У цій статті ви дізнаєтесь про різні методи конвертації PDF у Google Таблиці.
Ви також дізнаєтеся, як можуть Nanonets автоматизувати весь робочий процес перетворення PDF у Google Таблиці Інтернет.
Перш ніж ми розглянемо, як конвертувати PDF у Google Таблиці, давайте подивимося, чому це важливо робити.
Навіщо конвертувати PDF-файли в Google Таблиці?
Відповідно до цього Блог Google на офіційній сторінці блогу Google, понад 5 мільйонів компаній використовують їх рішення G Suite. У той же час велика кількість компаній також почали використовувати інтеграцію Google Таблиць для автоматизації завдань.
Розглянемо типовий випадок використання. Ваша команда з питань кредиторської заборгованості отримує рахунок-фактуру у стандартному форматі PDF. Хтось вручну переглядає рахунок-фактуру та вводить необхідну інформацію в документ Google Таблиць, перш ніж пересилати його в розділ «Фінанси». Розділ фінансів оплачує ваш постачальник і робить запис у бухгалтерській книзі компанії.
Крім того, що це довгий процес, він схильний до помилок, і було б набагато доцільніше просто автоматизувати його.
Тепер, коли необхідність конвертації PDF-файлів у форму аркуша Google зрозуміла, давайте подивимося, як структуровані PDF-документи та які труднощі виникають під час їх аналізу.
Хочу конвертувати PDF файлів Google Таблиці ? Перевіряти Нанонець безкоштовно Конвертер PDF у CSV. Або дізнайтеся, як автоматизуйте весь робочий процес із PDF-файлів у Google Таблиці за допомогою Nanonets.
Проблеми з аналізом PDF-документа
Формат портативного документа був форматом файлу, спочатку розробленим Adobe, який пізніше був випущений як відкритий стандарт. З тих пір він був широко прийнятий, оскільки він не залежить від основної операційної системи.
Отже, чому так складно проаналізувати PDF-файл і перетворити його вміст в інший формат? Наступні зображення говорять тисячу слів і підкажуть суть.
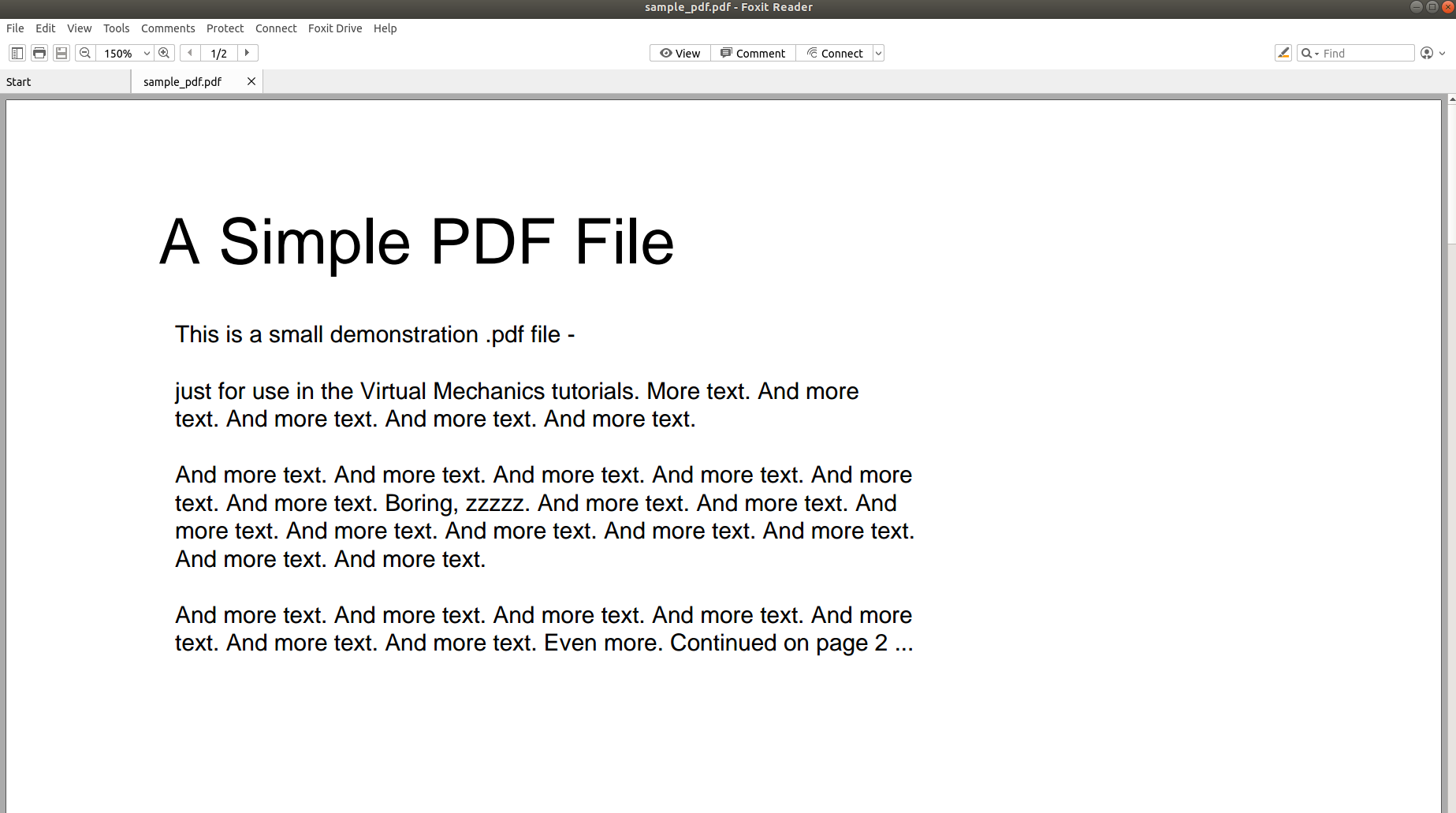
На зображенні вище показано знімок екрана PDF-документа, який відкривається за допомогою програми для читання PDF-файлів. Давайте спробуємо відкрити той самий PDF-документ за допомогою текстового редактора.
