Цей допис написано у співавторстві з Гійомом Сен-Мартеном у Sun King.
Король сонця є провідною у світі компанією автономної сонячної енергетики, яка має на меті забезпечити доступ до яскравішого життя за допомогою автономної сонячної енергії. Sun King проектує, розповсюджує, встановлює та фінансує сонячні домашні енергетичні продукти для людей, які зараз живуть без надійного доступу до енергії. Він обслуговує понад 100 мільйонів користувачів у 65 країнах світу.
Понад 26,000 XNUMX агентів по всій Африці сьогодні допомагають місцевим сім’ям отримати доступ до автономних продуктів Sun King, щоб мати більш продуктивне життя. Ці агенти отримують інформацію майже в реальному часі, щоб знайти правильні географічні райони та родини, які не мають доступу до недорогої електроенергії. Sun King керується даними для аналізу областей зростання на тисячі миль за допомогою інформаційних панелей на основі Amazon Redshift.
У цій публікації ми розповідаємо, як використовує Sun King Amazon Redshift і такі функції Redshift, як обмін даними можливості покращити продуктивність запитів у Красуня для понад 1,000 наших співробітників.
Амазонська червона зміна – це повністю кероване, масштабоване хмарне сховище даних, яке прискорює ваш час для аналізу за допомогою швидкої, легкої та безпечної масштабної аналітики. Десятки тисяч клієнтів покладаються на Amazon Redshift для аналізу ексабайтів даних і виконання складних аналітичних запитів, що робить його широко використовуваним хмарним сховищем даних. Ви можете запускати та масштабувати аналітику за лічені секунди для всіх своїх даних без необхідності керувати інфраструктурою сховища даних.
Використовуйте футляр
Sun King використовує наданий Redshift кластер для запуску процесів вилучення, перетворення та завантаження (ETL) і аналітичних процесів для отримання та перетворення даних із різних джерел. Потім він надає доступ до цих даних для бізнес-користувачів через Looker. Зараз Amazon Redshift керує різноманітними вимогами до споживання для користувачів Looker по всьому світу
Amazon Redshift використовується для очищення та агрегування даних у попередньо оброблені таблиці, виконання конвеєрів ETL Sun King і обробки Looker.постійні похідні таблиці» (PDT) заплановано з погодинною періодичністю або менше. Ці конвеєри ETL і PDT були конкуруючими робочими навантаженнями та іноді стикалися з конфліктами читання/запису.
Оскільки компанія, що керується даними, продовжує розширюватися, Sun King знадобилося рішення, яке б робило наступне:
- Дозволяє виконувати сотні запитів паралельно з бажаною пропускною здатністю.
- Оптимізуйте керування робочим навантаженням, щоб робочі навантаження ETL, бізнес-аналітики (BI4) і Looker запускалися одночасно, не впливаючи одне на одного.
- Плавно масштабуйте потужність із збільшенням бази користувачів і підтримуйте ефективність витрат.
Огляд рішення
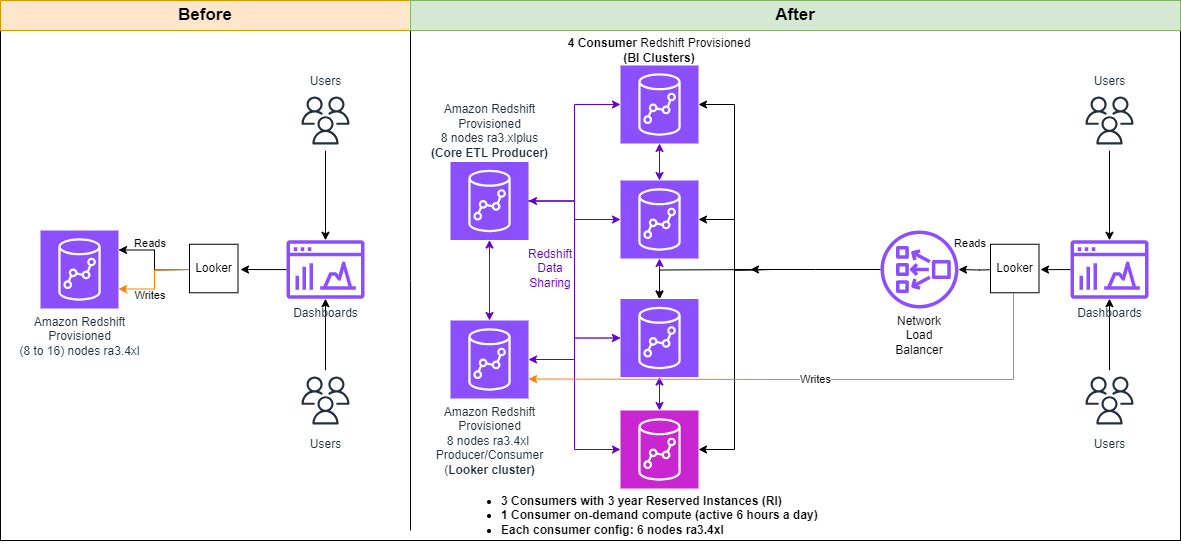
Оскільки обсяги даних, кількість запитів і користувачів продовжують зростати, Sun King вирішила перейти від однокластерної архітектури до мультикластерної архітектури із спільним використанням даних, щоб скористатися перевагами ізоляції робочого навантаження та розділити навантаження ETL і аналітику на різні кластери, продовжуючи використовувати одну копію даних.
