Коли OpenAI випустили третє покоління своєї моделі машинного навчання (ML), яка спеціалізується на генерації тексту, у липні 2020 року, я знав, що щось інше. Ця модель вразила нерви, як ніхто, що був до неї. Раптом я почув, як друзі та колеги, які, можливо, цікавляться технологіями, але зазвичай не піклуються про останні досягнення у сфері AI/ML, говорять про це. Навіть The Guardian писав Стаття про це. Або, якщо бути точним, то модель написав статтю, а Guardian відредагував і опублікував її. Не можна було заперечувати – GPT-3 змінив гру.
Після того, як модель була випущена, люди відразу почали придумувати потенційні застосування для неї. За кілька тижнів було створено багато вражаючих демонстрацій, які можна знайти на сайті Веб-сайт GPT-3. Одна конкретна програма, яка впала мені в очі узагальнення тексту - здатність комп'ютера читати заданий текст і узагальнювати його зміст. Це одне з найскладніших завдань для комп’ютера, оскільки він поєднує в собі дві сфери обробки природної мови (NLP): розуміння читання та генерування тексту. Ось чому мене так вразили демонстрації GPT-3 для узагальнення тексту.
Ви можете спробувати їх Веб-сайт Hugging Face Spaces. Мій улюблений на даний момент це an додатку який створює резюме статей новин із лише URL-адресою статті в якості вхідних даних.
У цій серії, що складається з двох частин, я пропоную практичний посібник для організацій, щоб ви могли оцінити якість моделей узагальнення тексту для вашого домену.
Огляд підручника
Багато організацій, з якими я працюю (благодійні організації, компанії, НУО), мають величезну кількість текстів, які їм потрібно прочитати та узагальнити – фінансові звіти чи статті новин, науково-дослідницькі роботи, патентні заявки, юридичні контракти тощо. Природно, ці організації зацікавлені в автоматизації цих завдань за допомогою технології НЛП. Щоб продемонструвати мистецтво можливого, я часто використовую демонстраційні відео узагальнення тексту, які майже ніколи не вражають.
Але тепер що?
Проблема для цих організацій полягає в тому, що вони хочуть оцінити моделі узагальнення тексту на основі резюме для багатьох, багатьох документів, а не по одному. Вони не хочуть наймати стажера, єдина робота якого – відкрити програму, вставити документ, натиснути кнопку Підсумувати натисніть кнопку, дочекайтеся результату, оцініть, чи є підсумок хорошим, і повторіть це знову для тисяч документів.
Я написав цей підручник, маючи на увазі своє минуле чотири тижні тому – це підручник, який я хотів би мати тоді, коли я почав цю подорож. У цьому сенсі цільовою аудиторією цього підручника є ті, хто знайомий з AI/ML і раніше використовував моделі Transformer, але перебуває на початку свого шляху узагальнення тексту та хоче зануритися в це глибше. Оскільки він написаний «початківцем» і для початківців, я хочу підкреслити той факт, що цей посібник a практичний посібник – ні практичний посібник. Будь ласка, ставтеся до цього так, ніби Джордж EP Box сказав:
![]()
З точки зору того, скільки технічних знань потрібно в цьому підручнику: він дійсно передбачає деяке кодування на Python, але більшість часу ми просто використовуємо код для виклику API, тому глибокі знання кодування також не потрібні. Корисно знати певні поняття ML, наприклад, що це означає поїзд та розгортання модель, концепції навчання, перевірка достовірності та тестові набори даних, і так далі. Також насолодившись Бібліотека трансформерів раніше може бути корисним, оскільки ми широко використовуємо цю бібліотеку в цьому підручнику. Я також додаю корисні посилання для подальшого читання цих понять.
Оскільки цей підручник написаний початківцем, я не очікую, що експерти НЛП та досвідчені практики глибокого навчання отримають більшу частину цього підручника. Принаймні не з технічної точки зору – ви все ще можете насолоджуватися читанням, тому, будь ласка, не залишайте поки що! Але вам доведеться набратися терпіння щодо моїх спрощень – я намагався жити за концепцією, щоб зробити все в цьому підручнику якомога простіше, але не простіше.
