Закон Гудхарта Відомо сказано: «Коли міра стає мішенню, вона перестає бути хорошою мірою». Хоча спочатку з економіки, це те, з чим нам доводиться боротися в OpenAI, коли з’ясовують, як оптимізувати цілі, які важко або дорого виміряти. Часто необхідно представити деякі проксі мета це простіше чи дешевше виміряти, але коли ми це робимо, нам потрібно бути обережними, щоб не оптимізувати це занадто сильно.
Наприклад, в рамках нашої роботи по вирівнювати такі моделі, як GPT-3 із людськими намірами та цінностями, ми хотіли б оптимізувати такі речі, як «Як корисний це відповідь?» або «Як фактично точні це претензія?» Це складні цілі, які вимагають від людей ретельної перевірки. З цієї причини ми навчаємо модель передбачати ці людські переваги, відомі як a модель винагородиі використовувати прогнози моделі винагороди як проксі-цілі. Але важливо стежити за тим, наскільки добре оптимізується справжня мета.
У цьому дописі ми розглянемо деякі з математичних принципів того, як ми це робимо. Ми зосередимося на обстановці, яку особливо легко аналізувати, у якій ми маємо доступ до справжньої мети. На практиці навіть людські уподобання можуть не виміряти те, що нас справді цікавить, але ми відкладаємо це питання в цій публікації.
Найкраще з $n$ вибірки
Є багато способів, за допомогою яких можна оптимізувати ціль проксі, але, мабуть, найпростіший найкраща вибірка з $n$, також відомий як відбір проб or переранжування. Ми просто відбираємо $n$ разів і беремо той, який має найвищий бал відповідно до проксі-цілі.
Незважаючи на те, що цей метод дуже простий, він насправді може конкурувати з більш просунутими методами, такими як навчання з підкріпленням, хоча й ціною більшого обчислення часу на висновки. Наприклад, в WebGPT, наша найкраща модель за 64$ перевершила нашу модель навчання з підкріпленням, можливо, частково через те, що модель найкраща за 64$ мала переглядати набагато більше веб-сайтів. Навіть застосування найкращого з $4$ значно підвищило переваги людей.
Крім того, вибірка найкращого з $n$ має надійну продуктивність і її легко аналізувати математично, що робить її добре придатною для емпіричних досліджень закону Гудхарта та пов’язаних явищ.
Математика найкращої вибірки з $n$
Давайте вивчимо вибірку кращих із $n$ більш формально. Припустімо, що ми маємо деякий вибірковий простір $S$ (наприклад, набір можливих пар запитання-відповідь), деякий розподіл імовірностей $P$ за $S$, справжня мета (або «винагорода») $R_{text{true}}:Stomathbb R$, і проксі-мета $R_{text{proxy}}:Stomathbb R$. Скажімо, ми якимось чином оптимізуємо $R_{text{proxy}}$ і таким чином отримаємо новий розподіл $P^просте$. Тоді:
- Математичне очікування $mathbb E_{x^primesim P^prime}left[R_{text{true}}left(x^primeright)right]$ вимірює, наскільки добре ми оптимізували справжню ціль.
- Команда KL дивергенція $D_{text{KL}}left(P^primeparallel Pright)$ вимірює обсяг оптимізації, яку ми зробили. Наприклад, якщо $P^prime$ отримано шляхом взяття першого зразка з $P$, який лежить у деякій підмножині $S^primesubseteq S$, тоді ця розбіжність KL є лише негативною логарифмічної ймовірністю того, що вибірка з $P$ лежить у $S^prime$.
Виявляється, що у випадку найкращої вибірки з $n$ обидві ці величини можна ефективно оцінити, використовуючи вибірки з $P$.
Давайте спочатку розглянемо очікування. Наївний підхід полягає у використанні оцінювача Монте-Карло: запустіть найкращу вибірку за $n$ багато разів, виміряйте справжню мету на цих вибірках і усередніть результати. Однак є кращий оцінювач. Якщо ми маємо $Ngeq n$ зразків із $P$ загалом, тоді ми можемо розглядати одночасно кожна можлива підмножина цих зразків розміром $n$, зважте кожен зразок за кількістю підмножин, для яких він є найкращим відповідно до проксі-цілі, а потім візьміть середньозважену істинну цільову оцінку. Ця вага є просто біноміальним коефіцієнтом $binom{k-1}{n-1}$, де $k$ — це ранг вибірки за проксі-метою, від $1$ (найгірший) до $N$ (найкращий). Окрім більш ефективного використання зразків, це також дозволяє нам повторно використовувати зразки для різних значень $n$.
