Амазонка Афіна це безсерверна інтерактивна служба запитів, яка дозволяє легко аналізувати дані в Служба простого зберігання Amazon (Amazon S3) і понад 25 джерел даних, включаючи локальні джерела даних або інші хмарні системи, що використовують SQL або Python. Вбудовані можливості Athena включають запити для геопросторові дані; наприклад, ви можете підрахувати кількість землетрусів у кожному каліфорнійському окрузі. Одним із недоліків аналізу на рівні округу є те, що він може дати вам оманливе уявлення про те, в яких частинах Каліфорнії було найбільше землетрусів. Це тому, що округи не однакові за розміром; в окрузі може бути більше землетрусів просто тому, що це велика країна. Що, якби нам потрібна ієрархічна система, яка дозволяла б збільшувати та зменшувати масштаб для агрегування даних щодо різних географічних областей однакового розміру?
У цій публікації ми представляємо рішення, яке використовує Гексагональний ієрархічний просторовий індекс Uber (H3) щоб розділити земну кулю на шестикутники однакового розміру. Потім ми використовуємо Athena визначена користувачем функція (UDF), щоб визначити, у якому шестикутнику відбувався кожен історичний землетрус. Оскільки шестикутники мають однакові розміри, цей аналіз дає чітке уявлення про те, де зазвичай відбуваються землетруси.
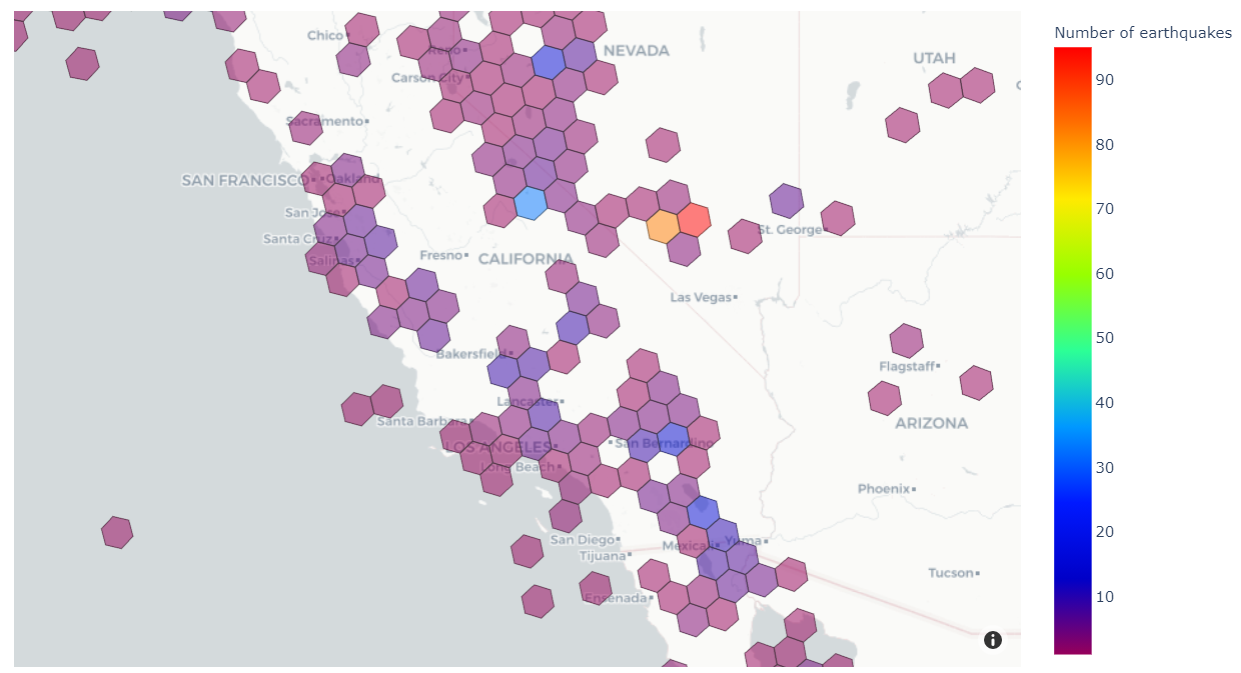
Наприкінці ми створимо візуалізацію, подібну до наведеної нижче, яка показує кількість історичних землетрусів у різних областях західної частини США.
