Дослідження останніх кількох років показали, що моделі машинного навчання (ML) вразливі до змагальні входи, де супротивник може створювати вхідні дані для стратегічної зміни результатів моделі (в класифікація зображень, розпізнавання мовиабо виявлення шахрайства). Наприклад, уявіть, що ви розгорнули модель, яка ідентифікує ваших співробітників на основі зображень їхніх облич. Як показано в офіційному документі Співучасть у злочині: реальні та приховані атаки на найсучаснішу систему розпізнавання обличчя, зловмисники можуть застосувати тонкі, але ретельно розроблені зміни до свого зображення та обдурити модель, щоб ідентифікувати їх як інших співробітників. Очевидно, що такі ворожі дії, особливо якщо їх є значна кількість, можуть мати руйнівний вплив на бізнес.
В ідеалі ми хочемо виявляти щоразу, коли в модель надсилається вхідні дані, щоб кількісно визначити, як вхідні дані впливають на вашу модель і бізнес. З цією метою широкий клас методів аналізує окремі вхідні дані моделі для перевірки змагальності. Однак активні дослідження змагального ML призвели до все більш складних змагальних вводів, багато з яких, як відомо, роблять виявлення неефективним. Причина цього недоліку полягає в тому, що важко зробити висновок з індивідуального введення щодо того, чи є воно змагальним чи ні. З цією метою останній клас методів зосереджений на перевірках на рівні розподілу шляхом аналізу кількох вхідних даних одночасно. Ключова ідея цих нових методів полягає в тому, що врахування кількох вхідних даних одночасно забезпечує потужніший статистичний аналіз, який неможливий з окремими вхідними даними. Однак перед обличчям рішучого супротивника, який глибоко знає модель, навіть ці вдосконалені методи виявлення можуть виявитися невдалими.
Однак ми можемо перемогти навіть цих рішучих супротивників, надавши методам захисту додаткову інформацію. Зокрема, замість аналізу вхідних даних моделі аналіз латентних уявлень, зібраних із проміжних рівнів глибокої нейронної мережі, значно посилює захист.
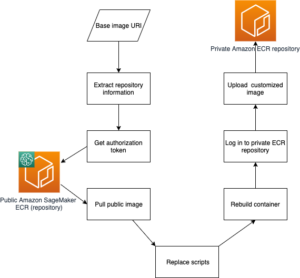
У цій публікації ми розповімо вам, як виявити змагальні дії за допомогою Монітор моделі Amazon SageMaker та Налагоджувач Amazon SageMaker для моделі класифікації зображень, розміщеної на Amazon SageMaker.
Щоб відтворити різні кроки та результати, перелічені в цьому дописі, клонуйте репозиторій виявлення змагальних зразків за допомогою Sagemaker у свій екземпляр блокнота Amazon SageMaker і запустіть блокнот.
Виявлення змагальності
Ми покажемо вам, як виявляти протилежні введення за допомогою уявлень, зібраних із глибокої нейронної мережі. Наступні чотири зображення показують оригінальне навчальне зображення ліворуч (взяте з набору даних Tiny ImageNet) і три зображення, створені атакою Projected Gradient Descent (PGD) [1] з різними параметрами збурення ϵ. Тут використана модель ResNet18. Параметр ϵ визначає кількість протилежного шуму, доданого до зображень. Оригінальне зображення (ліворуч) правильно передбачено як клас 67 (goose). Конкурентно модифіковані зображення 2, 3 і 4 неправильно передбачувано як клас 51 (mantis) за моделлю ResNet18. Ми також бачимо, що зображення, створені з малим ϵ, перцепційно не відрізняються від оригінального вхідного зображення.

Далі ми створюємо набір звичайних і змагальних зображень і використовуємо t-розподілене стохастичне вбудовування сусідів (t-SNE [2]), щоб візуально порівняти їхні розподіли. t-SNE — це метод зменшення розмірності, який відображає високовимірні дані у 2- або 3-вимірний простір. Кожна точка даних на наступному зображенні представляє вхідне зображення. Помаранчеві точки даних представляють звичайні вхідні дані, взяті з тестового набору, а сині точки даних вказують на відповідні змагальні зображення, створені з епсилоном 0.003. Якщо звичайні та змагальні вхідні дані розрізняються, тоді ми очікуємо окремих кластерів у візуалізації t-SNE. Оскільки обидва належать до одного кластеру, це означає, що метод виявлення, який зосереджується виключно на змінах у розподілі вхідних даних моделі, не може розрізнити ці вхідні дані.

