Керовані робочі процеси Amazon для Apache Airflow (Amazon MWAA) — це керована служба оркестровки для Потік повітря Apache це спрощує налаштування та керування наскрізними конвеєрами даних у хмарі в масштабі. Конвеєр даних — це набір завдань і процесів, які використовуються для автоматизації переміщення та перетворення даних між різними системами. Спільнота з відкритим вихідним кодом Apache Airflow надає понад 1,000 готових операторів (плагінів, які спрощують підключення до служб) для Apache Airflow для створення конвеєрів даних. The Пакет провайдера Amazon для Apache Airflow забезпечує інтеграцію для понад 31 служби AWS, наприклад Служба простого зберігання Amazon (Amazon S3), Амазонська червона зміна, Amazon EMR, Клей AWS, Amazon SageMakerІ багато іншого.
Найпоширенішим випадком використання Airflow є ETL (вилучення, перетворення та завантаження). Майже всі користувачі Airflow впроваджують конвеєри ETL, починаючи від простих до складних. Операціоналізація машинного навчання (ML) є ще одним зростаючим випадком використання, коли дані потрібно трансформувати та нормалізувати, перш ніж їх можна буде завантажити в модель ML. В обох випадках використання конвеєр даних готує дані для споживання, приймаючи дані з різних джерел і перетворюючи їх за допомогою серії кроків.
Спостереженість за різними процесами в конвеєрі даних є ключовим компонентом для моніторингу успіху чи невдачі конвеєра. Хоча плануванням виконання завдань у конвеєрі даних керує Airflow, виконання самого завдання (перетворення, нормалізація та агрегування даних) виконується різними службами залежно від варіанту використання. Наскрізний перегляд потоку даних є проблемою через численні точки дотику в конвеєрі даних.
У цій публікації ми надаємо огляд удосконалень журналювання під час роботи з Amazon MWAA, який є одним із стовпів спостережуваності. Потім ми обговорюємо рішення для подальшого покращення наскрізної спостережуваності шляхом зміни визначень завдань, які складають конвеєр даних. У цьому дописі ми зосередимося на визначеннях завдань для двох сервісів: AWS Glue і Amazon EMR, однак той самий метод можна застосувати до різних сервісів.
виклик
Багато конвеєрів даних клієнтів починаються просто, організовуючи кілька завдань, і з часом стають більш складними, складаючись із великої кількості завдань і залежностей між ними. Зі збільшенням складності стає все важче працювати та налагоджувати у разі збою, що створює потребу в одній скляній панелі для забезпечення наскрізної оркестровки конвеєра даних і керування працездатністю. Для оркестровки конвеєра даних, Інтерфейс Apache Airflow це зручний інструмент, який надає детальний перегляд вашого каналу даних. Що стосується управління працездатністю конвеєра, кожна служба, з якою взаємодіють ваші завдання, може зберігати або публікувати журнали в різних місцях, наприклад у відро S3 або Amazon CloudWatch колоди. Оскільки кількість точок дотику інтеграції зростає, об’єднання розподілених журналів, створених різними службами в різних місцях, може бути складним завданням.
Одне з рішень, надане Amazon MWAA для консолідації Airflow і журналів завдань у межах орієнтований ациклічний граф (DAG) пересилати журнали до Групи журналів CloudWatch. Окрема група журналу створюється для кожного ввімкненого параметра журналу Airflow (наприклад, DAGProcessing, Scheduler, Task, WebServer та Worker). Ці журнали можна запитувати між групами журналів за допомогою CloudWatch Logs Insights.
Загальним підходом у розподіленому трасуванні є використання ідентифікатора кореляції для зшивання та запиту розподілених журналів. Ідентифікатор кореляції — це унікальний ідентифікатор, який передається через потік запитів для відстеження послідовності дій протягом усього життєвого циклу. Коли кожна служба в робочому процесі потребує реєстрації інформації, вона може містити цей ідентифікатор кореляції, таким чином гарантуючи, що ви можете відстежувати повний запит від початку до кінця.
