Вступ
На сучасному складному ринку праці люди повинні збирати достовірну інформацію, щоб приймати обґрунтовані рішення щодо кар’єри. Glassdoor — популярна платформа, де співробітники анонімно діляться своїм досвідом. Однак велика кількість відгуків може приголомшити шукачів роботи. Ми спробуємо побудувати НЛПкерована система, яка автоматично згущує огляди Glassdoor у змістовні підсумки, щоб вирішити цю проблему. Наш проект досліджує покроковий процес, від використання Selenium для збору оглядів до використання NLTK для підсумовування. Ці стислі підсумки надають цінну інформацію про культуру компанії та можливості зростання, допомагаючи людям узгоджувати свої кар’єрні прагнення з відповідними організаціями. Ми також обговорюємо обмеження, такі як відмінності в тлумаченні та помилки збору даних, щоб забезпечити повне розуміння процесу узагальнення.
Мета навчання
Навчальні цілі цього проекту охоплюють розробку надійної системи підсумовування тексту, яка ефективно конденсує об’ємні огляди Glassdoor у стислі та інформативні резюме. Беручи участь у цьому проекті, ви:
- Зрозумійте, як узагальнювати відгуки з публічних платформ, у даному випадку Glassdoor, і яку користь це може принести людям, які хочуть оцінити організацію, перш ніж прийняти пропозицію про роботу. Визнати проблеми, пов'язані з величезною кількістю доступних текстових даних і потребою в автоматизованих техніках підсумовування.
- Вивчіть основи веб-скрейпінгу та використовуйте бібліотеку Selenium у Python, щоб отримати огляди Glassdoor. Досліджуйте навігацію веб-сторінками, взаємодію з елементами та отримання текстових даних для подальшого аналізу.
- Розвивайте навички очищення та підготовки текстових даних, отриманих з оглядів Glassdoor. Впровадити методи обробки шуму, видалення нерелевантної інформації та забезпечення якості вхідних даних для ефективного узагальнення.
- Використовуйте бібліотеку NLTK (Natural Language Toolkit) у Python, щоб використовувати широкий спектр функцій NLP для обробки тексту, токенізації, сегментації речень тощо. Отримайте практичний досвід використання цих інструментів, щоб полегшити процес підсумовування тексту.
Ця стаття була опублікована як частина Blogathon Data Science.
Зміст
Опис проекту
Зведіть до мінімуму рецензування значного обсягу відгуків Glassdoor, розробивши автоматизовану систему підсумовування тексту. Запрягаючи обробка природної мови (НЛП) методики та алгоритми машинного навчання, ця система витягує найбільш актуальну інформацію з оглядів і створює компактні та інформативні підсумки. Проект передбачатиме збір даних від Glassdoor за допомогою Selenium, попередньої обробки даних і передових методів резюмування тексту, щоб дати можливість людям швидко осягнути важливу інформацію про культуру організації та робоче середовище.
Постановка проблеми

Цей проект має на меті допомогти людям інтерпретувати культуру організації та робоче середовище на основі численних оглядів Glassdoor. Glassdoor, широко використовувана платформа, стала для людей основним ресурсом для збору інформації про потенційних роботодавців. Однак величезна кількість оглядів на Glassdoor може лякати, створюючи труднощі для ефективного аналізу корисної інформації.
Розуміння культури організації, стилю лідерства, гармонії між роботою та особистим життям, перспективи просування та загального щастя співробітників є ключовими факторами, які можуть суттєво вплинути на кар’єрні рішення людини. Але завдання навігації в численних оглядах, кожен з яких відрізняється довжиною, стилем і фокусом, справді складне. Крім того, відсутність стислого, легкого для розуміння резюме лише загострює проблему.
Таким чином, поставлене завдання полягає в тому, щоб розробити систему для підсумовування тексту, яка могла б ефективно обробляти безліч оглядів Glassdoor і надавати стислі, але інформативні резюме. Автоматизуючи цей процес, ми прагнемо надати людям вичерпний огляд характеристик компанії в зручній формі. Система дозволить шукачам роботи швидко зрозуміти ключові теми та настрої з оглядів, що полегшить процес прийняття рішень щодо можливостей роботи.
Вирішуючи цю проблему, ми прагнемо зменшити інформаційну насиченість, з якою стикаються шукачі роботи, і дати їм змогу приймати обґрунтовані рішення, які відповідають їхнім кар’єрним цілям. Система підсумовування тексту, розроблена в рамках цього проекту, стане безцінним ресурсом для людей, які прагнуть зрозуміти робочий клімат і культуру організації, що дасть їм впевненість у орієнтуванні в робочому середовищі.
Підхід
Ми прагнемо спростити розуміння робочої культури та середовища компанії через огляди Glassdoor. Наша стратегія передбачає систематичний процес, який охоплює збір даних, підготовку та узагальнення тексту.
- Збір даних: Ми будемо використовувати бібліотеку Selenium для збирання оглядів Glassdoor. Це дозволить нам накопичити багато відгуків про цільову компанію. Автоматизація цього процесу забезпечує збір різноманітних оглядів, що пропонують повний спектр досвіду та точок зору.
- Підготовка даних: Після того, як відгуки будуть зібрані, ми проведемо попередню обробку даних, щоб забезпечити якість і релевантність вилученого тексту. Це включає видалення нерелевантних даних, усунення незвичайних символів або невідповідностей у форматуванні та сегментування тексту на менші компоненти, наприклад речення чи слова.
