Цю публікацію написано спільно з Махімою Агарвал, інженером з машинного навчання, та Діпаком Меттемом, старшим менеджером з інженерних питань у VMware Carbon Black
VMware Carbon Black це відоме рішення безпеки, яке пропонує захист від повного спектру сучасних кібератак. Маючи терабайти даних, згенерованих продуктом, команда аналітики безпеки зосереджується на розробці рішень машинного навчання (ML), щоб виявити критичні атаки та виділити нові загрози від шуму.
Для команди VMware Carbon Black надзвичайно важливо розробити та створити спеціальний наскрізний конвеєр MLOps, який організовує та автоматизує робочі процеси в життєвому циклі ML і забезпечує навчання моделі, оцінку та розгортання.
Існує дві основні мети створення цього конвеєра: підтримка дослідників даних для розробки моделі на пізній стадії та прогнозування поверхневих моделей у продукті шляхом обслуговування моделей у великих обсягах і в робочому трафіку в реальному часі. Тому VMware Carbon Black і AWS вирішили побудувати спеціальний конвеєр MLOps за допомогою Amazon SageMaker за простоту використання, універсальність і повністю керовану інфраструктуру. Ми організовуємо наші конвеєри навчання та розгортання ML за допомогою Керовані робочі процеси Amazon для Apache Airflow (Amazon MWAA), що дозволяє нам більше зосередитися на програмному створенні робочих процесів і конвеєрів, не турбуючись про автоматичне масштабування чи обслуговування інфраструктури.
Завдяки цьому конвеєру те, що колись було дослідженням машинного навчання на базі ноутбуків Jupyter, тепер є автоматизованим процесом розгортання моделей у виробництві з невеликим ручним втручанням спеціалістів із обробки даних. Раніше процес навчання, оцінки та розгортання моделі міг зайняти більше дня; за допомогою цієї реалізації все є лише одним тригером і скоротило загальний час до кількох хвилин.
У цій публікації архітектори VMware Carbon Black і AWS обговорюють, як ми створювали та керували користувальницькими робочими процесами ML за допомогою Гітлаб, Amazon MWAA та SageMaker. Ми обговорюємо, чого ми вже досягли, подальші вдосконалення конвеєра та уроки, отримані на цьому шляху.
Огляд рішення
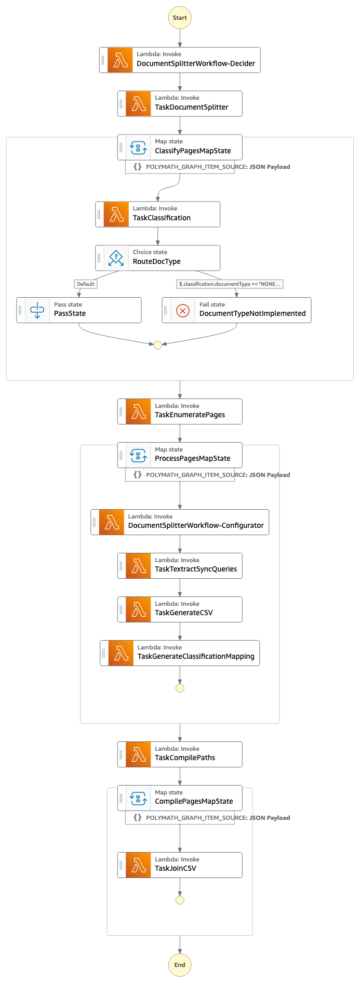
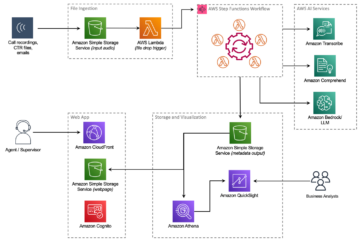
Наступна діаграма ілюструє архітектуру платформи ML.

