Проміжна еволюція. V1 – V5.1
У 2015, A наукова робота Стенфордського університету та Каліфорнійського університету в Берклі представив дифузійні моделі, що походять із статистичної фізики, у сферу машинного навчання. Відповідно до резюме статті, «основна ідея полягає в тому, щоб систематично і повільно руйнувати структуру в розподілі даних через ітеративний процес прямої дифузії. Потім ми вчимося процесу зворотної дифузії, який відновлює структуру даних, створюючи дуже гнучку та піддатливу генеративну модель даних». Це основна ідея, яка використовується в останніх моделях дифузії, як-от DALL-E 2 або Stale Diffusion. Однак якість створених зображень була досить низькою ще в 2015 році, оскільки ще було багато можливостей для вдосконалення.
Через п’ять років, у 2020 році, дослідницька група з Каліфорнійського університету в Берклі введені основоположна дослідницька стаття з кількома новаторськими змінами, які призвели до величезного стрибка в якості створених зображень. Ми почнемо наш огляд із цієї статті, а потім подивимося, які інші впливові дослідницькі статті зробили революцію у сфері створення зображень. Якщо ви хочете пропустити, ось мовні моделі, які ми представили:
- Імовірнісні моделі знешумлення дифузії від UC Berkeley
- Дифузійні моделі перемагають GAN у синтезі зображень за допомогою OpenAI
- Стабільна дифузія групою комп'ютерного зору та навчання (LMU)
- DALL-E 2 від OpenAI
- Зображення Google
- ControlNet від Stanford
Якщо цей поглиблений навчальний контент стане для вас корисним, ви можете підпишіться на наш список розсилки досліджень ШІ щоб отримати попередження, коли ми випускаємо новий матеріал.
Найвпливовіші дослідницькі статті про генерацію зображень за допомогою дифузійних моделей
1. Імовірнісні моделі знешумлення дифузії, Каліфорнійський університет у Берклі
Підсумки
Дослідники Каліфорнійського університету в Берклі представили ймовірнісні моделі знешумлення дифузії (DDPM), новий клас генеративних моделей, які навчаються перетворювати випадковий шум у реалістичні зображення. DDPM використовує структуру відповідності балів усунення шуму, яка визначає розподіл по зображеннях за допомогою процесу прямої дифузії, який перетворює зображення на шум. Навчаючи функції усунення шуму, щоб мінімізувати втрату відповідності оцінки усунення шуму, DDPM можуть генерувати високоякісні зразки з випадкового шуму.
Яка мета?
- Продемонструвати, що ймовірнісні моделі дифузії здатні генерувати високоякісні зображення.
Як підійти до проблеми?
- Автори використовують дифузійну ймовірнісну модель, яка є параметризованим ланцюгом Маркова, навченим за допомогою варіаційного висновку для створення вибірок, що відповідають даним через кінцевий час.
- Переходи цього ланцюга навчені інвертувати процес дифузії, який поступово додає шум до даних, рухаючись у протилежному напрямку вибірки, доки сигнал не буде знищено.
- Якщо процес дифузії включає невеликі кількості гауссового шуму, переходи ланцюжка вибірки можуть бути встановлені на умовні гауссові, що робить параметризацію нейронної мережі особливо простою.
- Дослідження показує, що найкращі результати досягаються під час навчання на зваженій варіаційній межі, розробленій відповідно до нового зв’язку між імовірнісними моделями дифузії та збігом результатів зменшення шуму з динамікою Ланжевена.

Які результати?
- Автори продемонстрували, що дифузійні моделі можуть бути придатним інструментом для створення зразків високоякісних зображень.
- Крім того, модель, представлена в дослідницькій статті, може інтерполювати зображення в прихованому просторі, таким чином усуваючи будь-які артефакти, які можуть бути введені інтерполяцією зображень у просторі пікселів. Реконструйовані зображення мають високу якість.
- Автори також показують, що латентні змінні кодують значущі атрибути високого рівня про зразки, такі як поза та окуляри.
Де дізнатися більше про це дослідження?
Де ви можете отримати код реалізації?
- Офіційна реалізація TensorFlow імовірнісних моделей усунення шуму дифузії доступна на GitHub.