- Резюмування тексту: На етапі підсумовування тексту ми використовуватимемо методи обробки природної мови (NLP) і алгоритми машинного навчання для створення коротких підсумків із попередньо оброблених даних огляду.
сценарій

Уявіть собі випадок Алекса, досвідченого інженера-програміста, якому запропонували посаду у Salesforce, відомій технологічній фірмі. Алекс хоче глибше дослідити культуру роботи Salesforce, оточення та задоволеність співробітників як частину процесу прийняття рішень.
За допомогою нашого методу згортання оглядів Glassdoor Алекс може швидко отримати доступ до основних моментів багатьох відгуків співробітників Salesforce. Використовуючи створену нами автоматизовану систему підсумовування тексту, Алекс може отримувати стислі резюме, які висвітлюють такі ключові елементи, як культура роботи компанії, орієнтована на команду, можливості просування по службі та загальне задоволення співробітників.
Переглядаючи ці підсумки, Алекс може повністю зрозуміти корпоративні характеристики Salesforce, не витрачаючи надто багато часу на читання оглядів. Ці підсумки надають компактну, але глибоку перспективу, що дозволяє Алексу прийняти рішення, яке відповідає його кар’єрним цілям.
Збір і підготовка даних
Ми будемо використовувати бібліотеку Selenium в Python щоб отримати відгуки від Glassdoor. Наданий фрагмент коду ретельно пояснює процес. Нижче ми описуємо кроки, пов’язані з підтриманням прозорості та дотриманням етичних стандартів:
Імпорт бібліотек
Починаємо з імпорту необхідних бібліотек, в т.ч Селен, Пандита інші важливі модулі, що забезпечують комплексне середовище для збору даних.
# Importing the necessary libraries
import selenium
from selenium import webdriver as wb
import pandas as pd
import time
from time import sleep
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
import itertoolsНалаштування драйвера Chrome
Ми встановлюємо налаштування для ChromeDriver, вказуючи відповідний шлях, де він зберігається, таким чином дозволяючи бездоганну інтеграцію з інфраструктурою Selenium.
# Chaning the working directory to the path # where the chromedriver is saved & setting # up the chrome driver %cd "PATH WHERE CHROMEDRIVER IS SAVED"
driver = wb.Chrome(r"YOUR PATHchromedriver.exe") driver.get('https://www.glassdoor.co.in
/Reviews/Salesforce-Reviews-E11159.
htm?sort.sortType=RD&sort.ascending=false&filter.
iso3Language=eng&filter.
employmentStatus=PART_TIME&filter.employmentStatus=REGULAR')
Доступ до сторінки Glassdoor
Ми використовуємо функцію driver.get() для доступу до сторінки Glassdoor, де розміщено бажані відгуки. У цьому прикладі ми спеціально орієнтуємося на сторінку оглядів Salesforce.
Перегляд рецензій
У добре структурованому циклі ми переглядаємо заздалегідь визначену кількість сторінок, уможливлюючи систематичне та широке вилучення оглядів. Цей підрахунок можна скоригувати відповідно до індивідуальних вимог.
Розгортання деталей огляду
Ми активно розширюємо деталі огляду під час кожної ітерації, взаємодіючи з елементами «Продовжити читання», сприяючи повному збору відповідної інформації.
Ми систематично знаходимо та вилучаємо багато деталей відгуків, включаючи заголовки оглядів, відомості про роботу (дата, посада, місцезнаходження), рейтинги, тривалість роботи співробітників, плюси та мінуси. Ці деталі відокремлюються та зберігаються в окремих списках, що забезпечує точне представлення.
Створення DataFrame
Використовуючи можливості Pandas, ми встановлюємо тимчасовий DataFrame (df_temp), щоб зберігати інформацію, отриману з кожної ітерації. Потім цей ітеративний DataFrame додається до основного DataFrame (df), що дозволяє консолідувати дані перегляду.
Щоб керувати процесом розбиття на сторінки, ми ефективно знаходимо кнопку «Далі» та ініціюємо подію клацання, згодом переходячи до наступної сторінки відгуків. Цей систематичний прогрес триває до тих пір, поки не буде успішно отримано всі доступні відгуки.
Очищення та сортування даних
Нарешті, ми виконуємо основні операції з очищення даних, такі як перетворення стовпця «Дата» у формат дати й часу, скидання індексу для покращення організації та сортування DataFrame у порядку спадання на основі дат перегляду.
Цей ретельний підхід забезпечує повний і етичний збір багатьох оглядів Glassdoor, уможливлюючи подальший аналіз і наступні завдання підсумовування тексту.