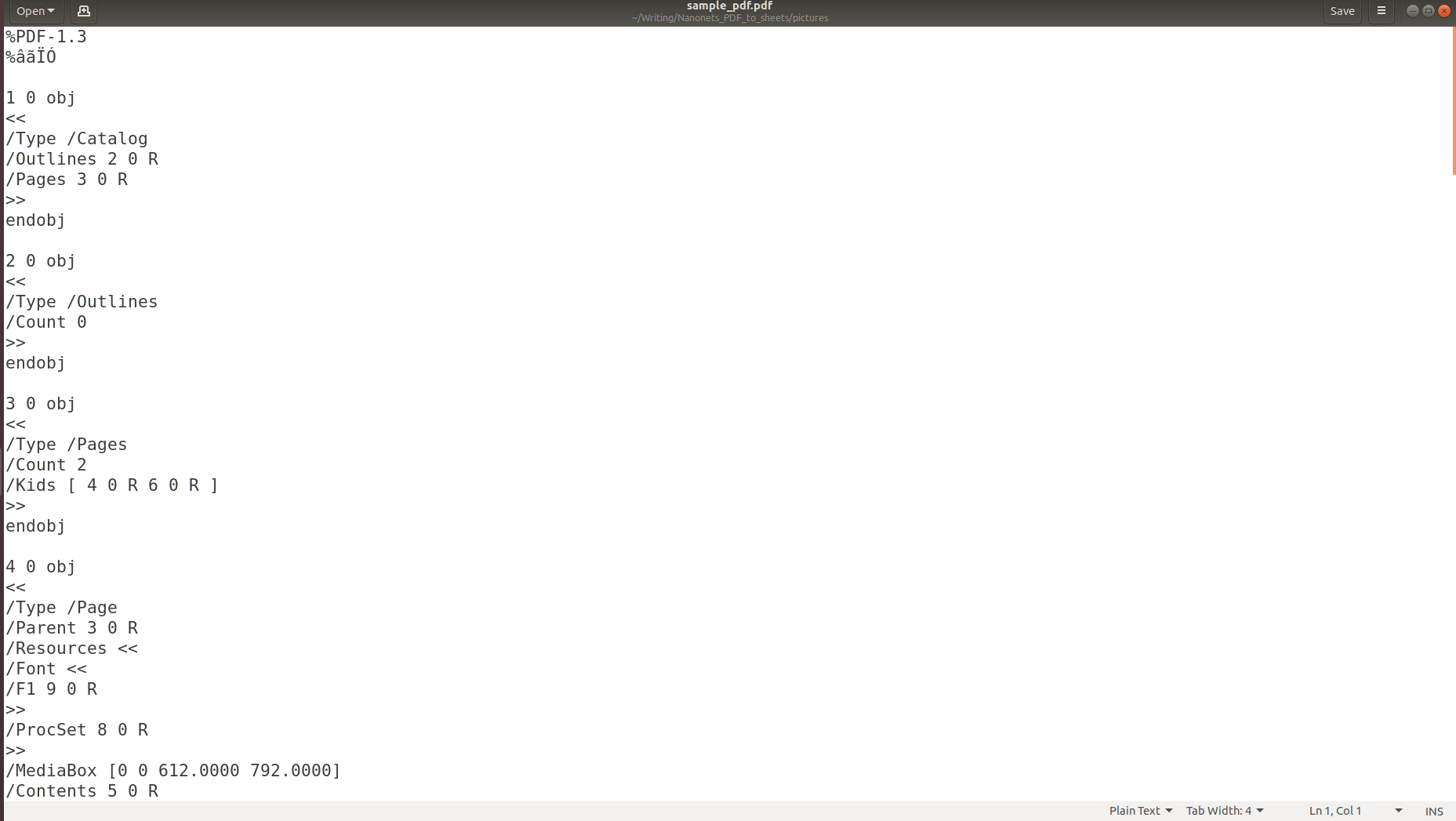
Наведені вище зображення показують, що коли інформація зберігається в PDF, її оригінальна структура повністю втрачається. Це пояснюється тим, що формат PDF складається лише з інструкцій щодо того, як надрукувати/малювати послідовність символів на сторінці.
Якщо ви вважаєте, що витягти текст складно, витягти дані, присутні в таблицях, ще складніше через широку різноманітність табличних форматів, які використовуються.
Сподіваємось, ви переконалися, що конвертувати PDF-документ у форму Google Sheets – це не просто прогулянка. У наступному розділі розповідається про підхід, використаний більшістю сучасних аналізаторів PDF для розпізнавання/аналізу інформації з документа PDF.
Сучасний підхід до аналізу PDF-документів
Більшість сучасних парсерів PDF використовують описаний нижче потік для аналізу неструктурованих даних із документів PDF.
