будь-який із них недоступний для користувача, відповідь надсилається назад. Якщо запит підтверджено, він пересилається до відповідної служби Kubeflow і надає доступ до інформаційної панелі Kubeflow
Постійне зберігання метаданих і артефактів компонентів Kubeflow за допомогою Amazon RDS і Amazon S3
Kubeflow на AWS забезпечує інтеграцію з Служба реляційних баз даних Amazon (Amazon RDS) у Kubeflow Pipelines і AutoML (Катиб) для постійного зберігання метаданих і Amazon S3 у Kubeflow Pipelines для постійного зберігання артефактів. Давайте продовжимо обговорювати Kubeflow Pipelines більш детально.
Kubeflow Pipelines — це платформа для створення та розгортання портативних, масштабованих робочих процесів машинного навчання. Ці робочі процеси можуть допомогти автоматизувати складні конвеєри машинного навчання за допомогою вбудованих і спеціальних компонентів Kubeflow. Kubeflow Pipelines включає Python SDK, компілятор DSL для перетворення коду Python у статичну конфігурацію, службу Pipelines, яка запускає конвеєри зі статичної конфігурації, і набір контролерів для запуску контейнерів у Kubernetes Pods, необхідних для завершення конвеєра.
Метадані Kubeflow Pipelines для конвеєрних експериментів і запусків зберігаються в MySQL, а артефакти, включаючи пакети конвеєрів і показники, зберігаються в MinIO.
Як показано на наведеній нижче схемі, Kubeflow на AWS дозволяє зберігати такі компоненти за допомогою керованих сервісів AWS:
- Метадані конвеєра в Amazon RDS – Amazon RDS забезпечує масштабовану, високодоступну та надійну архітектуру розгортання Multi-AZ із вбудованим автоматичним механізмом відновлення після збою та змінним розміром ємності для реляційної бази даних галузевого стандарту, як-от MySQL. Він керує звичайними завданнями адміністрування бази даних без необхідності надавати інфраструктуру чи підтримувати програмне забезпечення.
- Артефакти конвеєра в Amazon S3 – Amazon S3 пропонує найкращі в галузі масштабованість, доступність даних, безпеку та продуктивність і може використовуватися для задоволення потреб вимогам відповідності.
Ці інтеграції допомагають перенести керування та обслуговування метаданих і сховища артефактів із самокерованого Kubeflow на керовані служби AWS, які легше налаштовувати, керувати та масштабувати.

Підтримка розподілених файлових систем за допомогою Amazon EFS і Amazon FSx
Kubeflow базується на Kubernetes, який забезпечує інфраструктуру для великомасштабної розподіленої обробки даних, включаючи навчання та налаштування великих моделей із глибокою мережею з мільйонами або навіть мільярдами параметрів. Для підтримки таких розподілених систем обробки даних Kubeflow на AWS забезпечує інтеграцію з такими службами зберігання:
- Amazon EFS – Високопродуктивна хмарна розподілена файлова система, якою можна керувати за допомогою Драйвер Amazon EFS CSI. Amazon EFS надає
ReadWriteManyрежим доступу, і тепер ви можете використовувати його для монтування в модулі (Jupyter, навчання моделі, налаштування моделі), що працюють у площині даних Kubeflow, щоб забезпечити постійний, масштабований і спільний робочий простір, який автоматично збільшується та зменшується, коли ви додаєте та видаляєте файли за допомогою відсутність потреби в управлінні. - Amazon FSx для Luster – Оптимізована файлова система для інтенсивних обчислювальних навантажень, таких як високопродуктивні обчислення та машинне навчання, якою ви можете керувати за допомогою Драйвер Amazon FSx CSI. FSx для Lustre надає
ReadWriteManyрежим доступу також, і ви можете використовувати його для кешування навчальних даних із прямим підключенням до Amazon S3 як резервного сховища, яке ви можете використовувати для підтримки серверів ноутбуків Jupyter або розподіленого навчання, що виконується в площині даних Kubeflow. Завдяки цій конфігурації вам не потрібно передавати дані у файлову систему перед використанням тому. FSx для Lustre забезпечує постійні субмілісекундні затримки та високий паралелізм, а також може масштабуватися до ТБ/с пропускної здатності та мільйонів IOPS.