Структура цього підручника
Ця серія складається з чотирьох розділів, розділених на дві публікації, в яких ми проходимо різні етапи проекту узагальнення тексту. У першому дописі (розділ 1) ми починаємо з введення метрики для завдань на узагальнення тексту – показника ефективності, який дозволяє нам оцінити, хороший підсумок чи поганий. Ми також представляємо набір даних, який ми хочемо узагальнити, і створюємо базову лінію, використовуючи модель без ML – ми використовуємо просту евристику, щоб створити підсумок із заданого тексту. Створення цього базового сценарію є життєво важливим кроком у будь-якому проекті ML, оскільки він дає нам змогу кількісно оцінити, наскільки прогрес ми досягаємо, використовуючи AI у майбутньому. Це дозволяє нам відповісти на питання «Чи дійсно варто інвестувати в технології AI?»
У другій публікації ми використовуємо модель, яку вже попередньо навчили для створення підсумків (розділ 2). Це можливо за допомогою сучасного підходу в ML під назвою трансферне навчання. Це ще один корисний крок, оскільки ми в основному беремо готову модель і тестуємо її на нашому наборі даних. Це дозволяє нам створити ще одну базову лінію, яка допоможе нам побачити, що відбувається, коли ми насправді навчаємо модель на нашому наборі даних. Підхід називається нульовий підсумок, оскільки модель не мала доступу до нашого набору даних.
Після цього настав час використовувати попередньо навчену модель і навчити її на нашому власному наборі даних (розділ 3). Це також називається тонка настройка. Це дозволяє моделі вчитися на моделях та особливостях наших даних і повільно адаптуватися до них. Після навчання моделі ми використовуємо її для створення підсумків (розділ 4).
Підіб'ємо підсумки:
- Частина 1:
- Розділ 1: Використовуйте модель без ML для встановлення базової лінії
- Частина 2:
- Розділ 2: Створення підсумків за допомогою моделі нульового пострілу
- Розділ 3: Навчіть модель узагальнення
- Розділ 4: Оцініть навчену модель
Повний код цього підручника доступний нижче GitHub репо.
Чого ми досягнемо до кінця цього уроку?
До кінця цього підручника ми НЕ буде мати модель узагальнення тексту, яку можна використовувати у виробництві. У нас навіть не буде добре модель підсумовування (вставте емодзі крику тут)!
Натомість у нас буде відправна точка для наступного етапу проекту, який є етапом експериментів. Ось тут і з’являється «наука» в науці про дані, тому що тепер це все про експерименти з різними моделями та різними налаштуваннями, щоб зрозуміти, чи можна навчити досить хорошу модель підсумовування з доступними навчальними даними.
І, щоб бути повністю прозорим, є велика ймовірність, що висновок буде, що технологія просто ще не дозріла і проект не буде реалізований. І ви повинні підготувати зацікавлені сторони вашого бізнесу до такої можливості. Але це тема для іншого повідомлення.
Розділ 1: Використовуйте модель без ML для встановлення базової лінії
Це перший розділ нашого підручника зі створення проекту узагальнення тексту. У цьому розділі ми встановлюємо базову лінію, використовуючи дуже просту модель, фактично не використовуючи ML. Це дуже важливий крок у будь-якому проекті ML, оскільки він дає нам змогу зрозуміти, яку цінність додає ML за час проекту та чи варто інвестувати в нього.
Код для підручника можна знайти нижче GitHub репо.
Дані, дані, дані
Кожен проект ML починається з даних! Якщо можливо, ми завжди повинні використовувати дані, пов’язані з тим, чого ми хочемо досягти за допомогою проекту узагальнення тексту. Наприклад, якщо наша мета — узагальнити патентні заявки, ми також повинні використовувати патентні заявки для навчання моделі. Великим застереженням для проекту ML є те, що навчальні дані зазвичай мають бути позначені. У контексті узагальнення тексту це означає, що нам потрібно надати текст, який потрібно узагальнити, а також резюме (мітку). Тільки надавши обидва, модель може дізнатися, як виглядає гарне резюме.
