Попереднє навчання сучасної моделі часто вимагає розгортання більшого кластера, щоб скоротити час і витрати. На рівні сервера такі навчальні навантаження вимагають швидшого обчислення та збільшення обсягу пам’яті. Коли моделі розростаються до сотень мільярдів параметрів, їм потрібен механізм розподіленого навчання, який охоплює кілька вузлів (примірників).
У жовтні 2022 року ми запустили Примірники Amazon EC2 Trn1, Живлення від AWS Trainium, який є прискорювачем машинного навчання другого покоління, розробленим AWS. Екземпляри Trn1 створені спеціально для високопродуктивного навчання моделі глибокого навчання, водночас пропонуючи до 50% економії вартості навчання порівняно з порівнянними екземплярами на основі GPU. Щоб скоротити час навчання з тижнів до днів або днів до годин, і розподілити навчальну роботу великої моделі, ми можемо використати EC2 Trn1 UltraCluster, який складається з щільно упакованих, розташованих поруч стійків обчислювальних екземплярів Trn1, які з’єднані між собою за допомогою неблокуюча петабайтна мережа. Це наш найбільший UltraCluster на сьогоднішній день, який пропонує 6 екзафлопс обчислювальної потужності за запитом із до 30,000 XNUMX мікросхем Trainium.
У цій публікації ми використовуємо робоче навантаження перед навчанням моделі Hugging Face BERT-Large як простий приклад, щоб пояснити, як використовувати UltraClusters Trn1.
Ультракластери Trn1
Trn1 UltraCluster — це група розміщення екземплярів Trn1 у центрі обробки даних. У рамках одного запуску кластера ви можете створити кластер екземплярів Trn1 за допомогою прискорювачів Trainium. На наступній діаграмі показано приклад.
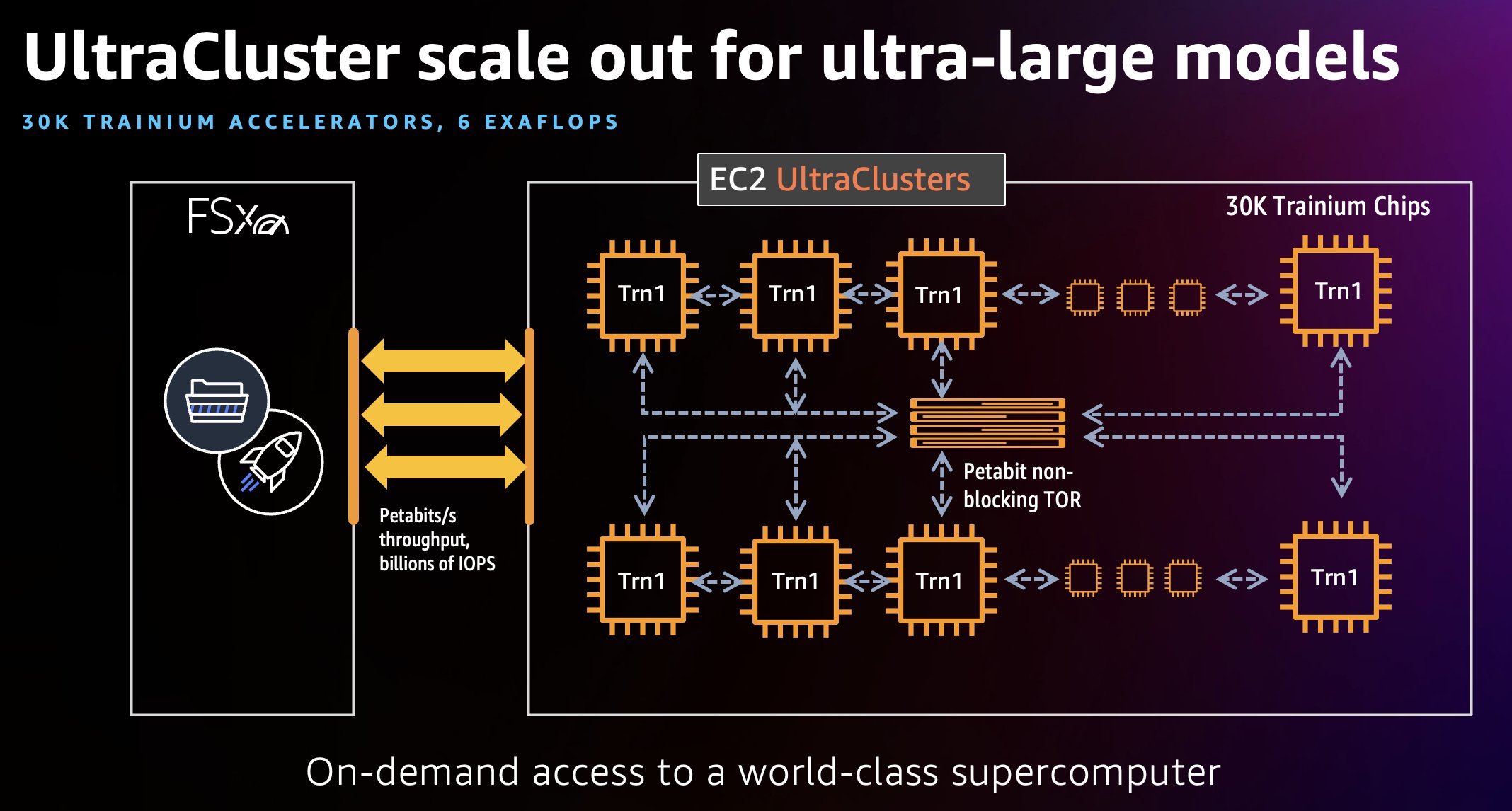