Параметри розгортання Kubeflow
AWS пропонує різні варіанти розгортання Kubeflow:
- Розгортання за допомогою Amazon Cognito
- Розгортання за допомогою Amazon RDS і Amazon S3
- Розгортання за допомогою Amazon Cognito, Amazon RDS і Amazon S3
- Ванільне розгортання
Докладніше про інтеграцію служби та доступні додаткові компоненти для кожного з цих параметрів див Варіанти розгортання. Ви можете встановити варіант, який найкраще відповідає вашому випадку використання.
У наступному розділі ми розглянемо кроки для встановлення дистрибутива AWS Kubeflow v1.4 на Amazon EKS. Потім ми використовуємо наявний приклад конвеєра XGBoost, доступний на центральній інформаційній панелі інтерфейсу Kubeflow, щоб продемонструвати інтеграцію та використання AWS Kubeflow з Amazon Cognito, Amazon RDS і Amazon S3 із диспетчером секретів як доповненням.
Передумови
Для цього покрокового керівництва ви повинні мати такі передумови:
- An Обліковий запис AWS.
- Наявний кластер Amazon EKS. Це має бути версія Kubernetes 1.19 або новіша. Для автоматичного створення кластерів використовують екстлСм. Створіть кластер Amazon EKS і використовуйте параметр eksctl.
Установіть наведені нижче інструменти на клієнтській машині, яка використовується для доступу до вашого кластера Kubernetes. Ви можете використовувати AWS Cloud9, хмарне інтегроване середовище розробки (IDE) для налаштування кластера Kubernetes.
- Інтерфейс командного рядка AWS (AWS CLI) – інструмент командного рядка для взаємодії зі службами AWS. Інструкції зі встановлення див Встановлення, оновлення та видалення AWS CLI.
- екстл > 0.56 – інструмент командного рядка для роботи з кластерами Amazon EKS, який автоматизує багато окремих завдань.
- кубектл – Інструмент командного рядка для роботи з кластерами Kubernetes.
- мерзотник – Програмне забезпечення розподіленого контролю версій.
- Python 3.8+ – Середовище програмування Python.
- типун – Менеджер пакетів для Python.
- налаштувати версію 3.2.0 – Інструмент командного рядка для налаштування об’єктів Kubernetes за допомогою файлу налаштування.
Встановіть Kubeflow на AWS
Налаштуйте kubectl, щоб можна було підключитися до кластера Amazon EKS:
У розгортанні Kubeflow використовуються різні контролери Ролі IAM для облікових записів служб (IRSA). Щоб ваш кластер міг використовувати IRSA, повинен існувати постачальник OIDC. Створіть постачальника OIDC і пов’яжіть його з кластером Amazon EKS, виконавши наведену нижче команду, якщо у вашому кластері його ще немає:
Склонуйте сховище маніфестів AWS і сховище маніфестів Kubeflow і перевірте відповідні гілки випуску:
Додаткову інформацію про ці версії див Випуски та керування версіями.
Налаштуйте Amazon RDS, Amazon S3 і Secrets Manager
Ви створюєте ресурси Amazon RDS і Amazon S3 перед розгортанням маніфестів Kubeflow. Ми використовуємо автоматизовані сценарії Python, які створюють сегмент S3, базу даних RDS і необхідні секрети в диспетчері секретів. Він також редагує необхідні файли конфігурації для конвеєра Kubeflow і AutoML, щоб правильно налаштувати базу даних RDS і сегмент S3 під час встановлення Kubeflow.
Створіть користувача IAM з дозволами дозволити GetBucketLocation і доступ для читання та запису до об’єктів у відрі S3, де ви хочете зберігати артефакти Kubeflow. Використовувати AWS_ACCESS_KEY_ID та AWS_SECRET_ACCESS_KEY користувача IAM у такому коді:
Налаштуйте Amazon Cognito як постачальника автентифікації
У цьому розділі ми створюємо спеціальний домен у Route 53 і ALB для маршрутизації зовнішнього трафіку на Kubeflow Istio Gateway. Ми використовуємо ACM для створення сертифіката для ввімкнення автентифікації TLS в ALB і Amazon Cognito для підтримки пулу користувачів і керування автентифікацією користувачів.
