Нещодавно ми оголосили про загальну доступність Amazon OpenSearch Serverless , новий варіант для Служба Amazon OpenSearch це полегшує виконання великомасштабних пошукових і аналітичних робочих навантажень без необхідності налаштовувати, керувати або масштабувати кластери OpenSearch. З OpenSearch Serverless ви отримуєте такий самий інтерактивний час відповіді в мілісекундах, що й OpenSearch Service, з простотою безсерверного середовища.
У цьому дописі ви дізнаєтесь, як перенести наявні індекси з домену кластера, керованого OpenSearch Service, до безсерверної колекції за допомогою Logstash.
З доменами OpenSearch ви отримуєте виділені безпечні кластери, налаштовані та оптимізовані для ваших робочих навантажень за лічені хвилини. Ви маєте повний контроль над конфігурацією обчислювальних ресурсів, пам’яті та ресурсів зберігання в кластерах, щоб оптимізувати вартість і продуктивність ваших програм. OpenSearch Serverless забезпечує ще простіший спосіб запуску пошукових і аналітичних робочих навантажень — без необхідності думати про кластери. Ви просто створюєте колекцію та групу індексів, і можете почати приймати та запитувати дані.
Огляд рішення
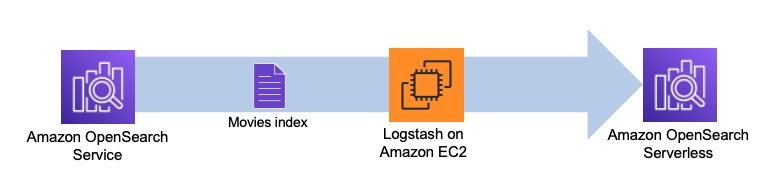
Логсташ це програмне забезпечення з відкритим вихідним кодом, яке забезпечує ETL (вилучення, перетворення та завантаження) для ваших даних. Ви можете налаштувати Logstash для підключення до джерела та призначення через плагіни введення та виведення. Між цим ви налаштовуєте фільтри, які можуть перетворювати ваші дані. У цьому дописі описано кроки, необхідні для налаштування Logstash для підключення домену OpenSearch Service (вхід) до колекції OpenSearch Serverless (вихід).
Ви встановлюєте плагіни джерела та призначення у конфігураційному файлі Logstash. У конфігураційному файлі є розділи для Input, Filter та Output. Після налаштування Logstash надішле запит до домену OpenSearch Service і прочитає дані відповідно до запиту, який ви поставили в input розділ. Після зчитування даних зі служби OpenSearch ви можете відправити їх на наступний етап Filter для таких перетворень, як додавання або видалення поля з вхідних даних або оновлення поля іншими значеннями. У цьому прикладі ви не використовуватимете Filter підключати. Далі йде Output підключати. Версія Logstash з відкритим вихідним кодом (Logstash OSS) забезпечує зручний спосіб використання групового API для завантаження даних у ваші колекції. OpenSearch Serverless підтримує logstash-вивід-opensearch вихідний плагін, який підтримує Управління ідентифікацією та доступом AWS (IAM) облікові дані для контролю доступу до даних.
Наступна діаграма ілюструє наш робочий процес рішення.
Передумови
Перш ніж почати, переконайтеся, що ви виконали наступні передумови:
- Занотуйте ARN домену служби OpenSearch, ім’я користувача та пароль.
- Створіть колекцію OpenSearch Serverless. Якщо ви новачок у OpenSearch Serverless, зверніться до Аналітика журналів – простий спосіб за допомогою Amazon OpenSearch Serverless щоб дізнатися більше про те, як налаштувати свою колекцію.
Налаштуйте Logstash і плагіни введення та виведення для OpenSearch
Виконайте наступні кроки, щоб налаштувати Logstash і плагіни:
- Завантажити
logstash-oss-with-opensearch-output-plugin. (У цьому прикладі використовується дистрибутив для macos-x64. Для інших дистрибутивів зверніться до артефакти.) - Розпакуйте завантажений архів:
- Оновити
logstash-output-opensearchплагін до останньої версії: - встановити
logstash-input-opensearchпідключати:
Перевірте плагін
Давайте приступимо до дії та подивимося, як працює плагін. Наступний файл конфігурації отримує дані з movies індексує у вашому домені OpenSearch Service та індексує ці дані у вашій безсерверній колекції OpenSearch з тим самим ім’ям індексу, movies.