# Importing the necessary libraries
import selenium
from selenium import webdriver as wb
import pandas as pd
import time
from time import sleep
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
import itertools # Changing the working directory to the path # where the chromedriver is saved
# Setting up the chrome driver
%cd "C:UsersakshiOneDriveDesktop"
driver = wb.Chrome(r"C:UsersakshiOneDriveDesktopchromedriver.exe") # Accessing the Glassdoor page with specific filters
driver.get('https://www.glassdoor.co.in/Reviews/
Salesforce-Reviews-E11159.htm?sort.sortType=RD&sort.
ascending=false&filter.iso3Language=eng&filter.
employmentStatus=PART_TIME&filter.employmentStatus=REGULAR') df = pd.DataFrame() num = 20
for _ in itertools.repeat(None, num): continue_reading = driver.find_elements_by_xpath( "//div[contains(@class,'v2__EIReviewDetailsV2__ continueReading v2__EIReviewDetailsV2__clickable v2__ EIReviewDetailsV2__newUiCta mb')]" ) time.sleep(5) review_heading = driver.find_elements_by_xpath("//a[contains (@class,'reviewLink')]") review_heading = pd.Series([i.text for i in review_heading]) dets = driver.find_elements_by_xpath("//span[contains(@class, 'common__EiReviewDetailsStyle__newUiJobLine')]") dets = [i.text for i in dets] dates = [i.split(' - ')[0] for i in dets] role = [i.split(' - ')[1].split(' in ')[0] for i in dets] try: loc = [i.split(' - ')[1].split(' in ')[1] if i.find(' in ')!=-1 else '-' for i in dets] except: loc = [i.split(' - ')[2].split(' in ')[1] if i.find(' in ')!=-1 else '-' for i in dets] rating = driver.find_elements_by_xpath("//span[contains (@class,'ratingNumber mr-xsm')]") rating = [i.text for i in rating] emp = driver.find_elements_by_xpath("//span[contains (@class,'pt-xsm pt-md-0 css-1qxtz39 eg4psks0')]") emp = [i.text for i in emp] pros = driver.find_elements_by_xpath("//span[contains (@data-test,'pros')]") pros = [i.text for i in pros] cons = driver.find_elements_by_xpath("//span[contains (@data-test,'cons')]") cons = [i.text for i in cons] df_temp = pd.DataFrame( { 'Date': pd.Series(dates), 'Role': pd.Series(role), 'Tenure': pd.Series(emp), 'Location': pd.Series(loc), 'Rating': pd.Series(rating), 'Pros': pd.Series(pros), 'Cons': pd.Series(cons) } ) df = df.append(df_temp) try: driver.find_element_by_xpath("//button[contains (@class,'nextButton css-1hq9k8 e13qs2071')]").click() except: print('No more reviews') df['Date'] = pd.to_datetime(df['Date'])
df = df.reset_index()
del df['index']
df = df.sort_values('Date', ascending=False)
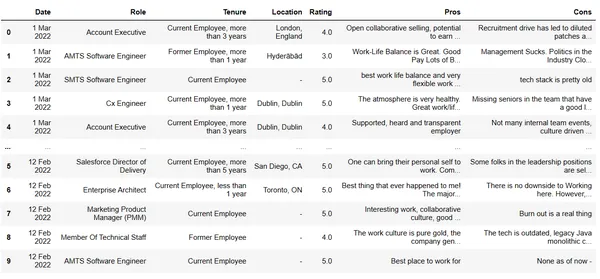
df
Отримуємо вихід наступним чином.
Узагальнення тексту
Для створення підсумків із вилучених оглядів ми використовуємо НЛТК бібліотеку та застосовувати різні техніки для обробка та аналіз тексту. Фрагмент коду демонструє процес, забезпечуючи дотримання етичних стандартів і уникаючи потенційних проблем із платформами детекторів тексту ШІ.
Імпорт бібліотек
Ми імпортуємо основні бібліотеки з модуля колекцій, включаючи pandas, string, nltk і Counter. Ці бібліотеки пропонують надійні функції обробки даних, обробки рядків і аналізу тексту, забезпечуючи комплексний робочий процес підсумовування тексту.
import string
import nltk
from nltk.corpus import stopwords
from collections import Counter
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))Підготовка даних
Отримані відгуки фільтруємо за бажаною роллю (Інженер програмного забезпечення в нашому сценарії), що забезпечує релевантність і контекстно-залежний аналіз. Нульові значення видаляються, а дані очищаються для полегшення точної обробки.
role = input('Input Role') df = df.dropna()
df = df[df['Role'].str.contains(role)]Попередня обробка тексту
Плюси та мінуси кожного огляду обробляються окремо. Ми забезпечуємо послідовність нижнього регістру та усуваємо знаки пунктуації за допомогою функції translate(). Потім текст розбивається на слова, видаляючи стоп-слова та конкретні слова, пов’язані з контекстом. Отримані списки слів, pro_words і con_words, фіксують відповідну інформацію для подальшого аналізу.
pros = [i for i in df['Pros']]
cons = [i for i in df['Cons']] # Split pro into a list of words
all_words = []
pro_words = ' '.join(pros)
pro_words = pro_words.translate(str.maketrans
('', '', string.punctuation))
pro_words = pro_words.split()
specific_words = ['great','work','get','good','company', 'lot','it’s','much','really','NAME','dont','every', 'high','big','many','like']
pro_words = [word for word in pro_words if word.lower() not in stop_words and word.lower() not in specific_words]
all_words += pro_words con_words = ' '.join(cons)
con_words = con_words.translate(str.maketrans
('', '', string.punctuation))
con_words = con_words.split()
con_words = [word for word in con_words if word.lower() not in stop_words and word.lower() not in specific_words]
all_words += con_wordsЧастотний аналіз слів
Використовуючи клас Counter з модуля колекцій, ми отримуємо підрахунки частоти слів як для плюсів, так і для мінусів. Цей аналіз дозволяє нам ідентифікувати слова, які найчастіше зустрічаються в оглядах, полегшуючи подальше виділення ключових слів.