Підставте наступні значення в
- route53.rootDomain.name – Зареєстрований домен. Припустімо, що цей домен є
example.com. - route53.rootDomain.hostedZoneId – Якщо вашим доменом керують у Route53, введіть ідентифікатор розміщеної зони під деталями розміщеної зони. Пропустіть цей крок, якщо вашим доменом керує інший постачальник доменів.
- route53.subDomain.name – Ім’я субдомену, де ви хочете розмістити Kubeflow (наприклад,
platform.example.com). Додаткову інформацію про субдомени див Розгортання Kubeflow з AWS Cognito як IdP. - cluster.name – Назва кластера та місце розгортання Kubeflow.
- cluster.region – Регіон кластера, де розгорнуто Kubeflow (наприклад,
us-west-2). - cognitoUserpool.name – Ім’я пулу користувачів Amazon Cognito (наприклад,
kubeflow-users).
Файл конфігурації виглядає приблизно так:
Запустіть сценарій, щоб створити ресурси:
Сценарій оновлює config.yaml файл із назвами ресурсів, ідентифікаторами та ARN, які він створив. Це виглядає приблизно так:
Створюйте маніфести та розгортайте Kubeflow
Розгорніть Kubeflow за допомогою такої команди:
Оновіть домен за допомогою адреси ALB
Під час розгортання створюється балансувальник навантаження програми AWS, керований входом. Ми оновлюємо записи DNS для субдомену в Route 53 за допомогою DNS балансувальника навантаження. Виконайте таку команду, щоб перевірити, чи налаштовано балансувальник навантаження (це займає приблизно 3–5 хвилин):
Якщо ADDRESS поле пусте через кілька хвилин, перевірте журнали alb-ingress-controller. Інструкції див ALB не вдається забезпечити.
Коли балансувальник навантаження надано, скопіюйте DNS-ім’я балансувальника навантаження та замініть його адресою kubeflow.alb.dns in ${kubeflow_manifest_dir}/tests/e2e/utils/cognito_bootstrap/config.yaml. Розділ Kubeflow конфігураційного файлу виглядає так:
Запустіть такий сценарій, щоб оновити записи DNS для субдомену в Route 53 за допомогою DNS наданого балансувальника навантаження:
Пошук і усунення несправностей
Якщо під час інсталяції у вас виникнуть проблеми, зверніться до усунення несправностей або почніть заново, дотримуючись розділу «Очищення» в цьому блозі.
Покрокове керівництво по використанню
Тепер, коли ми завершили встановлення необхідних компонентів Kubeflow, давайте подивимося на їх дію за допомогою одного з існуючих прикладів, наданих Kubeflow Pipelines на інформаційній панелі.
Отримайте доступ до інформаційної панелі Kubeflow за допомогою Amazon Cognito
Щоб почати, давайте отримаємо доступ до інформаційної панелі Kubeflow. Оскільки ми використовували Amazon Cognito як IdP, використовуйте інформацію, надану в офіційний файл README. Спочатку ми створюємо кількох користувачів на консолі Amazon Cognito. Це користувачі, які будуть входити в центральну інформаційну панель. далі, створити профіль для створеного користувача. Тоді ви зможете отримати доступ до інформаційної панелі через сторінку входу за адресою https://kubeflow.platform.example.com.

На наступному знімку екрана показано нашу інформаційну панель Kubeflow.

Запустити трубопровід
Виберіть на інформаційній панелі Kubeflow Трубопроводи в назві навігації. Ви повинні побачити чотири приклади, надані Kubeflow Pipelines, які можна запустити безпосередньо, щоб дослідити різні функції Pipelines.
Для цієї публікації ми використовуємо зразок XGBoost під назвою [Demo] XGBoost – Ітеративна модель навчання. Ви можете знайти вихідний код на GitHub. Це простий конвеєр, який використовує існуючий XGBoost/Train та XGBoost/Predict Компоненти конвеєра Kubeflow для ітеративного навчання моделі, доки показники не будуть вважатися хорошими на основі вказаних показників.