Двигун Airflow пропускає декілька змінні за замовчуванням, які доступні для всіх шаблонів. run_id є однією з таких змінних, яка є унікальним ідентифікатором для запуску DAG. The run_id можна використовувати як ідентифікатор кореляції для запиту до різних груп журналів у CloudWatch, щоб отримати всі журнали для певного запуску DAG.
Однак майте на увазі, що служби, з якими взаємодіють ваші завдання, використовуватимуть окрему групу журналів і не реєструватимуть run_id як частину їх продукції. Це запобіжить вам отримати наскрізний перегляд DAG.
Наприклад, якщо ваш конвеєр даних складається із завдання AWS Glue, яке виконує завдання Spark як частину конвеєра, то журнали завдань Airflow будуть доступні в одній групі журналів CloudWatch, а журнали завдань AWS Glue будуть в іншій групі журналів CloudWatch. . Однак завдання Spark, яке виконується як частина завдання AWS Glue, не має доступу до ідентифікатора кореляції та не може бути прив’язане до певного запуску DAG. Отже, навіть якщо ви використовуєте ідентифікатор кореляції для запиту до різних груп журналів CloudWatch, ви не отримаєте жодної інформації про запуск завдання Spark.
Огляд рішення
Як ви тепер знаєте, run_id це змінна, яка є унікальним ідентифікатором для запуску DAG. The run_id присутній як частина журналів завдань Airflow. Для використання run_id ефективно та підвищити спостережуваність у всьому циклі DAG, який ми використовуємо run_id як ідентифікатор кореляції та передайте його іншим завданням за допомогою DAG. Ідентифікатор кореляції потім споживається сценаріями, які використовуються в завданнях.
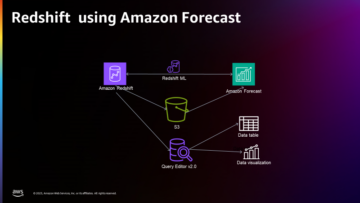
Наступна діаграма ілюструє архітектуру рішення.
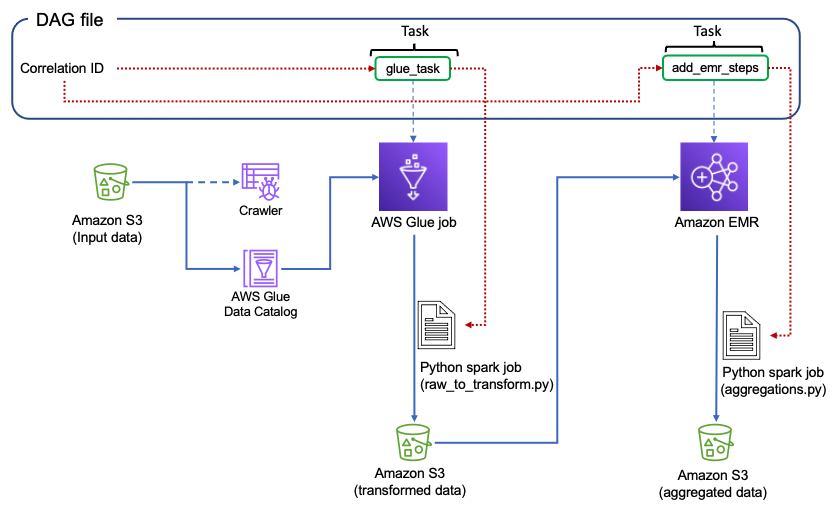
Конвеєр даних, на якому ми зосереджуємося, складається з таких компонентів:
- Відро S3, яке містить вихідні дані
- An Сканер AWS Glue який створює метадані таблиці в каталозі даних із вихідних даних
- An Робота з клеєм AWS який перетворює необроблені дані у формат оброблених даних, виконуючи перетворення форматів файлів
- An EMR робота який створює набори даних звітності
Докладніше про архітектуру та повні кроки щодо запуску DAG див Amazon MWAA for Analytics Workshop.