Рішення від Sun King складається з кількох кластерів Redshift і балансування мережевого навантаження Amazon Elastic Compute Cloud (EC2), що використовує можливість обміну даними в Amazon Redshift.
Amazon Redshift Data Sharing забезпечує доступ до даних у кластерах Redshift без необхідності копіювати чи переміщувати дані. Таким чином, коли робоче навантаження переміщується з одного кластера Redshift до іншого, робоче навантаження може продовжувати отримувати доступ до даних у початковому кластері Redshift. Для отримання додаткової інформації див Безпечний обмін даними Amazon Redshift між кластерами Amazon Redshift для ізоляції робочого навантаження.
Рішення складається з таких ключових компонентів:
- Основний кластер ETL: основний кластер виробника ETL (8 вузлів ra3.xlplus) із спільним використанням даних.
- Кластер Looker: Кластер виробник/споживач (8 вузлів ra3.4xlarge) із спільним використанням даних для виконання наступного:
- Великі процеси ETL
- Процеси ETL, ініційовані Looker (PDT)
- Робочі навантаження групи даних
- BI кластери: Він складається з чотирьох великих кластерів споживачів (6 вузлів ra3.4xlarge кожен):
- Три кластери, що використовують зарезервовані екземпляри (RI), які працюють 24/7
- Один кластер на вимогу вмикався на шість годин щодня
- Балансувальник мережевого навантаження: балансир навантаження мережі розподіляє запити, що надходять від Looker, між кластерами споживачів
- Безкоштовний рівень паралельного масштабування: кожен із трьох кластерів, які використовують зарезервовані екземпляри (RI), видає одну годину кредитів за паралельне масштабування на день, які використовуються по понеділках, тоді як кластер на вимогу виробляє чотири години кредитів за паралельне масштабування, зберігаючи вартість паралельного масштабування на рівні безкоштовного.
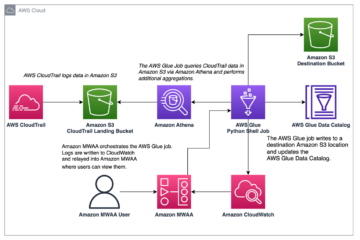
На наступній діаграмі показано рішення та кроки робочого процесу
результати
Завдяки цьому рішенню Sun King отримав такі покращення:
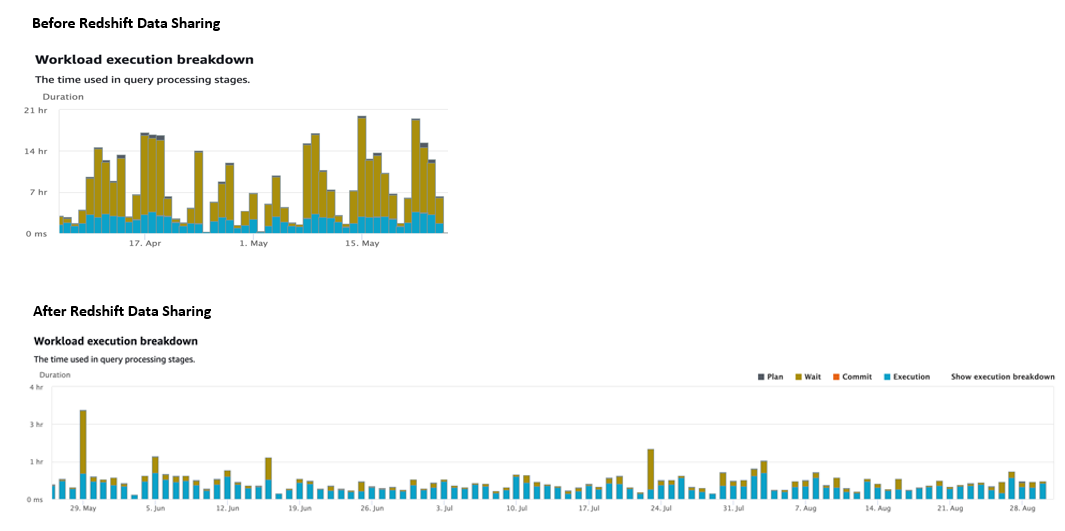
- продуктивність – Поліпшення продуктивності було значним і одразу після впровадження розподіленої архітектури виробник/споживач. Більшість запитів (95%), які раніше займали від 50 до 90 секунд, тепер займають щонайбільше 40 секунд, 75% запитів раніше займали до 40 секунд, тепер займають менше однієї секунди. Крім того, кількість виконаних запитів (прийняття Amazon Redshift) зросла на XNUMX%, завдяки більшому використанню Looker після зміни архітектури.
