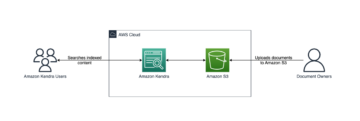
У листопаді 2022 року ми оголошений за допомогою якого клієнти AWS можуть створювати зображення з тексту Стабільна дифузія моделі в Росії Amazon SageMaker JumpStart. Stable Diffusion — це модель глибокого навчання, яка дозволяє створювати реалістичні високоякісні зображення та приголомшливе мистецтво всього за кілька секунд. Незважаючи на те, що створення вражаючих зображень може знайти застосування в різних галузях, від мистецтва до NFT і не тільки, сьогодні ми також очікуємо, що ШІ буде персоналізованим. Сьогодні ми оголошуємо, що ви можете персоналізувати модель генерації зображень відповідно до свого випадку використання, налаштувавши її на своєму спеціальному наборі даних у Amazon SageMaker JumpStart. Це може бути корисно під час створення мистецтва, логотипів, нестандартного дизайну, NFT тощо, або цікавих речей, таких як створення власних зображень ШІ ваших домашніх тварин або ваших аватарів.
У цій публікації ми надаємо огляд того, як точно налаштувати модель Stable Diffusion двома способами: програмно за допомогою API JumpStart доступні в SageMaker Python SDKта інтерфейс користувача (UI) JumpStart Студія Amazon SageMaker. Ми також обговорюємо, як зробити вибір дизайну, включаючи якість набору даних, розмір навчального набору даних, вибір значень гіперпараметрів і застосовність до кількох наборів даних. Нарешті, ми обговорюємо понад 80 загальнодоступних точно налаштованих моделей з різними мовами та стилями введення, нещодавно доданими в JumpStart.
Стабільне дифузійне та трансферне навчання
Stable Diffusion — це модель перетворення тексту в зображення, яка дає змогу створювати фотореалістичні зображення лише з текстової підказки. Модель дифузії тренується, навчаючись видаляти шум, доданий до реального зображення. Цей процес усунення шумів створює реалістичне зображення. Ці моделі також можуть генерувати зображення лише з тексту, обумовлюючи процес генерації текстом. Наприклад, стабільна дифузія — це прихована дифузія, коли модель вчиться розпізнавати форми в зображенні з чистим шумом і поступово фокусує ці форми, якщо фігури відповідають словам у вхідному тексті. Текст спочатку має бути вбудований у прихований простір за допомогою мовної моделі. Потім у прихованому просторі з архітектурою U-Net виконується ряд операцій додавання та видалення шуму. Нарешті, знешумлений вихід декодується в простір пікселів.
У машинному навчанні (ML) називається здатність передавати знання, отримані в одній області, в іншу трансферне навчання. Ви можете використовувати передачу навчання для створення точних моделей на невеликих наборах даних із значно нижчими витратами на навчання, ніж витрати на навчання вихідної моделі. Завдяки трансферному навчанню ви можете точно налаштувати модель стабільної дифузії на власному наборі даних лише за допомогою п’яти зображень. Наприклад, ліворуч зображені тренувальні зображення собаки на прізвисько Доплер, які використовуються для точного налаштування моделі, посередині та праворуч зображені зображення, створені точно налаштованою моделлю, коли її попросили передбачити зображення Доплера на пляжі та ескіз олівцем.

Зліва зображено біле крісло, яке використовується для точного налаштування моделі, і червоне зображення крісла, створене налаштованою моделлю. Праворуч зображені пуфики, які використовуються для точного налаштування моделі, і зображення кота, що сидить на пуфику.