У наступних розділах ми досліджуємо такі теми:
- Файл DAG, щоб зрозуміти, як визначити та потім передати ідентифікатор кореляції в завданнях AWS Glue і EMR
- Код, необхідний у сценаріях Python для виведення інформації на основі ідентифікатора кореляції
Див GitHub репо для детального визначення DAG і сценаріїв Spark. Щоб запустити сценарії, зверніться до Аналітичний семінар Amazon MWAA.
Визначення DAG
У цьому розділі ми розглянемо фрагменти доповнень, необхідних для файлу DAG. Ми також обговорюємо, як передати ідентифікатор кореляції в завдання AWS Glue і EMR. Зверніться до GitHub репо для повного коду DAG.
Файл DAG починається з визначення змінних:
# Змінні
Далі розглянемо, як передати ідентифікатор кореляції в завдання AWS Glue за допомогою оператора AWS Glue. Оператори є будівельними блоками Airflow DAG. Вони містять логіку того, як дані обробляються в конвеєрі даних. Кожне завдання в DAG визначається створенням екземпляра оператора.
Airflow надає операторам різні завдання. Для цієї публікації ми використовуємо Оператор клею AWS.
Визначення завдання AWS Glue містить наступне:
- Сценарій завдання Python Spark (raw_to_tranform.py), щоб виконати завдання
- Назва DAG, ідентифікатор завдання та ідентифікатор кореляції, які передаються як аргументи
- Команда Роль служби AWS Glue призначений, який має дозволи на запуск сканера та завдань
Дивіться наступний код:
# Клей Визначення завдання
Далі ми передаємо ідентифікатор кореляції в завдання EMR за допомогою Оператор ЕМВ. Це включає наступні кроки:
- Визначте конфігурацію кластера EMR.
- Створіть кластер EMR.
- Визначте кроки, які має виконати завдання EMR.
- Запустіть завдання EMR:
- Ми використовуємо сценарій завдання Python Spark aggregations.py.
- Ми передаємо ім’я DAG, ідентифікатор завдання та ідентифікатор кореляції як аргументи для кроків завдання EMR.
Почнемо з визначення конфігурації для кластера EMR. The correlation_id передається в назві кластера, щоб легко ідентифікувати кластер, який відповідає запуску DAG. Журнали, створені завданнями EMR, публікуються в сегменті S3; в correlation_id є частиною LogUri так само. Перегляньте наступний код:
# Визначте конфігурацію кластера EMR
Тепер давайте визначимо завдання для створення кластера EMR на основі конфігурації:
# Створіть кластер EMR
cluster_creator = EmrCreateJobFlowOperator( task_id= emr_task_id, job_flow_overrides=JOB_FLOW_OVERRIDES, aws_conn_id=’aws_default’, emr_conn_id=’emr_default’, dag=dag
)Далі визначимо кроки, необхідні для виконання завдання EMR. Вхідні та вихідні дані, оброблені завданням EMR, зберігаються у сегменті S3, що передається як аргументи. Dag_name, task_id та correlation_id також передаються як аргументи. Використовуваний task_id може бути назвою за вашим вибором; тут ми використовуємо add_steps:
# кроків EMR, які має виконати кластер EMR
Далі додамо завдання для виконання кроків у кластері EMR. The job_flow_id є ідентифікатором JobFlow, який передається з EMR create task описане раніше використання Airflow XComs. Дивіться наступний код:
#Виконайте завдання EMR
Це завершує кроки, необхідні для передачі ідентифікатора кореляції у визначенні завдання DAG.
У наступному розділі ми використовуємо цей ідентифікатор під час запуску сценарію для реєстрації деталей.