У цьому підручнику ми використовуємо загальнодоступний набір даних, але кроки та код залишаються точно такими ж, якщо ми використовуємо користувацький або приватний набір даних. І знову ж таки, якщо у вас є ціль для вашої моделі узагальнення тексту і ви маєте відповідні дані, використовуйте замість цього свої дані, щоб отримати максимальну віддачу від цього.
Дані, які ми використовуємо, це Набір даних arXiv, який містить тези доповідей arXiv, а також їх назви. Для нашої мети ми використовуємо анотацію як текст, який ми хочемо узагальнити, а заголовок — як довідкове резюме. Усі етапи завантаження та попередньої обробки даних доступні нижче ноутбук. Ми вимагаємо Управління ідентифікацією та доступом AWS (IAM), яка дозволяє завантажувати дані до та з Служба простого зберігання Amazon (Amazon S3), щоб успішно запустити цей ноутбук. Набір даних був розроблений як частина статті Про використання ArXiv як набору даних і має ліцензію згідно з Creative Commons CC0 1.0 Універсальне присвоєння суспільного надбання.
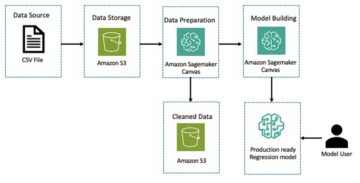
Дані поділяються на три набори даних: навчальні, перевірочні та тестові дані. Якщо ви хочете використовувати власні дані, переконайтеся, що це теж саме так. Наступна діаграма ілюструє, як ми використовуємо різні набори даних.
![]()
Природно, поширене запитання на цьому етапі: скільки даних нам потрібно? Як ви, напевно, вже здогадалися, відповідь: це залежить. Це залежить від того, наскільки спеціалізованим є домен (узагальнення патентних заяв значно відрізняється від узагальнення статей новин), наскільки точною має бути модель, щоб бути корисною, скільки має коштувати навчання моделі тощо. Ми повернемося до цього питання пізніше, коли ми фактично навчатимемо модель, але коротко: ми повинні випробувати різні розміри наборів даних, коли ми знаходимося на етапі експерименту проекту.
Що робить хорошу модель?
У багатьох проектах ML досить просто виміряти продуктивність моделі. Це тому, що зазвичай немає невизначеності щодо того, чи правильний результат моделі. Мітки в наборі даних часто двійкові (правда/неправда, так/ні) або категоричні. У будь-якому випадку в цьому сценарії легко порівняти вихід моделі з міткою і позначити його як правильний або неправильний.
Під час створення тексту це стає складнішим. Підсумки (мітки), які ми надаємо в нашому наборі даних, є лише одним із способів узагальнення тексту. Але є багато можливостей для узагальнення даного тексту. Отже, навіть якщо модель не відповідає нашій мітці 1:1, результат може бути дійсним і корисним підсумком. Отже, як ми порівняємо підсумок моделі з тим, який ми надаємо? Метрикою, яка найчастіше використовується при узагальненні тексту для вимірювання якості моделі, є метрика Оцінка ROUGE. Щоб зрозуміти механіку цієї метрики, див Найвищий показник ефективності в НЛП. Підсумовуючи, оцінка ROUGE вимірює перекриття n-грамів (безперервна послідовність n елементів) між підсумком моделі (зведенням кандидата) та еталонним підсумком (мітка, яку ми надаємо в нашому наборі даних). Але, звичайно, це не ідеальний захід. Щоб зрозуміти його обмеження, перегляньте ROUGE чи ні ROUGE?
Отже, як ми обчислимо оцінку ROUGE? Існує чимало пакетів Python для обчислення цієї метрики. Щоб забезпечити узгодженість, ми повинні використовувати один і той же метод протягом усього нашого проекту. Оскільки пізніше в цьому підручнику ми будемо використовувати навчальний сценарій із бібліотеки Transformers замість того, щоб писати власний, ми можемо просто зазирнути в вихідні сценарію та скопіюйте код, який обчислює оцінку ROUGE:
Використовуючи цей метод для обчислення балів, ми гарантуємо, що ми завжди порівнюємо яблука з яблуками протягом усього проекту.