2. Дифузійні моделі випереджають GAN у синтезі зображень за допомогою OpenAI
Підсумки
Завдяки цьому дослідженню команда OpenAI кинула виклик домінуванню GAN у створенні зображень, продемонструвавши, що дифузійні моделі можуть створювати чудову якість зображення. Використовуючи структуру зіставлення результатів усунення шумів і процес прямої дифузії, DDPM навчаються створювати високоякісні зразки зображення з випадкового шуму. Дослідження демонструє потенціал цього нового класу моделей у різних програмах синтезу зображень, підкреслюючи їх здатність захоплювати більше різноманітності та забезпечувати більш стабільне навчання та менше проблем згортання режиму порівняно з GAN.
Яка мета?
- Щоб продемонструвати, що дифузійні моделі можуть перевершувати генеративні змагальні мережі (GAN) у безумовному синтезі зображень, оскільки, хоча GAN демонструють найсучаснішу продуктивність з точки зору якості зображення, ці моделі:
- вловлювати менше різноманітності;
- часто важко навчити, оскільки вони можуть легко згорнутися без ретельно підібраних гіперпараметрів і регуляризаторів.
Як підійти до проблеми?
- Дослідники OpenAI запропонували застосувати переваги GAN до дифузійних моделей за допомогою:
- вдосконалення архітектури моделі;
- розробка схеми обміну різноманітністю на вірність.
- Зокрема, вони змогли значно підвищити оцінку FID, запровадивши, серед іншого, наступні архітектурні зміни:
- Збільшення глибини в порівнянні з шириною, утримання розміру моделі відносно постійним.
- Збільшення кількості уваги голів.
- Використання уваги при роздільній здатності 32×32, 16×16 і 8×8, а не лише при 16×16.
- Використання залишкового блоку BigGAN для підвищення та зменшення дискретизації активацій.
- Крім того, вони розробили техніку використання градієнтів класифікатора для керування моделлю дифузії під час вибірки.
- Було виявлено, що коригування одного конкретного гіперпараметра – масштабу градієнтів класифікатора – можна налаштувати на компроміс між різноманітністю та точністю.

Які результати?
- Результати показали це
- Дифузійні моделі можуть отримати кращу якість зразків, ніж найсучасніші GAN.
- У завданнях з умовою класу можна налаштувати шкалу градієнтів класифікатора, щоб отримати компроміс між різноманітністю та точністю.
- Інтеграція вказівок із підвищенням дискретизації дозволяє додатково покращити якість зразка для умовного синтезу зображення з високою роздільною здатністю.
Де дізнатися більше про це дослідження?
Де ви можете отримати код реалізації?
- Офіційна реалізація цього документа доступна на GitHub.
3. Стабільна дифузія по Група комп’ютерного зору та навчання (LMU)
Підсумки
Розробники моделей стабільної дифузії вирішили вирішити проблему високої обчислювальної вартості та дорогого висновку в моделях дифузії (DM), які вже відомі своїми найсучаснішими результатами синтезу даних зображень. Щоб вирішити цю проблему, дослідники застосували DM у латентному просторі потужних попередньо навчених автокодерів, що дозволило їм досягти майже оптимального балансу між зменшенням складності та збереженням деталей. Вони також представили рівні перехресної уваги, щоб зробити DM більш гнучкими та здатними обробляти загальні вхідні дані, такі як текст або обмежувальні рамки. У результаті їх моделі прихованої дифузії (LDM) досягли нових найсучасніших балів для малювання зображень і синтезу умовних зображень класу, а також конкурентоспроможності в таких завданнях, як синтез тексту в зображення, генерація безумовного зображення , і суперроздільність. Крім того, LDM значно зменшили вимоги до обчислень порівняно з піксельними DM.

Яка мета?
- Розробити метод, який дозволяє навчати дифузійні моделі (DM) з обмеженими обчислювальними ресурсами, зберігаючи їх якість і гнучкість.
Як підійти до проблеми?
- Дослідницька група запропонувала розділити навчання на дві окремі фази:
- Навчання автокодувальника для надання маловимірного та перцептивно еквівалентного простору представлення.
- Навчання дифузійних моделей у вивченому латентному просторі, що призводить до моделей латентної дифузії (LDM).
- У результаті універсальний етап автокодування вимагає лише одноразового навчання, що дозволяє ефективно досліджувати різноманітні завдання зображення в зображення та тексту в зображення.
- Для останнього дослідник розробив архітектуру, що підключає трансформатори до магістралі UNet DM для довільних механізмів кондиціонування на основі маркерів.
Які результати?