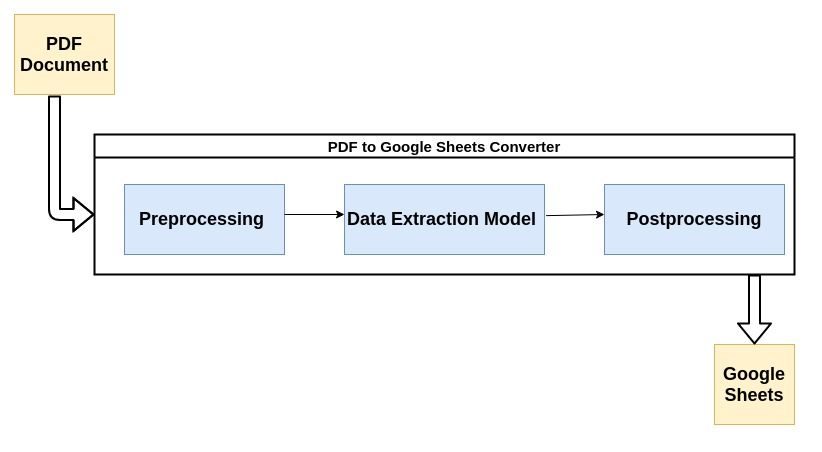
Давайте коротко розглянемо кожен етап процесу:
1. Попередня обробка або очищення даних:
Чим краще виглядатиме ваш PDF-файл, тим простіше буде для вашої моделі машинного навчання видобувати або захоплення даних з цього. Наприклад, якщо PDF-документ було відскановано, він обов’язково міститиме деякі артефакти сканування, які можуть вплинути на продуктивність конвертера.
Видалення шуму за допомогою відповідних фільтрів, бінаризація, корекція перекосу тощо є одними з найпоширеніших етапів попередньої обробки. Наступна публікація Nanonets Наномережі Tesseract Post містить чудові приклади попередньої обробки документів Оптичне розпізнавання символів(OCR) запускається на них.
Саме тут відбувається більшість магії. Вилучення даних зазвичай здійснюється за допомогою моделі машинного навчання (ML). Більшість моделей ML, які використовуються для вилучення даних із PDF-файлів, містять комбінацію інструментів оптичного розпізнавання символів, інструментів розпізнавання тексту та шаблонів тощо.
Для цілей цієї публікації ми можемо розглядати модель як чорний ящик, який приймає ваш PDF-документ як вхідні дані та викидає проаналізовану інформацію. Крім того, оскільки в його основі використовується ML, його можна перенавчити за допомогою спеціальних даних відповідно до сценарію використання вашої компанії.
3. Постобробка:
На цьому кроці витягнуті дані перетворюються в необхідний формат, наприклад CSV, XML, JSON тощо. Крім того, до прогнозів, зроблених ШІ, додаються додаткові правила, визначені користувачем. Це може включати правила для форматування виводу, додаткові обмеження щодо інформації, яка витягується тощо.
У наступному розділі розглядаються деякі показники, які ми можемо використовувати для вимірювання продуктивності аналізатора PDF.
Хочу конвертувати PDF файлів Google Таблиці ? Перевіряти Нанонець безкоштовно Конвертер PDF у CSV. Дізнайтеся, як автоматизувати весь робочий процес із PDF-файлів у Google Таблиці за допомогою Nanonets.

