NLP із багатьма мітками стосується завдання присвоєння кількох міток певному введеному тексту, а не лише однієї. У традиційних завданнях НЛП, таких як класифікація тексту або аналіз настроїв, кожному введенню зазвичай присвоюється одна мітка на основі його вмісту. Однак у багатьох сценаріях реального світу фрагмент тексту може належати до кількох категорій або виражати кілька почуттів одночасно.
NLP з декількома мітками важливий, оскільки він дозволяє отримувати більш тонку та складну інформацію з текстових даних. Наприклад, у сфері аналізу відгуків споживачів відгук клієнта може виражати як позитивні, так і негативні настрої одночасно або він може стосуватися кількох аспектів продукту чи послуги. Призначаючи кілька міток для таких вхідних даних, ми можемо отримати більш повне розуміння відгуків клієнтів і вживати більш цілеспрямованих заходів для вирішення їхніх проблем.
У цій статті розглядається заслуговує на увагу випадок використання Provectus НЛП із кількома мітками.
Контекст:
До нас звернувся клієнт з проханням допомогти автоматизувати маркування документів певного типу. На перший погляд завдання здавалося простим і легко вирішуваним. Однак, працюючи над цією справою, ми зіткнулися з набором даних із непослідовними анотаціями. Незважаючи на те, що наш клієнт зіткнувся з проблемами, пов’язаними з різними номерами класів і змінами в їхній команді перевірки з часом, вони вклали значні зусилля у створення різноманітного набору даних із низкою анотацій. Хоча в мітках існували певні дисбаланси та невизначеності, цей набір даних надав цінну можливість для аналізу та подальшого дослідження.
Давайте детальніше розглянемо набір даних, вивчимо показники та наш підхід, а також нагадаємо, як Provectus вирішив проблему класифікації тексту з кількома мітками.
Набір даних містить 14,354 124 спостереження зі XNUMX унікальними класами (мітками). Наше завдання полягає в тому, щоб кожному спостереженню присвоїти один або декілька класів.
Таблиця 1 надає описову статистику для набору даних.
У середньому ми маємо близько двох класів на одне спостереження, в середньому 261 різних текстів, що описують один клас.

Таблиця 1: Статистика набору даних
На малюнку 1 ми бачимо розподіл класів на верхньому графіку, і ми маємо певну кількість міток HEAD з найвищою частотою появи в наборі даних. Також зауважте, що більшість занять мають низьку частоту зустрічальності.
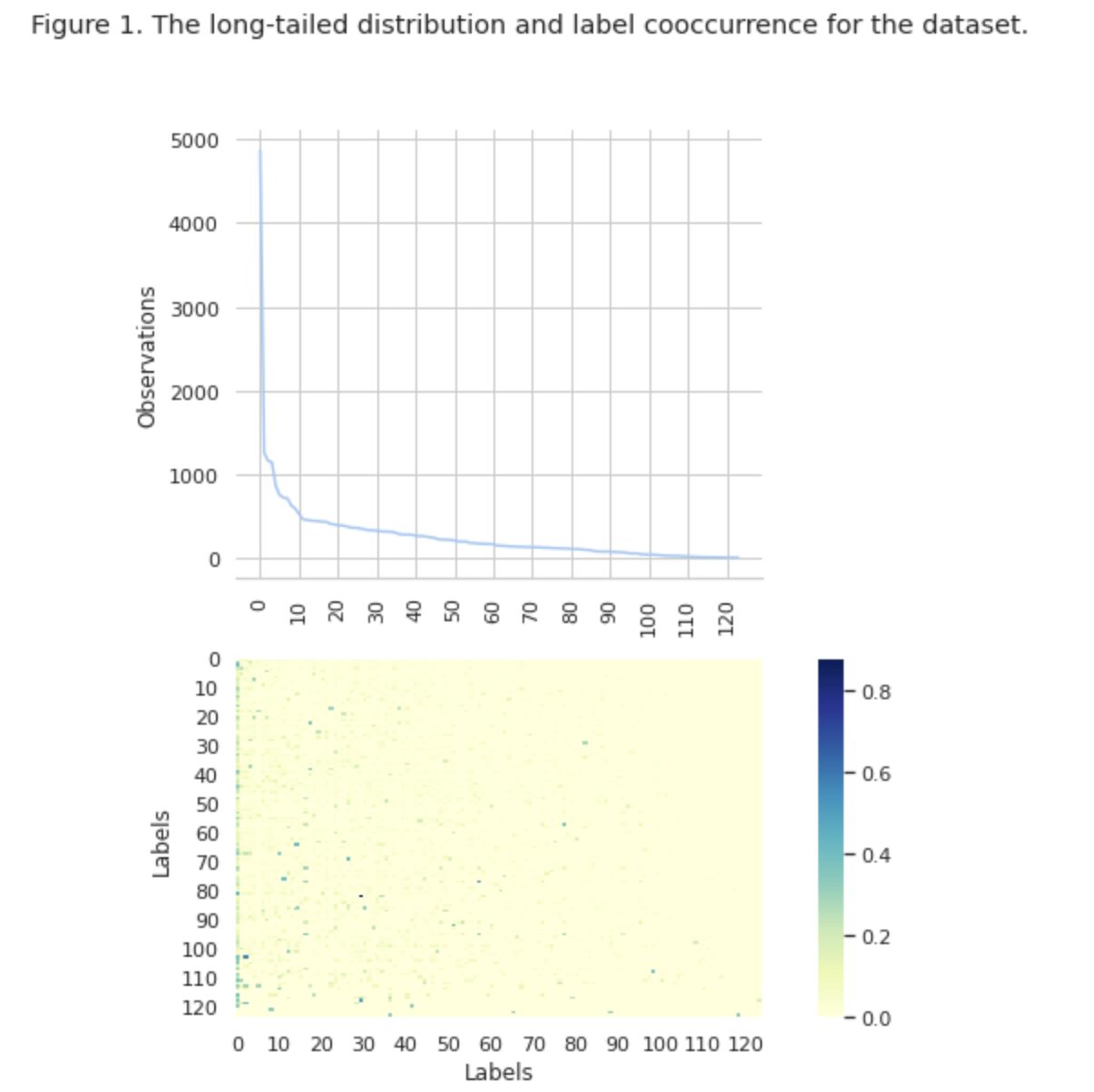
На нижньому графіку ми бачимо часте збігання між класами, які найкраще представлені в наборі даних, і класами, які мають низьку значущість.