- Модель прихованої дифузії забезпечує конкурентоспроможну продуктивність для багатьох завдань і наборів даних зі значно меншими обчислювальними витратами.
- Для щільно обумовлених завдань, таких як надвисока роздільна здатність, замальовування та семантичний синтез, LDM може відтворювати великі узгоджені зображення 1024*1024 пікселів.
- Дослідники також запровадили механізм кондиціонування загального призначення, заснований на перехресному зверненні уваги, який дозволяє мультимодальне навчання моделей умовного класу, тексту в зображення та макета в зображення.
- Нарешті вони випущений попередньо навчені моделі латентної дифузії та автокодування для широкого загалу, щоб уможливити їх повторне використання для різних завдань, навіть за межами навчання моделей дифузії.
Де дізнатися більше про це дослідження?
Де ви можете отримати код реалізації?
- Офіційне впровадження цього дослідження доступно на GitHub.
4. DALL-E 2 від OpenAI
Підсумки
DALL-E 2 від OpenAI базується на оригінальних можливостях DALL-E для синтезу зображень із керуванням текстом, усуваючи певні обмеження та покращуючи компонування. Дослідники навчили DALL-E 2 на наборі даних із 400 мільйонів пар зображення-текст, щоб розробити генеративну модель, здатну синтезувати складні та різноманітні зображення на основі складних текстових підказок.
Яка мета?
- Щоб створити модель, яка може:
- синтезувати реалістичні образи з текстового опису, вловлюючи як семантику, так і стилі;
- увімкнути мовні маніпуляції зображеннями.
Як підійти до проблеми?
- DALL·E 2 — це модель із двох частин, яка складається з попередньої моделі та моделі декодера:
- По-перше, попередній модель бере текстовий опис і створює з нього вбудоване зображення. Це комп’ютерна аналогія ментальних образів, які виникають у людській свідомості, коли ми уявляємо певний об’єкт (наприклад, невеликий будиночок біля озера).
- Далі, в декодер модель використовує це вбудовування зображення та генерує зображення. Подібно до людей, які можуть малювати різні малюнки з різними деталями та в різних стилях з тих самих уявних образів, модель декодера може генерувати кілька зображень з одного вбудованого зображення, змінюючи деталі, не вказані в текстовому описі.
Які результати?
- Численні експерименти демонструють, що з DALL-E 2 ви можете:
- створювати оригінальні та реалістичні зображення з текстових описів, де можна вказати не лише атрибути зображення, а й його стиль (наприклад, «у фотореалістичному стилі», «як малюнок олівцем»);
- внести реалістичні правки до наявних зображень, дотримуючись текстових інструкцій (зверніть увагу, що тіні, відблиски та текстури також враховуються);
- візьміть зображення та створіть різні варіанти, натхненні цим оригінальним зображенням.
- Команда OpenAI також запровадила кілька заходів безпеки, щоб усунути поширені проблеми ризики та обмеження моделей розповсюдження, як, наприклад, обмеження здатності DALL·E 2 генерувати зображення насильства, ненависті або дорослих.

Де дізнатися більше про це дослідження?
Де взяти код реалізації?
- На даний момент код реалізації для DALL-E 2 не оприлюднено. Однак ви можете звернутися до дослідницької статті, щоб отримати детальну інформацію про використану методологію та техніки.
5. Imagen від Google
Підсумки
Imagen — це модель розповсюдження тексту в зображення введені дослідницька команда Google. Модель демонструє високу ступінь фотореалізму і глибоке розуміння мови. Спираючись на переваги великих трансформаторних мовних моделей (наприклад, T5) і дифузійних моделей, Imagen показує, що збільшення розміру мовної моделі покращує точність вибірки та вирівнювання зображення та тексту більше, ніж збільшення розміру моделі дифузії зображення. Imagen отримує нову найсучаснішу оцінку FID 7.27 на наборі даних COCO без навчання, а оцінювачі вважають, що його зразки відповідають даним COCO у вирівнюванні зображення та тексту. Дослідники також представили DrawBench, еталонний тест для моделей перетворення тексту в зображення, який показує, що оцінювачі віддають перевагу Imagen перед іншими моделями, зокрема VQ-GAN+CLIP, Latent Diffusion Models, GLIDE і DALL-E 2, з точки зору вибірки. якість і вирівнювання зображення та тексту.
Яка мета?
- Подібно до DALL-E 2, модель Imagen створює реалістичні зображення з описів тестів. Ця модель фокусується на безпрецедентній фотореалістичності вихідних зображень.