Показники для вимірювання продуктивності конвертера PDF
Оскільки більшість PDF-конвертерів використовуватимуться для обробки рахунків-фактур або пов’язаних завдань, точність і швидкість вилучення таблиці з PDF-документа є критичним фактором для оцінки продуктивності PDF-конвертера.
2. Багатомовність:
Більшість великих компаній зобов’язані отримувати рахунки кількома різними мовами. Синтаксичний аналізатор PDF має або підтримувати багатомовний синтаксичний аналіз із коробки, або він має забезпечувати опцію, за допомогою якої користувачі можуть навчати модель, використовуючи спеціальні дані.
3. Інтеграція з бухгалтерським програмним забезпеченням:
Ідеальний PDF-конвертер має бути модулем підключення та відтворення, який можна легко додати до наявного документообіг. Він має підтримувати інтеграцію з популярним бухгалтерським програмним забезпеченням, таким як QuickBooks, Xero, Wave тощо.
4. Легко та інтуїтивно зрозуміло:
Інструментом, швидше за все, керуватимуть нетехнічні користувачі. Було б вигідно, якби ним можна було керувати з мінімальними технічними знаннями.
Різні методи перетворення PDF-файлів у Google Таблиці
1. Використання Google Docs для перетворення PDF у Google Sheets
Диск Google має вбудовану можливість розпізнавати таблиці та текст у простих документах PDF. Вам просто потрібно:
-
Завантажте PDF-файл на Google Drive
-
Натисніть «Відкрити за допомогою Google Docs»
-
Скопіюйте потрібні дані та вставте в Google Таблиці
Хоча це, здається, працює добре, давайте спробуємо щось більш практичне. Розгляньте цей простий рахунок-фактуру.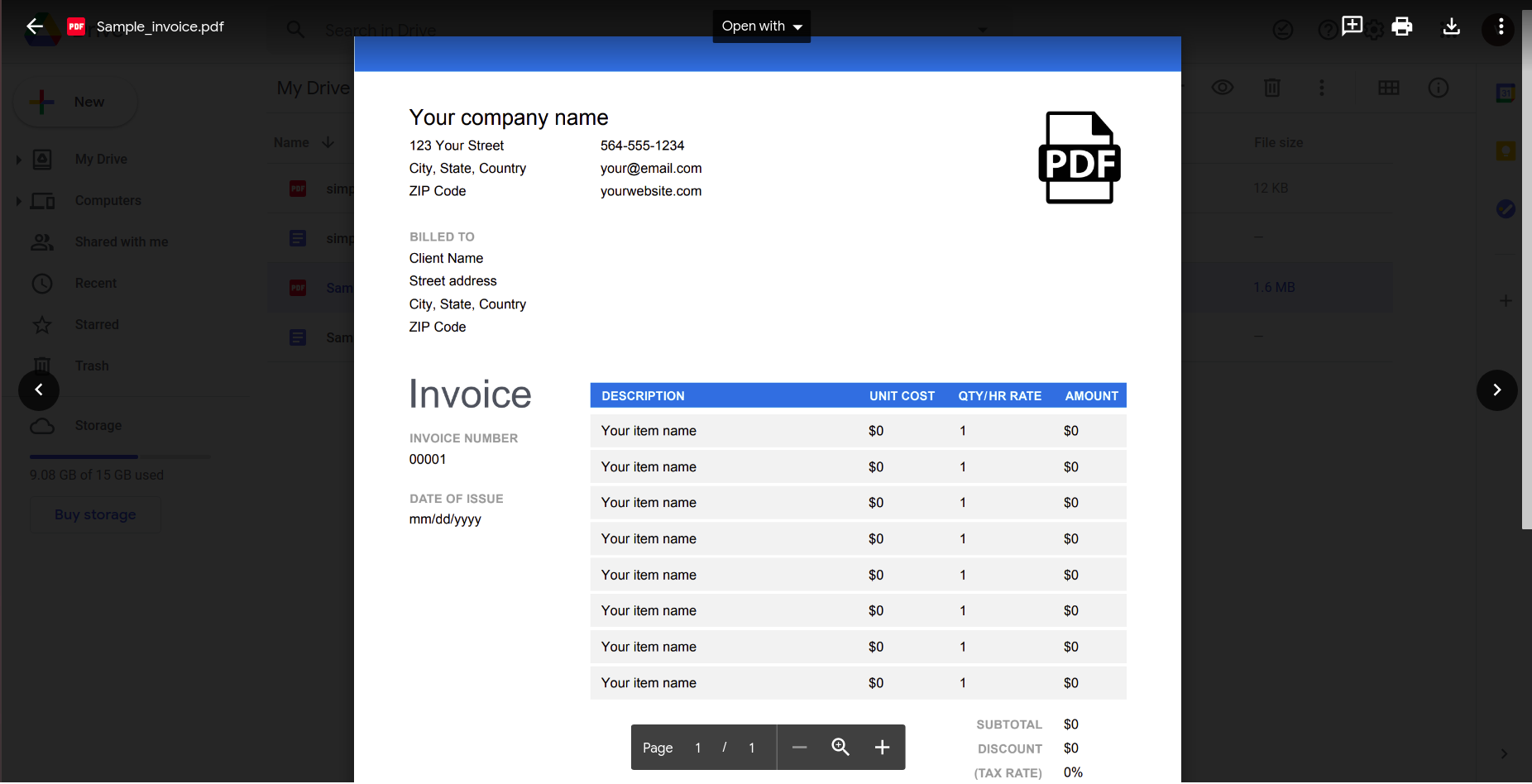
Відкриття цього за допомогою програми Google Документи дає такий результат.
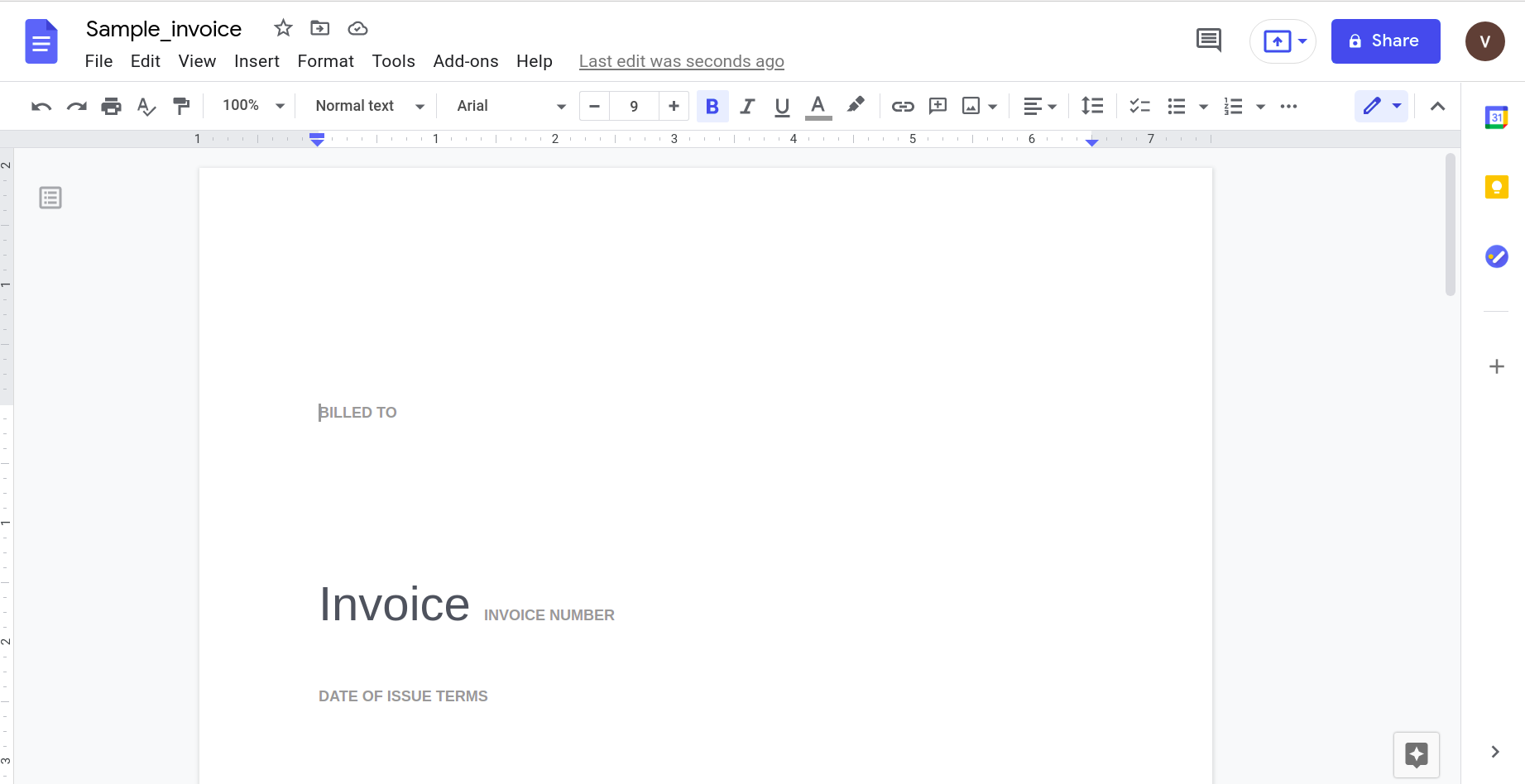
Очевидно, що зі збільшенням складності документа нам потрібно покладатися на більш складні інструменти для розпізнавання даних.