Для тонкого налаштування великих моделей, таких як Stable Diffusion, зазвичай потрібно надати навчальні сценарії. Є безліч проблем, зокрема проблеми з пам’яттю, розміром корисного навантаження тощо. Крім того, ви повинні запустити наскрізні тести, щоб переконатися, що сценарій, модель і потрібний екземпляр працюють разом ефективним чином. JumpStart спрощує цей процес, надаючи готові до використання сценарії, які були ретельно перевірені. Сценарій точного налаштування JumpStart для моделей Stable Diffusion базується на сценарії точного налаштування з будка мрій. Ви можете отримати доступ до цих сценаріїв одним клацанням миші в інтерфейсі Studio або за допомогою кількох рядків коду через API JumpStart.
Зауважте, що використовуючи модель Stable Diffusion, ви погоджуєтеся з Ліцензія CreativeML Open RAIL++-M.
Використовуйте JumpStart програмно з SageMaker SDK
У цьому розділі описано, як навчити та розгорнути модель за допомогою SageMaker Python SDK. Ми вибираємо відповідну попередньо навчену модель у JumpStart, навчаємо цю модель за допомогою навчального завдання SageMaker і розгортаємо навчену модель на кінцевій точці SageMaker. Крім того, ми виконуємо висновок на розгорнутій кінцевій точці, використовуючи SageMaker Python SDK. Наступні приклади містять фрагменти коду. Повний код із усіма кроками в цій демонстрації див Вступ до JumpStart – текст до зображення зразок зошита.
Навчання та тонке налаштування моделі стабільної дифузії
Кожна модель має унікальний ідентифікатор model_id. Наступний код показує, як точно налаштувати базову модель Stable Diffusion 2.1, визначену за model_id model-txt2img-stabilityai-stable-diffusion-v2-1-base на спеціальному навчальному наборі даних. Для повного списку model_id значення та моделі, які можна точно налаштувати, див Вбудовані алгоритми з попередньо навченою таблицею моделей. Для кожного model_id, щоб запустити навчальне завдання SageMaker через Оцінювач класу SDK SageMaker Python, вам потрібно отримати URI зображення Docker, URI навчального сценарію та URI попередньо навченої моделі за допомогою службових функцій, наданих у SageMaker. URI сценарію навчання містить увесь необхідний код для обробки даних, завантаження попередньо навченої моделі, навчання моделі та збереження навченої моделі для висновку. URI попередньо підготовленої моделі містить визначення архітектури попередньо підготовленої моделі та параметри моделі. Попередньо підготовлений URI моделі є специфічним для конкретної моделі. Попередньо підготовлені архіви моделей попередньо завантажено з Hugging Face і збережено з відповідним підписом моделі в Служба простого зберігання Amazon (Amazon S3), так що навчання виконується в ізоляції мережі. Перегляньте наступний код:
За допомогою цих специфічних для моделі навчальних артефактів ви можете побудувати об’єкт Оцінювач клас:
Набір тренінгових даних
Нижче наведено вказівки щодо форматування навчальних даних:
- вхід – Каталог, що містить зображення екземплярів,
dataset_info.json, з такою конфігурацією:- Зображення можуть бути у форматі .png, .jpg або .jpeg
- Команда
dataset_info.jsonфайл повинен мати формат{'instance_prompt':<<instance_prompt>>}
- Вихід – Навчена модель, яку можна розгорнути для логічного висновку
Шлях S3 має виглядати так s3://bucket_name/input_directory/. Зверніть увагу на закінчення / не потрібно.
Нижче наведено приклад формату навчальних даних:
Щоб отримати інструкції щодо форматування даних під час попереднього збереження, зверніться до розділу Попереднє збереження у цій публікації.
Ми надаємо стандартний набір даних зображень котів. Він складається з восьми зображень (зображення екземпляра, що відповідають запиту екземпляра) одного кота без зображень класу. Його можна завантажити з GitHub. Якщо ви використовуєте набір даних за замовчуванням, спробуйте підказку «фото кота riobugger», роблячи висновок у демонстраційному блокноті.
Ліцензія: MIT.
Гіперпараметри
Далі, щоб перенести навчання на свій набір даних, вам може знадобитися змінити значення за замовчуванням гіперпараметрів навчання. Ви можете отримати словник Python цих гіперпараметрів із значеннями за замовчуванням за допомогою виклику hyperparameters.retrieve_default, оновіть їх за потреби, а потім передайте їх класу Estimator. Перегляньте наступний код:
Наступні гіперпараметри підтримуються алгоритмом тонкого налаштування:
- з_попередньою_консервацією – Позначте, щоб додати втрату попереднього збереження. Попередня консервація є регуляризатором, який дозволяє уникнути надмірного оснащення. (Вибір:
[“True”,“False”], за замовчуванням:“False”.) - num_class_images – Зображення мінімального класу для попередньої втрати збереження. Якщо
with_prior_preservation = Trueі вже недостатньо зображеньclass_data_dir, додаткові зображення будуть взяті за допомогоюclass_prompt. (Значення: натуральне число, за замовчуванням: 100.) - епохи – Кількість проходів, які виконує алгоритм точного налаштування через навчальний набір даних. (Значення: додатне ціле число, за замовчуванням: 20.)
- Макс_кроків – Загальна кількість тренувальних кроків для виконання. Якщо ні
None, перекриває епохи. (Значення:“None”або рядок цілого числа, за замовчуванням:“None”.) - Розмір партії –: кількість навчальних прикладів, які опрацьовуються перед оновленням ваг моделі. Такий самий, як розмір пакету під час створення зображень класу, якщо
with_prior_preservation = True. (Значення: натуральне число, за замовчуванням: 1.) - швидкість_навчання – Швидкість, з якою вагові коефіцієнти моделі оновлюються після опрацювання кожної групи навчальних прикладів. (Значення: додатне значення з плаваючою точкою, за замовчуванням: 2e-06.)
- попередня_втрата_ваги – Вага втрати попереднього збереження. (Значення: додатне значення з плаваючою точкою, за замовчуванням: 1.0.)
- center_crop – Чи потрібно обрізати зображення перед зміною розміру до потрібної роздільної здатності. (Вибір:
[“True”/“False”], за замовчуванням:“False”.) - lr_scheduler – Тип планувальника курсу навчання. (Вибір:
["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"], за замовчуванням:"constant".) Для отримання додаткової інформації див Планувальники темпів навчання. - adam_weight_decay – Розпад ваги для застосування (якщо не дорівнює нулю) до всіх шарів, крім усіх зміщень і
LayerNormваги вAdamWоптимізатор. (Значення: float, за умовчанням: 1e-2.) - adam_beta1 – Гіперпараметр бета1 (експоненційна швидкість розпаду для оцінок першого моменту) для
AdamWоптимізатор. (Значення: float, за замовчуванням: 0.9.) - adam_beta2 – Гіперпараметр бета2 (експоненційна швидкість розпаду для оцінок першого моменту) для
AdamWоптимізатор. (Значення: float, за замовчуванням: 0.999.) - adam_epsilon - The
epsilonгіперпараметр дляAdamWоптимізатор. Зазвичай встановлюється невелике значення, щоб уникнути ділення на 0. (Значення: float, за замовчуванням: 1e-8.) - градієнт_накопичення_кроків – Кількість кроків оновлення, які потрібно накопичити перед виконанням зворотного проходу/оновлення. (Значення: ціле, за замовчуванням: 1.)
- max_grad_norm – Максимальна норма градієнта (для обрізки градієнта). (Значення: float, за умовчанням: 1.0.)
- насіння – Виправте випадковий стан для досягнення відтворюваних результатів у навчанні. (Значення: ціле, за замовчуванням: 0.)
Розгорніть детально навчену модель
Після завершення навчання моделі можна безпосередньо розгорнути модель на постійній кінцевій точці в реальному часі. Ми отримуємо необхідні URI зображення Docker і URI сценарію та розгортаємо модель. Перегляньте наступний код:
Ліворуч наведено навчальні зображення кота на прізвисько riobugger, які використовуються для точного налаштування моделі (параметри за замовчуванням, крім max_steps = 400). Посередині та праворуч – зображення, створені точно налаштованою моделлю, коли її попросили передбачити зображення riobugger на пляжі та ескіз олівцем.