Визначення сценарію роботи
У цьому розділі ми розглядаємо зміни, необхідні для реєстрації інформації на основі correlation_id. Почнемо зі сценарію завдання AWS Glue (повний код див. нижче файл в GitHub):
# Сценарій змінює файл "raw_to_transform"
Далі ми зосередимося на сценарії завдання EMR (повний код див файл в GitHub):
# Зміни сценарію до файлу 'nyc_aggregations'
На цьому кроки для передачі ідентифікатора кореляції до виконання сценарію завершено.
Після завершення визначення DAG і додавання сценаріїв ми можемо запустити DAG. Журнали для певного запуску DAG можна запитувати за допомогою ідентифікатора кореляції. Ідентифікатор кореляції для запуску DAG можна знайти за допомогою Інтерфейс Airflow. Приклад ідентифікатора кореляції manual__2022-07-12T00:22:36.111190+00:00. За допомогою цього унікального рядка ми можемо виконувати запити до відповідних груп журналів CloudWatch за допомогою CloudWatch Logs Insights. Результат запиту містить журнали, надані сценаріями AWS Glue і EMR, а також інші журнали, пов’язані з ідентифікатором кореляції.
Приклад запиту для журналів рівня DAG: manual__2022-07-12T00:22:36.111190+00:00
Ми також можемо отримати журнали на рівні завдань, використовуючи формат <dag_name.task_id correlation_id>:
Приклад запиту: data_pipeline.glue_task manual__2022-07-12T00:22:36.111190+00:00
Прибирати
Якщо ви створили налаштування для запуску та тестування сценаріїв за допомогою Аналітичний семінар Amazon MWAA, виконати прибирати кроки, щоб уникнути стягнення плати.
Висновок
У цій публікації ми показали, як надсилати журнали Amazon MWAA до груп журналів CloudWatch. Потім ми обговорили, як зв’язати журнали з різних завдань у DAG за допомогою унікального ідентифікатора кореляції. Ідентифікатор кореляції може бути виведений з такою кількістю чи меншою кількістю інформації, необхідної для вашої роботи, щоб надати більше деталей для всього запуску DAG. Потім ви можете використовувати CloudWatch Logs Insights, щоб запитувати журнали.
За допомогою цього рішення ви можете використовувати Amazon MWAA як єдине скло для оркестровки конвеєрів даних і журналів CloudWatch для керування працездатністю конвеєрів даних. Унікальний ідентифікатор покращує наскрізну спостережуваність для запуску DAG і допомагає скоротити час, необхідний для усунення несправностей.
Щоб дізнатися більше та отримати практичний досвід, почніть із Аналітичний семінар Amazon MWAA а потім використовуйте сценарії в GitHub репо щоб отримати кращу спостережливість вашого запуску DAG.
Про автора
 Паял Сінгх є архітектором партнерських рішень у Amazon Web Services, зосередженим на безсерверній платформі. Вона відповідає за допомогу партнерам і клієнтам у модернізації та перенесенні їхніх програм на AWS.