UltraClusters екземплярів Trn1 розташовані в центрі обробки даних і з’єднані між собою за допомогою Еластичний тканинний адаптер (EFA), який є петабайтним, неблокуючим мережевим інтерфейсом із пропускною здатністю мережі до 800 Гбіт/с, що вдвічі перевищує пропускну здатність, яку підтримують екземпляри AWS P4d (1.6 Тбіт/с, у чотири рази більше з майбутніми екземплярами Trn1n). Ці інтерфейси EFA допомагають запускати модельні навчальні робочі навантаження, які використовують Neuron Collective Communication Libraries у великому масштабі. Ультракластери Trn1 також включають суміжні служби зберігання, підключені до мережі, наприклад Amazon FSx для Luster для забезпечення високопродуктивного доступу до великих наборів даних, забезпечуючи ефективну роботу кластерів. Ультракластери Trn1 можуть розміщувати до 30,000 6 пристроїв Trainium і забезпечувати до 2 екзафлопс обчислень в одному кластері. EC1 Trn6 UltraClusters забезпечує до XNUMX екзафлопсів обчислення, буквально суперкомп’ютер на вимогу з моделлю використання оплати за використання. У цій публікації ми використовуємо деякі HPC-інструменти, такі як Slurm, щоб нарощувати UltraCluster і керувати робочими навантаженнями.
Огляд рішення
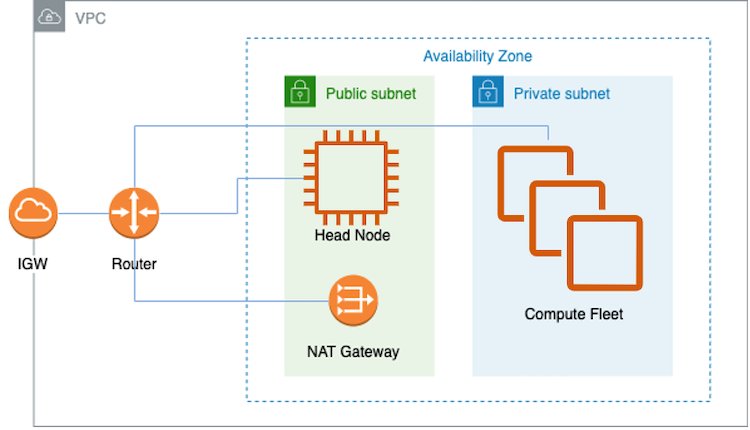
AWS пропонує широкий спектр послуг для навчання розподілених моделей або визначення робочих навантажень у масштабі, в тому числі Пакет AWS, Послуга Amazon Elastic Kubernetes (Amazon EKS) і UltraClusters. Ця публікація присвячена навчанню моделі в UltraCluster. Наше рішення використовує AWS ParallelCluster інструмент керування для створення необхідної інфраструктури та середовища для запуску Trn1 UltraCluster. Інфраструктура складається з головного вузла та кількох обчислювальних вузлів Trn1 у віртуальній приватній хмарі (VPC). Ми використовуємо Slurm як систему управління кластером і планування завдань. Наступна діаграма ілюструє архітектуру нашого рішення.