Ми змінили процес поділу набору даних на набори train/val/test. Замість використання традиційного методу ми застосували ітераційну стратифікацію, щоб забезпечити добре збалансований розподіл доказів зв’язків міток. Для цього ми використовували Мультинавчання Scikit
from skmultilearn.model_selection import iterative_train_test_split mlb = MultiLabelBinarizer() def balanced_split(df, mlb, test_size=0.5): ind = np.expand_dims(np.arange(len(df)), axis=1) mlb.fit_transform(df["tag"]) labels = mlb.transform(df["tag"]) ind_train, _, ind_test, _ = iterative_train_test_split( ind, labels, test_size ) return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:, 0]] df_train, df_tmp = balanced_split(df, test_size=0.4)
df_val, df_test = balanced_split(df_tmp, test_size=0.5)
Ми отримали такий розподіл:
- Навчальний набір даних містить 60% даних і охоплює всі 124 мітки
- Набір даних перевірки містить 20% даних і охоплює всі 124 етикетки
- Тестовий набір даних містить 20% даних і охоплює всі 124 етикетки
Класифікація з кількома мітками – це тип керованого алгоритму машинного навчання, який дозволяє нам призначати кілька міток одному зразку даних. Вона відрізняється від бінарної класифікації, де модель передбачає лише дві категорії, і багатокласової класифікації, де модель передбачає лише один із кількох класів для вибірки.
Метрики оцінки ефективності класифікації за багатьма мітками за своєю суттю відрізняються від тих, що використовуються в класифікації за кількома класами (або бінарною) через властиві відмінності проблеми класифікації. Більш детальну інформацію можна знайти у Вікіпедії.
Ми вибрали найбільш підходящі для нас метрики:
- Точність вимірює частку справжніх позитивних прогнозів серед загальної кількості позитивних прогнозів, зроблених моделлю.
- Згадувати вимірює частку справжніх позитивних прогнозів серед усіх фактичних позитивних зразків.
- Оцінка F1 це гармонійне середнє значення точності та відкликання, яке допомагає відновити баланс між ними.
- Втрата Хеммінга це частка міток, які неправильно передбачені
Ми також відстежуємо кількість передбачених міток у наборі { визначається як кількість міток, для яких ми отримуємо оцінку F1 > 0}.
Класифікація з кількома мітками – це тип проблеми навчання під наглядом, де один екземпляр або приклад можна пов’язати з кількома мітками чи класифікаціями, на відміну від традиційної класифікації з однією міткою, де кожен екземпляр пов’язується лише з однією міткою класу.
Для вирішення проблем класифікації з кількома мітками існує дві основні категорії методів:
- Методи перетворення задач
- Методи адаптації алгоритму
Методи перетворення задач дозволяють нам перетворювати завдання класифікації з кількома мітками в завдання класифікації з кількома мітками. Наприклад, базовий підхід двійкової релевантності (BR) розглядає кожну мітку як окрему проблему бінарної класифікації. У цьому випадку проблема з кількома мітками перетворюється на задачу з кількома одномітками.
Методи адаптації алгоритму модифікують самі алгоритми для обробки даних із кількома мітками, не перетворюючи завдання на декілька завдань класифікації з однією міткою. Прикладом такого підходу є модель BERT, яка є попередньо підготовленою мовною моделлю на основі трансформатора, яку можна точно налаштувати для різних завдань NLP, включаючи класифікацію тексту з кількома мітками. BERT розроблено для безпосередньої обробки даних із кількома мітками без необхідності перетворення проблем.
У контексті використання BERT для класифікації тексту з кількома мітками стандартним підходом є використання втрат двійкової крос-ентропії (BCE) як функції втрат. Втрати BCE — це функція втрат, яка зазвичай використовується для задач двійкової класифікації, і її можна легко розширити для вирішення проблем класифікації кількох міток шляхом обчислення втрат для кожної мітки незалежно, а потім підсумовування втрат. У цьому випадку функція втрат BCE вимірює похибку між прогнозованими ймовірностями та істинними мітками, де прогнозовані ймовірності отримані з останнього шару сигмоїдної активації в моделі BERT.
Тепер давайте уважніше розглянемо малюнок 2 нижче.