H3 ділить земну кулю на рівні правильні шестикутники. Кількість шестикутників залежить від обраного дозвіл, яке може варіюватися від 0 (122 шестикутники, кожен з довжиною ребра приблизно 1,100 км) до 15 (569,707,381,193,162 50 3 XNUMX XNUMX шестикутника, кожен з довжиною ребра приблизно XNUMX см). HXNUMX дозволяє аналізувати на рівні області, і кожна область має однаковий розмір і форму.
Огляд рішення
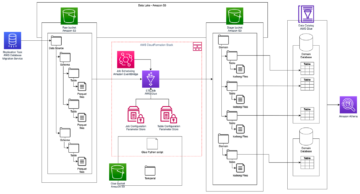
Розчин розширюється Вбудовані геопросторові можливості Athena шляхом створення UDF на основі AWS Lambda. Нарешті, ми використовуємо an Amazon SageMaker ноутбук для запуску запитів Athena, які відображаються як a хороплетна карта. Наступна діаграма ілюструє цю архітектуру.

Наскрізна архітектура така:
- CSV-файл історичних землетрусів завантажується в сегмент S3.
- An Клей AWS зовнішня таблиця створюється на основі CSV землетрусу.
- Лямбда-функція обчислює шестикутники H3 для параметрів (широти, довготи, роздільної здатності). Функція написана на Java і може бути викликана як UDF за допомогою запитів у Athena.
- Блокнот SageMaker використовує AWS SDK для панд пакет для виконання SQL-запиту в Athena, включаючи UDF.
- Пакет Plotly Express створює хороплетну карту кількості землетрусів у кожному шестикутнику.
Передумови
У цій публікації ми використовуємо Athena для читання даних в Amazon S3 за допомогою таблиці, визначеної в каталозі даних AWS Glue, пов’язаному з нашим набором даних про землетруси. Що стосується дозволів, існує дві основні вимоги:
Налаштуйте Amazon S3
Першим кроком є створення сегмента S3 для зберігання набору даних землетрусів, як показано нижче:
- Завантажте CSV-файл історичних землетрусів з GitHub.
- На консолі Amazon S3 виберіть Відра у навігаційній панелі.
- Вибирати Створити відро.
- для Назва відра, введіть глобально унікальну назву для свого сегмента даних.
- Вибирати Створити папкуі введіть назву папки
earthquakes. - Завантажте файл у сегмент S3. У цьому прикладі ми завантажуємо
earthquakes.csvфайл доearthquakesпрефікс.

Створіть таблицю в Афіні
Перейдіть до консолі Athena, щоб створити таблицю. Виконайте наступні дії:
- На консолі Athena виберіть Запит-редактор.
- Виберіть потрібну робочу групу за допомогою спадного меню.

- У редакторі SQL використовуйте такий код, щоб створити таблицю в базі даних за замовчуванням:
Створіть лямбда-функцію для UDF Athena
Докладне пояснення того, як створити Athena UDF, див Запити за допомогою визначених користувачем функцій. Ми використовуємо Java 11 і Прив’язка Uber H3 Java для створення H3 UDF. Забезпечуємо реалізацію ОДС на GitHub.
Є кілька варіантів для розгортання UDF за допомогою Lambda. У цьому прикладі ми використовуємо Консоль управління AWS. Для виробничих розгортань ви, ймовірно, захочете використовувати інфраструктуру як код, наприклад Набір хмарних розробок AWS (AWS CDK). Інформацію про те, як використовувати AWS CDK для розгортання функції Lambda, див сховище коду проекту. Іншим можливим варіантом розгортання є використання AWS Serverless Application Repository (SAR).
Розгорніть UDF
Розгорніть UDF прив’язки Uber H3 за допомогою консолі таким чином:
- Перейдіть до бінарного каталогу в GitHub репозиторій і завантажити
aws-h3-athena-udf-*.jarна ваш локальний робочий стіл. - Створіть лямбда-функцію під назвою
H3UDFз Час виконання встановлений в Java 11 (Corretto) та архітектура встановлений в x86_64.