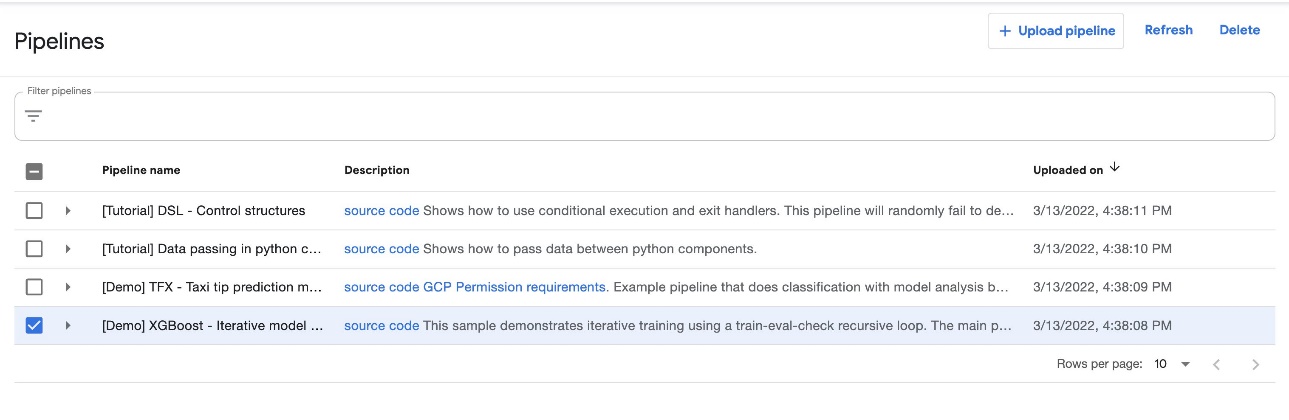
Щоб запустити конвеєр, виконайте такі дії:
- Виберіть конвеєр і виберіть Створіть експеримент.

- під Деталі експерименту, введіть ім'я (для цієї публікації,
demo-blog) і необов'язковий опис. - Вибирати МАЙБУТНІ.

- під Виконати деталі¸ виберіть конвеєр і версію конвеєра.
- для Назва запуску, введіть ім'я.
- для експеримент, виберіть експеримент, який ви створили.
- для Тип запускувиберіть Одноразовий.
- Вибирати Start.

Після того, як конвеєр почне працювати, ви побачите завершення роботи компонентів (протягом кількох секунд). На цьому етапі ви можете вибрати будь-який із завершених компонентів, щоб побачити більше деталей.

Доступ до артефактів в Amazon S3
Під час розгортання Kubeflow ми вказали, що Kubeflow Pipelines має використовувати Amazon S3 для зберігання своїх артефактів. Це включає в себе всі артефакти виводу конвеєра, кешовані прогони та графіки конвеєра, які потім можна використовувати для розширеної візуалізації та оцінки продуктивності.
Коли запуск конвеєра буде завершено, ви зможете побачити артефакти в сегменті S3, створеному під час встановлення. Щоб підтвердити це, виберіть будь-який завершений компонент трубопроводу та перевірте Введення-виведення розділ за замовчуванням Графік вкладка. URL-адреси артефактів мають вказувати на сегмент S3, який ви вказали під час розгортання.
