Великі моделі трансформаторів, орієнтовані на увагу, отримали величезні переваги в обробці природної мови (NLP). Однак навчання цих гігантських мереж з нуля вимагає величезної кількості даних і обчислень. Для менших наборів даних НЛП проста, але ефективна стратегія полягає у використанні попередньо навченого трансформатора, який зазвичай навчається без нагляду на дуже великих наборах даних, і точно налаштувати його на цікавий набір даних. Обіймати обличчя підтримує великий модельний зоопарк цих попередньо навчених трансформерів і робить їх легкодоступними навіть для початківців користувачів.
Однак для точного налаштування цих моделей все ще потрібні знання експертів, оскільки вони досить чутливі до своїх гіперпараметрів, таких як швидкість навчання або розмір пакету. У цій публікації ми покажемо, як оптимізувати ці гіперпараметри за допомогою фреймворка з відкритим кодом Мелодія Syne для оптимізації розподілених гіперпараметрів (HPO). Syne Tune дозволяє нам знайти кращу конфігурацію гіперпараметрів, яка досягає відносного покращення на 1-4% порівняно з гіперпараметрами за замовчуванням на популярних КЛЕЙ контрольні набори даних. Вибір попередньо підготовленої моделі також можна вважати гіперпараметром і, отже, автоматично вибиратися Syne Tune. У проблемі класифікації тексту це призводить до додаткового підвищення точності приблизно на 5% порівняно з моделлю за замовчуванням. Однак ми можемо автоматизувати більше рішень, які користувач повинен приймати; ми демонструємо це, також показуючи тип екземпляра як гіперпараметр, який ми пізніше використовуємо для розгортання моделі. Вибравши правильний тип екземпляра, ми можемо знайти конфігурації, які оптимально компенсують вартість і затримку.
Щоб ознайомитися з Syne Tune, див Виконуйте завдання з налаштування розподілених гіперпараметрів і нейронної архітектури за допомогою Syne Tune.
Оптимізація гіперпараметрів за допомогою Syne Tune
Ми будемо використовувати КЛЕЙ набір тестів, який складається з дев'яти наборів даних для завдань розуміння природної мови, таких як розпізнавання тексту або аналіз настроїв. Для цього ми адаптуємо Hugging Face run_glue.py сценарій навчання. Набори даних GLUE поставляються з попередньо визначеним набором для навчання та оцінки з мітками, а також із набором тривалих тестів без міток. Тому ми розділили навчальний набір на набори для навчання та перевірки (розділ 70%/30%) і використовуємо набір оцінки як набір даних для тесту очікування. Крім того, ми додаємо ще одну функцію зворотного виклику до Hugging Face Trainer API, яка повідомляє про ефективність перевірки після кожної епохи назад до Syne Tune. Дивіться наступний код:
Ми починаємо з оптимізації типових тренувальних гіперпараметрів: швидкість навчання, коефіцієнт розминки для збільшення швидкості навчання та розмір пакету для точного налаштування попередньо підготовленого BERT (bert-base-case) модель, яка є моделлю за замовчуванням у прикладі Hugging Face. Дивіться наступний код:
Як наш метод HPO ми використовуємо АША, який випадковим чином рівномірно відбирає конфігурації гіперпараметрів і ітераційно припиняє оцінку конфігурацій з поганою продуктивністю. Хоча більш складні методи використовують імовірнісну модель цільової функції, таку як існує BO або MoBster, ми використовуємо ASHA для цієї публікації, оскільки вона поставляється без будь-яких припущень щодо простору пошуку.
На наступному малюнку ми порівнюємо відносне покращення помилки тестування порівняно з конфігурацією гіперпараметрів за замовчуванням Hugging Faces.
![]()
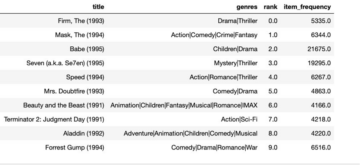
Для простоти ми обмежуємо порівняння з MRPC, COLA та STSB, але ми також спостерігаємо подібні покращення також для інших наборів даних GLUE. Для кожного набору даних ми запускаємо ASHA на одному ml.g4dn.xlarge Amazon SageMaker екземпляр з бюджетом виконання 1,800 секунд, що відповідає приблизно 13, 7 і 9 повним оцінкам функцій у цих наборах даних відповідно. Щоб врахувати внутрішню випадковість процесу навчання, наприклад, викликану вибіркою міні-партії, ми запускаємо як ASHA, так і конфігурацію за замовчуванням для п’яти повторень з незалежним початковим елементом для генератора випадкових чисел і повідомляємо про середнє та стандартне відхилення для відносне поліпшення під час повторень. Ми бачимо, що в усіх наборах даних ми фактично можемо покращити прогнозну продуктивність на 1-3% порівняно з продуктивністю ретельно відібраної конфігурації за замовчуванням.