- Завантажте
aws-h3-athena-udf*.jarфайлу.
- Змініть назву обробника на
com.aws.athena.udf.h3.H3AthenaHandler.
- У Загальна конфігурація розділ, вибрати Редагувати щоб встановити пам'ять функції Lambda на 4096 МБ, що є обсягом пам'яті, який підходить для наших прикладів. Можливо, вам знадобиться збільшити розмір пам’яті для ваших випадків використання.

Використовуйте функцію Lambda як UDF Athena
Після створення функції Lambda ви готові використовувати її як UDF. На наступному знімку екрана показано деталі функції.

Тепер ви можете використовувати функцію як Athena UDF. На консолі Athena виконайте таку команду:

Команда udf/examples папка в GitHub репозиторій містить більше прикладів запитів Athena.
Розробка UDF
Тепер, коли ми показали вам, як розгортати UDF для Athena за допомогою Lambda, давайте глибше заглибимося в те, як розробляти такі типи UDF. Як пояснив в Запити за допомогою визначених користувачем функцій, щоб розробити UDF, нам спочатку потрібно реалізувати клас, який успадковує UserDefinedFunctionHandler. Потім нам потрібно реалізувати функції всередині класу, які можна використовувати як UDF Athena.
Ми починаємо реалізацію UDF з визначення класу H3AthenaHandler що успадковує UserDefinedFunctionHandler. Потім ми реалізуємо функції, які діють як оболонки функцій, визначених у Прив’язка Uber H3 Java. Ми переконалися, що всі функції, визначені в H3 Java binding API, зіставлені, щоб їх можна було використовувати в Athena як UDF. Наприклад, ми наносимо карту lat_lng_to_cell_address функція, використана в попередньому прикладі до latLngToCell прив’язки H3 Java.
Окрім виклику прив’язки Java, багато функцій у H3AthenaHandler перевірити, чи вхідний параметр є нульовим. Перевірка на нуль корисна, оскільки ми не припускаємо, що вхідні дані не є нульовими. На практиці нульові значення для індексу або адреси H3 не є чимось незвичайним.
Наступний код показує реалізацію get_resolution функція:
Деякі функції H3 API, наприклад cellToLatLng повертати List<Double> з двох елементів, де перший елемент – це широта, а другий – довгота. H3 UDF, який ми реалізуємо, забезпечує функцію, яка повертає загальновідомий текст (WKT) представництво. Наприклад, ми надаємо cell_to_lat_lng_wkt, який повертає a Point Рядок WKT замість List<Double>. Потім ми можемо використати результат cell_to_lat_lng_wkt у поєднанні з вбудованою просторовою функцією Athena ST_GeometryFromText наступним чином:
Athena UDF підтримує лише скалярні типи даних і не підтримує вкладені типи. Однак деякі API H3 повертають вкладені типи. Наприклад, polygonToCells функція в H3 приймає a List<List<List<GeoCoord>>>. Наша реалізація polygon_to_cells ОДС отримує а Polygon WKT замість цього. Нижче показано приклад запиту Athena з використанням цього UDF:
Для візуалізації використовуйте блокноти SageMaker
A Блокнот SageMaker це обчислювальний екземпляр керованого машинного навчання, який запускає програму для ноутбука Jupyter. У цьому прикладі ми будемо використовувати блокнот SageMaker, щоб написати та запустити наш код для візуалізації наших результатів, але якщо ваш варіант використання включає Apache Spark, використовуйте Amazon Athena для Apache Spark був би чудовим вибором. Поради щодо найкращих методів безпеки для SageMaker див Створення безпечних середовищ машинного навчання за допомогою Amazon SageMaker. Ви можете створити власний блокнот SageMaker, дотримуючись цих інструкцій:
- На консолі SageMaker виберіть ноутбук у навігаційній панелі.
- Вибирати Екземпляри ноутбуків.
- Вибирати Створіть екземпляр блокнота.
- Введіть назву екземпляра блокнота.