2. Використання онлайн-інструментів:
Декілька онлайн-інструментів, таких як екстрактор PDF-таблиць, Online2PDF тощо, безпосередньо інтегруються з Google Диском і надають готову можливість конвертувати PDF-документи в Google Таблиці.
Однак під час тестування цих інструментів за допомогою PDF-зразка рахунку-фактури, наведеного вище, у більшості випадків таблиці не виявлено.
Хочу конвертувати PDF файлів Google Таблиці ? Перевіряти Нанонець безкоштовно Конвертер PDF у CSV. Дізнайтеся, як автоматизувати весь робочий процес PDF-файлів у Google Таблиці за допомогою Nanonets, як показано нижче.
Автоматизація процесу перетворення PDF у Google Таблиці
Ми можемо повністю автоматизувати процес аналізу PDF-файлу та вилучення даних у форму Google Таблиць за допомогою наведених нижче інструментів.
1. Використання Webhooks:
Вебхуки – це настроювані запити HTTP. Зазвичай вони викликаються подією, тобто коли відбувається подія, програма надсилає інформацію за попередньо визначеною URL-адресою.
Як ви можете використовувати це для автоматизації робочого процесу? Розглянемо типовий випадок використання обробки рахунків-фактур. Ви отримуєте кілька рахунків-фактур від своїх постачальників і завантажуєте їх у свій конвертер PDF у Google Таблиці, який знаходиться в хмарі. Як дізнатися, що модель завершила обробку документів?
Замість того, щоб вручну перевіряти, чи завершено перетворення, ви можете просто скористатися веб-хуком, який сповістить вас, коли дані з PDF-файлу буде витягнуто в документ Google Sheets.