Дизайн рішення високого рівня
Цю платформу ML було передбачено та розроблено для використання різними моделями в різних сховищах коду. Наша команда використовує GitLab як інструмент керування вихідним кодом для підтримки всіх сховищ коду. Будь-які зміни у вихідному коді репозиторію моделі постійно інтегруються за допомогою Gitlab CI, який викликає подальші робочі процеси в конвеєрі (навчання моделі, оцінка та розгортання).
Наступна діаграма архітектури ілюструє наскрізний робочий процес і компоненти, задіяні в нашому конвеєрі MLOps.

Наскрізний робочий процес
Конвеєри навчання, оцінки та розгортання моделі ML організовані за допомогою Amazon MWAA, що називається Направлений ациклічний графік (DAG). DAG — це сукупність завдань, упорядкованих із залежностями та зв’язками, які визначають, як вони мають виконуватися.
На високому рівні архітектура рішення включає три основні компоненти:
- Репозиторій конвеєрного коду ML
- Конвеєр навчання та оцінювання моделі ML
- Конвеєр розгортання моделі ML
Давайте обговоримо, як цими різними компонентами керують і як вони взаємодіють один з одним.
Репозиторій конвеєрного коду ML
Після того, як репозиторій моделі інтегрує репозиторій MLOps як їхній низхідний конвеєр, а фахівець із обробки даних фіксує код у своєму репозиторії моделі, бігун GitLab виконує стандартну перевірку коду та тестування, визначені в цьому репозиторії, і запускає конвеєр MLOps на основі змін коду. Ми використовуємо багатопроектний конвеєр Gitlab, щоб увімкнути цей тригер у різних сховищах.
Конвеєр MLOps GitLab проходить певний набір етапів. Він проводить базову перевірку коду за допомогою pylint, упаковує навчальний код моделі та код висновку в образ Docker і публікує зображення контейнера в Реєстр контейнерів Amazon Elastic (Amazon ECR). Amazon ECR — це повністю керований реєстр контейнерів, який пропонує високопродуктивний хостинг, тож ви можете надійно розгортати образи програм і артефакти будь-де.
Конвеєр навчання та оцінювання моделі ML
Після публікації зображення запускається навчання та оцінка Потік повітря Apache трубопроводу через в AWS Lambda функція. Lambda — це безсерверний обчислювальний сервіс, керований подіями, який дозволяє запускати код практично для будь-якого типу додатків або серверних служб без підготовки та керування серверами.
Після успішного запуску конвеєра запускається DAG навчання та оцінки, яка, у свою чергу, запускає навчання моделі в SageMaker. Наприкінці цього конвеєра навчання ідентифікована група користувачів отримує сповіщення з результатами навчання та оцінювання моделі електронною поштою через Служба простих сповіщень Amazon (Amazon SNS) і Slack. Amazon SNS — це повністю керована служба pub/sub для обміну повідомленнями A2A та A2P.
Після ретельного аналізу результатів оцінки фахівець із обробки даних або інженер ML може розгорнути нову модель, якщо продуктивність нової навченої моделі є кращою порівняно з попередньою версією. Продуктивність моделей оцінюється на основі специфічних для моделі показників (таких як оцінка F1, MSE або матриця плутанини).
Конвеєр розгортання моделі ML
Щоб розпочати розгортання, користувач запускає завдання GitLab, яке запускає DAG розгортання через ту саму функцію Lambda. Після успішного запуску конвеєра створюється або оновлюється кінцева точка SageMaker за допомогою нової моделі. Це також надсилає сповіщення з деталями кінцевої точки електронною поштою за допомогою Amazon SNS і Slack.
У разі збою в будь-якому з конвеєрів користувачі отримують сповіщення через ті самі канали зв’язку.
SageMaker пропонує логічний висновок у реальному часі, який ідеально підходить для робочих навантажень логічного висновку з низькою затримкою та високими вимогами до пропускної здатності. Ці кінцеві точки повністю керовані, з балансуванням навантаження та автоматичним масштабуванням і можуть бути розгорнуті в кількох зонах доступності для високої доступності. Наш конвеєр створює таку кінцеву точку для моделі після її успішного запуску.