- Виберіть наявну роль IAM або створити роль який дозволяє запускати SageMaker і надає доступ до Amazon S3 і Athena.
- Вибирати Створіть екземпляр блокнота.

- Дочекайтеся зміни статусу блокнота
CreatingдоInService. - Відкрийте екземпляр блокнота, вибравши Юпітер or лабораторія Юпітера.
Вивчіть дані
Тепер ми готові досліджувати дані.
- На консолі Jupyter під Новівиберіть ноутбук.
- на Виберіть Ядро виберіть спадне меню conda_python3.
- Додайте нові комірки, вибравши знак плюс.
- У свою першу комірку завантажте такі модулі Python, які не входять до стандартного середовища SageMaker:
GeoJSON — популярний формат для зберігання просторових даних у форматі JSON. The
geojsonМодуль дозволяє легко читати та записувати дані GeoJSON за допомогою Python. Другий модуль, який ми встановлюємо,awswrangler, Є AWS SDK для панд. Це дуже простий спосіб зчитувати дані з різних джерел даних AWS у фрейми даних Pandas. Ми використовуємо його для читання даних про землетруси з таблиці Athena. - Далі ми імпортуємо всі пакети, які використовуємо для імпорту даних, змінюємо їх форму та візуалізуємо:
- Ми починаємо імпорт наших даних за допомогою
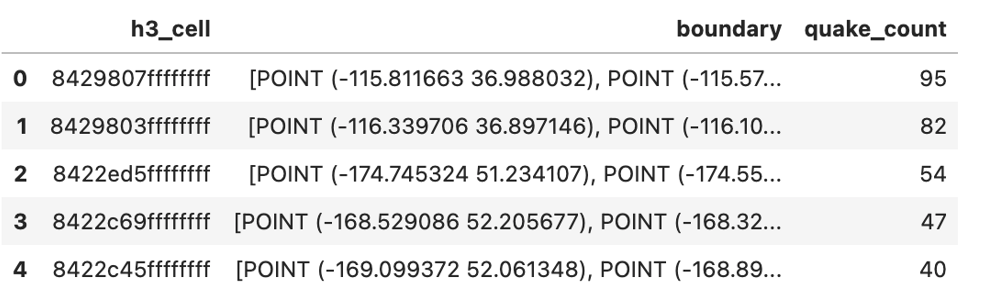
athena.read_sql._queryфункція в AWS SDK для pandas. Запит Athena має підзапит, який використовує UDF для додавання стовпцяh3_cellдо кожного рядка вearthquakesтаблицю, засновану на широті та довготі землетрусу. Аналітична функціяCOUNTпотім використовується для визначення кількості землетрусів у кожній комірці H3. Для цієї візуалізації нас цікавлять лише землетруси в межах США, тому ми відфільтровуємо рядки у фреймі даних, які знаходяться за межами області інтересів:Наступний знімок екрана показує наші результати.
Виконайте решту кроків у нашому Блокнот Юпітера щоб побачити, як ми аналізуємо та візуалізуємо наш приклад із даними H3 UDF.
Візуалізуйте результати
Щоб візуалізувати наші результати, ми використовуємо Plotly Express модуль для створення хороплетної карти наших даних. Хороплетна карта — це тип візуалізації, яка заштрихована на основі кількісних значень. Це чудова візуалізація для нашого випадку використання, оскільки ми затінюємо різні регіони на основі частоти землетрусів.
На отриманому зображенні ми можемо побачити діапазони частоти землетрусів у різних районах Північної Америки. Зауважте, що роздільна здатність H3 на цій карті нижча, ніж на попередній карті, через що кожен шестикутник покриває більшу площу земної кулі.

Прибирати
Щоб уникнути додаткових витрат на обліковий запис, видаліть створені вами ресурси:
- На консолі SageMaker виберіть блокнот і на Дії меню, виберіть Стоп.
- Зачекайте, поки статус блокнота зміниться на
Stopped, потім знову виберіть блокнот і на Дії меню, виберіть видаляти. - На консолі Amazon S3 виберіть створене вами відро та виберіть порожній.
- Введіть назву сегмента та виберіть порожній.
- Виберіть відро ще раз і виберіть видаляти.