Додаткову інформацію про висновок, включаючи підтримувані параметри, формат відповіді тощо, див Створюйте зображення з тексту за допомогою моделі стабільної дифузії на Amazon SageMaker JumpStart.
Отримайте доступ до JumpStart через інтерфейс користувача Studio
У цьому розділі ми демонструємо, як навчати та розгортати моделі JumpStart за допомогою інтерфейсу користувача Studio. У наступному відео показано, як знайти попередньо підготовлену модель Stable Diffusion у JumpStart, навчити її та розгорнути. Сторінка моделі містить цінну інформацію про модель і способи її використання. Після налаштування екземпляра навчання SageMaker виберіть поїзд. Після того, як модель навчена, ви можете розгорнути навчену модель, вибравши Розгортання. Коли кінцева точка перебуває на стадії «в роботі», вона готова відповідати на запити висновків.
Щоб пришвидшити час для висновку, JumpStart надає зразок блокнота, який показує, як запустити висновок на щойно створеній кінцевій точці. Щоб отримати доступ до блокнота в Studio, виберіть Відкрийте Блокнот в Використовуйте Endpoint із Studio розділ сторінки кінцевої точки моделі.
JumpStart також надає простий блокнот, який можна використовувати для точного налаштування моделі стабільної дифузії та розгортання отриманої точно налаштованої моделі. Ви можете використовувати його для створення веселих зображень вашої собаки. Щоб отримати доступ до блокнота, знайдіть «Створити веселі зображення вашої собаки» на панелі пошуку JumpStart. Щоб створити блокнот, ви можете використати лише п’ять навчальних зображень і завантажити їх у папку локальної студії. Якщо у вас більше п’яти зображень, ви також можете завантажити їх. Notebook завантажує навчальні зображення в S3, навчає модель на вашому наборі даних і розгортає отриману модель. Тренування може тривати 20 хвилин. Ви можете змінити кількість кроків, щоб прискорити навчання. Notebook надає кілька зразків підказок, які можна спробувати з розгорнутою моделлю, але ви можете спробувати будь-яку підказку, яка вам подобається. Ви також можете адаптувати блокнот для створення аватарів себе або своїх домашніх тварин. Наприклад, замість собаки ви можете завантажити зображення свого кота на першому кроці, а потім змінити підказки з собак на котів, і модель створить зображення вашого кота.
Міркування щодо тонкого налаштування
Навчання моделям Stable Diffusion має тенденцію до швидкого перепідбору. Щоб отримати зображення хорошої якості, ми повинні знайти хороший баланс між доступними гіперпараметрами навчання, такими як кількість кроків навчання та швидкість навчання. У цьому розділі ми показуємо деякі експериментальні результати та надаємо вказівки щодо встановлення цих параметрів.
Рекомендації
Враховуйте наступні рекомендації:
- Почніть із хорошої якості навчальних зображень (4–20). Якщо тренуватися на людських обличчях, вам може знадобитися більше зображень.
- Тренуйтеся робити 200–400 кроків під час тренувань на собаках, котах та інших нелюдських предметах. Якщо ви тренуєтеся на людських обличчях, вам може знадобитися більше кроків. Якщо трапиться переобладнання, зменшіть кількість кроків. Якщо трапляється недостатнє підгонювання (точно налаштована модель не може створити зображення цільового об’єкта), збільште кількість кроків.
- Якщо ви тренуєтеся на нелюдських обличчях, ви можете встановити
with_prior_preservation = Falseоскільки це суттєво не впливає на продуктивність. На людських обличчях вам може знадобитися встановитиwith_prior_preservation=True. - Якщо налаштування
with_prior_preservation=True, використовуйте тип екземпляра ml.g5.2xlarge. - Під час послідовного навчання кількох предметів, якщо суб’єкти дуже схожі (наприклад, усі собаки), модель зберігає останнього суб’єкта та забуває попередніх. Якщо суб’єкти різні (наприклад, спочатку кішка, потім собака), модель зберігає обидва суб’єкти.
- Ми рекомендуємо використовувати низьку швидкість навчання та поступово збільшувати кількість кроків, доки результати не будуть задовільними.
Набір тренінгових даних
На якість точно налаштованої моделі безпосередньо впливає якість навчальних зображень. Тому вам потрібно збирати якісні зображення, щоб отримати хороші результати. Розмиті зображення або зображення з низькою роздільною здатністю вплинуть на якість точно налаштованої моделі. Зверніть увагу на такі додаткові параметри:
- Кількість навчальних зображень – Ви можете точно налаштувати модель лише на чотирьох навчальних зображеннях. Ми експериментували з навчальними наборами даних розміром від 4 до 16 зображень. В обох випадках тонке налаштування змогло адаптувати модель до об’єкта.
- Формати набору даних – Ми протестували алгоритм тонкого налаштування на зображеннях формату .png, .jpg і .jpeg. Інші формати також можуть працювати.
- Роздільна здатність зображення – Навчальні зображення можуть мати будь-яку роздільну здатність. Алгоритм точного налаштування змінить розмір усіх навчальних зображень перед початком точного налаштування. З огляду на це, якщо ви хочете мати більше контролю над кадруванням і зміною розміру навчальних зображень, ми рекомендуємо самостійно змінити розмір зображень до базової роздільної здатності моделі (у цьому прикладі 512×512 пікселів).
Налаштування експерименту
В експерименті в цій публікації під час тонкого налаштування ми використовуємо значення гіперпараметрів за замовчуванням, якщо вони не вказані. Крім того, ми використовуємо один із чотирьох наборів даних:
- Собака1-8 – Собака 1 з 8 зображеннями
- Собака1-16 – Собака 1 з 16 зображеннями
- Собака2-4 – Собака 2 із чотирма зображеннями
- Кіт-8 – Кішка з 8 зображеннями
Щоб зменшити захаращення, ми показуємо лише одне типове зображення набору даних у кожному розділі разом із назвою набору даних. Повний навчальний набір ви можете знайти в розділі Набори експериментальних даних у цій публікації.
Переобладнання
Моделі Stable Diffusion мають тенденцію до надмірного підбору під час точного налаштування кількох зображень. Тому вам потрібно вибрати такі параметри, як epochs, max_epochs, і уважно оцінюйте навчання. У цьому розділі ми використовували набір даних Dog1-16.