Додаткову інформацію та способи розгортання цього рішення див Навчання моделі на AWS Trn1 ParallelCluster.
Давайте розглянемо деякі важливі кроки цього рішення:
- Створіть VPC і підмережі.
- Налаштуйте обчислювальний парк.
- Створіть кластер.
- Огляньте кластер.
- Розпочніть свою навчальну роботу.
Передумови
Додатково до цієї публікації, широке знайомство з основними службами AWS, такими як Обчислювальна хмара Amazon Elastic (Amazon EC2) мається на увазі, і базове знайомство з глибоким навчанням і PyTorch було б корисним.
Створення VPC і підмереж
Простий спосіб створити VPC і підмережі — через Віртуальна приватна хмара Amazon (Amazon VPC) консоль. Повні інструкції можна знайти на GitHub. Після встановлення VPC і підмереж вам потрібно налаштувати екземпляри в обчислювальній групі. Коротко кажучи, це стало можливим завдяки сценарію встановлення, визначеному CustomActions у файлі YAML, який використовується для створення ParallelCluster (див. Створіть ParallelCluster). Для ParallelCluster потрібен VPC, який має дві підмережі та шлюз трансляції мережевих адрес (NAT), як показано на попередній діаграмі архітектури. Цей VPC має знаходитися в зонах доступності, де доступні екземпляри Trn1. Крім того, у цьому VPC вам потрібно мати загальнодоступну підмережу та приватну підмережу для розміщення головного вузла та обчислювальних вузлів Trn1 відповідно. Вам також потрібен доступ до Інтернету через шлюз NAT, щоб обчислювальні вузли Trn1 могли завантажувати AWS нейрон пакети. Загалом обчислювальні вузли отримуватимуть оновлення для пакетів ОС, драйвера Neuron і середовища виконання, а також драйвера EFA для навчання кількох екземплярів.
Що стосується головного вузла, окрім вищезгаданих компонентів для обчислювальних вузлів, він також отримує компілятор PyTorch-NeuronX і NeuronX, який забезпечує процес компіляції моделі в пристроях XLA, таких як Trainium.
Налаштуйте обчислювальний парк
У файлі YAML для створення Trn1 UltraCluster InstanceType вказано як trn1.32xlarge. MaxCount та MinCount використовуються для позначення діапазону розміру вашого обчислювального парку. Ви можете використовувати MinCount щоб деякі або всі екземпляри Trn1 залишалися доступними в будь-який час. MinCount може бути встановлено на нуль, щоб у разі відсутності запущеного завдання екземпляри Trn1 вивільнялися з цього кластера.
Trn1 також можна розгорнути в UltraCluster з кількома чергами. У наведеному нижче прикладі для надсилання завдань Slurm налаштовується лише одна черга:
Якщо вам потрібна більше однієї черги, ви можете вказати кілька InstanceType, у кожного своє MaxCount, MinCount та Name:
Тут встановлено дві черги, щоб користувач міг гнучко вибирати ресурси для свого завдання Slurm.
Створіть кластер
Щоб запустити Trn1 UltraCluster, використовуйте наступне pcluster команда звідки ваш Інструмент ParallelCluster встановлено:
У цій команді ми використовуємо такі параметри:
--cluster-configuration– Цей параметр очікує файл YAML, який описує конфігурацію кластера-n(Або--cluster-name) – назва цього кластера
Ця команда створює кластер Trn1 у вашому обліковому записі AWS. Ви можете перевірити хід створення кластера на AWS CloudFormation консоль. Для отримання додаткової інформації див Використання консолі AWS CloudFormation.