Ця функція обчислює кілька балів ROUGE: rouge1, rouge2, rougeL та rougeLsum. «Сума» в rougeLsum посилається на той факт, що ця метрика обчислюється для всього підсумку, тоді як rougeL обчислюється як середнє значення для окремих речень. Отже, яку оцінку ROUGE ми повинні використовувати для нашого проекту? Знову ж таки, ми повинні спробувати різні підходи на етапі експерименту. Для чого це варте, оригінальний папір ROUGE стверджується, що «ROUGE-2 і ROUGE-L добре працювали в задачах узагальнення одного документа», тоді як «ROUGE-1 і ROUGE-L відмінно справляються з оцінкою коротких резюме».
Створіть базову лінію
Далі ми хочемо створити базову лінію, використовуючи просту модель без ML. Що це означає? У сфері узагальнення тексту багато досліджень використовують дуже простий підхід: вони беруть перший n речення тексту і оголосити його резюме кандидата. Потім вони порівнюють підсумок кандидата з довідковим підсумком і обчислюють оцінку ROUGE. Це простий, але потужний підхід, який ми можемо реалізувати за допомогою кількох рядків коду (весь код для цієї частини наведено нижче ноутбук):
Для цієї оцінки ми використовуємо набір тестових даних. Це має сенс, оскільки після навчання моделі ми також використовуємо той самий набір тестових даних для остаточної оцінки. Ми також намагаємося використовувати різні числа n: ми починаємо лише з першого речення як резюме кандидата, потім з перших двох речень і, нарешті, з перших трьох речень.
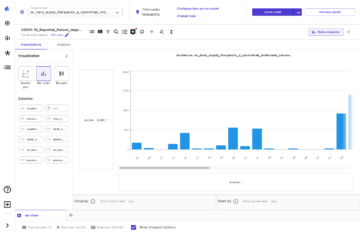
Наступний знімок екрана показує результати для нашої першої моделі.
![]()
Оцінки ROUGE найвищі, лише перше речення є підсумком кандидата. Це означає, що використання більш ніж одного речення робить резюме занадто багатослівним і призводить до нижчої оцінки. Тож це означає, що ми використовуватимемо бали для резюме з одного речення як базову лінію.
Важливо зазначити, що для такого простого підходу ці цифри насправді досить непогані, особливо для rouge1 оцінка. Щоб помістити ці цифри в контекст, ми можемо посилатися на Моделі Пегаса, який показує результати найсучаснішої моделі для різних наборів даних.
Висновок і що далі
У частині 1 нашої серії ми представили набір даних, який ми використовуємо в проекті узагальнення, а також метрику для оцінки підсумків. Потім ми створили наступну базову лінію з простою моделлю без ML.
![]()
У наступний пост, ми використовуємо модель нульового кадру – зокрема, модель, яка була спеціально навчена для узагальнення тексту в публічних новинах. Однак ця модель взагалі не буде навчатися на нашому наборі даних (звідси назва «нульовий постріл»).
Я залишаю вам як домашнє завдання здогадатися, як буде працювати ця модель з нульовим ефектом порівняно з нашим дуже простим базовим рівнем. З одного боку, це буде набагато складніша модель (насправді це нейронна мережа). З іншого боку, він використовується лише для узагальнення статей новин, тому він може боротися з шаблонами, властивими набору даних arXiv.
Про автора
![]() Хайко Хоц є старшим архітектором рішень для AI та машинного навчання та очолює спільноту обробки природних мов (NLP) у AWS. До цієї посади він обіймав посаду керівника відділу науки про дані служби підтримки клієнтів Amazon в ЄС. Heiko допомагає нашим клієнтам досягти успіху в їхньому шляху AI/ML на AWS і співпрацює з організаціями в багатьох галузях, включаючи страхування, фінансові послуги, медіа та розваги, охорону здоров’я, комунальні послуги та виробництво. У вільний час Хайко подорожує якомога більше.