Створіть новий файл і додайте наступний вміст, а потім збережіть файл як opensearch-serverless-migration.conf. Укажіть значення для кінцевої точки домену служби OpenSearch HOST, USERNAME та ПАРОЛЬ в input розділ, а також деталі кінцевої точки збору OpenSearch Serverless нижче HOST разом з РЕГІОН, AWS_ACCESS_KEY_ID та AWS_SECRET_ACCESS_KEY в output .
Ви можете вказати запит у input розділ попередньої конфігурації. The match_all запит відповідає всім даним у movies індекс. Ви можете змінити запит, якщо хочете вибрати підмножину даних. Ви також можете використовувати запит для розпаралелювання передачі даних, запускаючи кілька процесів Logstash із конфігураціями, які вказують різні фрагменти даних. Ви також можете розпаралелювати, запускаючи процеси Logstash з кількома індексами, якщо вони у вас є.
Запустіть Logstash
Використовуйте таку команду, щоб запустити Logstash:
Після того, як ви запустите команду, Logstash отримає дані з вихідного індексу з вашого домену OpenSearch Service і запише в індекс призначення у вашій колекції OpenSearch Serverless. Після завершення передачі даних Logstash вимикається. Перегляньте наступний код:
Перевірте дані в OpenSearch Serverless
Ви можете переконатися, що Logstash скопіював усі ваші дані, порівнявши кількість документів у вашому домені та вашій колекції. Виконайте наступний запит або з Інструменти розробника вкладка, або с curl, postmanабо подібний клієнт HTTP. Наступний запит допоможе вам шукати всі документи з movies індекс і повертає перші документи разом із підрахунком. За замовчуванням OpenSearch поверне кількість документів максимум до 10,000 XNUMX. Додавання track_total_hits прапорець допомагає отримати точну кількість документів, якщо кількість документів перевищує 10,000 XNUMX.
Висновок
У цьому дописі ви перенесли дані з домену OpenSearch Service до своєї колекції OpenSearch Serverless за допомогою плагінів введення та виведення OpenSearch від Logstash.
Слідкуйте за серією публікацій, присвячених різноманітним параметрам, доступним для створення ефективної аналітики журналів і пошукових рішень за допомогою OpenSearch Serverless. Ви також можете звернутися до Початок роботи з Amazon OpenSearch Serverless семінар, щоб дізнатися більше про OpenSearch Serverless.
Якщо у вас є відгуки про цю публікацію, надішліть їх у розділі коментарів. Якщо у вас є запитання щодо цієї публікації, створіть нову тему на Форум Amazon OpenSearch Service or зверніться до служби підтримки AWS.
Про авторів
 Прашант Агравал є старшим архітектором рішень спеціаліста з пошуку Amazon OpenSearch Service. Він тісно співпрацює з клієнтами, щоб допомогти їм перенести робочі навантаження в хмару, а також допомагає існуючим клієнтам налаштувати свої кластери для досягнення кращої продуктивності та економії коштів. До того як приєднатися до AWS, він допомагав різним клієнтам використовувати OpenSearch і Elasticsearch для пошуку та аналітики журналів. Коли він не працює, він подорожує та досліджує нові місця. Коротше кажучи, йому подобається Їсти → Подорожувати → Повторювати.
Прашант Агравал є старшим архітектором рішень спеціаліста з пошуку Amazon OpenSearch Service. Він тісно співпрацює з клієнтами, щоб допомогти їм перенести робочі навантаження в хмару, а також допомагає існуючим клієнтам налаштувати свої кластери для досягнення кращої продуктивності та економії коштів. До того як приєднатися до AWS, він допомагав різним клієнтам використовувати OpenSearch і Elasticsearch для пошуку та аналітики журналів. Коли він не працює, він подорожує та досліджує нові місця. Коротше кажучи, йому подобається Їсти → Подорожувати → Повторювати.
 Джон Хендлер (@_searchgeek) є старшим головним архітектором рішень у Amazon Web Services, що базується в Пало-Альто, Каліфорнія. Джон тісно співпрацює з командами CloudSearch і Elasticsearch, надаючи допомогу та вказівки широкому колу клієнтів, які мають робоче навантаження пошуку, яке вони хочуть перенести в AWS Cloud. До того як приєднатися до AWS, кар’єра Джона як розробника програмного забезпечення включала чотири роки кодування великомасштабної пошукової системи електронної комерції.