Автоматизуйте вибір попередньо навченої моделі
Ми можемо використовувати HPO, щоб не тільки знаходити гіперпараметри, але й автоматично вибирати потрібну попередньо навчену модель. Чому ми хочемо це зробити? Оскільки жодна модель не перевершує всі набори даних, ми повинні вибрати правильну модель для певного набору даних. Щоб продемонструвати це, ми оцінюємо цілий ряд популярних моделей трансформерів від Hugging Face. Для кожного набору даних ми оцінюємо кожну модель за її тестовою продуктивністю. Рейтинг між наборами даних (див. наступний малюнок) змінюється, а не одна модель, яка має найвищі оцінки для кожного набору даних. Як довідник ми також показуємо абсолютну продуктивність тесту кожної моделі та набору даних на наступному малюнку.
Щоб автоматично вибрати правильну модель, ми можемо відтворити вибір моделі як категоріальні параметри та додати це до нашого простору пошуку гіперпараметрів:
Хоча простір для пошуку тепер більше, це не обов’язково означає, що його важче оптимізувати. На наступному малюнку показано помилку тестування найкращої спостережуваної конфігурації (на основі помилки перевірки) у наборі даних MRPC ASHA з часом, коли ми шукаємо в оригінальному просторі (синя лінія) (за допомогою попередньо навченої моделі на основі BERT ) або в новому розширеному просторі пошуку (оранжевий рядок). Враховуючи той самий бюджет, ASHA може знайти набагато кращу конфігурацію гіперпараметрів у розширеному просторі пошуку, ніж у меншому просторі.
![]()
Автоматичний вибір типу екземпляра
На практиці ми можемо не дбати лише про оптимізацію прогнозної продуктивності. Ми також можемо піклуватися про інші цілі, такі як час навчання, вартість (у доларах), затримка або показники справедливості. Нам також потрібно зробити інші варіанти, крім гіперпараметрів моделі, наприклад, вибрати тип екземпляра.
Хоча тип екземпляра не впливає на прогнозну продуктивність, він сильно впливає на вартість (долар), час виконання навчання та затримку. Останнє стає особливо важливим, коли модель розгортається. Ми можемо сформулювати HPO як проблему багатоцільової оптимізації, де ми прагнемо оптимізувати кілька цілей одночасно. Однак жодне рішення не оптимізує всі показники одночасно. Замість цього ми прагнемо знайти набір конфігурацій, які оптимально компенсують одну ціль проти іншої. Це називається Набір Парето.
Для подальшого аналізу цього параметра ми додаємо вибір типу екземпляра як додатковий категоричний гіперпараметр до нашого простору пошуку:
Ми використовуємо МО-АША, який адаптує ASHA до багатоцільового сценарію за допомогою сортування без домінування. На кожній ітерації MO-ASHA також вибирає для кожної конфігурації також тип екземпляра, на якому ми хочемо його оцінити. Щоб запустити HPO на гетерогенному наборі екземплярів, Syne Tune надає бекенд SageMaker. За допомогою цього бекенда кожне випробування оцінюється як незалежне навчальне завдання SageMaker у окремому екземплярі. Кількість працівників визначає, скільки завдань SageMaker ми виконуємо паралельно в певний час. Сам оптимізатор, у нашому випадку MO-ASHA, працює або на локальній машині, у блокноті Sagemaker, або на окремому навчальному заданні SageMaker. Дивіться наступний код:
На наступних малюнках показано співвідношення затримки та помилки тесту ліворуч і затримки від вартості праворуч для випадкових конфігурацій, відібраних MO-ASHA (ми обмежуємо вісь для видимості) у наборі даних MRPC після його запуску протягом 10,800 XNUMX секунд на чотирьох працівниках. Колір вказує на тип екземпляра. Пунктирна чорна лінія представляє набір Парето, тобто набір точок, які домінують над усіма іншими точками принаймні в одній цілі.
Ми можемо спостерігати компроміс між затримкою та помилкою тестування, тобто найкраща конфігурація з найменшою помилкою тестування не досягає найменшої затримки. На основі ваших уподобань ви можете вибрати конфігурацію гіперпараметра, яка жертвує продуктивністю тестування, але має меншу затримку. Ми також бачимо компроміс між затримкою та вартістю. Наприклад, використовуючи менший екземпляр ml.g4dn.xlarge, ми лише незначно збільшуємо затримку, але сплачуємо четверту частину вартості екземпляра ml.g4dn.8xlarge.
Висновок
У цій публікації ми обговорили оптимізацію гіперпараметрів для точного налаштування попередньо навчених моделей трансформаторів від Hugging Face на основі Syne Tune. Ми побачили, що оптимізуючи гіперпараметри, такі як швидкість навчання, розмір пакету та коефіцієнт розігріву, ми можемо покращити ретельно вибрану конфігурацію за замовчуванням. Ми також можемо розширити це, автоматично вибравши попередньо навчену модель за допомогою оптимізації гіперпараметрів.