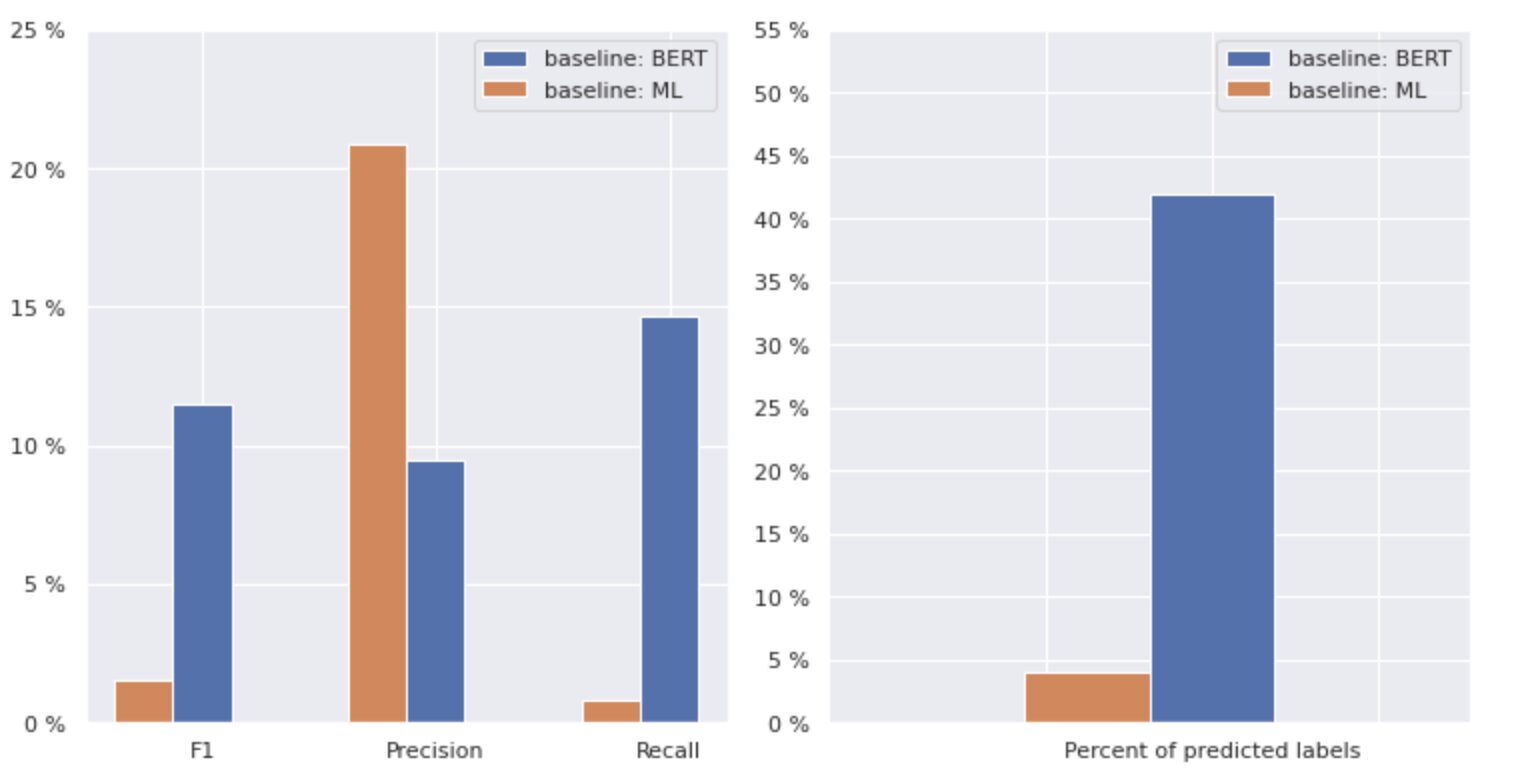
Рисунок 2. Показники для базових моделей
На графіку ліворуч показано порівняння показників для «базового рівня: BERT» і «базового рівня: ML». Таким чином, можна побачити, що для «базової лінії: BERT» показники F1 і Recall приблизно в 1.5 рази вищі, тоді як Precision для «базової лінії: ML» у 2 рази вища, ніж у моделі 1. Аналізуючи загальний відсоток передбачених класів, показаних праворуч, ми бачимо, що «базова лінія: BERT» передбачила класи більш ніж у 10 разів більше, ніж «базова лінія: ML».
Оскільки максимальний результат для «базової лінії: BERT» становить менше 50% усіх класів, результати є досить невтішними. Давайте розберемося, як покращити ці результати.
За матеріалами видатної статті «Методи збалансування для класифікації тексту з кількома мітками з розподілом класів за довгим хвостом», ми дізналися, що розподіл збалансованих втрат може бути для нас найбільш прийнятним підходом.
Збалансований розподіл втрат
Збалансована втрата розподілу — це техніка, яка використовується в проблемах класифікації тексту з кількома мітками для усунення дисбалансів у розподілі класів. У цих проблемах деякі класи мають набагато більшу частоту появи порівняно з іншими, що призводить до зміщення моделі в бік цих більш частих класів.
Щоб вирішити цю проблему, розподіл збалансованих втрат має на меті збалансувати внесок кожного зразка у функцію втрат. Це досягається шляхом повторного зважування втрати кожного зразка на основі зворотної частоти його появи в наборі даних. Таким чином, внесок менш частих класів збільшується, а внесок більш частих класів зменшується, таким чином збалансовуючи загальний розподіл класів.
Ця техніка показала свою ефективність у покращенні продуктивності моделей для проблем розподілу класів з довгим хвостом. Зменшуючи вплив частих занять і збільшуючи вплив нечастих занять, модель здатна краще фіксувати закономірності в даних і створювати більш збалансовані прогнози.