# Count the frequency of each word
pro_word_counts = Counter(pro_words)
con_word_counts = Counter(con_words)Щоб визначити ключові теми та настрої, ми виділяємо 10 найбільш поширених слів окремо від плюсів і мінусів за допомогою методу most_common(). Ми також беремо участь у наявності загальних ключових слів між двома наборами, забезпечуючи комплексний і неупереджений підхід до узагальнення.
# Get the 10 most common words from the pros and cons
keyword_count = 10
top_pro_keywords = pro_word_counts.most_common(keyword_count)
top_con_keywords = con_word_counts.most_common(keyword_count) # Check if there are any common keywords between the pros and cons
common_keywords = list(set([keyword for keyword, frequency in top_pro_keywords]).intersection([keyword for keyword, frequency in top_con_keywords])) # Handle the common keywords according to your desired behavior
for common_keyword in common_keywords: pro_frequency = pro_word_counts[common_keyword] con_frequency = con_word_counts[common_keyword] if pro_frequency > con_frequency: top_con_keywords = [(keyword, frequency) for keyword, frequency in top_con_keywords if keyword != common_keyword] top_con_keywords = top_con_keywords[0:6] else: top_pro_keywords = [(keyword, frequency) for keyword, frequency in top_pro_keywords if keyword != common_keyword] top_pro_keywords = top_pro_keywords[0:6] top_pro_keywords = top_pro_keywords[0:5]Аналіз почуттів
Ми проводимо аналіз настроїв на плюси і мінуси, визначаючи списки позитивних і негативних слів. Переглядаючи кількість слів, ми обчислюємо загальну оцінку настрою, надаючи розуміння загальних настроїв, висловлених у відгуках.
Розрахунок оцінки настрою
Щоб визначити оцінку настрою, ми ділимо загальну оцінку настрою на загальну кількість слів у відгуках. Помноживши це на 100, ви отримаєте відсоток оцінки настроїв, пропонуючи цілісне уявлення про розподіл настроїв у даних.
# Calculate the overall sentiment score by summing the frequencies of positive and negative words positive_words = ["amazing","excellent", "great", "good", "positive", "pleasant", "satisfied", "happy", "pleased", "content", "content", "delighted", "pleased", "gratified", "joyful", "lucky", "fortunate", "glad", "thrilled", "overjoyed", "ecstatic", "pleased", "relieved", "glad", "impressed", "pleased", "happy", "admirable","valuing", "encouraging"]
negative_words = ["poor","slow","terrible", "horrible", "bad", "awful", "unpleasant", "dissatisfied", "unhappy", "displeased", "miserable", "disappointed", "frustrated", "angry", "upset", "offended", "disgusted", "repulsed", "horrified", "afraid", "terrified", "petrified", "panicked", "alarmed", "shocked", "stunned", "dumbfounded", "baffled", "perplexed", "puzzled"] positive_score = 0
negative_score = 0
for word, frequency in pro_word_counts.items(): if word in positive_words: positive_score += frequency
for word, frequency in con_word_counts.items(): if word in negative_words: negative_score += frequency overall_sentiment_score = positive_score - negative_score # calculate the sentiment score in %
total_words = sum(pro_word_counts.values()) + sum(con_word_counts.values())
sentiment_score_percent = (overall_sentiment_score / total_words) * 100Друк результатів
Ми представляємо 5 найкращих ключових слів за плюси та мінуси, загальну оцінку настрою, відсоток оцінки настрою та середню оцінку в оглядах. Ці показники пропонують цінну інформацію про переважаючі настрої та враження користувачів, пов’язані з організацією.
# Print the results
print("Top 5 keywords for pros:", top_pro_keywords)
print("Top 5 keywords for cons:", top_con_keywords)
print("Overall sentiment score:", overall_sentiment_score)
print("Sentiment score percentage:", sentiment_score_percent)
print('Avg rating given',df['Rating'].mean())
Оцінювання речень
Щоб отримувати найрелевантнішу інформацію, ми створюємо модель сумки слів на основі плюсів і мінусів речень. Ми реалізуємо функцію підрахунку балів, яка призначає бали кожному реченню на основі появи певних слів або словосполучень, забезпечуючи ефективний процес вилучення підсумків.
# Join the pros and cons into a single list of sentences
sentences = pros + cons # Create a bag-of-words model for the sentences
bow = {}
for sentence in sentences: words = ' '.join(sentences) words = words.translate(str.maketrans ('', '', string.punctuation)) words = words.split() for word in words: if word not in bow: bow[word] = 0 bow[word] += 1 # Define a heuristic scoring function that assigns # a score to each sentence based on the presence of # certain words or word combinations
def score(sentence): words = sentence.split() score = 0 for word in words: if word in ["good", "great", "excellent"]: score += 2 elif word in ["poor", "bad", "terrible"]: score -= 2 elif word in ["culture", "benefits", "opportunities"]: score += 1 elif word in ["balance", "progression", "territory"]: score -= 1 return score # Score the sentences and sort them by score
scored_sentences = [(score(sentence), sentence) for sentence in sentences]
scored_sentences.sort(reverse=True)Ми вилучаємо 10 речень із найвищими балами та об’єднуємо їх у цілісне резюме за допомогою функції join(). Цей короткий виклад містить у собі найважливіші моменти та думки, висловлені в оглядах, надаючи стислий огляд для прийняття рішень.