Крім того, ви можете скористатися такою командою, щоб переглянути статус свого запиту:
і команда вкаже статус, наприклад:
Нижче наведено цікаві параметри з вихідних даних:
- instanceId – Це ідентифікатор екземпляра головного вузла, який буде вказано на консолі Amazon EC2
- computeFleetStatus – Цей атрибут вказує на готовність обчислювальних вузлів
- Теги – Цей атрибут вказує на версію
pclusterінструмент, який використовується для створення цього кластера
Огляньте кластер
Ви можете використовувати вищезазначене pcluster describe-cluster команда для перевірки кластера. Після створення кластера ви побачите наступне:
На цьому етапі ви можете підключитися через SSH до головного вузла (ідентифікованого ідентифікатором екземпляра на консолі Amazon EC2). Нижче наведена логічна схема кластера.
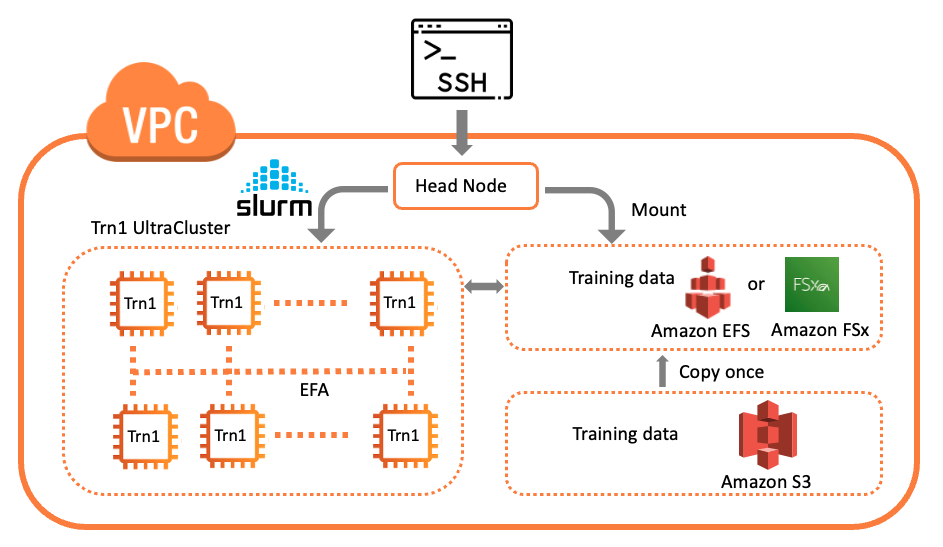
Після підключення SSH до головного вузла ви можете перевірити обчислювальний парк і його статус за допомогою команди Slurm, наприклад sinfo щоб переглянути інформацію про вузол системи. Нижче наведено приклад вихідних даних:
Це означає, що існує одна черга, як показано одним розділом. Доступно 16 вузлів і розподілено ресурси. З головного вузла ви можете зайти через SSH у будь-який заданий обчислювальний вузол:
Скористайтесь exit щоб повернутися до головного вузла.
Подібним чином ви можете підключитися до обчислювального вузла через SSH з іншого обчислювального вузла. На кожному обчислювальному вузлі встановлено інструменти Neuron, наприклад neuron-top. Ви можете викликати neuron-top під час запуску сценарію навчання для перевірки використання NeuronCore на кожному вузлі.
Розпочніть свою навчальну роботу
Ми використовуємо Hugging Face BERT-великий підручник для підготовки як приклад для запуску в цьому кластері. Після того, як навчальні дані та сценарії завантажено в кластер, ми використовуємо контролер Slurm для керування та оркестрування нашого робочого навантаження. Подаємо навчальну роботу з sbatch команда. Сценарій оболонки викликає сценарій Python через neuron_parallel_compile API для компіляції моделі в графіки без повного тренування. Перегляньте наступний код:
У цій команді ми використовуємо такі параметри:
--exclusive– Це завдання використовуватиме всі вузли та не ділитиметься вузлами з іншими завданнями під час виконання поточного завдання.--nodes– Кількість вузлів для цієї роботи.--wrap– Це визначає командний рядок, який виконується контролером Slurm. У цьому випадку він просто компілює модель паралельно з використанням усіх вузлів.
Після успішної компіляції моделі ви можете розпочати повне навчання за допомогою такої команди:
Ця команда запустить навчальне завдання для моделі Hugging Face BERT-Large. З 16 вузлами Trn1.32xlarge ви можете очікувати, що це буде завершено менш ніж за 8 годин.