Як підійти до проблеми?
- Щоб створити фотореалістичне зображення з вхідного тексту, алгоритм виконує кілька кроків:
- По-перше, велика мовна модель T5 використовується для кодування вхідного тексту у вбудовування. Команда Google стверджує, що розмір мовної моделі має значний вплив як на точність вибірки, так і на вирівнювання зображення та тексту.
- Потім модель умовної дифузії відображає вбудований текст у зображення 64×64.
- Нарешті, моделі дифузії з надвисокою роздільною здатністю, обумовлені текстом, використовуються для підвищення дискретизації зображення (64×64→256×256 та 256×256→1024×1024) і отримання фотореалістичного вихідного зображення.
Які результати?
- Imagen створює 1024 × 1024 зразки з безпрецедентним фотореалізмом і вирівнюванням зображення та тексту.
- Автори стверджують, що оцінювачі віддають перевагу Imagen перед іншими моделями (включно з DALL-E 2) у паралельних порівняннях як щодо якості зображення, так і щодо вирівнювання з текстом.
- Подібно до команди OpenAI, дослідницька група Google вирішила не випускати код чи публічну демонстрацію, оскільки мала дуже схожі проблеми (наприклад, створення шкідливого вмісту, насадження соціальних стереотипів).

Де дізнатися більше про це дослідження?
Де ви можете отримати код реалізації?
- Неофіційна реалізація Imagen на PyTorch доступна на GitHub.
6. ControlNet від Stanford
Підсумки
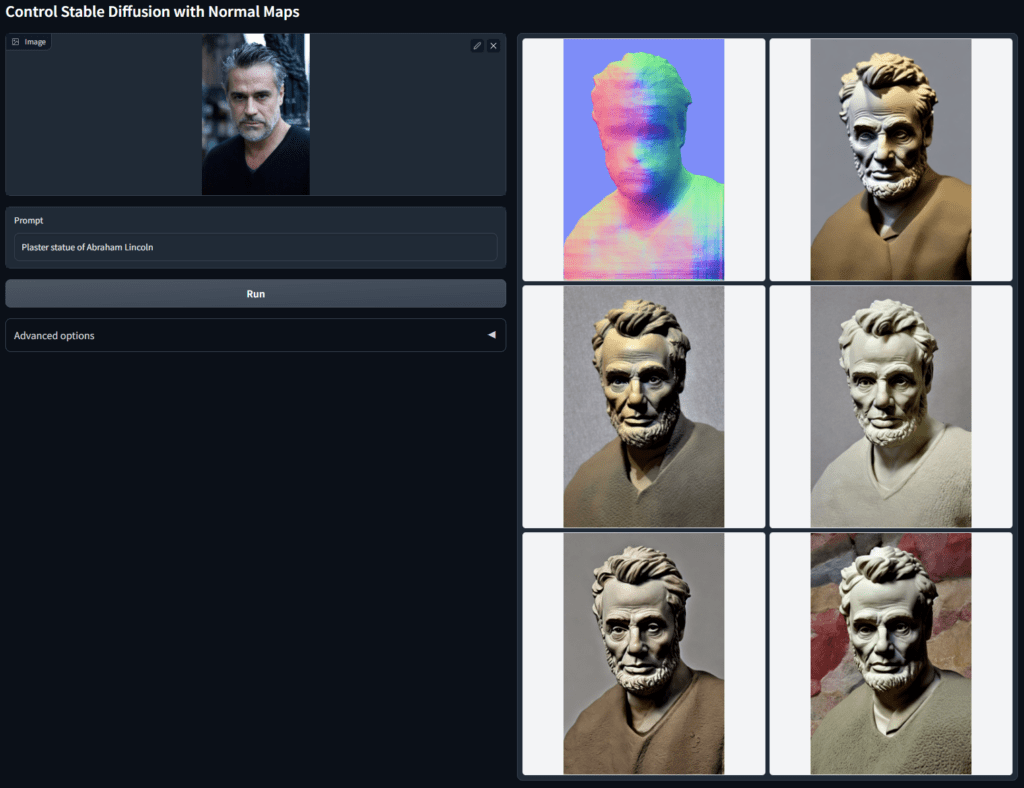
ControlNet — це структура нейронної мережі, розроблена дослідницькою групою Стенфордського університету для керування попередньо підготовленими моделями великої дифузії та підтримки додаткових умов введення. ControlNet наскрізно вивчає умови, пов’язані з конкретними завданнями, і демонструє надійне навчання навіть із невеликими наборами навчальних даних. Процес навчання такий же швидкий, як і тонке налаштування дифузійної моделі, і його можна виконувати на персональних пристроях або масштабувати для обробки великих обсягів даних за допомогою потужних обчислювальних кластерів. Доповнюючи моделі великої дифузії, такі як Stable Diffusion, за допомогою ControlNets, дослідники дають змогу вводити умовні вхідні дані, такі як карти країв, карти сегментації та ключові точки, тим самим збагачуючи методи керування моделями великої дифузії та полегшуючи пов’язані програми.