2. Використання API
API означає інтерфейс прикладного програмування. Використовуючи відповідні виклики API, конвертувати PDF-документи в Google Таблиці може виявитися так само просто, як написати такі рядки коду:
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Якщо ваша компанія вже налаштувала інтеграцію з Webhooks, ви отримаєте сповіщення, коли ваші PDF-документи буде успішно перетворено. Потім ви можете завантажити форму Google Sheets за допомогою API, показаного нижче.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF у Google Таблиці з Nanonets
Синтаксичний аналізатор Nanonets PDF робить аналіз і перетворення простим і точним. PDF-аналізатор використовувався для аналізу зразка рахунку-фактури. Цей розділ демонструє легкість використання та точність інструменту. Замість того, щоб говорити про те, наскільки це чудово, наступні зображення влучно ілюструють цю думку.
Наведене нижче зображення є знімком екрана зразка рахунка-фактури, який було передано аналізатору Nanonets PDF.
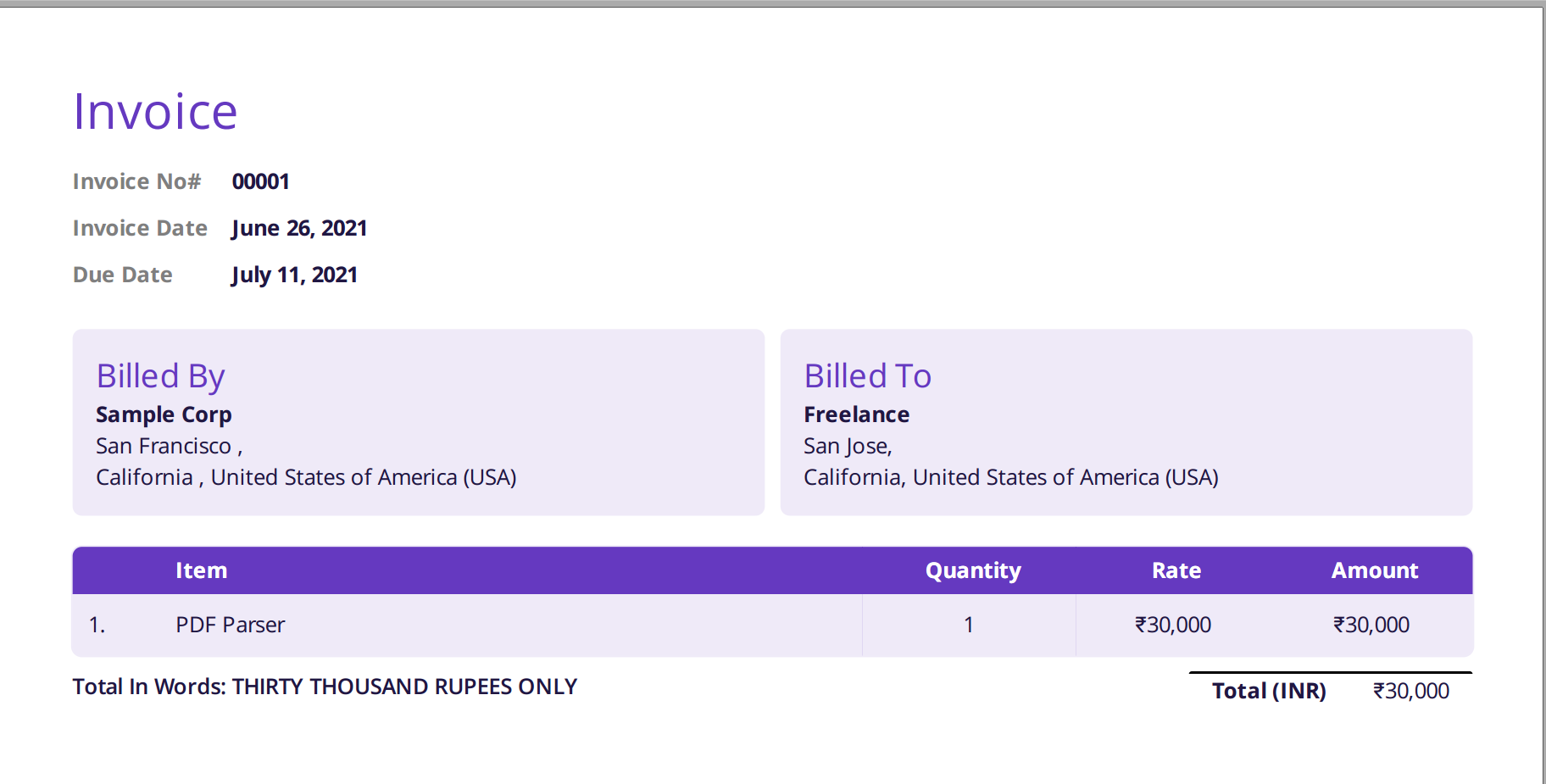
Просто перейдіть на веб-сайт Nanonets і завантажте рахунок-фактуру. Перетворення займає лише кілька секунд, після чого проаналізовані дані можна завантажити в різних форматах, наприклад CSV, XLSX тощо (перегляньте Nanonets' Конвертер PDF у CSV)
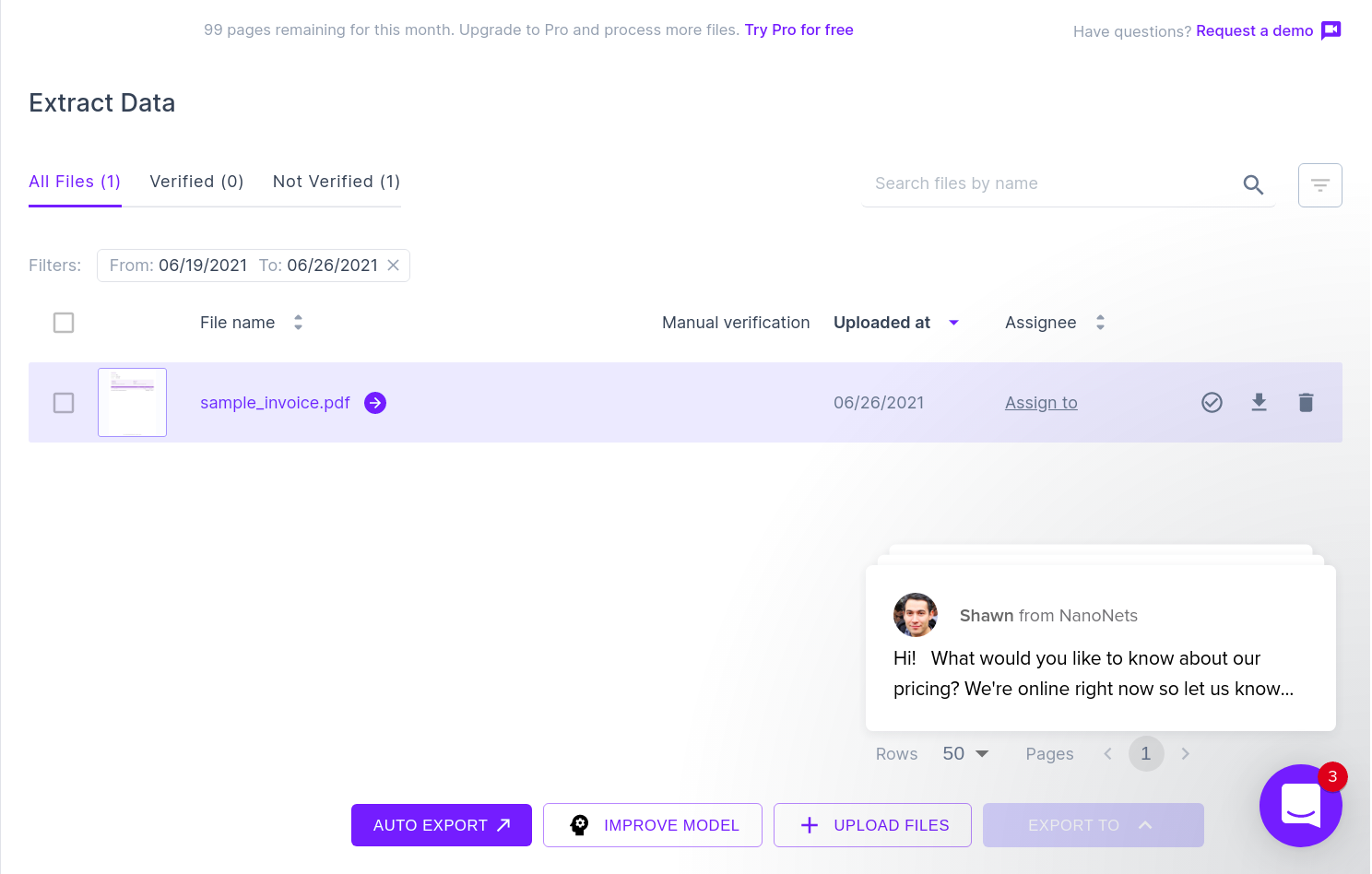
Наступне зображення показує знімок екрана файлу CSV, який містить проаналізовані дані з документа PDF.