# Extract the top 10 scored sentences
top_sentences = [sentence for score, sentence in scored_sentences[:10]] # Join the top scored sentences into a single summary
summary = " ".join(top_sentences)Друк резюме
Нарешті, ми друкуємо згенероване резюме, цінний ресурс для людей, які шукають уявлення про культуру організації та робоче середовище.
# Print the summary
print("Summary:")
print(summary)- Хороші люди, хороша культура, хороші переваги, хороша культура, зосередженість на психічному здоров’ї, більш-менш повністю віддалена.
- Чудова WLB і етика піклуються про співробітників.
- Колеги справді чудові, нетоксичні та чудові
- Хороший WLB, хороша компенсація, хороша культура
- 1. Хороша оплата 2. Цікава робота 3. Гарний баланс між роботою та життям 4. Чудові пільги – все термінове покрито
- Чудовий баланс роботи та життя, хороша оплата, чудова культура, чудові колеги, чудова зарплата
- Дуже хороша культура праці та переваги
- Чудовий баланс між роботою та особистим життям, великі переваги, підтримка сімейних цінностей, чудові можливості кар’єрного зростання.
- Співпраця, підтримка, сильна культура (охана), можливості для зростання, рух до асинхронності, технічно добре, чудові наставники та товариші по команді
Як ми бачимо вище, ми отримуємо чітке резюме та добре розуміємо корпоративну культуру, пільги та переваги, характерні для ролі розробника програмного забезпечення. Використовуючи можливості NLTK
і використовуючи надійні методи обробки тексту, цей підхід дає змогу ефективно виділяти ключові слова, аналізувати настрої та створювати інформативні підсумки з вилучених оглядів Glassdoor.
Використовуйте випадки
Система резюме тексту, що розробляється, має великий потенціал у різних практичних сценаріях. Його різноманітні програми можуть принести користь зацікавленим сторонам, зокрема шукачам роботи, спеціалістам із кадрових ресурсів і рекрутерам. Ось кілька важливих випадків використання:
- Шукають роботу: Шукачі роботи можуть отримати значну користь від системи узагальнення тексту, яка надає стислий та інформативний огляд культури та робочого середовища організації. Згортаючи огляди Glassdoor, шукачі роботи можуть швидко оцінити загальні настрої, визначити повторювані теми та прийняти обґрунтовані рішення щодо того, чи відповідає організація їхнім кар’єрним прагненням і цінностям.
- Фахівці з кадрів: Людський ресурс професіонали можуть використовувати систему підсумовування тексту для ефективного аналізу значного обсягу оглядів Glassdoor. Узагальнюючи огляди, вони можуть отримати цінну інформацію про сильні та слабкі сторони різних організацій. Ці знання можуть стати основою для стратегій брендингу роботодавця, допомогти визначити сфери, які потрібно вдосконалити, і підтримати ініціативи з порівняльного аналізу.
- Рекрутери: Рекрутери можуть оптимізувати свій час і зусилля, використовуючи систему підсумовування тексту для оцінки репутації та культури роботи організації. Узагальнені огляди Glassdoor дозволяють рекрутерам швидко визначити ключові настрої та важливі аспекти для спілкування з кандидатами. Це сприяє більш цілеспрямованому та ефективному процесу найму, покращуючи залучення кандидатів і результати відбору.
- Керівництво та особи, які приймають рішення: Система підсумовування тексту пропонує цінну інформацію для керівництва організації та осіб, які приймають рішення. Підсумовуючи внутрішні огляди Glassdoor, вони можуть краще зрозуміти сприйняття співробітників, рівень задоволеності та потенційні проблеми. Ця інформація може керувати прийняттям стратегічних рішень, інформувати про ініціативи залучення працівників і сприяти створенню позитивного робочого середовища.
Недоліки
Наш підхід до узагальнення оглядів Glassdoor передбачає кілька обмежень і потенційних проблем, які необхідно враховувати. До них належать:
- Якість даних: Точність і надійність створених підсумків значною мірою залежать від якості вхідних даних. Забезпечення автентичності та достовірності оглядів Glassdoor, які використовуються для узагальнення, має важливе значення. Для пом’якшення цього обмеження необхідні методи перевірки даних і заходи проти підроблених або упереджених оглядів.
- Суб'єктивність і упередженість: Огляди Glassdoor за своєю суттю відображають суб’єктивні думки та досвід. Процес узагальнення може ненавмисно посилити або послабити певні настрої, що призведе до необ’єктивних підсумків. Розгляд можливих упереджень і розробка методів неупередженого узагальнення мають вирішальне значення для забезпечення чесних і точних представлень.
- Контекстне розуміння: Зрозуміти контекст і нюанси відгуків може бути складно. Алгоритму підсумовування може бути важко зрозуміти повне значення та наслідки конкретних фраз або виразів, потенційно втрачаючи важливу інформацію. Включення передових методів розуміння контексту, таких як аналіз настроїв і контекстно-залежні моделі, може допомогти усунути це обмеження.
- Узагальнення: Важливо розуміти, що створені підсумки надають загальний огляд, а не вичерпний аналіз кожного огляду. Система може не охоплювати кожну деталь або унікальний досвід, згаданий у оглядах, що змушує користувачів розглядати ширший діапазон інформації, перш ніж робити висновки чи судження.