Паял Сінгх є архітектором партнерських рішень у Amazon Web Services, зосередженим на безсерверній платформі. Вона відповідає за допомогу партнерам і клієнтам у модернізації та перенесенні їхніх програм на AWS.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/improve-observability-across-amazon-mwaa-tasks/
- 000
- 1
- 10
- 100
- 11
- a
- МЕНЮ
- доступ
- доступною
- через
- діяльності
- ациклічні
- доповнення
- проти
- ВСІ
- хоча
- Amazon
- Amazon Web Services
- аналітика
- та
- Інший
- Apache
- застосування
- прикладної
- підхід
- архітектура
- аргументація
- призначений
- асоційований
- автоматизувати
- доступний
- уникнути
- AWS
- Клей AWS
- назад
- заснований
- стає
- перед тим
- між
- блоки
- будувати
- будівельник
- Створюємо
- захоплення
- випадок
- випадків
- каталог
- виклик
- складні
- Зміни
- вантажі
- вибір
- хмара
- кластер
- код
- загальний
- співтовариство
- повний
- Завершує
- комплекс
- складність
- компонент
- Компоненти
- конфігурація
- Зв'язки
- Складається
- Консолідувати
- спожитий
- споживання
- містить
- контроль
- Core
- Кореляція
- Відповідний
- може
- гусеничний
- створювати
- створений
- створює
- Клієнти
- DAG
- дані
- дефолт
- певний
- визначаючи
- описаний
- докладно
- деталі
- різний
- обговорювати
- обговорювалися
- розподілений
- Ні
- вниз
- кожен
- Раніше
- легко
- фактично
- включений
- кінець в кінець
- двигун
- забезпечення
- Весь
- Ефір (ETH)
- Навіть
- приклад
- досвід
- дослідити
- витяг
- Провал
- кілька
- філе
- закінчення
- потік
- Сфокусувати
- увагу
- після
- формат
- Вперед
- знайдений
- від
- Повний
- Функції
- далі
- Отримувати
- генерується
- генерує
- отримати
- отримання
- GitHub
- скло
- графік
- Group
- Групи
- Рости
- Зростання
- практичний
- Жорсткий
- має
- здоров'я
- допомогу
- допомагає
- тут
- Як
- How To
- Однак
- HTML
- HTTPS
- ідентифікатор
- ідентифікувати
- здійснювати
- імпорт
- удосконалювати
- поліпшується
- in
- включати
- includes
- Augmenter
- Збільшує
- все більше і більше
- інформація
- вхід
- розуміння
- інтеграція
- інтеграцій
- взаємодіючих
- IT
- сам
- робота
- Джобс
- ключ
- Знати
- великий
- УЧИТЬСЯ
- вивчення
- рівень
- термін
- трохи
- загрузка
- місць
- log4j
- подивитися
- машина
- навчання за допомогою машини
- зробити
- РОБОТИ
- вдалося
- управління
- ринок
- майстер
- метадані
- метод
- мігрувати
- ML
- модель
- Моделі
- модернізувати
- монітор
- більше
- найбільш
- руху
- множинний
- ім'я
- майже
- Необхідність
- необхідний
- потреби
- наступний
- вузли
- номер
- отримувати
- ONE
- з відкритим вихідним кодом
- працювати
- оператор
- Оператори
- варіант
- оркестровка
- порядок
- Інше
- огляд
- pane
- частина
- приватність
- партнер
- Пройшов
- проходить
- Проходження
- виконувати
- виконанні
- Дозволи
- трубопровід
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- plugins
- точок
- пошта
- підготовка
- представити
- запобігати
- процеси
- забезпечувати
- за умови
- Постачальник
- провайдери
- забезпечує
- опублікований
- Видавничий
- Python
- ранжування
- Сировина
- необроблені дані
- зменшити
- доречний
- Звітність
- запросити
- вимагається
- відповідальний
- результат
- огляд
- прогін
- біг
- то ж
- SC
- шкала
- scripts
- розділ
- розділам
- окремий
- Послідовність
- Серія
- Без сервера
- обслуговування
- Послуги
- Сесія
- комплект
- установка
- простий
- спростити
- один
- So
- рішення
- Рішення
- Source
- Джерела
- Іскритися
- SQL
- старт
- почалася
- заходи
- зберігання
- зберігати
- успіх
- такі
- Systems
- таблиця
- Завдання
- завдання
- Шаблони
- тест
- Команда
- Джерело
- їх
- тим самим
- через
- по всьому
- TIE
- Зв'язаний
- час
- до
- інструмент
- теми
- торкатися
- Простеження
- трек
- Відстеження
- Перетворення
- Перетворення
- перетворений
- перетворення
- правда
- розуміти
- створеного
- Використання
- використання
- використання випадку
- зручно
- користувачі
- різний
- через
- вид
- думки
- Web
- веб-сервіси
- який
- в той час як
- волі
- в
- робочий
- Робочі процеси
- робочий
- Семінари
- вашу
- зефірнет