Щоб оцінити продуктивність моделі, ми оцінюємо налаштовану модель для чотирьох завдань:
- Чи може налаштована модель генерувати зображення об’єкта (допплерівського собаки) у тих самих умовах, на яких її тренували?
- Спостереження – Так, може. Варто зазначити, що продуктивність моделі зростає зі збільшенням кількості кроків навчання.
- Чи може налаштована модель створювати зображення об’єкта в умовах, відмінних від тих, на яких вона тренувалася? Наприклад, чи може він створювати доплерівські зображення на пляжі?
- Спостереження – Так, може. Варто зазначити, що продуктивність моделі зростає із збільшенням кількості кроків навчання до певного моменту. Проте, якщо модель тренується надто довго, продуктивність моделі погіршується, оскільки модель має тенденцію до надмірного пристосування.
- Чи може налаштована модель генерувати зображення класу, до якого належить предмет навчання? Наприклад, чи може він створити образ загального собаки?
- Спостереження – Коли ми збільшуємо кількість тренувальних кроків, модель починає перевантажуватися. У результаті він забуває про загальний клас собаки і створюватиме лише зображення, пов’язані з об’єктом.
- Чи може налаштована модель створювати зображення класу чи предмета, яких немає в наборі навчальних даних? Наприклад, чи може він створити зображення кота?
- Спостереження – Коли ми збільшуємо кількість тренувальних кроків, модель починає перевантажуватися. У результаті створюватимуться лише зображення, пов’язані з об’єктом, незалежно від зазначеного класу.
Налаштовуємо модель на різну кількість кроків (встановивши max_steps гіперпараметри) і для кожної точно налаштованої моделі ми створюємо зображення за кожним із наступних чотирьох запитів (показано в наступних прикладах зліва направо):
- «Фото собаки з доплером»
- «Фото собаки з доплером на пляжі»
- «Фото собаки»
- «Фото кота»
Наступні зображення взято з моделі, навченої 50 кроками.