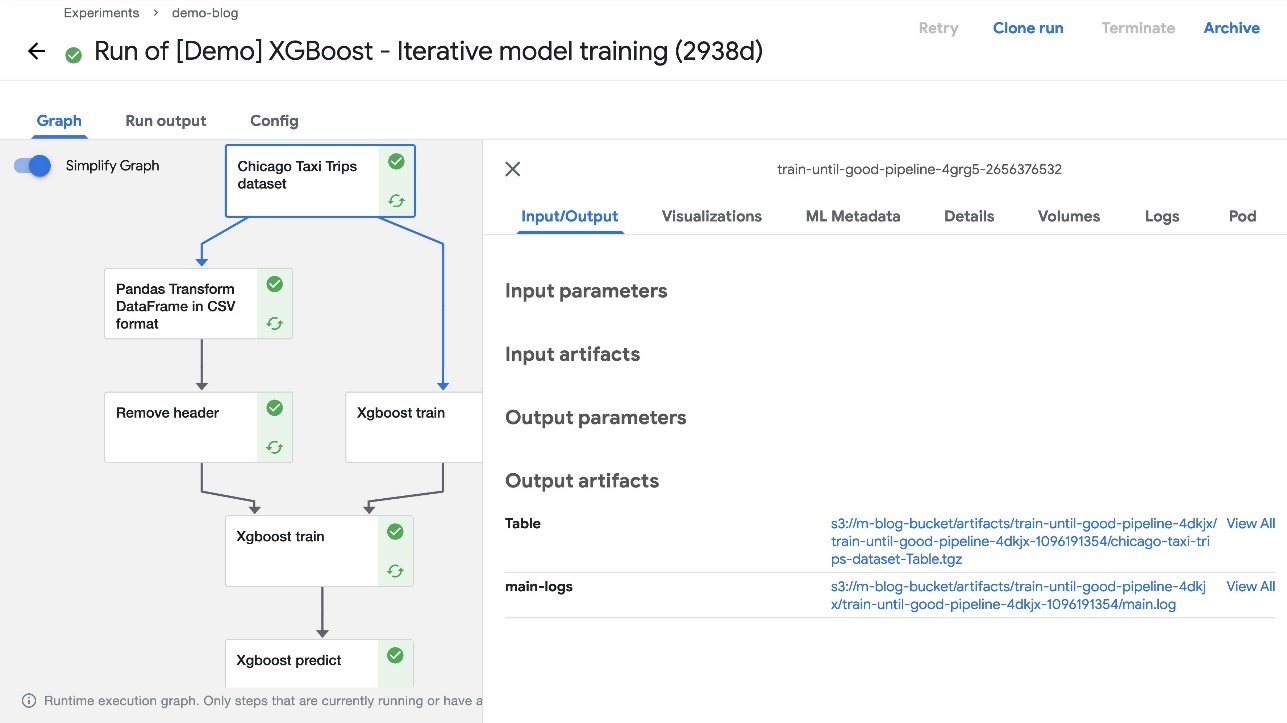
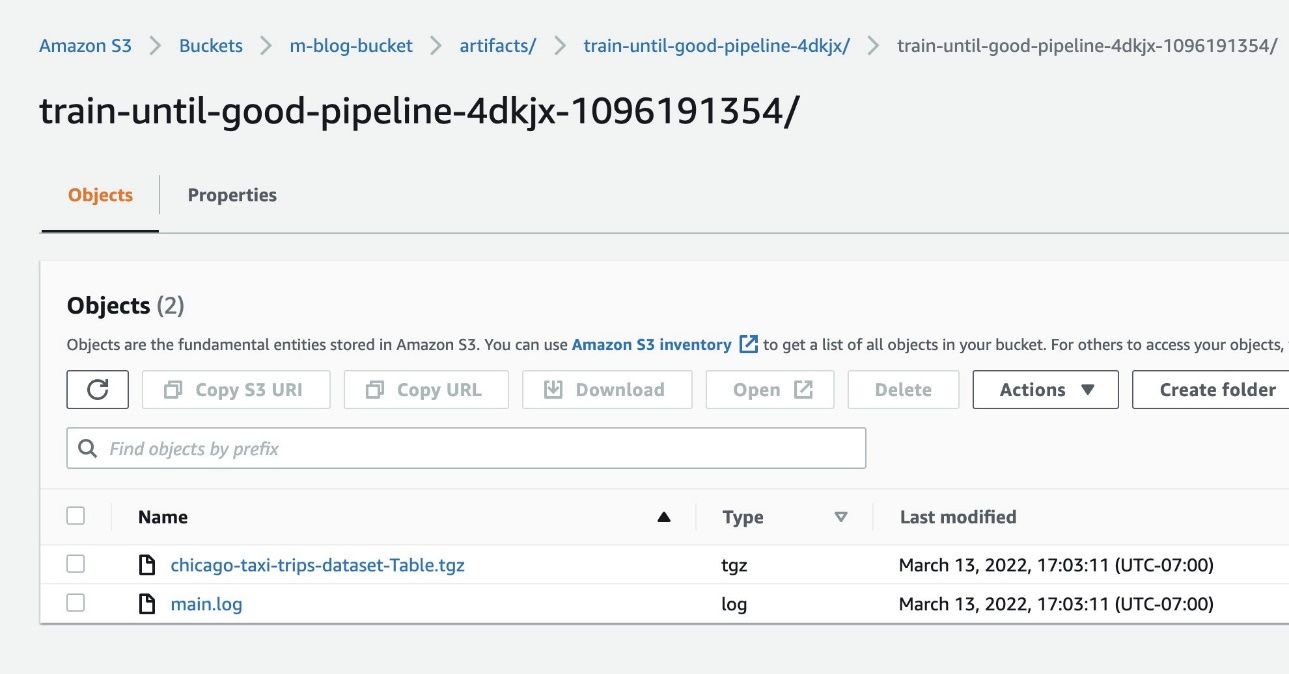
Щоб підтвердити, що ресурси додано до Amazon S3, ми також можемо перевірити сегмент S3 у нашому обліковому записі AWS через консоль Amazon S3.

