Ця серія з трьох частин демонструє, як використовувати графові нейронні мережі (GNN) і Амазонка Нептун для створення рекомендацій фільмів за допомогою IMDb і Box Office Mojo Movies/TV/OTT ліцензований пакет даних, який надає широкий спектр розважальних метаданих, включаючи понад 1 мільярд оцінок користувачів; титри для понад 11 мільйонів акторів і членів знімальної групи; 9 мільйонів назв фільмів, телепередач і розваг; і глобальні касові звіти з більш ніж 60 країн. Багато клієнтів медіа та розваг AWS ліцензують дані IMDb Обмін даними AWS щоб покращити виявлення вмісту та підвищити залучення та утримання клієнтів.
In Частина 1, ми обговорили застосування GNN, а також те, як трансформувати та підготувати наші дані IMDb для запитів. У цьому дописі ми обговорюємо процес використання Neptune для генерування вставок, які використовуються для пошуку поза каталогом у частині 3. Ми також переходимо Amazon Neptune ML, функція машинного навчання (ML) Neptune та код, який ми використовуємо в процесі розробки. У Частині 3 ми розглянемо, як застосувати наші вбудовані графи знань до випадку використання пошуку поза каталогом.
Огляд рішення
Великі підключені набори даних часто містять цінну інформацію, яку важко отримати за допомогою запитів, заснованих лише на людській інтуїції. Методи машинного навчання можуть допомогти знайти приховані кореляції на графіках із мільярдами зв’язків. Ці кореляції можуть бути корисними для рекомендацій продуктів, прогнозування кредитоспроможності, виявлення шахрайства та багатьох інших випадків використання.
Neptune ML дає змогу створювати та навчати корисні моделі ML на великих графіках за години замість тижнів. Щоб досягти цього, Neptune ML використовує технологію GNN на базі Amazon SageMaker і Бібліотека глибоких графів (DGL) (який з відкритим вихідним кодом). GNN є новою областю штучного інтелекту (для прикладу див Комплексне дослідження графових нейронних мереж). Практичний посібник із використання GNN із DGL див Вивчення графових нейронних мереж за допомогою Deep Graph Library.
У цій публікації ми покажемо, як використовувати Neptune у нашому конвеєрі для генерування вбудовувань.
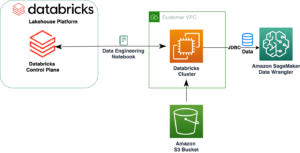
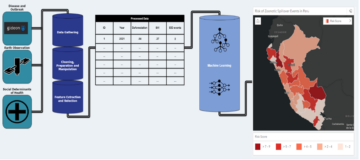
На наступній діаграмі зображено загальний потік даних IMDb від завантаження до генерації вбудовування.
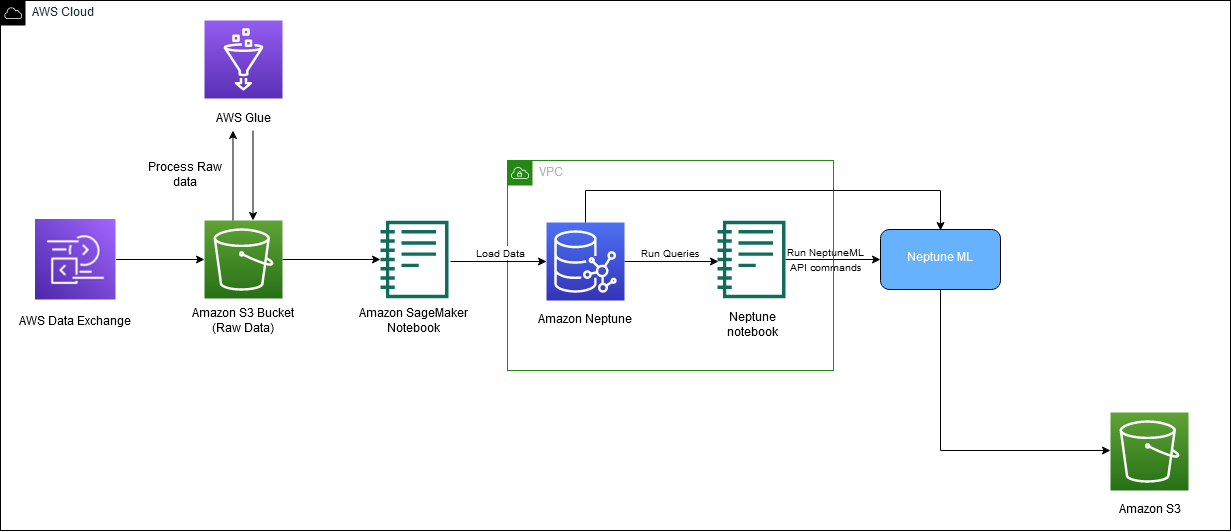
Для реалізації рішення ми використовуємо такі сервіси AWS:
У цій публікації ми проведемо вас через наступні етапи високого рівня:
- Налаштуйте змінні середовища
- Створіть завдання експорту.