Яка мета?
- Побудувати структуру, яка дозволить більше контролювати попередньо підготовлені моделі великої дифузії, підтримуючи додаткові умови введення.

Як підійти до проблеми?
- Дослідники представили ControlNet, наскрізну архітектуру нейронної мережі, яка керує моделями дифузії великих зображень, щоб вивчати умови введення для конкретних завдань.
- По-перше, ControlNet клонує вагові коефіцієнти великої дифузійної моделі в «навчальну копію» та «заблоковану копію»:
- Заблокована копія зберігає мережеві можливості, отримані з мільярдів зображень.
- Копія, яку можна навчити, навчається на наборах даних для конкретного завдання, щоб навчитися умовному управлінню.
- Далі блоки нейронної мережі, які можна навчити та заблокувати, з’єднуються з унікальним типом шару згортки, який називається «нульовою згорткою»:
- Вага згортки поступово зростає від нуля до оптимізованих параметрів у навчений спосіб.
- Як результат:
- Збережені готові до виробництва ваги дозволяють надійно тренуватися на наборах даних різного масштабу.
- Нульова згортка не додає нового шуму до глибоких функцій, роблячи процес навчання таким же швидким, як і тонке налаштування дифузійної моделі.
- По-перше, ControlNet клонує вагові коефіцієнти великої дифузійної моделі в «навчальну копію» та «заблоковану копію»:
Які результати?
- ControlNet кардинально змінює правила створення зображень штучного інтелекту, оскільки забезпечує набагато більше контролю над вихідними зображеннями за допомогою кількох можливих умов введення.
- Великі дифузійні моделі можна доповнити за допомогою ControlNet, щоб увімкнути умовні вхідні дані, такі як карти країв, карти HED, намальовані від руки ескізи, пози людини, карти сегментації, карти глибини, ключові точки тощо.
Де дізнатися більше про це дослідження?
Де ви можете отримати код реалізації?
- Офіційна реалізація цього документа доступна на GitHub.
Реальні застосування дифузійних моделей для генерації зображень
Дифузійні моделі для створення зображень досягли значних успіхів за останні роки, відкривши широкий спектр реальних застосувань.
- Моделі розповсюдження тексту в зображення можуть змінити графічний дизайн:
- Створити зображення за допомогою ШІ набагато дешевше, ніж найняти графічного дизайнера.
- Однак графічні дизайнери можуть перетворитися на важливий інтерфейс між своїми клієнтами та цією технологією. Вони можуть вивчати нюанси моделей штучного інтелекту, а також вирішувати, які творчі фільтри застосовувати для створення зображень (наприклад, у стилі Вінсента Ван Гога чи Енді Ворхола).
- Ці моделі також можуть підірвати арт-індустрію:
- Виконавці можуть відчувати загрозу через такі системи, як DALL-E 2, але насправді ці моделі мають багато обмежень, які не дозволять їм повністю замінити виконавців. Найважливіше те, що сучасні моделі штучного інтелекту не розуміють реальності та зв’язків між різними об’єктами.
- Отже, швидше за все, ця технологія допоможе певним митцям, які направлятимуть моделі штучного інтелекту до цікавих і творчих результатів, стаючи інтерфейсом між технологіями та клієнтами.
- Подібним чином генерація зображень на основі дифузійних моделей, ймовірно, революціонізує ще кілька галузей, включаючи фотографію, маркетинг, рекламу та інші.
Однак на поточному етапі розвитку ця технологія має ряд значних ризиків і обмежень.