- Введіть назву сегмента та виберіть Видалити відро.
- На консолі Lambda виберіть назву функції та на Дії меню, виберіть видаляти.
Висновок
У цій публікації ви побачили, як розширити функції в Athena для геопросторового аналізу, додавши власну функцію, визначену користувачем. Хоча в цій демонстрації ми використовували геопросторовий індекс Uber H3, ви можете використовувати свій власний геопросторовий індекс для власного геопросторового аналізу.
У цій публікації ми використали блокноти Athena, Lambda та SageMaker, щоб візуалізувати результати наших UDF на заході США. Приклади коду знаходяться в h3-udf-for-athena Репо GitHub.
Як наступний крок ви можете змінити код у цій публікації та налаштувати його відповідно до власних потреб, щоб отримати подальше розуміння на основі власних географічних даних. Наприклад, ви можете візуалізувати інші випадки, такі як посухи, повені та вирубка лісів.
Про авторів
 Джон Телфорд є старшим консультантом Amazon Web Services. Він фахівець у сфері великих даних та сховищ даних. Джон має ступінь комп’ютерних наук в Університеті Брунеля.
Джон Телфорд є старшим консультантом Amazon Web Services. Він фахівець у сфері великих даних та сховищ даних. Джон має ступінь комп’ютерних наук в Університеті Брунеля.
 Анвар Різал є старшим консультантом з машинного навчання в Парижі. Він працює з клієнтами AWS над розробкою даних і рішень штучного інтелекту для сталого розвитку їхнього бізнесу.
Анвар Різал є старшим консультантом з машинного навчання в Парижі. Він працює з клієнтами AWS над розробкою даних і рішень штучного інтелекту для сталого розвитку їхнього бізнесу.
 Полін Тінг є Data Scientist у команді AWS Professional Services. Вона підтримує клієнтів у досягненні та прискоренні бізнес-результатів, розробляючи стійкі рішення AI/ML. У вільний час Поліна любить подорожувати, займатися серфінгом і пробувати нові десертні заклади.
Полін Тінг є Data Scientist у команді AWS Professional Services. Вона підтримує клієнтів у досягненні та прискоренні бізнес-результатів, розробляючи стійкі рішення AI/ML. У вільний час Поліна любить подорожувати, займатися серфінгом і пробувати нові десертні заклади.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/extend-geospatial-queries-in-amazon-athena-with-udfs-and-aws-lambda/
- :є
- 1
- 10
- 100
- 11
- 7
- 70
- 8
- 9
- a
- МЕНЮ
- прискорення
- доступ
- рахунки
- досягнення
- Діяти
- адреса
- рада
- AI
- AI / ML
- ВСІ
- дозволяє
- хоча
- Amazon
- Амазонка Афіна
- Amazon Web Services
- Америка
- кількість
- аналіз
- Аналітичний
- аналізувати
- Аналізуючи
- та
- Інший
- Apache
- Apache Spark
- API
- Інтерфейси
- додаток
- архітектура
- ЕСТЬ
- ПЛОЩА
- області
- AS
- асоційований
- At
- уникнути
- AWS
- Клей AWS
- AWS Lambda
- Професійні послуги AWS
- заснований
- BE
- оскільки
- починати
- нижче
- КРАЩЕ
- передового досвіду
- між
- Великий
- Великий даних
- обов'язковий
- приносити
- будувати
- вбудований
- бізнес
- by
- обчислює
- Каліфорнія
- call
- званий
- CAN
- можливості
- випадок
- випадків
- каталог
- Клітини
- зміна
- вантажі
- перевірка
- вибір
- Вибирати
- Вибираючи
- вибраний
- клас
- хмара
- код
- Колонка
- поєднання
- повний
- обчислення
- комп'ютер
- Інформатика
- конфігурація
- Консоль
- консультант
- може
- графство
- обкладинка
- створювати
- створений
- створення
- виготовлений на замовлення
- Клієнти