- Управління робочим навантаженням – Після цієї зміни архітектури запити більше не стоять у черзі довгий час. На наступній діаграмі показано порівняння запитів у черзі та виконаних в одному з кластерів до та після модернізації.
- масштабованість – Завдяки цій архітектурі Redshift із підтримкою обміну даними команда Sun King змогла повернути прийнятну продуктивність своїм користувачам, що призвело до відновлення залучення, виміряного подвоєнням кількості щомісячних запитів протягом наступних кількох місяців, таким чином збільшуючи впровадження. Amazon Redshift у всій компанії.

За оцінками, витрати Sun King зростуть лише на 35%, завдяки резервуванню більшості екземплярів, що використовуються протягом трьох років (26 ra3.4xlarge і 8 ra3.xlplus), і покладаючись на безкоштовний рівень паралельного масштабування для підвищення продуктивності в день найбільшого використання. . Це порівнюється з меншою кількістю зарезервованих кластерів (8 ra3.4xlarge) і набагато ширшим використанням масштабування одночасності (два кластери масштабування паралельності, майже завжди ввімкнено). Ця модернізація підвищила продуктивність агентів, надаючи їм швидший і майже в режимі реального часу доступ до областей, які потребують доступу до недорогого джерела живлення.
Висновок:
У цій публікації ми обговорили, як Sun King використовував можливості обміну даними Amazon Redshift для розподілу робочого навантаження та масштабування Amazon Redshift, щоб задовольнити вимоги кінцевих користувачів до продуктивності Looker і зберегти контроль над вартістю використання Amazon Redshift. Спробуйте підходи, розглянуті в цій публікації, і повідомте нам свої відгуки в коментарях.
Про авторів
 Гійом Сен-Мартен очолює групу даних і аналітики в Sun King. Маючи 10-річний досвід роботи в секторах обробки даних і розробки, він керує командою з понад 30 аналітиків, інженерів з обробки даних і вчених з обробки даних для підтримки довгострокового моделювання та аналізу тенденцій Sun King.
Гійом Сен-Мартен очолює групу даних і аналітики в Sun King. Маючи 10-річний досвід роботи в секторах обробки даних і розробки, він керує командою з понад 30 аналітиків, інженерів з обробки даних і вчених з обробки даних для підтримки довгострокового моделювання та аналізу тенденцій Sun King.
 Аабер Джа є старшим спеціалістом з аналітики в AWS у Чикаго, штат Іллінойс. Він зосереджується на стимулюванні та підтримці бізнес-цінності AWS Data Analytics для клієнтів.
Аабер Джа є старшим спеціалістом з аналітики в AWS у Чикаго, штат Іллінойс. Він зосереджується на стимулюванні та підтримці бізнес-цінності AWS Data Analytics для клієнтів.
 Рохіт Вашішта є старшим архітектором рішень спеціаліста з аналітики в AWS у Далласі, штат Техас. Він має понад 17 років досвіду проектування, створення, керівництва та підтримки платформ великих даних. Rohit допомагає клієнтам модернізувати їх аналітичне робоче навантаження, використовуючи широкий спектр послуг AWS, і гарантує, що клієнти отримають найкращу ціну/продуктивність із максимальною безпекою та керуванням даними.