Ризики та обмеження
Почнемо з того, що інструменти для створення зображень AI знаходяться в a сіра зона коли мова заходить про юридичні аспекти навчання цих моделей штучного інтелекту на захищених авторським правом зображеннях, створення нових зображень у стилі інших художників і визначення права власності на вихідні зображення. Потрібні чіткі правила для захисту оригінальних художників, чиї роботи використовувалися для навчання моделей генерації штучного інтелекту, а також для визнання внеску творців штучного інтелекту, які володіють своїми навичками підказки та створюють чудові твори мистецтва за допомогою штучного інтелекту.
Крім того, важливо пам’ятати, що існують численні добре відомі зловмисні випадки використання моделей генерації зображень:
- Генератори зображень штучного інтелекту можна використовувати для створення шкідливого контенту, зокрема зображень, пов’язаних із насильством, переслідуваннями, незаконною діяльністю та ненавистю.
- Їх також можна використовувати для створення фальшивих зображень і відео відомих діячів.
- Генеративні моделі також відображають упередження в наборах даних, на яких вони навчаються. Якщо зразки з генеративних моделей, навчених на цих наборах даних, поширюватимуться в Інтернеті, ці упередження лише посиляться.
Генератори зображень штучного інтелекту включають різні фільтри, щоб запобігти створенню шкідливого вмісту, але ці фільтри можна обійти. Це особливо легко зробити, коли код є відкритим, як у випадку Stable Diffusion.
Крім численних ризиків, генератори ШІ тексту в зображення мають свої недоліки:
- Перш за все, це відсутність контролю, коли ви не можете відтворити зображення, яке ви маєте на увазі, незалежно від того, наскільки детальною є ваша підказка.
- Генератори зображень також мають проблеми зі створенням складних композицій, динамічних поз і великих натовпів.
- На даний момент вони не можуть точно зобразити літери, слова та символи на зображеннях.
- Нарешті, інструменти генерації зображень штучного інтелекту не дозволять вам зайти занадто далеко в стилізації ваших зображень, якщо це вимагає значних відхилень від належної структури та анатомії.
Висновок
Незважаючи на значні обмеження сучасних генераторів зображень ШІ, є підстави для оптимізму щодо майбутнього цієї технології. За останній рік ця сфера стала свідком величезного прогресу, і розумно очікувати, що деякі недоліки технології будуть усунені найближчим часом.
ControlNet є прикладом нещодавньої розробки, яка дає розробникам ШІ більше контролю над вихідними зображеннями, а команда Stable Diffusion працює над створення слів у зображеннях. Midjourney впроваджує нову систему модерації штучного інтелекту, щоб блокувати шкідливий вміст, а також уникати помилкової заборони невинних підказок.
Вищезазначені випадки слугують лише уявленням про зусилля, які докладаються в цій галузі для підвищення можливостей і етичних міркувань зображень, створених ШІ. Оскільки штучний інтелект продовжує розвиватися, ми можемо передбачити все більш складні моделі, які зможуть краще розуміти реальний світ і створювати більш точні та різноманітні зображення.
Вам подобається ця стаття? Підпишіться на отримання нових оновлень щодо досліджень ШІ.
Ми повідомимо вас, коли випустимо більше таких підсумкових статей, як ця.
споріднений
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoAiStream. Web3 Data Intelligence. Розширення знань. Доступ тут.
- Карбування майбутнього з Адріенн Ешлі. Доступ тут.
- Купуйте та продавайте акції компаній, які вийшли на IPO, за допомогою PREIPO®. Доступ тут.