У наступних розділах ми розглянемо різні компоненти та зануримося в деталі.
GitLab: моделі пакетів і тригерні конвеєри
Ми використовуємо GitLab як репозиторій коду та для конвеєра для упаковки коду моделі та запуску DAG Airflow.
Мультипроектний конвеєр
Функція конвеєра GitLab для кількох проектів використовується, коли батьківський конвеєр (вгорі) є репозиторієм моделі, а дочірній конвеєр (вниз) є репо MLOps. Кожне репо зберігає .gitlab-ci.yml, а наступний блок коду, активований у вихідному конвеєрі, запускає низхідний конвеєр MLOps.
Вихідний конвеєр надсилає код моделі в нижній конвеєр, де запускаються завдання CI пакування та публікації. Код для контейнеризації коду моделі та публікації його в Amazon ECR підтримується та керується конвеєром MLOps. Він надсилає такі змінні, як ACCESS_TOKEN (можна створити в Налаштування, доступу), змінні JOB_ID (для доступу до артефактів висхідного потоку) і $CI_PROJECT_ID (ідентифікатор проекту репо моделі), щоб конвеєр MLOps міг отримати доступ до файлів коду моделі. З артефакти роботи функція від Gitlab, сховище нижнього потоку отримує доступ до віддалених артефактів за допомогою такої команди:
Репозиторій моделі може споживати низхідні конвеєри для кількох моделей з того самого репо, розширюючи етап, який запускає його за допомогою продовжується ключове слово від GitLab, яке дозволяє повторно використовувати ту саму конфігурацію на різних етапах.
Після публікації зображення моделі в Amazon ECR конвеєр MLOps запускає конвеєр навчання Amazon MWAA за допомогою Lambda. Після схвалення користувача він також запускає конвеєр розгортання моделі Amazon MWAA за допомогою тієї самої функції Lambda.
Семантичне керування версіями та передача версій вниз
Ми розробили спеціальний код для версії зображень ECR і моделей SageMaker. Конвеєр MLOps керує семантичною логікою керування версіями для зображень і моделей як частину етапу, на якому код моделі контейнеризується, і передає версії на наступні етапи як артефакти.
Перепідготовка
Оскільки перенавчання є ключовим аспектом життєвого циклу машинного навчання, ми запровадили можливості перенавчання як частину нашої розробки. Ми використовуємо API списку моделей SageMaker, щоб визначити, чи відбувається повторне навчання, на основі номера версії повторного навчання моделі та позначки часу.
Ми ведемо щоденний графік конвеєра перепідготовки за допомогою Конвеєри розкладу GitLab.
Terraform: налаштування інфраструктури
Окрім кластера Amazon MWAA, сховищ ECR, функцій Lambda та теми SNS, це рішення також використовує Управління ідентифікацією та доступом AWS (IAM) ролі, користувачі та політики; Служба простого зберігання Amazon (Amazon S3) відра та an Amazon CloudWatch журнал експедитор.
Щоб оптимізувати налаштування і обслуговування інфраструктури для послуг, задіяних у нашій системі, ми використовуємо Terraform реалізувати інфраструктуру як код. Щоразу, коли потрібні інфраоновлення, зміни коду запускають налаштований нами конвеєр GitLab CI, який перевіряє та розгортає зміни в різних середовищах (наприклад, додавання дозволу до політики IAM в облікових записах dev, stage і prod).
Amazon ECR, Amazon S3 і Lambda: спрощення конвеєра
Ми використовуємо такі ключові послуги, щоб полегшити наш конвеєр:
- Amazon ECR – Щоб підтримувати та дозволяти зручний пошук зображень контейнерів моделі, ми позначаємо їх семантичними версіями та завантажуємо їх до сховищ ECR, налаштованих відповідно до
${project_name}/${model_name}через Terraform. Це забезпечує хороший рівень ізоляції між різними моделями та дозволяє нам використовувати користувацькі алгоритми та форматувати запити на висновок і відповіді, щоб включати бажану інформацію про маніфест моделі (назва моделі, версія, шлях навчальних даних тощо). - Amazon S3 – Ми використовуємо сегменти S3 для збереження даних навчання моделі, навчених артефактів моделі на модель, груп DAG Airflow та іншої додаткової інформації, необхідної для конвеєрів.