На наступному знімку екрана показано наші файли.
Перевірте метадані ML в Amazon RDS
Ми також інтегрували Kubeflow Pipelines з Amazon RDS під час розгортання, а це означає, що будь-які метадані конвеєра повинні зберігатися в Amazon RDS. Це включає будь-яку інформацію про час виконання, таку як статус завдання, доступність артефактів, спеціальні властивості, пов’язані з виконанням або артефактами, тощо.
Щоб перевірити інтеграцію Amazon RDS, виконайте дії, наведені в офіційний файл README. Зокрема, виконайте такі кроки:
- Отримайте ім’я користувача та пароль Amazon RDS із секрету, створеного під час встановлення:
- Використовуйте ці облікові дані для підключення до Amazon RDS із кластера:
- Коли відкриється підказка MySQL, ми можемо перевірити
mlpipelinesбазу даних наступним чином: - Тепер ми можемо прочитати вміст певних таблиць, щоб переконатися, що ми можемо бачити інформацію метаданих про експерименти, які запускали конвеєри:
Прибирати
Щоб деінсталювати Kubeflow і видалити створені вами ресурси AWS, виконайте такі дії:
- Видаліть вхід і балансувальник навантаження, керований входом, виконавши таку команду:
- Видаліть решту компонентів Kubeflow:
- Видаліть ресурси AWS, створені скриптами:
- Ресурси, створені для інтеграції Amazon RDS і Amazon S3. Переконайтеся, що у вас є файл конфігурації, створений сценарієм
${kubeflow_manifest_dir}/tests/e2e/utils/rds-s3/metadata.yaml: - Ресурси, створені для інтеграції Amazon Cognito. Переконайтеся, що у вас є файл конфігурації, створений сценарієм
${kubeflow_manifest_dir}/tests/e2e/utils/cognito_bootstrap/config.yaml:
- Ресурси, створені для інтеграції Amazon RDS і Amazon S3. Переконайтеся, що у вас є файл конфігурації, створений сценарієм
- Якщо ви створили спеціальний кластер Amazon EKS для Kubeflow за допомогою eksctl, ви можете видалити його за допомогою такої команди:
Підсумки
У цій публікації ми підкреслили цінність, яку надає Kubeflow на AWS завдяки власній інтеграції служб, керованих AWS, для безпечних, масштабованих і готових для підприємств робочих навантажень AI і ML. Ви можете вибрати один із кількох варіантів розгортання, щоб установити Kubeflow на AWS із різними інтеграціями сервісів. Випадок використання в цій публікації продемонстрував інтеграцію Kubeflow з Amazon Cognito, Secrets Manager, Amazon RDS і Amazon S3. Щоб розпочати роботу з Kubeflow на AWS, перегляньте доступні варіанти розгортання, інтегровані в AWS, у Kubeflow на AWS.