Наступну модель було навчено 100 кроками.

Ми навчили наступну модель із 200 кроків.

Наступні зображення взято з моделі, яка пройшла 400 кроків.

Нарешті, наступні зображення є результатом 800 кроків.

Тренуйтеся на кількох наборах даних
Під час точного налаштування ви можете налаштувати кілька об’єктів, щоб налаштована модель створювала зображення всіх об’єктів. На жаль, JumpStart наразі обмежується навчанням з однієї теми. Ви не можете точно налаштувати модель на кількох предметах одночасно. Крім того, точне налаштування моделі для різних суб’єктів послідовно призводить до того, що модель забуває про перший суб’єкт, якщо суб’єкти схожі.
У цьому розділі ми розглядаємо такі експерименти:
- Тонко налаштуйте модель для предмета А.
- Тонко налаштуйте отриману модель із Кроку 1 для суб’єкта B.
- Створіть зображення суб’єкта A та суб’єкта B, використовуючи вихідну модель із кроку 2.
У наступних експериментах ми спостерігаємо, що:
- Якщо A — собака 1, а B — собака 2, то всі зображення, створені на кроці 3, схожі на собаку 2
- Якщо A — собака 2, а B — собака 1, то всі зображення, створені на кроці 3, схожі на собаку 1
- Якщо A — собака 1, а B — кіт, то зображення, згенеровані за допомогою підказок собаки, схожі на собаку 1, а зображення, створені за допомогою підказок кота, схожі на кота
Тренуйте собаку 1, а потім собаку 2
На кроці 1 ми точно налаштовуємо модель на 200 кроків на восьми зображеннях собаки 1. На кроці 2 ми додатково налаштовуємо модель на 200 кроків на чотирьох зображеннях собаки 2.

Нижче наведено зображення, згенеровані налаштованою моделлю в кінці кроку 2 для різних підказок.

Тренуйте собаку 2, а потім собаку 1
На кроці 1 ми точно налаштовуємо модель на 200 кроків на чотирьох зображеннях собаки 2. На кроці 2 ми додатково налаштовуємо модель на 200 кроків на восьми зображеннях собаки 1.

Нижче наведено зображення, створені налаштованою моделлю наприкінці кроку 2 із різними підказками.

Тренувати на собаках і котах
На кроці 1 ми налаштовуємо модель на 200 кроків на восьми зображеннях кота. Потім ми додатково налаштовуємо модель на 200 кроків на восьми зображеннях собаки 1.

Нижче наведено зображення, створені налаштованою моделлю наприкінці кроку 2. Зображення з підказками, пов’язаними з котом, виглядають як кіт на кроці 1 точного налаштування, а зображення з підказками, пов’язаними з собакою, виглядають як собака в Крок 2 тонкого налаштування.