- Створіть завдання обробки даних.
- Надішліть навчальну роботу.
- Завантажити вставки.
Код для команд Neptune ML
Ми використовуємо такі команди як частину реалізації цього рішення:
Ми використовуємо neptune_ml export щоб перевірити статус або почати процес експорту Neptune ML, а також neptune_ml training щоб почати та перевірити статус завдання навчання моделі Neptune ML.
Додаткову інформацію про ці та інші команди див Використання магії верстака Нептуна у ваших зошитах.
Передумови
Щоб слідувати цій публікації, ви повинні мати наступне:
- An Обліковий запис AWS
- Знайомство з SageMaker, Amazon S3 і AWS CloudFormation
- Дані графіка, завантажені в кластер Neptune (див Частина 1 для отримання додаткової інформації)
Налаштуйте змінні середовища
Перш ніж ми почнемо, вам потрібно буде налаштувати ваше середовище, встановивши наступні змінні: s3_bucket_uri та processed_folder. s3_bucket_uri це назва відра, яке використовується в частині 1 і processed_folder це розташування Amazon S3 для результату завдання експорту.
Створіть завдання експорту
У частині 1 ми створили блокнот SageMaker і службу експорту для експорту наших даних із кластера Neptune DB до Amazon S3 у потрібному форматі.
Тепер, коли наші дані завантажено і служба експорту створена, нам потрібно створити завдання експорту, запустити його. Для цього використовуємо NeptuneExportApiUri і створіть параметри для завдання експорту. У наступному коді ми використовуємо змінні expo та export_params. Встановити expo to your NeptuneExportApiUri значення, яке ви можете знайти на Виходи вкладку вашого стеку CloudFormation. для export_params, ми використовуємо кінцеву точку вашого кластера Neptune і надаємо значення для outputS3path, що є розташуванням Amazon S3 для результатів завдання експорту.
Щоб надіслати завдання експорту, скористайтеся такою командою:
Щоб перевірити статус завдання експорту, скористайтеся такою командою:
Після завершення роботи встановіть processed_folder змінна для надання Amazon S3 розташування оброблених результатів:
Створіть завдання обробки даних
Тепер, коли експорт завершено, ми створюємо завдання обробки даних, щоб підготувати дані для процесу навчання Neptune ML. Це можна зробити кількома різними способами. Для цього кроку ви можете змінити job_name та modelType змінні, але всі інші параметри повинні залишатися незмінними. Основною частиною цього коду є modelType параметр, який може бути різнорідним графовим моделям (heterogeneous) або графіки знань (kge).
Експортне завдання також включає training-data-configuration.json. Використовуйте цей файл, щоб додавати або видаляти будь-які вузли чи ребра, які ви не хочете надавати для навчання (наприклад, якщо ви хочете передбачити зв’язок між двома вузлами, ви можете видалити цей зв’язок у цьому файлі конфігурації). Для цієї публікації в блозі ми використовуємо вихідний файл конфігурації. Додаткову інформацію див Редагування файлу конфігурації навчання.
Створіть завдання обробки даних за допомогою такого коду:
Щоб перевірити статус завдання експорту, скористайтеся такою командою:
Надішліть навчальну роботу
Після завершення роботи з обробки ми можемо розпочати нашу навчальну роботу, у якій ми створюємо наші вбудовування. Ми рекомендуємо тип екземпляра ml.m5.24xlarge, але ви можете змінити це відповідно до своїх обчислювальних потреб. Перегляньте наступний код:
Ми друкуємо змінну training_results, щоб отримати ідентифікатор навчального завдання. Використовуйте таку команду, щоб перевірити статус вашого завдання:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Завантажити вставки
Після завершення навчальної роботи останнім кроком є завантаження необроблених вбудованих файлів. У наступних кроках показано, як завантажити вбудовані файли, створені за допомогою KGE (ви можете використати той самий процес для RGCN).
У наступному коді ми використовуємо neptune_ml.get_mapping() та get_embeddings() щоб завантажити файл відображення (mapping.info) і файл необроблених вбудованих файлів (entity.npy). Потім нам потрібно зіставити відповідні вбудовування з їхніми відповідними ідентифікаторами.