- джерело: https://www.topbots.com/research-papers-diffusion-models/
- : має
- :є
- : ні
- :де
- $UP
- 2015
- 2020
- 27
- 7
- a
- здібності
- здатність
- Здатний
- МЕНЮ
- За
- рахунки
- точний
- точно
- Achieve
- досягнутий
- Досягає
- активації
- діяльність
- додавати
- доповнення
- Додатковий
- адреса
- адресація
- Додає
- Відрегульований
- Для дорослих
- досягнення
- змагальність
- реклама
- після
- AI
- ai дослідження
- алгоритм
- ВСІ
- дозволяти
- дозволяє
- вже
- Також
- серед
- суми
- an
- анатомія
- та
- передбачити
- будь-який
- застосування
- прикладної
- архітектурний
- архітектура
- ЕСТЬ
- навколо
- масив
- Art
- стаття
- статті
- Художники
- витвір мистецтва
- AS
- аспекти
- допомогу
- At
- увагу
- Атрибути
- збільшено
- authors
- доступний
- уникнути
- назад
- Хребет
- Balance
- заснований
- основний
- BE
- оскільки
- становлення
- було
- починати
- буття
- еталонний тест
- Переваги
- Берклі
- КРАЩЕ
- Краще
- між
- За
- упередження
- мільярди
- Блокувати
- блоки
- підвищення
- обидва
- пов'язаний
- коробки
- Приведення
- будувати
- Створюємо
- Будує
- але
- by
- званий
- CAN
- не може
- можливості
- здатний
- захоплення
- захопивши
- обережно
- випадок
- КПП
- певний
- ланцюг
- виклик
- проблеми
- Зміни
- заміна
- більш дешевий
- церква
- стверджувати
- претензій
- клас
- ясно
- клієнтів
- кокос
- код
- колапс
- приходить
- майбутній
- загальний
- порівняний
- конкурентоспроможний
- комплекс
- складність
- обчислення
- комп'ютер
- Комп'ютерне бачення
- Турбота
- Умови
- підключений
- З'єднувальний
- зв'язку
- значний
- міркування
- послідовний
- постійна
- зміст
- триває
- внесок
- контроль
- управління
- конвертувати
- Коштувати
- витрати
- може
- створювати
- створює
- створення
- Креатив
- Творці
- вирішальне значення
- Поточний
- Поточний стан
- Клієнти
- dall's
- дані
- набори даних
- вирішувати
- вирішене
- глибокий
- Визначає
- визначаючи
- Ступінь
- Демонстрація
- демонструвати
- продемонстрований
- демонструє
- демонстрація
- глибина
- description
- дизайн
- призначений
- Дизайнерка
- Дизайнери
- знищити
- зруйнований
- деталь
- докладно
- деталі
- розвивати
- розвиненою
- розробників
- розробка
- відхилення
- прилади
- різний
- важкий
- радіомовлення
- напрям
- відкритий
- Зривати
- чіткий
- розподіл
- Різне
- різноманітність
- do
- робить
- Панування
- малювати
- під час
- динамічний
- динаміка
- e
- легко
- легко
- край
- освітній
- ефективний
- зусилля
- усуваючи
- вбудовування
- працевлаштований
- включіть
- дозволяє
- дозволяє
- кінець в кінець
- виконання
- підвищувати
- збагачення
- Еквівалент
- особливо
- істотний
- і т.д.
- етичний
- Навіть
- еволюція
- еволюціонувати
- приклад
- існуючий
- очікувати
- дорогий
- Експерименти
- дослідження
- окуляри
- сприяння
- факт
- підроблений
- далеко
- ШВИДКО
- ознаками
- риси
- почувати
- кілька
- менше
- вірність
- поле
- цифри
- Фільтри
- знайти
- Гнучкість
- гнучкий
- Сфокусувати
- після
- для
- Вперед
- Рамки
- від
- повністю
- Функції
- далі
- Крім того
- майбутнє
- змінювач гри
- ГАН
- Загальне
- громадськість
- Головна мета
- породжувати
- генерується
- генерує
- породжує
- покоління
- генеративний
- генеративні змагальні мережі
- генеративна модель
- генератори
- отримати
- GitHub
- дає
- Проблиск
- Go
- мета
- йде
- градієнти
- поступово
- новаторський
- Group
- Рости
- керівництво
- керівництво
- обробляти
- Обробка
- переслідування
- шкідливий
- Мати
- має
- голови
- тут
- Високий
- на вищому рівні
- гучний
- високоякісний
- виділивши
- дуже
- Наймання
- проведення
- будинок
- Як
- Однак
- HTTPS
- величезний
- людина
- i
- ідея
- if
- незаконний
- зображення
- генерація зображень
- зображень
- картина
- Impact
- реалізація
- реалізовані
- реалізації
- важливо
- поліпшення
- поліпшується
- поліпшення
- in
- поглиблений
- У тому числі
- включати
- зростаючий
- все більше і більше
- промисловості
- промисловість
- Впливовий
- вхід
- витрати
- натхненний
- інструкції
- цікавий
- інтерфейс
- інтернет
- в
- введені
- введення
- включає в себе
- питання
- питання
- IT
- ЙОГО
- JPG
- стрибати
- Знати
- відомий
- відсутність
- озеро
- мова
- великий
- пізніше
- останній
- шар
- шарів
- УЧИТЬСЯ
- вчений
- вивчення
- Led
- легальний
- менше
- Важіль
- використання
- як
- Ймовірно
- недоліки
- обмеженою
- замкнений
- від
- машина
- навчання за допомогою машини
- made
- зробити
- Робить
- манера
- багато
- карти
- Маркетинг
- майстер
- узгодження
- матеріал
- Матерія
- макс-ширина
- Може..