Давайте ближче розглянемо представлення шарів, створені різними шарами в моделі ResNet18. ResNet18 складається з 18 шарів; на наступному зображенні ми візуалізуємо вкладення t-SNE для представлень для шести з цих шарів.

Як показано на попередньому малюнку, природні та змагальні вхідні дані стають більш помітними для більш глибоких рівнів моделі ResNet18.
На основі цих спостережень ми використовуємо статистичний метод, який вимірює відмінність за допомогою перевірки гіпотез. Метод складається з a двопробний тест використання максимальна середня розбіжність (ММД). MMD — це метрика на основі ядра для вимірювання подібності між двома розподілами, що генерують дані. Тест із двома вибірками бере два набори, які містять вхідні дані двох розподілів, і визначає, чи є ці розподіли однаковими. Ми порівнюємо розподіл вхідних даних, що спостерігаються в навчальних даних, і порівнюємо його з розподілом вхідних даних, отриманих під час висновку.
Наш метод використовує ці дані для оцінки p-значення за допомогою MMD. Якщо p-значення перевищує поріг значущості для користувача (у нашому випадку 5%), ми робимо висновок, що обидва розподіли відрізняються. Порогове значення налаштовує компроміс між помилковими позитивними та помилковими негативними результатами. Вищий поріг, наприклад 10%, зменшує частоту помилкових негативних результатів (є менше випадків, коли обидва розподіли були різними, але тест не вказав на це). Однак це також призводить до більшої кількості помилкових спрацьовувань (тест показує, що обидва розподіли відрізняються, навіть якщо це не так). З іншого боку, нижчий поріг, наприклад 1%, призводить до меншої кількості помилкових позитивних результатів, але більшої кількості помилкових негативних результатів.
Замість того, щоб застосовувати цей метод виключно до необроблених вхідних даних моделі (зображень), ми використовуємо приховані представлення, створені проміжними шарами нашої моделі. Щоб врахувати його ймовірнісний характер, ми застосовуємо перевірку гіпотези 100 разів на 100 випадково вибраних природних вхідних даних і 100 випадково вибраних змагальних вхідних даних. Потім ми повідомляємо рівень виявлення як відсоток тестів, які призвели до події виявлення відповідно до нашого 5% порогу значущості. Вищий рівень виявлення є сильнішим свідченням того, що два розподіли різні. Ця процедура дає нам такі показники виявлення:
- Шар 1: 3%
- Шар 4: 7%
- Шар 8: 84%
- Шар 12: 95%
- Шар 14: 100%
- Шар 15: 100%
У початкових шарах рівень виявлення досить низький (менше 10%), але зростає до 100% у більш глибоких шарах. Використовуючи статистичний тест, метод може впевнено виявляти конкурентні входи на більш глибоких рівнях. Часто достатньо просто використовувати представлення, створені передостаннім шаром (останнім шаром перед шаром класифікації в моделі). Для більш складних змагальних вхідних даних корисно використовувати представлення з інших рівнів і агрегувати показники виявлення.
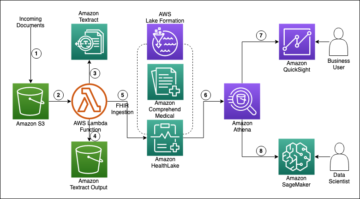
Огляд рішення
У попередньому розділі ми бачили, як виявляти суперечливі дані за допомогою представлень із передостаннього рівня. Далі ми покажемо, як автоматизувати ці тести на SageMaker за допомогою монітора моделі та відладчика. Для цього прикладу ми спочатку навчаємо модель класифікації зображень ResNet18 на крихітному наборі даних ImageNet. Далі ми розгортаємо модель на SageMaker і створюємо спеціальний розклад монітора моделі, який виконує статистичний тест. Після цього ми запускаємо логічний висновок зі звичайними та змагальними вхідними даними, щоб побачити, наскільки ефективним є метод.
Захоплення тензорів за допомогою Debugger
Під час навчання моделі ми використовуємо Debugger для захоплення представлень, створених передостаннім шаром, які використовуються пізніше для отримання інформації про розподіл звичайних вхідних даних. Налагоджувач — це функція SageMaker, яка дає змогу отримувати та аналізувати інформацію, таку як параметри моделі, градієнти та активації під час навчання моделі. Ці параметри, градієнти та тензори активації завантажуються в Служба простого зберігання Amazon (Amazon S3), поки триває навчання. Ви можете налаштувати правила, які аналізують їх на предмет таких проблем, як надмірне припасування та зникнення градієнтів. Для нашого випадку використання ми хочемо захопити лише передостанній шар моделі (.*avgpool_output) і результати моделі (прогнози). Ми вказуємо конфігурацію хука Debugger, яка визначає регулярний вираз для представлень шару, які потрібно зібрати. Ми також вказуємо a save_interval який наказує Debugger збирати ці дані під час фази перевірки кожні 100 проходів вперед. Перегляньте наступний код:
Запустіть навчання SageMaker
Ми передаємо конфігурацію Debugger в оцінювач SageMaker і починаємо навчання:
Розгорніть модель класифікації зображень
Після завершення навчання моделі ми розгортаємо модель як кінцеву точку на SageMaker. Ми вказуємо an сценарій висновку що визначає model_fn та transform_fn функції. Ці функції визначають спосіб завантаження моделі та спосіб попередньої обробки вхідних даних, щоб виконати висновок моделі. Для нашого випадку використання ми ввімкнули Debugger для захоплення відповідних даних під час висновку. В model_fn ми вказуємо хук Debugger і a save_config який визначає, що для кожного запиту на висновок записуються вхідні дані моделі (зображення), вихідні дані моделі (прогнози) і передостанній рівень (.*avgpool_output). Потім реєструємо гачок на моделі. Перегляньте наступний код:
Тепер ми розгортаємо модель, яку ми можемо зробити з блокнота двома способами. Ми можемо або подзвонити pytorch_estimator.deploy() або створіть модель PyTorch, яка вказує на файли артефактів моделі в Amazon S3, створені під час навчального завдання SageMaker. У цій публікації ми робимо останнє. Це дозволяє нам передавати змінні середовища в контейнер Docker, створений і розгорнутий SageMaker. Нам потрібна змінна середовища tensors_output щоб вказати сценарію, куди завантажувати тензори, які збирає SageMaker Debugger під час висновку. Перегляньте наступний код:
Далі ми розгортаємо предиктор на екземплярі типу ml.m5.xlarge:
Створіть власний розклад монітора моделі
Коли кінцева точка запущена та працює, ми створюємо налаштований розклад монітора моделі. Це Завдання обробки SageMaker який виконується з періодичним інтервалом (наприклад, щогодини чи щодня) і аналізує дані висновків. Model Monitor надає попередньо налаштований контейнер, який аналізує та виявляє дрейф даних. У нашому випадку ми хочемо налаштувати його для отримання даних Debugger і запуску двовибіркового тесту MMD на отриманих представленнях шару.
Щоб налаштувати його, ми спочатку визначимо об’єкт Model Monitor, який визначає, на якому типі екземпляра будуть виконуватися ці завдання, і розташування нашого спеціального контейнера Model Monitor:
Ми хочемо виконувати цю роботу погодинно, тому ми вказуємо CronExpressionGenerator.hourly() і вихідні місця, куди завантажуються результати аналізу. Для цього нам потрібно визначити ProcessingOutput для результату обробки SageMaker:
Давайте розглянемо докладніше, що працює в нашому спеціальному контейнері Model Monitor. Ми створюємо сценарій оцінки, який завантажує дані, зібрані Debugger. Ми також створюємо a пробний об'єкт, що дозволяє нам отримувати доступ, запитувати та фільтрувати дані, збережені Debugger. За допомогою пробного об’єкта ми можемо повторювати кроки, збережені під час фаз висновку та навчання trial.steps(mode).
Спочатку ми отримуємо вихідні дані моделі (trial.tensor("ResNet_output_0")), а також передостанній шар (trial.tensor_names(regex=".*avgpool_output")). Ми робимо це для етапів навчання та підтвердження (modes.EVAL та modes.PREDICT). Тензори з фази перевірки служать оцінкою нормального розподілу, який ми потім використовуємо для порівняння розподілу даних висновку. Ми створили клас ЛАДІС (Виявлення змагальних розподілів вхідних даних за допомогою пошарової статистики). Цей клас надає відповідні функціональні можливості для виконання тесту з двома зразками. Він бере список тензорів із фаз висновку та перевірки та запускає двовибірковий тест. Він повертає коефіцієнт виявлення, який є значенням від 0 до 100%. Чим вище значення, тим більша ймовірність того, що дані висновку мають інший розподіл. Крім того, ми обчислюємо оцінку для кожного зразка, який вказує на те, наскільки ймовірно, що зразок є змагальним, і записуємо 100 найкращих зразків, щоб користувачі могли їх перевірити. Перегляньте наступний код:
Перевірте протилежність
Тепер, коли розгорнуто наш спеціальний розклад монітора моделі, ми можемо зробити деякі висновки.
Спочатку ми працюємо з даними з набору затриманих, а потім із змагальними вхідними даними:
Потім ми можемо перевірити дисплей монітора моделі Студія Amazon SageMaker або використовувати Amazon CloudWatch журнали, щоб побачити, чи виявлено проблему.