Рохіт Вашішта є старшим архітектором рішень спеціаліста з аналітики в AWS у Далласі, штат Техас. Він має понад 17 років досвіду проектування, створення, керівництва та підтримки платформ великих даних. Rohit допомагає клієнтам модернізувати їх аналітичне робоче навантаження, використовуючи широкий спектр послуг AWS, і гарантує, що клієнти отримають найкращу ціну/продуктивність із максимальною безпекою та керуванням даними.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/sun-king-uses-amazon-redshift-data-sharing-to-accelerate-data-analytics-and-improve-user-experience/
- : має
- :є
- : ні
- $UP
- 000
- 1
- 10
- 100
- 17
- 26
- 30
- 35%
- 40
- 65
- 8
- 95%
- a
- Здатний
- прискорювати
- прискорюється
- прийнятний
- доступ
- через
- Додатково
- адреса
- Прийняття
- Перевага
- Африка
- після
- агенти
- сукупність
- ВСІ
- завжди
- Amazon
- Amazon Web Services
- an
- аналіз
- аналітики
- Аналітичний
- Аналітичний
- аналітика
- аналізувати
- Аналізуючи
- та
- Інший
- більше
- підходи
- архітектурний
- архітектура
- ЕСТЬ
- області
- At
- AWS
- назад
- свінг
- база
- заснований
- перед тим
- КРАЩЕ
- між
- Великий
- Великий даних
- підвищення
- широта
- яскравіше
- приносити
- Створюємо
- бізнес
- бізнес-аналітика
- by
- CAN
- можливості
- можливості
- потужність
- зміна
- Графік
- Чикаго
- очистити
- хмара
- кластер
- коментарі
- компанія
- порівняний
- конкурують
- повний
- комплекс
- Компоненти
- У складі
- обчислення
- Конфлікти
- складається
- споживач
- споживання
- продовжувати
- триває
- контроль
- Core
- Коштувати
- витрати
- країни
- кредити
- В даний час
- Клієнти
- Даллас
- інформаційні панелі
- дані
- доступ до даних
- Analytics даних
- обмін даними
- сховище даних
- керовані даними
- день
- вирішене
- Отриманий
- конструкцій
- бажаний
- розробка
- різний
- обговорювалися
- поширювати
- розподілений
- do
- робить
- Не знаю
- подвоєння
- керований
- водіння
- кожен
- легко
- ефективність
- включіть
- включений
- дозволяє
- енергія
- зачеплення
- Інженери
- гарантує
- оцінка
- Ефір (ETH)
- Кожен
- виконувати
- розширюється
- досвід
- витяг
- сімей
- ШВИДКО
- швидше
- риси
- зворотний зв'язок
- кілька
- фінанси
- знайти
- п'ять
- фокусується
- після
- для
- чотири
- Безкоштовна
- частота
- від
- повністю
- географічні
- отримати
- управління
- великий
- Рости
- Зростання
- Мати
- має
- he
- допомога
- допомагає
- найвищий
- Головна
- годину
- ГОДИННИК
- Як
- HTTPS
- Сотні
- Іллінойс
- ілюструє
- Негайний
- впливає
- реалізації
- удосконалювати
- поліпшення
- поліпшення
- in
- Augmenter
- збільшений
- зростаючий
- інформація
- повідомив
- Інфраструктура
- початковий
- розпочатий
- розуміння
- випадки
- Інтелект
- в
- ізоляція
- IT
- ЙОГО
- JPG
- тримати
- зберігання
- ключ
- King
- Знати
- великий
- більше
- провідний
- Веде за собою
- менше
- дозволяти
- як
- Місце проживання
- життя
- загрузка
- місцевий
- Довго
- багато часу
- низький
- підтримувати
- збереження
- Робить
- управляти
- вдалося
- управління
- управляє
- виміряний
- мільйона
- Місія
- моделювання
- модернізація
- модернізувати
- місяць
- щомісячно
- більше
- найбільш
- рухатися
- переїхав
- багато
- множинний
- Близько
- майже
- Необхідність
- необхідний
- мережу
- вузли
- зараз
- номер
- of
- on
- On-Demand
- ONE
- тільки
- or
- походження
- Інше
- наші
- над
- Паралельні
- Люди
- для
- продуктивність
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- пошта
- влада
- Харчування
- процес
- процеси
- виробник
- випускає
- продуктивний
- продуктивність
- Продукти
- забезпечує
- забезпечення
- запити
- реальний
- реального часу
- послатися
- надійний
- покладатися
- покладаючись
- оновлено
- Вимога
- захищені
- право
- прогін
- біг
- бачив
- масштабовані
- шкала
- Масштабування
- плановий
- Вчені
- другий
- seconds
- Сектори
- безпечний
- безпечно
- безпеку
- старший
- окремий
- служить
- Послуги
- Поділитись
- поділ
- Шоу
- одночасно
- один
- SIX
- менше
- сонячний
- сонячна енергія
- рішення
- Рішення
- іноді
- Source
- Джерела
- спеціаліст
- витрачати
- Персонал
- Як і раніше
- Sun
- підтримка
- Приймати
- команда
- тензор
- термін
- Техас
- ніж
- Що
- Команда
- світ
- їх
- Їх
- потім
- отже
- Ці
- це
- тисячі
- три
- через
- пропускна здатність
- Таким чином
- ярус
- час
- до
- сьогодні
- Перетворення
- Trend
- аналіз тенденцій
- намагатися
- Опинився
- два
- при
- us
- використовуваний
- користувач
- User Experience
- користувачі
- використовує
- використання
- утилізація
- максимально
- значення
- різний
- Обсяги
- vs
- Склад
- було
- we
- Web
- веб-сервіси
- були
- коли
- який
- в той час як
- ВООЗ
- широко
- з
- без
- робочий
- світ
- світі
- років
- ви
- вашу
- зефірнет