- значущим
- заходи
- механізм
- механізми
- психічний
- меров
- метод
- Методологія
- методика
- Серед Подорожі
- може бути
- мільйона
- mind
- умів
- мінімізувати
- пом'якшення
- режим
- модель
- Моделі
- помірність
- сучасний
- більше
- найбільш
- переміщення
- багато
- множинний
- Близько
- мережу
- мереж
- Нейронний
- нейронної мережі
- Нові
- немає
- шум
- увагу
- Зверніть увагу..
- роман
- зараз
- номер
- численний
- об'єкт
- об'єкти
- отримувати
- отриманий
- іноді
- of
- від
- офіційний
- часто
- on
- ONE
- тільки
- OpenAI
- відкриття
- протилежний
- Оптимізм
- оптимізований
- or
- оригінал
- спочатку
- Інше
- інші
- наші
- Вищі результати
- вихід
- над
- огляд
- власність
- пар
- Папір
- документи
- параметри
- особливо
- Минуле
- Люди
- продуктивність
- персонал
- малюнок
- Фотореалістичний
- Фізика
- фотографії
- піксель
- plato
- Інформація про дані Платона
- PlatoData
- бідні
- позах
- це можливо
- потенціал
- Харчування
- потужний
- надавати перевагу
- збереження
- запобігати
- попередній
- Проблема
- процес
- виробляти
- поступово
- правильний
- захист
- забезпечувати
- громадськість
- піторх
- якість
- випадковий
- швидше
- реальний
- Реальний світ
- реалістичний
- реалії
- розумний
- Причини
- останній
- визнавати
- Знижений
- скорочення
- відображати
- Роздуми
- про
- правила
- пов'язаний
- Відносини
- щодо
- звільнити
- випущений
- чудовий
- запам'ятати
- вимагається
- Вимога
- Вимагається
- дослідження
- дослідницької групи
- дослідник
- Дослідники
- ресурси
- відновлює
- результат
- в результаті
- результати
- утримує
- знову використовувати
- зворотний
- здійснити революцію
- революціонізували
- ризики
- міцний
- Кімната
- s
- Безпека
- то ж
- шкала
- схема
- рахунок
- побачити
- сегментація
- обраний
- семантика
- розділення
- служити
- комплект
- кілька
- недоліки
- Показувати
- Шоу
- підпис
- Сигнал
- значний
- істотно
- аналогічний
- Розмір
- навички
- Повільно
- невеликий
- соціальна
- деякі
- складний
- Простір
- конкретний
- зазначений
- стабільний
- Стажування
- Станфорд
- Стенфордський університет
- старт
- стан
- впроваджений
- статистичний
- заходи
- Як і раніше
- просто
- сильні сторони
- успіхів
- структура
- Вивчення
- стиль
- такі
- підходящий
- РЕЗЮМЕ
- чудовий
- підтримка
- Підтримуючий
- система
- Systems
- снасті
- приймає
- завдання
- команда
- методи
- Технологія
- тензорний потік
- terms
- тест
- ніж
- Що
- Команда
- Майбутнє
- їх
- Їх
- потім
- Там.
- тим самим
- Ці
- вони
- це
- хоча?
- через
- по всьому
- час
- до
- занадто
- інструмент
- інструменти
- топ
- ТОПБОТИ
- торгувати
- торгові площі
- поїзд
- навчений
- Навчання
- Перетворення
- трансформатор
- Трансформатори
- перетворення
- переходи
- величезний
- два
- тип
- не в змозі
- безумовно
- що лежить в основі
- розуміти
- розуміння
- створеного
- Universal
- університет
- безпрецедентний
- до
- Updates
- на
- використання
- використовуваний
- використання
- використовує
- v1
- змінні
- різний
- Проти
- дуже
- Відео
- Вінсент
- бачення
- було
- we
- ДОБРЕ
- добре відомі
- були
- Що
- коли
- який
- в той час як
- ВООЗ
- чий
- широкий
- волі
- з
- в
- без
- свідком
- слова
- робочий
- працює
- світ
- б
- рік
- років
- поступаючись
- ви
- вашу
- зефірнет