- Лямбда – Оскільки з міркувань безпеки наш кластер Airflow розгорнуто в окремому VPC, напряму отримати доступ до DAG неможливо. Тому ми використовуємо функцію Lambda, яка також підтримується Terraform, щоб запускати будь-які DAG, визначені назвою DAG. При правильному налаштуванні IAM завдання GitLab CI запускає функцію Lambda, яка передає конфігурації аж до запитаних DAG для навчання або розгортання.
Amazon MWAA: конвеєри навчання та розгортання
Як згадувалося раніше, ми використовуємо Amazon MWAA для організації конвеєрів навчання та розгортання. Ми використовуємо оператори SageMaker, доступні в Пакет постачальника Amazon для Airflow для інтеграції з SageMaker (щоб уникнути шаблонів jinja).
Ми використовуємо такі оператори в цьому навчальному конвеєрі (показано на наступній схемі робочого процесу):

Конвеєр навчання MWAA
Ми використовуємо такі оператори в конвеєрі розгортання (показано на наступній схемі робочого процесу):

Конвеєр розгортання моделі
Ми використовуємо Slack і Amazon SNS для публікації повідомлень про помилки/успіх і результатів оцінювання в обох конвеєрах. Slack надає широкий спектр параметрів для налаштування повідомлень, зокрема:
- SnsPublishOperator - Ми використовуємо SnsPublishOperator для надсилання повідомлень про успіх/невдачу на електронну пошту користувачів
- Slack API – Ми створили URL-адреса вхідного вебхуку щоб отримати конвеєрні сповіщення на потрібний канал
CloudWatch і VMware Wavefront: моніторинг і журналювання
Ми використовуємо інформаційну панель CloudWatch для налаштування моніторингу кінцевої точки та журналювання. Це допомагає візуалізувати та відстежувати різноманітні операційні показники та показники ефективності моделі, специфічні для кожного проекту. Окрім політик автоматичного масштабування, налаштованих для відстеження деяких із них, ми постійно відстежуємо зміни у використанні ЦП і пам’яті, кількість запитів за секунду, затримки відповіді та показники моделі.
CloudWatch навіть інтегровано з інформаційною панеллю VMware Tanzu Wavefront, щоб він міг візуалізувати показники кінцевих точок моделі, а також інші служби на рівні проекту.
Переваги для бізнесу та що далі
Конвеєри ML дуже важливі для послуг і функцій ML. У цій публікації ми обговорили наскрізний варіант використання можливостей ML із використанням можливостей AWS. Ми створили спеціальний конвеєр за допомогою SageMaker і Amazon MWAA, який ми можемо повторно використовувати в проектах і моделях, і автоматизували життєвий цикл машинного навчання, що скоротило час від навчання моделі до розгортання виробництва всього до 10 хвилин.
З перенесенням тягаря життєвого циклу машинного навчання на SageMaker він забезпечив оптимізовану та масштабовану інфраструктуру для навчання та розгортання моделі. Обслуговування моделі за допомогою SageMaker допомогло нам робити прогнози в реальному часі з мілісекундними затримками та можливостями моніторингу. Ми використовували Terraform для простоти налаштування та керування інфраструктурою.
Наступні кроки для цього конвеєра полягатимуть у вдосконаленні конвеєра навчання моделей за допомогою можливостей перенавчання, незалежно від того, здійснюється воно за розкладом або на основі виявлення дрейфу моделі, підтримки тіньового розгортання або A/B-тестування для швидшого та кваліфікованого розгортання моделі та відстеження походження ML. Також плануємо оцінити Трубопроводи Amazon SageMaker оскільки тепер підтримується інтеграція GitLab.