Що стосується дивергенції KL, то, як не дивно, виявляється, що вона має точну формулу, яка працює для будь-якого безперервного розподілу ймовірностей $P$ (тобто, поки $P$ не має точкових мас). Можна наївно здогадатися, що відповідь така $log n$, оскільки best-of-$n$ робить щось на зразок того, що бере верхню частину $frac 1n$ розподілу, і це приблизно правильно: точна відповідь: $log n-frac{n-1}n$.
Разом ці оцінювачі дозволяють нам легко проаналізувати, як справжня мета змінюється залежно від обсягу оптимізації, застосованої до проксі-цілі.
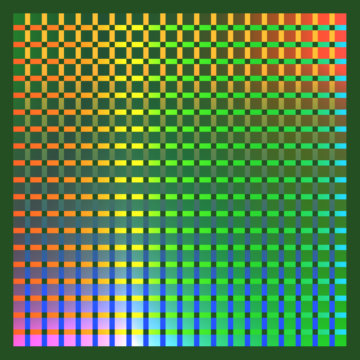
Ось приклад із реального життя WebGPT:
Найкраща з $n$ продуктивність для WebGPT 175B
Найкраща з $n$ продуктивність для WebGPT із затіненими областями, що представляють стандартну помилку $pm 1$, а вісь KL слідує за шкалою квадратного кореня. Тут вихідний розподіл ($P$) задано моделлю 175B, навченою за допомогою клонування поведінки, проксі-ціль, яка використовується для обчислення найкращого з-$n$ ($R_{text{proxy}}$), задана навчанням модель винагороди, і ми розглядаємо три ймовірно «істинні» цілі ($R_{text{true}}$): саму модель винагороди за навчання, модель винагороди за перевірку, навчену на збережених даних, і фактичні уподобання людини. Немає великої надмірної оптимізації цілі проксі, але ми очікуємо, що вона буде при вищих KL.
Вихід за рамки кращого з $n$ вибірки
Основним обмеженням вибірки найкращого з $n$ є те, що розбіжність KL зростає логарифмічно з $n$, тому вона підходить лише для застосування невеликої кількості оптимізації.
Щоб застосувати більше оптимізації, ми зазвичай використовуємо навчання з підкріпленням. У параметрах, які ми вивчили досі, наприклад підведення підсумків, зазвичай нам вдається досягти KL близько 10 нац використання навчання з підкріпленням до того, як справжня мета почне зменшуватися через закон Гудхарта. Нам потрібно було б прийняти $n$ приблизно до 60,000 XNUMX, щоб досягти цього KL за допомогою найкраще-$n$, і ми сподіваємося досягти значно більших KL, ніж цей, завдяки вдосконаленню нашого моделювання винагороди та практик навчання з підкріпленням.
Однак не всі нації однакові. Емпірично, для малих бюджетів KL, best-of-$n$ краще оптимізує як проксі, так і справжні цілі, ніж навчання з підкріпленням. Інтуїтивно зрозуміло, що best-of-$n$ — це підхід «грубої сили», що робить його більш ефективним з точки зору інформації, ніж навчання з підкріпленням, але менш ефективним з точки зору обчислень при великих KL.
У рамках нашої роботи ми активно вивчаємо властивості масштабування проксі-цілей вирівнювати наші моделі з людськими намірами та цінностями. Якщо ви хочете допомогти нам у цьому дослідженні, ми допоможемо наймання!
- AI
- ai мистецтво
- AI арт генератор
- ai робот
- штучний інтелект
- сертифікація штучного інтелекту
- штучний інтелект у банківській справі
- робот зі штучним інтелектом
- роботи зі штучним інтелектом
- програмне забезпечення для штучного інтелекту
- blockchain
- блокчейн конференція AI
- coingenius
- розмовний штучний інтелект
- крипто конференція ai
- dall's
- глибоке навчання
- у вас є гугл
- навчання за допомогою машини
- OpenAI
- plato
- платон ai
- Інформація про дані Платона
- Гра Платон
- PlatoData
- platogaming
- дослідження
- масштаб ai
- синтаксис
- зефірнет