На цьому етапі ви можете використовувати команду Slurm, наприклад squeue перевірити подану роботу. Приклад результату виглядає так:
Цей вихід показує, що завдання виконується (R) на 16 обчислювальних вузлах.
Під час виконання завдання результати фіксуються та додаються у файл журналу Slurm. З терміналу головного вузла ви можете перевірити його в режимі реального часу.
Крім того, у тому ж каталозі, що й файл журналу Slurm, є відповідний каталог для цієї роботи. Цей каталог містить наступне (наприклад):
Цей каталог доступний для всіх обчислювальних вузлів. results.json фіксує метадані цього конкретного виконання завдання, наприклад конфігурацію моделі, розмір партії, загальну кількість кроків, кроки накопичення градієнта та назву набору даних навчання. Контрольна точка моделі та вихідний журнал для кожного обчислювального вузла також записуються в цей каталог.
Розглянемо масштабованість кластера
У Trn1 UltraCluster кілька взаємопов’язаних екземплярів Trn1 паралельно запускають велике робоче навантаження для навчання моделі та скорочують загальний час обчислень або час для конвергенції. Існує дві міри масштабованості кластера: сильне масштабування та слабке масштабування. Як правило, для навчання моделі необхідно прискорити виконання навчання, оскільки вартість використання визначається пропускною здатністю вибірки для раундів оновлень градієнта. Сильне масштабування відноситься до сценарію, коли загальний розмір проблеми залишається незмінним, оскільки кількість процесорів збільшується. Сильне масштабування є важливим показником масштабованості для навчання моделі. Оцінюючи сильне масштабування (тобто вплив розпаралелювання), ми хочемо зберегти глобальний розмір пакета незмінним і побачити, скільки часу потрібно для конвергенції. У такому сценарії нам потрібно налаштувати мікрокрок накопичення градієнта відповідно до кількості обчислювальних вузлів. Це досягається за допомогою наступного сценарію навчальної оболонки run_dp_bert_large_hf_pretrain_bf16_s128.sh:
З іншого боку, якщо ви хочете оцінити, скільки додаткових навантажень можна запустити за фіксований час, додавши більше вузлів, використовуйте слабке масштабування для вимірювання масштабованості. При слабкому масштабуванні розмір проблеми зростає з тією ж швидкістю, що й кількість NeuronCoress, таким чином зберігаючи обсяг роботи на NeuronCores незмінним. Щоб оцінити слабке масштабування або вплив додавання додаткових вузлів на збільшення робочого навантаження, просто видаліть наведений вище рядок із сценарію навчання та збережіть кількість кроків для накопичення градієнта незмінною зі значенням за замовчуванням (32), наданим у сценарії навчання.
Оцініть свої результати
Ми надаємо деякі порівняльні результати в Сторінка продуктивності нейронів продемонструвати ефект масштабування. Дані демонструють переваги використання кількох екземплярів для розпаралелювання навчального завдання для багатьох різних великих моделей для навчання в масштабі.
Очистіть свою інфраструктуру
Щоб видалити всю інфраструктуру цього UltraCluster, скористайтеся pcluster команда для видалення кластера та його ресурсів:
Висновок
У цій публікації ми обговорили, як масштабування вашого навчального завдання на Trn1-UltraCluster, який працює на прискорювачах Trainium в AWS, скорочує час на навчання моделі. Ми також надали посилання на Сховище зразків нейронів, який містить інструкції щодо розгортання розподіленого навчального завдання для моделі BERT-Large. Trn1-UltraCluster запускає розподілені навчальні навантаження для навчання надвеликих моделей глибокого навчання в масштабі. Налаштування розподіленого навчання призводить до набагато швидшої конвергенції моделі порівняно з навчанням на одному екземплярі Trn1.
Щоб дізнатися більше про те, як розпочати роботу з екземплярами Trn1 на базі Trainium, відвідайте веб-сторінку Документація нейронів.