Уроки, витягнуті
Розробляючи це рішення, ми дізналися, що узагальнювати слід на ранній стадії, але не надто узагальнюйте. Коли ми вперше завершили проектування архітектури, ми спробували створити та застосувати шаблони коду для коду моделі як найкращу практику. Однак процес розробки був настільки раннім, що шаблони були або надто узагальненими, або надто деталізованими, щоб їх можна було повторно використовувати для майбутніх моделей.
Після доставки першої моделі в конвеєр, шаблони вийшли природним шляхом на основі ідей нашої попередньої роботи. Трубопровід не може зробити все з першого дня.
Вимоги до експериментування та виробництва моделі часто дуже різні (а іноді навіть суперечливі). Вкрай важливо збалансувати ці вимоги з самого початку як команда та відповідно розставити пріоритети.
Крім того, вам можуть знадобитися не всі функції служби. Використання важливих функцій служби та модульний дизайн є ключем до більш ефективної розробки та гнучкої конвеєрної обробки.
Висновок
У цій публікації ми показали, як ми створили рішення MLOps за допомогою SageMaker і Amazon MWAA, яке автоматизувало процес розгортання моделей у виробництві з невеликим ручним втручанням спеціалістів з обробки даних. Ми рекомендуємо вам оцінити різні сервіси AWS, такі як SageMaker, Amazon MWAA, Amazon S3 і Amazon ECR, щоб створити повне рішення MLOps.
*Apache, Apache Airflow і Airflow є зареєстрованими товарними знаками або товарними знаками Apache Software Foundation в США та / або інших країнах.
Про авторів
 Діпак Меттем є старшим інженерним менеджером у VMware, відділ сажі. Він і його команда працюють над створенням додатків і служб на основі потокового передавання, які є високодоступними, масштабованими та стійкими, щоб надавати клієнтам рішення на основі машинного навчання в режимі реального часу. Він і його команда також відповідають за створення інструментів, необхідних для науковців з обробки даних для створення, навчання, розгортання та перевірки своїх моделей машинного навчання у виробництві.
Діпак Меттем є старшим інженерним менеджером у VMware, відділ сажі. Він і його команда працюють над створенням додатків і служб на основі потокового передавання, які є високодоступними, масштабованими та стійкими, щоб надавати клієнтам рішення на основі машинного навчання в режимі реального часу. Він і його команда також відповідають за створення інструментів, необхідних для науковців з обробки даних для створення, навчання, розгортання та перевірки своїх моделей машинного навчання у виробництві.
 Махіма Агарвал є інженером машинного навчання у VMware, відділ сажі.
Махіма Агарвал є інженером машинного навчання у VMware, відділ сажі.
Вона працює над проектуванням, створенням і розробкою основних компонентів і архітектури платформи машинного навчання для VMware CB SBU.
 Вамші Крішна Енаботала є старшим архітектором із прикладного штучного інтелекту в AWS. Він працює з клієнтами з різних секторів, щоб прискорити ефективні дані, аналітику та ініціативи машинного навчання. Він захоплюється системами рекомендацій, НЛП і областями комп’ютерного зору в штучному інтелекті та машинному обігу. Поза роботою Вамші є ентузіастом радіоуправляного керування, будує обладнання для радіоуправління (літаки, автомобілі та дрони), а також захоплюється садівництвом.
Вамші Крішна Енаботала є старшим архітектором із прикладного штучного інтелекту в AWS. Він працює з клієнтами з різних секторів, щоб прискорити ефективні дані, аналітику та ініціативи машинного навчання. Він захоплюється системами рекомендацій, НЛП і областями комп’ютерного зору в штучному інтелекті та машинному обігу. Поза роботою Вамші є ентузіастом радіоуправляного керування, будує обладнання для радіоуправління (літаки, автомобілі та дрони), а також захоплюється садівництвом.
 Сахіл Тапар є архітектором корпоративних рішень. Він працює з клієнтами, щоб допомогти їм створити високодоступні, масштабовані та стійкі додатки в AWS Cloud. Зараз він зосереджений на контейнерах і рішеннях машинного навчання.