- налаштувати
- дані
- вчений даних
- сховища даних
- Database
- глибше
- дефолт
- певний
- визначаючи
- вирубка лісу
- Ступінь
- залежить
- розгортання
- розгортання
- розгортання
- глибина
- робочий стіл
- деталі
- Визначати
- розвивати
- розвивається
- розробка
- різний
- Недоліком
- відстань
- Не знаю
- подвійний
- скачати
- кожен
- Раніше
- землетрус
- легко
- легко
- край
- редактор
- елемент
- елементи
- дозволяє
- кінець в кінець
- Що натомість? Створіть віртуальну версію себе у
- Навколишнє середовище
- середовищах
- однаково
- Ефір (ETH)
- приклад
- Приклади
- існуючий
- пояснені
- пояснення
- дослідити
- експрес
- продовжити
- зовнішній
- додатково
- ярмарок
- Поля
- філе
- фільтрувати
- остаточний
- в кінці кінців
- знайти
- Перший
- після
- слідує
- для
- формат
- FRAME
- частота
- від
- функція
- Функції
- далі
- Отримувати
- розрив
- географічний
- географічні
- геометрія
- отримати
- GitHub
- Давати
- дає
- Глобально
- земну кулю
- гранти
- великий
- Group
- Рости
- Мати
- історичний
- Як
- How To
- Однак
- HTML
- HTTP
- HTTPS
- IAM
- здійснювати
- реалізація
- імпорт
- імпорт
- in
- включати
- включені
- includes
- У тому числі
- індекс
- інформація
- Інфраструктура
- вхід
- розуміння
- встановлювати
- екземпляр
- замість
- інструкції
- інтерактивний
- інтерес
- зацікавлений
- IT
- Java
- Джон
- json
- Jupyter Notebook
- більше
- широта
- вивчення
- рівень
- як
- LNG
- вантажі
- місцевий
- розташування
- Довго
- машина
- навчання за допомогою машини
- головний
- зробити
- РОБОТИ
- вдалося
- управління
- багато
- карта
- відображення
- пам'ять
- Меню
- змінювати
- Модулі
- Модулі
- більше
- ім'я
- навігація
- Необхідність
- потреби
- Нові
- наступний
- На північ
- Північна Америка
- ноутбук
- ноутбуки
- номер
- сталося
- of
- on
- ONE
- варіант
- Опції
- порядок
- Інше
- Результат
- вихід
- поза
- власний
- пакет
- пакети
- панди
- pane
- параметр
- параметри
- Паріс
- частини
- Дозволи
- місця
- plato
- Інформація про дані Платона
- PlatoData
- плюс
- Багатокутник
- популярний
- це можливо
- пошта
- Харчування
- практика
- практики
- переважним
- представити
- ймовірно
- виробляти
- Production
- професійний
- забезпечувати
- забезпечує
- громадськість
- Python
- кількісний
- діапазон
- RE
- Читати
- готовий
- отримує
- райони
- регулярний
- надає
- замінювати
- Сховище
- подання
- Вимога
- дозвіл
- ресурси
- REST
- результат
- в результаті
- результати
- повертати
- Умови повернення
- Роль
- ROW
- прогін
- мудрець
- то ж
- наука
- вчений
- Sdk
- другий
- безпечний
- безпеку
- старший
- Без сервера
- обслуговування
- Послуги
- комплект
- кілька
- Форма
- Шоу
- підпис
- простий
- просто
- Розмір
- So
- рішення
- Рішення
- деякі
- Source
- Джерела
- Іскритися
- просторовий
- спеціаліст
- SQL
- standard
- Статус
- Крок
- заходи
- зберігання
- зберігати
- зберігати
- такі
- підтримка
- Опори
- сталого
- система
- Systems
- таблиця
- приймає
- команда
- terms
- Що
- Команда
- Площа
- їх
- Ці
- час
- до
- топ
- Подорож
- Типи
- Убер
- при
- створеного
- університет
- незвичайний
- завантажено
- us
- USA
- використання
- використання випадку
- користувач
- Цінності
- різний
- візуалізації
- візуалізувати
- хотів
- шлях..
- Web
- веб-сервіси
- Western
- Що
- Чи
- який
- Вікіпедія
- волі
- з
- в
- WKT
- Робоча група
- працює
- б
- запис
- письмовий
- вашу
- зефірнет
- зум