Починаючи з v1.3, ви можете стежити за Репозиторій AWS Labs щоб відстежувати всі внески AWS у Kubeflow. Ви також можете знайти нас на Kubeflow #AWS Slack Channel; ваш відгук допоможе нам визначити пріоритети наступних функцій, щоб зробити внесок у проект Kubeflow.
Про авторів
 Канвалджит Хурмі є архітектором-спеціалістом з рішень AI/ML у Amazon Web Services. Він працює з продуктом AWS, розробником і клієнтами, щоб надати вказівки та технічну допомогу, допомагаючи їм підвищити цінність своїх гібридних рішень ML під час використання AWS. Kanwaljit спеціалізується на допомозі клієнтам із контейнерними програмами та програмами машинного навчання.
Канвалджит Хурмі є архітектором-спеціалістом з рішень AI/ML у Amazon Web Services. Він працює з продуктом AWS, розробником і клієнтами, щоб надати вказівки та технічну допомогу, допомагаючи їм підвищити цінність своїх гібридних рішень ML під час використання AWS. Kanwaljit спеціалізується на допомозі клієнтам із контейнерними програмами та програмами машинного навчання.
 Мегхна Байджал є інженером-програмістом із штучним інтелектом AWS, що полегшує користувачам інтеграцію робочих навантажень машинного навчання в AWS шляхом створення продуктів і платформ машинного навчання, таких як контейнери глибокого навчання, AMI глибокого навчання, контролери AWS для Kubernetes (ACK) і Kubeflow на AWS . Поза роботою вона любить читати, подорожувати та займатися малюванням.
Мегхна Байджал є інженером-програмістом із штучним інтелектом AWS, що полегшує користувачам інтеграцію робочих навантажень машинного навчання в AWS шляхом створення продуктів і платформ машинного навчання, таких як контейнери глибокого навчання, AMI глибокого навчання, контролери AWS для Kubernetes (ACK) і Kubeflow на AWS . Поза роботою вона любить читати, подорожувати та займатися малюванням.
 Сурадж Кота є інженером-програмістом, який спеціалізується на інфраструктурі машинного навчання. Він створює інструменти, щоб легко почати роботу та масштабувати навантаження машинного навчання на AWS. Він працював над контейнерами AWS Deep Learning Containers, Deep Learning AMI, операторами SageMaker для Kubernetes та іншими інтеграціями з відкритим кодом, як-от Kubeflow.
Сурадж Кота є інженером-програмістом, який спеціалізується на інфраструктурі машинного навчання. Він створює інструменти, щоб легко почати роботу та масштабувати навантаження машинного навчання на AWS. Він працював над контейнерами AWS Deep Learning Containers, Deep Learning AMI, операторами SageMaker для Kubernetes та іншими інтеграціями з відкритим кодом, як-от Kubeflow.
- Coinsmart. Найкраща в Європі біржа біткойн та криптовалют.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. БЕЗКОШТОВНИЙ ДОСТУП.
- CryptoHawk. Альткойн Радар. Безкоштовне випробування.