Сахіл Тапар є архітектором корпоративних рішень. Він працює з клієнтами, щоб допомогти їм створити високодоступні, масштабовані та стійкі додатки в AWS Cloud. Зараз він зосереджений на контейнерах і рішеннях машинного навчання.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :є
- $UP
- 1
- 10
- 100
- 7
- 8
- a
- МЕНЮ
- прискорювати
- доступ
- доступний
- відповідно
- Рахунки
- досягнутий
- через
- ациклічні
- доповнення
- Додатковий
- Додаткова інформація
- після
- проти
- AI
- алгоритми
- ВСІ
- дозволяє
- Amazon
- Amazon SageMaker
- аналіз
- аналітика
- та
- де-небудь
- Apache
- API
- додаток
- застосування
- прикладної
- Прикладний ШІ
- твердження
- архітектура
- ЕСТЬ
- області
- AS
- зовнішній вигляд
- At
- нападки
- авторство
- автоматичний
- Автоматизований
- автоматизує
- наявність
- доступний
- уникнути
- AWS
- Backend
- Balance
- заснований
- основний
- BE
- оскільки
- початок
- Переваги
- КРАЩЕ
- Краще
- між
- Black
- Блокувати
- Філія
- приносити
- будувати
- Створюємо
- побудований
- тягар
- by
- CAN
- не може
- можливості
- вуглець
- автомобілів
- випадок
- CB
- певний
- Зміни
- канали
- дитина
- вибрав
- хмара
- кластер
- код
- збір
- Комунікація
- порівняний
- повний
- Компоненти
- обчислення
- комп'ютер
- Комп'ютерне бачення
- проводить
- конфігурація
- конфігурації
- Конфлікти
- замішання
- міркування
- споживати
- спожитий
- Контейнер
- Контейнери
- постійно
- Зручний
- Core
- може
- країни
- центральний процесор
- створювати
- створений
- створює
- створення
- критичний
- вирішальне значення
- В даний час
- виготовлений на замовлення
- Клієнти
- налаштувати
- кібератаки
- DAG
- щодня
- приладова панель
- дані
- вчений даних
- день
- певний
- надання
- розгортання
- розгорнути
- розгортання
- розгортання
- розгортання
- розгортає
- дизайн
- призначений
- проектування
- докладно
- деталі
- Виявлення
- DEV
- розвиненою
- розвивається
- розробка
- різний
- безпосередньо
- обговорювати
- обговорювалися
- Docker
- Не знаю
- вниз
- Дронів
- кожен
- Раніше
- Рано
- простота використання
- ефективний
- або
- з'являються
- включіть
- включений
- дозволяє
- заохочувати
- кінець в кінець
- Кінцева точка
- інженер
- Машинобудування
- підприємство
- Рішення для підприємств
- ентузіаст
- середовищах
- обладнання
- істотний
- Ефір (ETH)
- оцінювати
- оцінюється
- оцінки
- оцінка
- оцінки
- Навіть
- Event
- Кожен
- все
- приклад
- Розширювати
- розширення
- f1
- фасилітувати
- Провал
- далеко
- швидше
- особливість
- риси
- кілька
- Файли
- Перший
- гнучкий
- Сфокусувати
- увагу
- фокусується
- після
- для
- формат
- від
- Повний
- Повний спектр
- повністю
- функція
- Функції
- далі
- майбутнє
- генерується
- отримати
- добре
- Group
- Мати
- має
- допомога
- допоміг
- допомагає
- Високий
- висока продуктивність
- дуже
- хостинг
- Як
- Однак
- HTML
- HTTP
- HTTPS
- IAM
- ID
- ідеальний
- ідентифікований
- ідентифікувати
- Особистість
- зображення
- зображень
- здійснювати
- реалізація
- реалізовані
- in
- включати
- includes
- У тому числі
- інформація
- Інфраструктура
- ініціативи
- розуміння
- інтегрувати
- інтегрований
- Інтеграція