- Своєчасність: Огляди Glassdoor динамічні та можуть змінюватися з часом. Система узагальнення може не забезпечувати оновлення в реальному часі, а згенеровані узагальнення можуть застаріти. Впровадження механізмів для періодичного повторного узагальнення або інтегрування моніторингу перегляду в реальному часі може допомогти усунути це обмеження та забезпечити релевантність узагальнень.
Визнання та активне усунення цих обмежень має вирішальне значення для забезпечення цілісності та корисності системи. Регулярне оцінювання, врахування відгуків користувачів і безперервне вдосконалення мають важливе значення для вдосконалення системи узагальнення та пом’якшення потенційних упереджень або проблем.
Висновок
Метою проекту було спростити розуміння культури компанії та робочого середовища через численні огляди Glassdoor. Ми успішно створили ефективну систему підсумовування тексту, реалізувавши систематичний метод, який включає збір даних, підготовку та підсумовування тексту. Проект надав цінні ідеї та ключові знання, такі як:
- Система узагальнення тексту надає шукачам роботи, спеціалістам з кадрів, рекрутерам і особам, які приймають рішення, важливу інформацію про компанію. Отримання багатьох відгуків сприяє більш ефективному прийняттю рішень завдяки глибокому розумінню культури компанії, робочого середовища та настроїв співробітників.
- Проект продемонстрував ефективність автоматизованих методів збору та аналізу оглядів Glassdoor за допомогою Selenium для веб-скрейпінгу та NLTK для підсумовування тексту. Автоматизація заощаджує час і зусилля та забезпечує масштабований і систематичний аналіз огляду.
- Проект підкреслив важливість розуміння контексту в точному підсумку рецензій. Такі фактори, як якість даних, суб’єктивні упередження та контекстуальні нюанси, розглядалися за допомогою попередньої обробки даних, аналізу настроїв і методів вилучення ключових слів.
- Система підсумовування тексту, створена в цьому проекті, має реальні додатки для шукачів роботи, кадрових спеціалістів, рекрутерів і команд управління. Він полегшує прийняття обґрунтованих рішень, підтримує бенчмаркінг і роботу з брендом роботодавця, забезпечує ефективну оцінку компаній і надає цінну інформацію для організаційного розвитку.
Уроки, отримані під час проекту, включають важливість якості даних, проблеми суб’єктивних перевірок, важливість контексту під час узагальнення та циклічний характер удосконалення системи. Використовуючи алгоритми машинного навчання та методи обробки природної мови, наша система підсумовування тексту забезпечує ефективний і детальний спосіб отримати інформацію з оглядів Glassdoor.
ЧАСТІ ЗАПИТАННЯ
A. Резюмування тексту з використанням NLP — це підхід, який використовує алгоритми обробки природної мови для створення скорочених підсумків із великої кількості текстових даних. Він спрямований на те, щоб витягти ключові деталі та основні ідеї з оригінального тексту, пропонуючи стислий огляд.
A. Методи НЛП відіграють ключову роль у резюмуванні тексту, сприяючи аналізу та розумінню текстової інформації. Вони дають змогу системі розпізнавати важливі деталі, виділяти ключові фрази та синтезувати важливі елементи, завершуючись послідовними підсумками.
А. Резюмування тексту за допомогою НЛП має кілька переваг. Він прискорює процес засвоєння інформації за рахунок представлення скорочених версій великих документів. Крім того, він забезпечує ефективне прийняття рішень, викладаючи ключові ідеї та спрощуючи обробку даних для покращення аналізу.
A. Ключові методи, які використовуються в резюмуванні тексту на основі НЛП, охоплюють розуміння природної мови, розбір речень, семантичний аналіз, розпізнавання сутностей і алгоритми машинного навчання. Це об’єднання методів дозволяє системі розпізнавати ключові речення, виділяти важливі фрази та будувати зв’язне резюме.
A. Резюмування тексту на основі НЛП є дуже універсальним і адаптованим, знаходячи застосування в різних областях. Він ефективно узагальнює різноманітні текстові джерела, такі як новинні статті, дослідницькі роботи, вміст соціальних мереж, відгуки клієнтів і юридичні документи, що дозволяє аналізувати та витягувати інформацію в різних контекстах.
Медіафайли, показані в цій статті, не належать Analytics Vidhya та використовуються на розсуд Автора.
споріднений
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- EVM Фінанси. Уніфікований інтерфейс для децентралізованих фінансів. Доступ тут.
- Quantum Media Group. ІЧ/ПР посилений. Доступ тут.
- PlatoAiStream. Web3 Data Intelligence. Розширення знань. Доступ тут.