Хайко Хоц є старшим архітектором рішень для AI та машинного навчання та очолює спільноту обробки природних мов (NLP) у AWS. До цієї посади він обіймав посаду керівника відділу науки про дані служби підтримки клієнтів Amazon в ЄС. Heiko допомагає нашим клієнтам досягти успіху в їхньому шляху AI/ML на AWS і співпрацює з організаціями в багатьох галузях, включаючи страхування, фінансові послуги, медіа та розваги, охорону здоров’я, комунальні послуги та виробництво. У вільний час Хайко подорожує якомога більше.
- Coinsmart. Найкраща в Європі біржа біткойн та криптовалют.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. БЕЗКОШТОВНИЙ ДОСТУП.
- CryptoHawk. Альткойн Радар. Безкоштовне випробування.
- Джерело: https://aws.amazon.com/blogs/machine-learning/part-1-set-up-a-text-summarization-project-with-hugging-face-transformers/
- '
- "
- &
- 100
- 2020
- МЕНЮ
- РЕЗЮМЕ
- доступ
- точний
- досягнутий
- просунутий
- досягнення
- AI
- ВСІ
- вже
- Amazon
- Неоднозначність
- суми
- Інший
- Інтерфейси
- додаток
- застосування
- підхід
- навколо
- Art
- стаття
- статті
- аудиторія
- доступний
- середній
- AWS
- Базова лінія
- В основному
- початок
- буття
- бізнес
- call
- який
- спійманий
- виклик
- код
- Кодування
- загальний
- співтовариство
- Компанії
- порівняний
- повністю
- обчислення
- концепція
- містить
- зміст
- контрактів
- створення
- виготовлений на замовлення
- Контакти
- Клієнти
- дані
- наука про дані
- глибше
- розвиненою
- різний
- документація
- Ні
- домен
- розваги
- особливо
- встановити
- EU
- все
- приклад
- очікувати
- experts
- очей
- Особа
- Поля
- в кінці кінців
- фінансовий
- фінансові послуги
- Перший
- після
- Вперед
- знайдений
- функція
- далі
- гра
- породжувати
- покоління
- мета
- буде
- добре
- великий
- опікун
- керівництво
- має
- голова
- охорона здоров'я
- корисний
- допомагає
- тут
- прокат
- Як
- HTTPS
- величезний
- Особистість
- здійснювати
- реалізовані
- важливо
- включати
- У тому числі
- індивідуальний
- промисловості
- страхування
- введення
- інвестування
- IT
- робота
- липень
- ключ
- знання
- етикетки
- мова
- останній
- Веде за собою
- УЧИТЬСЯ
- вивчення
- Залишати
- легальний
- бібліотека
- Ліцензований
- зв'язку
- трохи
- машина
- навчання за допомогою машини
- РОБОТИ
- Робить
- виробництво
- позначити
- матч
- вимір
- Медіа
- mind
- ML
- модель
- Моделі
- більше
- найбільш
- Природний
- мережу
- новини
- ноутбук
- номера
- відкрити
- порядок
- організації
- Інше
- Папір
- патент
- Люди
- продуктивність
- перспектива
- фаза
- точка
- можливостей
- можливість
- це можливо
- Пости
- потенціал
- потужний
- приватний
- Production
- проект
- проектів
- пропонувати
- забезпечувати
- забезпечення
- громадськість
- мета
- якість
- питання
- діапазон
- RE
- читання
- Звіти
- вимагати
- вимагається
- дослідження
- результати
- прогін
- Зазначений
- наука
- сенс
- Серія
- обслуговування
- Послуги
- комплект
- установка
- Короткий
- простий
- So
- Рішення
- Хтось
- що в сім'ї щось
- складний
- Простір
- пробіли
- спеціалізований
- спеціалізується
- конкретно
- розкол
- старт
- почалася
- починається
- впроваджений
- Штати
- зберігання
- стрес
- Дослідження
- успішний
- Успішно
- балаканина
- Мета
- завдання
- технічний
- Технологія
- тест
- тисячі
- через
- по всьому
- час
- назва
- Навчання
- прозорий
- лікувати
- кінцевий
- розуміти
- Universal
- us
- використання
- зазвичай
- значення
- чекати
- Що
- Чи
- ВООЗ
- Вікіпедія
- в
- без
- Work
- працював
- вартість
- лист
- X
- нуль