Нарешті, щоб конвертувати файл CSV у форму таблиць Google, потрібно просто завантажити файл XLSX/CSV на свій диск Google. Цей крок можна автоматизувати за допомогою API диска Google.
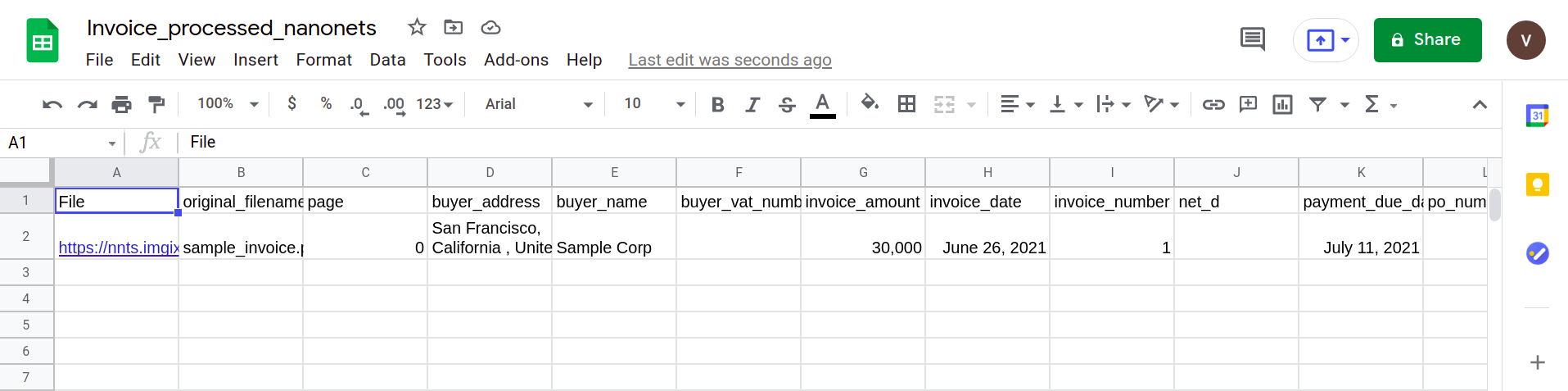
У наступному розділі показано, як можна створити простий конвеєр за допомогою аналізатора Nanonets PDF.
Хочете отримати інформацію з PDF-документів і перетворити/додати їх у документ Google Sheets? Перевірте Nanonets™ щоб автоматизувати експорт будь-якої інформації з будь-якого PDF-документа в Google Таблиці!
Створення простого конвеєра
1. Автоматично завантажуйте документи PDF за допомогою Nanonets API
API Nanonets дозволяє автоматично завантажувати документи, які потрібно проаналізувати. У наступному фрагменті коду показано, як це можна зробити за допомогою python.
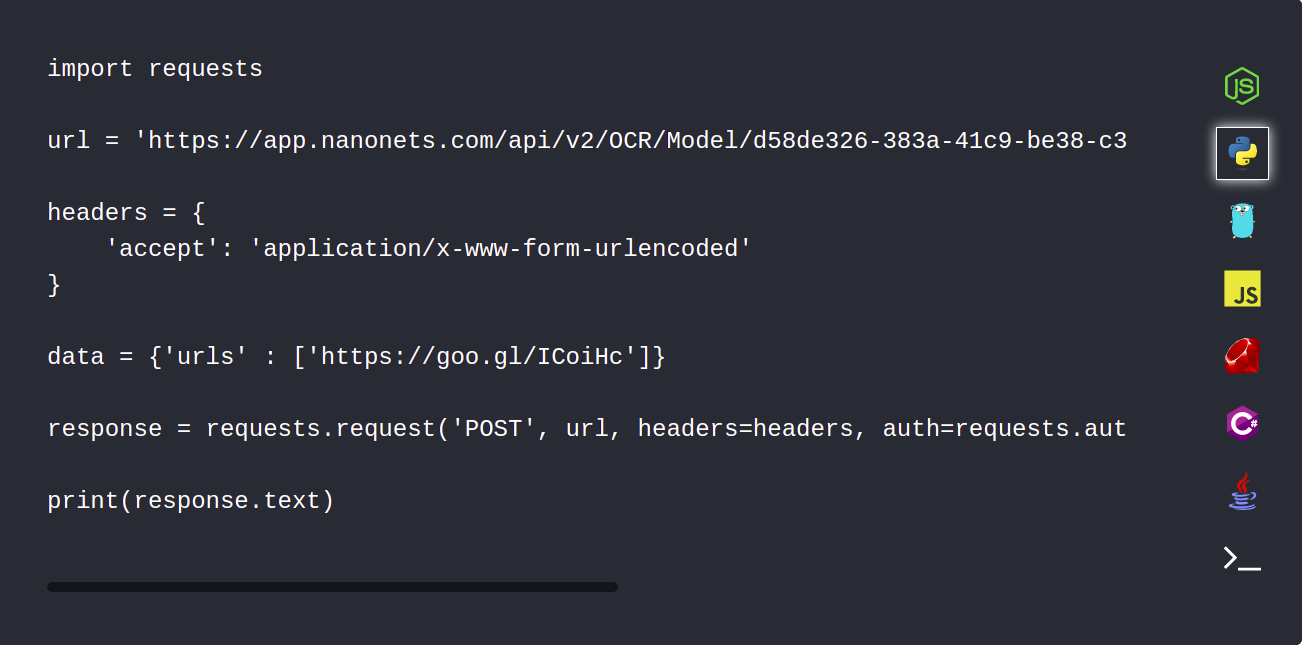
2. Використовуйте інтеграцію webhooks, щоб отримати сповіщення після завершення аналізу
Вебхуки можна налаштувати на автоматичне сповіщення після аналізу документів.