- джерело: https://www.analyticsvidhya.com/blog/2023/06/decoding-glassdoor-nlp-driven-insights-for-informed-decisions/
- : має
- :є
- : ні
- :де
- $UP
- 1
- 10
- 100
- 11
- 12
- 16
- 17
- 20
- 25
- a
- МЕНЮ
- вище
- достаток
- приймає
- доступ
- доступ до
- За
- Накопичуватися
- точність
- точний
- точно
- придбаний
- через
- активно
- адреса
- адресація
- Відрегульований
- чудовий
- просунутий
- просування
- боїться
- проти
- AI
- мета
- Цілі
- насторожений
- Alex
- алгоритм
- алгоритми
- вирівнювати
- Вирівнює
- ВСІ
- полегшувати
- Дозволити
- дозволяє
- Також
- дивовижний
- кількість
- an
- аналіз
- аналітика
- Аналітика Vidhya
- аналізувати
- Аналізуючи
- та
- Анонімно
- будь-який
- застосування
- прикладної
- Застосовувати
- підхід
- відповідний
- ЕСТЬ
- області
- стаття
- статті
- AS
- аспекти
- оцінити
- допомогу
- At
- справжність
- Автоматизований
- автоматично
- автоматизація
- Автоматизація
- доступний
- середній
- AVG
- уникає
- поганий
- Balance
- заснований
- BE
- ставати
- було
- перед тим
- починати
- буття
- нижче
- бенчмаркінг
- користь
- Переваги
- Краще
- між
- зміщення
- упереджений
- упередження
- Великий
- блогатон
- обидва
- брендинг
- ширше
- будувати
- побудований
- але
- button
- by
- обчислювати
- CAN
- кандидат
- кандидатів
- можливості
- захоплення
- кар'єра
- випадок
- випадків
- певний
- проблеми
- складні
- зміна
- заміна
- характеристика
- символи
- перевірка
- Chrome
- клас
- Очищення
- клацання
- клімат
- CO
- код
- КОГЕРЕНТНИЙ
- згуртований
- колеги
- збір
- Колекції
- Колонка
- комбінації
- загальний
- спілкуватися
- Компанії
- компанія
- Культура компанії
- Компанії
- Компенсація
- дотримання
- Компоненти
- всеосяжний
- Занепокоєння
- Проводити
- довіра
- мінуси
- Вважати
- значний
- міркування
- вважається
- беручи до уваги
- консолідація
- будувати
- містить
- зміст
- контекст
- контексти
- контекстуальний
- триває
- безперервний
- сприяти
- перетворення
- Корпоративний
- Counter
- створювати
- створений
- КРІСП
- вирішальне значення
- кульмінацією
- культура
- клієнт
- передовий
- Циклічний
- дані
- якість даних
- Дата
- Дати
- дата, час
- рішення
- Прийняття рішень
- ті що приймають рішення
- рішення
- Декодування
- глибше
- визначаючи
- в захваті
- доставляти
- демонструє
- бажаний
- деталь
- деталі
- розвиненою
- розвивається
- розробка
- валюта
- Відмінності
- різний
- відрізняються
- утруднення
- розсуд
- обговорювати
- розподіл
- Різне
- документація
- робить
- домени
- Не знаю
- водій
- під час
- динамічний
- кожен
- EC
- Ефективний
- фактично
- ефективність
- ефективний
- продуктивно
- зусилля
- зусилля
- елементи
- усунутий
- ще
- працевлаштований
- Співробітник
- Задоволення співробітників
- співробітників
- роботодавців
- зайнятість
- уповноважувати
- включіть
- дозволяє
- дозволяє
- охоплювати
- охоплює
- охоплюючий
- заохочення
- зачеплення
- інженер
- Машинобудування
- англійська
- підвищення
- забезпечувати
- гарантує
- забезпечення
- суб'єкта
- Навколишнє середовище
- помилки
- істотний
- встановити
- Ефір (ETH)
- етичний
- етика
- оцінювати
- оцінка
- Event
- Кожен
- все
- приклад
- відмінно
- Крім
- Розширювати
- прискорює
- досвід
- Досліди
- дослідити
- досліджує
- виражений
- обширний
- витяг
- видобуток
- Виписки
- стикаються
- фасилітувати
- полегшує
- сприяння
- фактори
- ярмарок
- підроблений
- сім'я
- зворотний зв'язок
- фільтрувати
- Фільтри
- виявлення
- Фірма
- Сфокусувати
- слідує
- для
- формат
- пощастило
- Рамки
- частота
- часто
- від
- розчарування
- Повний
- повністю
- функція
- функціональні можливості
- Основи
- далі
- Крім того
- Отримувати
- збирати
- збір
- Загальне
- породжувати
- генерується
- генерує
- покоління
- отримати
- даний
- Glassdoor
- Цілі
- добре
- схопити
- великий
- Рости
- Зростання
- керівництво
- рука
- обробляти
- Обробка
- практичний
- щасливий
- Harmony
- Запрягання
- Мати
- здоров'я
- сильно
- допомога
- тут
- Високий
- Виділіть
- дуже
- тримає
- цілісний
- будинок
- житло
- Як
- How To
- Однак
- hr
- HTTPS
- людина
- ЛЮДСЬКІ РЕСУРСИ
- i
- ідеї
- ідентифікувати
- if
- надзвичайно
- здійснювати
- реалізації
- наслідки
- імпорт
- значення
- важливо
- імпорт
- вражений
- поліпшений
- поліпшення
- поліпшення
- in
- включати
- includes
- У тому числі
- включення
- індекс
- індивідуальний
- осіб
- повідомити
- інформація
- вилучення інформації
- інформативний
- повідомив
- за своєю суттю
- ініціювати
- ініціативи
- вхід
- розуміння
- Інтеграція
- інтеграція
- цілісність
- взаємодіючих
- цікавий
- внутрішній
- інтерпретація
- в
- безцінний
- залучений
- включає в себе
- питання
- питання
- IT
- ітерація
- ЙОГО
- робота
- Вакансії
- шукають роботу
- приєднатися
- судження
- ключ
- ключі
- знання
- відсутність
- ландшафт
- мова
- Керівництво
- провідний
- вчений
- вивчення
- легальний
- довжина
- менше
- Уроки
- Уроки, витягнуті
- рівні
- Важіль
- використання
- libraries
- бібліотека
- життя
- як
- обмеження
- недоліки
- список
- списки
- розташування
- програш
- серія
- машина
- навчання за допомогою машини
- головний
- збереження
- зробити
- Робить
- управляти
- управління
- Маніпуляція
- манера
- багато
- ринок
- Може..