Про авторів
 KC Tung є старшим архітектором рішень в AWS Annapurna Labs. Він спеціалізується на навчанні та розгортанні великої моделі глибокого навчання в хмарі. Має ступінь доктора філософії. доктор молекулярної біофізики в Південно-Західному медичному центрі Техаського університету в Далласі. Він виступав на AWS Summits і AWS Reinvent. Сьогодні він допомагає клієнтам навчати та розгортати великі моделі PyTorch і TensorFlow у хмарі AWS. Він є автором двох книг: Дізнайтеся про TensorFlow Enterprise та Кишеньковий довідник TensorFlow 2.
KC Tung є старшим архітектором рішень в AWS Annapurna Labs. Він спеціалізується на навчанні та розгортанні великої моделі глибокого навчання в хмарі. Має ступінь доктора філософії. доктор молекулярної біофізики в Південно-Західному медичному центрі Техаського університету в Далласі. Він виступав на AWS Summits і AWS Reinvent. Сьогодні він допомагає клієнтам навчати та розгортати великі моделі PyTorch і TensorFlow у хмарі AWS. Він є автором двох книг: Дізнайтеся про TensorFlow Enterprise та Кишеньковий довідник TensorFlow 2.
 Джеффрі Гюйн є головним інженером AWS Annapurna Labs. Він захоплений тим, щоб допомогти клієнтам виконувати їхнє навчання та робочі навантаження з висновків на прискорювачах Trainium та Inferentia за допомогою AWS Neuron SDK. Він є випускником Каліфорнійського технологічного інституту/Стенфордського університету зі ступенем фізики та EE. Йому подобається бігати, грати в теніс, готувати їжу та читати про науку та техніку.
Джеффрі Гюйн є головним інженером AWS Annapurna Labs. Він захоплений тим, щоб допомогти клієнтам виконувати їхнє навчання та робочі навантаження з висновків на прискорювачах Trainium та Inferentia за допомогою AWS Neuron SDK. Він є випускником Каліфорнійського технологічного інституту/Стенфордського університету зі ступенем фізики та EE. Йому подобається бігати, грати в теніс, готувати їжу та читати про науку та техніку.
 Шруті Копаркар є старшим менеджером з маркетингу продуктів в AWS. Вона допомагає клієнтам вивчити, оцінити та застосувати прискорену обчислювальну інфраструктуру EC2 для потреб машинного навчання.
Шруті Копаркар є старшим менеджером з маркетингу продуктів в AWS. Вона допомагає клієнтам вивчити, оцінити та застосувати прискорену обчислювальну інфраструктуру EC2 для потреб машинного навчання.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/scaling-large-language-model-llm-training-with-amazon-ec2-trn1-ultraclusters/
- 000
- 1
- 10
- 100
- 102
- 2022
- 7
- 9
- a
- МЕНЮ
- вище
- прискорений
- прискорювач
- прискорювачі
- доступ
- доступною
- За
- рахунки
- накопичення
- досягнутий
- через
- доповнення
- адреса
- прийняти
- після
- ВСІ
- виділено
- розподіл
- Amazon
- Amazon EC2
- кількість
- та
- Інший
- API
- архітектура
- прикріплений
- автор
- наявність
- доступний
- AWS
- AWS CloudFormation
- назад
- ширина смуги
- основний
- оскільки
- буття
- еталонний тест
- користь
- мільярди
- Біофізика
- книги
- коротко
- приносити
- широкий
- побудований
- Виклики
- захвати
- випадок
- Центр
- перевірка
- Чіпси
- Вибирати
- хмара
- кластер
- код
- Collective
- Комунікація
- порівнянний
- порівняний
- повний
- Компоненти
- обчислення
- обчислення
- обчислення
- конфігурація
- Консоль
- постійна
- містить
- контролер
- Зближення
- приготування
- Core
- Відповідний
- Коштувати
- створювати
- створений
- створює
- створення
- створення
- Поточний
- Клієнти
- Даллас
- дані
- Центр обробки даних
- набори даних
- Дата
- Днів
- глибокий
- глибоке навчання
- дефолт
- Визначає
- доставляти
- Попит
- демонструвати
- демонструє
- розгортання
- розгорнути
- розгортання
- призначений
- деталі
- певний
- прилади
- різний
- обговорювалися
- поширювати
- розподілений
- розподілене навчання
- вниз
- скачати
- водій
- під час
- кожен
- ефект
- продуктивно
- включіть
- дозволяє
- інженер
- забезпечення
- Навколишнє середовище
- Ефір (ETH)
- оцінювати
- оцінки
- приклад
- очікувати
- чекає
- Пояснювати
- дослідити
- тканину
- Face
- Знайомство
- швидше
- філе
- фіксованою
- ФЛЕТ
- Гнучкість
- фокусується
- стежити
- після
- слідує
- знайдений
- від
- Повний
- шлюз
- Загальне
- покоління
- отримати
- Git
- даний
- Глобальний
- графіки
- великий
- Group
- Рости
- рука
- голова
- допомога
- корисний
- допомогу
- допомагає
- Високий
- висока продуктивність
- тримати
- господар
- ГОДИННИК
- Як
- How To
- к.с.