Реалізація класу Resample
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np class ResampleLoss(nn.Module): def __init__( self, use_sigmoid=True, partial=False, loss_weight=1.0, reduction="mean", reweight_func=None, weight_norm=None, focal=dict(focal=True, alpha=0.5, gamma=2), map_param=dict(alpha=10.0, beta=0.2, gamma=0.1), CB_loss=dict(CB_beta=0.9, CB_mode="average_w"), logit_reg=dict(neg_scale=5.0, init_bias=0.1), class_freq=None, train_num=None, ): super(ResampleLoss, self).__init__() assert (use_sigmoid is True) or (partial is False) self.use_sigmoid = use_sigmoid self.partial = partial self.loss_weight = loss_weight self.reduction = reduction if self.use_sigmoid: if self.partial: self.cls_criterion = partial_cross_entropy else: self.cls_criterion = binary_cross_entropy else: self.cls_criterion = cross_entropy # reweighting function self.reweight_func = reweight_func # normalization (optional) self.weight_norm = weight_norm # focal loss params self.focal = focal["focal"] self.gamma = focal["gamma"] self.alpha = focal["alpha"] # mapping function params self.map_alpha = map_param["alpha"] self.map_beta = map_param["beta"] self.map_gamma = map_param["gamma"] # CB loss params (optional) self.CB_beta = CB_loss["CB_beta"] self.CB_mode = CB_loss["CB_mode"] self.class_freq = ( torch.from_numpy(np.asarray(class_freq)).float().cuda() ) self.num_classes = self.class_freq.shape[0] self.train_num = train_num # only used to be divided by class_freq # regularization params self.logit_reg = logit_reg self.neg_scale = ( logit_reg["neg_scale"] if "neg_scale" in logit_reg else 1.0 ) init_bias = ( logit_reg["init_bias"] if "init_bias" in logit_reg else 0.0 ) self.init_bias = ( -torch.log(self.train_num / self.class_freq - 1) * init_bias ) self.freq_inv = ( torch.ones(self.class_freq.shape).cuda() / self.class_freq ) self.propotion_inv = self.train_num / self.class_freq def forward( self, cls_score, label, weight=None, avg_factor=None, reduction_override=None, **kwargs ): assert reduction_override in (None, "none", "mean", "sum") reduction = ( reduction_override if reduction_override else self.reduction ) weight = self.reweight_functions(label) cls_score, weight = self.logit_reg_functions( label.float(), cls_score, weight ) if self.focal: logpt = self.cls_criterion( cls_score.clone(), label, weight=None, reduction="none", avg_factor=avg_factor, ) # pt is sigmoid(logit) for pos or sigmoid(-logit) for neg pt = torch.exp(-logpt) wtloss = self.cls_criterion( cls_score, label.float(), weight=weight, reduction="none" ) alpha_t = torch.where(label == 1, self.alpha, 1 - self.alpha) loss = alpha_t * ((1 - pt) ** self.gamma) * wtloss loss = reduce_loss(loss, reduction) else: loss = self.cls_criterion( cls_score, label.float(), weight, reduction=reduction ) loss = self.loss_weight * loss return loss def reweight_functions(self, label): if self.reweight_func is None: return None elif self.reweight_func in ["inv", "sqrt_inv"]: weight = self.RW_weight(label.float()) elif self.reweight_func in "rebalance": weight = self.rebalance_weight(label.float()) elif self.reweight_func in "CB": weight = self.CB_weight(label.float()) else: return None if self.weight_norm is not None: if "by_instance" in self.weight_norm: max_by_instance, _ = torch.max(weight, dim=-1, keepdim=True) weight = weight / max_by_instance elif "by_batch" in self.weight_norm: weight = weight / torch.max(weight) return weight def logit_reg_functions(self, labels, logits, weight=None): if not self.logit_reg: return logits, weight if "init_bias" in self.logit_reg: logits += self.init_bias if "neg_scale" in self.logit_reg: logits = logits * (1 - labels) * self.neg_scale + logits * labels if weight is not None: weight = ( weight / self.neg_scale * (1 - labels) + weight * labels ) return logits, weight def rebalance_weight(self, gt_labels): repeat_rate = torch.sum( gt_labels.float() * self.freq_inv, dim=1, keepdim=True ) pos_weight = ( self.freq_inv.clone().detach().unsqueeze(0) / repeat_rate ) # pos and neg are equally treated weight = ( torch.sigmoid(self.map_beta * (pos_weight - self.map_gamma)) + self.map_alpha ) return weight def CB_weight(self, gt_labels): if "by_class" in self.CB_mode: weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) elif "average_n" in self.CB_mode: avg_n = torch.sum( gt_labels * self.class_freq, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, avg_n)).cuda() ) elif "average_w" in self.CB_mode: weight_ = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) weight = torch.sum( gt_labels * weight_, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) elif "min_n" in self.CB_mode: min_n, _ = torch.min( gt_labels * self.class_freq + (1 - gt_labels) * 100000, dim=1, keepdim=True, ) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, min_n)).cuda() ) else: raise NameError return weight def