3. Перегляньте та завантажте в Google Таблиці
Завантажте та перегляньте файли CSV, щоб переконатися, що все в порядку, і завантажте дані в Google Таблиці за допомогою API Google Drive.
Край наномереж
Ось деякі функції Nanonets PDF Parser, які роблять його ідеальним інструментом для вашого бізнесу.
1. Зовнішні інтеграції:
Модель nanonets можна легко інтегрувати з MySql, Quickbooks, Salesforce тощо. Це означає, що ваш поточний робочий процес не заважає, а конвертер nanonets можна просто підключити як додатковий модуль.
2. Висока точність і низький час обробки:
Інструмент синтаксичного аналізу PDF Nanonets має точність понад 95%, що набагато вище, ніж у конкурентів.
3. Класні функції постобробки:
Припустімо, що ваша база даних інтегрована з моделлю наномереж. Модель автоматично заповнює деякі поля (даними з вашої бази даних) на основі даних, отриманих із документа. Наприклад:
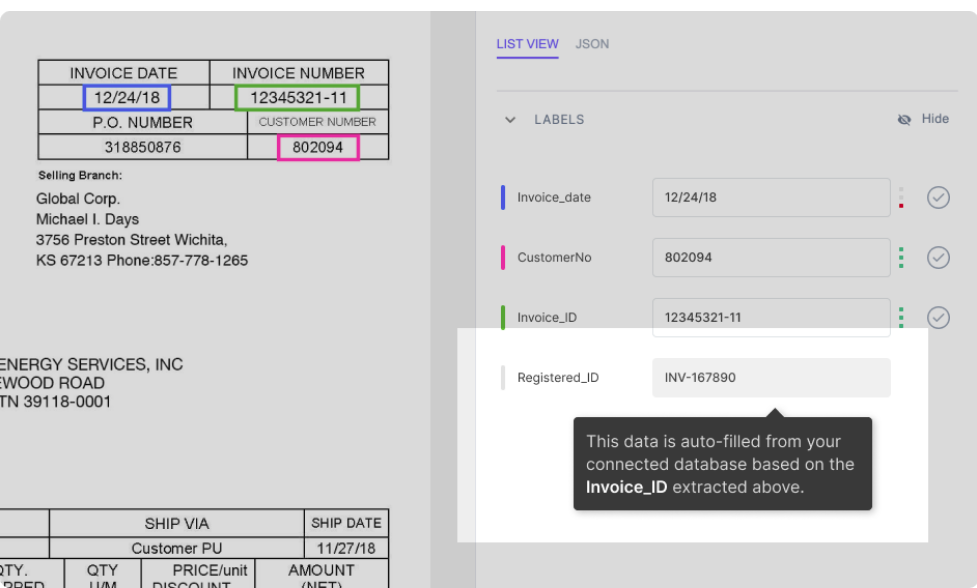
Як показано на малюнку, поле Registered_ID заповнюється автоматично (шляхом пошуку в базі даних) на основі Invoice_ID, витягнутого з PDF-файлу.
4. Простий та інтуїтивно зрозумілий інтерфейс
Хоча цю функцію недооцінюють, я вважаю, що інтерфейс і UX ідеальні. Весь процес реєстрації, завантаження документа та аналізу даних зайняв менше 5 хвилин. Це майже дорівнює часу, необхідному для завантаження мого ноутбука!
5. Величезна клієнтська база
Якщо у вас все ще є застереження щодо використання Nanonets для автоматизації робочого процесу, просто подивіться на деякі компанії, які користуються їхніми послугами.
- Deloitte
- Шервин Вільямс
- DoorDash
- P&G
Хочете отримати інформацію з PDF-документів і перетворити/додати їх у документ Google Sheets? Перевірте Nanonets™ щоб автоматизувати експорт будь-якої інформації з будь-якого PDF-документа в Google Таблиці!
Висновок
У цій публікації ми розглянули, як можна автоматизувати робочий процес за допомогою конвертера PDF у Google Таблиці. Спочатку ми дізналися про необхідність конвертації PDF-документів у Google Таблиці, а потім про труднощі, з якими зіткнулися під час цього процесу. Потім ми занурилися в підходи, які використовують сучасні парсери для аналізу PDF-документів, а також запровадили деякі загальні підходи. Ми також дізналися, як можна повністю автоматизувати перетворення за допомогою зовнішніх інтеграцій, таких як веб-хуки та API. Нарешті ми використали інструмент Nanonets для аналізу зразка рахунка-фактури, вилучення даних у форму Google Sheets, а також дослідили деякі з його чудових функцій постобробки.
Ви спробували модель Nanonets? Якщо так, залиште коментар нижче щодо свого досвіду роботи з інструментом. Якщо ні, спробуйте. Це може просто покращити ваш день!
- AI
- ШІ та машинне навчання
- ai мистецтво
- AI арт генератор
- ai робот
- штучний інтелект
- сертифікація штучного інтелекту
- штучний інтелект у банківській справі
- робот зі штучним інтелектом
- роботи зі штучним інтелектом
- програмне забезпечення для штучного інтелекту
- blockchain
- блокчейн конференція AI
- coingenius
- розмовний штучний інтелект
- крипто конференція ai
- dall's
- глибоке навчання
- у вас є гугл
- навчання за допомогою машини
- pdf в Google таблиці
- plato
- платон ai
- Інформація про дані Платона
- Гра Платон
- PlatoData
- platogaming
- масштаб ai
- синтаксис
- зефірнет