- Джерело: https://aws.amazon.com/blogs/machine-learning/build-and-deploy-a-scalable-machine-learning-system-on-kubernetes-with-kubeflow-on-aws/
- "
- 10
- 100
- 420
- 7
- МЕНЮ
- доступ
- рахунки
- дію
- Додатковий
- адреса
- адмін
- адміністрація
- Філії
- AI
- ВСІ
- вже
- Amazon
- Amazon Web Services
- Інший
- додаток
- застосування
- відповідний
- архітектура
- навколо
- Юрист
- автентифіковано
- засвідчує автентифікацію
- Authentication
- авторизації
- автоматизувати
- Автоматизований
- автоматизує
- наявність
- доступний
- AWS
- ставати
- Переваги
- КРАЩЕ
- мільярди
- Блог
- border
- будувати
- Створюємо
- Будує
- вбудований
- можливості
- потужність
- який
- випадків
- CD
- сертифікат
- сертифікати
- складні
- Введіть дані:
- Вибирати
- претензій
- клас
- код
- загальний
- завершення
- комплекс
- компонент
- комп'ютер
- обчислення
- конфігурація
- З'єднуватися
- зв'язок
- Консоль
- Контейнери
- містить
- зміст
- продовжувати
- сприяти
- контроль
- контролер
- авторське право
- може
- створювати
- створений
- створює
- створення
- створення
- Повноваження
- критичний
- виготовлений на замовлення
- Клієнти
- приладова панель
- дані
- обробка даних
- наука про дані
- Database
- DDoS
- присвячених
- Попит
- демонструвати
- продемонстрований
- розгортання
- розгорнути
- розгортання
- розгортання
- розгортання
- розгортає
- дизайн
- деталь
- деталі
- розробка
- Dex
- різний
- прямий
- безпосередньо
- обговорювати
- розподілений
- розподіл
- DNS
- Ні
- домен
- легко
- легкий у використанні
- нудьгувати
- включіть
- шифрування
- Кінцева точка
- інженер
- Машинобудування
- Що натомість? Створіть віртуальну версію себе у
- підприємство
- Навколишнє середовище
- оцінка
- Event
- приклад
- існуючий
- досвід
- експеримент
- дослідити
- Провал
- риси
- зворотний зв'язок
- фінансовий
- Перший
- відповідати
- потік
- Сфокусувати
- фокусується
- стежити
- після
- формат
- знайдений
- свіжий
- отримання
- Git
- GitHub
- добре
- Рости
- Зростання
- допомога
- допомогу
- допомагає
- тут
- Високий
- вище
- Виділено
- дуже
- хостинг
- HTTPS
- гібрид
- Особистість
- Impact
- здійснювати
- удосконалювати
- Инк
- includes
- У тому числі
- збільшений
- індивідуальний
- провідний в галузі
- інформація
- інформація
- Інфраструктура
- встановлювати
- інтегрований
- інтеграція
- інтеграцій
- інвестування
- ізоляція
- питання
- IT
- сам
- Джобс
- зберігання
- ключ
- Labs
- мова
- великий
- запущений
- вивчення
- підйомний
- Лінія
- загрузка
- місцевий
- машина
- навчання за допомогою машини
- підтримувати
- РОБОТИ
- Робить
- управляти
- вдалося
- управління
- менеджер
- Метрика
- мільйони
- ML
- модель
- Моделі
- моніторинг
- більше
- найбільш
- Імена
- Природний
- навігація
- мережу
- мережу
- вузли
- ноутбук
- номер
- Пропозиції
- відкрити
- з відкритим вихідним кодом
- Відкриється
- Оператори
- оптимізований
- варіант
- Опції
- Інше
- власний
- Пароль
- продуктивність
- платформа
- Платформи
- точка
- Політика
- басейн
- представити
- пріоритет
- обробка
- Product
- Продукти
- Програмування
- проект
- захист
- забезпечувати
- забезпечує
- забезпечення
- громадськість
- швидко
- досягати
- читання
- Причини
- запис
- зареєстрований
- звільнити
- запросити
- вимагається
- Вимога
- ресурс
- ресурси
- відповідь
- REST
- Маршрут
- прогін
- біг
- масштабованість
- масштабовані
- шкала
- Масштабування
- наука
- Sdk
- SEC
- seconds
- безпечний
- безпеку
- Без сервера
- обслуговування
- Послуги
- комплект
- установка
- акції
- Ознаки
- простий
- Розмір
- слабкий
- сон
- So
- соціальна
- Софтвер
- Інженер-програміст
- solid
- рішення
- Рішення
- деякі
- що в сім'ї щось
- вихідні
- спеціаліст
- спеціалізований
- спеціалізується
- конкретно
- Стажування
- старт
- почалася
- починається
- стан
- Статус
- зберігання
- зберігати
- Успішно
- підтримка
- Опори
- система
- Systems
- завдання
- технічний
- Джерело
- через
- час
- знак
- інструмент
- інструменти
- топ
- трек
- трафік
- Навчання
- переклад
- Переклад
- перевезення
- Подорож
- ui
- Оновити
- Updates
- us
- використання
- користувачі
- підтверджено
- значення
- різноманітність
- різний
- перевірити
- бачення
- обсяг
- Web
- веб-сервіси
- ВООЗ
- в
- без
- Work
- працював
- робочий
- працює