RW_weight(self, gt_labels, by_class=True): if "sqrt" in self.reweight_func: weight = torch.sqrt(self.propotion_inv) else: weight = self.propotion_inv if not by_class: sum_ = torch.sum(weight * gt_labels, dim=1, keepdim=True) weight = sum_ / torch.sum(gt_labels, dim=1, keepdim=True) return weight def reduce_loss(loss, reduction): """Reduce loss as specified. Args: loss (Tensor): Elementwise loss tensor. reduction (str): Options are "none", "mean" and "sum". Return: Tensor: Reduced loss tensor. """ reduction_enum = F._Reduction.get_enum(reduction) # none: 0, elementwise_mean:1, sum: 2 if reduction_enum == 0: return loss elif reduction_enum == 1: return loss.mean() elif reduction_enum == 2: return loss.sum() def weight_reduce_loss(loss, weight=None, reduction="mean", avg_factor=None): """Apply element-wise weight and reduce loss. Args: loss (Tensor): Element-wise loss. weight (Tensor): Element-wise weights. reduction (str): Same as built-in losses of PyTorch. avg_factor (float): Avarage factor when computing the mean of losses. Returns: Tensor: Processed loss values. """ # if weight is specified, apply element-wise weight if weight is not None: loss = loss * weight # if avg_factor is not specified, just reduce the loss if avg_factor is None: loss = reduce_loss(loss, reduction) else: # if reduction is mean, then average the loss by avg_factor if reduction == "mean": loss = loss.sum() / avg_factor # if reduction is 'none', then do nothing, otherwise raise an error elif reduction != "none": raise ValueError( 'avg_factor can not be used with reduction="sum"' ) return loss def binary_cross_entropy( pred, label, weight=None, reduction="mean", avg_factor=None
): # weighted element-wise losses if weight is not None: weight = weight.float() loss = F.binary_cross_entropy_with_logits( pred, label.float(), weight, reduction="none" ) loss = weight_reduce_loss( loss, reduction=reduction, avg_factor=avg_factor ) return loss
DBLoss
loss_func = ResampleLoss( reweight_func="rebalance", loss_weight=1.0, focal=dict(focal=True, alpha=0.5, gamma=2), logit_reg=dict(init_bias=0.05, neg_scale=2.0), map_param=dict(alpha=0.1, beta=10.0, gamma=0.405), class_freq=class_freq, train_num=train_num,
) """
class_freq - list of frequencies for each class,
train_num - size of train dataset """
Уважно дослідивши набір даних, ми дійшли висновку, що параметр
= 0.405.
Порогова настройка
Ще одним кроком у вдосконаленні нашої моделі став процес налаштування порогового значення як на етапі навчання, так і на етапах валідації та тестування. Ми розрахували залежність таких показників, як f1-бал, точність і запам’ятовування, від порогового рівня, і ми вибрали поріг на основі найвищого показника метрики. Нижче ви можете побачити реалізацію функції цього процесу.
Оптимізація оцінки F1 шляхом налаштування порогу:
def optimise_f1_score(true_labels: np.ndarray, pred_labels: np.ndarray): best_med_th = 0.5 true_bools = [tl == 1 for tl in true_labels] micro_thresholds = (np.array(range(-45, 15)) / 100) + best_med_th f1_results, pre_results, recall_results = [], [], [] for th in micro_thresholds: pred_bools = [pl > th for pl in pred_labels] test_f1 = f1_score(true_bools, pred_bools, average="micro", zero_division=0) test_precision = precision_score( true_bools, pred_bools, average="micro", zero_division=0 ) test_recall = recall_score( true_bools, pred_bools, average="micro", zero_division=0 ) f1_results.append(test_f1) prec_results.append(test_precision) recall_results.append(test_recall) best_f1_idx = np.argmax(f1_results) return micro_thresholds[best_f1_idx]Оцінка та порівняння з вихідним рівнем
Ці підходи дозволили нам навчити нову модель і отримати такий результат, який порівнюється з базовою лінією: BERT на малюнку 3 нижче.

Рисунок 3. Показники порівняння за базовим сценарієм і новішим підходом.
Порівнюючи метрики, релевантні для класифікації, ми бачимо значне збільшення показників ефективності майже в 5-6 разів:
Оцінка F1 зросла з 12% → 55%, тоді як точність зросла з 9% → 59%, а запам'ятовування зросла з 15% → 51%.
Завдяки змінам, показаним на правому графіку на малюнку 3, тепер ми можемо передбачити 80% класів.
Зрізи класів
Ми розділили наші мітки на чотири групи: HEAD, MEDIUM, TAIL і ZERO. Кожна група містить мітки з однаковою кількістю допоміжних даних спостережень.
Як видно на малюнку 4, розподіли груп відрізняються. Трояндова коробка (HEAD) має негативний перекіс розподілу, середня коробка (MEDIUM) має позитивний перекіс розподілу, а зелена коробка (TAIL), здається, має нормальний розподіл.
Усі групи також мають викиди, які є точками за межами вусів на прямокутному графіку. Група HEAD має великий вплив на клас MAJOR.
Крім того, ми визначили окрему групу під назвою «ZERO», яка містить мітки, які модель не змогла вивчити та не може розпізнати через мінімальну кількість випадків у наборі даних (менше 3% усіх спостережень).