Далі ми використовуємо вхідні дані проти моделі, розміщеної на SageMaker. Ми використовуємо тестовий набір даних Tiny ImageNet і застосовуємо атаку PGD, яка вносить збурення на рівні пікселів, так що модель не розпізнає правильні класи. На наступних зображеннях лівий стовпець показує два вихідних тестових зображення, середній стовпець показує їхні протилежно збурені версії, а правий стовпець показує різницю між обома зображеннями.

Тепер ми можемо перевірити стан монітора моделі та побачити, що деякі образи висновку були взяті з іншого дистрибутива.

Результати та дії користувача
Спеціальне завдання «Монітор моделі» визначає бали для кожного запиту на висновок, що вказує на те, наскільки ймовірно вибірка є змагальною відповідно до тесту MMD. Ці оцінки збираються для всіх запитів на висновок. Їхня оцінка з відповідним номером кроку Debugger записується у файл JSON і завантажується в Amazon S3. Після завершення завдання моніторингу моделі ми завантажуємо файл JSON, отримуємо номери кроків і використовуємо Debugger для отримання відповідних вхідних даних моделі для цих кроків. Це дозволяє нам перевірити зображення, які були виявлені як суперечливі.
У наведеному нижче блоці коду відображаються перші два зображення, визначені як найімовірніші змагальні:
У нашому прикладі тестового запуску ми отримуємо наступний результат. Зображення медузи було неправильно передбачено як апельсин, а зображення верблюда як панда. Очевидно, що модель не впоралася з цими вхідними даними і навіть не передбачила подібний клас зображень, як-от золота рибка чи кінь. Для порівняння ми також показуємо відповідні натуральні зразки з тестового набору з правого боку. Ми можемо помітити, що випадкові збурення, внесені зловмисником, добре помітні на фоні обох зображень.


Спеціальне завдання Model Monitor публікує частоту виявлення в CloudWatch, щоб ми могли досліджувати, як ця частота змінювалася з часом. Значна зміна між двома точками даних може означати, що зловмисник намагався обдурити модель у певний період часу. Крім того, ви також можете побудувати графік кількості запитів на висновок, які обробляються в кожному завданні монітора моделі, і базового рівня виявлення, який обчислюється за набором даних перевірки. Базова ставка зазвичай близька до 0 і слугує лише як показник порівняння.
На наступному знімку екрана показано показники, згенеровані нашими тестовими прогонами, під час яких три завдання моніторингу моделі виконувалися протягом 3 годин. Кожне завдання одночасно обробляє приблизно 200–300 запитів на висновок. Рівень виявлення становить 100% між 5:00 і 6:00, а потім падає.

Крім того, ми також можемо перевіряти розподіл уявлень, створених проміжними рівнями моделі. За допомогою Debugger ми можемо отримати доступ до даних із фази перевірки навчальної роботи та тензорів із фази висновку, а також використовувати t-SNE для візуалізації їх розподілу для певних прогнозованих класів. Перегляньте наступний код:
У нашому тестовому випадку ми отримуємо наступну візуалізацію t-SNE для другого класу зображень. Ми можемо помітити, що змагальні зразки групуються інакше, ніж природні.