- HTML
- HTTPS
- Сотні
- ідентифікований
- Impact
- мається на увазі
- важливо
- in
- включати
- includes
- У тому числі
- збільшений
- Збільшує
- вказувати
- вказує
- інформація
- Інфраструктура
- встановлений
- екземпляр
- інструкції
- взаємопов'язані
- інтерес
- інтерфейс
- Інтерфейси
- інтернет
- Доступ в інтернет
- викликає
- IT
- січень
- робота
- Джобс
- json
- тримати
- зберігання
- ключ
- Кубернетес
- Labs
- мова
- великий
- більше
- найбільших
- запуск
- запущений
- УЧИТЬСЯ
- вивчення
- рівень
- libraries
- Лінія
- LINK
- Перераховані
- логічний
- подивитися
- машина
- навчання за допомогою машини
- made
- управляти
- управління
- менеджер
- багато
- Маркетинг
- вимір
- заходи
- механізм
- медичний
- пам'ять
- метадані
- модель
- Моделі
- молекулярний
- більше
- множинний
- ім'я
- необхідно
- Необхідність
- потреби
- мережу
- мережа
- вузол
- вузли
- номер
- спостерігати
- жовтень
- пропонує
- Пропозиції
- ONE
- працювати
- варіант
- Опції
- порядок
- OS
- Інше
- власний
- пакети
- упакований
- Паралельні
- параметри
- частина
- приватність
- пристрасний
- продуктивність
- петабайт
- Фізика
- plato
- Інформація про дані Платона
- PlatoData
- точка
- це можливо
- пошта
- влада
- Харчування
- Головний
- приватний
- Проблема
- процес
- процесори
- Product
- прогрес
- забезпечувати
- за умови
- громадськість
- мета
- Python
- піторх
- Рамп
- діапазон
- ставка
- Готовність
- читання
- реальний
- реального часу
- причина
- отримати
- отримує
- зменшити
- знижує
- відноситься
- регіон
- випущений
- видаляти
- запросити
- вимагати
- Вимагається
- ресурси
- результати
- турів
- прогін
- біг
- то ж
- Економія
- масштабованість
- шкала
- Масштабування
- сценарій
- наука
- Наука і технології
- scripts
- другий
- Друге покоління
- старший
- Послуги
- комплект
- установка
- Поділитись
- Склад
- показаний
- Шоу
- простий
- просто
- один
- Розмір
- So
- рішення
- деякі
- прольоти
- спеціалізується
- зазначений
- швидкість
- Спін
- старт
- почалася
- стан
- Статус
- заходи
- зберігання
- сильний
- уявлення
- представляти
- представлений
- підмережі
- підмережі
- Успішно
- такі
- саміти
- суперкомп'ютер
- Підтриманий
- система
- приймає
- Технологія
- теніс
- тензорний потік
- термінал
- Техас
- Команда
- їх
- тим самим
- через
- пропускна здатність
- час
- times
- до
- сьогодні
- інструмент
- інструменти
- Усього:
- поїзд
- Навчання
- Переклад
- типово
- Ubuntu
- університет
- Майбутні
- Updates
- URL
- Використання
- використання
- користувач
- значення
- різноманітність
- перевірити
- версія
- через
- вид
- Віртуальний
- тижня
- який
- в той час як
- широкий
- волі
- в
- без
- Work
- б
- обернути
- ямл
- вашу
- зефірнет
- нуль
- зони