- сенс
- заходи
- механізми
- Медіа
- психічний
- Психічне здоров'я
- згаданий
- метод
- методика
- прискіпливо
- Метрика
- Пом'якшити
- пом’якшення
- модель
- Моделі
- Модулі
- Модулі
- моніторинг
- більше
- Більше того
- найбільш
- переміщення
- багато
- множення
- повинен
- ім'я
- Природний
- Природна мова
- Обробка природних мов
- природа
- Переміщення
- навігація
- необхідно
- Необхідність
- негативний
- новини
- наступний
- nlp
- немає
- шум
- Примітно,
- номер
- численний
- мета
- цілей
- отримувати
- отриманий
- трапляються
- of
- пропонувати
- запропонований
- пропонує
- Пропозиції
- on
- один раз
- тільки
- операції
- Думки
- Можливості
- Оптимізувати
- or
- порядок
- організація
- організаційної
- організації
- оригінал
- Інше
- наші
- Результати
- план
- вихід
- над
- загальний
- огляд
- яка перебуває у власності
- сторінка
- Нумерація сторінок
- панди
- документи
- частина
- шлях
- Платити
- Люди
- відсоток
- періодичний
- надбавки
- перспектива
- фаза
- фрази
- основний
- платформа
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- Play
- задоволений
- точок
- бідні
- популярний
- положення
- позитивний
- потенціал
- потенційно
- Практичний
- підготовка
- підготовка
- наявність
- представити
- переважаючий
- первинний
- Головний
- друк
- Pro
- Проблема
- процес
- оброблена
- обробка
- професіонали
- прогресія
- проект
- проектів
- PROS
- перспективи
- забезпечувати
- за умови
- забезпечує
- забезпечення
- громадськість
- опублікований
- цілей
- Python
- якість
- швидко
- діапазон
- швидше
- рейтинг
- рейтинги
- читання
- Реальний світ
- реального часу
- насправді
- визнання
- визнавати
- набір
- повторювані
- відображати
- про
- регулярний
- пов'язаний
- актуальність
- доречний
- надійність
- надійний
- покладатися
- віддалений
- видаляти
- Вилучено
- видалення
- Знаменитий
- подання
- репутація
- Вимога
- дослідження
- рішення
- ресурс
- в результаті
- результати
- повертати
- огляд
- рецензування
- Відгуки
- міцний
- Роль
- Salesforce
- задоволення
- Незадоволений
- масштабовані
- сценарій
- сценарії
- наука
- рахунок
- безліч
- рахунок
- вишкрібання
- безшовні
- побачити
- пошук
- сегментація
- відокремлені
- вибір
- пропозиція
- настрій
- окремий
- окремо
- комплект
- набори
- установка
- установка
- кілька
- Поділитись
- приголомшений
- показаний
- значення
- значний
- істотно
- спростити
- один
- навички
- сон
- сповільнювати
- менше
- більш гладкий
- соціальна
- соціальні медіа
- Софтвер
- Інженер-програміст
- розробка програмного забезпечення
- деякі
- Джерела
- конкретний
- конкретно
- Витрати
- розкол
- зацікавлених сторін
- стандартів
- Заява
- заходи
- зберігати
- Стратегічний
- стратегії
- Стратегія
- раціоналізувати
- сильні сторони
- рядок
- сильний
- боротьба
- стиль
- тема
- наступні
- Згодом
- істотний
- Успішно
- такі
- підходящий
- підсумовувати
- РЕЗЮМЕ
- підтримка
- підтримуючий
- Опори
- швидко
- система
- Мета
- цільове
- Завдання
- завдання
- команди
- технології
- технічно
- методи
- тимчасовий
- територія
- ніж
- Що
- Команда
- інформація
- їх
- Їх
- потім
- Там.
- отже
- Ці
- вони
- це
- ретельно
- в захваті
- через
- час
- до
- сьогоднішній
- Токенізація
- занадто
- Інструментарій
- інструменти
- топ
- Кращі 10
- топ 5
- Усього:
- до
- прозорість
- надійність
- намагатися
- два
- ui
- розуміти
- розуміння
- вживати
- створеного
- до
- незвичайний
- Updates
- на
- терміново
- us
- використання
- використовуваний
- користувач
- зручно
- користувачі
- використання
- використовувати
- використовує
- перевірка достовірності
- Цінний
- Цінності
- оцінювання
- різний
- величезний
- різнобічний
- вид
- точки зору
- обсяг
- хоче
- було
- шлях..
- we
- недоліки
- Web
- веб-вискоблювання
- webp
- були
- Що
- Що таке
- Чи
- який
- ВООЗ
- широкий
- Широкий діапазон
- волі
- з
- в
- без
- слово
- слова
- Work
- робочий
- робочий
- ще
- врожайність
- ви
- вашу
- зефірнет