Попередня консервація
Попереднє збереження — це техніка, яка використовує додаткові зображення того самого класу, на якому ми намагаємося тренуватися. Наприклад, якщо тренувальні дані складаються із зображень конкретної собаки з попереднім збереженням, ми включаємо зображення класу типових собак. Він намагається уникнути переобладнання, показуючи зображення різних собак під час навчання конкретної собаки. У підказці класу відсутній тег, що вказує на конкретну собаку в запиті екземпляра. Наприклад, підказка екземпляра може бути «фото кота riobugger», а підказка класу може бути «фото кота». Ви можете ввімкнути попереднє збереження, встановивши гіперпараметр with_prior_preservation = True. Якщо налаштування with_prior_preservation = True, ви повинні включити class_prompt in dataset_info.json і може включати будь-які доступні вам зображення класу. Нижче наведено формат навчального набору даних під час налаштування with_prior_preservation = True:
- вхід – Каталог, що містить зображення екземплярів,
dataset_info.jsonі (необов'язково) каталогclass_data_dir. Зверніть увагу на наступне:- Зображення можуть бути у форматі .png, .jpg, .jpeg.
- Команда
dataset_info.jsonфайл повинен мати формат{'instance_prompt':<<instance_prompt>>,'class_prompt':<<class_prompt>>}. - Команда
class_data_dirкаталог повинен містити зображення класів. Якщоclass_data_dirнемає або в ньому вже недостатньо зображеньclass_data_dir, додаткові зображення будуть взяті за допомогоюclass_prompt.
Для таких наборів даних, як коти та собаки, попереднє збереження не суттєво впливає на продуктивність точно налаштованої моделі, тому його можна уникнути. Однак при тренуванні на обличчях це необхідно. Для отримання додаткової інформації див Навчання стабільній дифузії з Dreambooth за допомогою дифузорів.
Типи екземплярів
Для точного налаштування моделей стабільної дифузії потрібне прискорене обчислення, що забезпечується екземплярами з підтримкою GPU. Ми експериментуємо з тонким налаштуванням з примірниками ml.g4dn.2xlarge (16 ГБ пам’яті CUDA, 1 GPU) і ml.g5.2xlarge (24 ГБ пам’яті CUDA, 1 GPU). Вимоги до пам'яті вищі під час генерації зображень класу. Тому, якщо установка with_prior_preservation=True, використовуйте тип екземпляра ml.g5.2xlarge, оскільки навчання стикається з проблемою нестачі пам’яті CUDA на екземплярі ml.g4dn.2xlarge. Сценарій точного налаштування JumpStart наразі використовує один графічний процесор, тому тонке налаштування екземплярів із кількома графічним процесором не призведе до підвищення продуктивності. Додаткову інформацію про різні типи екземплярів див Типи екземплярів Amazon EC2.
Обмеження та упередженість
Незважаючи на те, що Stable Diffusion має вражаючу продуктивність у створенні зображень, він страждає від кількох обмежень і упереджень. Вони включають, але не обмежуються:
- Модель може не генерувати точні обличчя чи кінцівки, оскільки навчальні дані не містять достатньо зображень із цими функціями
- Модель проходила навчання на Набір даних LAION-5B, який має вміст для дорослих і може бути непридатним для використання в продукті без подальших розглядів
- Модель може погано працювати з неанглійськими мовами, оскільки модель навчена на тексті англійською мовою
- Модель не може створити якісний текст у зображеннях
Додаткову інформацію про обмеження та упередження див Картка базової моделі Stable Diffusion v2-1. Ці обмеження для попередньо навченої моделі також можуть бути перенесені на налаштовані моделі.
Прибирати
Після того, як ви завершите роботу блокнота, обов’язково видаліть усі ресурси, створені в процесі, щоб переконатися, що виставлення рахунків зупинено. Код для очищення кінцевої точки надається в асоційованому Вступ до JumpStart – текст до зображення зразок зошита.
Загальнодоступні детально налаштовані моделі в JumpStart
Незважаючи на те, що моделі Stable Diffusion, випущені компанією Стабільність AI мають вражаючу продуктивність, у них є обмеження щодо мови чи домену, на якому вони навчалися. Наприклад, моделі Stable Diffusion були навчені на англійському тексті, але вам може знадобитися створити зображення з неанглійського тексту. Крім того, моделі Stable Diffusion були навчені генерувати фотореалістичні зображення, але вам може знадобитися генерувати анімовані чи художні зображення.
JumpStart надає понад 80 загальнодоступних моделей різними мовами та темами. Ці моделі часто є точно налаштованими версіями моделей Stable Diffusion, випущених StabilityAI. Якщо ваш варіант використання збігається з однією з точно налаштованих моделей, вам не потрібно збирати власний набір даних і налаштовувати його. Ви можете просто розгорнути одну з цих моделей за допомогою інтерфейсу користувача Studio або за допомогою простих у використанні API JumpStart. Щоб розгорнути попередньо навчену модель Stable Diffusion у JumpStart, див Створюйте зображення з тексту за допомогою моделі стабільної дифузії на Amazon SageMaker JumpStart.
Нижче наведено кілька прикладів зображень, створених різними моделями, доступними в JumpStart.