За допомогою бекенда Syne Tune SageMaker ми можемо розглядати тип екземпляра як гіперпараметр. Хоча тип екземпляра не впливає на продуктивність, він має значний вплив на затримку та вартість. Тому, відтворюючи HPO як багатоцільову оптимізаційну проблему, ми можемо знайти набір конфігурацій, які оптимально компенсують одну ціль проти іншої. Якщо ви хочете спробувати це самі, завітайте до нас приклад блокнота.
Про авторів
![]() Аарон Кляйн є вченим-прикладником в AWS.
Аарон Кляйн є вченим-прикладником в AWS.
![]() Матіас Сігер є головним прикладним науковцем у AWS.
Матіас Сігер є головним прикладним науковцем у AWS.
![]() Девід Салінас є старшим прикладним науковцем в AWS.
Девід Салінас є старшим прикладним науковцем в AWS.
![]() Емілі Веббер приєднався до AWS відразу після запуску SageMaker і з тих пір намагається розповісти про це всьому світу! Крім створення нових можливостей ML для клієнтів, Емілі любить медитувати та вивчати тибетський буддизм.
Емілі Веббер приєднався до AWS відразу після запуску SageMaker і з тих пір намагається розповісти про це всьому світу! Крім створення нових можливостей ML для клієнтів, Емілі любить медитувати та вивчати тибетський буддизм.
![]() Седрік Арчамбо є головним прикладним науковцем в AWS і членом Європейської лабораторії навчання та інтелектуальних систем.
Седрік Арчамбо є головним прикладним науковцем в AWS і членом Європейської лабораторії навчання та інтелектуальних систем.
- Coinsmart. Найкраща в Європі біржа біткойн та криптовалют.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. БЕЗКОШТОВНИЙ ДОСТУП.
- CryptoHawk. Альткойн Радар. Безкоштовне випробування.
- Джерело: https://aws.amazon.com/blogs/machine-learning/hyperparameter-optimization-for-fine-tuning-pre-trained-transformer-models-from-hugging-face/
- "
- 10
- 100
- 7
- 9
- a
- МЕНЮ
- абсолют
- доступною
- рахунки
- Achieve
- через
- Додатковий
- впливати
- ВСІ
- дозволяє
- хоча
- Amazon
- кількість
- аналіз
- аналізувати
- Інший
- API
- прикладної
- приблизно
- архітектура
- збільшено
- автоматизувати
- автоматично
- середній
- AWS
- Вісь
- оскільки
- еталонний тест
- КРАЩЕ
- Краще
- між
- За
- Black
- сміливий
- підвищення
- бюджет
- Створюємо
- який
- випадок
- викликаний
- вибір
- вибір
- вибраний
- клас
- класифікація
- код
- Приходити
- порівняний
- обчислення
- конфігурація
- контроль
- Клієнти
- дані
- рішення
- демонструвати
- розгортання
- розгорнути
- розподілений
- Ні
- Долар
- кожен
- легко
- Ефективний
- Європейська
- оцінювати
- оцінка
- приклад
- Досліди
- експерт
- продовжити
- Особа
- мода
- Рисунок
- після
- Рамки
- від
- Повний
- функція
- далі
- Крім того
- generator
- допомога
- тут
- Як
- How To
- Однак
- HTTPS
- Impact
- важливо
- удосконалювати
- поліпшення
- Augmenter
- незалежний
- вплив
- екземпляр
- Розумний
- інтерес
- IT
- сам
- робота
- Джобс
- приєднався
- знання
- lab
- етикетки
- мова
- великий
- більше
- запущений
- Веде за собою
- вивчення
- МЕЖА
- Лінія
- місцевий
- машина
- зробити
- РОБОТИ
- масивний
- сенс
- методика
- Метрика
- може бути
- ML
- модель
- Моделі
- більше
- множинний
- Природний
- обов'язково
- потреби
- мереж
- ноутбук
- номер
- цілей
- отриманий
- оптимізація
- Оптимізувати
- оптимізуючий
- оригінал
- Інше
- власний
- особливо
- Платити
- продуктивність
- виконанні
- будь ласка
- точок
- популярний
- практика
- Головний
- Проблема
- процес
- обробка
- забезпечує
- діапазон
- Ранжування
- звітом
- репортер
- Звіти
- представляє
- Вимагається
- результати
- прогін
- біг
- то ж
- вчений
- Пошук
- seconds
- насіння
- обраний
- настрій
- комплект
- установка
- Показувати
- значний
- аналогічний
- простий
- один
- Розмір
- рішення
- складний
- Простір
- конкретний
- розкол
- standard
- старт
- стан
- Як і раніше
- Стратегія
- Systems
- завдання
- тест
- Команда
- світ
- отже
- час
- торгувати
- Навчання
- лікувати
- величезний
- суд
- розуміння
- us
- використання
- користувачі
- зазвичай
- використовувати
- перевірка достовірності
- видимість
- Вікіпедія
- без
- робочі
- світ
- вашу