Джон Хендлер (@_searchgeek) є старшим головним архітектором рішень у Amazon Web Services, що базується в Пало-Альто, Каліфорнія. Джон тісно співпрацює з командами CloudSearch і Elasticsearch, надаючи допомогу та вказівки широкому колу клієнтів, які мають робоче навантаження пошуку, яке вони хочуть перенести в AWS Cloud. До того як приєднатися до AWS, кар’єра Джона як розробника програмного забезпечення включала чотири роки кодування великомасштабної пошукової системи електронної комерції.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/migrate-your-indexes-to-amazon-opensearch-serverless-with-logstash/
- 000
- 10
- 100
- 28
- 39
- 7
- a
- МЕНЮ
- доступ
- За
- Achieve
- дію
- після
- проти
- Агент
- ВСІ
- Amazon
- Amazon Web Services
- аналітика
- та
- оголошений
- API
- застосування
- наявність
- доступний
- AWS
- заснований
- перед тим
- Краще
- між
- широкий
- будувати
- CA
- кар'єра
- випадків
- CD
- зміна
- клієнт
- тісно
- хмара
- кластер
- код
- Кодування
- збір
- Колекції
- коментарі
- порівняння
- повний
- Зроблено
- обчислення
- конфігурація
- З'єднуватися
- зміст
- контроль
- Зручний
- Коштувати
- створювати
- Повноваження
- Клієнти
- дані
- доступ до даних
- присвячених
- дефолт
- призначення
- деталі
- Розробник
- різний
- інвалід
- документ
- документація
- справи
- домен
- домени
- вниз
- є
- електронної комерції
- Ефективний
- або
- Elasticsearch
- Кінцева точка
- двигун
- Навколишнє середовище
- Ефір (ETH)
- Навіть
- НІКОЛИ
- приклад
- перевищує
- існуючий
- Дослідження
- витяг
- зворотний зв'язок
- поле
- філе
- Фільтри
- знайти
- фокусування
- після
- від
- Повний
- Загальне
- отримати
- отримання
- Group
- має
- допомога
- допоміг
- допомагає
- Як
- How To
- HTTPS
- IAM
- Особистість
- in
- включені
- індекс
- покажчики
- індекси
- інформація
- вхід
- встановлювати
- інтерактивний
- IT
- приєднання
- Знати
- масштабний
- останній
- УЧИТЬСЯ
- загрузка
- головний
- зробити
- РОБОТИ
- управляти
- вдалося
- максимальний
- пам'ять
- мігрувати
- мілісекунда
- протокол
- більше
- рухатися
- кіно
- множинний
- ім'я
- Необхідність
- Нові
- наступний
- з відкритим вихідним кодом
- Програмне забезпечення з відкритим кодом
- Оптимізувати
- оптимізований
- варіант
- Опції
- Нам
- Інше
- Пало-Альто
- Пароль
- продуктивність
- трубопровід
- місця
- plato
- Інформація про дані Платона
- PlatoData
- підключати
- plugins
- пошта
- Пости
- передумови
- Головний
- попередній
- процеси
- забезпечувати
- забезпечує
- забезпечення
- put
- питань
- діапазон
- Читати
- нещодавно
- регіон
- реєстру
- Вилучено
- видалення
- повторювати
- запросити
- ресурси
- відповідь
- повертати
- Умови повернення
- прогін
- бігун
- біг
- то ж
- зберегти
- шкала
- Пошук
- Пошукова система
- розділ
- розділам
- безпечний
- Серія
- Без сервера
- обслуговування
- Послуги
- комплект
- Короткий
- Вимикати
- Заткнись
- аналогічний
- простота
- просто
- Софтвер
- рішення
- Рішення
- Source
- спеціаліст
- Стажування
- старт
- почалася
- заходи
- зберігання
- представляти
- Успішно
- такі
- Опори
- команди
- Команда
- Джерело
- їх
- через
- times
- до
- топ
- переклад
- Перетворення
- перетворень
- подорожувати
- Подорож
- правда
- при
- Оновити
- оновлення
- використання
- користувач
- Цінності
- різний
- перевірити
- версія
- через
- Web
- веб-сервіси
- який
- ВООЗ
- волі
- без
- робочий
- робочий
- працює
- майстерня
- Семінари
- запис
- років
- вашу
- зефірнет