Зауважте, що ці моделі не налаштовуються за допомогою сценаріїв JumpStart або DreamBooth. Ви можете завантажити повний список загальнодоступних налаштованих моделей із прикладами підказок тут.
Більше прикладів зображень, створених із цих моделей, див. у розділі Досконалі моделі з відкритим кодом у Додатку.
Висновок
У цій публікації ми показали, як точно налаштувати модель Stable Diffusion для тексту в зображення, а потім розгорнути її за допомогою JumpStart. Крім того, ми обговорили деякі з міркувань, які ви повинні враховувати під час точного налаштування моделі, і як це може вплинути на продуктивність точно налаштованої моделі. Ми також обговорили понад 80 готових до використання налаштованих моделей, доступних у JumpStart. У цьому дописі ми показали фрагменти коду. Щоб отримати повний код із усіма кроками в цій демонстрації, див. Вступ до JumpStart – текст до зображення приклад зошита. Спробуйте рішення самостійно та надішліть нам свої коментарі.
Щоб дізнатися більше про модель і тонке налаштування DreamBooth, перегляньте такі ресурси:
Щоб дізнатися більше про JumpStart, перегляньте такі публікації блогу:
Про авторів
 Доктор Вівек Мадан є прикладним науковцем у команді Amazon SageMaker JumpStart. Він отримав ступінь доктора філософії в Університеті Іллінойсу в Урбана-Шампейн і був науковим співробітником у технічному університеті Джорджії. Він є активним дослідником машинного навчання та розробки алгоритмів і публікував статті на конференціях EMNLP, ICLR, COLT, FOCS і SODA.
Доктор Вівек Мадан є прикладним науковцем у команді Amazon SageMaker JumpStart. Він отримав ступінь доктора філософії в Університеті Іллінойсу в Урбана-Шампейн і був науковим співробітником у технічному університеті Джорджії. Він є активним дослідником машинного навчання та розробки алгоритмів і публікував статті на конференціях EMNLP, ICLR, COLT, FOCS і SODA.
 Хайко Хоц є старшим архітектором рішень для ШІ та машинного навчання з особливою увагою до обробки природної мови (NLP), великих мовних моделей (LLM) і генеративного ШІ. До цієї посади він був керівником відділу обробки даних у відділі обслуговування клієнтів Amazon в ЄС. Heiko допомагає нашим клієнтам досягти успіху на шляху штучного інтелекту/ML на AWS і співпрацює з організаціями в багатьох галузях, зокрема страхування, фінансові послуги, медіа та розваги, охорона здоров’я, комунальні послуги та виробництво. У вільний час Хейко якомога більше подорожує.
Хайко Хоц є старшим архітектором рішень для ШІ та машинного навчання з особливою увагою до обробки природної мови (NLP), великих мовних моделей (LLM) і генеративного ШІ. До цієї посади він був керівником відділу обробки даних у відділі обслуговування клієнтів Amazon в ЄС. Heiko допомагає нашим клієнтам досягти успіху на шляху штучного інтелекту/ML на AWS і співпрацює з організаціями в багатьох галузях, зокрема страхування, фінансові послуги, медіа та розваги, охорона здоров’я, комунальні послуги та виробництво. У вільний час Хейко якомога більше подорожує.
Додаток: набори даних експерименту
Цей розділ містить набори даних, використані в експериментах у цій публікації.
Собака1-8

Собака1-16

Собака2-4

Собака3-8

Додаток: Тонко налаштовані моделі з відкритим кодом
Нижче наведено кілька прикладів зображень, створених різними моделями, доступними в JumpStart. Кожне зображення має підпис а model_id починаючи з префікса huggingface-txt2img- а потім підказка, яка використовується для створення зображення в наступному рядку.

























- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/fine-tune-text-to-image-stable-diffusion-models-with-amazon-sagemaker-jumpstart/
- 1
- 100
- 11
- 2022
- 9
- a
- здатність
- Здатний
- МЕНЮ
- прискорювати
- прискорений
- доступ
- Накопичуватися
- точний
- Achieve
- активний
- пристосовувати
- доданий
- доповнення
- Додатковий
- Для дорослих
- після
- AI
- ШІ та машинне навчання
- AI / ML
- алгоритм
- алгоритми
- ВСІ
- дозволяє
- тільки
- вже
- хоча
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- та
- Оголосити
- Інший
- Інтерфейси
- прикладної
- Застосовувати
- відповідний
- архітектура
- Art
- художній
- асоційований
- автоматично
- доступний
- аватари
- уникнути
- уникати
- AWS
- Balance
- бар
- база
- Пляж
- оскільки
- перед тим
- буття
- між
- За
- зміщення
- біллінг
- Блог
- Повідомлення в блозі
- Приносить
- Будує
- званий
- покликання
- обережно
- нести
- випадок
- випадків
- КПП
- коти
- певний
- Крісло
- зміна
- перевірка
- вибір
- вибір
- Вибирати
- Вибираючи
- клас
- захаращення
- код
- збирати
- коментарі
- обчислення
- конференції
- конфігурація
- Вважати
- міркування
- постійна
- будувати
- Контейнер
- містить
- зміст
- контроль
- Відповідний
- витрати
- створювати
- створений
- створення
- урожай
- В даний час
- виготовлений на замовлення
- клієнт
- Контакти
- Клієнти
- дані
- обробка даних
- наука про дані
- набори даних
- глибокий
- глибоке навчання
- дефолт
- Демонстрація
- демонструвати
- розгортання
- розгорнути
- дизайн
- конструкцій
- деталі
- різний
- радіомовлення
- безпосередньо
- обговорювати
- обговорювалися
- Роздільна
- Docker
- Докер-контейнер
- Ні
- Пес
- собаки
- справи
- домен
- Не знаю
- скачати
- під час
- кожен
- легкий у використанні
- ефективний
- вбудований
- включіть
- дозволяє
- кінець в кінець
- Кінцева точка
- англійська
- досить
- забезпечувати
- розваги
- запис
- епохи
- Оцінки
- і т.д.
- Ефір (ETH)
- EU
- оцінювати
- приклад
- Приклади
- Крім
- виконувати
- очікувати
- експеримент
- експонентний
- Особа
- особи
- кілька
- філе
- Файли
- в кінці кінців
- фінансовий
- фінансові послуги
- знайти
- закінчення
- Перший
- відповідати
- виправляти
- Поплавок
- Сфокусувати
- потім
- після
- формат
- від
- Повний
- веселощі
- Функції
- далі
- Крім того
- Отримувати
- породжувати
- генерується
- генерує
- породжує
- покоління
- генеративний
- Генеративний ШІ
- Грузія
- отримати
- GitHub
- добре
- GPU
- поступово
- Обробка
- відбувається
- голова
- охорона здоров'я
- допомагає
- високоякісний
- вище
- господар
- Як
- How To
- Однак
- HTML
- HTTPS
- людина
- ICLR
- ідентифікований
- Іллінойс
- зображення
- генерація зображень
- зображень
- Impact
- вплив
- імпорт
- вражаючий
- in
- включати
- includes
- У тому числі
- включати
- Augmenter
- Збільшує
- зростаючий
- промисловості
- інформація
- вхід
- екземпляр
- замість
- інструкції
- страхування
- інтерфейс
- залучений
- ізоляція
- питання
- питання
- IT
- робота
- подорож
- json
- тримати
- знання
- мова
- мови
- великий
- останній
- запуск
- шарів
- УЧИТЬСЯ
- вчений
- вивчення
- недоліки
- обмеженою
- Лінія
- ліній
- список
- трохи
- погрузка
- місцевий
- Довго
- подивитися
- виглядає як
- від
- низький
- машина
- навчання за допомогою машини
- зробити
- манера
- вручну
- виробництво
- багато
- матч
- максимальний
- Медіа
- пам'ять
- Середній
- може бути
- mind
- мінімальний
- відсутній
- ML
- модель
- Моделі
- момент
- більше
- множинний
- ім'я
- Названий
- Природний
- Природна мова
- Обробка природних мов
- необхідно
- Необхідність
- необхідний
- мережу
- наступний
- NFT
- nlp
- шум
- ноутбук
- Листопад
- номер
- об'єкт
- спостерігати
- ONE
- відкрити
- операції
- порядок
- організації
- оригінал
- Інше
- огляд
- власний
- документи
- параметри
- приватність
- проходить
- Проходження
- шлях
- виконувати
- продуктивність
- виконанні
- Уособлювати
- Домашні тварини
- Фотореалістичний
- піксель
- plato
- Інформація про дані Платона
- PlatoData
- будь ласка
- точка
- позитивний
- це можливо
- пошта
- Пости
- передбачати
- представити
- попередній
- попередній
- процес
- обробка
- виробляти
- Product
- поступово
- забезпечувати
- за умови
- забезпечує
- забезпечення
- публічно
- опублікований
- Python
- якість
- швидко
- випадковий
- ранжування
- ставка
- готовий
- реальний
- реального часу
- реалістичний
- нещодавно
- визнавати
- рекомендувати
- рекомендації
- червоний
- зменшити
- Незалежно
- пов'язаний
- випущений
- видалення
- видаляти
- представник
- запитів
- вимагати
- вимагається
- вимога
- Вимагається
- дослідник
- дозвіл
- ресурси
- Реагувати
- відповідь
- результат
- в результаті
- результати
- Роль
- прогін
- біг
- мудрець
- Зазначений
- то ж
- економія
- наука
- вчений
- scripts
- Sdk
- Пошук
- seconds
- розділ
- старший
- Серія
- обслуговування
- Послуги
- комплект
- установка
- кілька
- форми
- Повинен
- Показувати
- показаний
- Шоу
- істотно
- аналогічний
- простий
- просто
- один
- Сидячий
- Розмір
- невеликий
- менше
- So
- рішення
- Рішення
- деякі
- Простір
- спеціальний
- конкретний
- зазначений
- швидкість
- стабільний
- Стажування
- Починаючи
- починається
- стан
- Крок
- заходи
- зупинений
- зберігання
- студія
- тема
- успішний
- такі
- Страждає
- достатній
- підтримка
- Підтриманий
- Опори
- TAG
- Приймати
- приймає
- Мета
- завдання
- команда
- технології
- terms
- Тести
- Команда
- їх
- отже
- через
- час
- до
- сьогодні
- разом
- занадто
- Усього:
- поїзд
- навчений
- Навчання
- поїзда
- переклад
- мандри
- Типи
- ui
- створеного
- університет
- Оновити
- оновлений
- Updates
- URI
- us
- використання
- використання випадку
- користувач
- Інтерфейс користувача
- зазвичай
- комунальні послуги
- утиліта
- використовує
- Цінний
- Цінна інформація
- значення
- Цінності
- різний
- Відео
- способи
- вага
- Чи
- який
- в той час як
- білий
- волі
- в
- без
- слова
- Work
- працювати разом
- працював
- робочий
- вартість
- вихід
- вашу
- себе
- зефірнет
- нуль