- інтеграція
- взаємодіяти
- втручання
- викликає
- залучений
- ізоляція
- IT
- ЙОГО
- робота
- Джобс
- JPG
- тримати
- ключ
- ключі
- Затримка
- шар
- вчений
- вивчення
- Уроки
- Уроки, витягнуті
- дозволяє
- рівень
- Життєвий цикл
- як
- трохи
- загрузка
- низький
- машина
- навчання за допомогою машини
- головний
- підтримувати
- підтримує
- обслуговування
- зробити
- управляти
- вдалося
- управління
- менеджер
- управляє
- управління
- керівництво
- Матриця
- пам'ять
- згаданий
- повідомлення
- обмін повідомленнями
- Метрика
- може бути
- мілісекунда
- протокол
- ML
- MLOps
- модель
- Моделі
- сучасний
- монітор
- моніторинг
- більше
- більш ефективний
- множинний
- ім'я
- природно
- необхідно
- Необхідність
- Нові
- наступний
- nlp
- шум
- сповіщення
- Повідомлення
- номер
- of
- пропонує
- Пропозиції
- on
- ONE
- оперативний
- Оператори
- оптимізований
- Опції
- організував
- Організований
- Інше
- поза
- загальний
- пакет
- пакети
- упаковка
- частина
- проходить
- Проходження
- пристрасний
- шлях
- продуктивність
- дозвіл
- трубопровід
- план
- Літаки
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- Політика
- політика
- пошта
- практика
- Прогнози
- попередній
- Пріоритетність
- процес
- Product
- Production
- проект
- проектів
- правильний
- захист
- за умови
- Постачальник
- забезпечує
- публікувати
- опублікований
- Видає
- Видавничий
- цілей
- кваліфікований
- діапазон
- реального часу
- Рекомендація
- Знижений
- називають
- зареєстрований
- реєстру
- Відносини
- віддалений
- Знаменитий
- Сховище
- просив
- запитів
- вимагається
- Вимога
- дослідження
- пружний
- відповідь
- відповідальний
- результати
- перепідготовка
- багаторазовий
- ролі
- прогін
- бігун
- мудрець
- то ж
- масштабовані
- Масштабування
- розклад
- плановий
- вчений
- Вчені
- другий
- розділам
- Сектори
- безпеку
- старший
- окремий
- Без сервера
- Сервери
- обслуговування
- Послуги
- виступаючої
- комплект
- установка
- тінь
- ПЕРЕМІЩЕННЯ
- Повинен
- показаний
- простий
- слабкий
- So
- так далеко
- Софтвер
- рішення
- Рішення
- деякі
- Source
- вихідні
- спеціаліст
- конкретний
- зазначений
- спектр
- Прожектор
- Стажування
- етапи
- standard
- старт
- починається
- Штати
- заходи
- зберігання
- Стратегія
- потоковий
- раціоналізувати
- наступні
- Успішно
- такі
- підтримка
- Підтриманий
- поверхню
- Systems
- TAG
- Приймати
- завдання
- команда
- Шаблони
- Terraform
- Тестування
- Що
- Команда
- їх
- Їх
- отже
- Ці
- загрози
- три
- через
- по всьому
- пропускна здатність
- час
- відмітка часу
- до
- разом
- занадто
- інструмент
- інструменти
- топ
- тема
- трек
- Відстеження
- торговельні марки
- трафік
- поїзд
- навчений
- Навчання
- викликати
- спрацьовує
- ПЕРЕГЛЯД
- при
- блок
- United
- Сполучені Штати
- Updates
- us
- Використання
- використання
- використання випадку
- користувач
- користувачі
- ПЕРЕВІР
- перевірка достовірності
- змінні
- різний
- версія
- фактично
- бачення
- візуалізувати
- VMware
- обсяг
- шлях..
- ДОБРЕ
- Що
- Чи
- який
- широкий
- Широкий діапазон
- з
- в
- без
- Work
- робочий
- Робочі процеси
- працює
- б
- зефірнет
- Zip
- зони