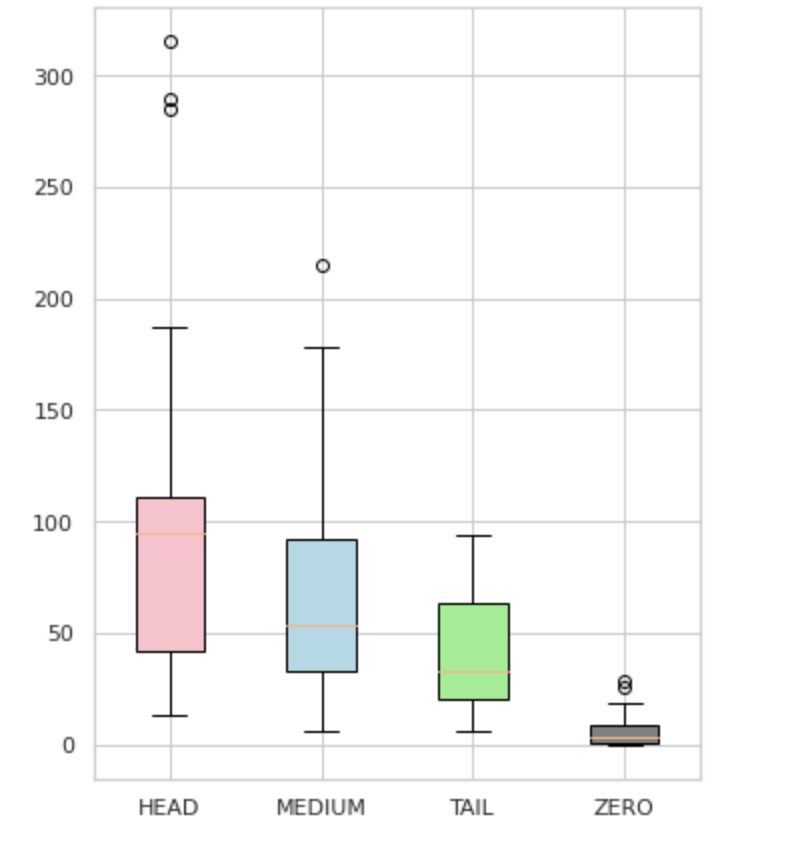
Рисунок 4. Кількість міток у порівнянні з групами
Таблиця 2 містить інформацію про показники для кожної групи міток для тестової підмножини даних.
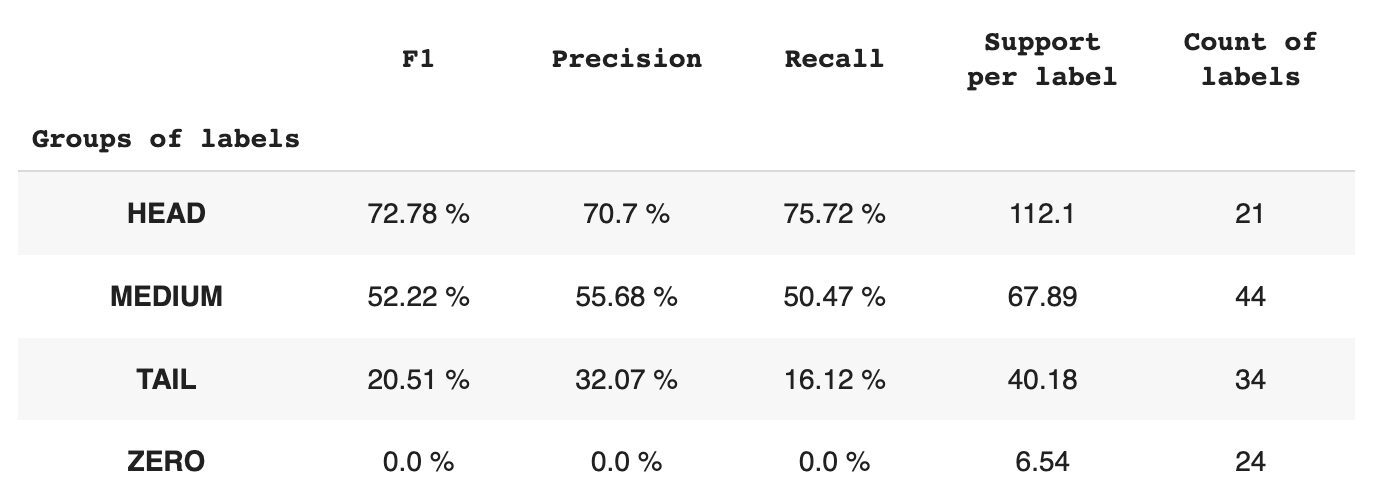
Таблиця 2. Показники по групах.
- Група HEAD містить 21 мітку із середнім показником 112 допоміжних спостережень на мітку. На цю групу впливають викиди, і завдяки високій представленості в наборі даних її показники високі: F1 – 73%, точність – 71%, запам’ятовування – 75%.
- Група MEDIUM складається з 44 міток із середньою підтримкою 67 спостережень, що приблизно вдвічі менше, ніж група HEAD. Очікується, що показники цієї групи зменшаться на 50%: F1 – 52%, Precision – 56%, Recall – 51%.
- Група TAIL має найбільшу кількість класів, але всі вони погано представлені в наборі даних, у середньому 40 допоміжних спостережень на мітку. В результаті показники значно падають: F1 – 21%, Precision – 32%, Recall – 16%.
- Група ZERO включає класи, які модель не може розпізнати взагалі, потенційно через їх низьку кількість у наборі даних. Кожна з 24 міток у цій групі має в середньому 7 допоміжних спостережень.
Рисунок 5 візуалізує інформацію, представлену в таблиці 2, забезпечуючи візуальне представлення показників для кожної групи міток.