Підсумки
У цьому дописі ми показали, як використовувати тест із двох вибірок із використанням максимальної середньої розбіжності для виявлення змагальних вхідних даних. Ми продемонстрували, як можна розгорнути такі механізми виявлення за допомогою Debugger і Model Monitor. Цей робочий процес дозволяє вам відстежувати ваші моделі, розміщені на SageMaker, у великому масштабі та автоматично виявляти суперечливі дані. Щоб дізнатися більше про це, перегляньте наш GitHub репо.
посилання
[1] Александер Мадрі, Александар Макелов, Людвіг Шмідт, Дімітріс Ціпрас та Адріан Владу. До моделей глибокого навчання, стійких до агресивних атак. в Міжнародна конференція з навчальних представництв, 2018.
[2] Лоуренс ван дер Маатен і Джеффрі Хінтон. Візуалізація даних за допомогою t-SNE. Journal of Machine Learning Research, 9:2579–2605, 2008. URL http://www.jmlr.org/papers/v9/vandermaaten08a.html.
Про авторів
 Наталі Раушмайр є старшим прикладним науковцем у AWS, де вона допомагає клієнтам розробляти програми глибокого навчання.
Наталі Раушмайр є старшим прикладним науковцем у AWS, де вона допомагає клієнтам розробляти програми глибокого навчання.
 Їгіткан Кая є студентом п’ятого курсу аспірантури в Університеті Меріленда та стажером прикладного вченого в AWS, який працює над безпекою машинного навчання та застосуванням машинного навчання для безпеки.
Їгіткан Кая є студентом п’ятого курсу аспірантури в Університеті Меріленда та стажером прикладного вченого в AWS, який працює над безпекою машинного навчання та застосуванням машинного навчання для безпеки.
 Білал Зафар є вченим-прикладником в AWS, працює над справедливістю, зрозумілістю та безпекою в машинному навчанні.
Білал Зафар є вченим-прикладником в AWS, працює над справедливістю, зрозумілістю та безпекою в машинному навчанні.
 Сергул Айдоре є старшим прикладним науковим співробітником AWS, який працює над конфіденційністю та безпекою в машинному навчанні
Сергул Айдоре є старшим прикладним науковим співробітником AWS, який працює над конфіденційністю та безпекою в машинному навчанні
- Coinsmart. Найкраща в Європі біржа біткойн та криптовалют.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. БЕЗКОШТОВНИЙ ДОСТУП.
- CryptoHawk. Альткойн Радар. Безкоштовне випробування.
- Джерело: https://aws.amazon.com/blogs/machine-learning/detect-adversarial-inputs-using-amazon-sagemaker-model-monitor-and-amazon-sagemaker-debugger/
- "
- 10
- 100
- 67
- 9
- МЕНЮ
- доступ
- За
- рахунки
- активний
- Додатковий
- просунутий
- ВСІ
- Amazon
- кількість
- аналіз
- застосування
- Застосування
- приблизно
- AWS
- фон
- Базова лінія
- основа
- ставати
- буття
- Блокувати
- бізнес
- call
- захоплення
- випадків
- зміна
- Перевірки
- клас
- класів
- класифікація
- ближче
- код
- збирати
- Колонка
- обчислення
- конференція
- конфігурація
- Контейнер
- сприяти
- створений
- Злочин
- виготовлений на замовлення
- Клієнти
- дані
- глибше
- оборони
- продемонстрований
- розгортання
- розгорнути
- виявлено
- Виявлення
- розвивати
- різний
- важкий
- дисплей
- розподіл
- Docker
- Ні
- Ефективний
- співробітників
- включіть
- Кінцева точка
- Навколишнє середовище
- оцінити
- Event
- приклад
- очікувати
- Face
- особи
- особливість
- Рисунок
- Перший
- фокусується
- після
- Вперед
- знайдений
- FRAME
- Повний
- функція
- далі
- породжує
- буде
- великий
- допомагає
- тут
- вище
- Як
- How To
- HTTPS
- ідея
- зображення
- Impact
- індекс
- індивідуальний
- інформація
- вхід
- дослідити
- питання
- питання
- IT
- робота
- Джобс
- журнал
- ключ
- знання
- відомий
- етикетки
- великий
- УЧИТЬСЯ
- вивчення
- Led
- рівень
- Ймовірно
- список
- Перераховані
- розташування
- місць
- машина
- навчання за допомогою машини
- карти
- Меріленд
- Метрика
- MIT
- ML
- модель
- Моделі
- монітор
- моніторинг
- більше
- найбільш
- множинний
- Природний
- природа
- мережу
- шум
- нормальний
- ноутбук
- номер
- номера
- Інше
- відсоток
- фаза
- точка
- це можливо
- потужний
- передбачати
- прогноз
- Прогнози
- представити
- недоторканність приватного життя
- Конфіденційність та безпека
- процеси
- виробляти
- Вироблений
- забезпечує
- забезпечення
- ставки
- Сировина
- визнавати
- реєструвати
- регулярний
- доречний
- звітом
- Сховище
- запросити
- запитів
- дослідження
- результати
- Умови повернення
- Правила
- прогін
- біг
- шкала
- вчений
- безпеку
- обраний
- комплект
- значний
- аналогічний
- простий
- SIX
- невеликий
- So
- деякі
- складний
- Простір
- конкретно
- старт
- впроваджений
- статистичний
- статистика
- статистика
- Статус
- зберігання
- студент
- тест
- Тестування
- Тести
- через
- час
- топ
- до
- Навчання
- суд
- університет
- us
- використання
- користувачі
- зазвичай
- значення
- видимий
- візуалізації
- Вразливий
- Що
- Чи
- в той час як
- Whitepaper
- Вікіпедія
- робочий
- б
- рік
- років