Щоб завантажити RGCN, виконайте той самий процес із новою назвою навчальної роботи, обробивши дані за допомогою параметра modelType, встановленого на heterogeneous, а потім навчайте вашу модель за допомогою параметра modelName, встановленого на rgcn побачити тут для більш детальної інформації. Коли це буде завершено, зателефонуйте get_mapping та get_embeddings функції для завантаження нового mapping.info та entity.npy файли. Коли у вас є файли сутності та зіставлення, процес створення файлу CSV є ідентичним.
Нарешті, завантажте свої вбудовування в потрібне розташування Amazon S3:
Переконайтеся, що ви запам’ятали це розташування S3, вам потрібно буде використовувати його в частині 3.
Прибирати
Коли ви закінчите користуватися рішенням, обов’язково очистіть усі ресурси, щоб уникнути поточних платежів.
Висновок
У цій публікації ми обговорили, як використовувати Neptune ML для навчання вбудовування GNN з даних IMDb.
Деякі пов’язані програми вбудовування графів знань – це такі поняття, як пошук поза каталогом, рекомендації вмісту, цільова реклама, передбачення відсутніх посилань, загальний пошук і когортний аналіз. Пошук поза каталогом – це процес пошуку вмісту, яким ви не володієте, і пошуку або рекомендації вмісту у вашому каталозі, який максимально наближений до того, що шукав користувач. У Частині 3 ми детальніше зануримося в пошук поза каталогом.
Про авторів
 Метью Роудс я спеціаліст з даних, я працюю в Amazon ML Solutions Lab. Він спеціалізується на створенні конвеєрів машинного навчання, які включають такі поняття, як обробка природної мови та комп’ютерне бачення.
Метью Роудс я спеціаліст з даних, я працюю в Amazon ML Solutions Lab. Він спеціалізується на створенні конвеєрів машинного навчання, які включають такі поняття, як обробка природної мови та комп’ютерне бачення.
 Дів'я Бхаргаві є спеціалістом із обробки даних і головним спеціалістом із медіа та розваг у Amazon ML Solutions Lab, де вона вирішує важливі бізнес-проблеми для клієнтів AWS за допомогою машинного навчання. Вона працює над розумінням зображень/відео, системами рекомендацій графів знань, сценаріями використання прогнозної реклами.
Дів'я Бхаргаві є спеціалістом із обробки даних і головним спеціалістом із медіа та розваг у Amazon ML Solutions Lab, де вона вирішує важливі бізнес-проблеми для клієнтів AWS за допомогою машинного навчання. Вона працює над розумінням зображень/відео, системами рекомендацій графів знань, сценаріями використання прогнозної реклами.
 Гаурав Реле є науковцем із даних у лабораторії рішень Amazon ML Solution Lab, де він працює з клієнтами AWS у різних галузях, щоб прискорити використання машинного навчання та хмарних служб AWS для вирішення їхніх бізнес-задач.
Гаурав Реле є науковцем із даних у лабораторії рішень Amazon ML Solution Lab, де він працює з клієнтами AWS у різних галузях, щоб прискорити використання машинного навчання та хмарних служб AWS для вирішення їхніх бізнес-задач.
 Каран Сіндвані є дослідником даних в Amazon ML Solutions Lab, де він створює та розгортає моделі глибокого навчання. Спеціалізується в області комп'ютерного зору. У вільний час захоплюється пішим туризмом.
Каран Сіндвані є дослідником даних в Amazon ML Solutions Lab, де він створює та розгортає моделі глибокого навчання. Спеціалізується в області комп'ютерного зору. У вільний час захоплюється пішим туризмом.
 Соджі Адешіна є прикладним науковцем в AWS, де він розробляє моделі на основі графових нейронних мереж для машинного навчання на графових завданнях із застосуваннями для шахрайства та зловживань, графів знань, систем рекомендацій і наук про життя. У вільний час любить читати та готувати.
Соджі Адешіна є прикладним науковцем в AWS, де він розробляє моделі на основі графових нейронних мереж для машинного навчання на графових завданнях із застосуваннями для шахрайства та зловживань, графів знань, систем рекомендацій і наук про життя. У вільний час любить читати та готувати.
 Від'я Сагар Равіпаті є менеджером Amazon ML Solutions Lab, де він використовує свій величезний досвід роботи з великомасштабними розподіленими системами та свою пристрасть до машинного навчання, щоб допомогти клієнтам AWS у різних галузевих галузях прискорити впровадження ШІ та хмари.