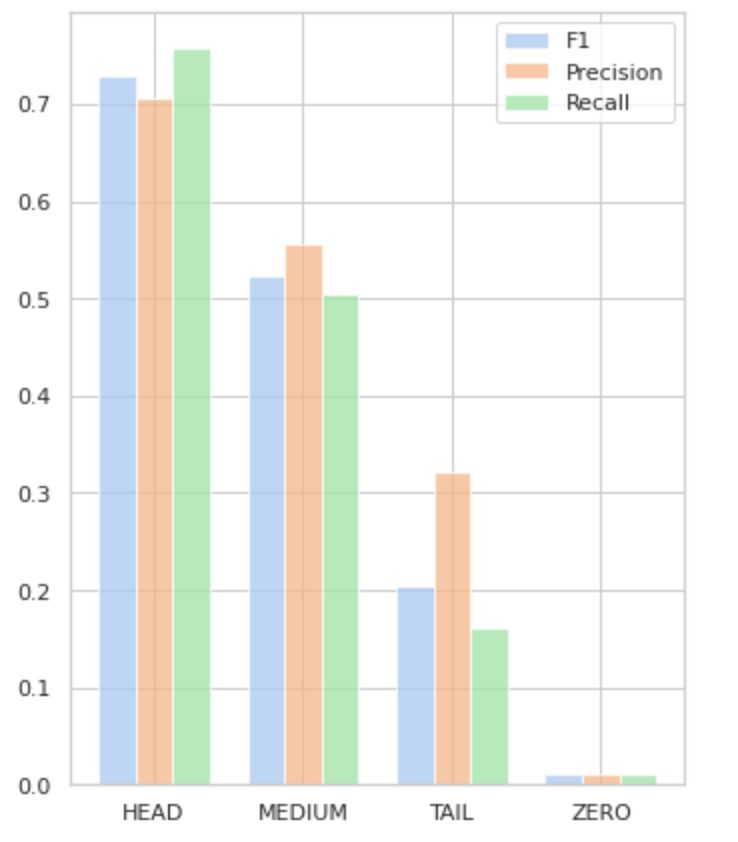
Рисунок 5. Метрики та групи міток. Усі значення НУЛЬ = 0.
У цій вичерпній статті ми продемонстрували, що, здавалося б, просте завдання класифікації тексту з кількома мітками може бути складним, якщо застосовувати традиційні методи. Ми запропонували використовувати функції розподілу-балансування втрат для вирішення проблеми дисбалансу класів.
Ми порівняли ефективність запропонованого нами підходу з класичним методом і оцінили його за допомогою реальних бізнес-метрик. Результати демонструють, що використання функцій втрат для усунення дисбалансу класів і спільної появи міток пропонує життєздатне рішення для класифікації тексту з кількома мітками.
Запропонований варіант використання підкреслює важливість розгляду різних підходів і методів під час роботи з класифікацією тексту з кількома мітками, а також потенційні переваги розподілу-балансування функцій втрат у вирішенні дисбалансу класів.
Якщо ви зіткнулися з подібною проблемою і прагнете упорядкувати операції з обробки документів у вашій організації, зв’яжіться зі мною або командою Provectus. Ми з радістю допоможемо вам знайти більш ефективні методи автоматизації ваших процесів.
Олексій Бабич є інженером машинного навчання в Provectus. Маючи досвід у галузі фізики, він володіє відмінними аналітичними та математичними здібностями, а також отримав цінний досвід під час наукових досліджень і виступів на міжнародних конференціях, зокрема SPIE Photonics West. Олексій спеціалізується на створенні наскрізних великомасштабних рішень AI/ML для галузі охорони здоров’я та фінтех. Він бере участь у кожному етапі життєвого циклу розробки ML, від визначення бізнес-проблем до розгортання та запуску виробничих моделей ML.
Рінат Ахметов є архітектором рішень ML у Provectus. Маючи солідний практичний досвід у сфері машинного навчання (особливо комп’ютерного бачення), Рінат є ботаніком, ентузіастом даних, програмістом і трудоголіком, другою найбільшою пристрастю якого є програмування. У Provectus Рінат відповідає за фази відкриття та підтвердження концепції, а також керує виконанням складних проектів ШІ.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://www.kdnuggets.com/2023/03/multilabel-nlp-analysis-class-imbalance-loss-function-approaches.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-label-nlp-an-analysis-of-class-imbalance-and-loss-function-approaches
- :є
- 1
- 10
- 100
- 15%
- 67
- 7
- 9
- a
- Здатний
- МЕНЮ
- Achieve
- досягнутий
- дії
- Активація
- адаптація
- адреса
- адресація
- AI
- AI / ML
- Цілі
- алгоритм
- алгоритми
- ВСІ
- дозволяє
- Альфа
- серед
- кількість
- аналіз
- Аналітичний
- Аналізуючи
- та
- з'явився
- прикладної
- Застосовувати
- підхід
- підходи
- приблизно
- ЕСТЬ
- стаття
- AS
- аспекти
- призначений
- допомогу
- асоційований
- At
- автоматизація
- середній
- фон
- Balance
- заснований
- Базова лінія
- BE
- оскільки
- нижче
- Переваги
- КРАЩЕ
- бета
- Краще
- між
- зміщення
- найбільший
- дно
- Box
- вбудований
- бізнес
- by
- розрахований
- CAN
- не може
- захоплення
- випадок
- категорії
- CB
- певний
- проблеми
- складні
- Зміни
- заряд
- клас
- класів
- classic
- класифікація
- клієнт
- тісно
- ближче
- зазвичай
- порівняний
- порівняння
- порівняння
- комплекс
- всеосяжний
- комп'ютер
- Комп'ютерне бачення
- обчислення
- концепція
- Турбота
- уклали
- конференція
- беручи до уваги
- контакт
- містить
- зміст
- контекст
- внесок
- охоплює
- створення
- клієнт
- цикл
- дані
- справу
- зменшити
- певний
- демонструвати
- продемонстрований
- розгортання
- призначений
- докладно
- розробка
- Відмінності
- різний
- безпосередньо
- відкриття
- чіткий
- розподіл
- Розподілу
- Різне
- розділений
- документ
- документація
- справи
- домен
- Падіння
- кожен
- легко
- Ефективний
- ефективний
- зусилля
- включіть
- кінець в кінець