Від'я Сагар Равіпаті є менеджером Amazon ML Solutions Lab, де він використовує свій величезний досвід роботи з великомасштабними розподіленими системами та свою пристрасть до машинного навчання, щоб допомогти клієнтам AWS у різних галузевих галузях прискорити впровадження ШІ та хмари.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- МЕНЮ
- зловживання
- прискорювати
- через
- Додатковий
- Додаткова інформація
- Прийняття
- реклама
- після
- AI
- ВСІ
- тільки
- Amazon
- Лабораторія рішень Amazon ML
- аналіз
- та
- застосування
- прикладної
- Застосовувати
- відповідний
- ПЛОЩА
- штучний
- штучний інтелект
- AWS
- заснований
- між
- Мільярд
- мільярди
- Блог
- Box
- театральна каса
- будувати
- Створюємо
- Будує
- бізнес
- call
- випадок
- випадків
- каталог
- проблеми
- зміна
- вантажі
- перевірка
- близько
- хмара
- прийняття хмари
- хмарні сервіси
- кластер
- код
- Когорта
- повний
- всеосяжний
- комп'ютер
- Комп'ютерне бачення
- обчислення
- поняття
- Проводити
- конфігурація
- підключений
- зміст
- Відповідний
- країни
- створювати
- створений
- кредит
- кредити
- клієнт
- Залучення клієнтів
- Клієнти
- дані
- обробка даних
- вчений даних
- набори даних
- глибокий
- глибоке навчання
- глибше
- розгортає
- деталі
- розробка
- розвивається
- dgl
- різний
- відкриття
- обговорювати
- обговорювалися
- розподілений
- розподілені системи
- Не знаю
- скачати
- або
- з'являються
- Кінцева точка
- зачеплення
- розваги
- суб'єкта
- Навколишнє середовище
- Ефір (ETH)
- приклад
- досвід
- експорт
- витяг
- особливість
- кілька
- поле
- філе
- Файли
- знайти
- виявлення
- потік
- стежити
- після
- формат
- шахрайство
- від
- Повний
- Функції
- Загальне
- породжувати
- покоління
- отримати
- Глобальний
- Go
- графік
- графіки
- практичний
- Жорсткий
- допомога
- корисний
- прихований
- на вищому рівні
- ГОДИННИК
- Як
- How To
- HTML
- HTTPS
- людина
- однаковий
- ідентифікує
- здійснювати
- реалізації
- удосконалювати
- in
- includes
- У тому числі
- Augmenter
- індекс
- промисловість
- інформація
- інформація
- екземпляр
- замість
- Інтелект
- залучати
- IT
- робота
- json
- ключ
- знання
- lab
- мова
- великий
- масштабний
- останній
- вести
- вивчення
- важелі
- бібліотека
- ліцензія
- життя
- Life Sciences
- LINK
- зв'язку
- розташування
- машина
- навчання за допомогою машини
- головний
- РОБОТИ
- менеджер
- багато
- карта
- відображення
- Медіа
- середа
- члени
- метадані
- мільйона
- відсутній
- ML
- модель
- Моделі
- більше
- фільм
- ім'я
- Природний
- Обробка природних мов
- Необхідність
- потреби
- Нептун
- на основі мережі
- мереж
- нейронні мережі
- Нові
- вузли
- ноутбук
- Office
- постійний
- оригінал
- Інше
- загальний
- власний
- пакет
- параметр
- параметри
- частина
- пристрасть
- трубопровід
- plato
- Інформація про дані Платона
- PlatoData
- це можливо
- пошта
- влада
- Харчування
- передбачати
- прогнозування
- Готувати
- друк
- проблеми
- процес
- обробка
- Продукти
- профіль
- забезпечувати
- забезпечує
- діапазон
- рейтинги
- Сировина
- читання
- рекомендувати
- Рекомендація
- рекомендації
- рекомендуючи
- пов'язаний
- Відносини
- залишатися
- запам'ятати
- видаляти
- Звітність
- вимагається
- ресурси
- результати
- утримання
- мудрець
- то ж
- НАУКИ
- вчений
- Пошук
- Грати короля карти - безкоштовно Nijumi логічна гра гри
- Серія
- обслуговування
- Послуги
- комплект
- установка
- Повинен
- Показувати
- рішення
- Рішення
- ВИРІШИТИ
- Вирішує
- спеціалізується
- стек
- старт
- Статус
- Крок
- заходи
- зберігати
- представляти
- такі
- костюм
- Огляд
- Systems
- цільове
- завдання
- методи
- Технологія
- Команда
- Площа
- їх
- через
- час
- назви
- до
- поїзд
- Навчання
- Перетворення
- правда
- підручник
- tv
- розуміння
- використання
- використання випадку
- користувач
- Цінний
- значення
- величезний
- версія
- вертикалі
- бачення
- способи
- тижня
- Що
- який
- широкий
- Широкий діапазон
- волі
- робочий
- працює
- вашу
- зефірнет