- інженер
- ентузіаст
- однаково
- помилка
- особливо
- Ефір (ETH)
- оцінюється
- Кожен
- докази
- приклад
- відмінно
- виконання
- очікуваний
- досвід
- дослідження
- дослідити
- експрес
- f1
- стикаються
- облицювання
- зворотний зв'язок
- Рисунок
- остаточний
- виявлення
- FinTech
- Перший
- Поплавок
- після
- для
- знайдений
- фракція
- частота
- частий
- від
- функція
- функціональний
- Функції
- далі
- Отримувати
- даний
- Погляд
- графік
- зелений
- Group
- Групи
- обробляти
- щасливий
- Мати
- голова
- охорона здоров'я
- допомога
- допомагає
- Високий
- вище
- найвищий
- основний момент
- Як
- How To
- Однак
- HTML
- HTTP
- HTTPS
- ідентифікований
- ідентифікує
- дисбаланс
- Impact
- вплив
- реалізація
- імпорт
- значення
- важливо
- удосконалювати
- поліпшення
- in
- includes
- У тому числі
- невірно
- Augmenter
- збільшений
- зростаючий
- самостійно
- промисловості
- інформація
- притаманне
- вхід
- екземпляр
- замість
- Міжнародне покриття
- інвестицій
- залучений
- питання
- IT
- ЙОГО
- JPG
- тільки один
- KDnuggets
- етикетка
- маркування
- етикетки
- мова
- масштабний
- найбільших
- шар
- Веде за собою
- УЧИТЬСЯ
- вчений
- вивчення
- рівень
- життя
- список
- подивитися
- від
- втрати
- низький
- машина
- навчання за допомогою машини
- made
- головний
- основний
- Більшість
- багато
- відображення
- математики
- максимальний
- заходи
- середа
- метод
- методика
- метрика
- Метрика
- мінімальний
- ML
- MLB
- модель
- Моделі
- змінювати
- Модулі
- більше
- більш ефективний
- найбільш
- множинний
- Названий
- Необхідність
- негативний
- негативно
- Нові
- nlp
- нормальний
- Примітно,
- номер
- номера
- нумпі
- отримувати
- отриманий
- of
- пропонувати
- on
- ONE
- Можливість
- протистояли
- Опції
- організація
- інші
- інакше
- поза
- видатний
- загальний
- параметр
- пристрасть
- моделі
- відсоток
- продуктивність
- Фізика
- частина
- plato
- Інформація про дані Платона
- PlatoData
- будь ласка
- точок
- PoS
- позитивний
- потенціал
- потенційно
- Практичний
- Точність
- передбачати
- передвіщений
- Прогнози
- Прогнози
- Presentations
- представлений
- Проблема
- проблеми
- процес
- процеси
- обробка
- виробляти
- Product
- Production
- Програмування
- проектів
- доказ
- доказ концепції
- запропонований
- забезпечувати
- за умови
- забезпечує
- забезпечення
- піторх
- підвищення
- діапазон
- швидше
- Реальний світ
- ребаланс
- Короткий огляд
- визнавати
- зменшити
- Знижений
- зниження
- відноситься
- відносини
- актуальність
- доречний
- подання
- представлений
- запросити
- дослідження
- результат
- в результаті
- результати
- повертати
- Умови повернення
- огляд
- ROSE
- біг
- s
- то ж
- сценарії
- Наукове дослідження
- другий
- пошук
- обраний
- SELF
- настрій
- окремий
- обслуговування
- комплект
- набори
- Форма
- показаний
- Шоу
- значення
- значний
- істотно
- аналогічний
- простий
- одночасно
- один
- Розмір
- навички
- So
- Софтвер
- Інженер-програміст
- solid
- рішення
- Рішення
- ВИРІШИТИ
- деякі
- спеціалізується
- зазначений
- Стажування
- етапи
- standard
- статистика
- Крок
- просто
- такі
- підходящий
- контрольоване навчання
- підтримка
- Підтримуючий
- таблиця
- TAG
- Приймати
- цільове
- Завдання
- завдання
- команда
- методи
- тест
- Тестування
- Класифікація тексту
- Що
- Команда
- інформація
- їх
- Їх
- самі
- Ці
- поріг
- через
- час
- times
- до
- топ
- факел
- Усього:
- торкатися
- до
- трек
- традиційний
- поїзд
- Навчання
- Перетворення
- Перетворення
- перетворений
- перетворення
- відноситься до
- правда
- типово
- невизначеності
- розуміння
- створеного
- us
- використання
- використання випадку
- використовує
- перевірка достовірності
- Цінний
- Цінності
- різний
- viable
- бачення
- vs
- вага
- West
- який
- в той час як
- Вікіпедія
- волі
- з
- в
- без
- працював
- вашу
- зефірнет
- нуль